これは、コンテスト
「SAP Coder-2017」の参加者への支援の枠組みにおける3番目の出版物です。
ライフサイクルの過程にある各企業は、「大」とそうでない両方の大量のデータを生成します。 これらのデータは、多くの場合、新しい知識を得るために使用できます。これは、ビジネスの開発戦略またはローカルな作業の瞬間の行動の戦術に大きな影響を与える可能性があります。 現在、コンピューター技術の開発と蓄積データ量の増加に関連して、数値メソッドが大幅に開発されており、「生の」データの配列から有用な情報を抽出し、さまざまなビジネスシナリオで使用できます。

SAP Cloud Platformには、他の組み込みサービスとともに、プラットフォーム上(および外部)で作成されたビジネスタスクで構築モデルを構築および使用できる予測分析ツールキットがあります。 投稿の公開日にサービスに含まれる予測ツールのセットは、次の要素で構成されます。
- クラスタリング-多数の属性分類子を持つオブジェクトのデータベースの古典的なクラスター分析とセグメンテーション。
- 予測-時系列に基づいて予測を行います。
- キーインフルエンサー-目的関数に最も影響を与えるパラメーターを検索します。
- 外れ値-データセット内の非標準パターンの検索(不正の識別、入力エラーなど);
- 推奨-購入履歴に基づいた製品推奨のモデルの構築(チェック);
- スコアリング方程式-目的関数を分析的に計算し、独自のアプリケーションに埋め込むことができる方程式を作成および抽出します。
- What If-オブジェクトの動作の履歴に基づいて特定のアクションの結果を推測できる「what-if」分析
メソッドとその説明の現在のリストは、
ここにあります 。
SAP Encoderコンテストのタスクの1つには、推奨モデルの使用が含まれます。 ここでは、SCPの予測サービスで同様のモデルを構築する方法を示します。 最初に行うことは、モデルの「トレーニング」のためのデータの準備です。 推奨サービスの場合、トレーニングとは、商品のペア(一緒に販売)を見つけ、特定の顧客(たとえば、ロイヤルティプログラムのメンバー)に対する推奨リストを作成することです。
ソースデータ
モデルを構築するための初期データは簡単です-これらは店のレジ係の小切手です。 次のパラメータが含まれている必要があります。
- userID-ロイヤルティプログラムのメンバーシップ番号(購入者の一意の識別子)
- itemID-製品コード(SKU)
- purchaseDate-取引日(チェック)
HANA Studio(Eclipse)のインポート/エクスポート機能を使用して、サーバーファイルシステムにアクセスせずにこのデータをシステムにダウンロードするのが最も簡単です。 これを行うには、以下を行う必要があります。
- CSVファイルでデータを準備します。
- SCPに新しいHANA MDCデータベースを作成します。 私たちの場合、それはh1と呼ばれます
- 実験を行うデータスキームを作成します。 PROBA回路を作成しました。
- ソースデータ(ここではPROBA.SALES_DATA)を配置するテーブルを作成します。 テーブルにはいくつかのキーフィールドが含まれている必要があります。この場合、RID-ロイヤリティプログラム参加者の数、RDATE、TRIME、RDATETIME-さまざまな形式のトランザクションの日付と時刻です。RDATETIMEのみが重要で、SKUが記事番号です。

さらに、データベースには、2つのフィールドのPRODUCTSテーブル(製品のコードと名前)が含まれています。
- エクスポート機能を使用して、SALES_DATAテーブルをローカルディスクにアンロードします。 ディレクトリ構造を下って説明ファイルをエクスポートします
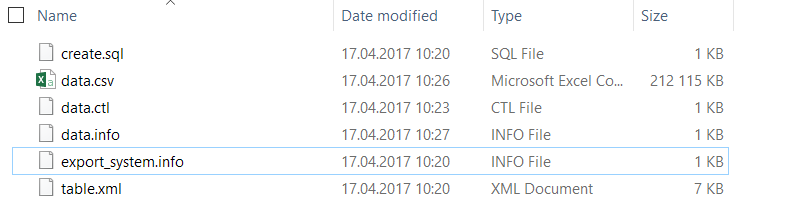
- data.csvファイルに、データをCSV形式で入れます
- data.ctlファイルで、CSVフィールドセパレータを必要なものに変更します
- data.infoファイルで、data.csvファイルのサイズとその中の行数のデータを変更します
- インポート機能を使用してデータをロードし、データベース内の既存のオブジェクトを置き換えます
サービスのセットアップ
モデルの構築を開始する前に、予測サービスの基本設定を行う必要があります。 デフォルトでは、サービスはオフになっています。最初にすることは、サービスを有効にすることです
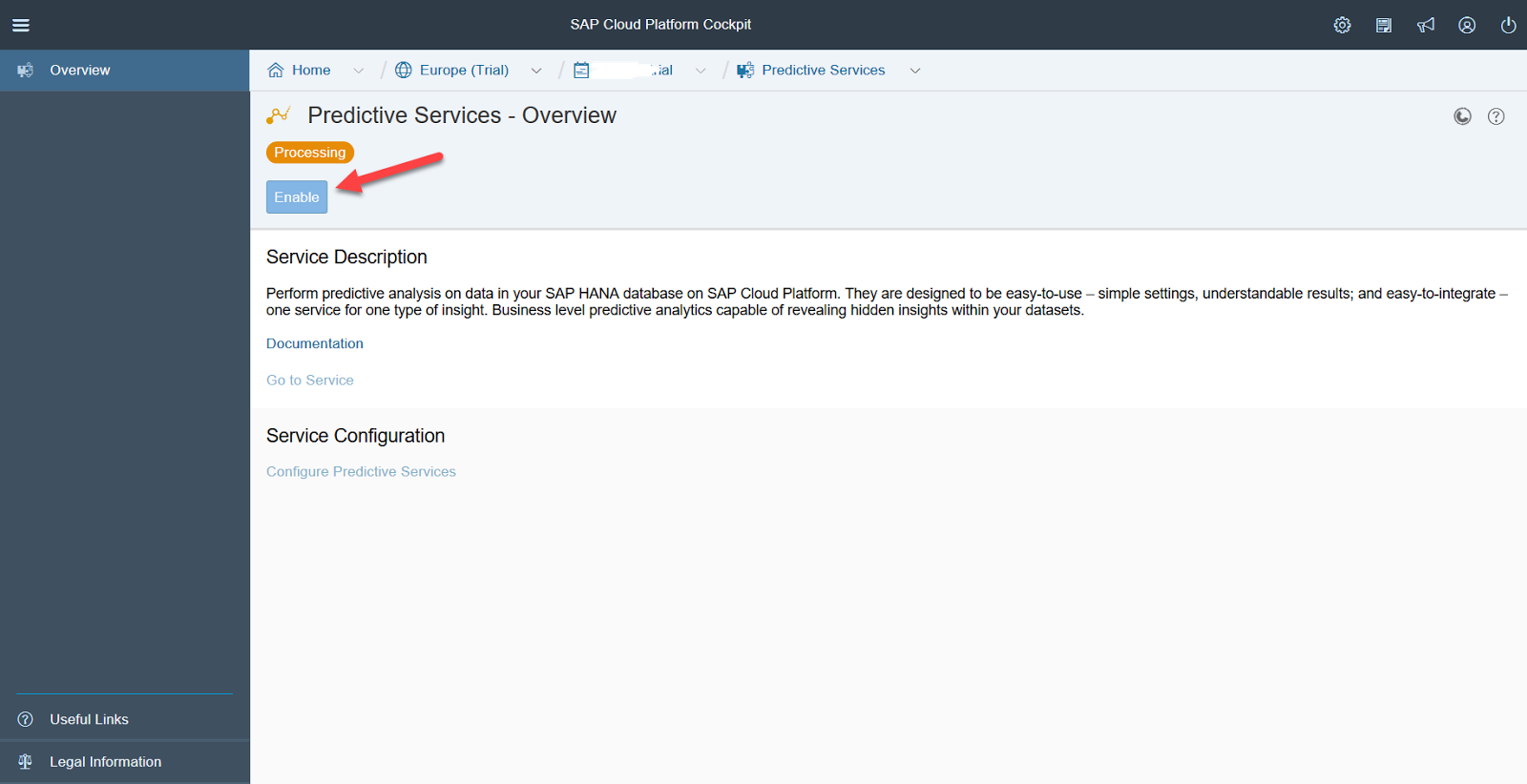
システムは、アップデートをインストールする価値があるかどうかを尋ねます。 正解はイエスです。 その後、ユーザーアカウントにサービスを展開する必要があります。そのためには、SCPへのログインに使用するログインとパスワードを入力する必要があります。
サービスをデプロイした後、Javaダッシュボードリンクをクリックします
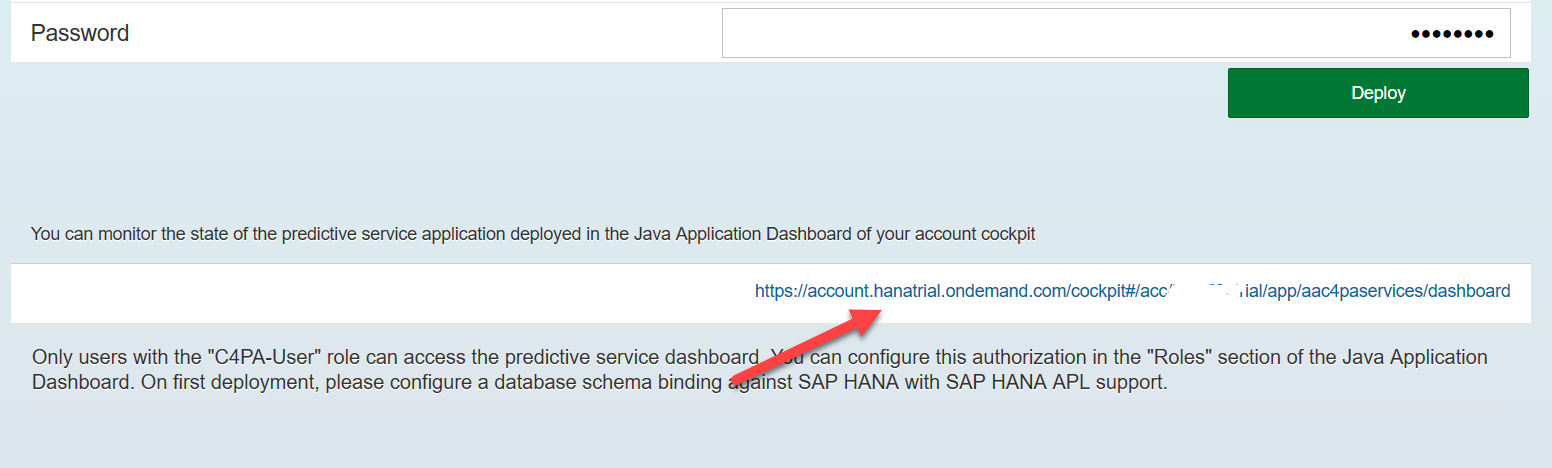
そして、指定された両方の役割をユーザー開発者に割り当てます:C4PA-User、C4PA-Admin

次のステップは、SCP Predictiveサービスをデータベースにバインドすることです。
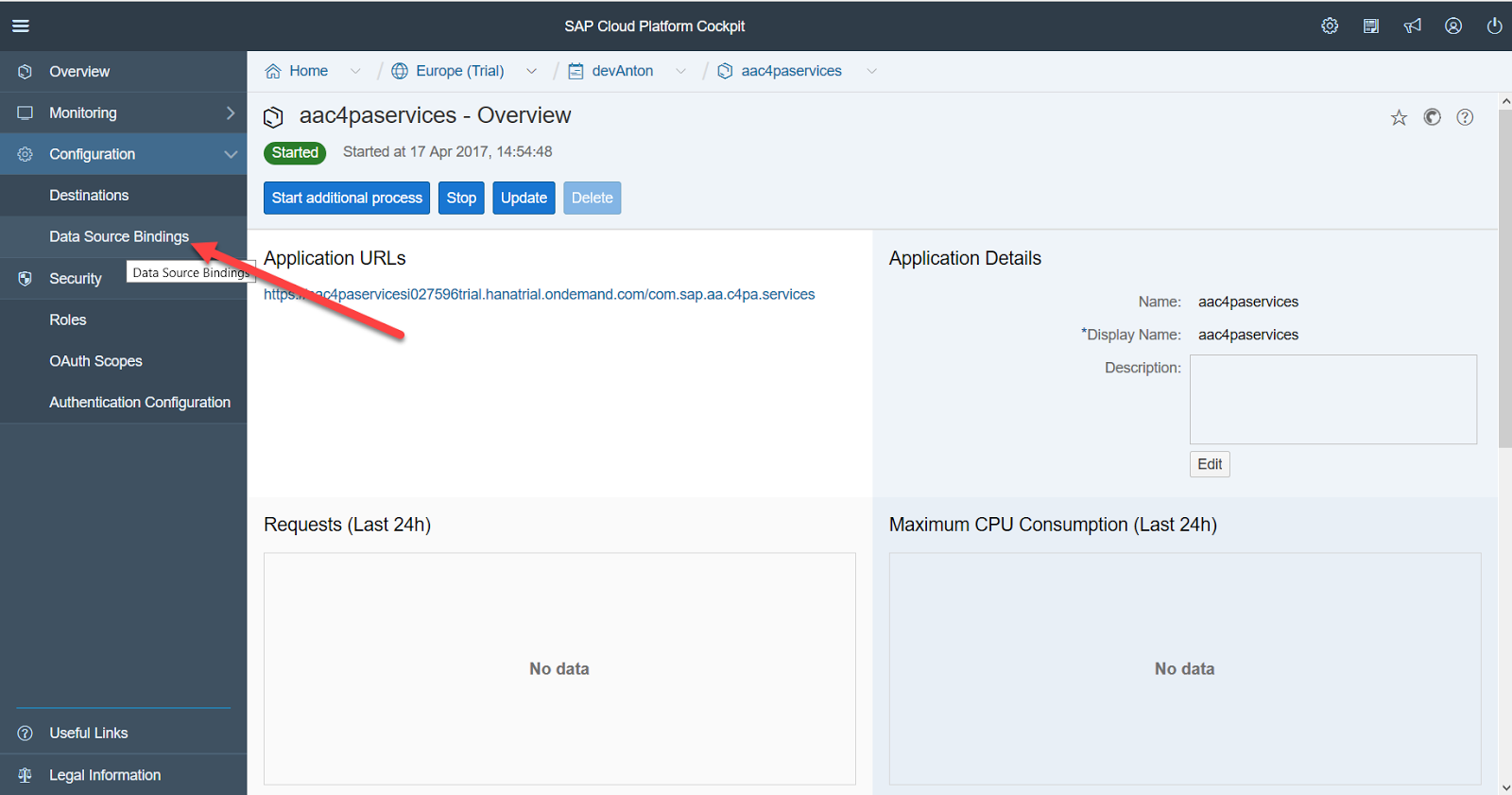
これを行うには、データベースに技術ユーザー(この場合はPROBA_U)を作成することが望ましい
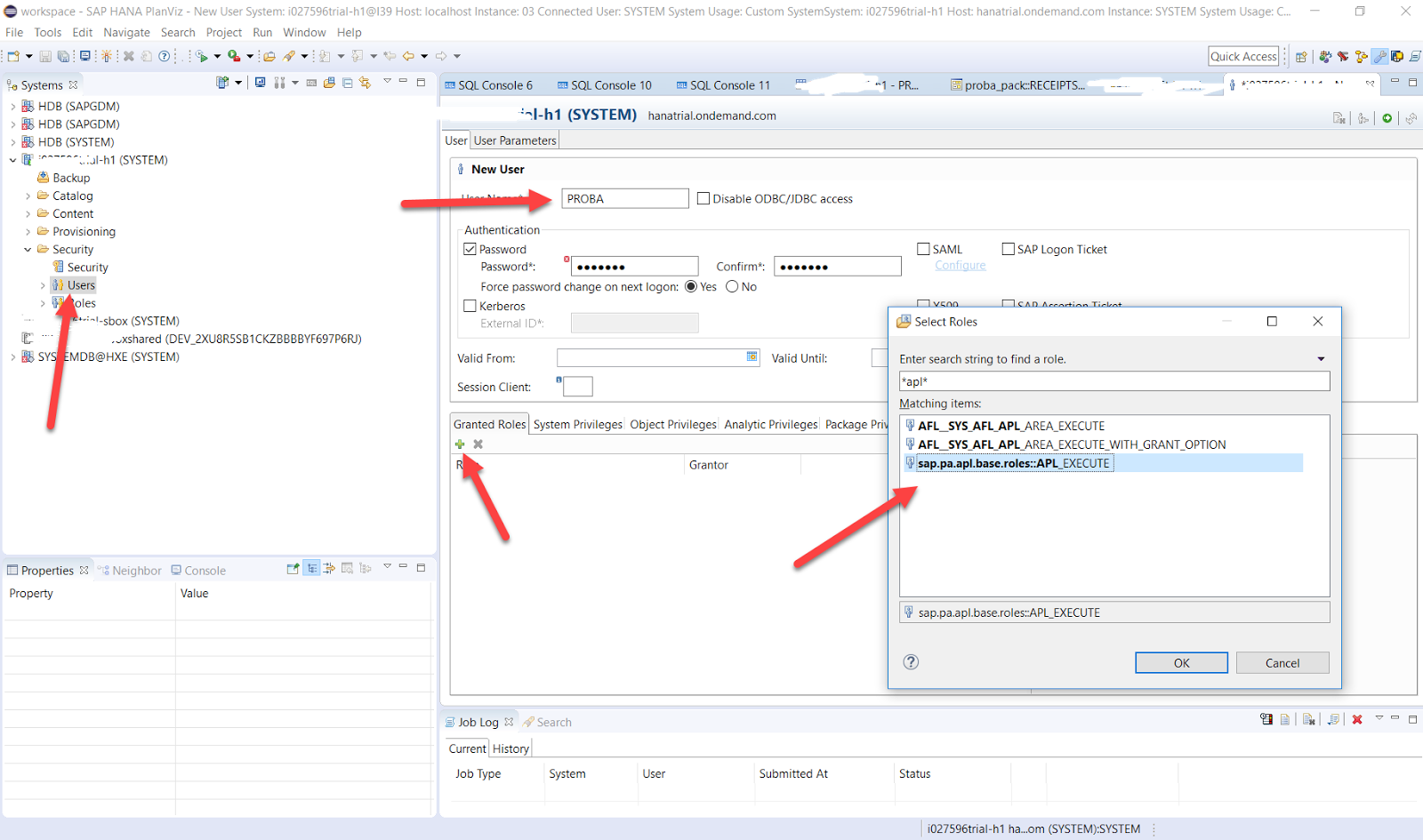
そして、予測サービスを実行するために必要な権限を彼に割り当てます。 ユーザーを作成するとき、HANAは初期パスワードを要求し、それを変更する(および予測サービスに代わってデータベースに自動的に入力する)ために、このユーザーに代わって1回ログインする必要があります。 これを行うには、HANA Studioでクラウドデータソースへの新しい接続を作成し、初期パスワードを変更してデータベースを入力します。
技術ユーザーを作成(または既存のユーザーを使用する決定)した後、サービスを特定のデータベーススキーマにバインドします。
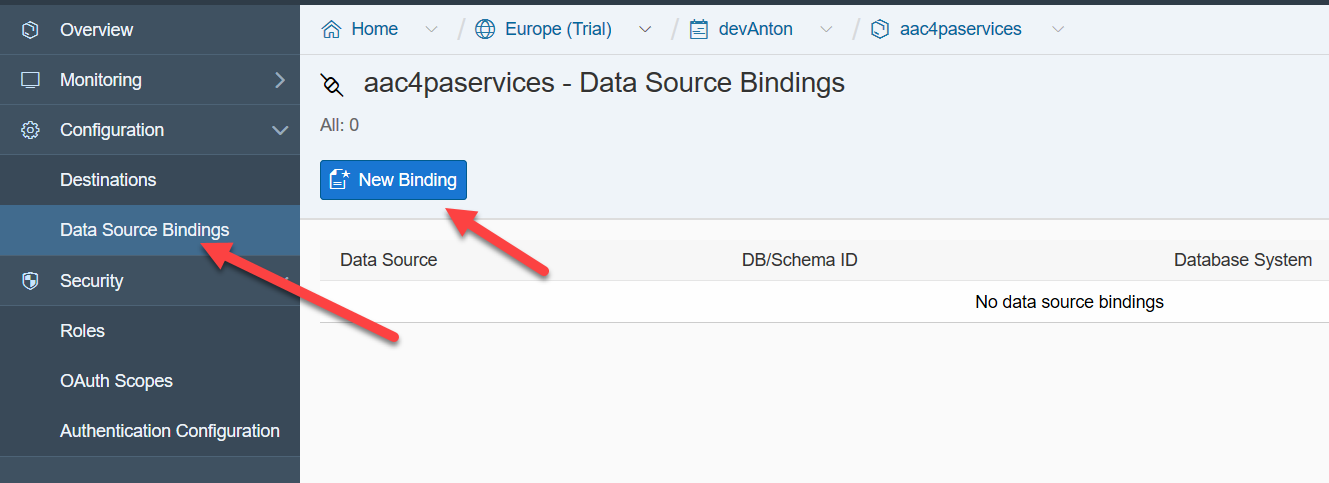
この場合、テクニカルユーザーのデータを使用します。デフォルトではデータソースはそのままです。
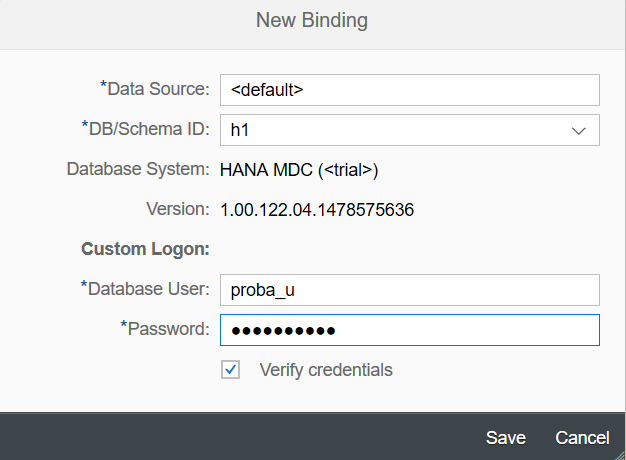
サービスが開発者アカウントにデプロイされ、データベースがバインドされた後、サービスを再起動します-停止ボタンと開始ボタンを順番にクリックします。
サービスを再起動すると、Javaアプリケーションへのリンクが表示され、サービスの管理、制御、アプリケーション開発での使用が可能になります
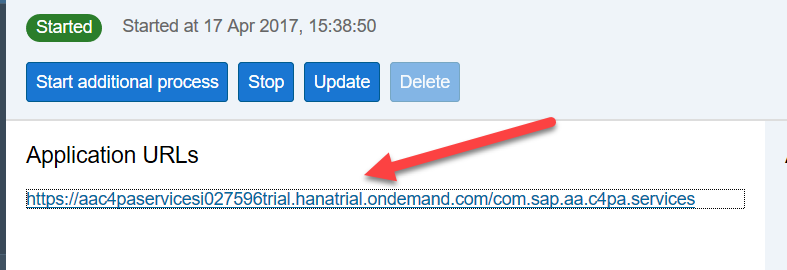
リンクを呼び出した後、システムは2つのパネルを提供します。1つは開発用、もう1つはサービスの監視用です
[管理]パネルをクリックすると、アプリケーションは予測サービスに関する大量の監視情報を提供します。これは分析に使用できますが、この場合、メインパネルは[予測サービスAPIドキュメント]です。
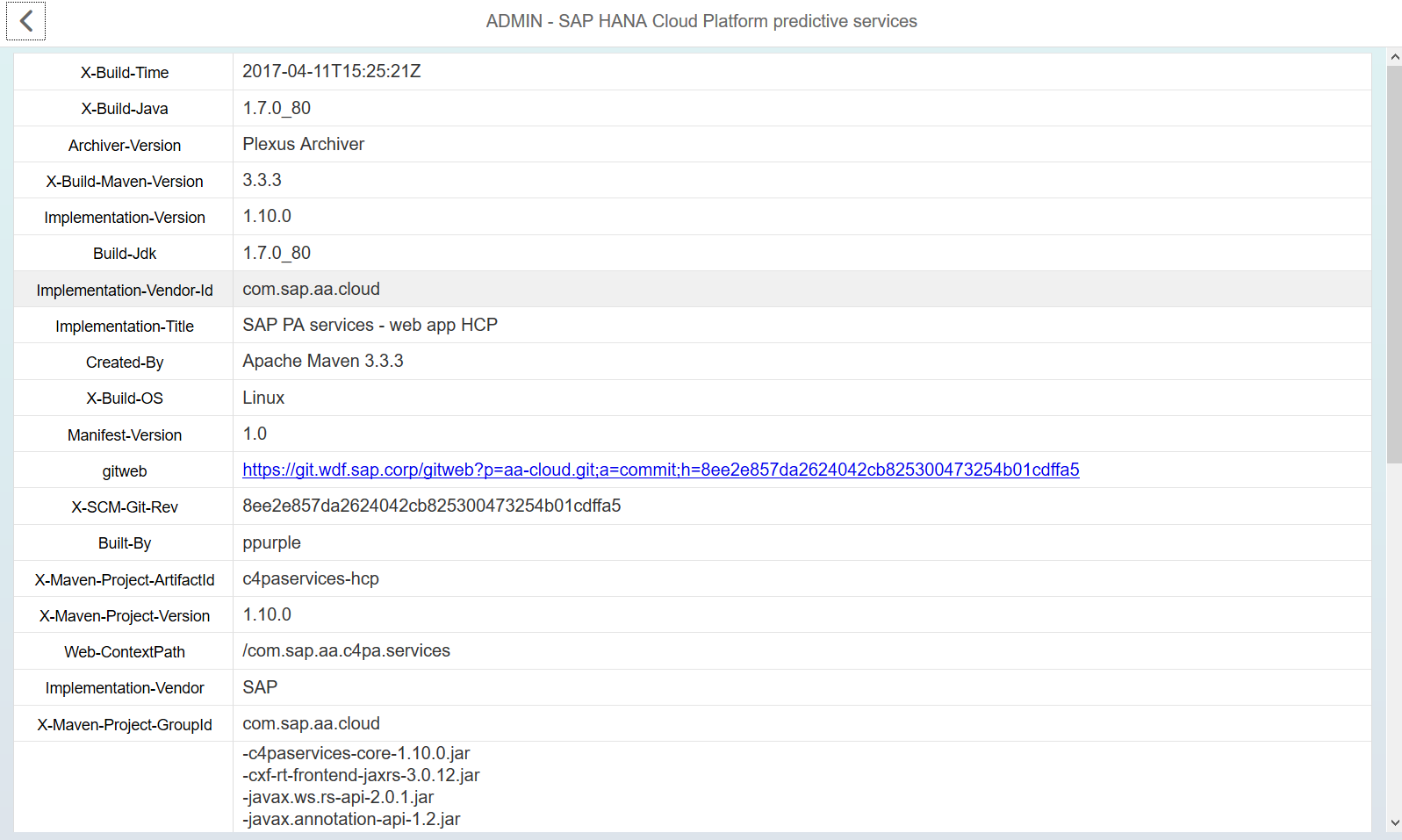
推奨モデルの構築と使用
人間の目により適合した形でチェックを見てみましょう。 これを行うには、フォームにデータ表現を作成します
CREATE VIEW "PROBA"."SALESWPROD" ( "RID",
"USER_ID",
"RDATE",
"RTIMESTAMP",
"ITEMS",
"SKU_ID",
"SKU_NAME" ) AS SELECT
T0."RID" ,
t0."USER_ID",
T0."RDATE",
TO_TIMESTAMP(T0."RDATETIME"),
T0."ITEMS",
T0."SKU",
T1."SKU_NAME"
from "PROBA"."SALES_DATA" T0
inner join "PROBA"."PRODUCTS" T1 on T0."SKU" = T1."SKU_ID" WITH READ ONLY
このビューは、問題を解決するために必要ではありませんが、販売ポジション(SKU)を含む領収書を視覚的に確認できます。

Predictive Services APIドキュメントを起動します。 Predictive Serviceアプリケーションのこのページには、それに含まれるすべての数学メソッドと、それらの各メソッドへのアクセスポイント(エンドポイント)が含まれています。
まず、予測モデルのデータソースを作成します。 これを行うには、アクセスポイント/ API /分析/データセットの[POST]タブをクリックします
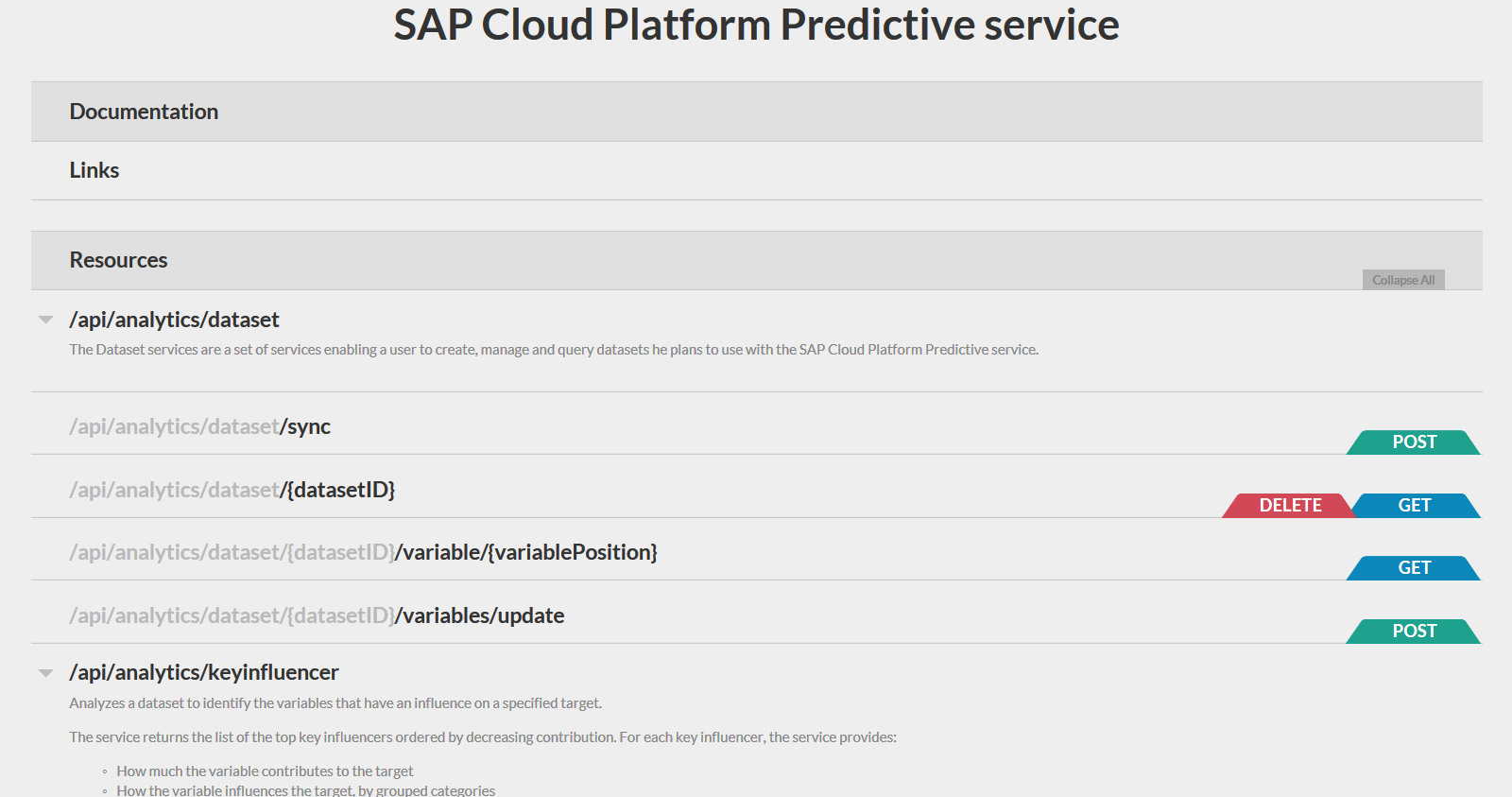
JSONテンプレートのhanaURLパラメーターを変更します。これにより、すべてのパラメーターがPerdictiveサービスに渡されます。 POSTを押して、ステータス200のサーバーの応答を待ちます。応答として、サーバーは接続されたソースに関する情報(行数、フィールドの数、タイプなど、そして最も重要なのはデータセットのID)を報告するJSONファイルも返します。覚えておく必要があります。今後、推奨モデルを作成するときに使用します。右上隅の閉じるボタンをクリックしてこのフォームを閉じます。
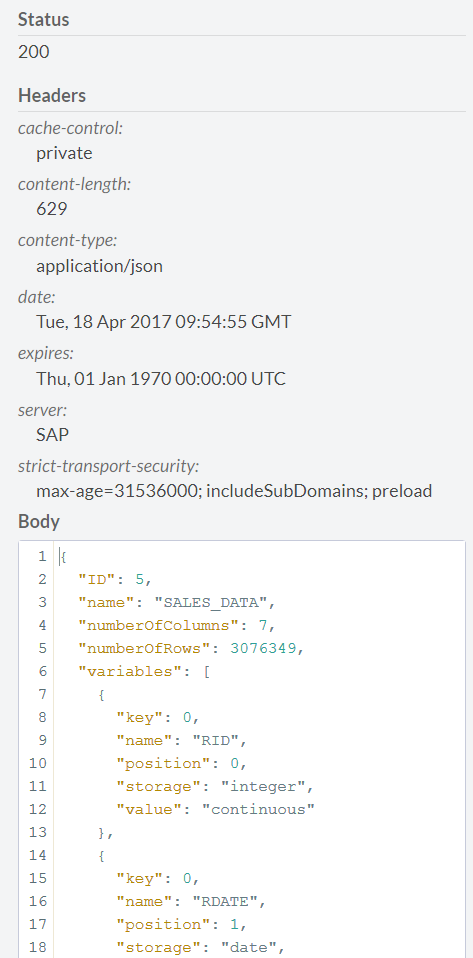
予測サービスのメインページに戻り、モデルの作成に進みます。 これを行うには、リンク/ api / analytics / recommendations / recommenderの[POST]タブをクリックします。 推奨モデルの設定ページが開きます。 将来のモデルを構築するためのパラメーターは、JSON形式で設定されます。 可能なすべてのモデルパラメーターは、
https://help.hana.ondemand.com/c4pa/frameset.htm?ee805144d197482abef88bfad8d895da.htmlのドキュメントに記載されてい
ます 。
それは
- UserColumn-ロイヤルティプログラム参加者の番号を含むフィールド
- itemColumn-SKU
- dateColumn-取引日
- startDate-計算するデータの開始日
- endDate-計算のデータ終了日
さらに、モデルの数学を記述するパラメーターを変更できます。 このモデルでは、次のパラメーターを使用します。
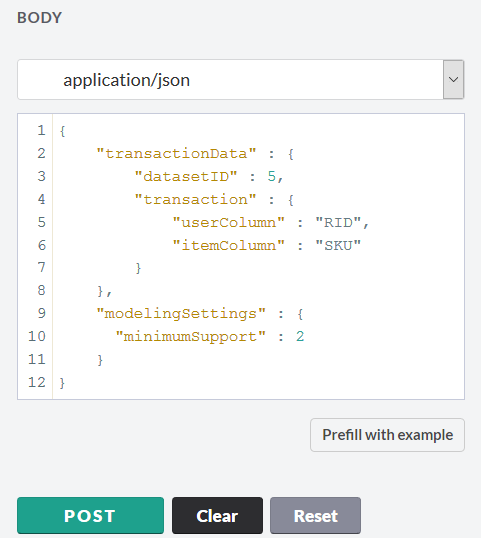
モデルの構築を開始し、応答を取得します。 キーポイントは、モデルIDを書き留めることです
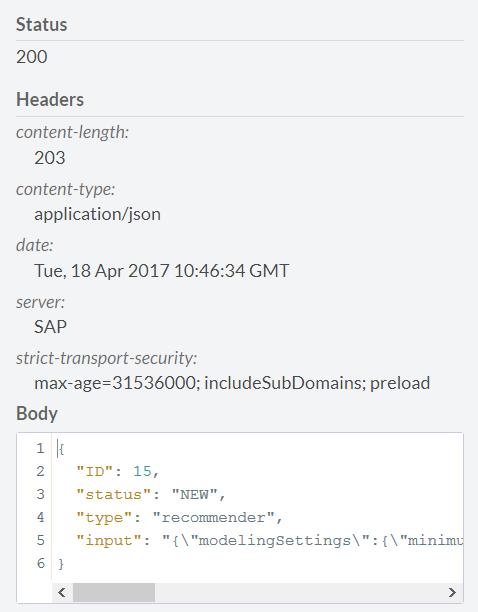
リンク/ api / analytics / recommendations / recommender / {jobID}を使用すると、IDとして15を指定して、構築されたモデルのステータスを確認できます。 このモデルのステータスは次のとおりです
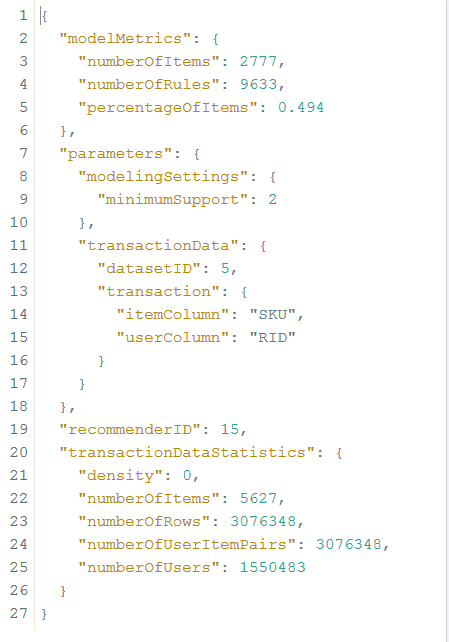
同じバスケットで他のバスケットと一緒に見つかったSKUの数は2777個であり、それに基づいて9633個の推奨ルールを見つけることができました。 リンク/ api /分析/推奨事項を使用して、結果のモデルをテストできます。 ここで、次のパラメータを入力する必要があります。
- itemList-すでにバスケットにあるSKU
- maxItems-返される推奨の最大数
- RecommendederID-前のステップで作成されたモデルのID
- userID-ロイヤルティプログラムのメンバー番号
itemListパラメーターとuserIDパラメーターの両方を指定することも、どちらか一方のみを指定することもできます。 パラメーターを1つだけ指定すると、システムは警告を発行しますが、引き続き機能します。
SKU 5000267097428でモデルを確認する
応答して
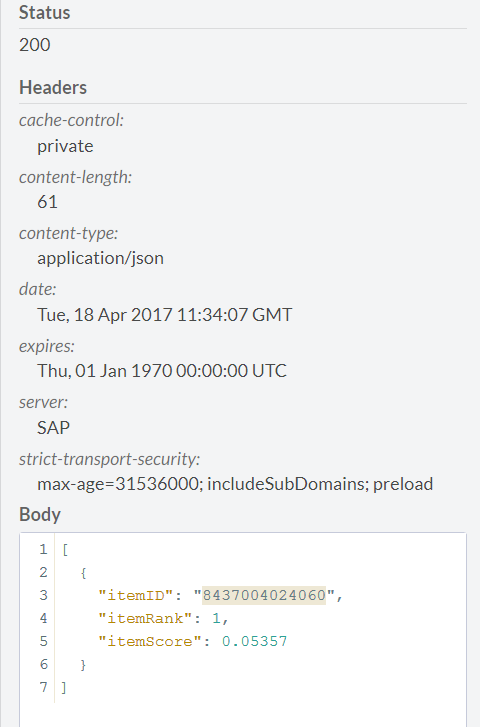
それが何であるか見てみましょう
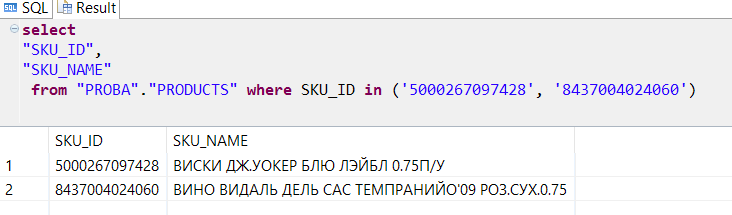
したがって、ウイスキーを購入する際には、バイヤーに辛口ワインをお勧めするのがいいでしょう。
推奨モデルはバッチモードで実行することもできます。これにより、ロイヤリティプログラムのすべてのユーザーに対する推奨の表が生成されます。 これを行うには、リンク/ API /分析/推奨事項/バッチのPOSTタブをクリックします

次に、推奨事項を配置する表を示します

そして、計算を開始します。 このサービスはテーブルを作成し、ユーザーごとに推奨される製品を計算します。この製品は購入される可能性が高くなります。
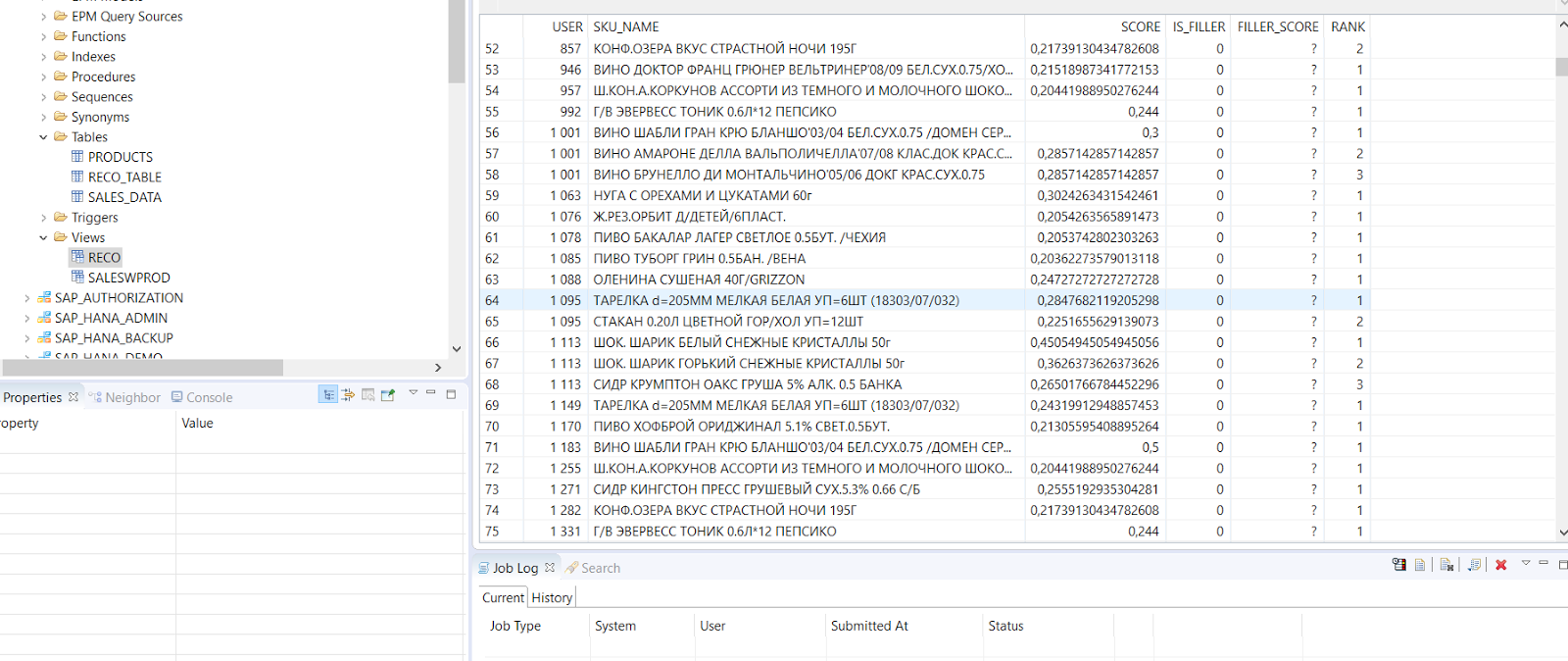
したがって、予測サービスを使用すると、最も一般的に使用される数学的手法のいくつかを迅速に構成および使用して、実際のビジネスでの使用に適した予測モデルを構築できます。