JPoint 2016スピーカーの筋金入りのレポートを解読し続けているところで、今日はレポートが小さくなり、それぞれわずか1時間で、メリットとアニーリングの集中が1分間スケールしなくなります。
それで、エフゲニー・エフゲニー・ボリソフ・ボリソフは、スパークについて、神話、そしてピンク・フロイドのテキストがケイティ・ペリーよりも適切かどうかについて少し説明します。
これは、Sparkに関する珍しいレポートです。
通常、彼らはSparkについて多くのことを話し、それがいかにクールか、Scalaでコードを示します。 しかし、私はわずかに異なる目標を持っています。 まず、Sparkの概要と、Sparkが必要な理由について説明します。 しかし、主な目標は、Java開発者として完全に使用できることを示すことです。 このレポートでは、Sparkに関するいくつかの神話を払拭します。
自分について簡単に
私は2001年からJavaプログラマーです。
2003年までに、彼は同時に教え始めました。
2008年から彼は協議に従事し始めました。
2009年以来、彼はさまざまなプロジェクトのアーキテクチャに携わってきました。
スタートアップは2014年に独自にオープンしました。
2015年以来、私はNaya Technologiesのビッグデータの技術リーダーであり、可能な限りビッグデータを実装しています。 私たちには彼らを助けてほしいと願う膨大な数の顧客がいます。 私たちは壊滅的に新しいテクノロジーに精通している人が不足しているので、私たちは常に労働者を探しています。
スパーク神話
Sparkには多くの神話があります。
まず、詳細に説明する概念的な神話がいくつかあります。
- SparkはHadoopのローションの一種です。 多くの人が、SparkとHadoopが一緒にいるようだと聞いています。 これがそうであるかどうかについて話しましょう。
- そのSparkはScalaで作成する必要があります。 SparkはScalaで作成できるだけでなく、Scalaで作成するのが正しいと聞いたことがあるでしょう。ネイティブAPIなどのためです。 これが正しいかどうかについて話します。
- 私はSpringが大好きで、可能な限りポストプロセッサを使用しています。 ポストプロセッサは本当にここで何か利益をもたらしますか?
- Sparkテストで何が起こるかについて話しましょう。 Sparkはビッグデータであるため、テスト方法はあまり明確ではありません。 そこにはテストをまったく書けないという神話があり、書けば、すべてが私たちが慣れているものとは完全に異なって見えるでしょう。
いくつかの技術的な神話があります(これはSparkで作業するか、多少なりともそれを知っている人向けです)。
- ブロードキャストについて-場合によっては使用する必要があります。使用しないと、すべてがクラッシュします。 これがそうであるかどうかについて話してください。
- データフレームについて-データフレームはスキームを持つファイルにのみ使用できると言われ、他の場合に使用できるかどうかについて説明します。
そして、主な神話はピンクフロイドグループについてです。 ピンク・フロイドがブリトニー・スピアーズやキャッティ・ペリーのように賢いテキストを書く(書く)というのは神話です。 そして今日、Sparkで文章を書きます。これは、これらすべてのミュージシャンの歌詞を分析し、それらの類似した単語を特定するのに役立ちます。 ピンクフロイドがポップアーティストと同じナンセンスを書いていることを証明しよう。
これらの神話のどれが反論できるか見てみましょう。
神話1. SparkとHadoop
概して、Hadoopは単なる情報のリポジトリです。 これは分散ファイルシステムです。 さらに、この情報を処理できる特定のツールとAPIのセットを提供します。
Sparkのコンテキストでは、Hadoopを必要とするのはSparkではなく、むしろ、Hadoopに保存してそのツールを使用して処理できる(パフォーマンスの問題に直面している)情報をSparkを使用してより高速に処理できるためです。
問題は、Sparkが動作するためにHadoopが必要かどうかです。
Sparkの定義は次のとおりです。
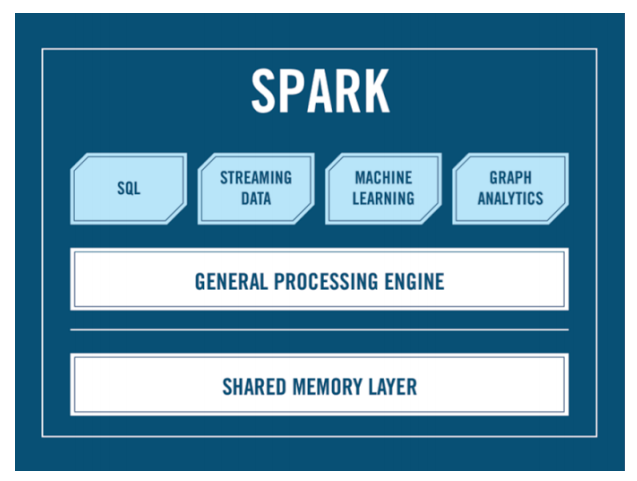
ここにHadoopという言葉はありますか? Sparkモジュールがあります:
- Spark Coreは、データを処理できる特定のAPIです。
- Spark SQL。これは、SQLに精通している人向けにSQLのような構文を作成することを可能にします(これについては、良いか悪いかについて別に説明します)。
- 機械学習モジュール。
- ストリーミング。Sparkを使用して情報を保持したり、何かを聞いたりできます。
しかし、Hadoopという言葉はどこにもありません。
Sparkについて話しましょう。
このアイデアは、2009年頃にバークレー大学で生まれました。 最初のリリースはそれほど前ではなく、2012年にリリースされました。今日はバージョン2.1.0です(2016年の終わりにリリースされました)。 このレポートを採点した時点では、バージョン1.6.1が関連していましたが、APIをクリーンにし、多くの新しい便利なものを追加するSpark 2.0の差し迫ったリリースを約束しました(ここではSpark 2.0のイノベーションは考慮されません)。
Spark自体はScalaで記述されています。これは、ネイティブAPIを取得するため、SparkでSparkを使用する方が良いという神話を説明しています。 ただし、Scala APIのほかに次のものがあります。
- Python
- Java
- Java 8(個別)
- およびR(統計ツール)。
InteliJでSparkを作成できます。これは、レポートプロセスで本日行います。 Eclipseを使用できますが、Sparkにはまだ特別なものがあります-これはSparkシェルで、現在は特定のバージョンのHadoopに付属しており、Sparkコマンドをライブで記述して即座に結果を得ることができます。再利用のため。
SparkをSparkシェルとノートブックで実行できます-組み込みです。 Spark-submitコマンドを使用してクラスターでSparkアプリケーションを起動し、通常のJavaプロセスとして実行できます(java -jaarとmainが呼び出され、コードが記述されている場所を言う)。 本日、レポートの過程でSparkを起動します。 解決したいタスクには、ローカルマシンで十分です。 ただし、クラスターで実行する場合は、クラスターマネージャーが必要です。 これがSparkが必要とする唯一のものです。 したがって、Hadoopなしには方法がないという錯覚がしばしば発生します。 Hadoopには、クラスター全体にSparkタスクを分散させるために使用できるクラスターマネージャーであるYarnがあります。 しかし、代替手段があります-Mesos-Hadoopとは関係のないクラスターマネージャーです。 それは長い間存在しており、約1年前に彼らは7000万ドルを受け取りました。 原則として、Hadoopを嫌う人は誰でも、YarnとHadoopがまったくないクラスターで実際にSparkタスクを実行できます。
データの局所性について2つの言葉だけで説明します。 1台のマシン上ではなく、多数のマシン上にあるビッグデータを処理するという考えは何ですか?
たとえばjdbcやORMで動作するコードを作成すると、実際にはどうなりますか? Javaプロセスを開始するマシンがあり、データベースにアクセスするコードがこのプロセスで実行されると、すべてのデータがデータベースから読み取られ、このJavaプロセスが機能する場所にリダイレクトされます。 ビッグデータについて話すとき、データが多すぎるため、これを行うことは不可能です-それは非効率的であり、ボトルのネックがあります。 さらに、データは既に配布されており、最初は多数のマシンに配置されているため、このプロセスにデータをプルするのではなく、この「日付」を処理するマシンにコードを配布することをお勧めします。 したがって、これは多くのマシンで並行して行われ、無制限の数のリソースを使用します。ここでは、これらのプロセスを調整するクラスターマネージャーが必要です。
この写真では、これらすべてがSparkの世界でどのように機能するかがわかります。
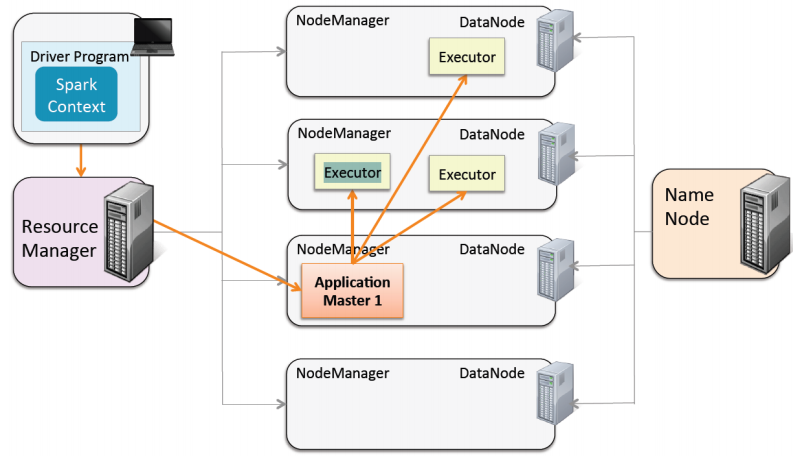
ドライバーがあります-メインは別のマシンで実行されます(クラスターに関連していません)。 Sparkアプリケーションを送信するとき、リソースマネージャーであるYarnに頼ります。 Javaプロセスに使用するワーカーの数(3など)を彼に伝えます。 クラスタマシンから、彼はアプリケーションマスターと呼ばれる1台のマシンを選択します。 そのタスクは、コードを取得し、それを実行するクラスター内の3台のマシンを見つけることです。 3つのマシンがあり、3つの別個のJavaプロセス(3つのエグゼキューター)が発生し、そこでコードが起動されます。 その後、すべてがアプリケーションマスターに戻り、最終的には、ビッグデータ操作の結果をコードの元の場所に戻すために、ドライバーに直接返します。
これは、今日お話しすることとは直接関係ありません。 SparkがCluster Manager(この例ではYarn)でどのように機能するか、そしてリソースが限られている理由(お金を除く-マシンやメモリなどの余裕がある場合)について簡単に説明します。 これは古典的なMapReduceに少し似ています-Hadoopにあった古いAPI(原則的には現在)です。唯一の違いは、このAPIが作成されたとき、マシンの強度が不十分であり、中間データの結果はディスクにしか保存できないことです。 RAMに十分なスペースがなかったためです。 したがって、これはすべてゆっくりと働きました。 例として、古いMapReduceで記述されたコードを最近書き換えたところ、約2.5時間実行されたと言えます。 SparkはすべてをRAMに保存するため、Sparkで1.5分動作します。
コードの記述時には、その一部がクラスターで実行され、他の部分がドライバーで実行されることを理解することが非常に重要です。 これをよく理解していない人は、あらゆる種類のOutOfMemoryなどを持っています。 (これについてお話します-これらのエラーの例を示します)。
だからスパーク...行きましょう
RDD(復元性のある分散データセット)は、すべてのSparkが実行される主要なコンポーネントです。
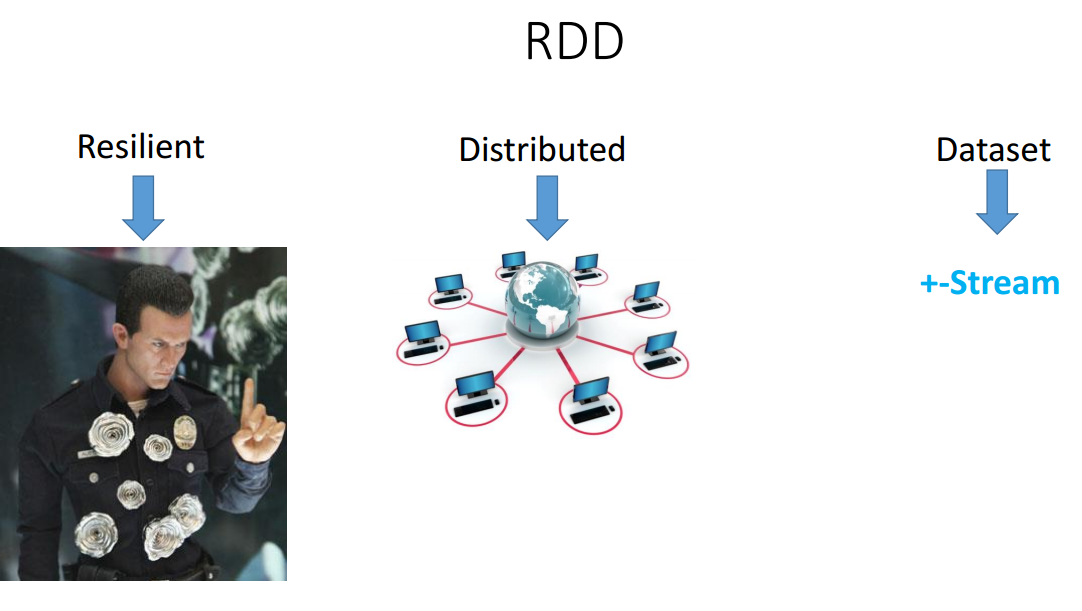
データセットという用語から始めましょう。これは単なる情報の集まりです。 そのAPIはStreamに非常に似ています。 実際、Streamと同様に、これはデータウェアハウスではなく、データの一種の抽象化(この場合は分散)であり、このデータに対してあらゆる種類の機能を実行できます。 Streamとは異なり、RDDは最初は分散型です。RDDは1つのRDDマシンではなく、Sparkの起動時に使用を許可されたマシンの数に配置されます。
レジリエントは、あなたが彼を殺すことはないと言います。なぜなら、データ処理中にマシンがオフになった場合(例えば、光が途切れたなど)回復します。 感じさえしません
RDDはどこから入手できますか?
- 最も一般的なオプションは、特定のタイプのファイルがあるファイルまたはディレクトリからのものです。 ファイルからRDDを作成できます(Streamがデータソースを必要とするように)。
- メモリから-何らかのコレクションまたはリストから。 これは、テストに最もよく使用されます。 たとえば、初期データを含むRDDを受け取り、処理されたデータをRDDに出力するサービスを作成しました。 これをテストするとき、ディスクからデータを読みたくありません。 テストで何らかのコレクションを作成したいと思います。 このコレクションをRDDに変換し、サービスをテストする機会があります。
- ストリームのように別のRDDから。 ほとんどのストリームメソッドはストリームを返します-すべてが非常に似ています。
RDDの作成方法の例を次に示します。
scとは後で説明します(これは、Sparkの開始オブジェクトです)。 ここで、RDDを作成します。
- ローカルディレクトリにあるテキストファイルから(ここではHadoopとは関係ありません)。
- リレーショナルパス上のファイルから。
- Hadoopで-ここで、Hadoopにあるファイルを取得します。 実際には細かく分割されていますが、1つのRDDにまとめられます。 ほとんどの場合、RDDはこのデータが配置されているマシンに配置されます。
- s3ストレージから読み取ることができます。あらゆる種類のワイルドカードを使用するか、データディレクトリからテキストファイルのみを取得できます。
このRDDには何が含まれますか? ここでは、これはRDD(テキストファイルに文字列がある)であると述べています。 さらに、ファイル(これらはこのファイルの行)からRDDを作成したか、ディレクトリ(このディレクトリ内のすべてのファイルの行)からRDDを作成したかは関係ありません。
これにより、メモリからRDDが作成されます。
リストを取得してRDDに変換するparallelizeメソッドがあります。
ここで、scが何であるかという問題に取り組みます。scは、RDDを取得するために常に使用されています。 Scalaで作業する場合、このオブジェクトはSparkContextと呼ばれます。 Java APIの世界では、JavaSparkContextと呼ばれます。 これは、そこからRDDを取得するため、Sparkに関連するコードの記述を開始する主要なポイントです。
JavaでSparkコンテキストオブジェクトを構成する方法の例を次に示します。
SparkConf conf = new SparkConf(); conf.setAppName("my spark application"); conf.setMaster("local[*]"); JavaSparkContext sc = new JavaSparkContext(conf);
最初に、Spark構成オブジェクトが作成され、構成され(アプリケーションの名前を言う)、ローカルで動作するかどうかを示します(アスタリスクは、検索するスレッドの数を示し、使用できるスレッドの数は1、2などを指定できます) d。)。 そして、JavaSparkContextを作成し、ここで構成を渡します。
これは最初の質問を提起します:どうすればすべてを分割できますか? この方法でSparkContextを作成し、ここに構成を渡すと、クラスターでは機能しません。 クラスターに何も書き込まれないように分割する必要があります(Sparkプロセスの開始時に、使用するマシンの数、マスターの所有者、クラスターマネージャーの所有者などを言う必要があります)。 この構成がここにあることは望ましくありません。 アプリケーション名のみを残します。
そして、Springが助けになります。2つのBeanを作成します。 1つはプロダクションプロファイルの下にあり(通常、所有者、マシンの数などに関する情報は送信されません)、もう1つはローカルプロファイルの下にあります(ここではこの情報を送信します。すぐに分割できます)。 テストでは、1つのBeanがSparkContextから機能し、本番-別のBeanが機能します。
@Bean @Profile("LOCAL") public JavaSparkContext sc() { SparkConf conf = new SparkConf(); conf.setAppName("music analyst"); conf.setMaster("local[1]"); return new JavaSparkContext(conf); } @Bean @Profile("PROD") public JavaSparkContext sc() { SparkConf conf = new SparkConf(); conf.setAppName("music analyst"); return new JavaSparkContext(conf); }
RDDの機能のリストは次のとおりです。
map flatMap filter mapPartitions, mapPartitionsWithIndex sample union, intersection, join, cogroup, cartesian (otherDataset) distinct reduceByKey, aggregateByKey, sortByKey pipe coalesce, repartition, repartitionAndSortWithinPartitions
これらはストリーム関数に非常に似ています:すべて不変であり、RDDも返します(ストリームの世界では、中間操作と呼ばれ、ここでは-変換)。 詳細は説明しません。
アクションもあります(Streamsの世界では、ターミナル操作と呼ばれていました)。
reduce collect count, countByKey, countByValue first take, takeSample, takeOrdered saveAsTextFile, saveAsSequenceFile, saveAsObjectFile foreach
アクションとは何か、トランスフォーメーションとは何かを判断する方法は? ストリームと同様に、RDDメソッドがRDDを返す場合、これは変換です。 そうでない場合、これはアクションです。
アクションには2つのタイプがあります。
- ドライバーに何かを返すもの(これはクラスター上にないことを強調することが重要です。答えはドライバーに戻ります)。 たとえば、reduceはすべてのデータを収集する方法に関する関数を取り、最終的に1つの回答が返されます(一般的な場合、1つである必要はありません)。
- ドライバーに応答を返さないもの。 たとえば、同じHadoopまたは他のストレージで処理した後にデータを保存できます(このためのsaveAsTextFileメソッドがあります)。
どのように機能しますか?
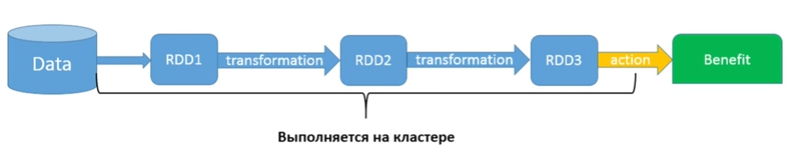
このスキームはストリームに似ていますが、小さな注意点が1つあります。 何らかの種類のデータがあり、たとえばs3ストレージにあります。 SparkContextを使用して、最初のRDD1を作成しました。 その後、あらゆる種類の異なる変換を行い、それぞれがRDDを返します。 最後に、アクションを実行し、何らかの利益(保存、印刷、または受け取ったものを転送)を取得します。 もちろん、この部分はクラスターで実行されます(すべてのRDDメソッドはクラスターで実行されます)。 結果がなんらかの答えである場合、最後に小さな断片がドライバーで起動されます。 Dataの左側(つまり、Sparkコードの使用を開始する前)はすべて、クラスターではなく、ドライバーで実行されます。
このLazyはすべて、ストリームとまったく同じです。 変換である各RDDメソッドは何も行いませんが、アクションを待ちます。 アクションがあると、チェーン全体が開始されます。 そして、ここで古典的な疑問が生じます。この場合、ここで何をしているのでしょうか?
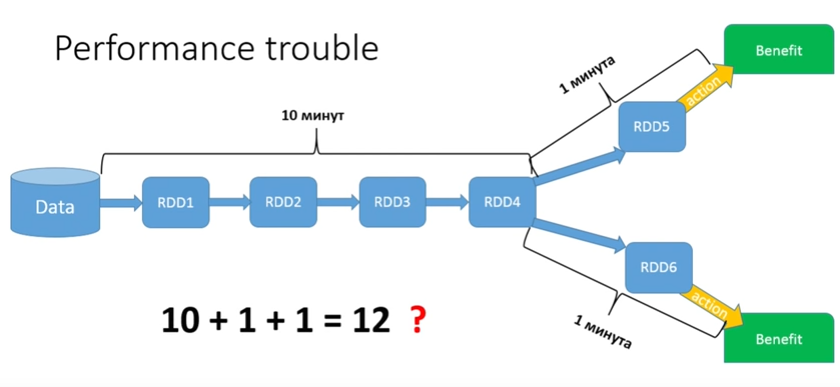
私のデータは、ある銀行での過去5年間のすべての金銭取引であると想像してください。 そして、私はかなり長い治療を実行する必要があり、それは分割されます。私はすべての男性のために1つのアクションを行い、すべての女性のために-別のアクションを行います。 プロセスの最初の部分に10分かかるとしましょう。 プロセスの2番目の部分には1分かかります。 合計12分を取得する必要があるように思えますか?
いいえ、遅延が発生するのは22分です。アクションが起動されるたびに、チェーン全体が最初から最後まで実行されます。 私たちの場合、共通のチャンクは2回しか開始されませんが、15個のブランチがある場合はどうでしょうか?
当然、パフォーマンスに大きな打撃を与えます。 Sparkの世界では、特に関数型プログラミングに精通している人にとっては、コードを書くのは非常に簡単です。 しかし、でたらめは判明しました。 効率的なコードを記述したい場合、多くの機能を知る必要があります。
問題を解決してみましょう。 ストリームで何をしますか? 彼らはいくつかの収集を行い、それをすべてまとめて収集し、それからストリームを取得します。
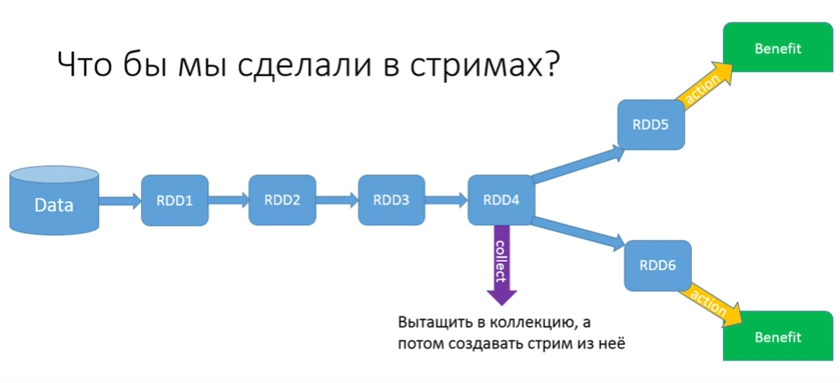
GetTaxiが試してみましたが、次のようになりました。

さらに、クラスター上でさらに多くのマシンを購入する予定であったため、40台あり、それぞれに20ギガバイトのRAMがありました。
理解する必要があります。ビッグデータについて話している場合、収集した時点で、すべてのRDDからのすべての情報がDriverで返されます。 そのため、ギガバイトとマシンは決して助けにはなりません。収集すると、すべての情報がアプリケーションが開始された場所から1つの場所にマージされます。 当然、メモリ不足になります。
この問題をどのように解決しますか(チェーンを2回実行したり、さらに15回実行したり、収集を実行したくない)。 これを行うために、Sparkにはpersistメソッドがあります。
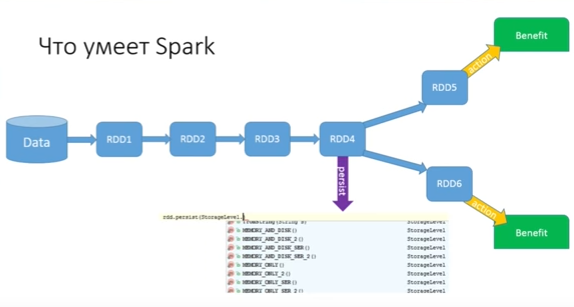
Persistでは、状態RDDを保存でき、保存先を選択できます。 多くの保護オプションがあります。 最も最適なものはメモリ内にあります(メモリのみがありますが、メモリは2つしかありません-バックアップが2つあります)。 カスタムストレージを作成して、保存方法を指定することもできます。 メモリとディスクを保存できます-メモリに保存しようとしますが、このワーカー(このRDDを実行するマシン)に十分なRAMがない場合、一部はメモリに書き込まれ、残りはディスクにフラッシュされます。 データをオブジェクトとして保存するか、シリアル化を実行できます。 各オプションには長所と短所がありますが、そのような機会があり、これは素晴らしいことです。
この問題を解決しました。 永続化はアクションではありません。 アクションがない場合、persistは何もしません。 最初のアクションが開始されると、チェーン全体が実行され、RDDチェーンの最初の部分の終わりで、データが配置されているすべてのマシンで保持されます。 アクションRDD6を実行するときは、既に永続化から開始します(他のブランチがある場合は、「記憶」または「マーク」された永続化から続行します)。
神話2. SparkはScalaでのみ書かれています。
Sparkは優れており、一部のローカルニーズにも使用できますが、必ずしもビッグデータには使用できません。 APIをデータ処理に使用するだけで済みます(本当に便利です)。 質問が発生します:何に書くべきですか? PythonとR私はすぐに却下しました。 調べてみましょう:ScalaとJavaのどちらですか?
通常のJava開発者はScalaについてどう思いますか?

上級のJava開発者はもう少し見ています。 彼は、ある種の遊び、いくつかのクールなフレームワーク、ラムダ、および多くの中国語があることを知っています。
お尻を覚えていますか? 彼女がいる。 これがScalaコードの外観です。
val lines = sc.textFile("data.txt") val lineLengths = lines.map(_.length) val totalLength = lineLengths.reduce(_+_)
私の究極の目標は、Javaで書くことは悪くないことを納得させることなので、Scala APIには入りませんが、このコードは各行の長さを数え、全体を要約します。
Javaに対する非常に強力な議論は、同じJavaコードが次のように見えることです。
JavaRDD<String> lines = sc.textFile("data.txt"); JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() { @Override public Integer call(String lines) throws Exception { return lines.length(); } }); Integer totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer a, Integer b) throws Exception { return a + b; } });
最初のプロジェクトを始めたとき、当局は私に確信があるかどうか尋ねました。 結局、私たちが書くとき、より多くのコードがあるでしょう。 しかし、これはすべて嘘です。 今日のコードは次のようになります。
val lines = sc.textFile("data.txt") val lineLengths = lines.map(_.length) val totalLength = lineLengths.reduce(_+_)
JavaRDD<String> lines = sc.textFile("data.txt"); JavaRDD<Integer> lineLengths = lines.map(String::length); int totalLength = lineLengths.reduce((a, b) -> a + b);
ScalaとJava 8には大きな違いがありますか? これは、Javaプログラマーにとって読みやすいと思われます。 しかし、Java 8にもかかわらず、SparkはScalaで作成する必要があるという神話になります。 Java 8ではすべてがそれほど悪くないことを知っている人よりも、Scalaで書く必要があると主張しますか?
Scalaの場合:
- Scalaはクールで、流行に敏感で、ファッショナブルで、まさに先へ進む必要があります。 このGroovyをNahig、Scalaではすべてが間違いなく面白いです。
- Scalaは簡潔で便利な構文です。 司祭がいます。
- Spark APIはScalaで作成されているため、主にScala用に設計されています。 これは深刻なプラスです。
- Java APIは、後で提出しなければなりません。偽造する必要があるためです。 常にすべてがそこにあるわけではありません。
Javaの場合:
- ほとんどのJavaプログラマーはJavaを知っています。 これらの人々はScalaを知らない。 大企業では、多かれ少なかれJavaを扱うJavaプログラマーの集まり。 Sparkを書くためにScalaを提供しますか? いいえ。
- おなじみの世界-Spring、おなじみのデザインパターン、Mavenまたはそれ以上-Gradle、シングルトンなど 私たちはそこで働くことに慣れています。 また、Scalaは異なる構文であるだけでなく、他の多くの概念でもあります。 Scalaは制御の反転を必要としません。なぜなら、 そこではすべてが異なります。
なぜJavaはまだ優れているのですか? もちろん、私たちはScalaを愛していますが、お金はJavaにあります。

何が起こったかを議論するポッドキャスト
-Issue 104-を聞いてください。
簡単に説明します。
1年前、2010年にTypesafeを開いたMartin Oderskyが閉じました。 ScalaをサポートするTypesafeはなくなりました。
これは、Typesafeの代わりにLightbendという別の会社が設立されたためScalaが死んだという意味ではありませんが、まったく異なるビジネスモデルを持っています。 Play、Akka、SparkのようなScalaで書かれた素晴らしいもののおかげでさえ、そして上記の教皇のおかげでさえ、大衆をScalaに切り替えることは不可能であるという結論に達しました。 1年前、Scalaは人気のピークでしたが、それにもかかわらず、ランキングの最初の40の場所にさえありませんでした。 比較のために、GroovyはJavaの20番目、最初はGroovyでした。
人気のピーク時でさえ、人々が大衆の間でScalaを使用することを強制していないことに気付いたとき、彼らは自分のビジネスモデルを誤っていると認識しました。 今日Scalaを導入する企業は、異なるビジネスモデルを採用しています。 彼らは、Sparkのような大衆向けに作られるすべての製品には優れたJava APIがあると言っています。 そして、データフレームに到達すると、Scalaで書くかJavaで書くかに違いはないことがわかります。
神話3. SparkとSpringは互換性がありません
最初に、Beanとして登録されているSparkContextがあることを既に示しました。 次に、PostanプロセッサBeanを使用して、Sparkの機能をサポートする方法を確認します。
すでにコードを書きましょう。
RDD文字列と上位ワードの数を受け入れるサービス(ヘルパー)を作成します。 彼の仕事はトップワードを返すことです。 コードで何をするのか見てみましょう。
@service public class PopularWordsServiceImpl implements PopularWordsService { @Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap) .sortByKey().map(Tuple2::_2).take(x); } }
まず、歌詞が小文字であるか大文字であるかがわからないため、大文字と小文字で単語を二重にカウントしないようにすべてを小文字に変換する必要があります。 したがって、マップ関数を使用します。 その後、関数flatmapを使用して行を単語に変換する必要があります。
これで、単語が存在するRDDができました。 数量に対してマッピングします。 しかし、最初に、各単語に単一性を割り当てる必要があります。 これは古典的なパターンになります:単語-1、単語-1があり、同じ単語に対するすべてのものを合計してソートする必要があります(すべてがメモリ内で機能し、十分なメモリがある場合は中間結果はディスクに保存されません)。
mapToPair関数があります-ペアを作成します。 問題は、JavaにはPairクラスがないことです。 実際には、これは大きな省略です。特定のコンテキストで結合したい何らかの情報があることが非常に多いのですが、このためのクラスを書くのは愚かです。
Scalaには既製のクラスがあります(たくさんあります)-Tuple。 Tuple2、3、4などがあります。 22へ。なぜ22へ。 誰も知らない。 2をマップするため、Tuple2が必要です。
これをすべて減らす必要があります。 すべての同じ単語をキーとして残すreduceByKeyメソッドがあり、すべての値で私が求めることを行います。 折りたたむ必要があります。 ペアを取得しました。量は量です。
次に、ソートする必要があります。 ここでも、Javaに小さな問題があります。なぜなら、 唯一のソートはsorkByKeyです。 Scala APIにはsortbyがあり、そこでこのTupleを取得して、そこから必要なものを引き出します。 そして、これはSortByKeyのみです。
私が言ったように、これまでのところいくつかの場所では、Java APIが十分に豊富ではないと感じています。 しかし、あなたは抜け出すことができます。 たとえば、ペアを反転できます。 これを行うために、再びmapToPairを作成します。Tupleには組み込みのスワップ関数があります(数個の単語が判明しました)。 これで、sortByKeyを実行できます。
この後、最初の部分ではなく、2番目の部分を引き出す必要があります。 したがって、地図を作成します。 2番目の部分を引き出すために、Tupleには既製の関数「_2」があります。 ここでTake(x)を実行します(x語のみが必要です-メソッドはTopXと呼ばれます)。これらすべてはreturnで実行できます。
テストの実行方法を示します。 しかしその前に、Springでの私のJava構成の内容を見てください(Springで作業しています。これは単なるクラスではなく、サービスです)。
@Configuration @ComponentScan(basePackages = "ru.jug.jpoint.core") @PropertySource("classpath:user.properties") public class AppConfig { @Bean public JavaSparkContext sc() { SparkConf conf = new SparkConf().setAppName("music analytst").setMaster("local[*]"); return new JavaSparkContext(conf); } @Bean public static PropertySourcesPlaceholderConfigurer configurer(){ return new PropertySourcesPlaceholderConfigurer(); } }
Java configで、ある種のuser.propertiesを読みました(理由は後で説明しますが、今は使用しません)。 また、すべてのクラスをスキャンし、2つのBeanを規定します。PropertySourcePlceholderConfigurer-プロパティファイルから何かを注入できるように、これはまだ関係ありません。 そして今私たちが興味を持っている唯一のBeanは、通常のJavaSparkContextです。
SparkConfを作成してセットアップし(音楽アナリストと呼ばれるプログラム)、マスターがいることを伝えました(ローカルで作業しています)。 JavaSparkContextを作成しました-すべてが素晴らしいです。
テストを見てください。
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(classes = AppConfig.class) public class PopularWordsServiceImplTest { @Autowired JavaSparkContext sc; @Autowired PopularWordsService popularWordsService; @Test public void textTopX() throws Exception { JavaRDD<String> rdd = sc.parallelize(Arrays.asList(“java java java scala grovy grovy”); List<String> top1 = popularWordsService.topX(rdd, 1); Assert.assertEquals(“java”,top1.get(0)); } }
Springで作業しているため、ランナーは自然に跳ね上がります。 構成はAppConfigです(テスト用と運用用に異なる構成を作成するのが正しいでしょう)。 次に、ここにJavaSparkContextと確認したいサービスを注入します。 SparkContextを使用して、parallelizeメソッドを使用し、「java java java scala grovy grovy」という文字列を渡します。 次に、メソッドを実行し、Javaが最も一般的な単語であることを確認します。
テストは落ちました。 最も人気があるのはスカラだからです。
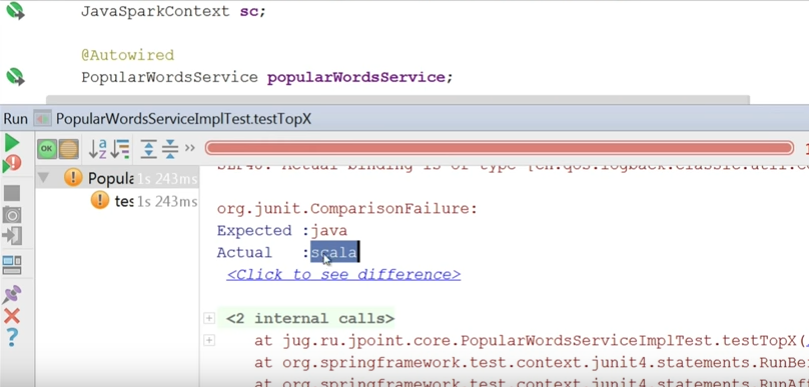
何をするのを忘れましたか? 並べ替えを行ったとき、他の方法で並べ替える必要がありました。
サービスで修正します。
@service public class PopularWordsServiceImpl implements PopularWordsService { @Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x); } }
テストに合格しました。
ここでmainを実行して、実際の曲で結果を確認してください。 データディレクトリがあります。ビートルズフォルダーがあり、そこには昨日の1曲のテキストがあります。 昨日の最も人気のある言葉は何だと思いますか?
ここに、ArtistsJudgeサービスがあります。 TopXメソッドを実装しました。これはアーティストの名前を取得し、このアーティストの曲が置かれているディレクトリを追加してから、すでに作成されたサービスのtopXメソッドを使用します。
@Service public class ArtistJudgeImpl implements ArtistJudge { @Autowired private PopularDFWordsService popularDFWordsService; @Autowired private WordDataFrameCreator wordDataFrameCreator; @Value("${path2Dir}") private String path; @Override public List<String> topX(String artist, int x) { DataFrame dataFrame = wordDataFrameCreator.create(path + "data/songs/" + artist + "/*"); System.out.println(artist); return popularDFWordsService.topX(dataFrame, x); } @Override public int compare(String artist1, String artist2, int x) { List<String> artist1Words = topX(artist1, x); List<String> artist2Words = topX(artist2, x); int size = artist1Words.size(); artist1Words.removeAll(artist2Words); return size - artist1Words.size(); } public static void main(String[] args) { List<String> list = Arrays.asList("", null, ""); Comparator<String> cmp = Comparator.nullsLast(Comparator.naturalOrder()); System.out.println(Collections.max(list, cmp)); } }
メインはこのように見えます:
package ru.jug.jpoint; import org.springframework.context.annotation.AnnotationConfigApplicationContext; import ru.jug.jpoint.core.ArtistJudge; import java.util.List; import java.util.Set; public class Main { public static void main(String[] args) { AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); ArtistJudge judge = context.getBean(ArtistJudge.class); List<String> topX = judge.topX("beatles", 3); System.out.println(topX); } }
したがって、最も人気のある単語は昨日ではなく、「i」です。
[i, yesterday, to]
同意します、これはあまり良くありません。 セマンティックの負荷を伴わない不要な単語があります(最終的には、Pink Floydの歌の深さを分析したいと思います。これらの単語は私たちを大きく妨害します)。
したがって、不要な単語を定義するuserPropertiesファイルがありました。
garbage = the,you,and,a,get,got,m,chorus,to,i,in,of,on,me,is,all,your,my,that,it,for
このガベージをすぐにサービスに注入することもできますが、私はそれを好まないのです。 さまざまなサービスに送信されるUserConfigがあります。 誰もが彼から必要なものを引き出します。
@Component public class UserConfig implements Serializable{ public List<String> garbage; @Value("${garbage}") private void setGarbage(String[] garbage) { this.garbage = Arrays.asList(garbage); } }
セッターにはprivateを使用し、プロパティ自体にはpublicを使用していることに注意してください。 しかし、これにこだわるのはやめましょう。
PopularWordsServiceImplに移動し、このUserConfigに自動接続して、すべての単語をフィルタリングします。
@service public class PopularWordsServiceImpl implements PopularWordsService { @Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x); } }
main.
, ( ):
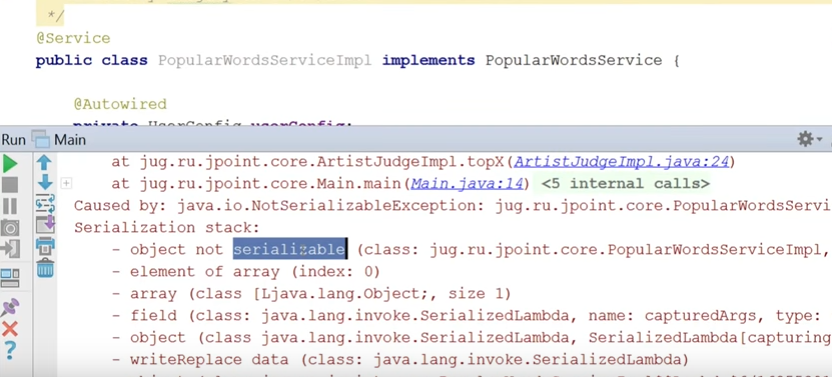
, not serializable. . , UserConfig — serializable.
Component public class UserConfig implements Serializable{ public List<String> garbage; @Value("${garbage}") private void setGarbage(String[] garbage) { this.garbage = Arrays.asList(garbage); } }
serializable PopularWordsServiceImpl:
@Service public class PopularWordsServiceImpl implements PopularWordsService {
serializable:
public interface PopularWordsService extends Serializable { List<String> topX(JavaRDD<String> lines, int x); }
map- ( , ) state- - , . つまり UserConfig , serializable. , UserConfig , . , serializable.
. yesterday. — oh, — believe. oh -, .
, , UserConfig worker? ? ? , Spark , , - .
, broadcast-.
4. , broadcast
, worker- data ( UserConfig ). , , broadcast, . ( ), broadcast .
2 , :
- . Spark ;
- , , , — . broadcast.
:
Israel, +9725423632 Israel, +9725454232 Israel, +9721454232 Israel, +9721454232 Spain, +34441323432 Spain, +34441323432 Israel, +9725423232 Israel, +9725423232 Spain, +34441323432 Russia, +78123343434 Russia, +78123343434
.
( ), . , . — - property- worker-. , , :
Israel, Orange Israel, Orange Israel, Pelephone Israel, Pelephone Israel, Hot Mobile Israel, Orange Russia, Megaphone Russia, MTC
- Excel-, , 054 — Orange, 911 — . (10 ; 2 — big data) .
:
Orange Orange Pelephone Pelephone Hot Mobile Orange Megaphone MTC
?
public interface CommonConfig { Operator getOperator(String phone); List<String> countries(); }
CommonConfig, , .
, :
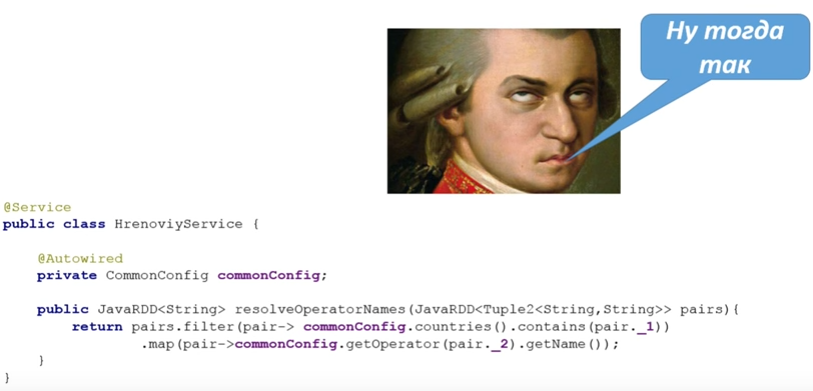
@Service public class HrenoviyService { @Autowired private CommonConfig config; public JavaRDD<String> resolveOperatorNames(JavaRDD<Tuple2<String,String>> pairs){ return pairs.filter(pair-> config.countries().contains(pair._1)) .map(pair-> config.getOperator(pair._2).getName()); } }
- Spring, , , data.
! , ( broadcast).
? Driver Worker-, , , , 1 . . , . , , 1000 . Spark-, 10 Worker-.
Worker- - . 10, 1000, 100 . , , , .. - ( 1 , 2, .. 2 ). , worker- , broadcast.
:
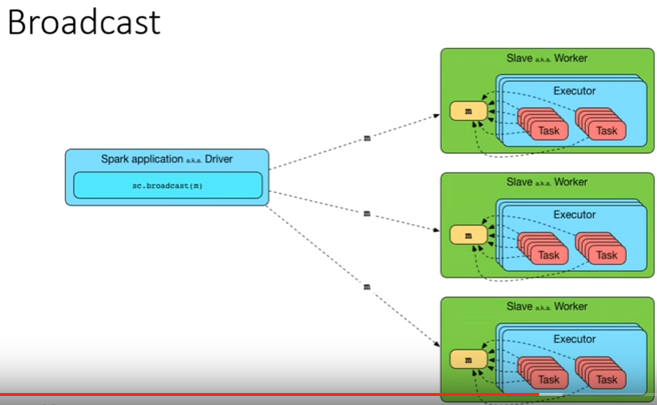
context, , broadcast, , broadcast-. , worker- .
問題は何ですか? :
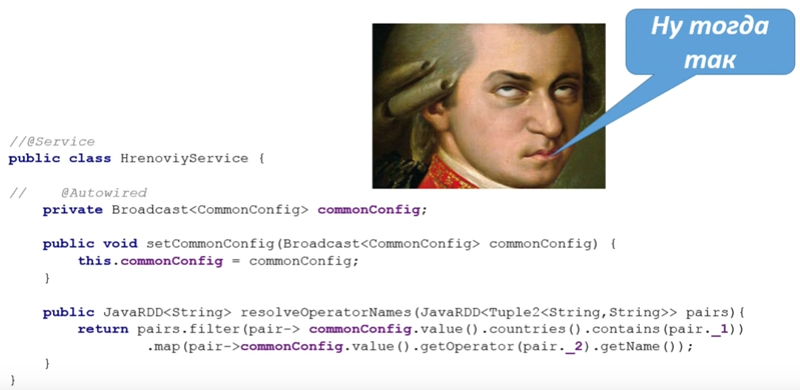
@Service public class HrenoviyService { @Autowired private JavaSparkContext sc; @Autowired private CommonConfig commonConfig; private Broadcast<CommonConfig> configBroadcast; @PostConstruct public void wrapWithBroadCast(){ configBroadcast = sc.broadcast(commonConfig); } public JavaRDD<String> resolveOperatorNames(JavaRDD<Tuple2<String,String>> pairs){ return pairs.filter(pair-> configBroadcast.value().countries().contains(pair._1)) .map(pair-> configBroadcast.value().getOperator(pair._2).getName()); } }
context (, , Spring). broadcast- , PostConstruct, wrapWithBroadcast. SparkContext , . PostConstruct.
( broadcast , ):
return pairs.filter(pair-> configBroadcast.value().countries().contains(pair._1)) .map(pair-> configBroadcast.value().getOperator(pair._2).getName());
:

SparkContext, . . copy-paste, , broadcast, .

copy-past .
, Spark - ( broadcast — ). , SparkContext, .
:

SparkContext , serializable.
, , , . :
broadcast? , bean:
broadcast-, bean , broadcast.

, , broadcast? , ,
Service , , broadcast.
.
@Service public class PopularWordsServiceImpl implements PopularWordsService { @AutowiredBroadcast private Broadcast<UserConfig> userConfig;
broadcast UserConfig AutowiredBroadcast. , ?
:
@Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .filter(w -> !userConfig.value().garbage.contains(w)) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x); } }
UserConfig.value, .
, bean-, .
.
lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .filter(word-> !Arrays.asList(garbage).contains(word)) .mapToPair(word-> new Tuple2<>(word, 1)) .reduceByKey((x, y)->x+y) .mapToPair(Tuple2::swap) .sortByKey(false) .map(Tuple2::_2) .take(amount);
lines.map(_.toLowerCase()) .flatMap("\\w+".r.findAllIn(_)) .filter(!garbage.contains(_)) .map((_,1)).reduceByKey(_+_) .sortBy(_._2,ascending = false) .take(amount)
, Java ( ..). — Scala. , Java 8, 2 . , :
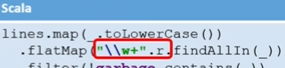
Java GetWords, . Scala . Scala SortBy, Tuple, Scala ( ascending false, false).
? .
DataFrames — API, Spark 1.3. , ( Tuple). RDD, .. RDD , — . ( ), task- .
:
DSL SQLContext ( ).
, :
Agg, columns, count, distinct, drop, dropDuplicates, filter groupBy, orderBy, registerTable, schema, show, select, where, withColumn
SQL :
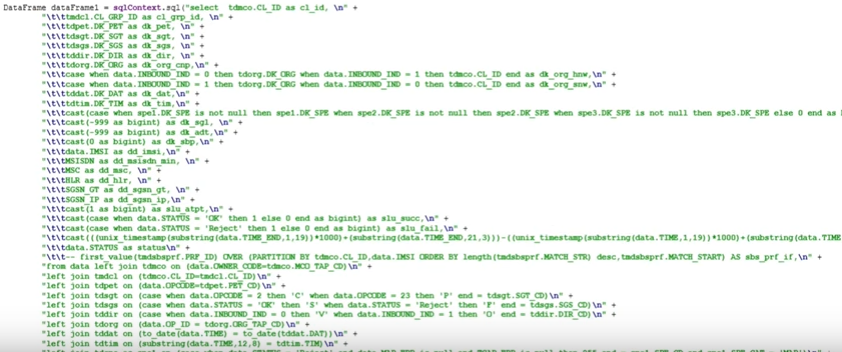
dataFrame.registerTempTable("finalMap"); DataFrame frame = sqlContext.sql("select cl_id, cl_grp_id, dk_org_snw, dk_org_hnw, dk_org_cnp, dk_dir, dk_dat, DK_TIM_HR as dk_tim_hr, dk_spe, dk_sgt, dk_pet, dk_sgs, dk_sbp,\n" + "SUM(slu_atpt) slu_atpt, SUM(slu_succ) slu_succ, SUM(slu_fail) slu_fail, SUM(slu_dly) slu_dly\n" + "FROM finalMap f join tdtim t on f.dk_tim = t.DK_TIM\n" + "WHERE dk_pet IN (1, 4)\n" + "group by cl_id, cl_grp_id, dk_org_snw, dk_org_hnw, dk_org_cnp, dk_dir, dk_dat, DK_TIM_HR, dk_spe, dk_sgt, dk_pet, dk_sgs, dk_sbp").toDF();
, SQL sqlContext.
, :
:
abs, cos, asin, isnull, not, rand, sqrt, when, expr, bin, atan, ceil, floor, factorial, greatest, least, log, log10, pow, round, sin, toDegrees, toRadians, md5, ascii, base64, concat, length, lower, ltrim, unbase64, repeat, reverse, split, substring, trim, upper, datediff, year, month, hour, last_day, next_day, dayofmonth, explode, udf
, . :

keywords (, ).
main.
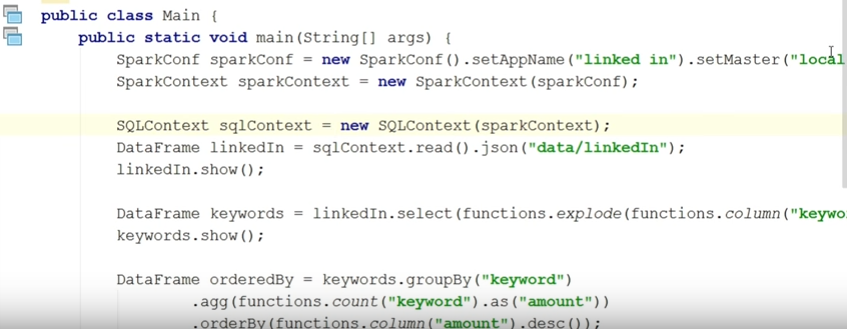
-, , . sqlContext.read.json ( , json, — ; json ). show. :

: , keywords, . . , 30 ( ), .
. linkedIn. select, keywords. , , explode ( keyword ).
linkedIn.select(functions.explode(functions.column(“keywords”)).as(“keyword”));
. , :

sort .. .
. keyword:
DataFrame orderedBy = keywords.groupBy(“keyword”) .agg(functions.count(“keyword”).as(“amount”)) .orderBy(functions.column(“amount”).desc()); orderedBy.show();
, . keyword- amount. amount descended ( false). :

. :
String mostPopularWord = orderedBy.first().getString(0); System.out.println(“mostPopularWord = “ + mostPopularWord);
first — , string ( resultset-). , :
linkedIn.where{ functions.column(“age”).leq(30).and(functions.array_contains(functions.column(“keywords”).mostPopularWord))) .select(“name”).show(); }
30 . , functions.array_contains. show. :

. : XML-, JSON-, . ( )? , Java Scala? , .
WordDataFrameCreator.
, :
@Component public class WordDataFrameCreator { @Autowired private SQLContext sqlContext; @Autowired private JavaSparkContext sc; public DataFrame create(String pathToDir) { JavaRDD<Row> rdd = sc.textFile(pathToDir).flatMap(WordsUtil::getWords).map(RowFactory::create); return sqlContext.createDataFrame(rdd, DataTypes.createStructType(new StructField[]{ DataTypes.createStructField("words", DataTypes.StringType, true) })); } }
. RDD map- . , RowFactory — RDD. RDD, RDD , , , , .. , — . SqlContext.
, SqlContext JavaSparkContext ( AppConfig, SqlContext ). , :
public SQLContext sqlContext(){ return new SQLContext(sc()); }
SqlContext , RDD, , , — ( , words, string — true).
API : , - .
:
@Service public class PopularDFWordsServiceImpl implements PopularDFWordsService { @AutowiredBroadcast private Broadcast<UserConfig> userConfig; @Override public List<String> topX(DataFrame lines, int x) { DataFrame sorted = lines.withColumn("words", lower(column("words"))) .filter(not(column("words").isin(userConfig.value().garbage.toArray()))) .groupBy(column("words")).agg(count("words").as("count")) .sort(column("count").desc()); sorted.show(); Row[] rows = sorted.take(x); List<String> topX = new HashSet<>(); for (Row row : rows) { topX.add(row.getString(0)); } return topX; } }
, , RDD, . API .
lower case . withColumn — , . , , . , count , — descended-. - .
. , ? . , custom-, , .

ustom- ( udf) — , . . notGarbage. , udf1, string (), — boolean ( ).
, :
@Service public class PopularWordsResolverWithUDF { @Autowired private GarbageFilter garbageFilter; @Autowired private SQLContext sqlContext; @PostConstruct public void registerUdf(){ sqlContext.udf().register(garbageFilter.udfName(),garbageFilter, DataTypes.BooleanType); } public List<String> mostUsedWords(DataFrame dataFrame, int amount) { DataFrame sorted = dataFrame.withColumn("words", lower(column("words"))) .filter(callUDF(garbageFilter.udfName(),column("words")))…
, , PostConstruct .
callUDF — . — , - . udf-.
UDF , , , @RegisterUDF BPP .
, ( Tomcat, ):
10 :
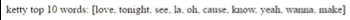
( ):
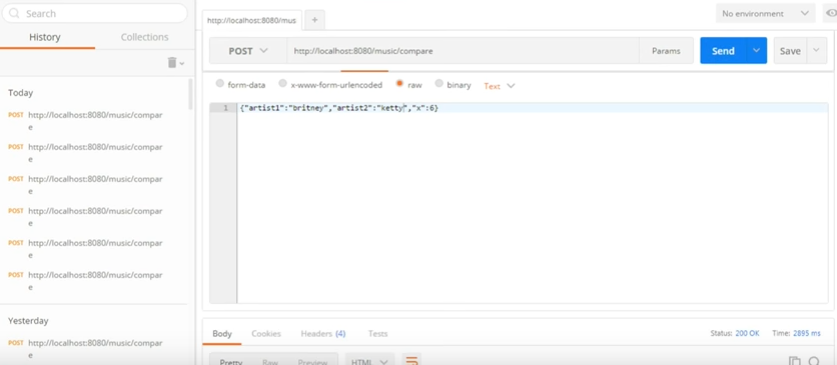
, . 6 4 .
:
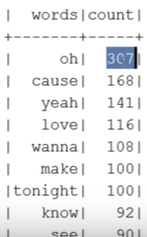
:

Pink Floyd 0 . , :

結論
- Hadoop Spark, Spark Hadoop. Yarn, , — ;
- Scala, . ;
- : , Spring, , , ..;
- . - , bean, , ;
- ( , ).
:

:
— 5 Spark-. , , , . Spark , - . , : , , , — « Spark!» .
— 7-8 JPoint 2017 . : «Spring – » « Spring Test» . , !
, JPoint Java — , .