Quake IIのソースコードの読み取りに費やした約1か月の空き時間。 idTech3エンジンは大きな変化をもたらしたため、驚くほど有益な経験でした。Quake1、Quake World、およびQuakeGLは、1つの美しいコードアーキテクチャに統合されています。 特に興味深いのは、Cプログラミング言語が多相性を提供しないという事実にもかかわらず、モジュール性が達成される方法でした。
Quake IIは、多くの点で、ソフトウェアの素晴らしい例です。これは、これが(ライセンスの数で)最も人気のある3次元エンジンであったためです。 それに基づいて、30以上のゲームが作成されました。 さらに、彼はゲーム業界のソフトウェア/ 8ビットカラーシステムからハードウェア/ 24ビットへの移行を示しました。 この移行は1997年頃に発生しました。
したがって、プログラミングが好きな人はこのエンジンを学ぶことを強くお勧めします。 いつものように、私は無数のメモを保管し、整理して数時間を節約するために記事として公開しました。
「クリーニング」のプロセスは非常に夢中になりました。現在、この記事には40メガバイト以上のビデオ、スクリーンショット、イラストがあります。 私の仕事にそれだけの価値があるかどうか、そして将来ASCIIで未処理のメモを公開する必要があるかどうかはわかりませんが、あなたの意見を述べてください。
最初の会議と編集
ソースコードはid Software
ftpサイトから無料で入手できます。 このプロジェクトはVisual Studio Express 2008で開くことができ、Microsoft Webサイトから無料でダウンロードすることもできます。
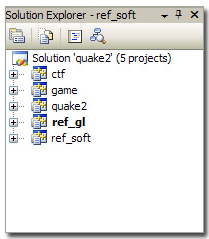
最初の問題は、Visual Studio 6の作業環境が1つではなく5つのプロジェクトを作成することです。 これは、Quake2がモジュール方式で開発されたためです(これについては後で説明します)。 プロジェクトの結果は次のとおりです。
| プロジェクト | 組立 |
| ctf | gamex86.dll |
| ゲーム | gamex86.dll |
| 地震2 | quake.exe |
| ref_soft | ref_soft.dll |
| ref_gl | ref_gl.dll |
注: 「ctf」プロジェクトと「game」プロジェクトは互いに上書きします。これについては後で詳しく説明します。
注2: DirectXヘッダーがないため、最初にビルドが失敗します。
fatal error C1083: Cannot open include file: 'dsound.h': No such file or directory
Direct3D SDKとMicrosoft SDK(MFC用)をインストールし、すべてが正常にコンパイルされました。
ソフトウェアの侵食: Quake 2でQuakeコードベースで起こったことは起こり始めたようです。VisualStudio 2010で作業環境を開くことは不可能です。VS2008を使用する必要があります。
注:コンパイル後にエラーが発生した場合
"Couldn't fall back to software refresh!" 、
これは、レンダラーDLLが正しくロードできなかったことを意味します。 しかし、これは簡単に修正できます。
Quake2カーネルは、win32 API:LoadLibraryを使用して2つのDLLをロードします。 DLLが予期したものではない場合、またはDLLの依存関係を解決できない場合、エラーメッセージを表示せずにエラーが発生します。 したがって:
- 5つのプロジェクトすべてを1つのライブラリに接続します-各プロジェクトを右クリック->プロパティ-> C / C ++:「ランタイムライブラリ」=マルチスレッドデバッグDLL(構成「デバッグ」、そうでなければリリースを使用)を確認します。
id Softwareがリリースしたquake2バージョンを使用している場合、これでエラーが修正されます。
- 私のバージョンを使用している場合:スクリーンショットをエンジンのPNGに保存する機能を追加したので、libpngとlibzもビルドする必要があります(これらはサブディレクトリにあります)。 デバッグDLL構成が選択されていることを確認してください。 ビルドするとき、libpngおよびzlib DLLをquake2.exeと同じフォルダーに置くことを忘れないでください。
Quake2アーキテクチャ
Quake 1コードを読んだとき、
記事 (翻訳は
こちら )を3つの部分に分割しました:「ネットワーク」、「予測」、「視覚化」。 このアプローチはQuake 2に適しています。中核となるエンジンはそれほど大きな違いはありませんが、記事を次の3つの主要なタイプのプロジェクトに分割すると改善がわかりやすくなります。
| プロジェクトの種類 | プロジェクト情報 |
| メインエンジン(.exe) | モジュールを呼び出し、クライアントとサーバー間で情報を交換するカーネル。 実稼働環境では、これはquake2プロジェクトです。 |
| レンダラーモジュール(.dll) | 視覚化を担当します。 作業環境には、ソフトウェアレンダラー( ref_soft )とOpenGLレンダラー( ref_gl )が含まれています。 |
| ゲームモジュール(.dll) | ゲームプレイ(ゲームコンテンツ、武器、モンスターの動作など)を担当します。 実稼働環境には、シングルユーザーモジュール( game )とCapture The Flagモジュール( ctf )が含まれています。 |
Quake2にはシングルスレッドアーキテクチャがあり、エントリポイントは
win32/sys_win.cます。
WinMainメソッドは、次のタスクを実行します。
game_export_t *ge;
完全に分解されたサイクルは、私の
ノートに記載されてい
ます。「なぜアーキテクチャのそのような変更が必要なのか」と尋ねることができます。 この質問に答えるために、1996年から1997年までのQuakeのすべてのバージョンを見てみましょう。
- 地震
- WinQuake
- GLQuake
- VQuake (開発者の1人であるStefan Podell(Stefan Podell)から、 Zバッファリング ( ミラー ) におけるV2200の問題についてのいくつかの言葉)。
- Quake World Server。
- Quake World Client。
多くの実行可能ファイルが作成され、そのたびに
#ifdefプリプロセッサを介してコードを分岐または構成する必要がありました。 それは完全な混乱であり、それを取り除くために必要でした:
- クライアント/サーバーを統合します。
- 交換可能なモジュールをロードできるカーネルを構築します。
新しいアプローチは次のように説明できます。
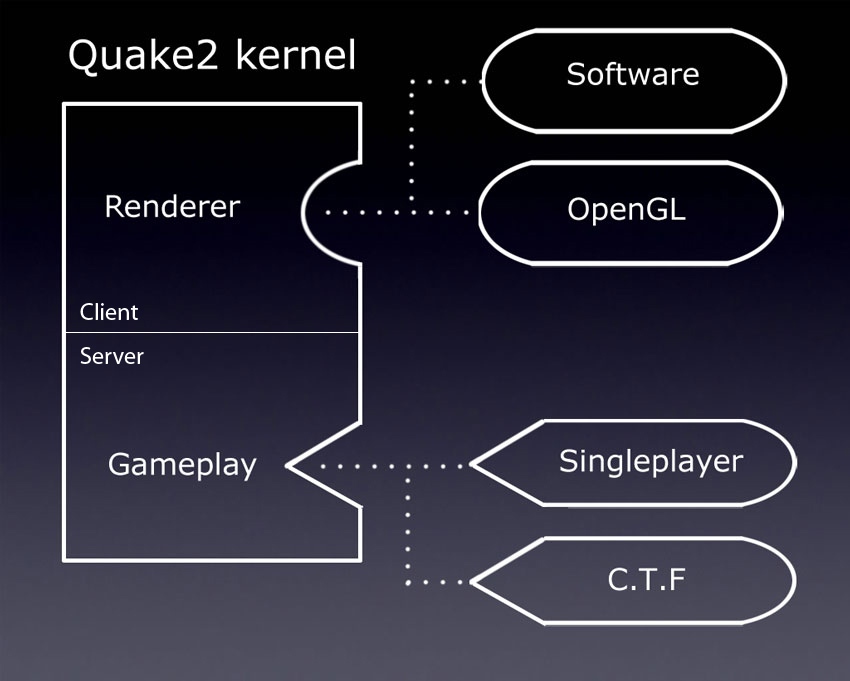
2つの主要な改善:
- クライアントとサーバーの統合:クライアント用とサーバー用に1つのexeがなくなったため、メインの実行可能ファイルはサーバー、クライアント、またはその両方として同時に機能しました。 シングルユーザーモードでも、クライアントとサーバーは同じ実行可能ファイルで実行されていました(ただし、この場合、データ交換はTCP IP / IPXではなくローカルバッファーを介して実行されました)。
- モジュール性:動的な接続により、コードの一部は交換可能になりました。 レンダラーとゲームコードは、Quake2のコアを変更せずに切り替えることができるモジュールになりました。 したがって、関数ポインターを含む2つの構造を使用して、ポリモーフィズムが実現されました。
これらの2つの変更により、コードベースが非常にエレガントになり、コードエントロピーに苦しむQuake 1よりも読みやすくなりました。
実装の観点から、DLLプロジェクトは、レンダラー用の
GetRefAPIメソッドとゲーム用の
GetGameAPIを1つだけ公開する必要があります(「リソースファイル」フォルダーの
GetGameAPIファイルを参照)。
reg_gl/Resource Files/reg_soft.def EXPORTS GetGameAPI
カーネルがモジュールをロードする必要がある場合、DLLをプロセススペースにロードし、
GetProcAddressで
GetRefAPIアドレスを取得し、必要な関数ポインターを取得します。それだけです。
興味深い事実:ローカルゲームでは、クライアントとサーバー間の通信はソケットを介して実行されません。 代わりに、コマンドは、コードのクライアント部分で
NET_SendLoopPacketを使用してループバックバッファーにスローされます。 サーバーは
NET_GetLoopPacketを使用して同じバッファーからコマンドを再構築します。
偶然の事実:この写真を見た
ことがあるなら、おそらくジョン・カーマックが1996年頃に巨大なディスプレイに何を使っていたのか疑問に思うでしょう。
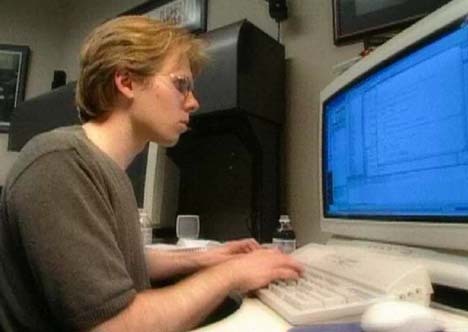
Intergraphが製造した28インチのInterView 28hd96モニターでした。 この獣は、最大1920x1080の解像度を提供しました。これは1995年には非常に印象的です(詳細については、
こちら (
ミラー )を参照してください)。

ノスタルジックなYoutubeビデオ:
Intergraph Computer Systems Workstations 。
追加:この記事は、
「John Carmackが1995年に28インチ16:9 1080pモニターでQuakeを作成した」という記事(
mirror )を書いたため、geek.comの誰かに刺激を与えたようです。
更新: Doom 3の開発時に、ジョンカーマックがこのモニターをまだ使用していたようです。
可視化
ソフトウェアレンダラー(
ref_soft )およびハードウェアアクセラレータレンダラー(
ref_soft )
ref_glは非常に大きいため、それらについて個別のセクションを作成しました。
繰り返しになりますが、カーネルはどのレンダラーが接続されているかさえ知らなかったことは注目に値します。それは単に構造内で関数ポインターを呼び出しただけです。 つまり、視覚化パイプラインは完全に抽象化されました。このC ++が必要なのはだれですか。
興味深い事実: id Softwareは、1992年のWolfenstein 3Dゲームの座標系を使用しています(少なくともDoom3の場合はそうでした)。 これは、レンダラーのソースコードを読み取るときに知っておくことが重要です。
idシステムでは:OpenGL座標系の場合:そのため、OpenGLレンダラーは
GL_MODELVIEWマトリックスを使用して、
R_SetupGLメソッド(
glLoadIdentity +
glRotatef )を使用して各フレームの座標系を「修正」します。
動的な接続
カーネル/モジュールの相互作用については多くのことが言えます。動的接続に関する別のセクションを書きました。
改造:gamex86.dll
プロジェクトのこの部分を読むことはそれほど面白くないことが判明しましたが、コンパイルされたモジュールのQuake-Cを終了すると、2つの良い結果と1つの非常に悪い結果につながりました。
悪い点:- 移植性は犠牲になります。ゲームモジュールは、特定のリンカーパラメーターを使用して異なるプラットフォーム用に再コンパイルする必要があります。
良い:- 速度:Quake1のゲーム言語Quake1はコードを解釈しましたが、動的ライブラリモジュールQuake2
gamex86.dllはネイティブです。 - 自由:改造者は、Quake-Cで利用可能なものだけでなく、すべてにアクセスできました。
興味深い事実: id Softwareがゲーム、人工知能、改造に仮想マシン(QVM)を使用するようにQuake3に切り替えた
ことは皮肉です。
私の地震2
ハッキングプロセス中に、Quake2のソースコードをわずかに変更しました。 Quakeコンソールを学習するためにゲームを一時停止するのではなく、プロセスで
printf出力を見るためにDOSコンソールを追加することを強くお勧めします。
DOSスタイルのコンソールをWin32ウィンドウに追加するのは非常に簡単です。
Parallelsを使用してMacでWindowsを実行していたため、ゲームの実行中に「printscreen」を押すことは困難でした。 スクリーンショットを作成するには、デジタルブロックから「*」キーを設定します。
そして最後に、多くのコメントと図を追加しました。 「私の」完全なソースコードを次に示します。
アーカイブメモリ管理
DoomとQuake1には、「Zone Memory Allocation」と呼ばれる独自のメモリマネージャがありました。起動時に、
malloc実行され、メモリブロックはポインタのリストを使用して制御されました。 メモリゾーンをマークして、目的のメモリカテゴリをすばやく消去できます。 ゾーンメモリアロケータ(
common.c: Z_Malloc, Z_Free, Z_TagMalloc , Z_FreeTags )はQuake2に残っていましたが、ほとんど役に立ちません:
- タグは使用されず、メモリ割り当て/割り当て解除は
mallocおよびfreeで実行されます(id Softwareがこの作業をC標準ライブラリに委ねることを決めた理由はわかりません)。 - オーバーフロー検出器(定数
Z_MAGICを使用)も使用されることはありません
各メモリブロックが割り当てられる前に挿入されたヘッダーの
size属性により、メモリ消費を測定することは依然として非常に便利です。
#define Z_MAGIC 0x1d1d typedef struct zhead_s { struct zhead_s *prev, *next; short magic; short tag;
サーフェスキャッシュシステムには独自のメモリマネージャーがあります。 分散メモリの量は解像度に依存し、奇妙な式によって決定されますが、ガベージから非常に効果的に保護します:
malloc : ============================== size = SURFCACHE_SIZE_AT_320X240;

「ハンクアロケーター」は、リソース(画像、サウンド、およびテクスチャ)を読み込むために使用されます。 彼は、
virtualAllocを使用してデータをページサイズ(8 KB、Win98では4 KBが使用されていたにもかかわらず?!
最後に、多くのFIFOスタックもあります
(とりわけ、間隔を保存するため) 。機能が明らかに制限されているにもかかわらず、非常にうまく機能します。
メモリ管理:注文の秘rick
Quake2は多くの通常のポインターを管理するため、32ビット(またはWindows 98が4 KBページを使用していてもPAGE_FAULTを最小化するために8 KB)にポインターを配置するのに良いトリックが使用されます。
ページレイアウト(8KB): int roundUpToPageSize(int size) { size = (size + 8191) & ~8191; return size; }
メモリ位置(4 B): memLoc = (memLoc + 3) & ~3;
コンソールサブシステム
Quake2カーネルには、インデックスリストと線形検索を広範囲に使用する強力なコンソールシステムが含まれています。
次の3種類のオブジェクトがあります。
- コマンド:指定された文字列値に関数ポインタを与えます。
- Cvar:指定された文字列名の文字列値を保存します。
- エイリアス:指定された文字列値の置換を提供します。
コードの観点から見ると、オブジェクトの各タイプにはポインターのリストがあります。
cmd_function_t *cmd_functions
各行がコンソールに入力されると、スキャンされ、補足され(エイリアスと対応するcvarを使用)、次に2つのグローバル変数
cmd_argcと
cmd_argv格納されたトークンに分割されます。
static int cmd_argc; static char *cmd_argv[MAX_STRING_TOKENS];
例:

バッファー内で識別された各トークンは、
memcpyによって、
cmd_argvして
mallocで示される場所にコピーされます。 このプロセスはかなり非効率的であり、このサブシステムにほとんど注意が払われていないことを示しています。 ちなみに、これは完全に正当化されています。めったに使用されず、ゲームにほとんど影響を与えないため、最適化は努力する価値がありませんでした。 より適切な方法は、ソース文字列にパッチを適用し、各トークンのポインター値を書き込むことです。

トークンは引数の配列内にあるため、
cmd_argv[0] 、関数ポインターのリストで宣言されているすべての関数に準拠するために、非常に低速で線形にチェックされます。 一致が見つかった場合、関数ポインターが呼び出されます。
一致するものがない場合は、エイリアスポインターのリストが線形的にチェックされ、トークンが関数呼び出しであるかどうかが判断されます。 エイリアスが関数呼び出しを置き換える場合、呼び出されます。
最後に、上記のいずれも機能しない場合、Quake2はトークンを変数宣言として(または変数が既にポインターのリストにある場合は更新として)扱います。
ここでは、ポインターのリストで多くの線形検索が行われます。ハッシュテーブルを使用することが理想的です。 O(n²)ではなくO(n)の複雑さを実現できます。
構文解析に関する興味深い事実1 : ASCIIテーブルはスマートに編成されています。文字列を解析してトークンを作成する場合、セパレーターとスペース文字をスキップできます。
char* returnNextToken(char* string) { while (string && *string < ' ') string++; return string; }
解析2に関する興味深い事実 : ASCIIテーブルは非常に巧妙に構成されています。次のように文字cを整数に変換できます。
int値= c-'0';
int charToInt(char v) { return v - '0' ; }
cvar値のキャッシュ:このシステムのメモリ内のcvarの場所(
Cvar_Get )がO(n²)(線形検索+各レコードのstrcmp)であるため、レンダラーはメモリ内のcvarの場所をキャッシュします。
この値へのアクセスは、O(1)で取得できます。
悪役に対する保護
不正行為から保護するために、いくつかのメカニズムが挿入されました。
- UDPには独自のCRCがありますが、Quake CRC(
COM_BlockSequenceCRCByte )が各パケットに追加され、変更から保護されます。 - 試合開始前に、レベルはMD4を使用してハッシュされます。 このハッシュはサーバーに送信され、クライアントが変更されたカード(
Com_BlockChecksumM )を使用しないようにします。 - 各プレイヤーからの1秒あたりのチーム数(
SV_ClientThink )をチェックするシステムもありますが、それがどれほど効果的だったかは正確にはわかりません。
内部アセンブラー
Quakeのすべてのバージョンと同様に、有用な関数の一部はアセンブラーを使用して最適化されました(ただし、Quake3にあった有名な「高速平方根逆関数」の痕跡はまだありません)。
32ビット浮動小数点数の高速絶対値 (今日ほとんどのコンパイラーはこれを自動的に行います):
float Q_fabs (float f) { int tmp = * ( int * ) &f; tmp &= 0x7FFFFFFF; return * ( float * ) &tmp; }
フロートから整数への高速変換 __declspec( naked ) long Q_ftol( float f ) { static int tmp; __asm fld dword ptr [esp+4] __asm fistp tmp __asm mov eax, tmp __asm ret }
コード統計
Clocのコードを分析すると、コードには138,240行あることがわかりました。 いつものように、多くのことがエンジンバージョンの反復サイクルで見捨てられたため、この数字は投資された努力のアイデアを提供しませんが、私には思えるが、これはエンジンの全体的な複雑さの良い指標です。
$ cloc quake2-3.21/ 338 text files. 319 unique files. 34 files ignored. http:
注:すべてのアセンブラーコードは、手動で作成されたソフトウェアレンダラー用です。
推奨されるQuake2ハッキングツール
- Visual Studio Express 2008。
- idウェブサイトからの無料のQuake2デモ。
- 私が書いた朴探検家 。
- Wally :WAL画像形式ビューア。
- 有名な朴研究ツール( PakExpl )
- FlipCode WebサイトからのBSP形式 ( ミラー ) に関する記事 。
- プロファイラーC:VTune(Intel)、CodeAnalysis(AMD)、Visual Studio Team Profiler(私の意見では最高)。
- 24/30インチの大型スクリーン。
- キーボードIBMモデルM
Quake2は、1つのコアと、実行時にロードされる2つのモジュール(ゲームとレンダラー)で構成されます。 ポリモーフィズムのおかげで、何でもコアに接続できることが非常に興味深いです。
読み続ける前に、この
すばらしい記事 (
ミラー )を使用して仮想メモリの原理を理解していることを確認することをお勧めします。
動的接続を伴うCの多態性
動的接続には多くの利点があります。
- レンダラー:
- 純粋なQuake2カーネルコード、コードエントロピーの削減、どこにも狂った
#ifdefはありません。 - 複数のレンダラー(ソフトウェア、openGL)を使用したゲームのリリース。
- レンダラーはゲーム中に変更できます。
- ゲームのリリース後に作成された機器(Glide、Verity)の新しいレンダラーを作成する機能。
- 改造ゲーム:
- mod作成者向けのその他の機能、game.dllを使用してゲームを完全に変更できます。
- Modでの完全なゲームスピード。QuakeCおよびQuake Virtual Machineに依存する必要はありません。
- QuakeCを学ぶ必要はありません。DLLはCで作成されています。
しかし、Quake2はオブジェクト指向プログラミング言語ではないCで書かれていたため、「OOではない言語でポリモーフィズムを実装する方法は?」という疑問が生じました。
OOシミュレーション手法は、JAVAおよびC ++で使用される方法に似ています:関数ポインターを含む構造を使用します。
したがって、4つの構造体が関数ポインターを交換するために使用されました:
refimport_tおよび
refexport_tは、レンダラーモジュールをロードするときに関数ポインターを交換するためのコンテナーとして機能しました。
game_import_tおよび
game_export_t 、ゲームモジュールのロード時
game_export_t使用されました。
長い説明よりも小さなイラストの方が良い
ステップ1:初期段階:
quake2.exeは、関数ポインタがNULL (灰色)の構造quake2.exeが含まれていNULL 。- DLLモジュール(
ref_opengl.dll )には、 NULL (灰色)への関数ポインターを持つkernel_fct_t構造体も含まれていNULL 。
プロセスのタスクは、各部分が他を呼び出すことができるように、関数のアドレスを渡すことです。

ステップ2:関数を呼び出すカーネルは、独自の関数へのポインターを含む構造体を埋め、これらのDLL値を送信します。

ステップ3:受信DLLは、カーネル関数ポインターをコピーし、独自の関数アドレスを含む構造体を返します。

実名を使用したプロセスについては、次の2つのセクションで詳しく説明します。
レンダラーライブラリ
レンダラーモジュールを受け取るメソッドは
VID_LoadRefreshと呼ばれ
VID_LoadRefresh 。 Quakeがレンダラーを切り替えることができるように、すべてのフレームと呼ばれます(ただし、レンダラーが必要とする前処理のため、レベルを再起動する必要があります)。
Quake2カーネル側で何が起こるかを次に示します。
refexport_t re; qboolean VID_LoadRefresh( char *name ) { refimport_t ri; GetRefAPI_t GetRefAPI; ri.Sys_Error = VID_Error; ri.FS_LoadFile = FS_LoadFile; ri.FS_FreeFile = FS_FreeFile; ri.FS_Gamedir = FS_Gamedir; ri.Cvar_Get = Cvar_Get; ri.Cvar_Set = Cvar_Set; ri.Vid_GetModeInfo = VID_GetModeInfo; ri.Vid_MenuInit = VID_MenuInit; ri.Vid_NewWindow = VID_NewWindow; GetRefAPI = (void *) GetProcAddress( reflib_library, "GetRefAPI" ); re = GetRefAPI( ri ); ... }
上記のコードでは、Quake2カーネルは(ビルトインwin32メソッド)GetRefAPIを使用してレンダラーDLLからメソッド関数ポインターを取得しますGetProcAddress。それは中に何が起こるかだGetRefAPI内部のDLLレンダラ: refexport_t GetRefAPI (refimport_t rimp ) { refexport_t re; ri = rimp; re.api_version = API_VERSION; re.BeginRegistration = R_BeginRegistration; re.RegisterModel = R_RegisterModel; re.RegisterSkin = R_RegisterSkin; re.EndRegistration = R_EndRegistration; re.RenderFrame = R_RenderFrame; re.DrawPic = Draw_Pic; re.DrawChar = Draw_Char; re.Init = R_Init; re.Shutdown = R_Shutdown; re.BeginFrame = R_BeginFrame; re.EndFrame = GLimp_EndFrame; re.AppActivate = GLimp_AppActivate; return re; }
最後に、カーネルとDLLの間で双方向のデータ交換が確立されます。レンダラーDLLは構造内の独自の関数アドレスを返し、Quake2カーネルは違いを認識せず、常に同じ関数ポインターを呼び出すため、これはポリモーフィックです。ゲームライブラリ
カーネル側のゲームライブラリでもまったく同じプロセスが実行されます。 game_export_t *ge; void SV_InitGameProgs (void) { game_import_t import; import.linkentity = SV_LinkEdict; import.unlinkentity = SV_UnlinkEdict; import.BoxEdicts = SV_AreaEdicts; import.trace = SV_Trace; import.pointcontents = SV_PointContents; import.setmodel = PF_setmodel; import.inPVS = PF_inPVS; import.inPHS = PF_inPHS; import.Pmove = Pmove;
ゲームDLL側で行われることは次のとおりです。 game_import_t gi; game_export_t *GetGameAPI (game_import_t *import) { gi = *import; globals.apiversion = GAME_API_VERSION; globals.Init = InitGame; globals.Shutdown = ShutdownGame; globals.SpawnEntities = SpawnEntities; globals.WriteGame = WriteGame; globals.ReadGame = ReadGame; globals.WriteLevel = WriteLevel; globals.ReadLevel = ReadLevel; globals.ClientThink = ClientThink; globals.ClientConnect = ClientConnect; globals.ClientDisconnect = ClientDisconnect; globals.ClientBegin = ClientBegin; globals.RunFrame = G_RunFrame; globals.ServerCommand = ServerCommand; globals.edict_size = sizeof(edict_t); return &globals; }
関数ポインターを使用する
メソッドポインターを渡すと、ポリモーフィズムが有効になります。ここで、コードでは、カーネルは異なるモジュールに「ジャンプ」します。レンダラーは「にジャンプ」しSCR_UpdateScreenます:
ゲームは「ジャンプ」しSV_RunGameFrameます: void SV_RunGameFrame (void) { sv.framenum++; sv.time = sv.framenum*100;
ソフトウェアレンダラー
Quake2ソフトウェアレンダラーは、最大かつ最も複雑なため、研究にとって最も興味深いモジュールです。 ディスクから始まりピクセルで終わる隠れたメカニズムはありません。すべてのコードはきちんと手作業で最適化されています。彼は彼の種類の最後であり、時代の終わりをマークしました。その後、業界は完全にハードウェアアクセラレーションを使用したレンダリングのみに切り替えました。OpenGLソフトウェアレンダリングとレンダリングの基本的な違いは、今日の通常の24ビットTrue Color RGBシステムの代わりに256色パレットシステムを使用していることです。
ディスクから始まりピクセルで終わる隠れたメカニズムはありません。すべてのコードはきちんと手作業で最適化されています。彼は彼の種類の最後であり、時代の終わりをマークしました。その後、業界は完全にハードウェアアクセラレーションを使用したレンダリングのみに切り替えました。OpenGLソフトウェアレンダリングとレンダリングの基本的な違いは、今日の通常の24ビットTrue Color RGBシステムの代わりに256色パレットシステムを使用していることです。 レンダラーとハードウェアアクセラレーションおよびソフトウェアレンダラーを比較すると、最も明白な2つの違いに気付きます。しかし、これを除いて、エンジンはパレットを非常に巧妙に使用して驚くべき仕事をすることができました。これについては後で説明します。
レンダラーとハードウェアアクセラレーションおよびソフトウェアレンダラーを比較すると、最も明白な2つの違いに気付きます。しかし、これを除いて、エンジンはパレットを非常に巧妙に使用して驚くべき仕事をすることができました。これについては後で説明します。- カラーグラデーションのクイック選択(64値)。
- ポストエフェクトのフルスクリーンカラーミキシング。
- ピクセルごとの半透明性。
まず、Quake2パレットがPAKアーカイブファイルからロードされますpics/colormap.pcx。 注:黒の値は0、白は15、緑は208、赤は240(左下隅)、透明は255です。最初のことは、これらに従って256色を再配置することです
注:黒の値は0、白は15、緑は208、赤は240(左下隅)、透明は255です。最初のことは、これらに従って256色を再配置することですpics/colormap.pcx: この256x320スキームはルックアップテーブルとして使用され、多くの興味深い機能を提供するため、異常にスマートです。
この256x320スキームはルックアップテーブルとして使用され、多くの興味深い機能を提供するため、異常にスマートです。- 64 : 256 «» . 63 , 255 . :
- [0,255] ( ).
- x*256, x [0,63] ( ).
64 256 . 256 . 素晴らしい。 - 画像の残りの部分は16x16の正方形から作成されるため、パレットに基づいてピクセルブレンディングを使用できます。すべての正方形がソース色、最終色、および中間色から作成されていることがはっきりとわかります。これが、ゲームで水の透明性を実現する方法です。たとえば、左上の正方形に黒と白が混在しています。
興味深い事実: Quake2ソフトウェアレンダラーは、当初MMXテクノロジーのおかげで、このビデオでのQuake1のリリース後にジョンカーマックが言った、パレットではなくRGBに基づいているはずでした(10分17秒):MMXはSIMDテクノロジーであり、1つのチャンネルのコストで3つのRGBチャンネルすべてを操作できるため、許容可能なCPU消費でミキシングを提供できます。次の理由で放棄されたと思います。- Pentium MMX 1997 , .
- RGB (16 32 ) (8 ) , .
主な制限(パレット)を決定したら、レンダラーの一般的なアーキテクチャに移動できます。彼の哲学は、Pentiumの長所(浮動小数点計算)を使用して、弱点の影響を軽減しました。つまり、メモリへのピクセルの書き込みに影響を与えるバスの速度です。レンダリングパスのほとんどは、ゼロの再描画を実現することに焦点を当てています。本質的に、ソフトウェアレンダリングパスはQuake 1ソフトウェアレンダリング方法に似ています。その中で、BSPとPVS(表示される可能性のあるポリゴンのセット)を積極的に使用して、マップをバイパスし、レンダリングする必要のあるポリゴンのセットを取得しました。各フレームは、3つの異なる要素をレンダリングします。- マップ:BSPに基づいたコヒーレントな行ごとの画像構築のアルゴリズムの助けを借りて(詳細は後ほど)。
- エンティティ:「スプライト」(ウィンドウ)として、または「オブジェクト」(プレイヤー、敵)として、行ごとのイメージを構築するための簡単なアルゴリズムを使用します。
- 粒子。
注:これらの「古い」アルゴリズムに慣れていない場合は、コンピューターグラフィックスの原則 3.6および15.6のJames D. Foleyの章を読むことを強くお勧めします。Michael Abrashのグラフィックスプログラミングブラックブックの 59〜70 章にも多くの情報があります。高レベルの擬似コードは次のとおりです。- 地図のレンダリング
- 前処理されたBSPツリーをウォークスルーして、現在のクラスターを特定します。
- この特定のクラスターについてPVSデータベースを照会します:PVSを取得および解凍します。
- PVS: , , .
- BSP. , - . , .
- :
- , Z- .
- .
- .
- ( ).
画面の視覚化:パレットインデックスはオフスクリーンバッファに書き込まれます。モード(フルスクリーン/ウィンドウ)に応じて、DirectDrawまたはGDIが使用されます。フレームごとのフレームバッファーが完了すると、またはのいずれかを使用して、ビデオカードスクリーンバッファー(GDI =>rw_dib.cDirectDraw =>rw_ddraw.c)に転送されます。BitBlt WinGDI.hBltFast ddraw.hDirectDrawまたはGDI
プログラマーが1997年に直面しなければならなかったこれらの問題は、単に憂鬱なものでした。ジョンカーマックは、ソースコードに面白いコメントを残しました。
Quake2がDirectDrawを使用してフルスクリーンモードで動作する場合、オフスクリーンバッファーを上から下に描画する必要がありました。これがスクリーン上に表示される方法です。しかし、GDIを使用してウィンドウモードで実行された場合、ビデオカードメーカーのほとんどのドライバーが反射モードでRAMからビデオメモリにDIBイメージを転送したため、DIBバッファーにオフスクリーンバッファーを垂直に反映する必要がありました(本当に質問する価値はありますか?略語では、GDIは「独立」を表します)。したがって、フレームごとのバッファを介した遷移は抽象的であると想定されていました。必要なのは、これらの違いから抽象化するために異なる方法で初期化された構造と値です。これは、Cでポリモーフィズムを実装する原始的な方法です。 typedef struct { pixel_t *buffer;
フレームバッファーの描画に必要な方法に応じてvid.buffer、最初のピクセルとして初期化されました。- directdrawの最初の行
- WinGDI / DBIの最後の行
上下に移動するには、またはvid.rowbytesとして初期化しvid.widthます-vid.width。
 トランジションでは、レンダリングがどのように実行されるかは問題ではありません。通常の反射でも垂直反射でも:
トランジションでは、レンダリングがどのように実行されるかは問題ではありません。通常の反射でも垂直反射でも:
このトリックにより、視覚化パイプラインは、下位レベルでの転送の実行方法について心配する必要がなくなり、これは非常に注目に値すると思います。カードの前処理
コードをさらに掘り下げる前に、マップの前処理中に生成される2つの重要なデータベースを理解する必要があります。- バイナリ空間分割(BSP)/潜在的に可視のポリゴンセット(PVS)。
- 放射線ベースの照明マップのテクスチャ。
BSP切断、PVS生成
バイナリ空間パーティションのより深い研究をお勧めします:Quake1と同様に、Quake2カードは深刻な予備処理を受けます。そのボリュームは、下図のように再帰的にカットされます。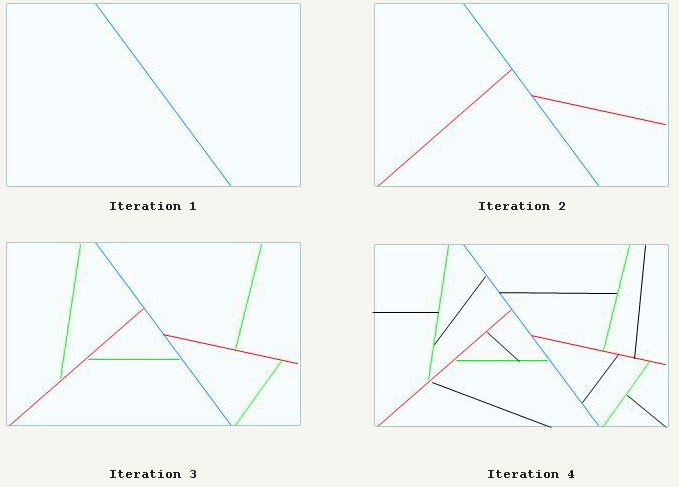 最終的に、マップは完全に凸3Dスペース(クラスターと呼ばれる)にカットされます。DoakeとQuake1のように、これらを使用してすべてのポリゴンを前面から背面、背面から前面に並べ替えることができます。すばらしい追加は、ビットベクトルのセット(クラスターごとに1つ)であるPVSです。任意のクラスターから表示される可能性のあるクラスターを照会および取得できるデータベースと考えてください。このデータベースは巨大(5 MB)ですが、効果的に数百キロバイトに圧縮され、RAMに収まります。注: PVS圧縮では、0x00の値のみを渡す圧縮が使用されます。このプロセスについては以下で説明します。
最終的に、マップは完全に凸3Dスペース(クラスターと呼ばれる)にカットされます。DoakeとQuake1のように、これらを使用してすべてのポリゴンを前面から背面、背面から前面に並べ替えることができます。すばらしい追加は、ビットベクトルのセット(クラスターごとに1つ)であるPVSです。任意のクラスターから表示される可能性のあるクラスターを照会および取得できるデータベースと考えてください。このデータベースは巨大(5 MB)ですが、効果的に数百キロバイトに圧縮され、RAMに収まります。注: PVS圧縮では、0x00の値のみを渡す圧縮が使用されます。このプロセスについては以下で説明します。放射線
Quake1と同様に、レベル照明の効果は事前に計算され、照明マップと呼ばれるテクスチャに保存されます。ただし、Quake1とは異なり、Quake2は予備計算で放射と色照明を使用します。その後、照明マップはアーカイブに保存PAKされ、ゲーム中に使用されます。作成者の1人からの2、3の言葉:「プログラミングのブラックブック」のマイケルアブラッシュ(「Quake:事後分析と未来への展望」の章):グラフィックに対する最も興味深い変更は予備的な計算にあり、そこではジョンが放射光のサポートを追加しました...
Quake 2レベルの処理には最大1時間かかりました。
(ただし、BSPの作成、PVSおよび放射光の計算が含まれていることは注目に値します。これについては後で説明します。)
放射照明について知りたい場合は、この驚くほどよく説明されている記事(ミラー)を読んでください。これは単なる傑作です。放射線テクスチャーを重ね合わせた最初のレベルは次のとおりです。残念なことに、ソフトウェアレンダラーのグレースケールで見事なRGBカラーをサンプリングする必要がありました(詳細は後ほど)。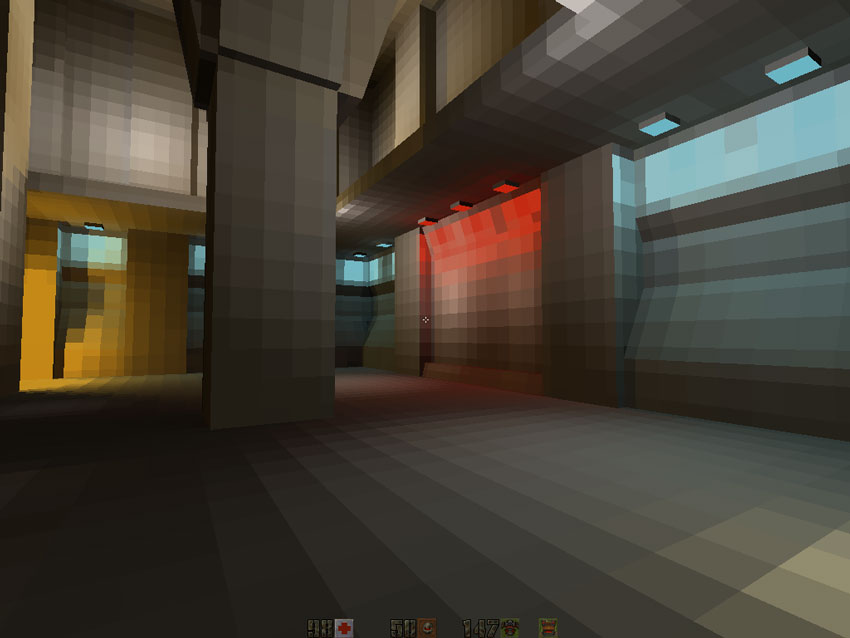 ライティングマップの低解像度はここでは驚くべきものですが、バイリニアフィルタリング(ソフトウェアレンダラーでも)が行われるため、最終結果はカラーテクスチャと非常に良好です。興味深い事実:照明マップは、2x2から17x17の任意のサイズにすることができます(フリップコードの記事で宣言されている最大サイズの16にもかかわらず(ミラー ))そして正方形である必要はありません。
ライティングマップの低解像度はここでは驚くべきものですが、バイリニアフィルタリング(ソフトウェアレンダラーでも)が行われるため、最終結果はカラーテクスチャと非常に良好です。興味深い事実:照明マップは、2x2から17x17の任意のサイズにすることができます(フリップコードの記事で宣言されている最大サイズの16にもかかわらず(ミラー ))そして正方形である必要はありません。コードアーキテクチャ
ほとんどのソフトウェアレンダラーコードはメソッドにありR_RenderFrameます。ここに簡単な説明がありますが、より詳細な分析は私の予備ノートにあります。R_SetupFrame:BSPをバイパスして現在の視点を取得し(呼び出しMod_PointInLeaf)、視点のclusterIDをに保存しr_viewclusterます。R_MarkLeaves:現在のブラウズクラスター(r_viewcluster)がPVSを受信して解凍します。PVSを使用して、目に見える顔をマークします。R_PushDlights:BSPを再度使用して、面を前面から背面に移動します。顔が可視としてマークされている場合、ライトがその顔に影響を与えるかどうかを確認します。R_EdgeDrawing :レベルの視覚化。
R_RenderWorld :前面から背面へのBSPバイパス
- 表示されているすべてのポリゴンをスクリーンスペースに投影する:グローバルエッジテーブルを構築します。
- ( ).
R_ScanEdges : , . :
R_InsertNewEdges : , .(*pdrawfunc)() : , . . .D_DrawSurfaces : , .
R_DrawEntitiesOnList : , BModel (BModel — ). (, , )...R_DrawAlphaSurfaces :R_CalcPalette :ポストエフェクトの計算、たとえば、色の混合(損傷を受けたとき、アイテムを拾ったときなど)
R_RenderFrame { R_SetupFrame
R_SetupFrame:BSPコントロール
バイナリスペースパーティションツリートラバーサルは、コード全体で実行されます。これは、安定した速度の強力なメカニズムであり、ポリゴンを前面から背面または背面から前面に並べ替えることができます。それを理解するには、構造を理解する必要がありますcplane_t: typedef struct cplane_s { vec3_t normal; float dist; } cplane_t;
ノードの割線平面からの距離またはポイントを計算するには、その座標を平面の方程式に挿入するだけです。 int d = DotProduct (p,plane->normal) - plane->dist;
サインのおかげでd、飛行機の前にいるのか後ろにいるのかがわかり、並べ替えができます。このプロセスは、DoomからQuake3までのエンジンで使用されています。R_MarkLeaves:PVSバルク解凍
Quake 1ソースコードの分析で PVSの解凍を理解する方法は完全に間違っていました。エンコードされるのはビット1間の距離ではなく、0x00に書き込まれたバイト数だけです。PVSでは、グループ圧縮0x00のみが実行されます:圧縮ストリームの読み取り時:- 圧縮されたPVSからゼロ以外のバイトが読み取られると、解凍されたバージョンに書き込まれます。
- バイト0x00が圧縮PVSから読み取られる場合、次のバイトはスキップするバイト数を示します。
最初のケースでは、何も圧縮されません。グループ圧縮は、2番目の場合にのみ実行されます。 byte *Mod_DecompressVis (byte *in, model_t *model) { static byte decompressed[MAX_MAP_LEAFS/8];
必要に応じて、最大255バイト(255 * 8リーフ)までスキップできます。その後、次の255バイトのためにスキップする数値でゼロを再度追加する必要があります。つまり、511バイト(511 * 8リーフ)のパスには4バイトが必要です:0-255-0-255例:
現在のクラスターのPVSを解凍すると、PVSで表示されていると見なされるクラスターに属する個々の顔も表示されます:Q:i解凍されたPVSを使用して特定の識別子を持つクラスターの表示を確認するにはどうすればよいですか?O:バイトi / 8 PVSと1 <<(i%8)の間のビットAND char isVisible(byte* pvs, int i) {
Quake1の場合と同様に、ポリゴンを可視としてマークするために使用する優れたトリックがあります。フラグを使用して各フレームの開始時にそれらをリセットする代わりに、適用されintます。各フレームの開始時に、フレームカウンターはr_visframecount1ずつ増加しR_MarkLeavesます。PVSを解凍した後、visframe現在の値をフィールドに割り当てることにより、すべてのゾーンが可視としてマークされますr_visframecount。コードの後半で、ノード/クラスターの可視性は常に次の方法でチェックされます。 if (node->visframe == r_visframecount) {
R_PushDlights:動的照明
アクティブな動的光源の各lightIDについて、BSPは光源の位置から再帰的に走査されます。光源とクラスター間の距離が計算され、光の強度がクラスターからの距離よりも大きい場合、クラスター内のすべてのサーフェスがこの光源識別子の影響を受けるとマークされます。注:サーフェスには2つのフィールドがマークされています。dlightframe-これは、intクラスターの可視性をマークする場合と同じ方法で使用されるフラグです(各フレームのすべてのフラグをリセットする代わりに、グローバル変数が増加しr_dlightframecountます。ライトが動作するためにr_dlightframecountは、等しくなければなりませんsurf.dlightframe。dlightbitsintこの面に影響を与える光源のさまざまな配列のインデックスを格納するために使用されるビットベクトルです。
R_EdgeDrawing:レベルの視覚化
R_EdgeDrawing-これはソフトウェアレンダラーのモンスターであり、最も理解しにくいものです。それに対処するには、メインのデータ構造を見る必要があります:スタックsurf_t(プロキシとして動作m_surface_t)はCPUスタックに配置されます。
このスタックは、BSPを前面から背面へ移動するときに読み込まれます。表示されている各ポリゴンは、プロキシサーフェスとしてスタックにプッシュされます。後で、アクティブなエッジのテーブルを回って画面の行を生成するときに、メモリ内のアドレスを比較するだけで、他のすべてのポリゴンの前にあるポリゴンを非常にすばやく確認できます(スタックが低いほど、視点に近い)。これが、ラインごとの画像構築の変換アルゴリズムに「接続性」を実装する方法です。注:スタックの各要素には、インターバルバッファスタックの要素を指すポインターのリスト(テクスチャチェーンと呼ばれる)もあります(以下で説明します)。間隔はバッファに格納され、テクスチャチェーンから描画されて間隔をテクスチャグループ化し、CPUプリキャッシュバッファを最大化します。スタックは最初に初期化されますR_EdgeDrawing: void R_EdgeDrawing (void) {
詳細は次のとおりです。R_BeginEdgeFrame :最後のフレームからグローバルエッジテーブルをクリアします。R_RenderWorld :BSPバイパス(画面には何も表示しないことに注意してください):
- 可視と見なされる各表面は、プロキシスタックにプッシュされます
surf_t。 - すべてのポリゴンの頂点をスクリーンスペースに投影し、グローバルエッジテーブルに入力します。
- また、すべての頂点に対して1 / Z値を生成して、間隔でZバッファーを生成できるようにします。
R_DrawBEntitiesOnList :このフラグメントが何をするのか分かりません。R_ScanEdges :レベルレンダリング用に現在受信しているすべての情報を結合します。
- アクティブなエッジのテーブルの初期化。
- 間隔バッファー(スタック)の初期化:

- 画面の上部から下部への画像のプログレッシブ構築のアルゴリズムを起動します。
- 行ごとに:
- グローバルエッジテーブルからアクティブエッジのテーブルを更新します。
- 行全体のアクティブエッジのテーブルを実行する:
- サーフェススタック内のアドレスを使用して可視ポリゴンを定義します。
- 間隔を間隔バッファーに渡す。
- 間隔バッファーがいっぱいの場合:すべての間隔を描画し、間隔スタックをリセットします。
- バッファ内の残りの間隔を確認します。何かが残っている場合:すべての間隔を描画し、間隔スタックをリセットします。
ビデオ作品R_EdgeDrawing
以下のビデオでは、エンジンは1024x768の解像度で動作します。また、特殊なcvarを使用すると速度が低下しますsw_drawflat 1。これにより、テクスチャなしで多角形を異なる色でレンダリングできます。このビデオでは、多くの興味深いことがわかります。- 画面は上から下に生成されます。これはプログレッシブイメージングの一般的なアルゴリズムです。
- , . Pentium: textureId , « ». . , .
- , .
- , : , .
- 40% , 10%. , , .
- OMG, .
:
:、6ビットグレースケール(R、G、Bの明るいチャネルに1つ)を再サンプリングする制約パレットを満たすために必要残念ながら、美しい24ビットの点灯カードRGBアーカイブに保存されているものPAK(24ビット)と負荷後ディスクと最大6ビットのリサンプリング: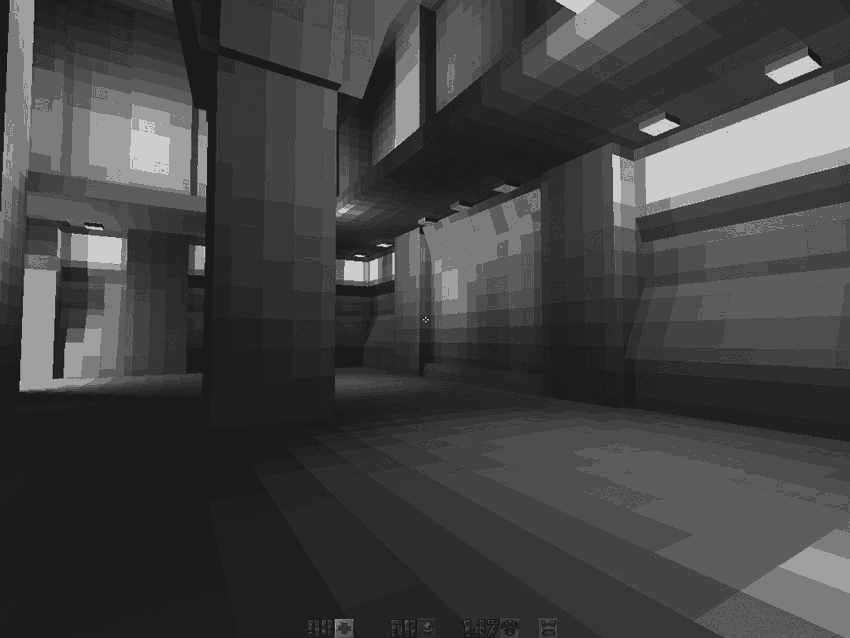 そして、すべて一緒に:顔のテクスチャは[0.255]の範囲の色を与えます。この値は、パレットの色のインデックスを作成します
そして、すべて一緒に:顔のテクスチャは[0.255]の範囲の色を与えます。この値は、パレットの色のインデックスを作成しますpics/colormap.pcx。 照明マップはフィルターされます。その結果、範囲[0.63]の値を取得します。
照明マップはフィルターされます。その結果、範囲[0.63]の値を取得します。 これで、
これで、pics/colormap.pcxエンジンは上部を使用して、パレットの希望の位置を選択できます。最終結果を取得するために、彼はテクスチャの入力値をX座標として使用し、イルミネーション* 63をY座標として使用します 。
。 個人的には、最高だと思います:256色の64のグラデーションを模倣して...合計256色!
個人的には、最高だと思います:256色の64のグラデーションを模倣して...合計256色!表面サブシステム
前のスクリーンショットから、サーフェス生成がCPUにとってQuake2の最も要求の厳しい部分であることが明らかです(これは、以下のプロファイラーの結果によって確認されます)。速度とメモリ消費に関して許容できるサーフェス生成は、次の2つのメカニズムによって提供されます。- MIPテクスチャリング(ミップマッピング)
- キャッシング
Surfaceサブシステム:MIPテクスチャリング
ポリゴンをスクリーン空間に投影すると、その距離の1 / Zが生成されます。最も近い頂点は、使用するMIPテクスチャのレベルを決定するために使用されます。ライティングマップの例と、MIPテクスチャのレベルに応じてフィルタリングされる方法の例を示します。
 ランダムイメージでのQuake2バイリニアフィルタリングの品質をテストするために取り組んだミニプロジェクト:archiveです。以下は、13x15テクセル照明マップに対して実行されたテストの結果です。
ランダムイメージでのQuake2バイリニアフィルタリングの品質をテストするために取り組んだミニプロジェクト:archiveです。以下は、13x15テクセル照明マップに対して実行されたテストの結果です。 レベル3 MIPテクスチャ:ブロックは2x2テクセルです。
レベル3 MIPテクスチャ:ブロックは2x2テクセルです。 レベル2のMIPテクスチャ:ブロックは4x4テクセルです。
レベル2のMIPテクスチャ:ブロックは4x4テクセルです。 レベル1 MIPテクスチャ:ブロックのサイズは8x8テクセルです。
レベル1 MIPテクスチャ:ブロックのサイズは8x8テクセルです。 レベル0 MIPテクスチャ:ブロックのサイズは16x16テクセルです。フィルタリングを理解するための鍵は、すべてがワールド空間のポリゴンのサイズに基づいていることです(幅と高さはと呼ばれます
レベル0 MIPテクスチャ:ブロックのサイズは16x16テクセルです。フィルタリングを理解するための鍵は、すべてがワールド空間のポリゴンのサイズに基づいていることです(幅と高さはと呼ばれますextent):- Quake2プリプロセッサは、ポリゴン(XまたはY)が256以下であり、16の倍数であることを保証します。
- 世界の空間における多角形の次元から、以下を推測できます。
- ライティングマップサイズ(テクセル単位):LmpDim = PolyDim / 16 + 1
- 表面サイズ(ブロック単位):SurDim = LmpDim -1 = PolyDim / 16
次の図では、ポリゴンの寸法は(3.4)、照明マップは(4.5)テクセルであり、縮退したサーフェスのサイズは常にブロックのサイズ(3.4)です。 MIPテクスチャのレベルは、テクセル単位のブロックサイズを決定するため、テクセル単位の総表面サイズを決定します。 これはすべてで行われ
これはすべてで行われR_DrawSurfaceます。 MIPテクスチャのレベルはsurfmiptable、目的のラスタライズ関数を選択する関数ポインターの配列()を使用して選択されます。 static void (*surfmiptable[4])(void) = { R_DrawSurfaceBlock8_mip0, R_DrawSurfaceBlock8_mip1, R_DrawSurfaceBlock8_mip2, R_DrawSurfaceBlock8_mip3 }; R_DrawSurface { pblockdrawer = surfmiptable[r_drawsurf.surfmip]; for (u=0 ; u<r_numhblocks; u++) (*pblockdrawer)(); }
以下の変更されたエンジンでは、3つのレベルのMIPテクスチャを見ることができます:0-グレー、1-黄色、2-赤: フィルターはサーフェスのブロック[i] [j]を生成するときにブロックによって実行され、フィルターはライティングマップの値を使用します:lightmap [i] [ j]、ライトマップ[i + 1] [j]、ライトマップ[i] [j + 1]およびライトマップ[i + 1] [j + 1]:本質的に、座標に直接4つのテクセルを使用し、右下に3つ。これは、ウェイト補間ではなく、生成された値によって最初に垂直方向に、次に水平方向に線形補間によって行われることに注意してください。要するに、これはウィキペディアの双線形フィルタリングに関する記事とまったく同じように機能します。そして今、すべて一緒に:
フィルターはサーフェスのブロック[i] [j]を生成するときにブロックによって実行され、フィルターはライティングマップの値を使用します:lightmap [i] [ j]、ライトマップ[i + 1] [j]、ライトマップ[i] [j + 1]およびライトマップ[i + 1] [j + 1]:本質的に、座標に直接4つのテクセルを使用し、右下に3つ。これは、ウェイト補間ではなく、生成された値によって最初に垂直方向に、次に水平方向に線形補間によって行われることに注意してください。要するに、これはウィキペディアの双線形フィルタリングに関する記事とまったく同じように機能します。そして今、すべて一緒に: オリジナルの照明マップ、13x15テクセル。
オリジナルの照明マップ、13x15テクセル。 フィルタリング、レベル0 MIPテクスチャ(16x16ブロック)= 192x224テクセル。
フィルタリング、レベル0 MIPテクスチャ(16x16ブロック)= 192x224テクセル。結果:

Surfaceサブシステム:キャッシング
でも、エンジンが積極的にメモリを管理するために使用されているという事実にもかかわらず、mallocとfree彼はまだ表面をキャッシュするための独自のメモリマネージャを使用しています。メモリブロックは、視覚化の解像度が判明した直後に初期化されます。 size = SURFCACHE_SIZE_AT_320X240; pix = vid.width*vid.height; if (pix > 64000) size += (pix-64000)*3; size = (size + 8191) & ~8191; sc_base = (surfcache_t *)malloc(size); sc_rover = sc_base;
最初のローバーsc_roverは、ビジー状態を追跡するためにブロックに配置されています。ローバーがメモリの最後に到達すると、折り畳まれ、本質的に古い表面を置き換えます。予約されたメモリの量は、グラフで確認できます。 ブロックから新しいメモリが割り当てられる方法は次のとおりです。
ブロックから新しいメモリが割り当てられる方法は次のとおりです。 memLoc = (int)&((surfcache_t *)0)->data[size];
注:高速キャッシュ割り当てのトリック(メモリシステムに移動できます)注:ヘッダーは、要求されたメモリサイズの上に配置されます。NULL(((surfcache_t *)0))ポインターを使用する非常に奇妙な行(ただし、遅延がないため、すべて正常です)。貧しい人々のための透視投影?
さまざまなインターネットの記事は、Quake2が単純な式で、同質の座標または行列(以下からのコードR_ClipAndDrawPoly)なしで「貧しい人々のための透視投影」を使用することを示唆しています XscreenSpace = X / Z * XScale YscreenSpace = Y / Z * YScale
XScaleとYScaleは、視野とアスペクト比によって決まります。このような透視図法は、GL_PROJECTION + W除算ステップ中にOpenGLで実際に発生するものに似ています。 : ======================= | X | Y | Z | 1 -------------------------------------------------- | | XScale 0 0 0 | XClip 0 YScale 0 0 | YClip 0 0 V1 V2 | ZClip 0 0 -1 0 | WClip : ================ XClip = X * XScale YClip = Y * YScale ZClip = / WClip = -Z NDC W: ========= XNDC = XClip/WClip = X * XScale / -Z YNDC = YClip/WClip = Y * YScale / -Z
最初の素朴な証拠:オーバーレイスクリーンショットを比較します。コードを見ると:貧しい人々への投影?いや!
R_DrawEntitiesOnList:スプライトとオブジェクト
視覚化プロセスのこの段階では、レベルはすでに画面にレンダリングされています:エンジンは16ビットのzバッファーも生成しました(記録されましたが、まだ読み取られていません): 注:値が近いほど、「明るい」(OpenGLに対して)近いほど「暗い」)。これは、1 / ZがZではなくZバッファーに格納されるためです。ポインタから始まる16ビットのzバッファが保存されます
注:値が近いほど、「明るい」(OpenGLに対して)近いほど「暗い」)。これは、1 / ZがZではなくZバッファーに格納されるためです。ポインタから始まる16ビットのzバッファが保存されますd_pzbuffer。 short *d_pzbuffer;
上記のように、Michael Abrashの記事「代替案の検討:Quakeの隠面消去」で説明されている式を直接適用することにより、1 / Zが保存されます。これは、に位置していますD_DrawZSpans: zi = d_ziorigin + dv*d_zistepv + du*d_zistepu;
1 / Zを実際に補間できる数学的な証明に興味がある場合は、Kok-Lim Lowの記事PDFをご覧ください。レベルの視覚化の段階で推定されるZバッファが、エンティティの正しいトリミングの入力として使用されるようになりました。アニメーション化されたエンティティ(プレイヤーと敵)について少し:- Quake1はキーフレームのみをレンダリングしましたが、現在ではすべての頂点が
R_AliasSetUpLerpDataスムーズなアニメーションのためにLERP()を受けます。 - レンダリングのためのQuake1は、エンティティをBLOBとして表示しました。これは不正確ですが、非常に高速なレンダリング方法です。Quake2はこれを放棄し、BoundingBoxをテストし、ベクター製品で前面をテストした後、エンティティを通常にレンダリングしました。
照明に関して:- すべての影が描かれるわけではありません。
- ポリゴンには、照明の方向が厳密に定義されたグーローシェーディングがあります(
{-1, 0, 0}from R_AliasSetupLighting)。 - 光の強度は、それが向けられる面光源の強度に基づいています。

R_DrawAlphaSurfacesの半透明性
パレットインデックスを使用して半透明性を実行する必要があります。記事では10回これを繰り返してきたと思いますが、これが私にとって驚くほど素晴らしいことを表現できる唯一の方法です。透過ポリゴンは次のようにレンダリングされます。- すべての頂点を画面空間に投影します。
- 左端と右端の定義。
- 表面が歪んでいない場合(アニメーションの水)、RAMのキャッシュシステムで視覚化が実行されます。
その後、表面が完全に不透明でない場合は、オフスクリーンフレームバッファーと混合する必要があります。トリックは、イメージの2番目の部分を使用して実行pics/colormap.pcxされます。これは、サーフェスキャッシュのソースピクセルとターゲットピクセル(フレームごとのバッファー内)を混合するためのルックアップテーブルとして使用されました。 以下のアニメーションは、パレットのピクセルごとの混合の前後のフレームを示しています。
以下のアニメーションは、パレットのピクセルごとの混合の前後のフレームを示しています。
R_CalcPalette:ポストエフェクト操作とガンマ補正
エンジンは、「パレットのピクセル単位の混合」と「パレットに基づいた色のグラデーションの選択」を実行できるだけでなく、健康状態の低下やアイテムの収集に関する情報を送信するためにパレット全体を変更することもできます: ゲームのサーバー側DLLの「アナライザー」が色を混合する必要がある場合視覚化プロセスの最後に、彼
ゲームのサーバー側DLLの「アナライザー」が色を混合する必要がある場合視覚化プロセスの最後に、彼float player_state_t.blend[4]はゲーム内のすべてのプレーヤーのRGBA変数の値を設定する必要がありました。この値はネットワークを介して送信され、にコピーされたrefdef.blend[4]後、レンダラーDLLが渡されます(旅行です!)。検出されると、パレットインデックスの256 RGB要素ごとに混合されます。ガンマ補正後、パレットが再びビデオカードにロードされます。R_CalcPaletteでr_main.c:
興味深い事実:上記の方法でパレットを変更した後、それに対してガンマ補正を実行する必要があります(cR_GammaCorrectAndSetPalette): ガンマ補正は、呼び出し
ガンマ補正は、呼び出しpowと除算を含むリソース集約型の操作です...さらに、各チャネルR、GおよびBカラー値! int newValue = 255 * pow ( (value+0.5)/255.5 , gammaFactor ) + 0.5;
合計で3つの呼び出しがありpow、それは- 、3つの操作部門、パレットの256インデックス値のそれぞれについて、3の和と乗算の6つの操作は非常に多くは。ただし、入力はチャネルごとに8ビットに制限されているため、事前に完全な補正を計算し、256要素の小さな配列にキャッシュできます。 void Draw_BuildGammaTable (void) { int i, inf; float g; g = vid_gamma->value; if (g == 1.0) { for (i=0 ; i<256 ; i++) sw_state.gammatable[i] = i; return; } for (i=0 ; i<256 ; i++) { inf = 255 * pow ( (i+0.5)/255.5 , g ) + 0.5; if (inf < 0) inf = 0; if (inf > 255) inf = 255; sw_state.gammatable[i] = inf; } }
したがって、このトリックにsw_state.gammatableは検索テーブル()が使用され、ガンマ補正プロセスが大幅に加速されます。 void R_GammaCorrectAndSetPalette( const unsigned char *palette ) { int i; for ( i = 0; i < 256; i++ ) { sw_state.currentpalette[i*4+0] = sw_state.gammatable[palette[i*4+0]]; sw_state.currentpalette[i*4+1] = sw_state.gammatable[palette[i*4+1]]; sw_state.currentpalette[i*4+2] = sw_state.gammatable[palette[i*4+2]]; } SWimp_SetPalette( sw_state.currentpalette ); }
注: LCDにはCRTのようなガンマの問題はないと判断するかもしれません...ただし、通常はCRT画面の動作を模倣します!コード統計
ソフトウェアレンダラーのトピックを閉じるためのClocコードの少しの分析:このモジュールには14,874行あります。これは全体の10%を少し上回っていますが、このスキームを選択する前に他のいくつかのテストが行われたため、投資された取り組みについてはわかりません。 $ cloc ref_soft/ 39 text files. 38 unique files. 4 files ignored. http:
9つのファイルでのアセンブラーの最適化にr_*.asmは、コードベース全体の25%が含まれており、これは非常に印象的な比率です。ソフトウェアレンダラーに費やされた労力の量を非常に明確に示していると思います。ほとんどのラスタライゼーション手順は、Michael Abrashによってx86プロセッサ用に手動で最適化されています。彼のGraphics Programming Black Bookで説明されているPentium最適化のほとんどは、これらのファイルで使用されています。興味深い事実:本とQuake2コードのメソッドの名前の一部は同じです(例:)ScanEdges。プロファイリング
 さまざまなプロファイラーを使用してみましたが、それらはすべてVisual Studio 2008に統合されています。
さまざまなプロファイラーを使用してみましたが、それらはすべてVisual Studio 2008に統合されています。- AMDコード分析
- Intel VTune Amplifier XE 2011
- Visual Studio Team Profiler
タイムサンプリングへのスナップは、非常に異なる結果を示しました。たとえば、VtuneはRAMからビデオメモリへの転送コスト(BitBlit)を考慮しましたが、他のプロファイラーはそれらを逃しました。IntelとAMDのプロファイラーは機器のチェックに失敗しました(そして、なぜそれが起こったのかを知るほど自虐的ではありません)が、VS 2008 Teamプロファイラーはそれを行いました...私はお勧めしませんが、ゲームは毎秒3フレームの頻度で動作し、分析のために20 -2番目のゲームには1時間かかりました!プロファイリングVS 2008チームエディション: 結果は次のとおりです。
結果は次のとおりです。- ソフトウェアレンダリングのコストは膨大です。89%の時間がDLLに費やされています。
- ゲームロジックはほとんど目立たない:0%。
- 驚くべきことに、DirectXオーディオDLLには多くの時間がかかります。
libcquake.exeコアよりも多くの時間を費やしました。
 ref_soft.dllに費やした時間を詳しく見てみましょう。
ref_soft.dllに費やした時間を詳しく見てみましょう。- 前述したように、メモリへのバイトの書き込みは非常に高価です。
- 巨大なコスト(33%)は、Zバッファーの構築に関連してい
D_DrawZSpansます()。 - 膨大なコスト(22%)は、オフスクリーンバッファーの記録間隔()に関連付けられています
D_DrawZSpans16。 - キャッシュスキップサーフェスの生成に関連する莫大なコスト(13%)。
- 行ごとの画像構築アルゴリズムのコストは明らかです。
R_LeadingEdgeR_GenerateSpansR_TrailingEdge
Intel VTuneのプロファイリング: 以下が顕著です。
以下が顕著です。- 18%の時間は、ソフトウェアレンダラーの標準的な問題、つまりレンダリングされたイメージをRAMからビデオメモリに転送するコスト(
BitBlit)に費やされています。 - 時間の34%は、サーフェスのレンダリングとキャッシュに費やされています(
D_DrawSurfaces)。 - 8%は、プレイヤー/敵をアニメーション化するためのLERP頂点専用
R_AliasPreparePointsです()。
そして、VTuneを使用したref_sof Quake2のより詳細なプロファイリングを以下に示します。AMDコード分析プロファイリングコアはこちら、ref_sofはこちらです。テクスチャフィルタリング
テクスチャフィルタリングを改善する方法について多くの質問がありました(Unreal(ミラー)で使用されているのと同様のバイリニアフィルタリングまたはディザリングに進みます)。この側面を試してみたい場合は、以下を検討D_DrawSpans16してref_soft/r_scan.cください。画面スペースの初期座標(X、Y)はpspan->uおよびpspan->vであり、spancountどのターゲット画面ピクセルが生成されるかを計算するための間隔幅もあります。テクスチャ座標に関して:sとtテクスチャと増加(それぞれ)上の元の座標でINITIALIZE sstepとtstepテクスチャサンプリングを制御します。例えば、Szilard Biroは、Unreal Iディザリングテクニックを使用して非常に良い結果を得 ました。ディザリングレンダラーのソースコードは、githubのQuake2のフォークにあります。ディザリングを有効にするには、cvar sw_texfiltを1に設定します。Unreal1ソフトウェアレンダラーからの最初のディザリング:
ました。ディザリングレンダラーのソースコードは、githubのQuake2のフォークにあります。ディザリングを有効にするには、cvar sw_texfiltを1に設定します。Unreal1ソフトウェアレンダラーからの最初のディザリング:
OpenGLレンダラー
 Quake2は、ネイティブのハードウェアアクセラレーションレンダリングサポートでリリースされた最初のエンジンです。彼は、テクスチャのバイリニアフィルタリング、マルチテクスチャリングの増加、および24ビットカラーミキシングによる間違いのない改善を示しました。ユーザーの観点から、ハードウェアアクセラレーションバージョンは次の改善を提供しました。
Quake2は、ネイティブのハードウェアアクセラレーションレンダリングサポートでリリースされた最初のエンジンです。彼は、テクスチャのバイリニアフィルタリング、マルチテクスチャリングの増加、および24ビットカラーミキシングによる間違いのない改善を示しました。ユーザーの観点から、ハードウェアアクセラレーションバージョンは次の改善を提供しました。- バイリニアフィルタリング
- カラー照明
- 高解像度で30%高いフレームレート
ジョン・ロメロが最初に色のついた照明を見た方法について、マスターズ・オブ・ドゥームから引用するしかありません。transl。:Quake 2の仕事を始める前に、彼はすでにid Softwareを去り、自分の会社Ion Stormを作成していました]:id [...].
, Quake II. , : ! , . , , . , . , Softdisk, Dangerous Dave in Copyright Infringement [. .: 1990 PC ] .
« », — . .
この機能は、大刀の開発に大きな影響を与えました。以下からのコードの視点(ページの最後センチ。「Insightsのコード」)が50%以下のソフトウェアレンダラ以外のレンダラ。これは、開発者が必要とする作業が少ないことを意味しました。また、そのような実装は、ソフトウェア/アセンブリに最適化されたバージョンよりもはるかにシンプルでエレガントでした。- Zバッファーにより、アクティブなポリゴンのスタックを取り除くことができました(この高速Zバッファーへの依存は、V2200用のVQuakeの開発時に問題を引き起こしました。
- ZバッファのRAM速度と組み合わせたラスタライザチップの高速化により、ゼロ再描画のタスクが不要になりました。
- 行ごとのイメージ構築の組み込み手順により、エッジのグローバルテーブルとアクティブエッジのテーブルが不要になりました。
- 照明カードはビデオプロセッサ(およびグレースケールの代わりにRGB)でフィルター処理されました。これらの計算はCPUにはまったく入りませんでした。
最終的に、OpenGLレンダラーはレンダラーというよりもリソースマネージャーです。頂点を渡し、照明マップのアトラスをその場でロードし、テクスチャ状態を割り当てます。興味深い事実: Quake2フレームには通常600〜900のポリゴンが含まれています。これは、現代のエンジンの何百万ものポリゴンとの顕著な違いです。グローバルコードアーキテクチャ
レンダリングフェーズは非常に単純であり、ソフトウェアレンダリングとほとんど同じであるため、詳細に検討しません。 R_RenderView { R_PushDlights
すべてのステージがビデオに明確に示されており、エンジンが「スローダウン」されています。視覚化の順序:- 世界。
- エンティティ(Quake2では「エイリアス」と呼ばれます)。
- 粒子。
- 半透明の表面。
- フルスクリーンポストエフェクト。
コードの主な複雑さは、ビデオカードがマルチテクスチャリングをサポートしているかどうか、およびグループ頂点レンダリングが有効になっているかどうかによって異なるパスから発生します。例えば、マルチテクスチャリングがサポートされている場合、DrawTextureChainsおよびは、R_BlendLightmaps以下のコードで何もしておらず、コードを読むときだけ混乱します: R_DrawWorld {
世界の可視化
レベルレンダリングはで行われR_DrawWorldます。頂点には5つの属性があります。- 位置。
- カラーテクスチャの識別子。
- カラーテクスチャの座標。
- 静的照明マップのテクスチャ識別子。
- 静的な照明マップのテクスチャの座標。
OpenGLレンダラーには「表面」はありません。色と照明マップはオンザフライで結合され、キャッシュされることはありません。ビデオカードがマルチテクスチャリングをサポートしている場合、必要なパスは1つだけで、テクスチャの識別子とその座標を示します。- カラーテクスチャはOpenGL GL_TEXTURE0状態にバインドします。
- ライトマップのテクスチャは、OpenGL GL_TEXTURE1状態にマップされます。
- カラーテクスチャの座標とライティングマップのテクスチャのピークが送信されます。
ビデオカードがマルチテクスチャリングをサポートしていない場合、2つのパスが実行されます。- ミキシングはオフになります。
- カラーテクスチャはOpenGL GL_TEXTURE0状態にバインドします。
- 頂点は、カラーテクスチャの座標とともに送信されます。
- ミキシングはオンです。
- ライトマップのテクスチャは、OpenGL GL_TEXTURE0状態にマップされます。
- 照明マップのテクスチャの座標を持つピークが送信されます。
テクスチャ管理
すべてのラスタライズはビデオプロセッサで実行されるため、レベルの開始時に、すべてのテクスチャをビデオメモリにロードする必要があります。- カラーテクスチャ
- 事前に計算されたライトマップテクスチャ
OpenGLデバッガgDEBuggerを使用すると、ビデオプロセッサのメモリを簡単に掘り下げて統計情報を取得 できます。ご覧のとおり、各カラーテクスチャには独自のテクスチャ識別子(textureID)があります。静的ライトマップは、次のようにテクスチャアトラス(quake2では「ブロック」と呼ばれます)としてロードされます。
できます。ご覧のとおり、各カラーテクスチャには独自のテクスチャ識別子(textureID)があります。静的ライトマップは、次のようにテクスチャアトラス(quake2では「ブロック」と呼ばれます)としてロードされます。 ライトマップがテクスチャアトラスにアセンブルされている場合、カラーテクスチャが別のテクスチャにあるのはなぜですか?理由の嘘テクスチャチェーンの最適化:あなたがビデオで作業する場合、あなたの生産性を向上したい場合は、彼はできるだけ彼の状態を変更したことのために努力する必要があります。これは、テクスチャバインディング(
ライトマップがテクスチャアトラスにアセンブルされている場合、カラーテクスチャが別のテクスチャにあるのはなぜですか?理由の嘘テクスチャチェーンの最適化:あなたがビデオで作業する場合、あなたの生産性を向上したい場合は、彼はできるだけ彼の状態を変更したことのために努力する必要があります。これは、テクスチャバインディング(glBindTexture)に特に当てはまります。悪い例は次のとおりです。 for(i=0 ; i < polys.num ; i++) { glBindTexture(polys[i].textureColorID , GL_TEXTURE0); glBindTexture(polys[i].textureLightMapID , GL_TEXTURE1); RenderPoly(polys[i].vertices); }
各ポリゴンにカラーテクスチャとライトマップのテクスチャがある場合、ほとんど実行できませんが、Quake2はアトラスでライトマップを収集します。これは識別子で簡単にグループ化できます。したがって、ポリゴンはBSPから返された順序でレンダリングされません。代わりに、それらは、それらが表すテクスチャマップのアトラスに基づいて、テクスチャのチェーンにグループ化されます。 glBindTexture(polys[textureChain[0]].textureLightMapID , GL_TEXTURE1); for(i=0 ; i < textureChain.num ; i++) { glBindTexture(polys[textureChain[i]].textureColorID , GL_TEXTURE0); RenderPoly(polys[textureChain[i]].vertices); }
以下のビデオは、「テクスチャチェーン」の視覚化プロセスを示しています。ポリゴンは、距離ではなく、関連するライティングマップのブロックに基づいてレンダリングされます。注:一定の半透明性を実現するために、完全に不透明なポリゴンのみがテクスチャチェーンに分類され、半透明のポリゴンは引き続き前面から背面にレンダリングされます。ダイナミックライティング
視覚化フェーズの最初の段階で、すべてのポリゴンにマークが付けられ、動的な照明の影響を受けていることが示されR_PushDlightsます()。したがって、事前に計算された静的照明マップは使用されません。代わりに、静的な照明マップとポリゴンプレーンに投影される光の追加(R_BuildLightMap)を組み合わせた新しい照明マップが生成されます。ライティングマップの最大サイズは17x17であるため、ダイナミックライティングマップの生成フェーズはそれほど高価ではありませんが、それを使用してビデオプロセッサに変更をダウンロードするのはqglTexSubImage2D 非常に遅いです。すべての動的な照明マップを保存するために、サイズ128x128の照明マップのブロックが使用されます。そのIDは1024です。テクスチャアトラスですべてのダイナミックライティングマップをその場で組み合わせる方法の説明については、「ライティングマップの管理」を参照してください。 1.動的照明ユニットの初期状態。2.最初のフレームの後。3. 10フレーム後。注:動的ライトマップがいっぱいの場合、バッチレンダリングが実行されます。ローバーは、割り当てられたスペースがクリアされたかどうかを追跡し、動的ライトマップの生成を再開します。
1.動的照明ユニットの初期状態。2.最初のフレームの後。3. 10フレーム後。注:動的ライトマップがいっぱいの場合、バッチレンダリングが実行されます。ローバーは、割り当てられたスペースがクリアされたかどうかを追跡し、動的ライトマップの生成を再開します。照明カードを管理する
前述したように、OpenGLバージョンのレンダラーには「表面」の概念がありません。ライトマップとカラーテクスチャはオンザフライで結合され、キャッシュされません。静的照明マップはビデオメモリに読み込まれますが、RAMに保存されます。動的照明がポリゴンに影響を与える場合、静的照明マップとそれに投影される光を組み合わせた新しい照明マップが生成されます。次に、ダイナミックライティングマップがtextureId = 1024にロードされ、テクスチャリングに使用されます。テクスチャアトラスは、Quake2では「ブロック」と呼ばれ、128x128テクセルで構成され、3つの機能によって制御されます。LM_InitBlock :ブロックメモリ消費の追跡をリセットします。LM_UploadBlock :テクスチャコンテンツをダウンロードまたは更新します。LM_AllocBlock :照明マップを保存するのに適した場所を見つけます。
以下のビデオは、照明マップがブロックでどのように接続されているかを示しています。ここで、エンジンはテトリスを再生します。左から右にスキャンし、照明マップが画像の最高座標のどこに完全に収まるかを記憶します。アルゴリズムに注意を払う必要があります。ローバー(int gl_lms.allocated[BLOCK_WIDTH])は、ピクセルの各列が占める高さを幅全体に沿って追跡します。 // "best" "bestHeight" // "best2" "tentativeHeight" static qboolean LM_AllocBlock (int w, int h, int *x, int *y) { int i, j; int best, best2; //FCS: best = BLOCK_HEIGHT; for (i=0 ; i<BLOCK_WIDTH-w ; i++) { best2 = 0; for (j=0 ; j<w ; j++) { if (gl_lms.allocated[i+j] >= best) break; if (gl_lms.allocated[i+j] > best2) best2 = gl_lms.allocated[i+j]; } if (j == w) { // *x = i; *y = best = best2; } } if (best + h > BLOCK_HEIGHT) return false; for (i=0 ; i<w ; i++) gl_lms.allocated[*x + i] = best + h; return true; }
注:「ローバー」デザインパターンは非常にエレガントで、ソフトウェアレンダラーのサーフェスをキャッシュするためのメモリシステムでも使用されます。ピクセルフィルレートとレンダリングパス
次のビデオからわかるように、再描画は非常に重要です。最悪の場合、ピクセルは3〜4回上書きされます(再描画はカウントされません)。- ワールド:1-2パス(マルチテクスチャリングのサポートによる)。
- 粒子の混合:1パス。
- ポストエフェクトのミキシング:1パス。
GL_LINEAR
バイリニアフィルタリングはカラーテクスチャでうまく機能しましたが、ライトマップをフィルタリングすると本当に花開きます。それは:
次のようになりました:
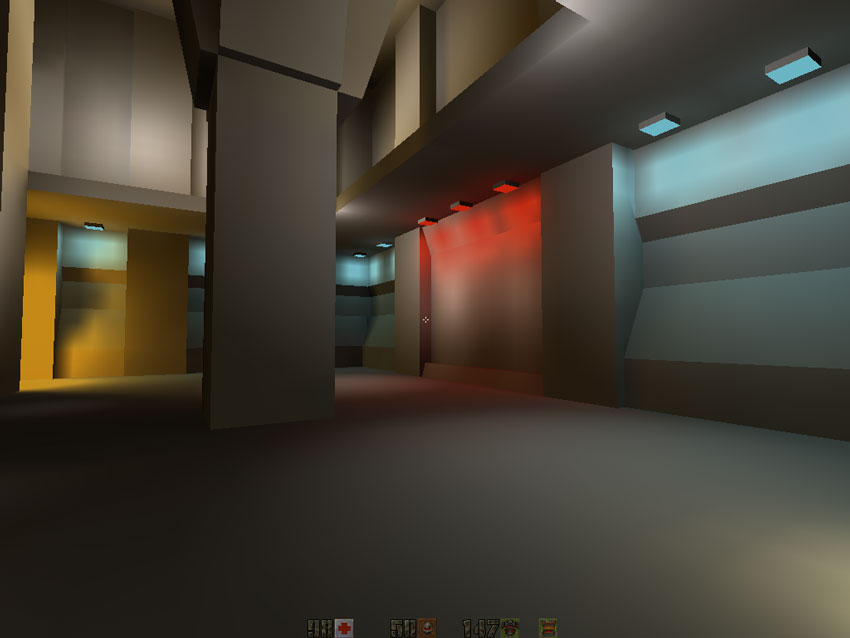 そして今、すべて一緒に:
そして今、すべて一緒に: 1.テクスチャ:動的/静的照明マップ。
1.テクスチャ:動的/静的照明マップ。 2.テクスチャ:色。
2.テクスチャ:色。 3.混合の結果:1つまたは2つのパス。
3.混合の結果:1つまたは2つのパス。
エンティティの可視化
エンティティはグループでレンダリングされます。頂点、テクスチャ座標、およびカラー配列ポインターは、を使用して収集され送信されglArrayElementます。レンダリングの前に、アニメーションをスムーズにするために、すべてのエンティティの頂点に対してLERPが実行されます(Quake1ではキーフレームのみが使用されました)。Gouroの照明モデルが使用されます:Quake2は、照明値を格納するために色の配列をインターセプトします。視覚化の前に、各頂点について、照明値が計算され、色の配列に保存されます。この配列の値はビデオプロセッサで補間され、Gouroライティングで良好な結果が得られます。 R_DrawEntitiesOnList { if (!r_drawentities->value) return;
背面のクリップはビデオプロセッサで行われます(まあ、その時点でCPUでテッセレーションとライティングが行われているため、ドライバーの段階で行われたと言えます)。注:計算を高速化するために、光の方向は常に同じ({-1, 0, 0})であると想定されていましたが、これはエンジンには反映されません。照明の色は正確で、エンティティのベースとなっている現在のポリゴンに応じて選択されます。これは、光源の定義が間違っているにもかかわらず、光と影の方向が同じである下のスクリーンショットで非常にはっきりと見えます。注:もちろん、このシステムは必ずしも完全ではなく、影がボイドに投影され、顔が互いに上書きして、さまざまなレベルの影になりますが、これは1997年でも非常に印象的です。影の詳細:多くの人は、Quake2がエンティティのおおよその影を計算できたことを知りません。この機能はデフォルトで無効になっていますが、コマンドで有効にできますgl_shadows 1。影は常に一方向に向けられ(最も近い光源に依存しません)、面はエンティティレベルの平面に投影されます。このコードR_DrawAliasModelは、エンティティレベルの平面に面を投影するためにshadevector使用されるベクトルを生成しGL_DrawAliasShadowます。エンティティ可視化照明:サンプリングトリック
モデル内のポリゴンの数が少ないため、法線とスカラーの法線/光の積をリアルタイムで計算できると判断できますが、そうではありません。すべてのスカラー積は事前に計算されfloat r_avertexnormal_dots[SHADEDOT_QUANT][256]、に保存されSHADEDOT_QUANTます。ここで= 16です。離散化が使用されます。光の方向は常に同じです:{-1,0,0}。Y軸に沿ったモデルの方向に応じて、16の異なる法線の1つのみが計算されます.16の方向のいずれかを選択すると、256の異なる法線のスカラー積が事前に計算されます。 MD2モデル形式の標準は、常に事前に計算された配列のインデックスです。 X、Y、Z法線の任意の組み合わせは、256方向のいずれかに分類されます。これらすべての制限のため、すべてのスカラー積はr_avertexnormal_dots16x256サイズ。法線インデックスはアニメーション中に補間できないため、キーフレームには最も近い法線インデックスが使用されます。これについての詳細:http : //www.quake-1.com/docs/quakesrc.org/97.html(mirror)。古き良きOpenGL ...
glGenTexturesはどこにありますか?!:今日、openGL開発者はを介してビデオプロセッサからtextureIDを要求していglGenTexturesます。 Quake2はこれを気にせず、独自に識別子を選択しました。したがって、カラーテクスチャは0から始まり、動的ライトマップのテクスチャは常に1024の識別子を持ち、静的ライトマップは1025から1036まででした。悪名高いイミディエイトモード:頂点データはイミディエートモードを使用してビデオカードに転送されます。トップ(への2つの関数呼び出しglVertex3fvとglTexCoord2f世界のレンダリング用)(ポリゴンが個別に切断して、グループにそれらを集めることができませんでした)。を使用してモデル(敵、プレイヤー)のグループの視覚化を実行しましたglEnableClientState (GL_VERTEX_ARRAY)。送信トップスglVertexPointerとglColorPointerCPUによって計算された照明値を送信するために使用されました。マルチテクスチャリング:新しいテクノロジをサポートする/サポートしない機器に適応しようとするため、コードは複雑です...マルチテクスチャリング。使用しないGL_LIGHTING:すべての計算はCPU(ワールドのテクスチャ生成とエンティティの頂点イルミネーションの値)で実行されたため、コードにはトレースがありませんGL_LIGHTING。OpenGL 1.0は、Phongシェーディング(法線が実際の「ピクセル単位のイルミネーション」で補間される)ではなく、Gouraudシェーディング(頂点間の色の補間)を実行GL_LIGHTINGするため、その場で頂点を作成する必要があるため、世界では見た目が悪くなります。エンティティに適用できますが、頂点法線ベクトルも送信する必要があります。これは不適切と思われるため、ライティング値の計算はCPUで行われます。照明値は色の配列から送信され、値はCPUに補間されてグーローシェーディングを取得します。フルスクリーンポストエフェクト
パレットベースのソフトウェアレンダラーは、ルックアップテーブルを使用して、エレガントで完全なパレットカラーミキシングと追加のガンマ補正を実行しました。しかし、OpenGLバージョンはこれを必要としません。これは、次の「ブルートフォース」メソッドの例で見ることができますR_Flash:問題:画面をもう少し赤くする必要がありますか?解決策:画面全体に、アルファチャネルミキシングをオンにして巨大な赤い長方形GL_QUADを描画するだけです。できた
注:サーバーは、ソフトウェアレンダラーと同じ方法でクライアントを制御しました。サーバーがポストエフェクトのためにフルスクリーンカラーミキシングを実行する必要がある場合は、単にfloat player_state_t.blend[4]RGBA 変数に値を割り当てました。変数の値は、ネットワークを介してquake2コアのおかげで送信され、レンダラーDLLに送信されました。プロファイリング
Visual Studio 2008 Teamプロファイラーは素晴らしいです。これがOpenGL Quake2で判明したことです。当然です 。ほとんどの時間はOpenGLドライバーNVidiaとWin32(
。ほとんどの時間はOpenGLドライバーNVidiaとWin32(nvoglv32.dllおよびopengl32.dll)に費やされており、約30%しかありません。視覚化はビデオプロセッサで実行されますが、RAMからビデオメモリへのデータのコピーだけでなく、イミディエイトモードメソッドの複数の呼び出しに多くの時間が費やされます。次はレンダラーモジュール(ref_gl.dll23%)とquake2コア(quake2.exe15%)です。エンジンは積極的にmallocを使用しますが、ほとんど時間を費やさないことがわかります(MSVCR90D.dllおよびmsvcrt.dll)。また、ゲームロジック(gamex86.dll)に費やされる時間は重要ではありません。directX(dsound.dll)サウンドライブラリで予想外の時間が無駄になります:合計時間の12%。OpenGL Quake2 dllレンダラーを詳しく見てみましょう。
- ほとんどの時間は世界のレンダリングに費やされています(
R_RecurseiveWorldNode)。 - ほぼ同じ量-敵(エイリアスモデル)のレンダリング:(
GL_DrawAliasFrameLerp2.5%)。スカラー積が事前に計算されるという事実にもかかわらず、コストは非常に高くなります。 - 照明マップの生成(動的照明では、以前に計算された静的照明マップの使用が許可されていない場合)も、時間の2.5%を要します(
GL_RenderLightMappedPoly)。
全体として、OpenGL dllはバランスがよく、明らかなボトルネックはありません。コード統計
Clocコードを分析すると、合計7,265行のコードがあることがわかります。 $ cloc ref_gl 17 text files. 17 unique files. 1 file ignored. http:
ソフトウェアレンダラーと比較すると、違いは顕著です。アセンブラーの最適化なしでコードが50%減少しますが、速度は30%高くなり、カラー照明とバイリニアフィルタリングがあります。id SoftwareがQuake3のソフトウェアレンダラーを気にしなかった理由は簡単にわかります。