金曜日は、新しい一連の機械学習の記事など、開始するのに最適な日です。 第1部では、WaveAccessチームは、保険会社で機械学習が必要な理由と、コストのピークを予測する実現可能性をテストした方法について説明します。

一連の記事「保険会社の機械学習」
- 現実的なアイデア 。
- アルゴリズムの研究 。
- アルゴリズムの最適化によるモデルの改善 。
はじめに
現在、機械学習は、多くの日常的な手作業を必要とし、従来の方法ではプログラミングが困難なタスクを自動化するために効果的に使用されています。 たとえば、これらは、スパムメールの識別、テキスト内の情報の検索など、多数の影響変数を持つタスクです。 そのような状況では、機械学習の使用が特に必要になります。
機械学習を使用した多数の成功したプロジェクトが米国で実施されており、これらは主にインテリジェントアプリケーションの分野からのソリューションです。 それらを開発した企業は、業界の市場とゲームのルールを変えました。 たとえば、AmazonはWebサイトでの購入に関する推奨システムを導入しました。これにより、オンラインストアの現在の外観が事前に決定されました。 Googleは、機械学習アルゴリズムを使用して、自分について知られている情報に基づいてユーザーが個別に選択した製品を提供するターゲット広告システムを開発しました。 Netflix、Pandora(インターネットラジオ)、Uberはそれぞれの市場で重要な存在となり、さらなる発展のベクトルを設定し、機械学習がソリューションの基盤となりました。
保険会社が機械学習を必要とするのはなぜですか?
保険会社にとって重要な財務指標は、販売された保険の費用と被保険イベントの償還費用の差です。
このビジネスではコスト削減が重要であるため、企業は多数の実証済みの方法を使用しますが、常に新しい機会を探しています。
医療保険会社(クライアント)にとって、被保険者の治療費用を予測することは、費用を削減する良い方法です。 次の1か月または2か月の間にクライアントの治療に相当額が必要であることがわかっている場合は、さらに詳しく調べる必要があります。たとえば、資格のあるキュレーターに引き渡し、事前に診断検査を受けることを申し出て、医師の推奨事項の実施を監視するなどです。場合によっては、将来の治療のコストを削減します。
しかし、100万を超える場合に各クライアントを処理するコストをどのように予測するのでしょうか?
1つのオプションは、患者について知られている情報の個別の分析です。 そのため、たとえば、コストの急激な増加(相対的な値を考慮する場合)または単なるピーク(絶対値)を予測できます。 この問題のデータには多くのノイズが含まれているため、正しい予測の100%に近い結果を期待することはできません。 ただし、クラス不均衡統計について説明しているため、予測されたピークの50%が予測された80〜90%のコスト増加なしでも、企業にとって重要な情報を提供できます。 同様の問題は、機械学習によってのみ効果的に解決できます。 もちろん、既存のデータに基づいて一連のルールを手動で選択できますが、最適な境界値と係数を手動で選択することはほとんど不可能であるため、機械学習アルゴリズムと比較すると、長期的には非常に粗く非効率になります。
機械学習の実装
このようなプロジェクトでは、多くの場合、Webサービスの形式でソフトウェアパッケージを実装することが重要です。 機械学習を実装するために、クライアントはこの分野で最も有名な2つのソリューション、MS Azure MLとAmazon MLを検討しました。
Amazon MLは1つのアルゴリズム(線形回帰(および分類問題への適応-ロジスティック))の操作のみをサポートしているためです。 これにより、実装されたソリューションの可能性が制限されます。
Microsoft Azure MLは、より柔軟なサービスです。
- 多数の組み込みアルゴリズム+コードをRおよびPythonに埋め込むためのサポート。
- 組み込みツールには、分類、クラスタリング、回帰、コンピュータービジョン、テキストの操作などの分野での基本的な作業に必要なすべてのものが含まれています。
- データの前処理、操作、編成のための機能があります。
- Azure MLのモジュールはフローチャートとして編成されているため、エントリのしきい値が低くなり、作業が直感的になります。したがって、Azure MLは、仮説、アイデア、プロジェクトの実行可能性をテストする基本的なソリューションをすばやく実装できる便利なプロトタイプ作成ツールになりました。
プロジェクトで発生した問題を解決するには、アルゴリズムの複雑な構成が必要であったため、Azureが選択されました。 ただし、機械学習の問題を比較して解決する統合アプローチの利点について話すことは不可能であるため、この記事では単純なアルゴリズムに限定し、次の記事でより複雑なバリエーションを検討します。
プロトタイピング
コストのピークを予測する可能性を検証しましょう。 最初のデータとして、基本的なマークを取得するために、生データを取得します:患者の年齢、医師の予約数、過去数か月間でクライアントに費やされた金額。 翌月のコストのピークの境界は、1000ドルとして選択されます。 データをAzureにアップロードし、4対1の比率でトレーニングサンプルとテストサンプルに分割します(この段階では検証を実施しないため、この状況ではサンプリングは提供されません)。
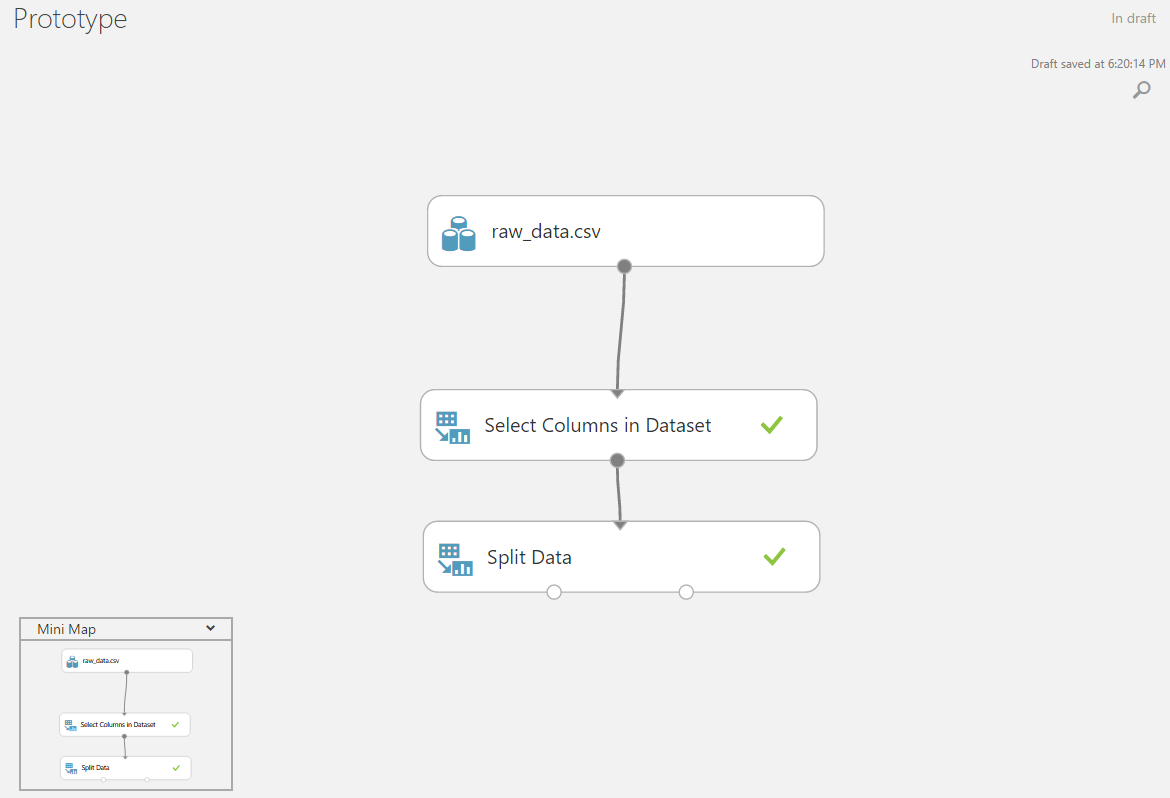
ロードされたデータに必要以上の列が含まれている場合、またはその逆の場合、一部のデータは別のソースにあります-入力データマトリックスから簡単に結合または削除できます。
アルゴリズムの最も単純なバージョンであるロジスティック回帰を(トレーニング用に)選択しましょう。 この保守的な方法は、多くの場合、最初に使用して、さらに比較するポイントを取得します。 特定のタスクでは、それが最適であり、最良の結果を示す場合があります。
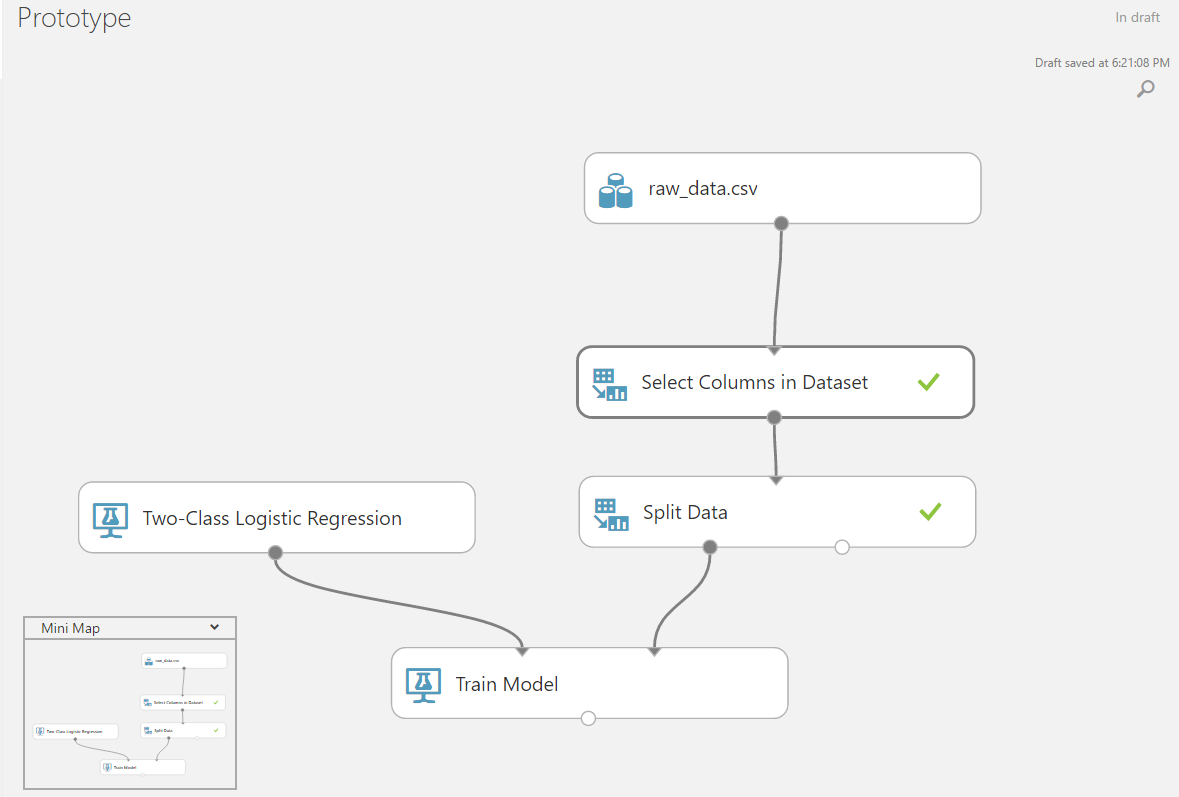
アルゴリズムのトレーニングブロックとテストブロックを追加し、初期データをそれらに関連付けます。

便宜上、結果を確認するために、アルゴリズムの結果を評価するためのブロックを追加し、クラス分離境界で実験することができます。
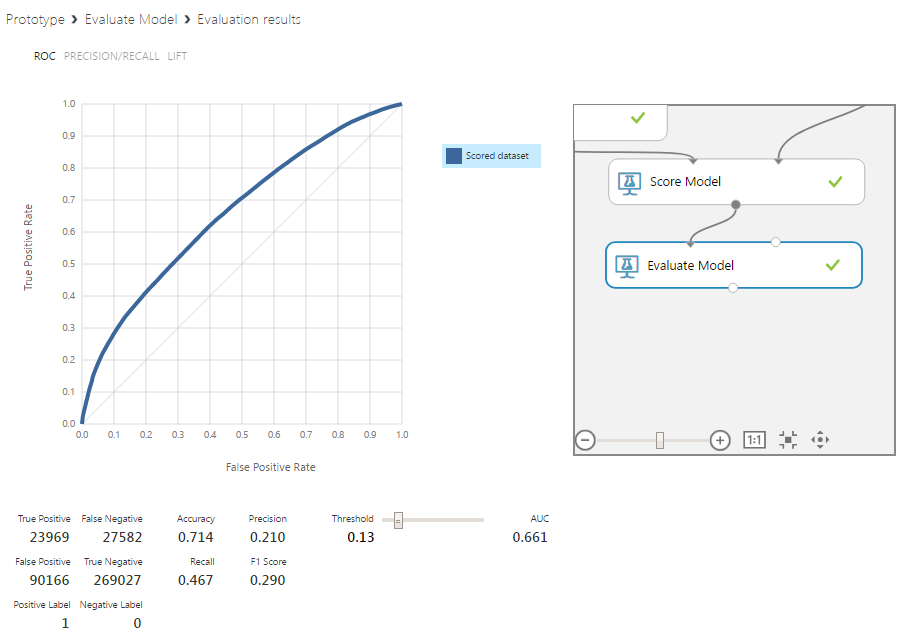
私たちの実験では、クラス分離境界を0.13に設定した生データの基本的なアルゴリズムは、ピークの約45%とその不在の75%を予測しました。 これは、将来的に行われるより複雑なスキームで概念を開発する必要があることを示しています。
次の記事では、例として、データ分析、他のアルゴリズムの動作とそれらの組み合わせ、再トレーニングと不正なデータとの戦いについて検討します。
著者について
WaveAccessチームは、さまざまな国の企業向けに、技術的に洗練され、負荷が高く、フォールトトレラントなソフトウェアを作成しています。 WaveAccessの機械学習責任者であるAlexander Azarovのコメント:
機械学習により、専門家の意見が現在支配している分野を自動化できます。 これにより、人的要因の影響を軽減し、ビジネスのスケーラビリティを高めることができます。