 時系列予測は、かなり一般的な分析タスクです。 予測は、たとえば、オンラインサービスが1年間に必要とするサーバーの数、ハイパーマーケットの各製品の需要を理解するため、または目標を設定してチームの作業を評価するために使用されます(これのために、ベースライン予測を構築し、実際の値を予測と比較できます)。
時系列予測は、かなり一般的な分析タスクです。 予測は、たとえば、オンラインサービスが1年間に必要とするサーバーの数、ハイパーマーケットの各製品の需要を理解するため、または目標を設定してチームの作業を評価するために使用されます(これのために、ベースライン予測を構築し、実際の値を予測と比較できます)。
ARIMA 、 ARCH 、回帰モデル、ニューラルネットワークなど、時系列を予測するためのさまざまなアプローチが多数あります。
今日は、 Facebook Prophet時系列を予測するためのライブラリ( 英語から翻訳、「prophet」、2017年2月23日にオープンソースでリリース )に精通し、Habrehabrの投稿数を予測するという重要なタスクにも挑戦します。
図書館
Facebook Prophet 記事によると、多数の異なるビジネスメトリックを予測し、非常に優れたデフォルトの予測を作成するように設計されています。 さらに、このライブラリは、人間が読み取れるパラメーターを変更することにより、予測を改善することを可能にし、アナリストが予測モデルの設計に関する深い知識を必要としないようにします。
Prophetライブラリがどのように機能するかについて少し話しましょう。 本質的に、これは次のコンポーネントで構成される加法回帰モデルです。
y(t)=g(t)+s(t)+h(t)+ epsilont
- 季節の成分 s(t) 彼らは、毎週および毎年の季節性に関連する定期的な変化をモデル化する責任があります。 週ごとの季節性は、
dummy variablesを使用してモデル化されdummy variables 。 [monday, tuesday, wednesday, thursday, friday, saturday]など、日付に応じて値0および1をとる6つの記号が追加されます。 曜日の7日目に対応するsunday属性は追加されません。これは、他の曜日に線形に依存し、これがモデルに影響するためです。
年間の季節性は、フーリエ級数によってモデル化されます。 - トレンド g(t) -これは区分的線形またはロジスティック関数です。 線形関数を使用すると、すべてが明確になります。 フォームのロジスティック関数 g(t)= fracC1+exp(−k(t−b)) インディケータが増加すると成長率が低下する場合、飽和状態で成長をシミュレートできます。 典型的な例は、アプリケーションまたはサイトの視聴者の増加です。
とりわけ、ライブラリは履歴データからトレンド変化の最適なポイントを選択できます。 ただし、手動で設定することもできます(たとえば、重要な指標に大きな影響を与える新機能のリリース日がわかっている場合)。 - 成分 h(t) ブラックフライデーなどの不規則な日を含む、ユーザー定義の異常な日を担当します。
- エラー epsilont モデルによって考慮されない情報が含まれます。
アルゴリズムの詳細については、ベンジャミン・レサムの「大規模な予測」のショーン・J・テイラーを参照してください 。
同じ出版物は、自動時系列予測のさまざまな方法のmean absolute percentage error比較も示しており、 Prophet誤差は大幅に低くなっています。
まず、記事のモデルの品質がどのように評価されるかを理解してから、 Prophet比較されたアルゴリズムに移りましょう。
MAPE (mean absolute percentage error)は、予測の平均絶対誤差です。 させる yi インジケータであり、 hatyi -これは、この値に対応するモデルの予測です。 それから ei=yi− hatyi 予測エラーです pi= fraceiyi 相対的な予測エラーです。
MAPE=平均(|pi|)
この値は相対的であり、異なるデータセットであっても品質を比較するために使用できるため、 MAPEしばしば品質の評価に使用されます。
さらに、絶対項でモデルがどの程度誤解されているかを理解するために、絶対誤差MAE - mean absolute errorを調べると便利です。
MAE=平均(|ei|)
特にそれらのほとんどは非常にシンプルで、しばしばベースラインとして使用されているため、 Prophet出版物で比較されたアルゴリズムについていくつかの言葉を言う価値があります。
naive最後のポイントまでに後続のすべての値を予測する場合の単純な予測。snaive - seasonal naive -この予測は、顕著な季節性を持つデータに適しています。 たとえば、週ごとの季節性を示すインジケーターについて話している場合、その後の月曜日ごとに、最後の月曜日、火曜日、最後の火曜日などの値を取得します。meanインジケーターの平均値は予測として使用されます。arima - autoregressive integrated moving average詳細。ets - exponential smoothing詳細。
練習する
設置
まず、ライブラリをインストールする必要があります。 Prophetライブラリは、 pythonおよびR利用可能ですR 私はpython好きなので、使用しました。 pythonライブラリは次のようにPyPiを使用してPyPiれます。
pip install fbprophet
Rでは、ライブラリにはCRAN package 。 詳細なインストール手順は、 ドキュメントに記載されています 。
データ
予測の指標として、Habrahabrで公開される投稿の数を選択しました。 Kaggleトレーニングコンテスト「 Habré での記事の人気の予測」からデータを取得しました 。 競争とそれが開催される機械学習コースについて詳しく説明します。
データの前処理のためのコード import pandas as pd habr_df = pd.read_csv('howpop_train.csv') habr_df['published'] = pd.to_datetime(habr_df.published) habr_df = habr_df[['published', 'url']] aggr_habr_df = habr_df.groupby('published')[['url']].count() aggr_habr_df.columns = ['posts'] aggr_habr_df = aggr_habr_df.resample('D').apply(sum)
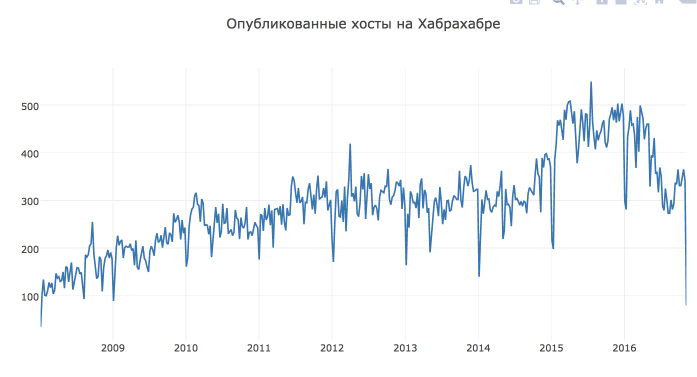
まず、データを見て、全期間のtime series plotを作成しましょう。 このような長い期間では、毎週のポイントを見る方が便利です。
視覚化には、いつものように、 plot.lyライブラリを使用します。これにより、 pythonインタラクティブなグラフを作成できます。 一般的な記事「 Open Machine Learning Course 」で、その詳細と視覚化について詳しく読むことができます。 トピック2:Pythonによるデータの視覚化 。
可視化コード from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot from plotly import graph_objs as go
予測
Prophetライブラリにはsklearnに似たインターフェースがあります。最初にモデルを作成し、次にfitメソッドを呼び出して、予測を取得します。 ライブラリは、 fitメソッドへの入力として2列のdataframeを受け入れます。
ds時間。フィールドはdate型またはdatetime型でなければなりません。yは、予測する数値指標です。
取得した予測の品質を測定するために、トレーニングから先月のデータを削除し、予測します。 作成者は、数か月、理想的には1年以上のデータを予測することをお勧めします(この場合、学習には数年の歴史があります)。
次に、 Prophetクラスのオブジェクトを作成し(すべてのモデルパラメーターはクラスコンストラクターで設定され、最初に既定のパラメーターを取得します)、トレーニングします。
m = Prophet() m.fit(train_df)
ヘルパー関数Prophet.make_future_dataframeを使用して、すべての過去の時点と、予測を作成したい別の30日間を含むdataframeを作成します。
予測を作成するために、モデルのpredict関数を呼び出して、前のステップで受け取ったdataframe futureをdataframe future 。
future = m.make_future_dataframe(periods=predictions) forecast = m.predict(future)
Prophetライブラリには、構築されたモデルの結果を評価できる視覚化ツールが組み込まれています。
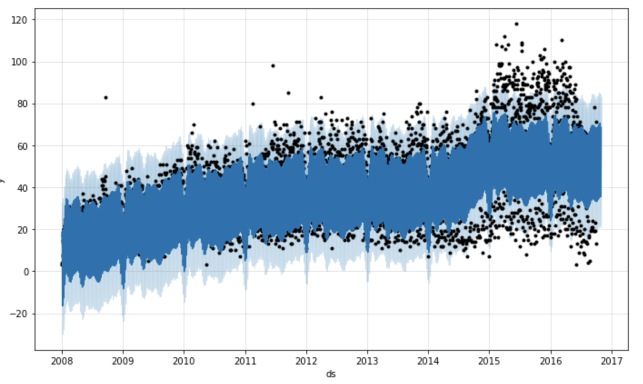
最初に、 Prophet.plotメソッドは予測を表示します。 正直なところ、この場合、そのような視覚化はあまり示唆的ではありません。 私が作成したこのグラフの主な結論は、データに多くのoutlierがあるということです。 ただし、予測の履歴ポイントが少ない場合は、何かを理解することができます。
m.plot(forecast)
私の意見では、2番目の関数Prophet.plot_componentsははるかに便利です。 コンポーネント、トレンド、年次、週次の季節性を個別に見ることができます。 モデルの構築時に異常な日/休日が指定された場合、それらもこのグラフに表示されます。
m.plot_components(forecast)
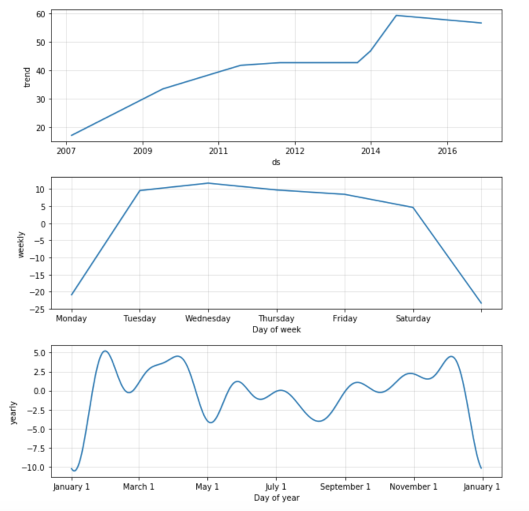
グラフは、 Prophetが2015年初頭の投稿「ステップ」の数の増加にうまく適応していることを示しています。 毎週の季節ごとに、日曜日と月曜日に投稿が少なくなると結論付けることができます。 年次季節性チャートでは、年末年始の活動の失敗が最も顕著であり、5月の祝日にも景気後退が見られます。
モデル品質評価
アルゴリズムの品質を評価し、予測した過去30日間のMAPEを計算しましょう。 計算には観測値が必要です yi それらの予測 h a t y i 。
最初に、ライブラリが生成するforecastオブジェクトを見てください。 実際、これは予測に必要なすべての情報があるdataframeです。
print(', '.join(forecast.columns))
ds, t, trend, seasonal_lower, seasonal_upper, trend_lower, trend_upper, yhat_lower, yhat_upper, weekly, weekly_lower, weekly_upper, yearly, yearly_lower, yearly_upper, seasonal, yhat
続行する前に、 forecastを最初の観測と組み合わせる必要があります。
cmp_df = forecast.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(df.set_index('ds'))
先月のデータを最初に延期して、30日間の予測を作成し、結果のモデルの品質を測定したことを思い出させてください。
import numpy as np cmp_df['e'] = cmp_df['y'] - cmp_df['yhat'] cmp_df['p'] = 100*cmp_df['e']/cmp_df['y'] print 'MAPE', np.mean(abs(cmp_df[-predictions:]['p'])) print 'MAE', np.mean(abs(cmp_df[-predictions:]['e']))
その結果、約37.35%品質が得られ、予測では平均してモデルは10.62投稿と間違われています。
可視化
実際の値、予測、および信頼区間を使用して、構築されたProphetモデルの視覚化を行いましょう。
まず、データが混乱することのないように、より短い期間データを残しておきます。 第二に、予測を行った期間のみのモデルの結果を表示したい-これによりチャートが読みやすくなるように思えます。 第三に、 plot.lyを使用してチャートをインタラクティブにしplot.ly
可視化コード
ご覧のとおり、上記の機能を使用すると、視覚化を柔軟にカスタマイズし、モデルの任意の数の観測と予測を表示できます。
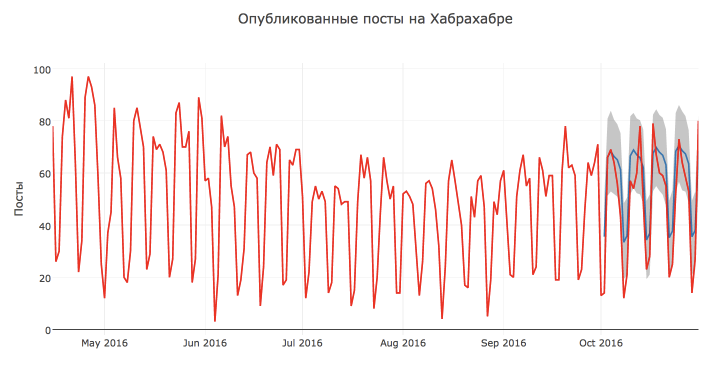
視覚的には、モデルの予測は非常に良好で合理的なようです。 おそらく、このような低い品質評価は、10月13日と17日に投稿数が異常に多くなり、10月7日からアクティビティが減少したためです。
また、グラフによれば、ほとんどのポイントは信頼区間内にあると結論付けることができます。
ARIMAモデルとの比較
一見、予測はかなり妥当であることが判明しましたが、これを従来のSARIMA - Seasonal autoregressive integrated moving averageモデル(週ごとのSARIMA - Seasonal autoregressive integrated moving averageと比較してみましょう。
HabrahabrにはARIMA モデルに関する記事がすでにいくつかあります。それらを読むことに興味がある人は誰でもお勧めします。
予測を作成するために、私はCourseraの応用データ分析コースのトレーニング資料にも触発されました。この資料では、 ARIMAモデルの詳細とpythonモデルを作成する方法について説明しています。
ARIMAモデルの構築はProphetよりもはるかに高価であることに注意する価値があります:初期シリーズを研究し、定常モデルに持ち込み、初期近似を取得し、アルゴリズムのハイパーパラメーターを選択するのに多くの時間を費やす必要があります(モデルはコンピューターでほぼ2時間選択されました)。
しかし、この場合、努力は無駄ではなく、 SARIMA予測SARIMAより正確であることがSARIMAしましたSARIMA MAPE=16.54%, MAE=7.28 です。 パラメーターを使用した最適なモデル: D=1, d=1, Q=1, q=4, P=1, p=3 。
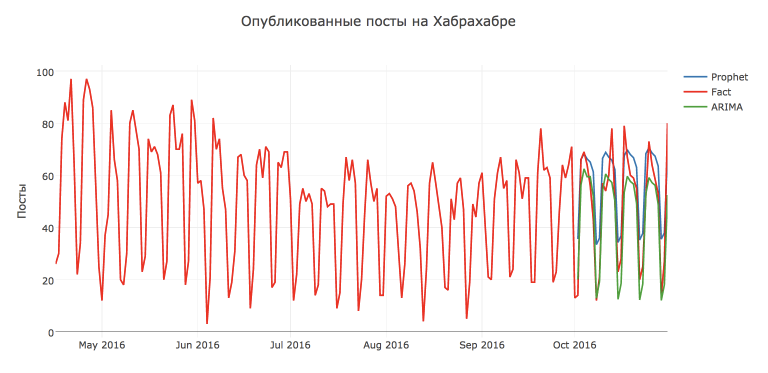
しかし、もちろんProphetはまだ引っ張ることができます。 たとえば、このライブラリで初期シリーズではなく、シリーズの分散を正規化するボックスコックス変換を予測すると、品質が向上します: MAPE=26.79%, MAE=8.49
Box-Cox変換を使用して系列を予測するためのコード from scipy import stats import statsmodels.api as sm def invboxcox(y,lmbda): if lmbda == 0: return(np.exp(y)) else: return(np.exp(np.log(lmbda*y+1)/lmbda)) train_df2 = train_df.copy().fillna(14) train_df2 = train_df2.set_index('ds') train_df2['y'], lmbda_prophet = stats.boxcox(train_df2['y']) train_df2.reset_index(inplace=True) m2 = Prophet() m2.fit(train_df2) future2 = m2.make_future_dataframe(periods=30) forecast2 = m2.predict(future2) forecast2['yhat'] = invboxcox(forecast2.yhat, lmbda_prophet) forecast2['yhat_lower'] = invboxcox(forecast2.yhat_lower, lmbda_prophet) forecast2['yhat_upper'] = invboxcox(forecast2.yhat_upper, lmbda_prophet) cmp_df2 = forecast2.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(df.set_index('ds')) cmp_df2['e'] = cmp_df2['y'] - cmp_df2['yhat'] cmp_df2['p'] = 100*cmp_df2['e']/cmp_df2['y'] np.mean(abs(cmp_df2[-predictions:]['p'])), np.mean(abs(cmp_df2[-predictions:]['e']))
まとめ
Prophetオープンソースライブラリと、実際の時系列予測への使用を紹介しました。
このライブラリが驚くほど機能し、将来を完全に予測するとは言いません。 私たちの場合、予測は標準のSARIMAよりも悪くなりました。 ただし、 Prophetライブラリは非常に便利で、簡単にカスタマイズできます(これは既知の異常な日を追加するだけの価値があります)。したがって、分析toolbox'eと便利toolbox'e 。
便利なリンク
一般に、 Prophetライブラリと時系列予測のより深い研究のためのいくつかの資料: