ニューラルネットワークを含む多くの機械学習アルゴリズムでは、加重和、またはそうでなければ入力ベクトル成分の線形結合を常に処理する必要があります。 そして、結果のスカラー値の意味は何ですか?
記事では、すべての例を簡単に再現し、独自の実験を行うことができるように、多くの図とPythonコードだけでなく、例、式、この質問に答えようとします。
モデル例
理論が実際のケースから外れないように、例としてバイナリ分類問題を取り上げます。 データセットがあります:m個のサンプル、各サンプルはn次元の点です。 各サンプルについて、それが属するクラス(緑または赤)がわかります。 データセットが線形に分離可能であることも知られています。 緑のドットがその片側にあり、赤のドットがもう一方の側にあるようなn次元の超平面があります。

このような超平面を見つける問題の解決策は、たとえばロジスティック回帰(ロジスティック回帰)、線形カーネルを使用したサポートベクトルの方法(線形SVM)、または最も単純なニューラルネットワークを使用するなど、さまざまな方法でアプローチできます。

記事の最後で、パーセプトロン学習メカニズムをゼロから記述し、得られた知識を使用して、バイナリ分類問題を自分の手で解決します。
直線から超平面へ
直線の詳細な計算を検討してください。 n次元空間の超平面の一般的な場合、すべてがまったく同じであり、ベクトルの成分の数に合わせて調整されます。

平面上の直線は3つの数字で定義されます-
:
または:
または:
最初の2つの要因
ポイント(0、0)を通る直線のファミリー全体を定義します。 の関係
そして
軸に対する線の傾斜角度を決定します。
もし
、45度の角度で走るラインを取得します(
)軸へ
そして
そして、第1/3象限を半分に分割します。
非ゼロ係数
行がゼロを通過しないようにします。 この場合、軸への傾き
そして
変わりません。 つまり
平行線のファミリーを定義します:

ベクトルの幾何学的な意味。
直線に垂直
:
(オフセットを考慮しない場合
それから
2つのベクトルのスカラー積にすぎません。 ゼロへの平等は、それらの直交性と同等です。 だから
-直交ベクトルのファミリー
)
 PS
PS線を定義するトリプル(w1、w2、b)など、無限に多くのそのような法線があることは明らかです。 3つの数値すべてに非ゼロ係数が乗算された場合
-行は同じままです。
n次元空間の一般的な場合、 n次元の超平面を定義します。
または:
または:
線形結合の幾何学的な意味
ポイントが
その後、超平面上にあります
ポイントが平面上にない場合、この合計はどうなりますか?
ハイパープレーンは、ハイパースペースを2つのハイパースペースに分割します。 そのため、これらのサブスペースの1つ(条件付きで「超平面」の上にある)にあるポイントと、これらのサブスペースのもう1つにあるポイント(条件付きで「超平面」の下にある)は、この合計で異なる符号を与えます:
-ポイントは超平面の「上」にあります
-ポイントは超平面の「下」にあります
これは非常に重要な観察であるため、単純なPythonコードで再確認することをお勧めします。

「上」と「下」は条件付きの概念であることを理解する必要があります。 これは例に具体的に反映されています-緑のドットは視覚的に低くなっています。 幾何学的な観点から、この特定の線の「上」の方向は法線ベクトルによって決まります。 法線が見えるところには、上部があります:

T.O. 線形結合記号を使用すると、ポイントを上部または下部のサブスペースに割り当てることができます。
そしてその意味は? 値(モジュロ)は、平面からの点の距離を決定します。
つまり ポイントが平面から遠いほど、その線形結合の値は大きくなります。 線形結合の値を修正すると、元の線に平行な線上にある点が得られます。
繰り返しますが、観察は重要なので、再確認します。
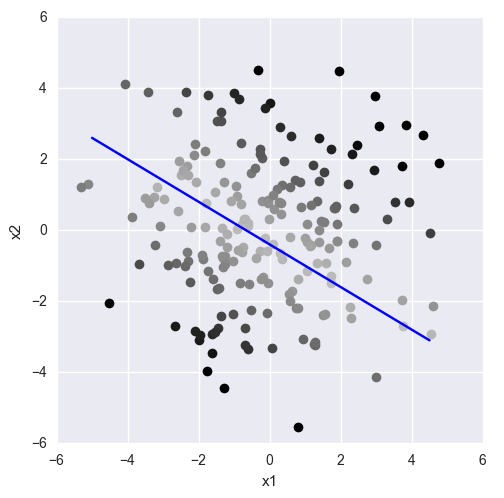
それはすべて一緒に収まります。
結論
- 線形結合により、n次元空間を超平面で分割できます。
- 超平面の反対側の点は、線形結合の異なる符号を持ちます 。
- 超平面から離れるほど、線形結合の絶対値が大きくなります。
バイナリ分類の観点から、最後のステートメントは次のように再定式化できます。 ポイントが決定平面である超平面から遠ければ遠いほど、このポイントによって定義されたサンプルが1つまたは別のクラスに分類されることを確信できます。
近いところと遠いところ:どうですか?
概念は非常に主観的です。 そして、分類では明確に答える必要があります-火星に飛ぶロケットの建設に適しているか、これは結婚です。 ユーザーが広告をクリックするかどうか。 ある程度の自信を持って答えることができます-肯定的な(真の)結果の確率を与えるために。
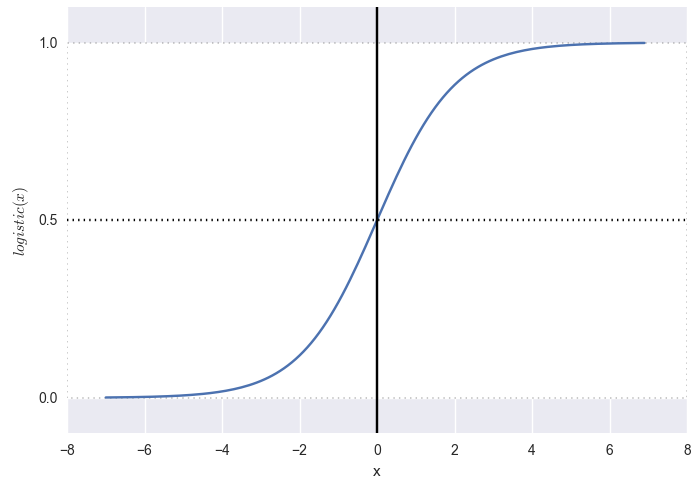
これを行うには、活性化関数を線形結合に適用できます(ニューラルネットワークの用語で)。
ロジスティック関数を適用する場合(下の図を参照):
確率の出力とそのような画像を取得します。

レッズ-間違いではありません(偽、結婚のように、クリックしません)。 緑-まさにはい(本当、ちょうどいい、クリックします)。 超平面(解の境界)に特定の近接範囲内にあるすべてのものは、何らかの確率を取得します。 最も直接的な確率では、正確に0.5です。
PSここで「正確に」は、0.001未満または0.999を超えると定義されます。 ロジスティック関数自体は、負の無限大でゼロになり、正の無限大で団結する傾向がありますが、これらの値を取りません。
注:この例は、符号付き距離を確率間隔に押し込む方法のみを示していることに注意してください。
。 実際の問題では、最適なマッピングを見つけるために確率キャリブレーションが使用されます。 たとえば、Plattスケーリングアルゴリズムでは、ロジスティック関数がパラメーター化されます。
そしてオッズ
そして
機械学習により選択。 詳細については、バイナリ分類子キャリブレーション、確率キャリブレーションを参照してください。
私たちはどのスペースにいますか? (有用な投機的演習)
それは明らかなようです-私たちはデータスペースにいます
(データ空間)サンプルが存在する場所
。 そして、ベクトルで定義される平面による最適な分離を探しています
。
緑のドット用
赤い点用
しかし、バイナリ分類の問題では、サンプルが固定され、重みが変化します。 したがって、重みの空間に入ることですべてを再生できます
(重量スペース):
トレーニングセットのサンプル
この場合セット
超平面と私たちのタスクは、そのような点を見つけることです
、各平面の右側にあります。 ソースデータセットが線形分離可能である場合、そのようなポイントが存在します。

モデルを訓練するとき、重みの空間で推論する方が便利です。 重みが更新され、トレーニングセットのサンプルベクトルが超平面の法線を定義します。 例:

サンプルと仮定します
不等式に対応する緑のクラスに対応します。
なぜなら ベクトル図
普通に見える
、線形結合の値は負になります-したがって、分類エラーがあります。
したがって、ベクトルを更新する必要があります
法線で示される側へ:
どこで
いくらかの「速度」で
。 したがって、次のステップでは、予測は真であるか偽であるかのどちらかです。 期間
、法線に合わせて、重みベクトルを緑の領域に「プル」します。
練習。 パーセプトロンを訓練する
サンプルの線形分離性の場合のバイナリ分類の問題を解決するために、このスキームに従って配置された単純なパーセプトロンをトレーニングできます。
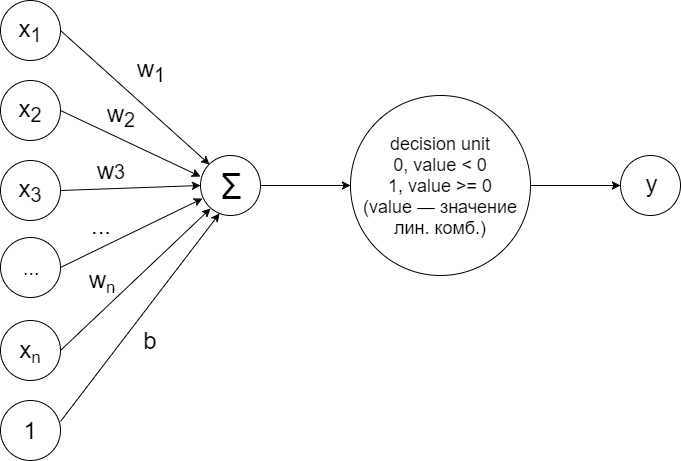
この設計は、上記で説明した原則を正確に実装しています。 線形結合が計算されます:
ソルバー(決定単位)が、次の原則に従って2つのクラスのいずれかにサンプルを帰属させることを決定する値によって:
クラス+1(緑色の点)
クラス-1(赤い点)
最初に、重みはランダムに初期化され、各サンプルの各トレーニングステップで次のアルゴリズムが実行されます。
予測ラベルが計算されます。 実際のクラスと一致しない場合、次の原則に従って重みが更新されます。
どこで
-サンプルの実際のクラス
。 なぜこれが機能するのかは、重みの空間への移行を伴う投機的な演習で上で説明されています。 簡単に:
- 重みベクトルを正しいクラスに向けて回転させます:normal クラス+1の場合。 通常に対して クラス-1の場合。 (法線自体は常にクラス+1の方向を向いています。)
- 同様の原則に従ってオフセットを更新します。
結果は次のとおりです。
 重みの空間を見てみましょう (重量スペース):
重みの空間を見てみましょう (重量スペース):
赤と緑の線はソースサンプル、青の点は総重量です。
そして、他のどの重みが正しい分類を与えますか? 私たちは見ます:
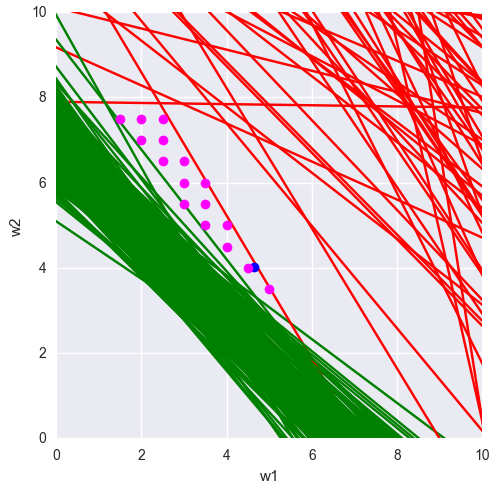
赤と緑の線はソースサンプル、青の点は総重量、紫の点は他の可能な重量です。
そして、すべてを再び裏返し、再びデータ空間に変えます
(データスペース):

上の図の重み空間、ここではデータ空間で紫色の点でマークされた重みは、ソリューションの他の可能な境界の線になりました。
演習(単純):最後の図では、4つの特徴的な線の束。 スケールのスペースにある紫色のドットの中から見つけてください。
著者から
記事の最初のバージョンに関する重要なコメントを寄せてくれたすべてのKhabrovsk市民に感謝します。yorkoは、
Open Data Scienceコミュニティとともに
、超クールなオープンマシンラーニングコースを実施しています。皆さんにお勧めします。
資料には最終的な仕上げがなく、記事は改訂のために送られたことが明らかになりました。 2番目の(現在の)バージョンには、パーセプトロントレーニングの例が追加されています。
まとめ
この記事が、線形結合の幾何学的な意味をより良く理解し、感じることを願っています。 以下は、記事の準備に使用される資料へのリンクであり、トピックを深めるという点で興味深いものです。 (すべての資料は英語です。)