この記事では、アトミック操作とC ++ 11メモリバリア、およびそれらによってx86_64プロセッサで生成されたアセンブラ命令を詳細に分析します。
次に、
contfree_safe_ptr <std :: map>の作業を、std :: map <>と機能的に類似した複雑で最適化された
ロックフリーデータ構造のレベルまで高速化する方法を示します
。 com / khizmax / libcdsまた、contfree_safe_ptr <T>として使用される最初のスレッドセーフクラスTのいずれでも、このようなマルチスレッドパフォーマンスを得ることができます。 生産性を約1000%向上させる最適化に関心があるため、弱くて疑わしい最適化には注意を払いません。
関連する3つの記事:
- オブジェクトをスレッドセーフにする
- stdの高速化:: shared_mutexを10倍
- スレッドセーフstd ::ロックのないマップパフォーマンスを備えたマップ
→
私の英語の記事→
3つの記事すべての例とテスト高性能ロックベースのデータ構造
contfree_safe_ptr <T>はクラスsafe_ptr <T、contention_free_shared_mutex>です。contention_free_shared_mutexは、独自の最適化された共有mutexです。 また、safe_ptrは前回の記事のスレッドセーフポインターです。
順番に、独自の高性能で
競合のないshared-mutexを実装する方法を示します。これは、読み取りでほとんど競合しません。 更新操作で行をブロックするために、独自のアクティブスピンロックおよび再帰スピンロックロックを実装します。 RAIIブロッキングポインターを作成して、複数のブロッキングのコストを回避します。 パフォーマンステストの結果は次のとおりです。
また、「楽しみのため」のボーナスとして、各セクションの境界が最初にわかっている場合、DBMSのパーティションテーブルに似た複数のstd ::マップで構成される、マルチスレッド用にさらに最適化された独自の単純化パーティションタイプpartition_mapのクラスを実装する方法を示します。
原子操作の基礎
マルチスレッド、原子性、メモリバリアの基本を考慮してください。 複数のスレッドから同じデータを変更する場合、つまり thread_func()関数を複数のスレッドで同時に実行する場合:
int a; void thread_func() { a = a + 1; }
次に、thread_func()関数を呼び出す各スレッドは、通常の共有変数int aに1を追加します。 このようなコードは一般にスレッドセーフではありません。 通常の変数に対する複合操作(RMW-読み取り-変更-書き込み)は、別のスレッドがデータを変更できる多くの小さな操作で構成されます。 操作a = a + 1; 少なくとも3つのミニオペレーションで構成されます。
- 変数「a」の値をプロセッサレジスタにロードします
- レジスタの値に1を加算します
- レジスタの値を変数「a」に書き戻します
たとえば、int a = 0; また、2つのスレッドが操作a = a + 1を実行します。 結果はa = 2になります。 しかし、次のことが起こる可能性があります-ステップバイステップ:
int a = 0;
2つのストリームが同じグローバル変数+1に追加されますが、最終的に変数a = 1です。この問題はデータレースと呼ばれます。
この問題を回避するには3つの方法があります。
- アトミック変数でアトミック命令を使用しますが、1つの欠点があります。アトミック関数の数は非常に少ないため、それらを使用して複雑なロジックを実装することは困難です。
- 新しいコンテナごとに独自の複雑なロックフリーアルゴリズムを開発します。
- ロックを使用する(std :: mutex、std :: shared_timed_mutex、spinlock ...)-ブロックされたコードへの1つのストリームを順番に許可するため、データ競合は発生せず、通常のスレッドセーフでない任意の複雑なロジックを使用できますオブジェクト。
std :: atomic <int> a; 最初にa = 0の場合; また、2つのスレッドが操作a + = 1を実行します。 結果は常にa = 2になります。
std::atomic<int> a; void thread_func() { a += 1; }
次はx86_64プロセッサで常に発生します(ステップバイステップ)。
std::atomic<int> a = 0;
ARMやPowerPCなど、LL / SCをサポートするプロセッサーでは、他の手順が発生しますが、同じ結果a = 2が発生します。
C ++ 11で導入されたアトミック変数:
en.cppreference.com/w/cpp/atomic/atomicstd :: atomic <>クラステンプレートのメンバーである関数は常にアトミックです。
以下に、正しいコードの3つのフラグメントを示します。意味は同じです。
1.例:
std::atomic<int> a; a = 20; a += 50;
2.これは例1と同じです。
std::atomic<int> a; a.store( 20 ); a.fetch_add( 50 );
3.そして、これは例1と同じです。
std::atomic<int> a; a.store( 20, std::memory_order_seq_cst ); a.fetch_add( 50, std::memory_order_seq_cst );
つまり、std :: atomicの場合:
- load()およびstore()は、 演算子Tおよび演算子=と同じです。
- fetch_add()およびfetch_sub()は、 operator + =およびoperator- =と同じです
- Sequential Consistency(std :: memory_order_seq_cst)は、デフォルトのメモリバリアです(最も厳格で信頼性がありますが、他と比較して最も低速です)。
C ++ 11の
std :: atomicと
volatileの違いに注意してください:
www.drdobbs.com/parallel/volatile-vs-volatile/2127014845つの主な違いがあります。
- 最適化 :std :: Atomic <T> a; 揮発性T aでは不可能な2つの最適化が可能です。
•マージの最適化:a = 10; a = 20; = 20のコンパイラーに置き換えることができます。
•定数置換の最適化:a = 1; ローカル= a; = 1コンパイラで置き換えることができます。 ローカル= 1; - 並べ替え :stdの操作:: atomic <T> a; 使用されているメモリバリアstd :: memory_order_ ...に従って、通常の変数を使用した操作および他のアトミック変数を使用した操作について、それ自体の周りの並べ替えを制限できます。 通常の変数(非原子/不揮発性)の順序には影響しませんが、すべての揮発性変数の呼び出しは常に厳密な相互順序を維持します。 2つの揮発性操作の実行順序は、コンパイラーではなく、プロセッサーで変更できます。
- スピル:メモリバリアstd :: memory_order_release、std :: memory_order_acq_rel、std :: memory_order_seq_cstがstd :: atomic <T> aの操作に指定されています。 アトミック操作を実行する前に、すべての共通変数の流出を開始します。 つまり これらのバリアは、コンパイラがこのローカル変数を他のスレッドで使用できないことを100%保証できない限り、プロセッサレジスタからRAM /キャッシュに通常の変数をアンロードします。
- Atomicity / Alignment :stdに対する操作:: atomic <T> a; 他のストリームに完全に表示されるか、まったく表示されません。 整数型Tの場合、これはコンパイラーによってメモリ内のアトミック変数の位置を調整することで実現されます-少なくとも変数は1つのキャッシュラインに存在する必要があるため、アトミック変数は1回のCPU操作で変更または読み取りできます 逆に、コンパイラは、揮発性変数のアライメントとそれらに対する操作のアトミック性を保証しません。 揮発性変数は通常、デバイスメモリへのアクセスやその他の場合に使用されますが、スレッド間のデータ交換には使用されません。 デバイスドライバーAPIは、揮発性変数へのポインターを返します。必要に応じて、このAPIはアライメントを提供します。
- RMW操作のアトミック性 (読み取り-変更-書き込み):std に対する操作 :: atomic <T> a; (++、-、+ =、-=、* =、/ =、CAS、交換)などは、アトミックに実行されます。 2つのスレッドが++ a操作を実行する場合; この変数は、キャッシュライン(x86_64)をブロックするか、RMW操作の全期間にわたってLL / SC(ARM、PowerPC)をサポートするプロセッサーのキャッシュラインに変更がないことをマークすることで達成されます。 揮発性変数は、複合RMW操作の原子性を提供しません。
std ::アトミック変数と揮発性変数には、1つの一般的なルールがあります。各読み取りまたは書き込み操作は、常にメモリ/キャッシュにアクセスします。 値がプロセッサレジスタにキャッシュされることはありません。
また、通常の(通常の)変数とオブジェクト(非アトミック/不揮発性)については、コンパイラまたはプロセッサによる相互の独立した命令の最適化と並べ替えが可能です。
メモリバリアstd :: memory_order_release、std :: memory_order_acq_relおよびstd :: memory_order_seq_cstを使用してアトミック変数にメモリに書き込む操作は、現在オンになっているすべての非アトミック/不揮発性変数の流出(レジスタからメモリへの書き込み)を保証することを思い出してくださいプロセッサの登録の瞬間:
en.wikipedia.org/wiki/Register_allocation#Spilling命令の実行順序を変更する
コンパイラとプロセッサは命令を並べ替えて、プログラムを最適化し、パフォーマンスを向上させます。
GCCコンパイラとx86_64プロセッサが行う最適化の例を次に示します
。godbolt.org /
g /
n91hpt
フルサイズの画像:
hsto.org/files/3d2/18b/c7b/3d218bc7b3584f82820f92077096d7a0.jpg写真の最適化は何ですか:
- GCC 7.0コンパイラの並べ替え:
•メモリエントリを交換しますb = 5; メモリからレジスタint tmp_c = c;にロードします。 これにより、「c」の値をできるだけ早く要求することができ、プロセッサはこの長い操作の完了を期待しますが、プロセッサのパイプラインは操作b = 5の並列実行を許可します。 これら2つの操作は互いに独立しています。
•メモリからレジスタint tmp_a = aへのロードを組み合わせます。 および追加操作tmp_c = tmp_c + tmp_a; -結果として、2つの命令の代わりに、1つの追加eaxが取得され、[rip] - x86_64プロセッサによる並べ替え:
プロセッサは、実際のメモリレコードmov b [rip]、5をスワップし、add add eax、a [rip]と組み合わせてメモリから読み取ることができます。
mov b [rip]命令を使用してメモリへの書き込みを開始すると、次の5が発生します。まず、値5とアドレスb [rip]がStore-bufferハードウェアキューに配置され、すべてのプロセッサコアのアドレスb [rip]応答の場合、CPU-Core-0はb [rip]を含むキャッシュラインにステータス「eXclusive」を設定し、その後で実際の値5がストアバッファからb [rip]でこのキャッシュラインに書き込まれます。 x86_64キャッシュコヒーレンスプロトコルの詳細MOESI / MESIF-すべてのコアに即座に表示される変更: en.wikipedia.org/wiki/MESIF_protocol
このすべての時間を待たないために、実際のキャッシュエントリを待たずに5がStore-Bufferに配置された直後に、メモリからの読み取りまたはレジスタ操作の実行を開始できます。 これは、まさにx86_64プロセッサーが行うことです。
Intel 64およびIA-32アーキテクチャソフトウェア開発者向けマニュアル第3巻(3A、3B、3Cおよび3D):システムプログラミングガイド: www-ssl.intel.com/content/dam/www/public/us/en/documents/manuals/ 64-ia-32-architectures-software-developer-system-programming-manual-325384.pdf
8.2.3.4異なる場所への以前のストアでロードを並べ替えることができます
Intel-64のメモリ順序モデルでは、以前のストアを使用して別の場所にロードを並べ替えることができます。 ただし、同じ場所への店舗の場合、荷物は並べ替えられません。
x86_64ファミリのプロセッサには強力なメモリモデルがあります。 また、PowerPCやARM v7 / v8などのメモリモデルが弱いプロセッサは、さらに多くの並べ替えを実行できます。
通常の
通常変数、
揮発性変数、
アトミック変数のメモリエントリの可能な並べ替えの例を示します。
通常の変数の並べ替え:
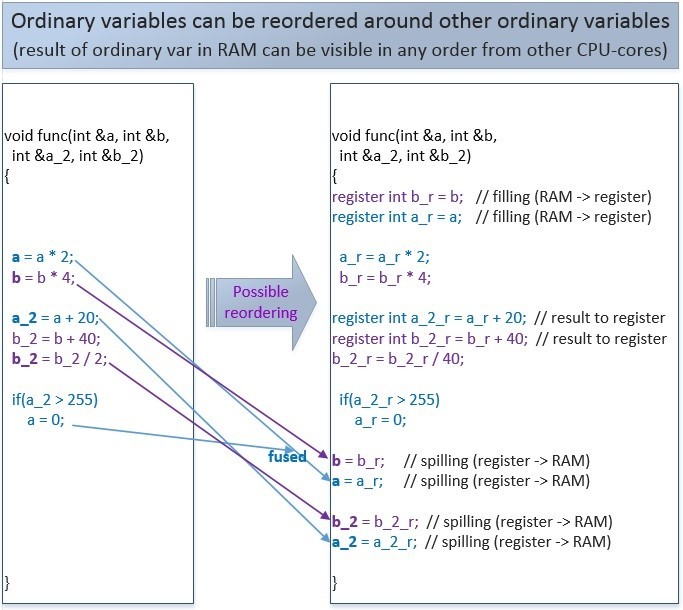
通常の変数を含むこのコードは、コンパイラまたはプロセッサによって次のように並べ替えることができます。 1つのストリーム内では、その意味は変わりません。 しかし、多くのスレッド内では、このような並べ替えがプログラムロジックに影響を与える可能性があります。
2つの変数が揮発性の場合、次の並べ替えが可能です。 コンパイラーは、コンパイル時にvolatile変数の操作を並べ替えることはできませんが、コンパイラーは、実行時にプロセッサーがこの並べ替えを実行できるようにします。
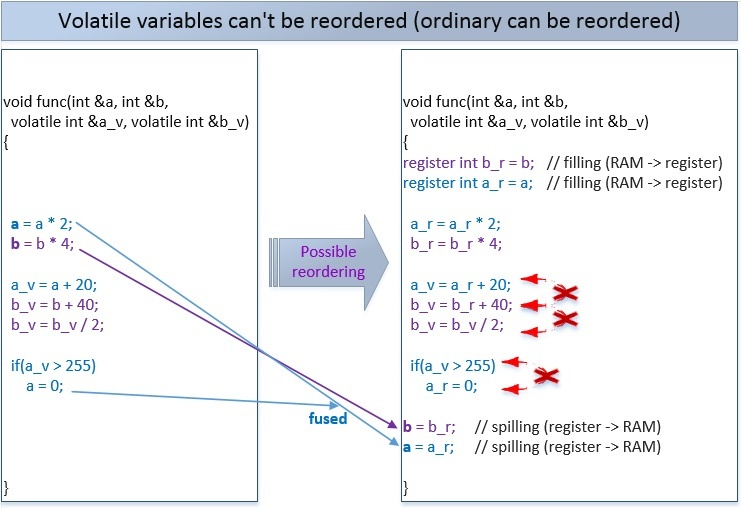
そのような並べ替えのすべてまたは一部のみを防ぐために、アトミック操作があります(デフォルトでは、アトミック操作は最も厳しいメモリバリア
std :: memory_order_seq_cstを使用することを思い出して
ください ):

別のスレッドは、メモリ内の変数の変更をこの変更された順序で正確に見ることができます。
アトミック操作にメモリバリアを指定しない場合、最も厳密なstd :: memory_order_seq_cstバリアがデフォルトで使用され、アトミックまたは非アトミック操作はそのような操作で並べ替えることはできません(ただし、例外があります-これについては後で説明します)。
上記の場合、最初に通常の変数aおよびbに書き込み、次にアトミック変数a_atおよびb_atに書き込みます。この順序は変更できません。 また、b_atメモリへの書き込みは、a_atメモリへの書き込みよりも早く行うことはできません。 ただし、変数aおよびbへの書き込みは、相互に並べ替えることができます。
「注文できる」と言うとき、これは可能ですが、必ずしもそうではありません。 コンパイラがコンパイル時にC ++コードを最適化するか、実行時にCPUを最適化するかによって異なります。
以下では、許可された方向に命令を並べ替えることができる、より弱いメモリバリアについて説明します。これにより、コンパイラとプロセッサはコードをより最適化し、パフォーマンスを向上させることができます。
メモリアクセス操作に対する障壁の並べ替え
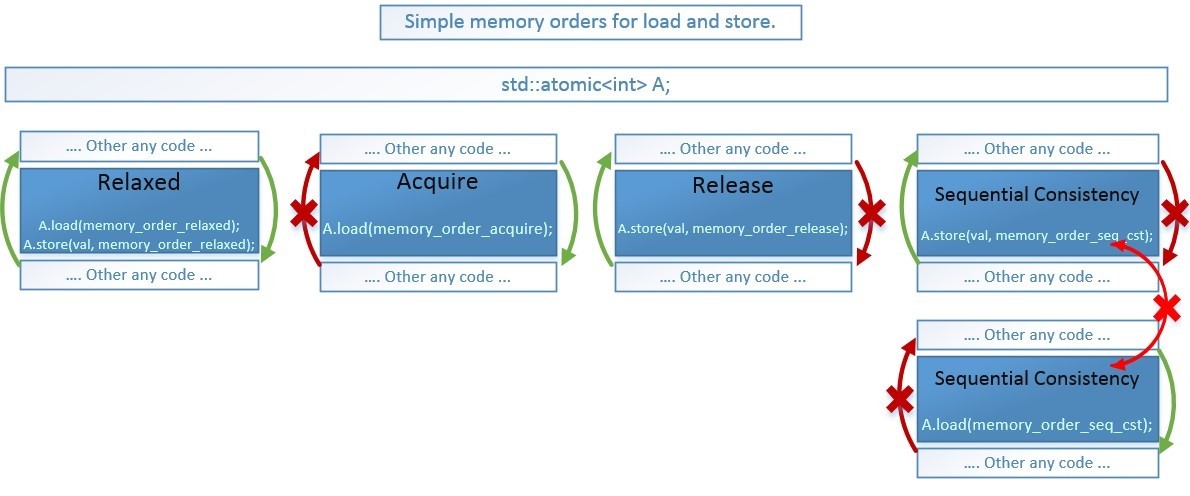
C ++ 11標準メモリモデルは、最新のCPUの投機的実行の機能に対応する6種類のメモリバリアを提供します。これらを使用すると、並べ替えを完全に禁止するのではなく、必要な方向にのみ使用できます。 これにより、コンパイラとプロセッサがコードを可能な限り最適化できるようになります。 また、禁止されている並べ替えの指示により、コードの正確性を維持できます。
en.cppreference.com/w/cpp/atomic/memory_order enum memory_order { memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, memory_order_seq_cst };
- memory_order_consume。 ただし、memory_order_consumeバリアを実際には使用しないことに注意してください。 標準はその使用の適切性に疑問を抱いています-標準からの引用: www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
§29.3
(1.3)-memory_order_consume:ロード操作は、影響を受けるメモリ位置で消費操作を実行します。 [注:memory_order_acumeを優先します。これは、memory_order_consumeよりも強力な保証を提供します。 実装では、memory_order_acquireのパフォーマンスよりも優れたパフォーマンスを提供することは実行不可能であることがわかっています。 仕様の改訂は検討中です。 -終了ノート]
- memory_order_acq_rel。 また、memory_order_acq_relバリアは、compare_exchange_weak()/ _ strong()、exchange()、fetch_(add、sub、and、or、xor)などのアトミックな化合物RMW(読み取り-変更-書き込み)操作にのみ使用されることに注意してください。名前付き演算子: en.cppreference.com/w/cpp/atomic/atomic
残りの4つのメモリバリアは、取得-ストア()に使用されない、リリース-ロード()に使用されない-を除く、すべての操作に使用できます。
選択したメモリバリアに応じて、コンパイラとプロセッサはバリアに対して実行可能なコードを異なる方向に移動することを禁止されています。
ここで、矢印が示すものを正確に示します-場所を変更できるものとできないものを示します:
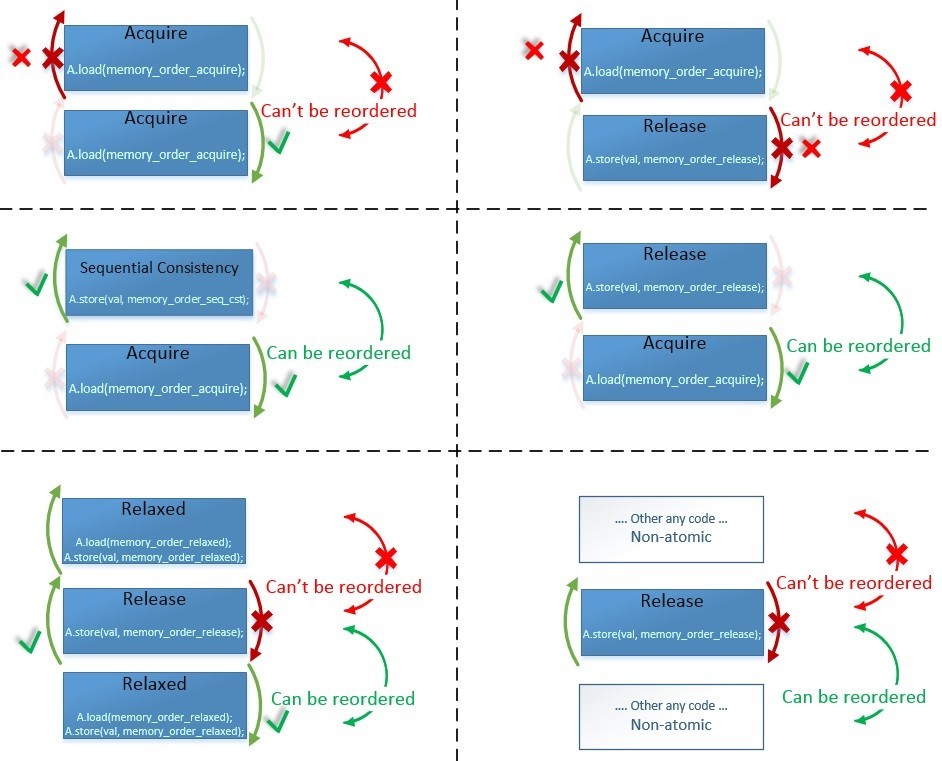
2つの命令で場所を切り替えるには、これらの命令の両方の障壁がそのような交換を許可する必要があります。 なぜなら 「その他の任意のコード」は、障壁のない通常の非原子変数であり、順序を変更できます。 左下の例の
Relaxed-Release-Relaxedでは、ご覧の
とおり 、同じメモリバリアの順序を変更できるかどうかは、その順序によって異なります。
これらのメモリバリアの意味と、最も一般的なAcquire-Releaseの並べ替えセマンティクスを必要とする単純なスピンロック実装を使用して得られる利点を見てみましょう。 スピンロックは、std :: mutexと同様の使用法によるロックです。
まず、プログラムの本体にスピンロックの概念を直接実装します。 そして、別のスピンロッククラスを実装します。 ロック(ミューテックス、スピンロック...)を実装するには、Acquire-Releaseセマンティクス、
C ++ 11 Standard§1.10.1 (3)を使用する必要があります:
www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606 .pdf...たとえば、mutexを取得する呼び出しは、mutexを構成する場所で取得操作を実行します。 同様に、同じミューテックスを解放する呼び出しは、同じ場所で解放操作を実行します。 非公式には、 Aでリリース操作を実行すると、他のメモリ位置に対する以前の副作用が、後でAで消費または取得操作を実行する他のスレッドから見えるようになります。
Acquire-Releaseセマンティクスの主なポイントは、
次のとおりです。flag.load操作
(std :: memory_order_acquire)の後のthread-2“ Thread-2”は、行われた変数/構造/クラス(アトミックなものでさえない)のすべての変更を確認することです
thread.1 flag.store(0、std :: memory_order_release)操作が
実行される前の「スレッド-1」。
ロック(ミューテックス、スピンロック...)の主な意味は、一度に1つのスレッドのみが実行できるコードのセクションを作成することです。 複数のスレッドで並行して実行することはできません。 コードのこのセクションは、クリティカルセクションと呼ばれます。 その内部では、std :: atomicなしなど、通常のコードを使用できます。
メモリバリア(メモリフェンス)-クリティカルセクションからの操作がそれを超えて拡張しないように、コンパイラがプログラムを最適化しないようにします。
最初にロックを取得したスレッドはこのコードブロックを実行し、残りのスレッドはループで待機します(一時的にスリープ状態になる可能性があります)。 最初のスレッドがロックを解放すると、プロセッサは次の待機スレッドのどれがロックを取得するかを決定します。 などなど。
意味が同じ2つの例を次に示します。
- std :: atomic_flagを使用:[19] coliru.stacked-crooked.com/a/1ec9a0c2b10ce864
- std :: atomic <int>を使用:[20] coliru.stacked-crooked.com/a/03c019596b65199a
例1が望ましいため、メモリバリアを使用する意味を概略的に示しています。原子操作は青一色で示されています。
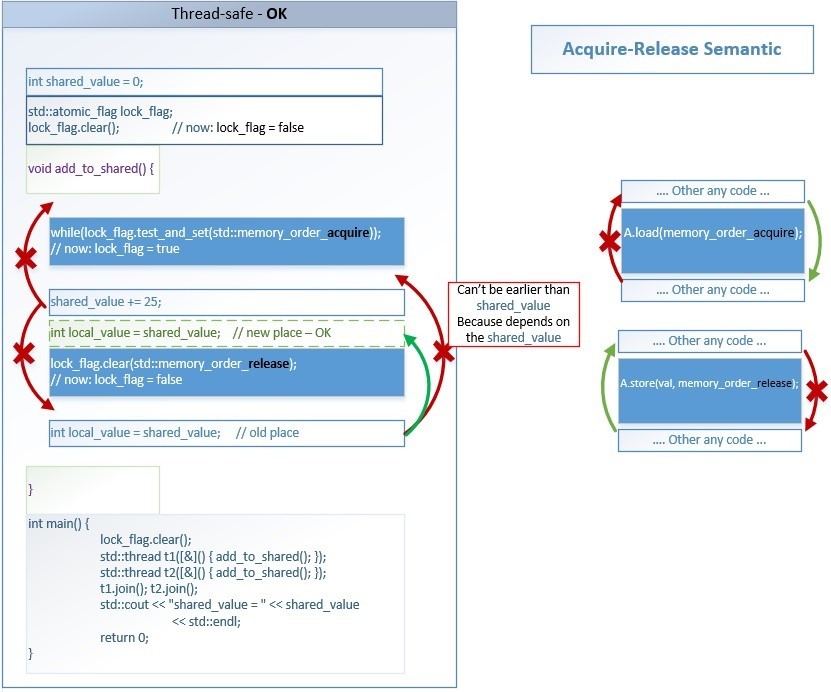
[19]
coliru.stacked-crooked.com/a/1ec9a0c2b10ce864バリアの意味は非常に単純です-コンパイラーオプティマイザーは、命令をクリティカルセクションから外部に移動することを許可されていません。
- memory_order_ acquireの後にある命令は、その前に実行できません。
- memory_order_ releaseの前にある命令は、それより後に実行することはできません。
パフォーマンスを最適化するために、コンパイラー(コンパイル時)またはプロセッサー(ランタイム)によって、独立した命令の実行順序のその他の変更を実行できます。
たとえば、文字列
int new_shared_value = shared_value; lock_flag.clear(std :: memory_order_release)の前に実行できます
。 。 この並べ替えは許容され、データ競合を作成しません。 複数のストリームに共通のデータにアクセスするすべてのコードは、常に2つの取得および解放バリアに囲まれています。 外部には、ストリームのローカルデータでのみ機能するコードがあります。実行される順序は関係ありません。 スレッドにローカルな依存関係は、シングルスレッド実行の場合と同じ方法で常に保持されるため、
int new_shared_value = shared_value; shared_value + = 25より前に実行することはできません
。禁止されているものと、取得-解放の障壁がクリティカルセクションを許可するものは何ですか:
- クリティカルセクションの内部にある操作は、クリティカルセクションの外部で実行できません。
- クリティカルセクション外の操作は、クリティカルセクション内で実行できます(追加のメモリバリアがない場合)。
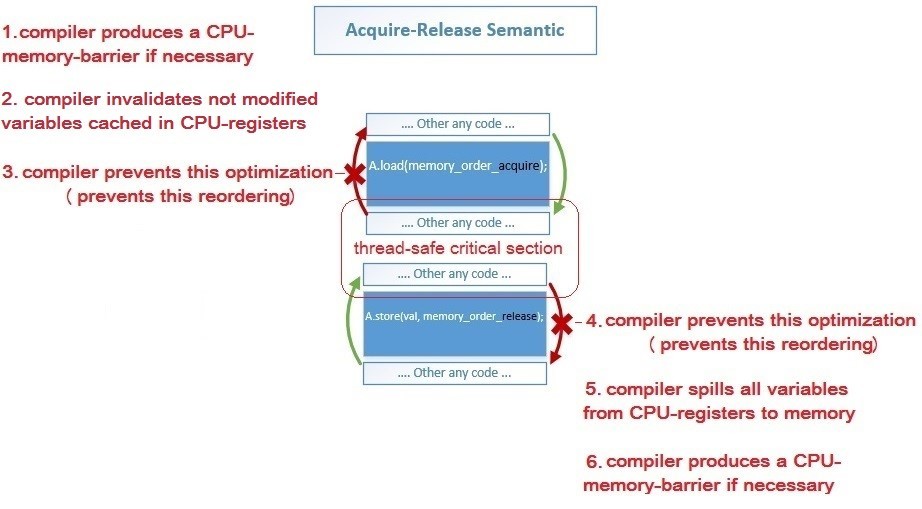
std :: memory_orderでコンパイラが実行する特定のアクション:
- 1、6:コンパイラーは、特定のプロセッサー・アーキテクチャーにこれらのバリアーが必要な場合、ロード操作の取得バリアーとストア操作のリリースバリアーのアセンブラー命令を生成します。
- 2 :コンパイラは、別のスレッドによって変更されたこれらの変数の値を再ロードするために、プロセッサレジスタの変数の以前のキャッシュをキャンセルします-ロード(取得)操作後
- 5 :コンパイラは、すべての変数の値をプロセッサレジスタからメモリに保存して、他のスレッドから見えるようにします。 こぼれる( リンク )-ストア(リリース)の前
- 3、4 :コンパイラーは、オプティマイザーが禁止された方向に命令を並べ替えることを防ぎます-赤い矢印で示されています
次に、Acquire-Releaseの代わりにRelaxed-Releaseセマンティクスを使用した場合に何が起こるかを見てみましょう。
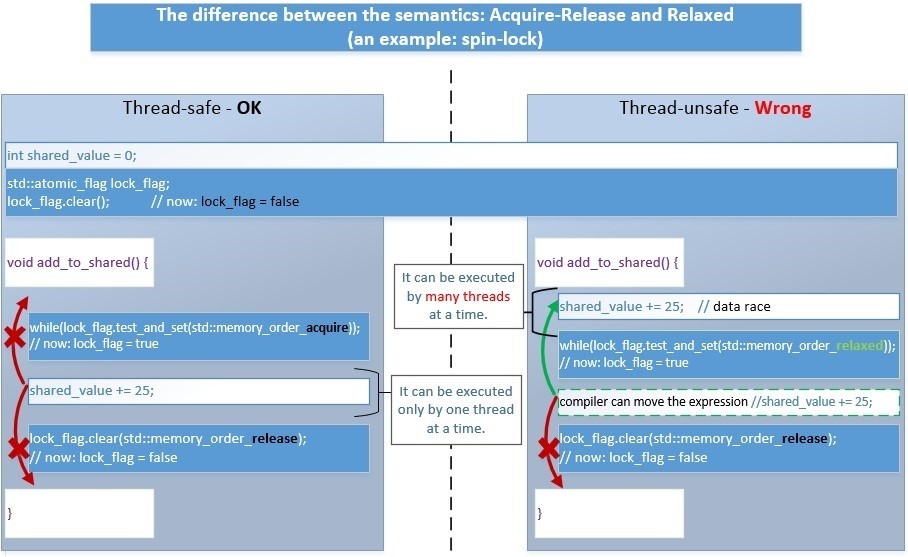
- 左へ。 Acquire-Releaseの場合、すべてが正しく実行されます。
- 右へ。 Relaxed-Releaseの場合、アルゴリズムは次のように正しく動作しません。 ロックによって保護されているクリティカルセクション内のコードの一部は、コンパイラまたはプロセッサによって外側に移動できます。 その後、データ競合の問題が発生します-ロック前であっても、多くのスレッドが非アトミック操作が実行されるデータと同時に動作を開始します-誤った結果を得ることができます。
アトミック操作の助けを借りてのみ、一般的なデータを介してすべてのロジックを実装することは通常不可能であることに注意してください。
したがって、よりシンプルで高速です。1つのアトミック操作で、フラグ「closed」を設定し、フローに共通のデータですべての非アトミック操作を実行し、フラグ「open」を設定します。このプロセスを時間的に概略的に示します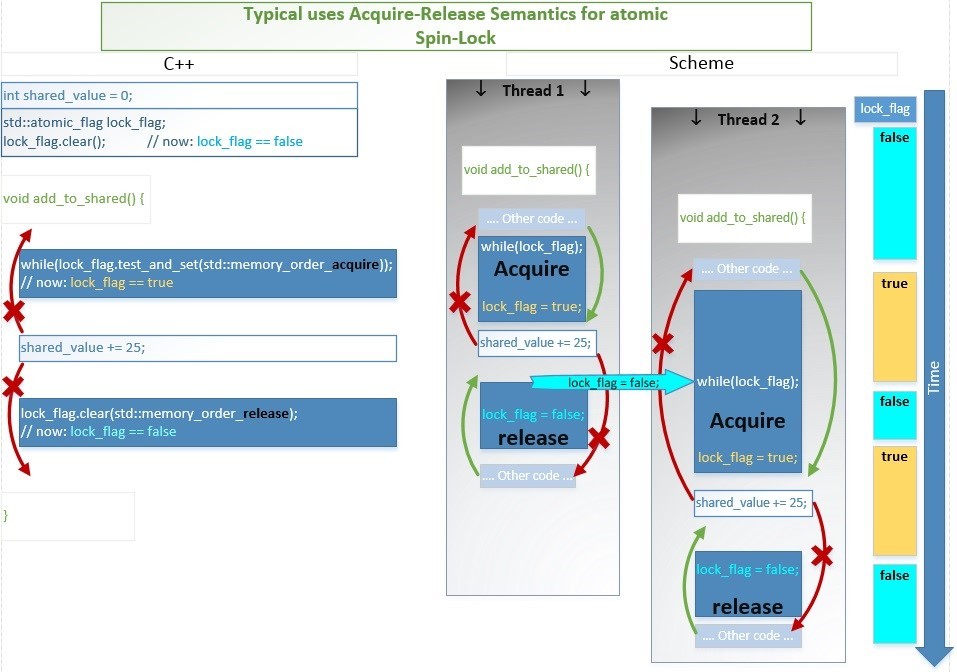 。たとえば、2つのスレッドがadd_to_shared()関数の実行を開始します。
。たとえば、2つのスレッドがadd_to_shared()関数の実行を開始します。- スレッド1は少し早く入り、1つのアトミック命令test_and_set()で一度に2つの操作を実行します:lock_flag == falseかどうかをチェックし、trueに設定(つまり、スピンロックをブロック)し、falseを返します。したがって、式while(lock_flag.test_and_set()); クリティカルセクションコードはすぐに終了し、実行を開始します。
- 現時点でスレッド2は、このアトミックなtest_and_set()命令の実行も開始します。lock_flag== falseであるかどうかを確認し、trueに設定します。したがって、式while(lock_flag.test_and_set()); while(lock_flag)まで実行されます;
- スレッド1は、加算操作shared_value + = 25を実行します。そして、アトミック操作によって値lock_flag = falseを設定します(つまり、スピンロックを解除します)。
- スレッド2、最後に条件lock_flag == falseを待って、lock_flag = trueを割り当て、falseを返し、ループを終了します。次に、shared_value + = 25を追加します。また、lock_flag = false(スピンロックのロック解除)を割り当てます。
この章の冒頭で、2つの例を挙げました。- std :: atomic_flagおよびtest_and_set()を使用:[21] coliru.stacked-crooked.com/a/1ec9a0c2b10ce864
- std :: atomic <int>およびcompare_exchange_weak()を使用:[22] coliru.stacked-crooked.com/a/03c019596b65199a
これらの操作の詳細については、リンクをご覧ください。en.cppreference.com / w / cpp / atomic / atomicGCCコンパイラーによって生成されるx86_64のアセンブラーコードが、これら2つの例でどのように異なるかを見てみましょう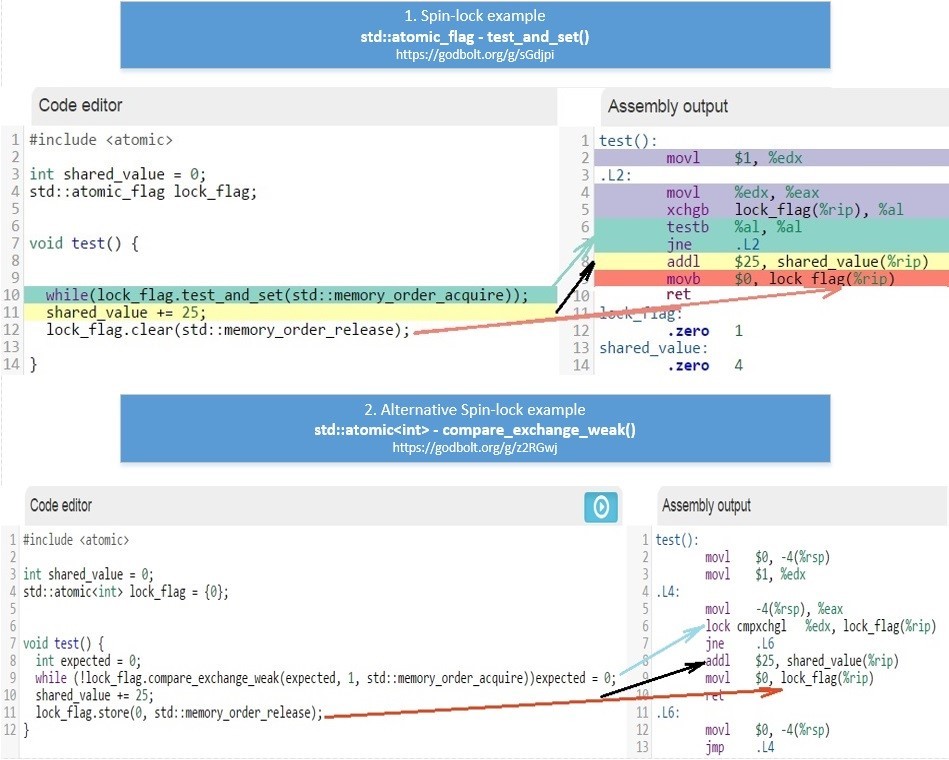 。便宜上、1つのクラスに結合できます。
。便宜上、1つのクラスに結合できます。 class spinlock_t { std::atomic_flag lock_flag; public: spinlock_t() { lock_flag.clear(); } bool try_lock() { return !lock_flag.test_and_set(std::memory_order_acquire); } void lock() { for (size_t i = 0; !try_lock(); ++i) if (i % 100 == 0) std::this_thread::yield(); } void unlock() { lock_flag.clear(std::memory_order_release); } };
クラスの使用例は、spinlock_t次のリンクを:[23] coliru.stacked-crooked.com/a/92b8b9a89115f080あなたが障壁の種類、使用するとそれがx86_64版でコンパイルされます、私は次の表を与える理解することはできません決してことを確認します。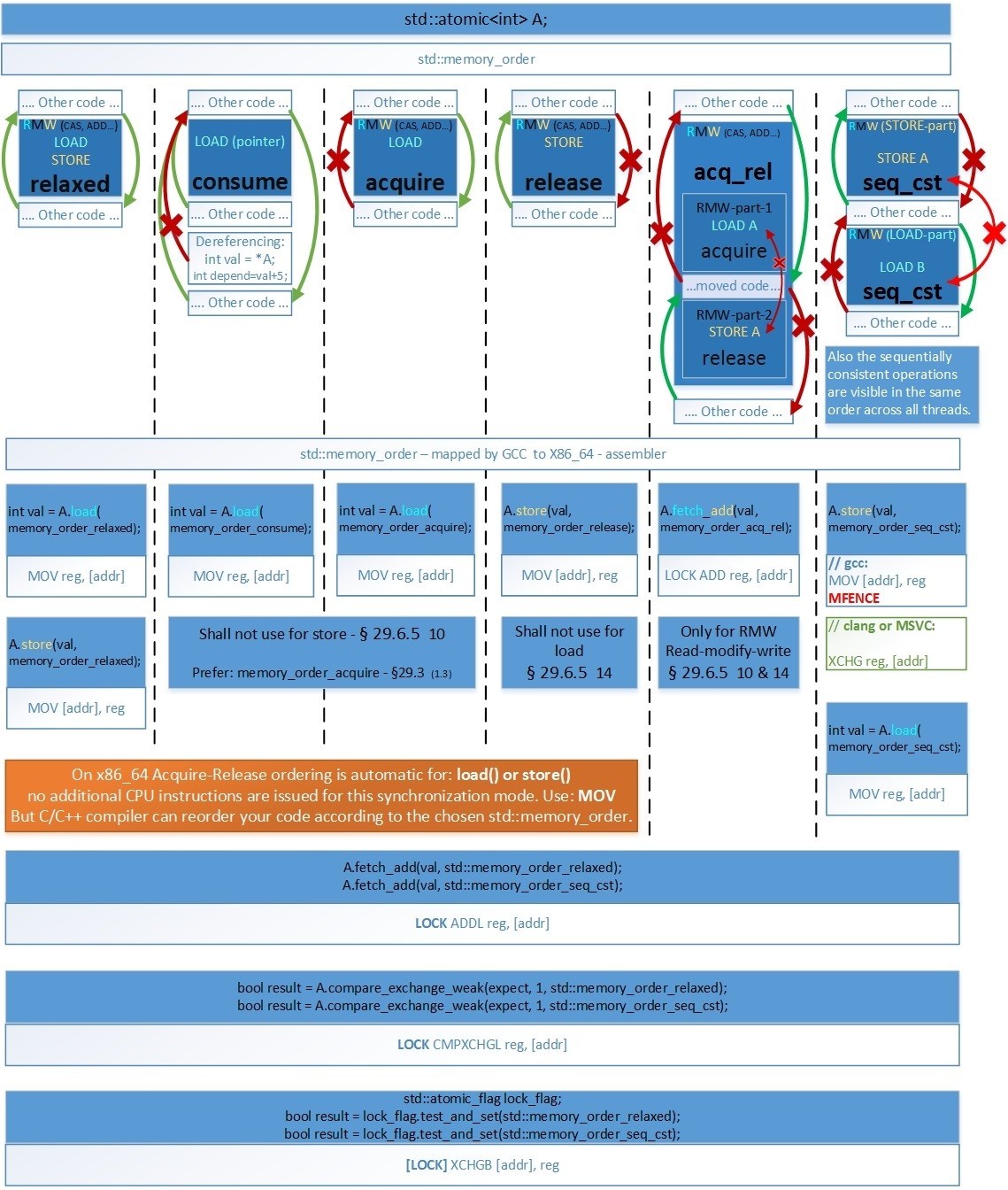 画像がフルサイズで表示することができますリンクをたどります:hsto.org/files/4f8/7b4/1b6/4f87b41b64a54549afca679af1028f84.jpgコンパイラが最適化のためにアセンブラ命令を交換できない場合にアセンブラx86_64でコードを記述している場合にのみ、以下を知る必要があります。
画像がフルサイズで表示することができますリンクをたどります:hsto.org/files/4f8/7b4/1b6/4f87b41b64a54549afca679af1028f84.jpgコンパイラが最適化のためにアセンブラ命令を交換できない場合にアセンブラx86_64でコードを記述している場合にのみ、以下を知る必要があります。- seq_cst . (Clang MSVC) GCC – Store Sequential Consistency, : a.store(val, memory_order_seq_cst); — Clang MSVC [LOCK] XCHG reg, [addr], CPU-Store-buffer , MFENCE. GCC MOV [addr], reg MFENCE.
- RMW (CAS, ADD…) always seq_cst . なぜなら RMW (Read-Modify-Write) x86_64 LOCK, Store-Buffer, Sequential-Consistency . memory_order RMW , memory_order_acq_rel.
- LOAD(acquire), STORE(release) . , x86_64 4 (relaxed, consume, acquire, release) – .. x86_64 acquire-release – - MESIF(Intel) / MOESI (AMD). Write Back ( , Un-cacheable Write Combined – Mapped Memory Area from Device – Acquire-semantic).
私たちが知っているように、依存する操作はどこでも並べ替えることはできません。たとえば、(Read-X、Write-X)または(Write-X、Read-X)x86_64のHerb Sutterのパフォーマンスからのスライド:https : //onedrive.live。 com / view.aspx?resid = 4E86B0CF20EF15AD!24884&app = WordPdf&authkey =!AMtj_EflYn2507c•x86_64では順序を変更できません。- 読み取りX-読み取りY
- 読み取りX-書き込みY
- 書き込みX-書き込みY
•x86_64では、任意の順序を変更できます:Write-X <–> Read-Y。これを防ぐために、std :: memory_order_seq_cstバリアが使用されます。これは、コンパイラに応じて4つのバージョンのx86_64コードを生成できます。- ロード:MOV(メモリから)ストア:MOV(メモリへ)、MFENCE
- ロード:MOV(メモリから)ストア:LOCK XCHG(メモリへ)
- ロード:MFENCE + MOV(メモリから)ストア:MOV(メモリへ)
- ロード:LOCK XADD(0、メモリから)ストア:MOV(メモリへ)
アーキテクチャー(x86_64、PowerPC、ARMv7、ARMv8、AArc64、Itanium)のプロセッサー命令とメモリーバリアーのコンプライアンスの概要表:www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.htmlさまざまなコンパイラーの実際のアセンブラーコードを表示リンクをたどることができます。また、ARM、ARM64、AVR、PowerPCなどの他のアーキテクチャも選択できます。GCC 6.1(x86_64):Clang 3.8(x86_64):また、CAS(Compare-and-swap)命令の順序にさまざまなメモリバリアが及ぼす影響を表に簡単に示します。en.cppreference.com / w / cpp / atomic / atomic / compare_exchange
メモリアクセス操作の並べ替えの例
次に、4つの連続した操作(LOAD、STORE、LOAD、STORE)からの並べ替えのより複雑な例を示します。- 青い長方形はアトミック操作です。
- 明るい青色の内側の暗い青色の四角形(例3および4)は、複数のアトミック操作で構成される複合アトミック読み取り-変更-書き込み(RMW)命令の一部です。
- 白い長方形は、通常の非原子操作です。
アトミック変数を使用した操作の周りに、通常の変数を使用した操作の可能な並べ替えを示す4つの例をそれぞれ示します。ただし、例1および3のみで、アトミック操作を並べ替えることも可能です。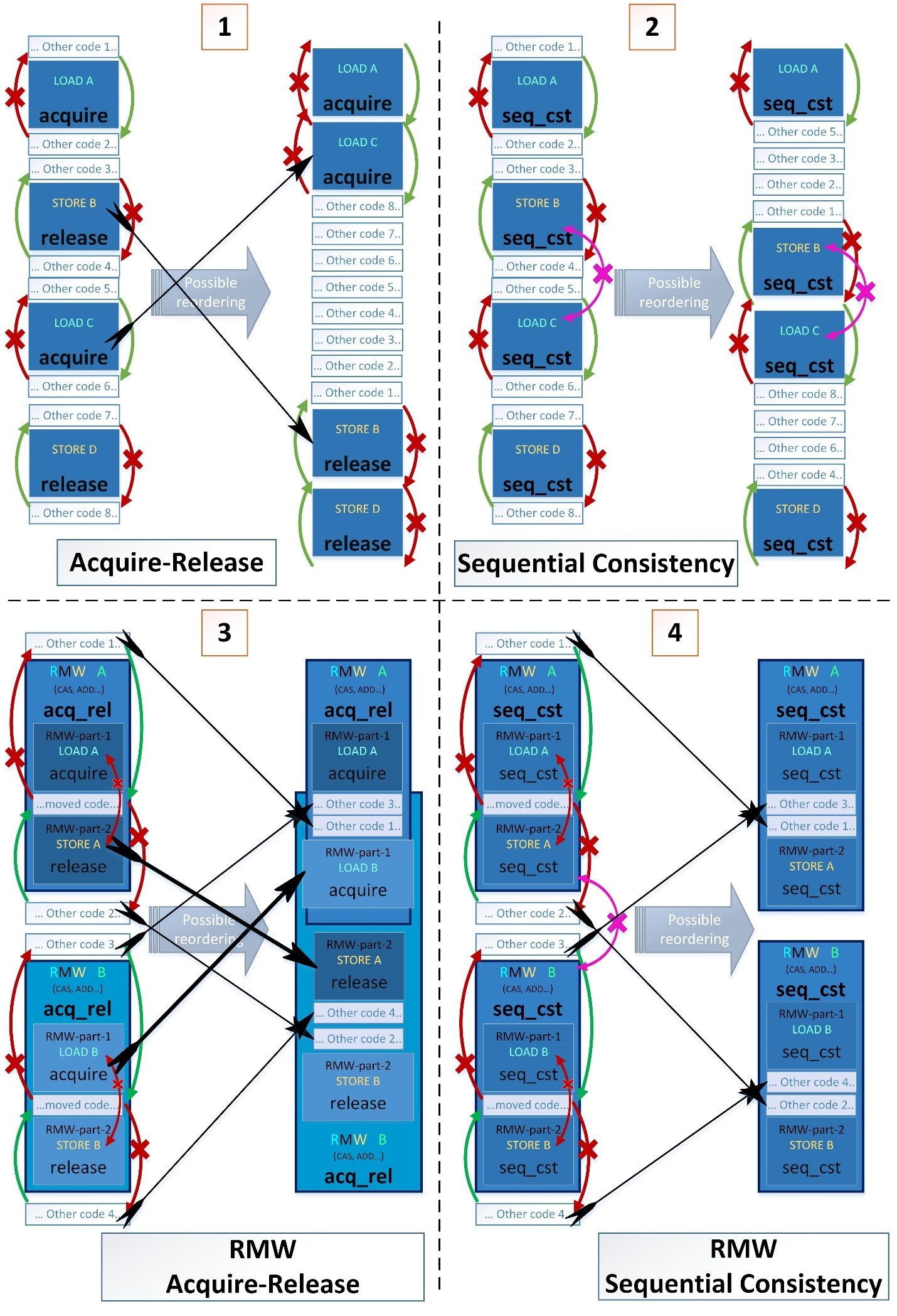 最初のケースは、いくつかのクリティカルセクションを1つに融合できるという点で興味深いものです。コンパイラはコンパイル時にそのような並べ替えを実行できませんが、コンパイラは実行時にプロセッサがこの並べ替えを実行できるようにします。したがって、異なるスレッドの異なるシーケンスで実行されるクリティカルセクションのマージは、最初の命令シーケンスがプロセッサに表示されるため、デッドロックにつながることはありません。したがって、プロセッサは事前に2番目のクリティカルセクションに入るように試みますが、できない場合は、最初のクリティカルセクションの実行を継続し、完全に完了した後、2番目のクリティカルセクションに入るのを待ちます。3番目のケースは、2つの複合アトミック命令の一部を並べ替えることができるという点で興味深い:STORE A <-> LOAD B.2番目のケースは、std :: memory_order_seq_cstが最も強力な障壁であり、それ自体のアトミックまたは非アトミック操作の並べ替えを禁止しているように見えるという点で興味深いものです。ただし、seq_cstバリアには、取得/解放と比較して1つの追加プロパティしかありません。両方のアトミック操作にseq_cstバリアがある場合のみ、操作のシーケンスはSTORE-A(seq_cst)です。LOAD-B(seq_cst); 並べ替えることはできません。C ++標準からの2つの引用符を次に示します。
最初のケースは、いくつかのクリティカルセクションを1つに融合できるという点で興味深いものです。コンパイラはコンパイル時にそのような並べ替えを実行できませんが、コンパイラは実行時にプロセッサがこの並べ替えを実行できるようにします。したがって、異なるスレッドの異なるシーケンスで実行されるクリティカルセクションのマージは、最初の命令シーケンスがプロセッサに表示されるため、デッドロックにつながることはありません。したがって、プロセッサは事前に2番目のクリティカルセクションに入るように試みますが、できない場合は、最初のクリティカルセクションの実行を継続し、完全に完了した後、2番目のクリティカルセクションに入るのを待ちます。3番目のケースは、2つの複合アトミック命令の一部を並べ替えることができるという点で興味深い:STORE A <-> LOAD B.2番目のケースは、std :: memory_order_seq_cstが最も強力な障壁であり、それ自体のアトミックまたは非アトミック操作の並べ替えを禁止しているように見えるという点で興味深いものです。ただし、seq_cstバリアには、取得/解放と比較して1つの追加プロパティしかありません。両方のアトミック操作にseq_cstバリアがある場合のみ、操作のシーケンスはSTORE-A(seq_cst)です。LOAD-B(seq_cst); 並べ替えることはできません。C ++標準からの2つの引用符を次に示します。- 厳密で均一な相互実行順序は、memory_order_seq_cstバリア、Standard C ++ 11§29.3(3)を使用した操作に対してのみ保持されます:www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
There shall be a single total order S on all memory_order_seq_cst operations , consistent with the “happens before” order and modification orders for all affected locations, such that each memory_order_seq_cst operation B that loads a value from an atomic object M observes one of the following values: …
- memory_order_seq_cst memory_order_seq_cst– , Standard C++11 § 29.3 (8): www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
[注:memory_order_seq_cstは、データの競合がなく、memory_order_seq_cst操作のみを使用するプログラムに対してのみ、順次整合性を保証します。弱い順序付けを使用すると、細心の注意を払わない限り、この保証は無効になります。特に、memory_order_seq_cstフェンスは、フェンス自体に対してのみ完全な順序を保証します。一般に、フェンスを使用して、順序付け仕様がより弱いアトミック操作の順次一貫性を復元することはできません。-終了ノート]
seq_cst操作を中心に非seq_cst操作(アトミックおよび非アトミック)を並べ替えるために許可されている指示は、取得/解放と同じです。- a.load(memory_order_seq_cst) -と同じ順序ではないseq_cstオペレーションを保証するa.load(memory_order_acquire)
- b.store(memory_order_seq_cst) -と同じ順序ではないseq_cstオペレーションを保証するb.store(memory_order_release)
より厳密な順序も可能ですが、保証されていません。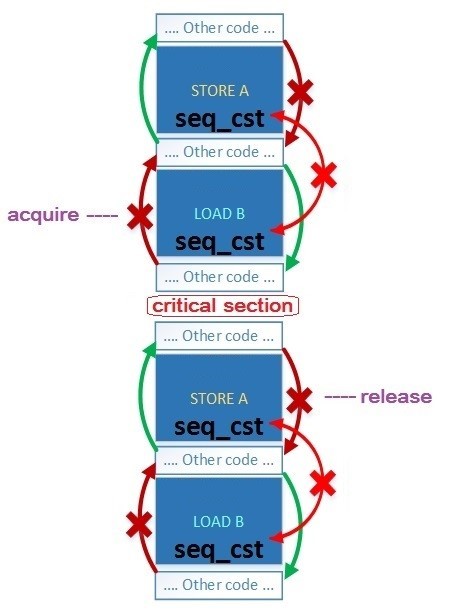 seq_cstの場合、および取得と解放の場合:STORE(seq_cst)の前には何もできず、LOAD(seq_cst)の前には何もできません。しかし、逆方向では並べ替えが可能です。次に、コンパイラーがプロセッサーに許可する命令の順序の変更、たとえばx86_64およびPowerPCのGCC-アセンブラーx86_64およびPowerPCのC ++コードと生成コードの例を示します。memory_order_seq_cst –操作の前後で、次の順序変更が可能です。
seq_cstの場合、および取得と解放の場合:STORE(seq_cst)の前には何もできず、LOAD(seq_cst)の前には何もできません。しかし、逆方向では並べ替えが可能です。次に、コンパイラーがプロセッサーに許可する命令の順序の変更、たとえばx86_64およびPowerPCのGCC-アセンブラーx86_64およびPowerPCのC ++コードと生成コードの例を示します。memory_order_seq_cst –操作の前後で、次の順序変更が可能です。- x86_64 Store-Load. つまり :
STORE-C(release); LOAD-B(seq_cst); ==> LOAD-B(seq_cst); STORE-C(release);
なぜなら x86_64, MFENCE STORE(seq_cst), LOAD(seq_cst) LOAD(release) LOAD(relaxed): godbolt.org/g/BsLqas - PowerPC Store-Load, Store-Store . つまり :
STORE-A(seq_cst); STORE-C(relaxed); LOAD-C(relaxed); ==>
LOAD-C(relaxed); STORE-C(relaxed); STORE-A(seq_cst);
なぜならPowerPCアーキテクチャでは、seq_cstバリアの場合、sync(hwsync)はSTORE(seq_cst)およびLOAD(seq_cst)にのみ追加されるため、STORE(seq_cst)とLOAD(seq_cst)の間にあるすべての命令はSTORE(seq_cst)の前に実行できます:godbolt.org/g/dm7tWd
セマンティクスを持つ3つの変数の例、seq_cstおよびrelaxedをより詳細に示します。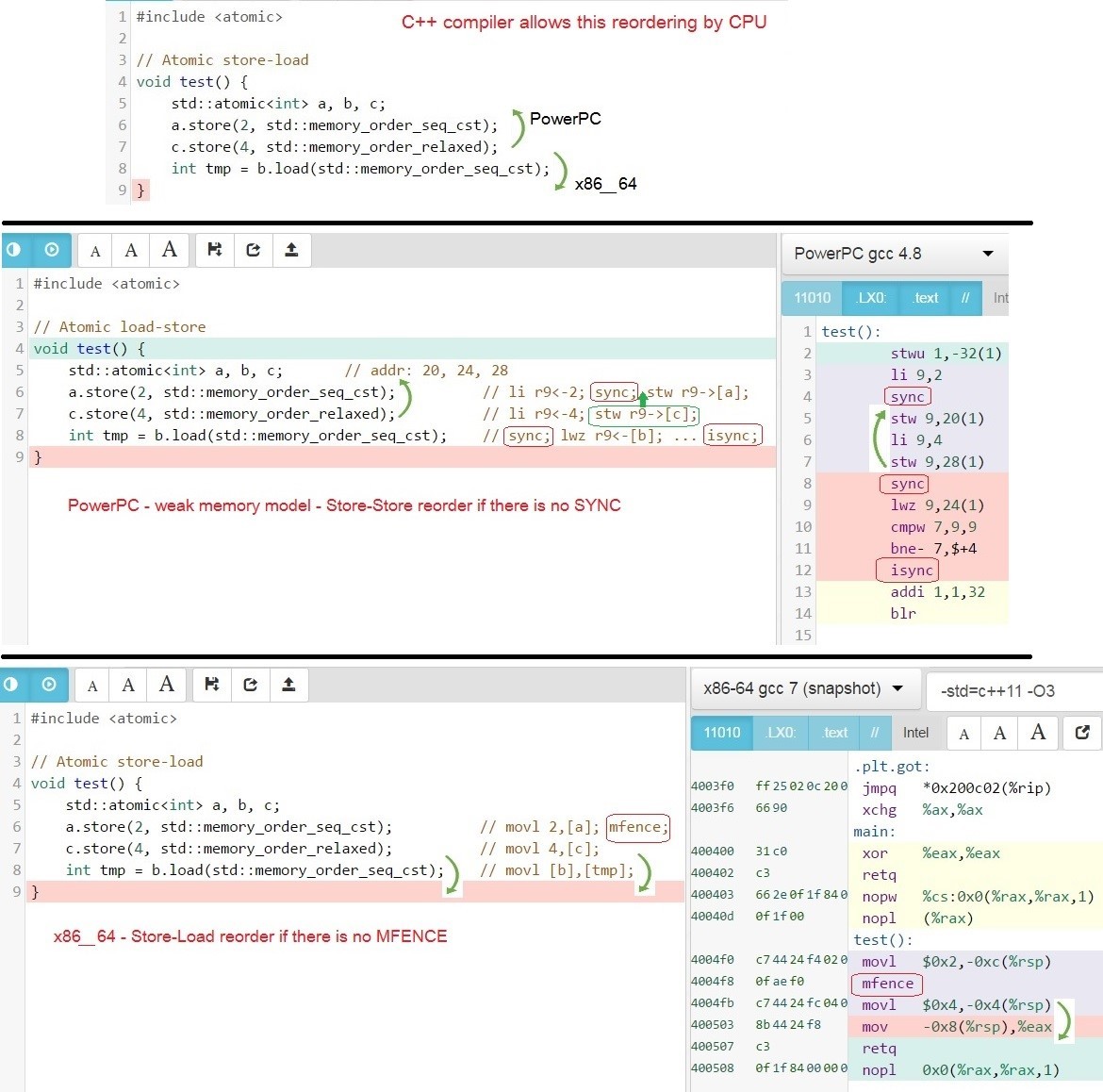 C ++コンパイラができる並べ替えなぜそのような注文変更が可能ですか?C ++コンパイラはx86_64プロセッサとPowerPCプロセッサのこのような並べ替えを可能にするアセンブラコードを生成するため、
C ++コンパイラができる並べ替えなぜそのような注文変更が可能ですか?C ++コンパイラはx86_64プロセッサとPowerPCプロセッサのこのような並べ替えを可能にするアセンブラコードを生成するため、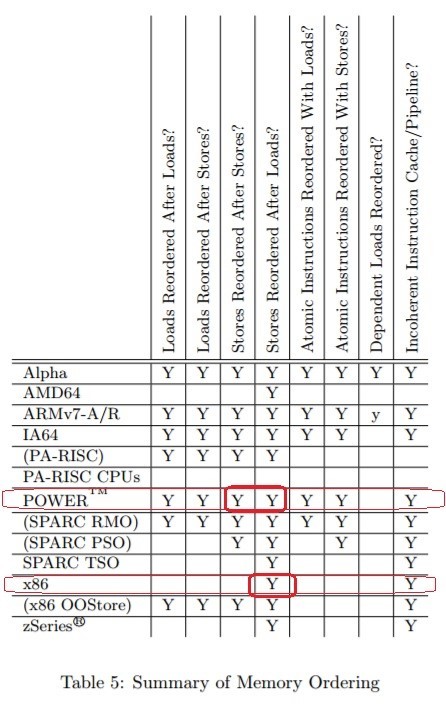 命令間にアセンブラバリアがない場合、さまざまなCPUは並べ替えを実行できます。「メモリバリア:ソフトウェアハッカーのハードウェアビュー」Paul E. McKenney 2010年6月7日-表5:www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdfデータ交換には別の機能がありますスレッド間。4スレッド以上の相互作用で現れます。次の操作の少なくとも1つが最も厳しいバリアmemory_order_seq_cstを使用しない場合、異なるスレッドは同じ変更を異なる順序で見ることができます。
命令間にアセンブラバリアがない場合、さまざまなCPUは並べ替えを実行できます。「メモリバリア:ソフトウェアハッカーのハードウェアビュー」Paul E. McKenney 2010年6月7日-表5:www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdfデータ交換には別の機能がありますスレッド間。4スレッド以上の相互作用で現れます。次の操作の少なくとも1つが最も厳しいバリアmemory_order_seq_cstを使用しない場合、異なるスレッドは同じ変更を異なる順序で見ることができます。例:
- スレッド1が最初に値を変更した場合
- -2
- -3 -2, -1
- -4 -1, -2
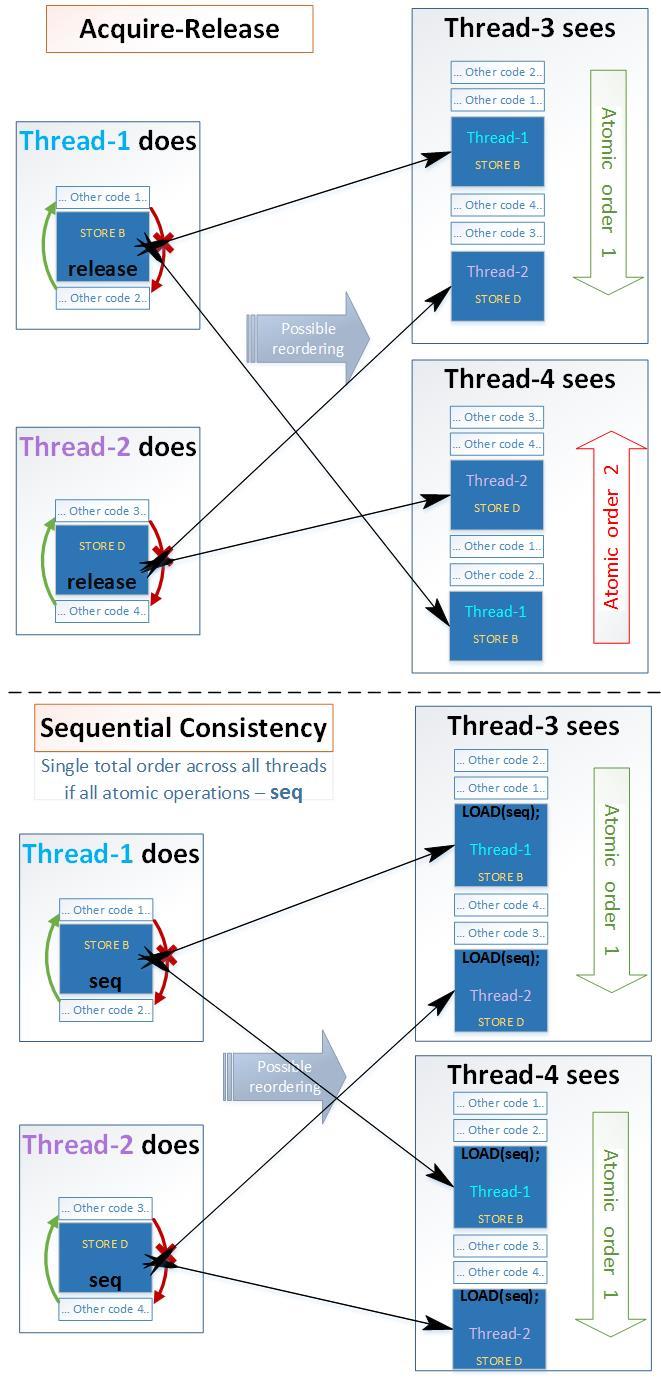
これは、キャッシュコヒーレントプロトコルのハードウェア機能、追加のロード/ストアバッファ、およびプロセッサ内のコアの場所のトポロジにより可能です。この場合、いくつかの2つのカーネルは、他のカーネルによって行われた変更を見る前に、互いに行われた変更を見ることができます。すべてのスレッドが同じ順序で変更を認識するように、つまりあっ単全順序(C ++ 11§29.3(3)) -すべての操作(ロード、ストア、RMW)は、メモリバリアmemory_order_seq_cst上で実行することが必要である:en.cppreference.com/w/cpp/atomic/memory_order以下の例では、プログラムアサートエラー(z.load()!= 0)で失敗することはありません。なぜなら
すべての操作は、最も厳しいメモリバリアmemory_order_seq_cstを適用されます。coliru.stacked-crooked.com/a/52726a5ad01f6529図は、順序の変更がシーケンシャルのために獲得-リリースセマンティクスとセマンティクス-EH 4ストリームの例については、可能であることを示します。- Acuire-Release:
•通常の変数の順序を許可された方向
に変更することができます。•Acquire-Releaseセマンティクスでアトミック変数の順序を変更することができます。 - シーケンシャル:
•許可された方向で通常の変数の順序を変更することは可能です。• シーケンシャルセマンティクスでアトミック変数の順序を変更することはできません
。
アクティブスピンロックと再帰的スピンロック
独自のアクティブロック(スピンロックと再帰的スピンロック)を実装する例により、アトミック操作でメモリバリアがどのように使用されるかを示します。さらに、テーブル全体(テーブルロック)をロックするのではなく、テーブルの個々の行(行ロック)をロックするためにこれらのロックが必要になります。これにより、並列度が向上し、パフォーマンスが向上します。異なるスレッドは、テーブル全体をブロックすることなく、異なる行を並行して処理できます。オペレーティングシステムによって提供される同期オブジェクトの数は制限される場合があります。テーブル内の行の数は数百万または数十億になる可能性があり、多くのオペレーティングシステムではそれほど多くのミューテックスを作成できません。また、スピンロックの数はRAMが許す限りいくつでも構いません。したがって、個々の行をブロックするために使用できます。実際、スピンロックは各行に+ 1バイト、または再帰スピンロックを使用する場合は+17バイトです(フラグに1バイト+再帰カウンターに8バイト+ thread_idスレッド番号に8バイト)。recursive_spinlockと通常のスピンロックの主な違いは、同じスレッドによってrecursive_spinlockを何度もブロックできることです。再帰的なネストされたロックをサポートします。同様に、std :: recursive_mutexとstd :: mutexは異なります。ネストされたロックの例:recursive_spinlock_tの仕組みを見てみましょう。MSVC 2013コンパイラでこのコードを実行しようとすると、std :: this_thread :: get_id()function:connect.microsoft.com/VisualStudio/feedback/details/1558211の ために非常に強力なスローダウンが発生します。recursive_spinlock_tクラスをファイナライズして、 __declspec(スレッド)変数のキャッシュされたthread-idは、C ++ 11標準のthread_localに類似しています。この例はMSVC 2013でも良好なパフォーマンスを示します。[28] coliru.stacked-crooked.com/a/3090a9778d02f6eaこれは古いMSVC 2013の一時的な修正であるため、このようなソリューションの美しさについては考えません。ほとんどの場合、mutexの繰り返し(再帰的)ブロックは設計エラーであると考えられていますが、今回の場合、遅いが動作するコードである可能性があります。第二に、誰もが間違っており、再帰ロックが埋め込まれているため、recursive_spinlock_tはずっと遅くなり、spinlock_tは永久にハングアップします。スレッドセーフsafe_ptr <T>を使用する場合、両方の例は非常に論理的ですが、2番目の例はrecursive_spinlockでのみ機能します。 safe_int_spin_recursive->second++;
独自の高性能共有ミューテックスの実装
ご存知のように、新しいタイプのミューテックスが新しいC ++標準に徐々に登場しました:en.cppreference.com/w/cpp/thread- C ++ 11:mutex、timed_mutex、recursive_mutex、recursive_timed_mutex
- C ++ 14:shared_timed_mutex
- C ++ 17:shared_mutex
 shared_mutexは、その時点でこのデータを変更するスレッドが存在しない場合、多くのスレッドが同じデータを同時に読み取ることができるミューテックスです。 shared_mutexはすぐには表示されませんでした。通常のstd :: mutexと比較したパフォーマンスについては議論がありました。リーダーの数のカウンターを使用したshared_mutexの古典的な実装は、多くのリーダーが長時間ロックを保持している場合にのみ速度の利点を示しました-つまり彼らが長い間読んだとき短い読み取りでは、shared_mutexはプログラムの速度を低下させ、コードを複雑にするだけです。しかし、すべてのshared_mutex実装は短い読み取りで非常に遅いのでしょうか?std :: shared_mutexおよびboost :: shared_mutexの動作が遅い主な理由は、アトミックリーダーカウンターです。各読み取りストリームは、ブロックされるとカウンターをインクリメントし、ロックが解除されるとカウンターをデクリメントします。その結果、スレッドはコア間の1つのキャッシュラインを常に駆動します(つまり、排他状態(E)を駆動します)。このような実装のロジックによれば、各読み取りストリームは現在のリーダーの数をカウントしますが、これは読み取りストリームにとって絶対に重要ではありません。彼にとって重要なのは、一人の作家がいるべきではないということです。また、インクリメントとデクリメントはRMW操作であり、常にストアバッファクリーンアップ(MFENCE x86_64)を生成し、x86_64 asmレベルでシーケンシャル整合性の最も遅いセマンティクスに実際に対応します。この問題を解決してみましょう。競合のない書き込みとして分類されるタイプのアルゴリズムがあります-複数のストリームが書き込み可能な単一のメモリセルがない場合。また、より一般的なケースでは、複数のスレッドが書き込むことができる単一のキャッシュラインはありません。共有ミューテックスが、リーダーのみの存在下で、書き込み競合なしとして分類されるためには、リーダーが互いに干渉しないことが必要です-つまりそのため、各リーダーは自分の個別のセルにフラグ(読み取ったもの)を書き込み、読み取りの最後に同じセルのフラグをRMW操作なしで削除します。書き込みコンテンションフリーは最も生産的な保証であり、待機フリーやロックフリーよりも生産的です。偽共有を排除するために、各セルを個別のキャッシュラインに配置する必要があります。また、セルが同じキャッシュラインの16に厳密に配置される可能性があります。パフォーマンスの低下はCPUとスレッドの数に依存します。誤った共有を排除するには、各変数を個別のキャッシュラインに配置する必要があります。このため、C ++ 17にはアライメント(std :: hardware_destructive_interference_size)が存在し、以前のバージョンではプロセッサー依存のソリューションchar tmp [60]を使用できます。(x86_64では、キャッシュラインサイズは64バイトです):
shared_mutexは、その時点でこのデータを変更するスレッドが存在しない場合、多くのスレッドが同じデータを同時に読み取ることができるミューテックスです。 shared_mutexはすぐには表示されませんでした。通常のstd :: mutexと比較したパフォーマンスについては議論がありました。リーダーの数のカウンターを使用したshared_mutexの古典的な実装は、多くのリーダーが長時間ロックを保持している場合にのみ速度の利点を示しました-つまり彼らが長い間読んだとき短い読み取りでは、shared_mutexはプログラムの速度を低下させ、コードを複雑にするだけです。しかし、すべてのshared_mutex実装は短い読み取りで非常に遅いのでしょうか?std :: shared_mutexおよびboost :: shared_mutexの動作が遅い主な理由は、アトミックリーダーカウンターです。各読み取りストリームは、ブロックされるとカウンターをインクリメントし、ロックが解除されるとカウンターをデクリメントします。その結果、スレッドはコア間の1つのキャッシュラインを常に駆動します(つまり、排他状態(E)を駆動します)。このような実装のロジックによれば、各読み取りストリームは現在のリーダーの数をカウントしますが、これは読み取りストリームにとって絶対に重要ではありません。彼にとって重要なのは、一人の作家がいるべきではないということです。また、インクリメントとデクリメントはRMW操作であり、常にストアバッファクリーンアップ(MFENCE x86_64)を生成し、x86_64 asmレベルでシーケンシャル整合性の最も遅いセマンティクスに実際に対応します。この問題を解決してみましょう。競合のない書き込みとして分類されるタイプのアルゴリズムがあります-複数のストリームが書き込み可能な単一のメモリセルがない場合。また、より一般的なケースでは、複数のスレッドが書き込むことができる単一のキャッシュラインはありません。共有ミューテックスが、リーダーのみの存在下で、書き込み競合なしとして分類されるためには、リーダーが互いに干渉しないことが必要です-つまりそのため、各リーダーは自分の個別のセルにフラグ(読み取ったもの)を書き込み、読み取りの最後に同じセルのフラグをRMW操作なしで削除します。書き込みコンテンションフリーは最も生産的な保証であり、待機フリーやロックフリーよりも生産的です。偽共有を排除するために、各セルを個別のキャッシュラインに配置する必要があります。また、セルが同じキャッシュラインの16に厳密に配置される可能性があります。パフォーマンスの低下はCPUとスレッドの数に依存します。誤った共有を排除するには、各変数を個別のキャッシュラインに配置する必要があります。このため、C ++ 17にはアライメント(std :: hardware_destructive_interference_size)が存在し、以前のバージョンではプロセッサー依存のソリューションchar tmp [60]を使用できます。(x86_64では、キャッシュラインサイズは64バイトです):
フラグを設定する前に、リーダーはライターがあるかどうかを確認します。つまり、排他ロックがあります。そして以来
共有ミューテックスは、ライターが非常に少ない場合に使用されます。使用されるすべてのカーネルは、共有状態(S)のキャッシュL1にこの値のコピーを保持でき、そこから3クロックサイクルの間、ライターのフラグの値が変更されるまで取得されますすべてのライターには、いつものように、1つの同じwant_x_lockフラグがあります-これは、現時点でライターがいることを意味します。スレッドライターは、RMW操作を使用してインストールおよび削除します。 lock(): while(!want_x_lock.compare_exchange_weak(flag, true, std::memory_order_acquire))
unlock(): want_x_lock.store(false, std::memory_order_release);
ただし、読者が互いに干渉しないように、異なるメモリセルに共有ロックに関する情報を書き込む必要があります。これらのロック用の配列を選択します。テンプレートパラメータで設定されるサイズは、デフォルトでは20です。lock_shared()が初めて呼び出されると、ストリームは自動的に登録され、この配列の特定の場所を占有します。配列のサイズよりも多くのスレッドがある場合、lock_shared()を呼び出すときの残りのスレッドはライターで排他ロックを引き起こします。ストリームはめったに作成されず、オペレーティングシステムがストリームを作成するのにかかる時間は非常に長いため、オブジェクトに新しいストリームを登録する時間はごくわずかです。明らかなエラーがないことを確認します。すべてが正しく機能することを例で示してから、アプローチの正確性を概略的に証明します。以下は、リーダーが互いに干渉しない高速共有ロックの例です。[30] coliru.stacked-crooked.com/a/b78467b7a3885e5b- 共有ロック中は、オブジェクトを変更することはできません。2つの再帰的な共有ロックのこの行は、これを示しています。assert(readonly_safe_map_string-> at( "apple")== readonly_safe_map_string-> at( "potato")); -両方の行の値は常に等しいはずです、なぜなら stdの2行を変更します:: 1つの排他ロックstdの下のマップ:: lock_guard
- 読み取り中に、実際にlock_shared()関数を呼び出します。ループを2回の反復に減らし、データを変更する行を削除し、std :: mapの最初の2つの挿入のみをmain()関数に残します。次に、Sという文字の出力をlock_shared()関数に追加し、Xという文字をlock()関数に追加します。最初に2つの挿入Xがあり、次に文字Sだけがあることがわかります。実際には、constオブジェクトを読み取るときにshared_lock()を呼び出します:[31] coliru.stacked-crooked.com/a/515ba092a46135ae
- 変更中に、実際にlock()関数を呼び出します。読み取りをコメントアウトし、配列を変更する操作のみを残し、文字Xのみが表示されるようになりました。[32] coliru.stacked-crooked.com/a/882eb908b22c98d6
主なタスクは、同時に2つの状態のうちの1つのみが存在するようにすることです。- 任意の数のスレッドがlock_shared()を正常に実行しましたが、lock()を実行しようとするすべてのスレッドは待機する必要があります
- スレッドの1つが正常にロック()を実行し、lock_shared()またはlock()を実行しようとする他のすべてのスレッドは待機する必要があります
概略的に、互換性のある状態のテーブルは次のようになります。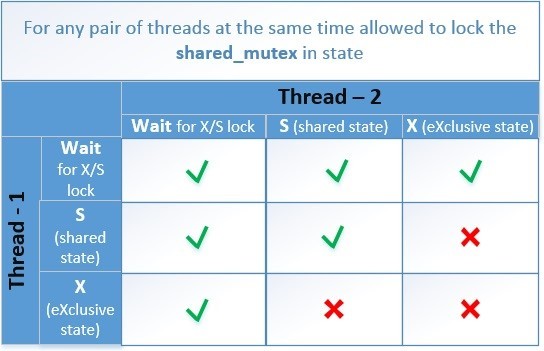 2つのスレッドが同時に操作を実行しようとしている場合のcontention_free_shared_mutexのアルゴリズムを検討してください。
2つのスレッドが同時に操作を実行しようとしている場合のcontention_free_shared_mutexのアルゴリズムを検討してください。- T1-read & T2-read: - lock_shared() – , .. , - (want_x_lock == false). , , – - , CAS-: want_x_lock = true.
- T1-write & T2-write: - (want_x_lock) true, CAS-: want_x_lock.compare_exchange_weak(); , recursive_spinlock_t, .
- T1-read & T2-write: - T1 , (want_x_lock), (true), , (want_x_lock == false) .
ライタースレッドT2はフラグを設定し(want_x_lock = true)、すべてのリーダースレッドがセルからロックフラグを削除するのを待ちます。このスキームのライタースレッドは、リーダーよりも優先度が高くなっています。また、ロックフラグを同時に設定すると、次の操作でリーダースレッドはライタースレッドがあるかどうかを確認し(want_x_lock == true)、そうであれば、リーダーはそのロックをキャンセルします。ライタースレッドは、リーダーからのロックがこれ以上ないことを確認し、ブロック機能を正常に完了します。これらのロックのグローバルな順序は、Sequential Consistency(std :: memory_order_seq_cst)のセマンティクスにより尊重されます。概略的には、2つのストリーム(リーダーとライター)の相互作用は次のとおりです。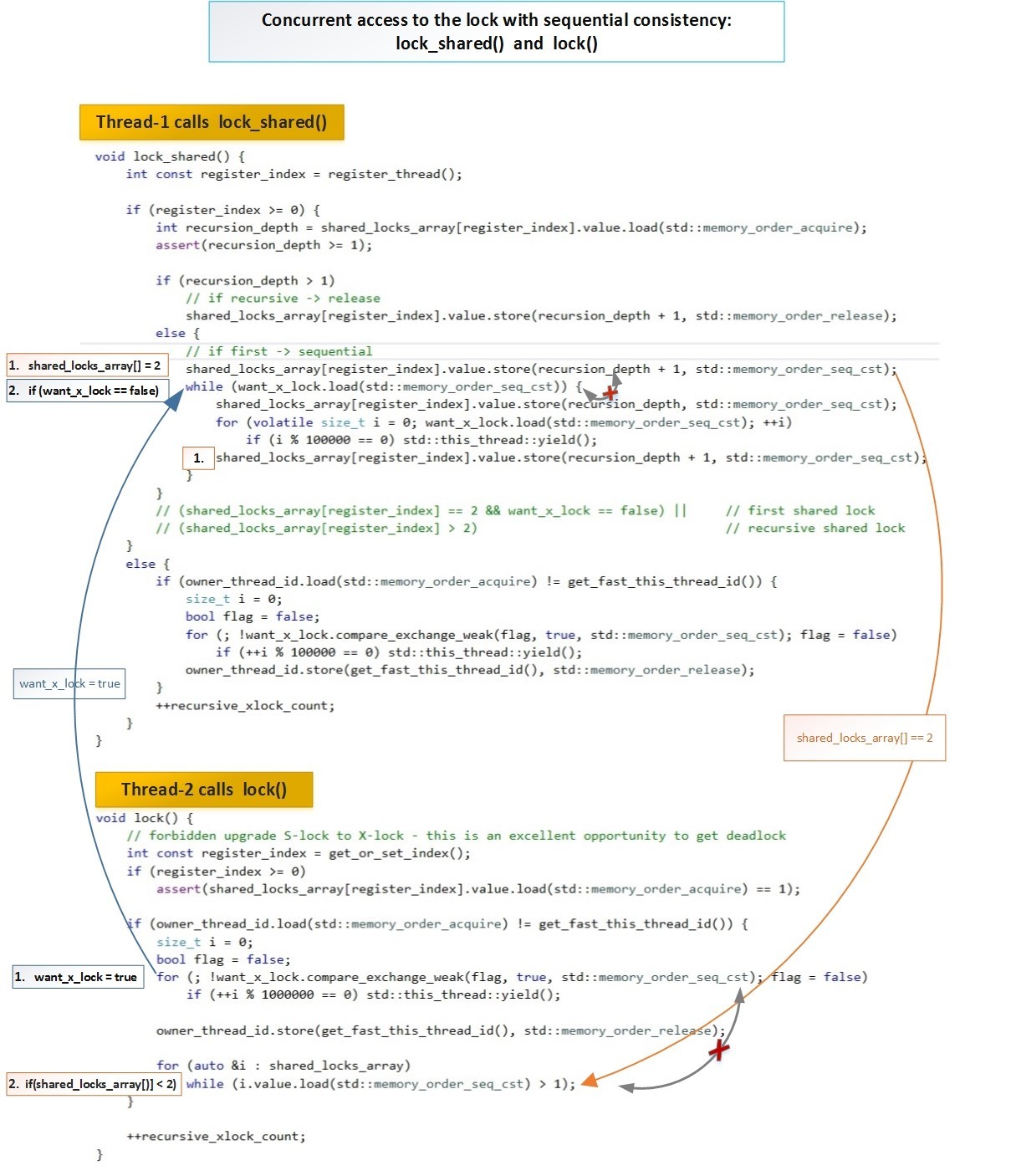 フルサイズで:habrastorage.org/getpro/habr/post_images/5b2/3a3/23b/5b23a323b6a1c9e13ade90bbd82ed98b.jpg両方の操作の両方lock_shared関数()とロックで()、1,2使用のstd :: memory_order_seq_cst -すなわち これらの操作では、すべてのスレッドに対して単一の合計順序が保証されます。
フルサイズで:habrastorage.org/getpro/habr/post_images/5b2/3a3/23b/5b23a323b6a1c9e13ade90bbd82ed98b.jpg両方の操作の両方lock_shared関数()とロックで()、1,2使用のstd :: memory_order_seq_cst -すなわち これらの操作では、すべてのスレッドに対して単一の合計順序が保証されます。cont-free shared-mutexでストリームを自動的に登録解除します
スレッドが最初にロックにアクセスすると、登録されます。そして、このスレッドが完了するか、ロックが削除されると、登録をキャンセルする必要があります。しかし、20個のスレッドがミューテックスで動作し、ロック配列が20である場合、これらのスレッドが終了し、新しい20個のスレッドを登録しようとするとどうなるかを見てみましょう:[33] coliru.stacked-crooked.com/a/ f1ac55beedd31966ご覧のとおり、最初の20個のスレッドは正常に登録されましたが、次の20個のスレッドは登録できず(register_thread = -1)、前の20個のスレッドは既に削除されてロックを使用していませんが、排他的なライターロックの使用を強制されました。この問題を解決するために、ストリームが削除されたときにストリームの自動登録解除を追加します。スレッドがこれらのロックの多くで機能する場合、スレッドの終了時に、すべてのそのようなロックで登録解除が発生するはずです。また、ストリームの削除時に現在削除されているロックがある場合、存在しないロックで登録をキャンセルしようとしてエラーが発生することはありません。例:[34] coliru.stacked-crooked.com/a/4172a6160ca33a0fご覧のとおり、最初に20個のスレッドが登録され、それらを削除して20個の新しいスレッドを作成した後、登録することもできました-同じ番号でregister_thread = 0-19(出力を参照) (出力)の例)。スレッドがロックで動作し、ロックが削除された場合でも、スレッドが完了すると、存在しないロックオブジェクトを登録解除しようとしてエラーが発生しないことがわかり ます。[35] coliru.stacked-crooked.com/a/d2e5a4ba1cd787daWe 20スレッドが作成され、ロックを使用して読み取られ、500ミリ秒でスリープ状態になるようにタイマーを設定します。その時点で、contention_free_shared_mutexロックを含むcontfree_safe_ptrオブジェクトが100ミリ秒後に削除され、その後20スレッドが起動して終了しました。それらが完了すると、リモートロックオブジェクトの登録解除によるエラーは発生しませんでした。小さな追加として、MSVS2013をサポートすることで、古いコンパイラの所有者もこの例に慣れることができます。簡素化されたストリーム登録サポートを追加しますが、ストリームを登録解除する機能はありません。上記の考えをすべて考慮に入れた例として、最終結果を示します。例:[36] coliru.stacked-crooked.com/a/0a1007765f13aa0dアルゴリズムと選択された障壁の適切な機能
上記では、明らかなエラーがないことを示すテストを実施しました。しかし、操作性を証明するために、操作の順序と変数の可能な状態の可能な変更のスキームを作成する必要があります。排他的ロック()/ロック解除()ロックは、recursive_spinlock_tの場合と同じくらい簡単なので、詳細に検討しません。lock_shared()のリーダースレッドとlock()のライタースレッドの競合については、上で詳しく調べました。ここでの主なタスクは、すべての場合でlock_shared()が少なくともAcquire-semanticを使用し、unlock_shared()がすべての場合で少なくともRelease-semanticを使用することを示すことです。しかし、これは再帰的なロック/ロック解除を繰り返すための前提条件ではありません。 次に、これらの障壁がコードでどのように実装されるかを示します。lock_shared()の図式の障壁-順序の変更が禁止されている方向を示す赤いバツ印の矢印:unlock_shared()の
次に、これらの障壁がコードでどのように実装されるかを示します。lock_shared()の図式の障壁-順序の変更が禁止されている方向を示す赤いバツ印の矢印:unlock_shared()の 図式の障壁:フルサイズ:hsto.org/files/065/9ce/bd7/0659cebd72424256b6254c57d35c7d07.jpgマークアウト付きのフルサイズ遷移:hsto.org/files/fa7/4d2/2b7/fa74d22b7cda4bf4b1015ee263cad9ee.jpgの存在はまた、この同じ機能のブロック図()lock_shared フルサイズの画像を:hsto.org/files/c3a/abd/4e7/c3aabd4e7cfa4e9db55b2843467d878f.jpgを内楕円形のブロックは、厳密な一連の操作を示します。
図式の障壁:フルサイズ:hsto.org/files/065/9ce/bd7/0659cebd72424256b6254c57d35c7d07.jpgマークアウト付きのフルサイズ遷移:hsto.org/files/fa7/4d2/2b7/fa74d22b7cda4bf4b1015ee263cad9ee.jpgの存在はまた、この同じ機能のブロック図()lock_shared フルサイズの画像を:hsto.org/files/c3a/abd/4e7/c3aabd4e7cfa4e9db55b2843467d878f.jpgを内楕円形のブロックは、厳密な一連の操作を示します。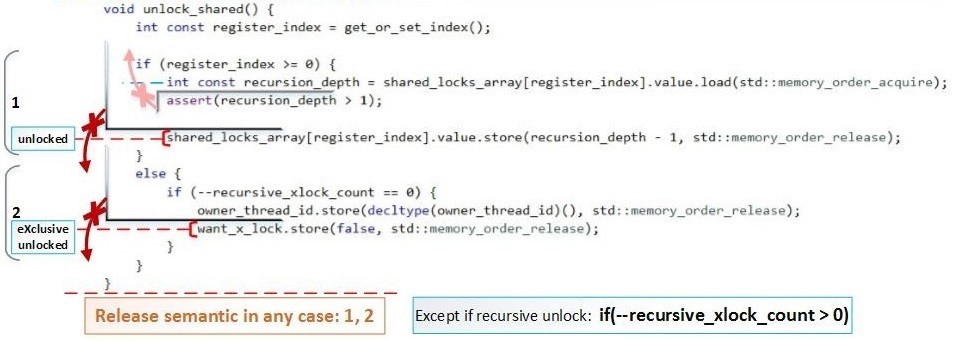

- 操作が最初に実行されます-赤で
- その後、操作が実行されます-紫色で
緑色は、任意の順序で実行できる変更を示します。これらの変更は「共有ミューテックス」をブロックしませんが、再帰ネスティングカウンターを増やすだけです-これらの変更はローカルでのみ使用する場合に重要です。つまり
これらの緑の操作は、ロックへの実際のエントリではありません。なぜなら
2つの条件が満たされています-マルチスレッドからのすべての必要な副作用が考慮されると考えられます:- ロックを入力する決定の瞬間には、常に「取得」以上のセマンティクスがあり
ます。•want_x_lock.load(std :: memory_order_seq_cst)
•want_x_lock.compare_exchange_weak(flag、true、std :: memory_order_seq_cst) - (1-), (2-) . .
さらに、これらの操作の結果とそのシーケンスをアルゴリズムのロジックと単純に比較することにより、アルゴリズムの正確性を確認できます。ブロッキング「contention_free_shared_mutex」の他のすべての機能は、マルチスレッド実行のロジックの観点からより明白です。また、繰り返し(再帰)ブロック中に、アトミック操作にstd :: memory_order_acquireバリアー(図に示すように)は必要ありません。これは、実際のロックエントリではないため、std :: memory_order_relaxedを設定するだけで十分です。 。ただし、これによって速度が大幅に向上することはなく、理解が複雑になります。使い方
C ++でcontention_free_shared_mutex <>を高度に最適化されたshared_mutexとして使用する例を示します。Linux(GCC 6.3.0)およびWindows(MSVS 2015/13)用のこのコードは、次の場所からダウンロードできます:github.com/AlexeyAB/object_threadsafe/tree/master/contfree_shared_mutexLinuxでClang ++ 3.8.0でこの例をコンパイルするには、変更する必要がありますメイクファイル。 #include < iostream > #include < thread > #include < vector > #include "safe_ptr.h" template < typename T > void func(T &s_m, int &a, int &b) { for (size_t i = 0; i < 100000; ++i) { // x-lock for modification { s_m.lock(); a++; b++; s_m.unlock(); } // s-lock for reading { s_m.lock_shared(); assert(a == b); // will never happen s_m.unlock_shared(); } } } int main() { int a = 0; int b = 0; sf::contention_free_shared_mutex< > s_m; // 19 threads std::vector< std::thread > vec_thread(20); for (auto &i : vec_thread) i = std::move(std::thread([&]() { func(s_m, a, b); })); for (auto &i : vec_thread) i.join(); std::cout << "a = " << a << ", b = " << b << std::endl; getchar(); return 0; }
このコードはオンラインコンパイラにあります:coliru.stacked-crooked.com/a/11c191b06aeb5fb6ご覧のとおり、mutex sf :: contention_free_shared_mutex <>は、標準std :: shared_mutexとまったく同じように使用されます。テスト:std :: shared_mutex VS contention_free_shared_mutex
1つのサーバープロセッサIntel Xeon E5-2660 v3 2.6 GHzの16スレッドでテストする例を次に示します。まず、青と紫の線に興味があります。- safe_ptr <std :: map、std :: shared_mutex>
- contfree_safe_ptr <std :: map>
:テストのソースコードgithub.com/AlexeyAB/object_threadsafe/tree/master/bench_contfree起動するためのコマンドライン:numactl --localalloc --cpunodebind = 0 ./benchmark 16だけマザーボード上のCPUを持っている場合は、実行します。 /ベンチマーク読み取りロック(共有ロック)と書き込みロック(排他ロック)の異なる比率に対するさまざまなロックのパフォーマンス。- 排他ロックの割合=(書き込み操作の割合)
- 共有ロック%= 100-(書き込み操作の%)
(std :: mutexの場合-排他ロックは常に機能します) パフォーマンス(大きいほど良い)、MOps-毎秒数百万回の操作
パフォーマンス(大きいほど良い)、MOps-毎秒数百万回の操作- 変更が0%の場合、共有mutex(contfree_safe_ptr <map>の一部として)は34.60 Mopsのパフォーマンスを示し、標準std :: shared_mutex(safe_ptr <map、std :: shared_mutex>の一部として)よりも14倍高速です。 2.44モップのみ。
- 15%の変更により、共有ミューテックス(contfree_safe_ptr <map>の一部として)は5.16 Mopsパフォーマンスを示し、標準std :: shared_mutex(safe_ptr <map、std :: shared_mutex>の一部)よりも7倍高速です。 0.74モップのみ。
「競合のない共有ミューテックス」ロックは、任意の数のスレッドで機能します。最初の36個のスレッドでは競合なし、後続のスレッドでは排他ロックとして機能します。グラフからわかるように、「排他ロック」のstd :: mutexでさえ、std :: shared_mutexよりも高速で、15%の変更があります。コンテンションフリーのストリーム36の数は、テンプレートパラメータによって設定され、変更できます。次に、ロックのタイプの異なる比率(読み取り(共有ロック)と書き込み(排他ロック))の遅延の中央値を示します。main.cppテストコードでは、次を設定する必要があります。const bool measure_latency = true;実行するコマンドライン:numactl --localalloc --cpunodebind = 0 ./benchmark 16マザーボードにCPUが1つしかない場合は、次を実行します:./benchmark レイテンシの中央値(低い-良い)、マイクロ秒したがって、std :: shared_timed_mutexおよびboost :: shared_mutexとは異なり、ロックおよびロック解除中にリーダーが互いに干渉しない共有ロックを作成しました。ただし、各スレッドに追加で割り当てられています。ロック配列の64バイト+ 24バイトは、登録解除のためのunregister_t構造体+ hash_mapからこの構造体を指す要素で占められています。合計で、ストリームごとに約100バイト。より深い問題は、スケーリングする能力です。たとえば、24個のコア(それぞれ48個のハイパースレッディングスレッド)を備えた8個のCPU(Intel Xeon Processor E7-8890 v4)がある場合、これは合計384個の論理コアになります。各ライタースレッドは、書き込み前に24,576バイト(各384コアから64バイト)を読み取る必要がありますが、並行して読み取ることができます。これは、1つのキャッシュラインが各384スレッドから各スレッドに順次移動するまで待つよりも確かに優れています。通常のstd :: shared_timed_mutexおよびboost :: shared_mutex(任意のタイプのユニーク/共有ロック)。ただし、1000コア以上の並列化は通常、各メッセージを処理するアトミック操作を呼び出すのではなく、異なるアプローチで実装されます。上記で説明したすべてのオプション:アトミック操作、アクティブロック、ロックのないデータ構造-これらはすべて、低レイテンシ(0、5-5 usec)個々のメッセージ。1秒あたりの操作率が高い場合、つまりシステム全体のパフォーマンスと数万の論理コアのスケーラビリティのために、大量並列処理、「レイテンシを隠す」、「バッチ処理」のアプローチを使用します。メッセージがソート(マップ用)またはグループ化(ハッシュマップ用)され、既存のソート済みのものとマージされる場合のバッチ処理または50〜500 usecのグループ化された配列。その結果、各操作には10〜100倍の遅延がありますが、これらの遅延は膨大な数のスレッドで同時に発生し、その結果、「Fine-grained Temporal multithreading」の使用によりレイテンシ「非表示レイテンシ」が隠されます。仮定すると、各メッセージには100倍の遅延がありますが、メッセージは10,000倍処理されます。これは、単位時間あたり100倍効果的です。 GPUで開発する場合、このような原則が適用されます。おそらく以下の記事でこれをより詳細に分析します。
レイテンシの中央値(低い-良い)、マイクロ秒したがって、std :: shared_timed_mutexおよびboost :: shared_mutexとは異なり、ロックおよびロック解除中にリーダーが互いに干渉しない共有ロックを作成しました。ただし、各スレッドに追加で割り当てられています。ロック配列の64バイト+ 24バイトは、登録解除のためのunregister_t構造体+ hash_mapからこの構造体を指す要素で占められています。合計で、ストリームごとに約100バイト。より深い問題は、スケーリングする能力です。たとえば、24個のコア(それぞれ48個のハイパースレッディングスレッド)を備えた8個のCPU(Intel Xeon Processor E7-8890 v4)がある場合、これは合計384個の論理コアになります。各ライタースレッドは、書き込み前に24,576バイト(各384コアから64バイト)を読み取る必要がありますが、並行して読み取ることができます。これは、1つのキャッシュラインが各384スレッドから各スレッドに順次移動するまで待つよりも確かに優れています。通常のstd :: shared_timed_mutexおよびboost :: shared_mutex(任意のタイプのユニーク/共有ロック)。ただし、1000コア以上の並列化は通常、各メッセージを処理するアトミック操作を呼び出すのではなく、異なるアプローチで実装されます。上記で説明したすべてのオプション:アトミック操作、アクティブロック、ロックのないデータ構造-これらはすべて、低レイテンシ(0、5-5 usec)個々のメッセージ。1秒あたりの操作率が高い場合、つまりシステム全体のパフォーマンスと数万の論理コアのスケーラビリティのために、大量並列処理、「レイテンシを隠す」、「バッチ処理」のアプローチを使用します。メッセージがソート(マップ用)またはグループ化(ハッシュマップ用)され、既存のソート済みのものとマージされる場合のバッチ処理または50〜500 usecのグループ化された配列。その結果、各操作には10〜100倍の遅延がありますが、これらの遅延は膨大な数のスレッドで同時に発生し、その結果、「Fine-grained Temporal multithreading」の使用によりレイテンシ「非表示レイテンシ」が隠されます。仮定すると、各メッセージには100倍の遅延がありますが、メッセージは10,000倍処理されます。これは、単位時間あたり100倍効果的です。 GPUで開発する場合、このような原則が適用されます。おそらく以下の記事でこれをより詳細に分析します。結論:
標準のstd :: shared_mutexで行われているように、リーダーストリームが互いに同期する必要のない独自の「共有ミューテックス」を開発しました。「共有ミューテックス」の動作の正確性を厳密に証明しました。また、アトミック操作、メモリバリアを詳細に検討し、パフォーマンスを最大限に最適化するために方向を変更できるようにしました。次に、libCDS(Concurrent Data Structuresライブラリ)ライブラリの高度に最適化されたロックフリーアルゴリズムと比較して、マルチスレッドプログラムのパフォーマンスをどれだけ向上できるかを確認します:github.com/khizmax/libcds