多数のサービスインスタンスを最大限に活用した分散システムに移行する場合、それらの検出( サービス検出 )およびそれらの間の要求の分散( 負荷分散 )で問題が発生します。 原則として、 Consul 、 Eureka、または古き良きZookeeperなどの特殊なツールを使用して、 Nginx 、 HAProxy 、およびそれらの間のブリッジと組み合わせてそれらを解決します( 登録者を参照)。
このアプローチの主な問題は、多数の統合であり、その結果、何かがうまくいかない可能性があるポイントです。 実際、上記のソリューションに加えて、ローカルの小規模なPaaS (たとえば、 Mesosphere MarathonやKubernetes )がおそらく使用されます。 ちなみに後者は、環境に関する必要な構成を既に保存しています(結局、展開全体がそれらを通過します)。 問題は、 サービスディスカバリ用の専用ツールを放棄して、このタスクに同じマラソンを再利用できるかどうかです。
簡単な答えは、できることです。 興味があれば、読んでください。
処分
だから、私たちが利用できるもの:
- Apache Mesosと、サービスオーケストレーションシステムとしての忠実なMarathonフレームワーク
- Spring BootフレームワークとそのSpring Cloud拡張機能を使用して記述されたサービス
シュガーフリーMesos (フレームワークなしで読む)は、フレームワークで拡張できるクラスターリソース管理システムです。 フレームワークにはさまざまな目的があります。 幅広い短期タスク( Chronos )を実行できるものもあれば、長命( Marathon )のものもあります。 また、 HadoopやJenkinsなどの特定の製品向けに調整されたものもあります。
Mesosphere Marathonは、クライアントを処理するサービスや非常に長い要求を含む長期タスクの開始、停止、全体的なスケジューリングを管理できるフレームワークです。
Spring Cloudもフレームワークですが、これらのサービスの開発用であり、分散システムでの作業の基本パターンと、これらのパターンと市場の既存のソリューション(たとえば、同じConsul )との特定の統合の両方を実装します。
Spring Cloudの一部として、実際にはサービス発見の問題を解決するための2つの実装があります。
1つ目は、 Netflix Zuulを使用して、 サーバー側のサービス検出パターンに起因する可能性があります。 テンプレートの本質は、現在の場所とサービスインスタンスに関するさまざまなメタ情報を知っている多くのルーターを作成し、リクエストをプロキシするための一定のhttpリソースを提供することです。 Springを無視する場合、従来のルーターはnginxです(動的に構成されている場合)。
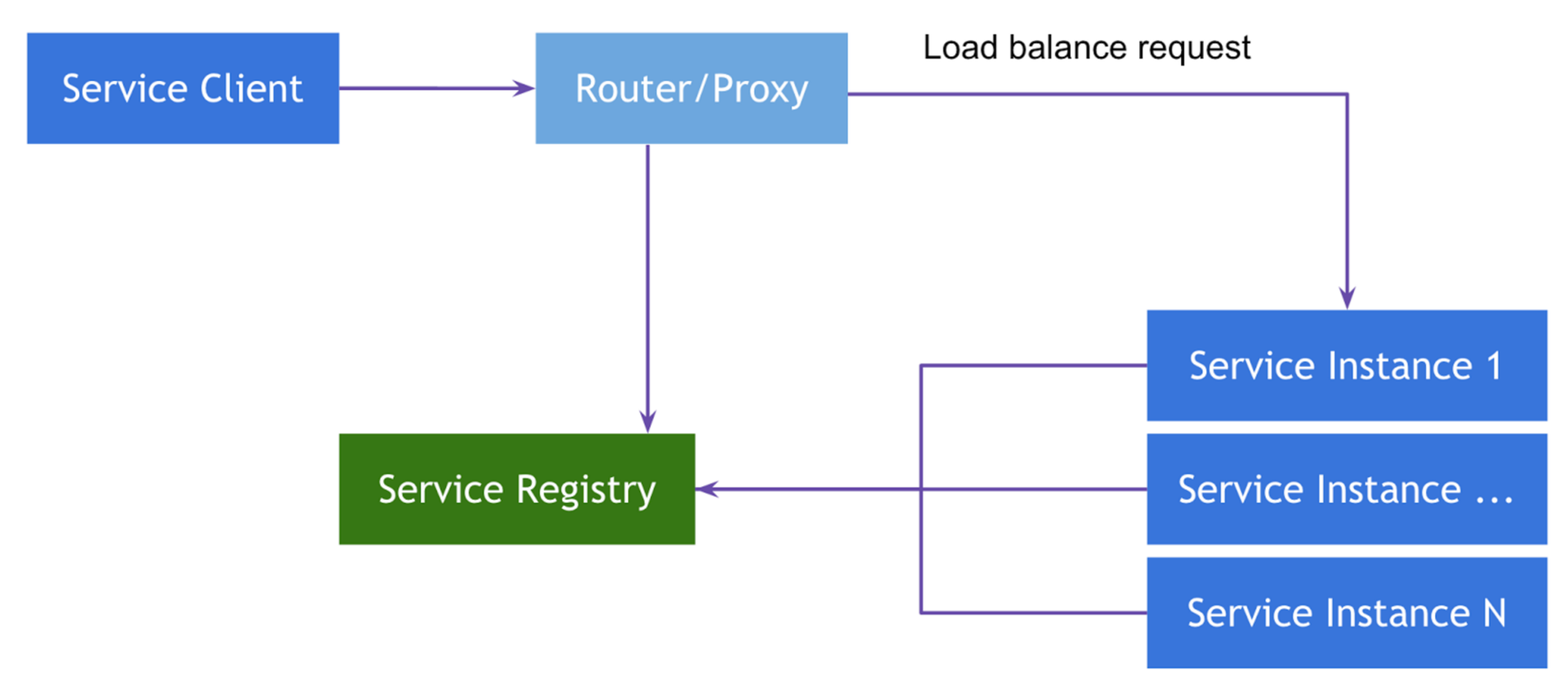
2番目の実装は、 Client-Side Service Discoveryクラスに属します。 前のものとの主な違いは、ルーターがないため、中間リンクと追加の障害点がクラスとして存在することです。 代わりに、「スマートな」クライアントバランサーがルーターとして使用されます。ルーターは、呼び出すサービスインスタンスについて知る必要があるすべてのことも知っています。 Spring Cloudでは、 Netflixリボンがそのようなバランサーとして使用されます。
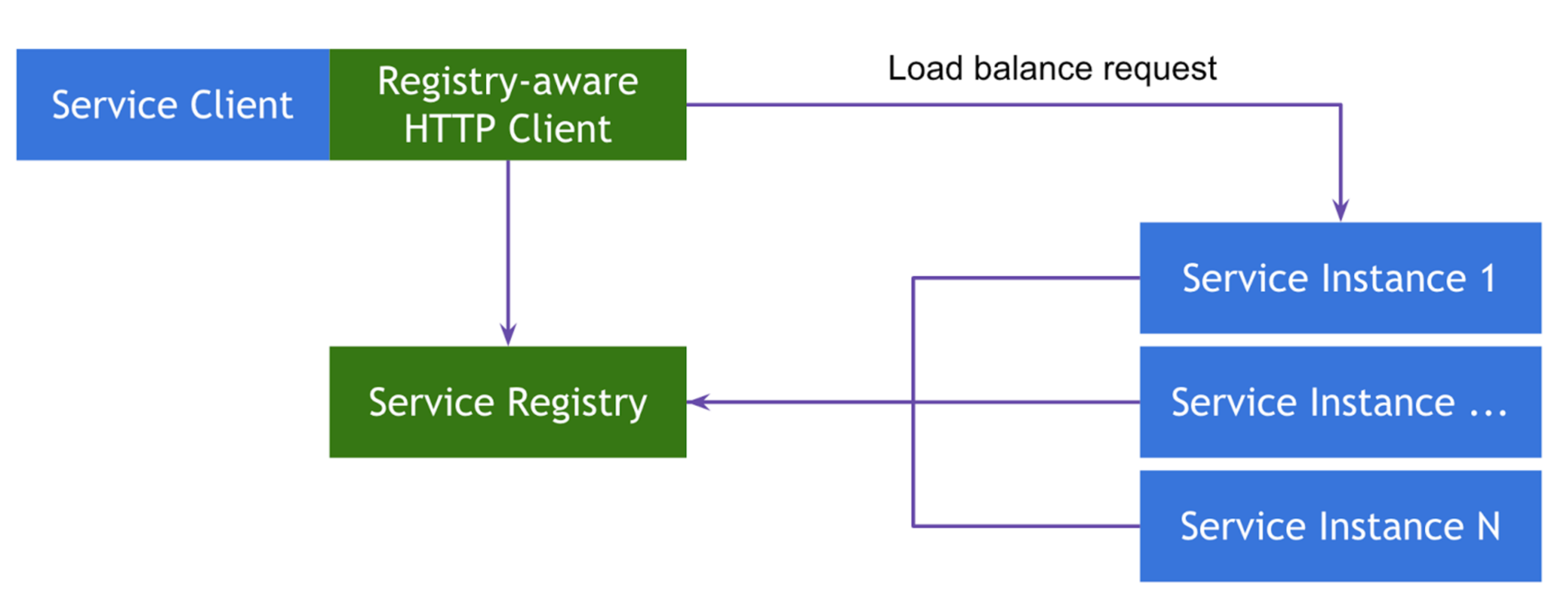
このシリーズの記事では、テンプレートのクライアント実装について詳しく説明しますが、サーバーについても説明します。
@EnableDiscoveryClient
Springでは、クラス/メソッド/変数に1ダースまたは20ダースのアノテーションを追加し、 yamlファイルに少しの設定を書き込むことで、ほとんどすべてを機能させることができます。 大丈夫、すべてではなく、たくさんあるとします。
トレーニングマニュアルでは、アプリケーションに@EnableDiscoveryClientマジックアノテーションを追加することにより、(いくつかの依存関係と設定の後、さらに詳しくは後で)サービスを検出することを教えています。 アプリケーション内で少なくともローカルに。 これは非常に簡単に行うことができ、緊張する必要さえありません:
@SpringBootApplication @EnableDiscoveryClient public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
その後、魔法のないところから魔法が始まります。 この注釈を見るSpringは、 META-INF / spring.factoriesでEnableDiscoveryClientのダウンロード可能として指定されているすべての構成をロードします。
org.springframework.cloud.client.discovery.EnableDiscoveryClient=\ org.springframework.cloud.xxx.discovery.XXXDiscoveryClientConfiguration
どこでどの構成をロードできますか? この質問に答えるには、 Spring Cloud自体が、さまざまなテンプレートを実装するために必要なインターフェイスと一般的なロジックを備えた基本部分、およびstartersの形で提供されるコネクタで構成され、特定のソリューションの特定の実装があると言わなければなりません。 概略的には、次のように描くことができます。 
たとえば、 Netflix Eurekaのスターターを接続する場合、 クラスパスに 1つのファクトリー構成があります。 スターターがConsulの場合は、もう1つです。
ただし、ここでの待ち伏せは、「 ハロワールド 」開発ではなく産業用の注釈自体は、まったく役に立たないということです。利益はすべて、 bootstap.ymlに正しい設定を書き込む領域にあるためです 。 そして、各コネクタについては、おそらくあなた自身が推測したものです。
なぜそれがとても簡単に理解できるのか。 ユーレカ 、 領事 、 マラソンはまったく違います。 さまざまな方法でそれらに接続する必要があります。 特定のソリューションに固有のさまざまなAPIと機能があります。 ユニバーサル構成を作成することは不可能であり、一般的には必要ありません。
ただし、 @EnableDiscoveryClientを使用して描画する構成に戻ります。 そして、最初に思い浮かぶのは、お気に入りのIDEでの検索ですぐに見つかる、 DiscoverClientインターフェイスの実装です。 最も重要な(少なくとも一見)インターフェイスは次のようになります。
public interface DiscoveryClient { public String description(); public ServiceInstance getLocalServiceInstance(); public List<ServiceInstance> getInstances(String serviceId); public List<String> getServices(); }
原則として、すべてがかなり明白です。 HealthIndicatorの説明を取得できます。 私たちは自分自身を得ることができます。 何らかのサービス識別子ですべてのインスタンスを取得できます。 そして最後に、すべての既知のサービス(より正確には、それらの識別子)のリストを取得できます。
Marathonからデータを受信するためにインターフェースを実装する時が来ました。
最初の血
データを取得する方法は? これは、解決する必要がある最初の問題です。 そして、それほど難しくはありません。
まず、強力なAPIがあります 。 第二に、 Java SDKの準備がすでに整ってい ます 。
私たちは自分の手に足を踏み入れ、すべてのサービスのリストを取得することに気付きます。
@Override public List<String> getServices() { try { return client.getApps() .getApps()
ServiceIdConverter::convertToServiceId以外の魔法はありません。 どんな奇妙なコンバーターを頼みますか? そして、ここで私はマラソンのサービス識別子の表現の1つの特徴について言わなければなりません。 一般に、彼らは次のパターンに従います:
/group/path/app
ただし、 /文字を使用して仮想ホストを構築することはできません。 したがって、サービス識別子を仮想ホストとして使用するSpring Cloudの一部は機能しません。 したがって、 /代わりに別の区切り文字を使用します。これは、ホスト名、つまりピリオドに含めることができます。 そのため、 group.path.app /group/path/appをgroup.path.appさgroup.path.appます。 コンバーターが実際に行うこと。
サービスのすべてのインスタンスの取得はやや複雑ですが、ロケット科学も実装されていません。
@Override public List<ServiceInstance> getInstances(String serviceId) { try { return client.getAppTasks(ServiceIdConverter.convertToMarathonId(serviceId)) .getTasks() .parallelStream() .filter(task -> null == task.getHealthCheckResults() ||
確認する必要がある主なことは、サービスのすべてのヘルスチェックに合格したことですHealthCheckResult::isAlive 。タスクは、生きている人だけとHealthCheckResult::isAliveするためです。 ヘルスチェックのメカニズムはMarathon自身によって提供されます。Marathonは 、それらを構成し、彼に委託されたサービスのヘルスを監視し、この情報をAPIを通じて無料で配布します。
これに加えて、識別子を正しい表現に再度変換し、最初にtask.getPorts().stream().findFirst().orElse(0)のみを選択することを忘れないでください。
だから、あなたは言います。 しかし、アプリケーションに複数のポートがある場合はどうでしょうか? 残念ながら、私たちの選択はわずかです。 一方では、 ServicePortインターフェイスを実装するオブジェクトを返す必要があります。これにはgetPortメソッドがあり、もちろん1つのポートのみを返すことができます。 一方、リストからどのポートを使用するかはわかりません。 マラソンはこれに関する情報を提供しません。 したがって、最初に示されているものを使用します。 おそらく幸運です。
同じConsulにサービスを登録するときに登録者が問題を解決するため、この問題の解決を試みることができます。 これは、識別子のサービスポートを考慮に入れます。 サービス識別子は次のようになります:複数のポートがある場合のgroup.path.app.8080 。
少し気が散る。 新しく実装された実装をビンとして追加します。
@Configuration @ConditionalOnMarathonEnabled @ConditionalOnProperty(value = "spring.cloud.marathon.discovery.enabled", matchIfMissing = true) @EnableConfigurationProperties public class MarathonDiscoveryClientAutoConfiguration { @Autowired private Marathon marathonClient; @Bean public MarathonDiscoveryProperties marathonDiscoveryProperties() { return new MarathonDiscoveryProperties(); } @Bean @ConditionalOnMissingBean public MarathonDiscoveryClient marathonDiscoveryClient(MarathonDiscoveryProperties discoveryProperties) { MarathonDiscoveryClient discoveryClient = new MarathonDiscoveryClient(marathonClient, marathonDiscoveryProperties()); return discoveryClient; } }
ここで重要なのは。 まず、 条件付き注釈@ConditionalOnMarathonEnabledおよび@ConditionalOnPropertyを使用します 。 つまり、たとえばspring.cloud.marathon.discovery.enabledを介して設定で機能が無効になっている場合、構成はロードされません。
次に、クライアントには魔法の@ConditionalOnMissingBean注釈があります。これにより、特定のアプリケーションで、ユーザーの必要に応じてBeanを再定義できます。
少しやらなければなりません。 Marathonのクライアントを構成します。 単純であると同時に機能する構成実装は、次のようになります。
spring: cloud: marathon: scheme: http #url scheme host: marathon #marathon host port: 8080 #marathon port
これを行うには、設定を持つクラスが必要です。
@ConfigurationProperties("spring.cloud.marathon") @Data
前の構成と非常によく似ています:
@Configuration @EnableConfigurationProperties @ConditionalOnMarathonEnabled public class MarathonAutoConfiguration { @Bean @ConditionalOnMissingBean public MarathonProperties marathonProperties() { return new MarathonProperties(); } @Bean @ConditionalOnMissingBean public Marathon marathonClient(MarathonProperties properties) { return MarathonClient.getInstance(properties.getEndpoint()); } }
その後、アプリケーションにアクセスして、 DiscoveryClient認証できます。
@Autowired private DiscoveryClient discoveryClient;
また、たとえば、特定のサービスのすべてのインスタンスのリストを取得します。
@RequestMapping("/instances") public List<ServiceInstance> instances() { return discoveryClient.getInstances("someservice"); }
そして、ここで最初の驚きが私たちを待っています。 結局のところ、私たちの目標は、インスタンスのリストを取得することではなく、インスタンス間のバランスをとることです。 そして、 DiscoveryClient単に分散の実装に参加しないため、これにはそれほど役立ちません。 嘘だ たとえば、 Zuulで エンドポイントを動的に登録するときなど、少し複雑です。 また、 ヘルスインジケータにも使用されます。 しかし、これは原則としてすべての標準アプリケーションです。 そんなに本当じゃない?
合計
マラソンと統合することができました。 これはいいです。 サービスとそのインスタンスのリストを取得することもできます。
しかし、同時に、少なくとも2つの未解決の問題があります。 1つ目は、構成ではMarathonウィザードの1つのインスタンスのみが接続用に指定されているという事実によるものです。 それが落ちれば、私たちは情報を所有しなくなり、したがって世界を所有しなくなります。
2つ目-クライアントバランシングの実現には至らず、問題を解決するツールではなく、子供用のおもちゃがまだ手元にあります。
続く