友人たち、今日は、 PostgreSQLのフォールトトレランスに関するPG Day'17 Russia Gulcin Yildirimレポーターの 1人による一連の記事の第3部の翻訳に注目します。PostgreSQLは驚くべき速度で開発されている素晴らしいプロジェクトです。 このシリーズの記事では、PostgreSQLのバージョン全体のフォールトトレランスの進化に焦点を当てます。 これはシリーズの3番目の記事であり、タイムラインの問題と、PostgreSQLのフォールトトレランスと信頼性への影響について説明します。

Postgresの進化を最初から追跡したい場合は、このシリーズの最初の2つの記事を読んでください。
- PostgreSQLのフォールトトレランスの進化
- PostgreSQLフェールオーバーの進化:レプリケーションフェーズ
タイムラインデータベースを以前の条件のいずれかにロールバックする機能は、特定の問題を引き起こします。
フェイルオーバー (図1)、
スイッチオーバー (図2)、および
pg_rewind (図3)の状況を分析することにより、それらのいくつかを調査し
ます 。
たとえば、データベースの元の履歴で、火曜日の夕方17時15分に重要なテーブルを削除したが、水曜日の正午に間違いに気付いたとします。 瞬きすることなく、バックアップコピーを取り出し、火曜日の午後17時14分に状態にロールバックすると、すべてが再び機能します。 このデータベースユニバースの履歴では、テーブルを削除したことはありません。 しかし、そのアイデアがあまり良くないことに気付いて、元のストーリーから水曜日の朝に戻りたいと思ったとします。 データベースが再び動作を開始した後、戻りたい時点に至るまでのWALセグメントを書き換えた場合、成功しません。
したがって、これを回避するには、特定の時点で復元を実行した後に生成された一連のWALを、元のデータベース履歴で作成されたWALから分離する必要があります。
この問題を解決するために、PostgreSQLにはタイムラインという概念があります。 アーカイブの復元が完了するたびに、新しいタイムラインが作成され、この復元後に生成された一連のWALレコードを識別します。 タイムラインIDはWALセグメントファイル名の一部であるため、新しいタイムラインは以前のタイムラインによって生成されたWALデータを上書きしません。 つまり、さまざまなタイムラインをアーカイブできます。
どの時点で回復する必要があるかわからず、試行錯誤して古いストーリーから分岐するのに最適な場所を見つけるためにいくつかの修復を行う必要がある状況を考えてください。 タイムラインがなければ、このプロセスはすぐに手に負えない混乱を引き起こすでしょう。 そして、それらを使用して、以前に放棄したタイムラインブランチの状態を含め、以前の状態に回復できます。
新しいタイムラインが作成されるたびに、PostgreSQLは「タイムライン履歴」ファイルを作成します。このファイルには、どのタイムラインからいつ分岐したかが示されます。 これらの履歴ファイルは、複数のタイムラインを含むアーカイブから復元するときにシステムが正しいWALセグメントファイルを選択できるようにするために必要です。 つまり、それらはWALセグメントファイルと同じ方法でWALアーカイブに保存されます。 履歴ファイルは小さなテキストファイルであるため、(大きなセグメントファイルとは異なり)無期限に保存することは安価で便利です。 必要に応じて、ストーリーファイルにコメントを追加して、この特定のタイムラインが作成された方法と理由に関する独自のメモを記録できます。 このようなコメントは、実験の結果として、さまざまなタイムラインが絡み合っている場合に特に役立ちます。
デフォルトでは、基本的なバックアップが作成されたときに関連していたのと同じタイムラインに従ってリカバリが行われます。 子のタイムラインに復旧する(つまり、復旧試行後に生成された状態に戻す)場合は、recovery.confでタイムラインIDを指定する必要があります。 ベースバックアップが作成される前に分岐したタイムラインに復元することはできません。
PostgreSQLのタイムラインの概念を簡素化するために、
failover 、
switchover、 pg_rewindの場合に関連する問題を図
1、2、3にまとめて説明します。
フェールオーバースクリプト :
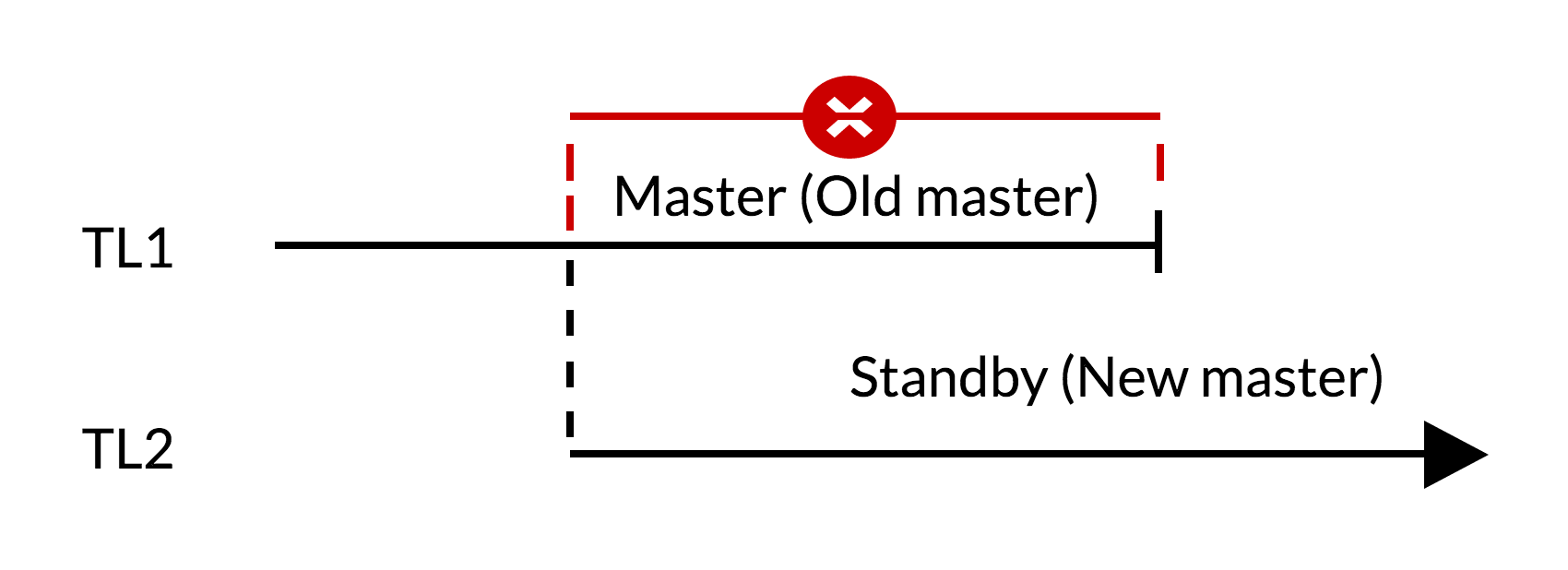
- 古いマスターには、スタンバイ(TL1)に適用されない変更があります。
- timelinの成長は、変更の新しい履歴(TL2)を反映しています。
- 古いタイムラインからの変更は、新しいタイムラインに切り替えるサーバーで再生できません。
- 古いマスターを新しいマスターのレプリカにすることはできません。
スイッチオーバースクリプト :
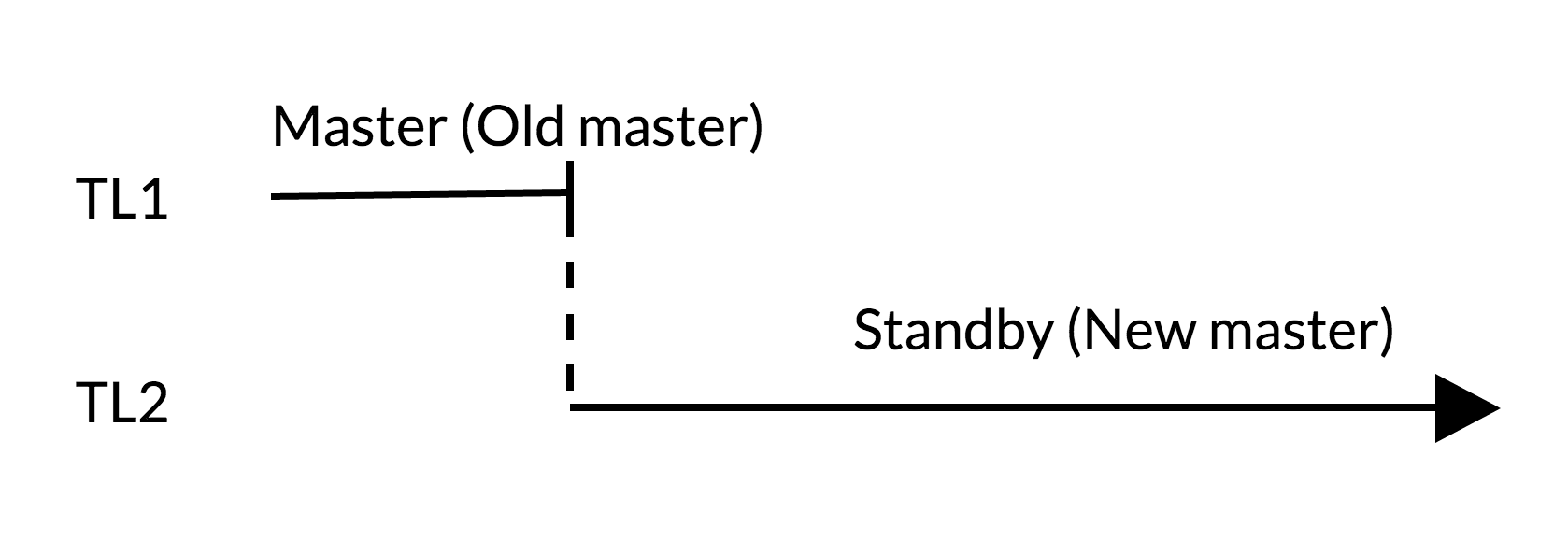
- 古いマスターでは、スタンバイ(TL1)に変更は適用されません。
- 成長のタイムラインは、変更の新しい履歴(TL2)を反映しています。
- 古いマスターが新しいマスターのスタンバイになる可能性があります。
Pg_rewindスクリプト :
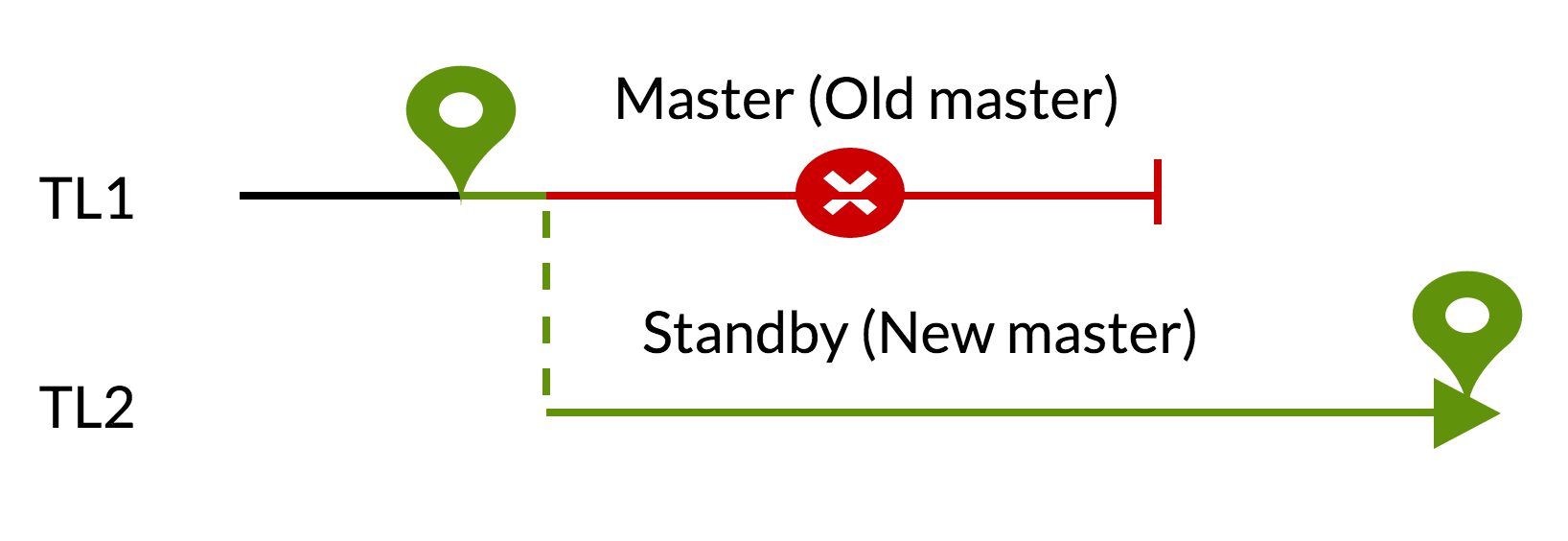
- コミットされていない変更は、新しいマスター(TL1)のデータを使用して削除されます。
- 古いマスターが新しい(TL2)のスタンバイになる可能性があります。
pg_rewindpg_rewindは、クラスターのタイムラインが分岐した後、PostgreSQLクラスターを同じクラスターの別のコピーと同期するためのツールです。 典型的なシナリオ:フェールオーバーの後、古いプライマリサーバーは新しいプライマリへのスタンバイとして再び立ち上がります。
結果は、ターゲットデータディレクトリを元のディレクトリに置き換えることと同じです。 構成ファイルを含むすべてのファイルがコピーされます。 新しいベースバックアップやrsyncなどのツールを削除するよりもpg_rewindの利点は、pg_rewindがクラスター内の変更されていないすべてのファイルを読み取る必要がないことです。 したがって、この方法は、特にデータベースが大きく、クラスター間で小さな部分のみが異なる場合に、はるかに高速です。
どのように機能しますか?主な考え方は、変更されていないことがわかっているブロックを除き、新しいクラスターから古いクラスターにすべてをコピーすることです。
- 古いクラスタのWALリストは、新しいクラスタのタイムライン履歴が古いクラスタから分岐した時刻の前の最後のチェックポイントからスキャンされます。 WALレコードごとに、影響を受けたデータブロックについてマークが付けられます。 これにより、新しいクラスターが分岐した後に古いクラスターで変更されたすべてのデータブロックのリストが作成されます。
- これらの変更されたブロックはすべて、新しいクラスターから古いクラスターにコピーされます。
- clogや構成ファイルなどの他のすべてのファイルは、新しいクラスターから古いクラスターにコピーされます。 関係ファイルを除くすべて。
- 新しいクラスターからのWALは、フェールオーバー時に作成されたチェックポイントから開始して適用されます。 (厳密には、pg_rewindはWALを使用せず、単にバックアップショートカットファイルを作成します。これは、PostgreSQLの起動時にこの参照ポイントから再生を開始し、必要なすべてのWALを適用することを示します。)
注 :
pg_rewindが機能するには、postgresql.confでwal_log_hintsを設定する必要があります。 このパラメーターは、サーバーの起動時にのみ構成できます。 デフォルト値は
offです。
おわりにこの記事では、Postgresの
タイムラインと 、
フェールオーバーと
スイッチオーバーの状況の処理方法について説明しました。 また、pg_rewindの仕組みと、Postgresの復元力と信頼性への貢献についても説明しました。 次の記事では、同期コミットについて説明することでトピックを継続します。

Gulcinは
PG Day'17に参加し、参加者からの質問に個人的に回答するとともに
、クラウドでのPostgresアップグレードの
自動化についてさらに詳しく話し
ます 。 バージョン9.4以降で使用可能なロジックデコード機能を使用して、メジャーバージョンにアップグレードする問題を解決するにはどうすればよいですか? 答えは
pglogicalの使用にあります。 さらに、ボーナスとして、
Ansibleを使用して提案されたソリューションを自動化します。
登録して質問を準備してください!