みなさんこんにちは。 この記事では、Zidium監視システムを使用してWindowsサービスの動作を制御する方法を説明します。
監視する理由
まず、監視とは何か、なぜ監視が必要なのか。 複数のシステムからデータを収集し、分析を実行し、レポートシステムにデータを送信するアプリケーションを注文しました。 アプリケーションをホスティングにデプロイされたWindowsサービスとして実装しました。 顧客は、アウトソーシングのためにサービスのさらなるサポートを私に手渡しました。つまり、私はそのパフォーマンスとエラーを修正する責任があります。
しかし、疑問が生じました-サービスで起こりうる問題をどのように追跡できますか?
内部エラーまたはフリーズによりサービスが停止した場合はどうなりますか? 顧客が数日間データが更新されていないという苦情を申し立てるまで、これについては知りません。 さらに、発生したエラーに関するデータ、分析用のログなどが必要です。
どのようなサービスステータス情報が必要ですか。
- アクティビティ信号の追跡(いわゆる「ハートビート」、ハートビート)。 サービスが停止すると、信号の受信が停止し、何か問題があることが明らかになります。
- 詳細なエラー情報の収集。 それらを修正する必要があります。 したがって、時間、メッセージ、スタックなど、できるだけ多くのデータが必要です。
- クラウドへのログイン。 なぜファイルではないのですか? このサービスは戦闘サーバーで実行され、管理者のみがアクセスできます。 管理者は忙しいので、ログを探して私に送る時間はありません。 または、ログが大きすぎて、企業のメールで送信されていないことがわかります。 一般に、ファイルはすべて複雑です。
- 電子メールによる、およびまあ、SMSによる問題の通知。 私-エラーについて、管理者-サービスの停止について。
- いくつかのパフォーマンス統計-データ処理の主要な領域の実行時間を測定します。 これは最適化に役立ちます。
- さて、異なる会計システムではなく、これらすべてを1つの場所に置くことが非常に望ましいです。
これは、監視システムが助けになる場所です。 このプロジェクトでは、
Zidiumモニタリングを選択し
ました 。 これは、無期限に完全に無料で使用できるクラウド監視システムです。 彼は私が必要とするすべてを1本のボトルに入れています。
仕組み
まず、監視せずに、サービスのソースコードを見てみましょう。 このサービスは、VS 2015の環境ではC#で記述されています。

ここではすべてがウィンドウの標準です。スレッド、作業の中断を伴う無限ループ、反復の終了時の遅延。
ループは、データを収集、処理、および送信するメソッドを実行します。 この記事では、彼らが正確に何をするかは重要ではありません。
Zidiumをプロジェクトに接続します。 これはNugetパッケージを使用して行われます。 dllとzidium.xmlファイルを設定とともに追加します。 xmlファイルで、アカウントのアクセス設定を設定します。 ファイルを使用することはできませんが、プログラムですべてを設定できますが、そのような構成の方が正しいように思えます。
Zidium Webサイトのドキュメントから使用例をすべて取り上げました。
まず、システムに接続して「コンポーネント」を取得するヘルパークラスを作成します。 私の場合、コンポーネントはサービスそのものです。 ここではすべてがドキュメントで推奨されているとおりで、名前のみが修正されています。

コンポーネントの作成を確認するために、サービスの起動メソッドにコンポーネントの領収書を挿入し、IsFakeメソッドを呼び出しました(実際、Zidium側のコンポーネントは、実際の作業が行われたときにのみ作成されます)。 通常の操作では、これは必要ありません。テスト後にこの呼び出しを削除できます。

開始後、アカウントにコンポーネントが表示されました。

まだデータを送信していないため、彼の色は灰色です。
アクティビティ信号(HeartBeat)
今すぐアクティビティ信号を追加します。 このために、いわゆる「ユニットテスト」が使用されます。
最初は、「コンポーネント」のチェック自体を作成し、変数に記憶する必要があります。
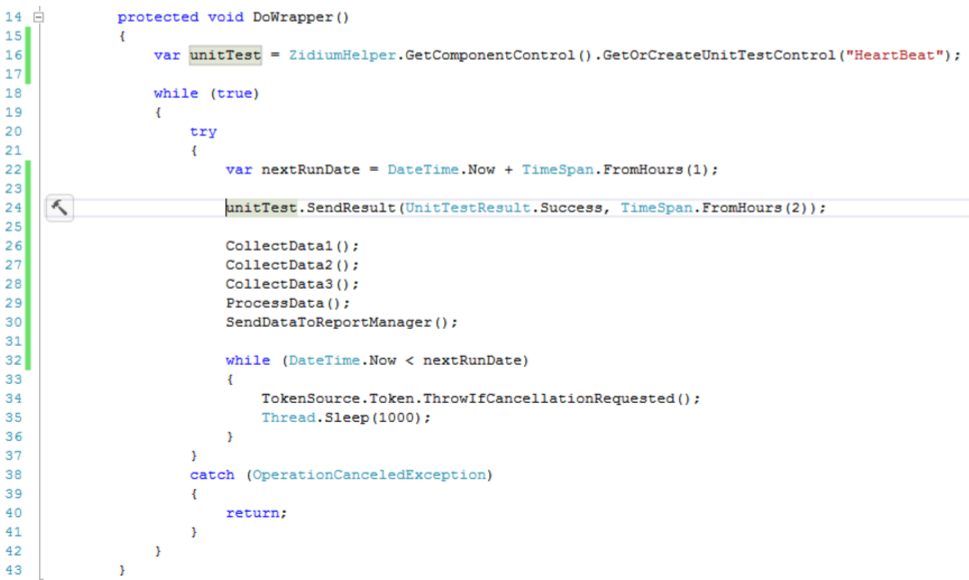
現在、作業サイクルの各反復で、サービスが正常に機能していることを確認した結果を送信します。 この場合、関連の時間を示します。 これは、次の信号が受信されない場合にシステムがアラームを発生させる正確な時間です。
私のデータは1時間に1回収集されるので、2時間の関連性を示しました。これは、1サイクルの作業のための予備です。 当然のことながら、メソッドのリアルタイムを考慮する必要がありますが、複雑にすることはありません。
サービスを開始すると、個人アカウントに緑色のコンポーネントと緑色のチェックが表示されます。 すべてが順調です。
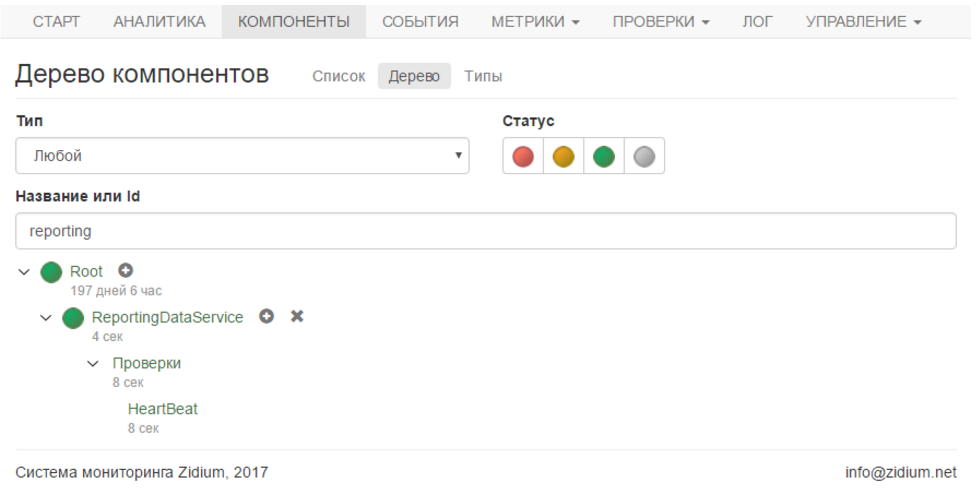
テストでは、1分という緊急時間を示し(長く待たないように)、サービスを停止しました。
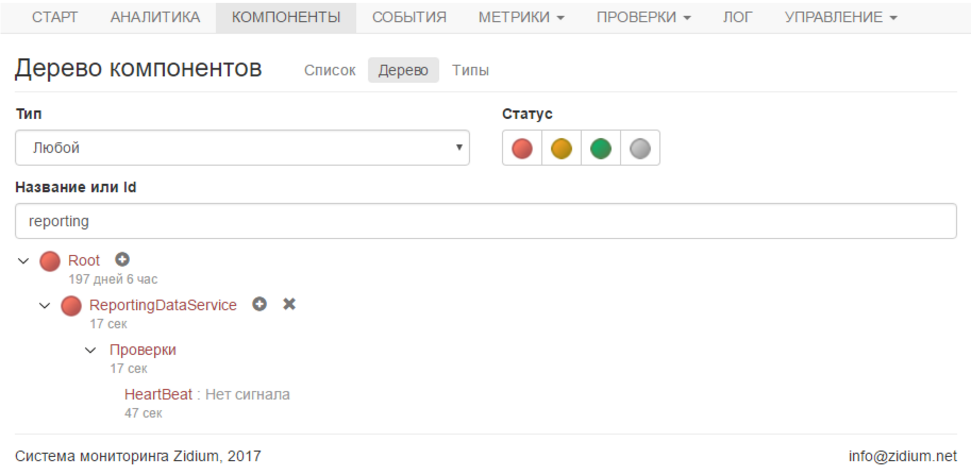
1分後、スキャンしたコンポーネントが赤になり、信号がなかったことを通知する電子メールを受け取りました。
すべての通知は非常に柔軟であり、電子メールとSMSで受信できます。 各ユーザーには、独自の連絡先と通知設定があります。 さて、この問題は解決されました。
間違い
それでは、エラーに対処しましょう。 ここではすべてが簡単です。
{}を試すと、キャッチでエラーを送信します。 例外からメッセージ、スタックなどを割り当てる便利な既製のメソッドがあります。 そして間違いを形成します。

テストでは、ループの本体でthrow new Exception()を呼び出しました。 アカウントのエラーは次のとおりです。
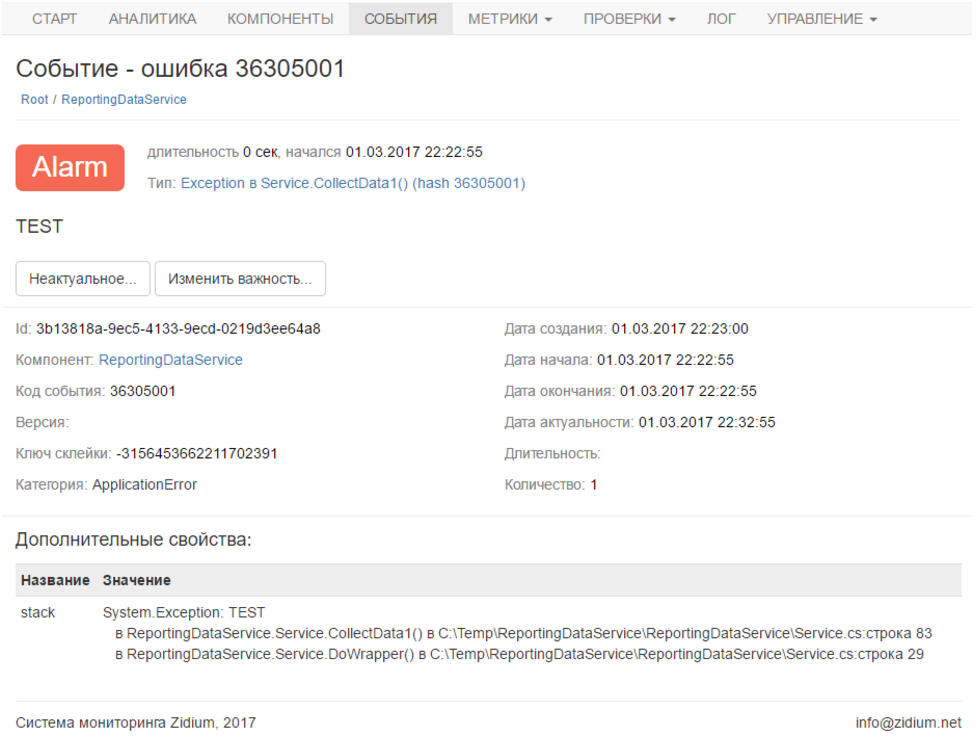
繰り返しになりますが、必要な場合は彼女に関する通知を受け取ります。
Zidiumは、いくつかのエラーが実際には同じであることを非常に知的に理解していると言わなければなりません。 このようなエラーは1つにまとめられ、非常に便利です。 また、通知によるスパムもありません。
ログ
次に、ログがあります。 ログの操作は、nLogやLog4Netなどの他のロギングライブラリと同様に行われます。 レコードのレベル(重要度)を示して、必要なものを書くだけです。

ボーナス-任意の数の追加プロパティを各ログエントリに添付できます。これらのプロパティには、xmlなど、何でも入力できます。 それらはログ自体を散らかすことはありませんが、いつでも見ることができます。
アカウントのログは次のとおりです。
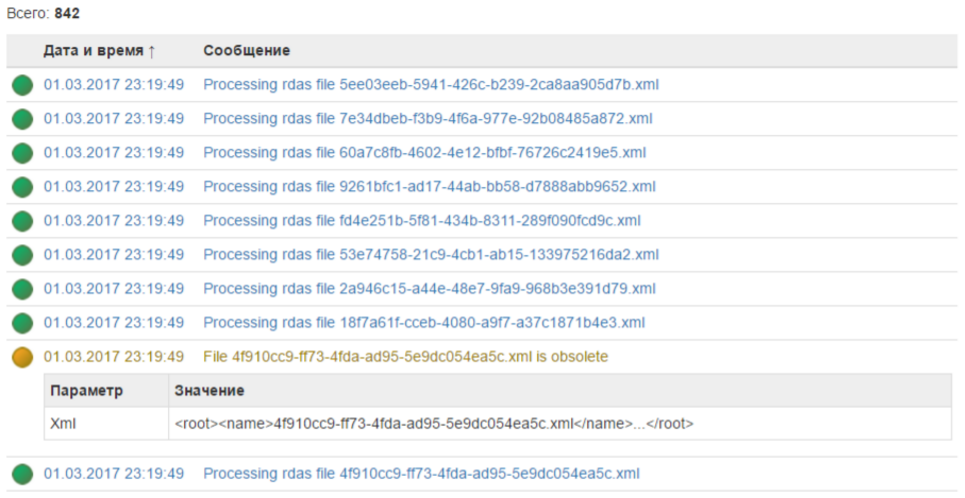
私にとっては、巨大なテストファイルを読むよりもはるかに便利です。
クラウドログに加えて、Zidiumは念のため古典的なファイルログを書き込みます(ただし、これは無効にできます)。 他のロギングライブラリも接続する必要がないのは素晴らしいことです。 それでも、極端な場合、たとえばクラウドとの接続がなかった場合、ファイルログは便利です。
性能
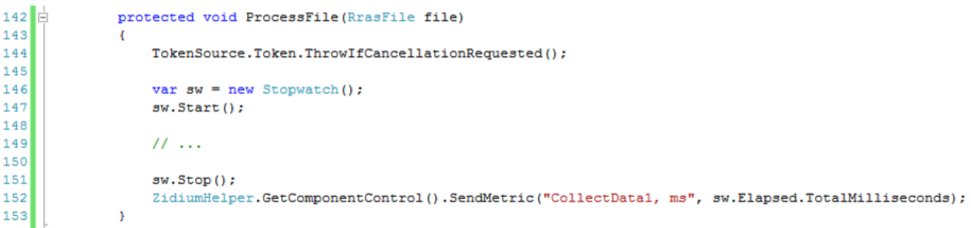
最後に、パフォーマンス統計。 このために、「メトリック」が使用されます。 興味のあるメソッドの合計作業時間を測定します。
メトリックには名前と意味があり、次のように送信されます。
アカウントでは、メトリックの全履歴を詳細に見ることができます。
選択した期間の主な集計-最大、最小、および平均がすぐに考慮されます。
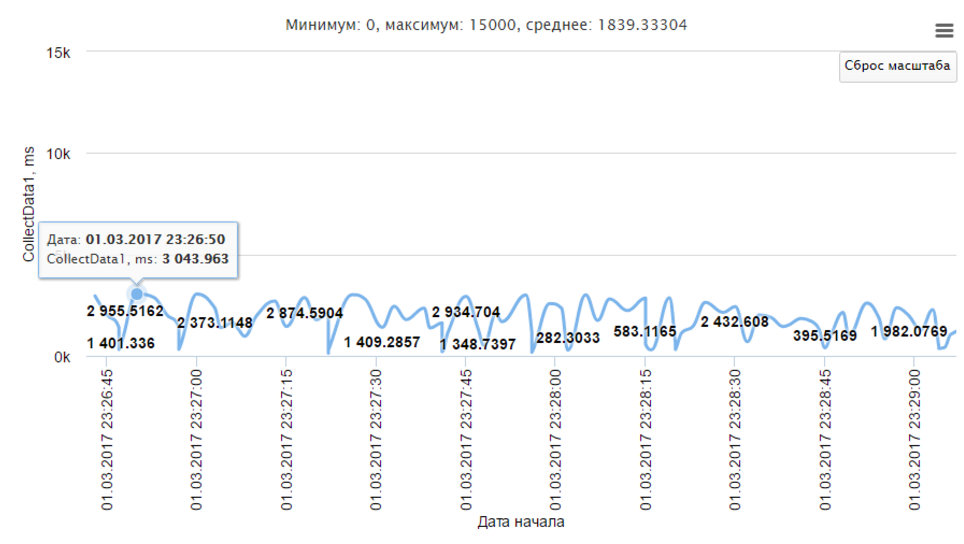
残念です。xlsxまたはcsv形式でデータをダウンロードすることはできません。これは、独自の分析に役立つ可能性があります。
また、メトリックについては、選択した範囲外の値に関する警告のルールを構成できます。 その後、メトリックも通知を受け取ります。 しかし、私はそれを使用しませんでした。稼働時間に関する統計情報を持っているだけで便利です。
合計
私のサービスは、アクティビティシグナルを監視に送信し、エラーを収集し、クラウドログを書き込み、パフォーマンス統計を保持します。
サービスが突然停止またはフリーズした場合、通知を受け取ります。 エラーが発生した場合は通知されます。
今、私は自分が行った仕事と顧客への義務の履行に対して冷静です)