
この記事では、データをSplunkにロードする方法、組み込みのSPL言語に基づいてシステムで検索クエリを作成する方法、およびそれらを視覚化する方法について説明します。 これは、
テストデータに基づいた純粋に実用的な「ハウツー」記事で、アクセスは自由に利用でき、誰でもダウンロードできます。
読んで実際に繰り返した後、次のことを学びます。
- システムの基本機能を使用する
- Splunkにデータをアップロードする
- 基本的な検索クエリを作成する
- 結果を視覚化する
システムへのデータのアップロード
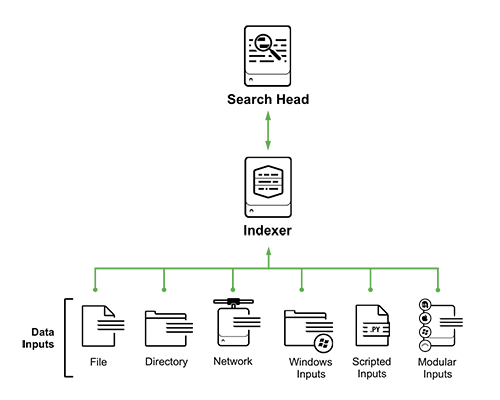
システムでログを収集するための5つの主なソースがあります(これは完全なリストではありません)。
- ファイルとディレクトリ: Splunkは、特定のファイルまたはファイルを含むディレクトリを一度だけピックアップまたは監視し、変更を個別に監視できます
- ネットワークイベント:ネットワークポートからのデータ(syslogなど)
- Windowsソース:Windowsイベントログ、ADイベント
- スクリプト化された入力:スクリプトを介して収集されたデータ
- モジュラー入力:特定のプラットフォーム、システム、アプリケーションからのデータ収集
この記事では、明確にするために、最も単純な方法を使用します。 ローカルコンピューターからSplunkに
テストファイルをアップロードするだけです。 エンタープライズの歴史上、これを誰も使用していないことは明らかであり、上記のオプションはターゲットシステム上の
エージェント (フォワーダー)と一緒に使用され、インフラストラクチャは次のようになります。

しかし、このケーススタディでは、ローカルコンピューターにダウンロードされた1つの無料の
Splunk Enterprise Freeで十分です。 インストール手順については、
以前の記事をご覧ください 。
データをダウンロードしてSplunkをインストールしたら、データをロードする必要があります。 実際、データは事前に準備されているため、非常に簡単です(
指示 )。
重要 ! アーカイブを解凍する必要はありません。
SPLリクエスト
SPL言語の主な機能:
- 140以上の検索チーム
- 構文は、UnixパイプラインおよびSQLに似ており、 タイムスタンプ付きデータ用に最適化されています。
- SPLを使用すると、検索、フィルタリング、変更、強化、結合、削除ができます
- SPLには機械学習と異常検索機能が含まれています
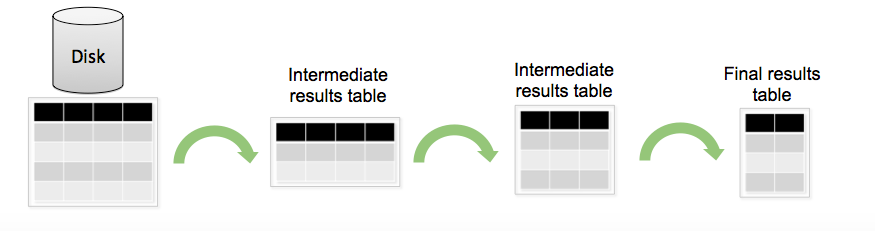
SPL構造:
デフォルトでは、SPLリクエストはいくつかの段階に分割できます:必要なデータのフィルタリングと選択、既存のデータに基づいた新しいフィールドの作成、データの集計と統計の計算、最後にフィールドの名前の変更、出力の並べ替え。

システムにデータをアップロードした後、それを検索できます(以下はクエリの例で、実行結果があります):
検索インターフェイスは次のとおりです。
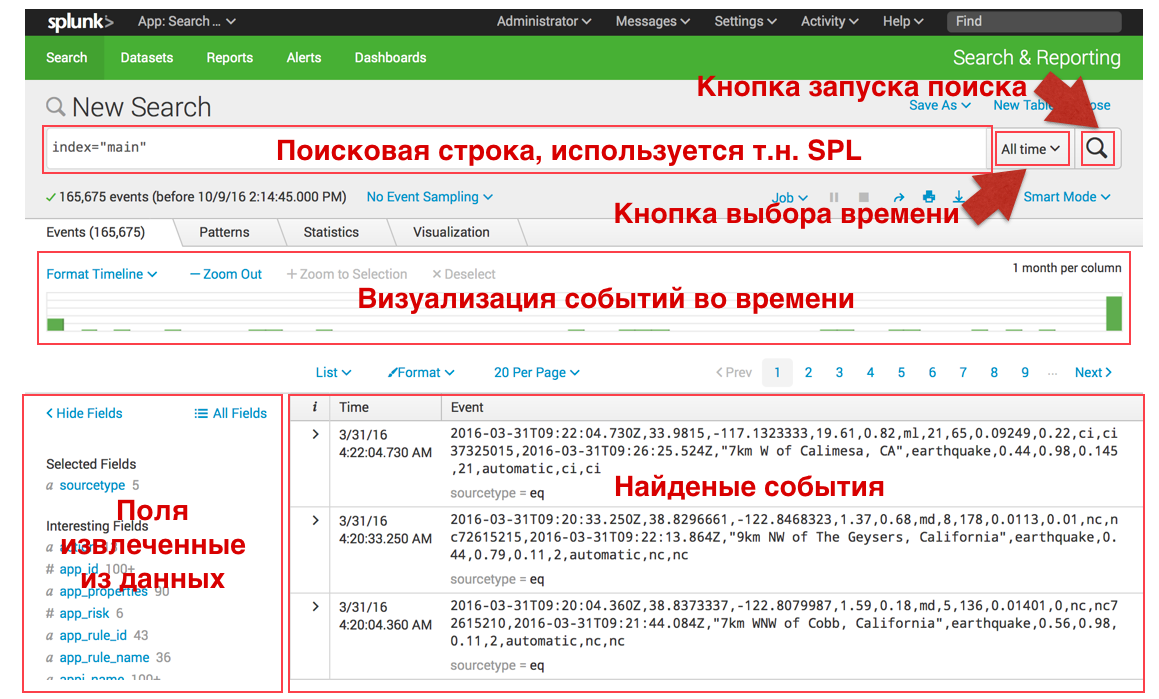
検索とフィルター:
Splunkでは、以下の例のように、キーワードまたは「標準の論理演算子で区切られたキーワードのセット」によって「Googleのような」イベントを検索できます。 また、右側のメニューと特定の期間のイベント数を示す中央の緑のヒストグラムの両方で必要な時間間隔を選択することにより、いつでも検索を更新できます。
- キーワード検索 : sourcetype = access * http
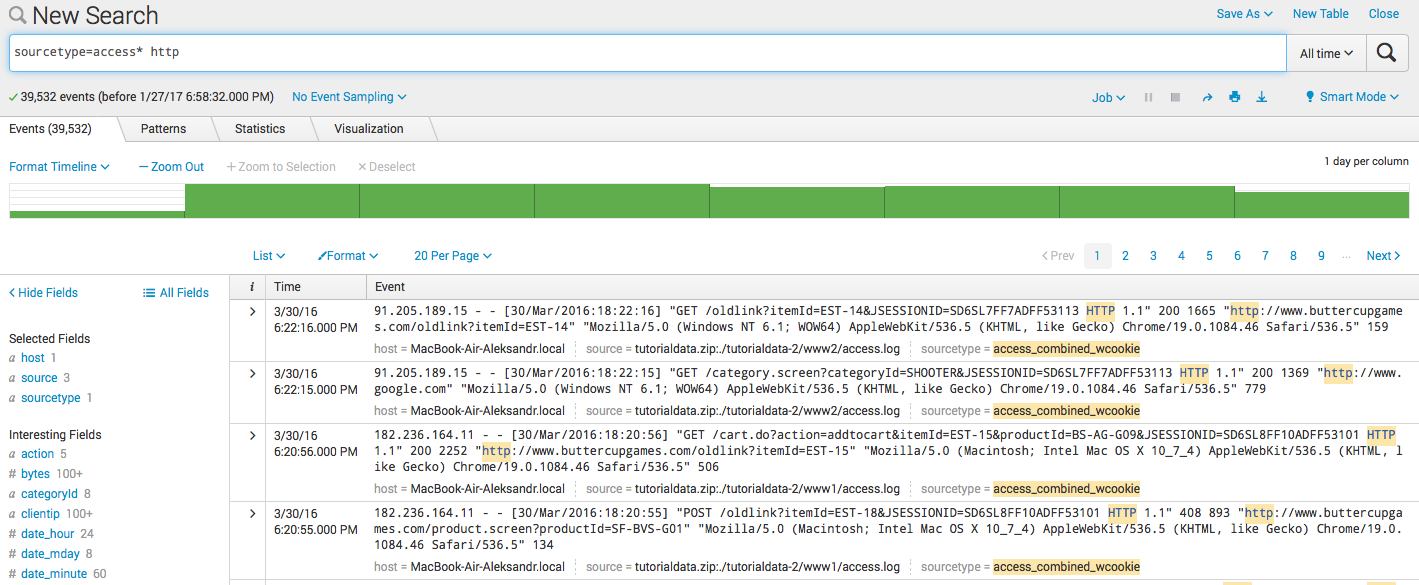
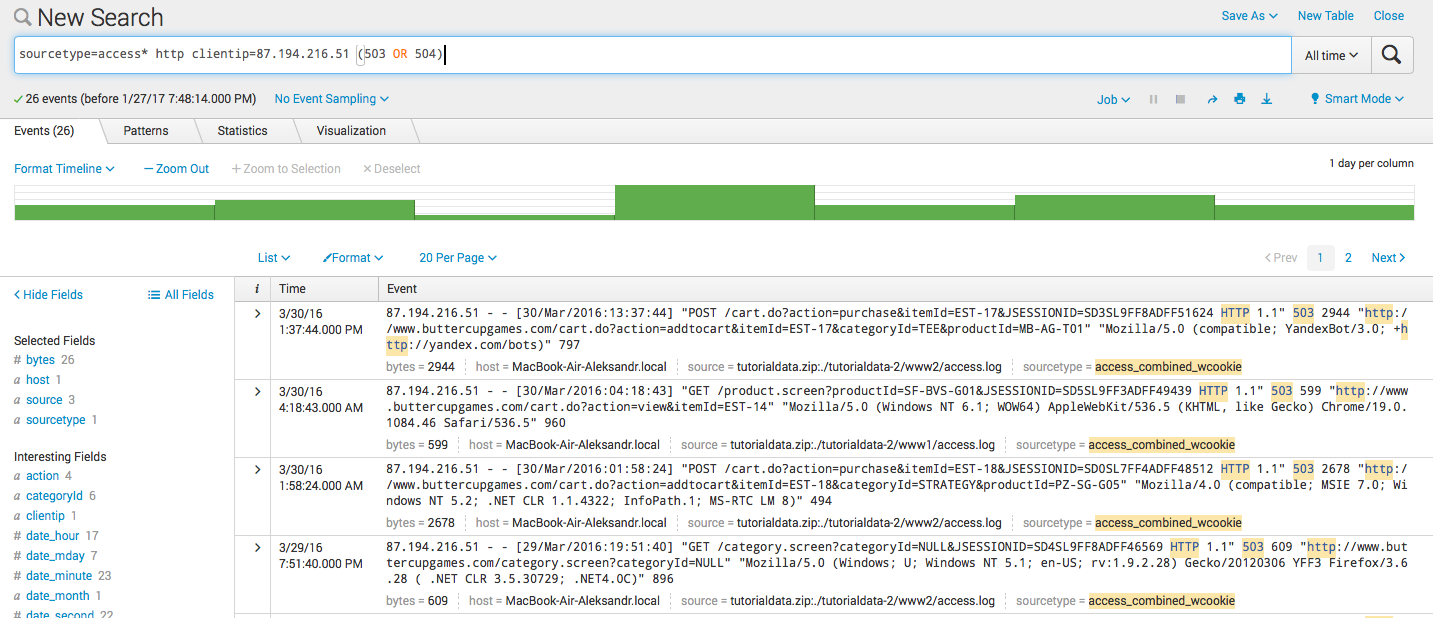
- フィルタリング : sourcetype = access * http clientip = 87.194.216.51

- 組み合わせ sourcetype = access * http clientip = 87.194.216.51(503 OR 504)
計算フィールド(評価):
Splunkは、既存のフィールドに基づいて新しいフィールドを作成できますこのために、
evalコマンドが使用され、その構文と使用例を以下に説明します。 いくつかのフィールドを作成した後、さらにリクエストに参加することもできます。
- 新しいフィールドの計算: sourcetype = access * | 評価KB =バイト/ 1024

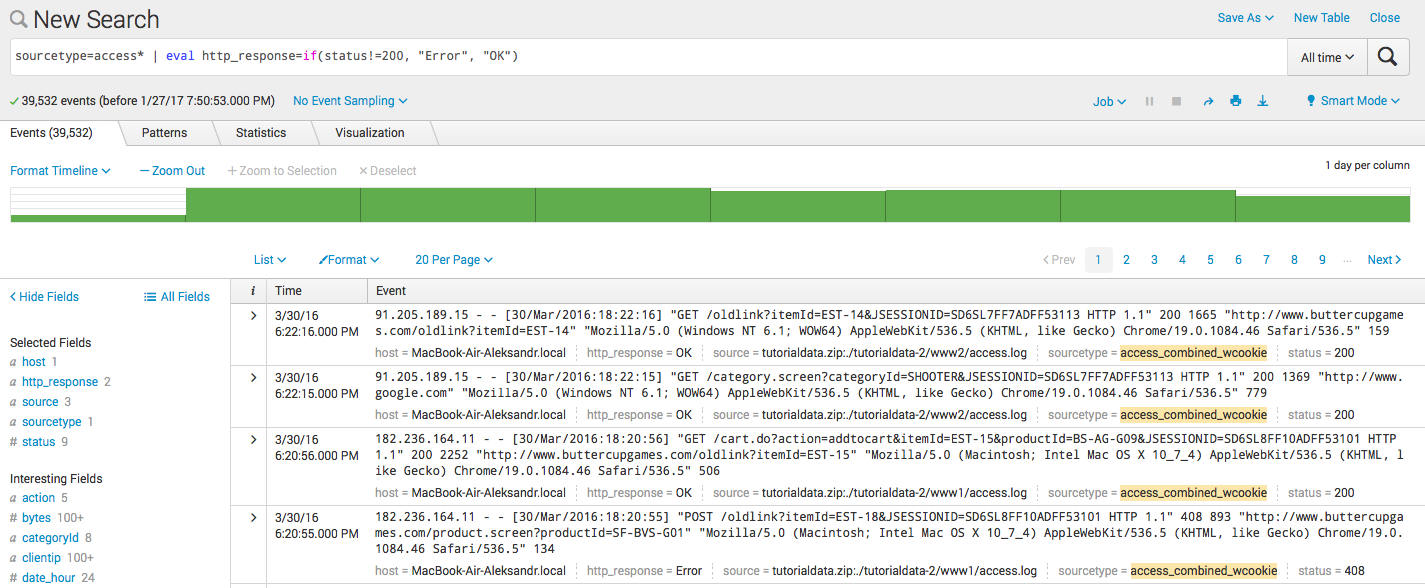
- 条件による新しいフィールドの作成: sourcetype = access * | eval http_response = if(status!= 200、 "Error"、 "OK")
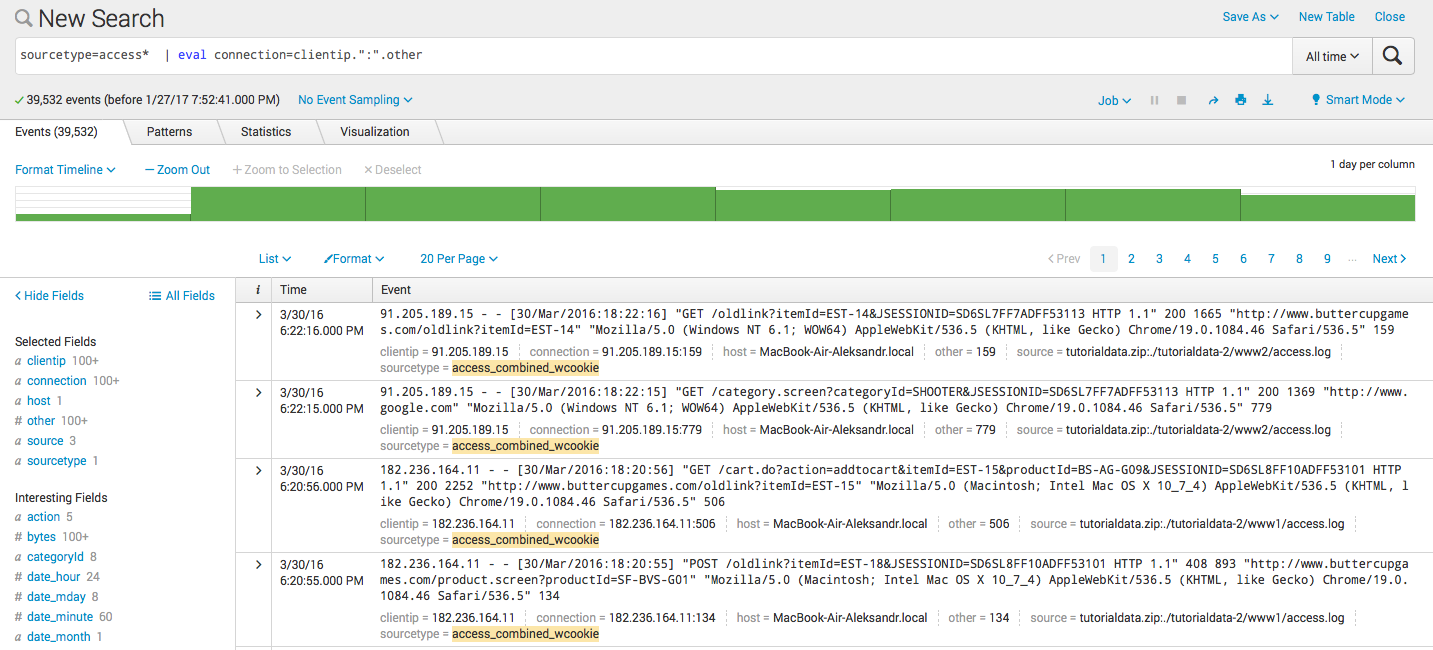
- 新規の2つのフィールドの結合: sourcetype = access * | eval connection = clientip。 ":"。その他
統計クエリと視覚化:
新しいフィールドのフィルタリングと作成を学んだ後、次のステップである統計クエリまたはデータ集約に進みます。 さらに、これらはすべて自然に視覚化できます。 これらのリクエストについては、
別のテストファイルをシステムにダウンロードする必要があり
ます 。 ブート段階で、[
名前を付けて
保存 ]ボタンを使用して
sourcetype csvを
eqに 変更し、クエリ結果がスクリーンショットに一致するようにすることが重要です。

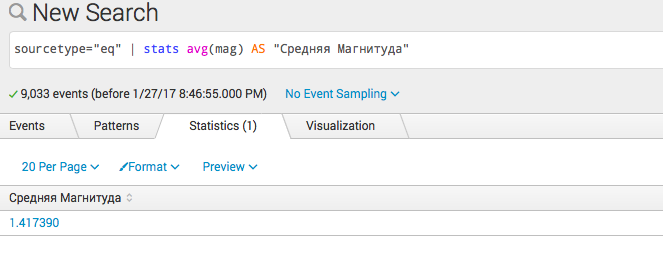
- 計算: sourcetype = "eq" | stats avg(mag)AS Medium Magnitude
- いくつかの計算: sourcetype = "eq" | 統計avg(mag)AS "Medium Magnitude"、スパークライン(avg(mag))AS "Trend"
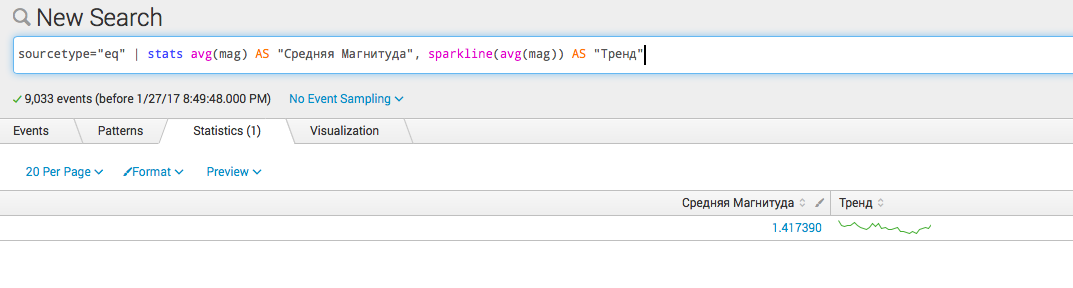
- タイプフィールドによるグループ化 sourcetype = "eq" | 統計avg(mag)AS「中規模」、スパークライン(avg(mag))AS「種類別」

経時的な統計クエリ:
Splunkはすべての検索を時間内に実行するため、最も一般的なコマンドの1つは
timechartです 。これにより、時間参照を使用して統計クエリを作成できます。以下に例を示します(視覚化の種類は、統計、視覚化タブ、および書式ボタンの下のインターフェイスで選択できます):
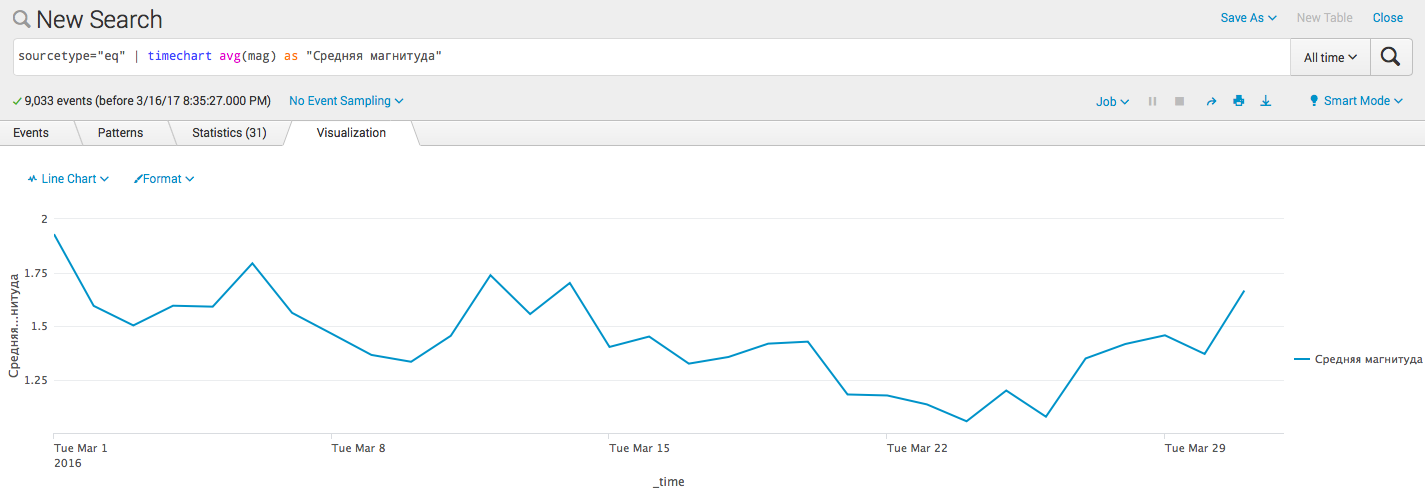
- 時間通りの単純な統計の視覚化: sourcetype = "eq" | 「中規模」としてのタイムチャートavg(mag)
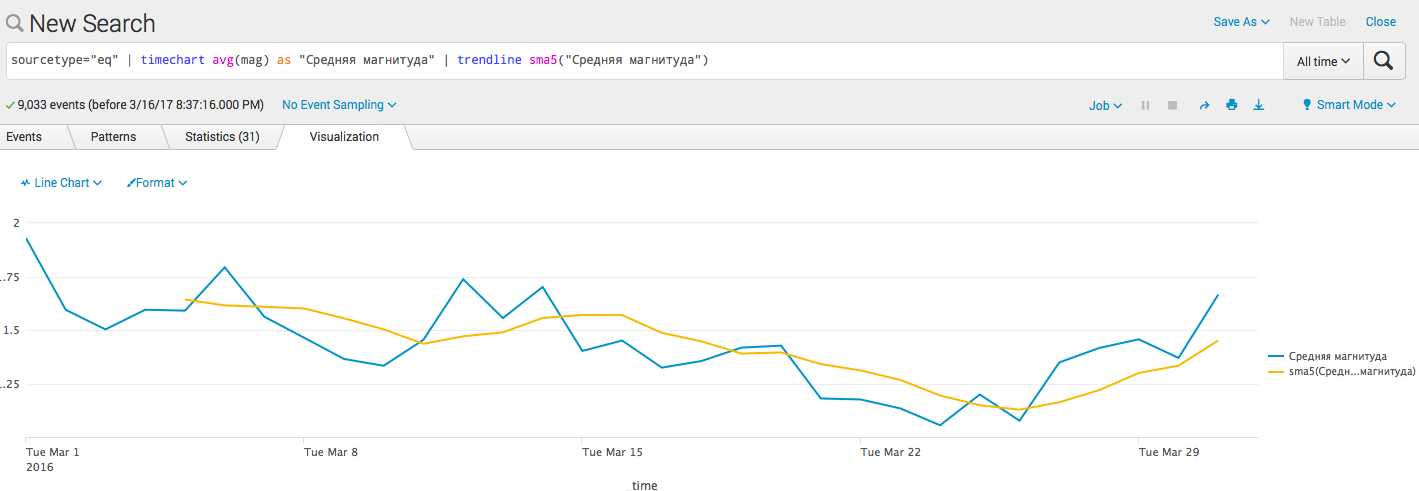
- トレンドラインを追加します( アルゴリズム ): sourcetype = "eq" | 「中規模」としてのタイムチャートavg(mag)| トレンドラインsma5(中規模)
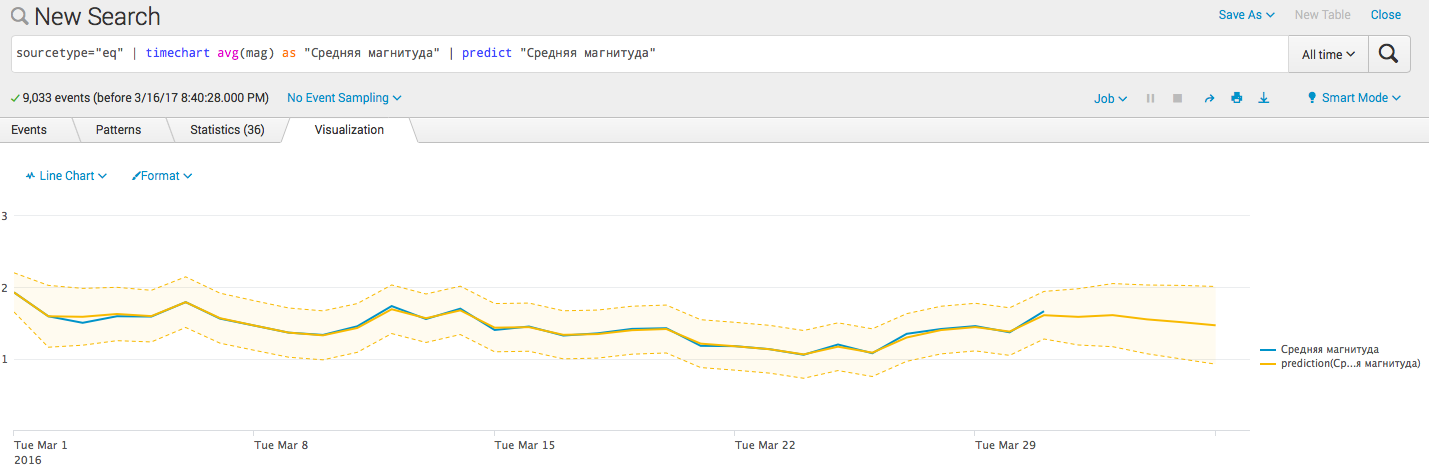
- 予測障壁を追加します。 sourcetype = "eq" | 「中規模」としてのタイムチャートavg(mag)| 「中規模」を予測する
おわりに
次回は、地理座標を持つデータを操作できるいくつかの興味深いコマンドと、これらの座標が利用できない場合にそれらを取得する方法と場所、およびトランザクションを強調表示してイベントのシーケンスを識別するデータのグループ化について説明します。
また、Splunk-
クイックリファレンスガイドに関する多くの情報を1か所にまとめた非常に便利なドキュメントについても言及します。