
(完全なソースコードはこちら )
化学の5時間のクラスに座って、壁に掛かっている周期表をよく見ました。 時間を過ごすために、テーブルの要素の表記のみを使用して書くことができる単語を探し始めました。 例:ScAlEs、FeArS、Erasure、WASTE、PoInTlEsSnEsS、MoISTeN、SALMONN、PuffInEsS。
それから、最長の単語は何にできるのだろうと思いました(私はなんとかTiNTiNNaBULaTiONSを見つけることができました )ので、化学元素の表記からなる単語を探すPythonプログラムを書くことにしました。 彼女はその言葉を受け取って、化学元素のセットに変換するためのすべての可能なオプションを返さなければなりませんでした:
- 入り口:切断
- 出力:AmPuTaTiONS、AmPUTaTiONS
シンボルグループの生成
すべての要素の指定が同じ長さであれば、タスクは簡単になります。 ただし、一部の指定は2文字で構成され、一部は1文字です。 これは問題を非常に複雑にします。 たとえば、切断のpuは、プルトニウム(Pu)またはウランを含むリン(PU)を意味する場合があります。 入力ワードは、1文字と2文字の指定のすべての可能な組み合わせに分割する必要があります。
そのような変換を「グループ化」と呼ぶことにしました。 単語の表記法への特定の区分を決定します。 グループ化は、ユニットと2のタプルとして表すことができます。1は1文字の指定を表し、2は2文字の指定を表します。 各要素化はグループ化に対応しています。
- 「AmPuTaTiONS」
- 「ApPUTaTiONS」
問題を分析し、パターンを見つけるために、ノートブックにそのようなテーブルを書きました。
質問:長さnの文字列が与えられた場合、それに対してユニットと2のシーケンスがいくつ存在できるので、各シーケンスの桁数はnに等しくなりますか?
| n | #グループ化 | グルーピング |
|---|
| 0 | 1 | () |
| 1 | 1 | (1) |
| 2 | 2 | (1,1), (2) |
| 3 | 3 | (1,1,1), (2,1), (1,2) |
| 4 | 5 | (1,1,1,1), (2,1,1), (1,2,1), (1,1,2), (2,2) |
| 5 | 8 | (1,1,1,1,1), (2,1,1,1), (1,2,1,1), (1,1,2,1), (1,1,1,2), (2,2,1), (2,1,2), (1,2,2) |
| 6 | 13 | (1,1,1,1,1,1), (2,1,1,1,1), (1,2,1,1,1), (1,1,2,1,1), (1,1,1,2,1), (1,1,1,1,2), (2,2,1,1), (2,1,2,1), (2,1,1,2), (1,2,2,1), (1,2,1,2), (1,1,2,2), (2,2,2) |
| 7 | 21 | (1,1,1,1,1,1,1), (2,1,1,1,1,1), (1,2,1,1,1,1), (1,1,2,1,1,1), (1,1,1,2,1,1), (1,1,1,1,2,1), (1,1,1,1,1,2), (2,2,1,1,1), (2,1,2,1,1), (2,1,1,2,1), (2,1,1,1,2), (1,2,2,1,1), (1,2,1,2,1), (1,2,1,1,2), (1,1,2,2,1), (1,1,2,1,2), (1,1,1,2,2), (2,2,2,1), (2,2,1,2), (2,1,2,2), (1,2,2,2) |
回答: fib(n + 1) !?
フィボナッチ数列がそのような予想外の場所にあることに驚いた。 その後の調査で、このパターンが二千年前に知られていることを知ってさらに驚いた。 古代インドのプロソディスト詩人は、ヴェーダの聖歌の短い音節と長い音節の変化を調べることでそれを発見しました。 Donald KnuthによるThe Art of Computer Programming本の7.2.1.7章で、このことや組み合わせ論の歴史における他の優れた研究について読むことができます。
この発見には感銘を受けましたが、それでも当初の目標であるグループ自体を生成することには達しませんでした。 いくつかの考えと実験の後、私が思いつく最も簡単な解決策に到達しました:可能なすべてのユニットと2のシーケンスを生成し、要素の合計が入力語の長さと一致しないものをフィルターで除外します。
from itertools import chain, product def generate_groupings(word_length, glyph_sizes=(1, 2)): cartesian_products = ( product(glyph_sizes, repeat=r) for r in range(1, word_length + 1) ) # , groupings = tuple( grouping for grouping in chain.from_iterable(cartesian_products) if sum(grouping) == word_length ) return groupings
デカルト積は、既存の要素セットから配置されたすべてのタプルのコレクションです。 Python標準ライブラリはitertools.product()関数を提供します。この関数は、 itertools.product()たitertools.product()の要素のデカルト積を返します。 cartesian_products - word_length指定された長さまでのglyph_sizesの要素のすべての可能な変換を収集する生成式。
word_lengthが3の場合、 cartesian_products生成します。
[ (1,), (2,), (1, 1), (1, 2), (2, 1), (2, 2), (1, 1, 1), (1, 1, 2), (1, 2, 1), (1, 2, 2), (2, 1, 1), (2, 1, 2), (2, 2, 1), (2, 2, 2) ]
次に、結果にフィルターが適用されるため、要素数がword_length満たす変換のみがgroupings含まれword_length 。
>>> generate_groupings(3) ((1, 2), (2, 1), (1, 1, 1))
もちろん、余分な作業がたくさんあります。 この関数は14回の変換を計算しましたが、残りは3回のみでした。 しかし、後でこれに戻ります。 それまでの間、私は作業機能を得て、次のタスクに進みました。
グルーピングと単語の一致
単語のすべての可能なグループ化を計算した後、各グループと「比較」する必要がありました。
def map_word(word, grouping): chars = (c for c in word) mapped = [] for glyph_size in grouping: glyph = "" for _ in range(glyph_size): glyph += next(chars) mapped.append(glyph) return tuple(mapped)
この関数は、グループ内の各指定をカップとして扱います。最初に、単語から可能な限り多くの文字を入力し、次に次の文字に移動します。 すべての文字が正しい表記法で配置されると、マッピングされた結果の単語がタプルとして返されます。
>>> map_word('because', (1, 2, 1, 1, 2)) ('b', 'ec', 'a', 'u', 'se')
照合後、単語は化学元素の記号のリストと比較する準備ができています。
スペルを検索する
以前のすべての操作を一緒に収集するspell()関数を作成しました。
def spell(word, symbols=ELEMENTS): groupings = generate_groupings(len(word)) spellings = [map_word(word, grouping) for grouping in groupings] elemental_spellings = [ tuple(token.capitalize() for token in spelling) for spelling in spellings if set(s.lower() for s in spelling) <= set(s.lower() for s in symbols) ] return elemental_spellings
spell()はすべての可能なスペルを取得し、要素表記で完全に構成されているもののみを返します。 不適切なオプションを効果的にフィルタリングするために、セットを使用しました。
Pythonのセットは数学セットに非常に似ています。 これらは、一意の要素の順不同のコレクションです。 舞台裏では、それらはキーを持つが値のない辞書(ハッシュテーブル)として実装されます。 セットのすべての要素がハッシュされるため、メンバーシップテストは非常に効率的に機能します( 平均してO(1) )。 これらの効率的なメンバーシップ検証操作を使用してサブセットをチェックするために、比較演算子がオーバーロードされます。 Luciano Ramalhoによる著名なFluent Pythonの本には、多くのセットと辞書が詳しく説明されています。
最後のコンポーネントを獲得し、機能するプログラムを入手しました!
>>> spell('amputation') [('Am', 'Pu', 'Ta', 'Ti', 'O', 'N'), ('Am', 'P', 'U', 'Ta', 'Ti', 'O', 'N')] >>> spell('cryptographer') [('Cr', 'Y', 'Pt', 'Og', 'Ra', 'P', 'H', 'Er')]
一番長い言葉?
基本機能の実装に満足したら、プログラムにStoichiographという名前を付け、コマンドラインを使用してラッパーを作成しました。 ラッパーは、引数として、またはファイルから単語を受け取り、スペルオプションを表示します。 単語を降順に並べ替える関数を追加することで、プログラムを単語のリストに設定しました。
$ ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english NoNRePReSeNTaTiONaL NoNRePReSeNTaTiONAl [...]
いいね! 私自身はその言葉を見つけられなかったでしょう。 プログラムはすでにタスクを解決しています。 私は遊んで、長い単語を見つけました:
$ ./stoichiograph.py nonrepresentationalisms NoNRePReSeNTaTiONaLiSmS NONRePReSeNTaTiONaLiSmS NoNRePReSeNTaTiONAlISmS NONRePReSeNTaTiONAlISmS
面白い。 これが実際に最も長い単語( ネタバレ )であるかどうかを知りたかったので、長い単語を調査することにしました 。 しかし、最初に、パフォーマンスに対処する必要がありました。
パフォーマンスの問題を解決する
119,095ワード(その多くはかなり短い)の処理には、プログラムに約16分かかりました。
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english [...] real 16m0.458s user 15m33.680s sys 0m23.173s
1秒あたり平均約120ワード。 もっと早くできると確信していました。 掘る場所を見つけるために、より詳細なパフォーマンス情報が必要でした。
ラインプロファイラーは、Pythonコードのパフォーマンスのボトルネックを識別するためのツールです。 彼女が23文字の単語のスペルを探していたときに、プログラムをプロファイルするために使用しました。 レポートの簡潔なバージョンは次のとおりです。
Line # % Time Line Contents =============================== 30 @profile 31 def spell(word, symbols=ELEMENTS): 32 71.0 groupings = generate_groupings(len(word)) 33 34 15.2 spellings = [map_word(word, grouping) for grouping in groupings] 35 36 elemental_spellings = [ 37 0.0 tuple(token.capitalize() for token in spelling) 38 13.8 for spelling in spellings 39 if set(s.lower() for s in spelling) <= set(s.lower() for s in symbols) 40 ] 41 42 0.0 return elemental_spellings Line # % Time Line Contents =============================== 45 @profile 46 def generate_groupings(word_length, glyhp_sizes=(1, 2)): 47 cartesian_products = ( 48 0.0 product(glyph_sizes, repeat=r) 49 0.0 for r in range(1, word_length + 1) 50 ) 51 52 0.0 groupings = tuple( 53 0.0 grouping 54 100.0 for grouping in chain.from_iterable(cartesian_products) 55 if sum(grouping) == word_length 56 ) 57 58 0.0 return groupings
generate_groupings()が長い間実行されているのも不思議でgenerate_groupings()ありません。 彼女が解決しようとしている問題は、サブセットの合計の問題の特殊なケースであり、これはNP完全問題です。 デカルト積を見つけることはすぐに高価になり、 generate_groupings()は多数のデカルト積を探します。
漸近解析を実行して、すべてがどれほど悪いかを理解できます。
glyph_sizes常に2つの要素(1と2)が含まれると仮定します。product()は、2つの要素のセットのデカルト積のr倍を求めるため、 product()時間計算量はO(2^r)です。product()はword_length回繰り返すループで呼び出されるため、 nをword_lengthとword_lengthと、ループ全体の時間の複雑さはO(2^r * n)ます。- しかし、
rはサイクルの実行ごとに異なる値を取得するため、実際には時間の複雑度はO(2^1 + 2^2 + 2^3 + ... + 2^(n-1) + 2^n)近くなります。 - また、
2^0 + 2^1 + ... + 2^n = 2^(n+1) - 1 、結果の時間の複雑さはO(2^(n+1) - 1)またはO(2^n) 。
O(2^n)を使用すると、 word_length増分ごとにランタイムが2倍になることが期待できます。 ひどい
私は何週間もパフォーマンスの問題について考えました。 相互に関連する2つの異なるタスクを解決する必要がありました。
- 異なる長さの単語のリストを処理します。
- 1つの非常に長い単語の処理。
2番目のタスクは、最初のタスクに影響を与えたため、はるかに重要であることが判明しました。 2番目のケースでは処理を改善する方法をすぐには理解しませんでしたが、最初のケースについてはアイデアがあったので、それから始めました。
タスク1:怠け者になる
怠azineは、 プログラマーだけでなく、プログラム自体にとっても美徳です。 最初の問題の解決には、怠の追加が必要でした。 プログラムが単語の長いリストをチェックする場合、どうすればできるだけ作業を少なくするのですか?
無効な文字を確認してください
当然、リストにはおそらく周期表では表されない文字を含む単語が含まれると考えました。 そのような単語のスペルを検索するのに時間を費やすことは意味がありません。 そのため、このような単語をすばやく見つけて捨てれば、リストをより速く処理できます。
残念ながら、表に示されていない文字はjとqだけでした。
>>> set('abcdefghijklmnopqrstuvwxyz') - set(''.join(ELEMENTS).lower()) ('j', 'q')
そして私の辞書では、これらの文字が含まれている単語は3%だけでした。
>>> with open('/usr/share/dict/american-english', 'r') as f: ... words = f.readlines() ... >>> total = len(words) >>> invalid_char_words = len( ... [w for w in words if 'j' in w.lower() or 'q' in w.lower()] ... ) ... >>> invalid_char_words / total * 100 3.3762962340988287
それらを捨てて、私はわずか2%のパフォーマンス向上を得ました:
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english [...] real 15m44.246s user 15m17.557s sys 0m22.980s
これは私が望んでいた改善ではなかったので、次のアイデアに移りました。
メモ化
メモ化は、関数の出力を保存し、同じ入力で関数が再度呼び出された場合にそれを返すための手法です。 メモ化された関数は、特定の入力に基づいて1回だけ出力を生成する必要があります。 これは、同じ複数の入力データで繰り返し呼び出される高価な関数を使用する場合に非常に便利です。 ただし、メモ化は純粋な関数に対してのみ機能します。
generate_groupings()は完璧な候補でした。 非常に広範囲の入力データに遭遇する可能性は低く、長い単語を処理するときに実行するのに非常にコストがかかります。 functoolsパッケージは、 @lru_cache()デコレーターを提供することでメモ化を容易にします。
generate_groupings()のメモ化は、実行時間の短縮をもたらしました-十分ではありませんが、著しく:
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english [...] real 11m15.483s user 10m54.553s sys 0m17.083s
しかし、標準ライブラリの単一のデコレータにとってはまだ悪くありません!
タスク2:スマートに
私の最適化は最初のタスクで少し助けましたが、重要な未解決の問題はgenerate_groupings()非効率性でした。大きな個々の単語はまだ処理に非常に長い時間がかかりました:
$ time ./stoichiograph.py nonrepresentationalisms [...] real 0m20.275s user 0m20.220s sys 0m0.037s
怠azineはある程度の進歩につながる可能性がありますが、時には賢くする必要があります。
再帰とDAG
ある夜、居眠りをして、インスピレーションの閃光を経験し、ホワイトボードに走ってこれを描きました。

どちらの場合でも、任意の行を使用して、1文字と2文字の表記をすべて引き出し、残りを再帰できると考えました。 行全体を調べた後、要素のすべての表記法を見つけ、最も重要なことには、要素の構造と配置に関する情報を取得します。 また、グラフはそのような情報を保存するための素晴らしいオプションかもしれないと考えました。
一連の再帰関数が美しい単語の切断を要求する場合、次のようになります。
'a' 'mputation' 'm' 'putation' 'p' 'utation' 'u' 'tation' 't' 'ation' 'a' 'tion' 't' 'ion' 'i' 'on' 'o' 'n' 'n' '' 'on' '' 'io' 'n' 'ti' 'on' 'at' 'ion' 'ta' 'tion' 'ut' 'ation' 'pu' 'tation' 'mp' 'utation' 'am' 'putation'
周期表を満たさないすべての指定をフィルタリングすると、同様のグラフを取得できます。
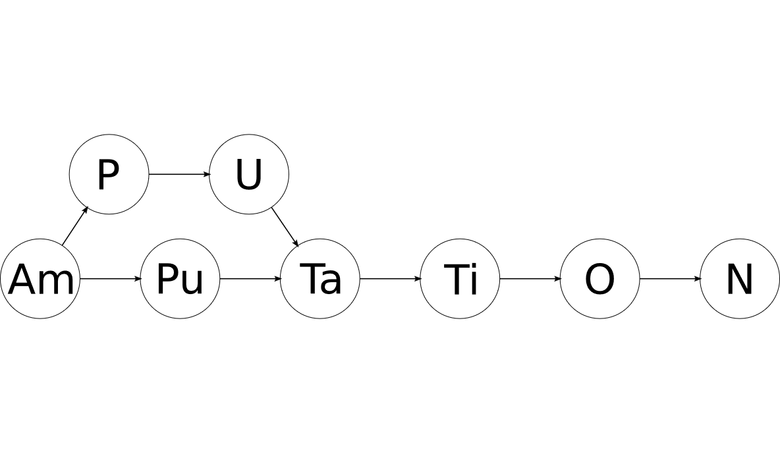
結果は有向非周期グラフ (DAG)で、その各ノードには化学元素の指定が含まれています。 最初のノードから最後のノードまでのすべてのパスは、化学要素の形で元の単語の有効なスペルになります!
それ以前は、グラフを扱っていませんでしたが、2つのノード間のすべてのパスの効率的な検索など、基本を説明する非常に有用なエッセイを見つけました。 500 Lines or Lessという優れた本には、Pythonでのグラフの別の実装例に関する章があります。 これらの例を基礎として取り上げました。
簡単なグラフクラスを実装してテストした後、ボード上の描画を関数に変換しました。
# . . Node = namedtuple('Node', ['value', 'position']) def build_spelling_graph(word, graph, symbols=ELEMENTS): """ , - . , . """ def pop_root(remaining, position=0, previous_root=None): if remaining == '': graph.add_edge(previous_root, None) return single_root = Node(remaining[0], position) if single_root.value.capitalize() in symbols: graph.add_edge(previous_root, single_root) if remaining not in processed: pop_root( remaining[1:], position + 1, previous_root=single_root ) if len(remaining) >= 2: double_root = Node(remaining[0:2], position) if double_root.value.capitalize() in symbols: graph.add_edge(previous_root, double_root) if remaining not in processed: pop_root( remaining[2:], position + 2, previous_root=double_root ) processed.add(remaining) processed = set() pop_root(word)
勝つ
額のアルゴリズムが非常に長く実行されている間( O(2^n) )、再帰アルゴリズムはO(n)続きました。 はるかに良い! 辞書で初めて最適化されたプログラムを実行したとき、ショックを受けました。
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english [...] real 0m11.299s user 0m11.020s sys 0m0.17ys
毎秒120ワード-10,800ワードではなく、16分ではなく10秒になりました!
データ構造とアルゴリズムの威力と価値に初めて感謝しました。
最長単語
新たに発見された機能により、化学要素に分解された最も長い単語であるfloccinaucinihilipilificatiousnessを見つけることができました。 これはfloccinaucinihilipilificationの派生物であり 、何かを説明したり、何かを重要でない、価値のない、または価値のないものとして扱う行動または習慣を意味します。 この単語は、英語で最も長い非技術的な単語と呼ばれることがよくあります。
Floccinaucinihilipilificatiousnessは54のスペルとして表すことができます。それらはすべてこの美しい列で暗号化されています。

オリジナル
よく過ごしました
上記のすべてが完全にナンセンスであると言う人もいるかもしれませんが、私にとっては貴重で重要な経験になりました。 私がプロジェクトを始めたとき、私はプログラミングの経験が比較的浅く、どこから始めればいいのか分かりませんでした。 物事はゆっくりと動き、満足のいく結果を得るまでに多くの時間が経過しました( コミットの履歴を参照してください。他のプロジェクトに切り替えたときに大きな中断があります)。
それにもかかわらず、私は多くのことを学び、多くのことに出会いました。 これは:
- 組み合わせ論
- パフォーマンスプロファイリング
- 時間の複雑さ
- メモ化
- 再帰
- グラフとツリー
これらの概念を理解することにより、繰り返し助けられてきました。 特に、 n体の再帰と木をシミュレートする私のプロジェクトにとって重要であることが判明しました。
最後に、あなた自身の最初の質問に対する答えを見つけることができて良かったです。 私はこのためのツールを持っているので、化学要素に分解することを考える必要がなくなったことを知っています。これはpip install stoichiographでも取得できます。
議論
善良な人々(およびいくつかの善意のボット)は、r /プログラミングスレッドでこの記事の議論に参加しました。
サブマテリアル
エレガントなソリューションからいくつかの興味深い問題へのインスピレーションのかなりの部分を得ました。これらのソリューションはPeter Norvigのものです。
Pythonのパフォーマンスプロファイリングに関する2つの有益な記事: