記事について簡単に
メソッドのインライン化は、JITコンパイラーで最も重要な最適化の1つです(これにより、「メソッドベース」または「ブロック」と呼ばれます)。 この最適化によりコンパイルの範囲が拡大し、いくつかのメソッドを全体として最適化できるようになり、アプリケーションのパフォーマンスが向上します。 ただし、インライン化メソッドを頻繁に使用すると、コンパイル時間が不必要に長くなり、生成されるマシンコードが多くなりすぎます。 そして、これは生産性にすでに悪影響を及ぼします。
トレースJITコンパイラーはすべてを連続して収集するのではなく、頻繁に実行されるパス、いわゆるトレースのみを収集します。 これにより、コンパイルを高速化し、生成されるマシンコードの量を減らし、品質を向上させることができます。 以前の作業では、トレースを記録するインフラストラクチャとトレースJavaコンパイラを実装し、HotSpot VMのJavaコードを変更しました。 この作業に基づいて、トレースのインライン化が生産性と生成コードの量に与える影響を計算しました。
インライン化方法と比較して、インライン化トレースにはいくつかの重要な利点があります。 第一に、インラインで実行されるパスは頻繁にしか実行されないため、トレースのインライン化はより選択的です。 次に、記録されたトレースに仮想呼び出しに関する情報を含めることができるため、インライン化が簡単になります。 3番目の利点は、トレース情報がコンテキスト依存であるため、メソッドのさまざまな部分が呼び出しの特定の場所に応じてインライン化できることです。 これらの利点により、生成されたコードの量がまだ妥当な制限内にある場合、インライン化がより積極的になります。
DaCapo 9.12 Bach、SPECjbb2005、SPECjvm2008ベンチマークを使用していくつかのインラインヒューリスティックをテストし、トレースコンパイラーによってHotSpotのブロッククライアントコンパイラーよりも51%高いピークパフォーマンスを達成できることを示しました。 さらに、トレーサーコンパイラのコンパイル領域の拡大が、定数の折りたたみやnullチェックの削除など、他の最適化にプラスの効果をもたらすことを示しました。
翻訳ノート
ライセンス:CC BY 3.0(Creative Commons Attribution 3.0 Unported)
「トレース」および「インライン化」という単語は、ロシア語の口語音声にしっかりと含まれるようになったため、翻訳せずに残しました。 同僚と「トラックの構築」について話し合うと、誤解されることがあります。
あるコードが別のコードを呼び出す場合、呼び出し元は送信者(呼び出し元、送信者)と呼ばれ、呼び出し先は受信者(呼び出し先、受信者)と呼ばれます。 これらの単語は非常に魅力的ですが、短くて一般的であり、このおかげで、テキストが乱雑になりません。
メソッドベースのコンパイラは、ここでは「ブロックコンパイラ」と呼ばれます。 この新語は、テキストの混乱を減らし、ロシア語版のあいまいさを排除するためにも導入されています。
写真や図は再描画されず、英語の碑文が含まれています。 ごめんなさい
翻訳は、翻訳者に不当な苦痛をもたらす場合でも、テキストの近くに保持されます。 特に、無限の自己繰り返し、大量の記事の内容を超える「紹介」、100倍複雑な文は、さまざまなJavaの研究論文の頻繁な仲間です。 既に誰かの顔を埋めたいという欲求がある場合は、これらの欲求を著者に連絡してください。
翻訳ノート:対象読者
先日、私たちは浴場で急上昇していました、そして、どんちゃん騒ぎの子供たちで、いつかソフトウェアの歴史が今と同じように研究されるという考えが響きました-ロシアの歴史。 特別なソフトウェア考古学者は、古代のリポジトリの奥深くから不思議を掘り出し、ほこりを慎重に払い落として収集しようとします。
家に帰ると、「必読」のパパの文書の半分が5年以上前の文書で構成されていることがわかりました。 つまり、今すぐ発掘を開始することができます。なぜ待つのですか。
したがって、この記事と次の記事を読む価値があるかどうかを推奨することは困難です。
泥の中にダイヤモンドを掘ることができることもあれば、ごみがただのごみになることもあります。
平均して、このテキストは仮想マシンの開発に熱心な人を対象としています。
テキストの著者と翻訳者に関する簡単な情報は、記事の最後に記載されています。
そして今、私たちは2013年、春、4月に運ばれ、鳥が歌っています。祖父のクリスチャン・ハウブル、クリスチャン・ウィマー、ハンスペッター・メッセンベックはベンチに座って、状況に応じた痕跡のインライン化について教えてくれます。
1.はじめに
インライン化メソッドに基づいて、JITコンパイラ(以下「ブロックコンパイラ」と呼びます)はメソッド全体を変換し、最適化されたマシンコードに変換します。 トレーサーコンパイラは、頻繁に実行されるパスをコンパイル単位として使用します[1]。 これにより、生成されるマシンコードの量を削減しながら、ピークパフォーマンスが向上します。 図1は、3つのメソッドとそれらに沿った3つのパスの制御フローグラフ(CFG)を示しています。 トレースの開始はトレースアンカーと呼ばれ、この例ではすべてのトレースに対してブロック1で表されます。 どのブロックがアンカーになるかは、トレース記録システムの特定の実装に大きく依存します。
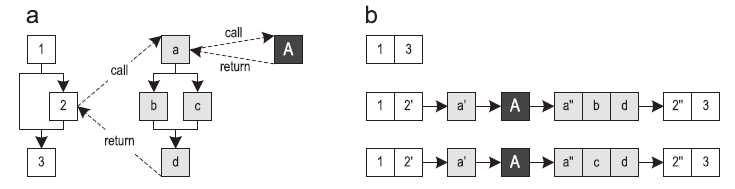 図1. 3つの方法に従うトレース:(a)制御フローグラフ(b)可能なトレース
図1. 3つの方法に従うトレース:(a)制御フローグラフ(b)可能なトレース仮想マシンでは、バイトコードの実行を計測することでトレースを記録できます。 次に、これらのトレースは最適化されたマシンコードにコンパイルされます。 メソッドのまだコンパイルされていない部分が実行されると、通常、システムはインタープリターモードに戻ります。
現在のほとんどのトレース記録の実装では、トレースがメソッドの境界を越えることができます。 [1、2、10、12、18]。 これは、一緒にコンパイルする必要がある大きなトレースにつながる可能性があります。
前の研究[14、15]では、Oracle Java HotSpotのクライアントコンパイラに基づいてトレースJITコンパイラを実装しました。 会議の以前の記事[15]は、トレースのインライン化に焦点を当てており、次の内容が含まれていました。
- インライントレースの実行方法の説明と、インライン化方法に対する利点の説明
- ネイティブトレーサJITコンパイラに実装されたいくつかのインライン化機能の説明
- DaCapo 9.12バッハベンチマークのコンパイル時間、ピークパフォーマンス、および生成されたマシンコードの量に対するトレースインライン化のヒューリスティックの影響の評価[3]。
この記事は、上記のドキュメントの拡張バージョンであり、次の新しい側面を追加します。
- トレースの記録およびインライン化のより詳細な説明
- ネイティブメソッドのコンパイラ組み込み関数が、トレースのインライン化の結果としてコンパイル領域を拡大することでメリットを得る理由の説明
- ベンチマークSPECjbb2005 [23]およびSPECjvm2008 [24]での特定のヒューリスティックの評価。
さらに、最高のヒューリスティックのピークパフォーマンスをHotSpotサーバーコンパイラと比較します。 - コンパイラーのどの高レベル最適化が、コンパイル領域の拡大の結果としてトレースのインライン化の恩恵を受けるかに関する研究。
この記事の残りの部分は次のように構成されています。
- 概要パート2では、トレーサー仮想マシンの簡単な紹介を行います
- パート3では、トレースを記録するシステムを示します。
- パート4では、インライン化の方法を説明します
- パート5では、読者にさまざまなヒューリスティックを紹介します
- パート6でベンチマーク結果について説明します
- パート7では、関連する作業について説明します
- パート8でこの記事を締めくくります。
2.クイックルック
以前の作業では、トレースを記録するためのインフラストラクチャとJava用のトレースJITコンパイラ[14,15]を実装しました。 図2は、VMの構造を示しています。
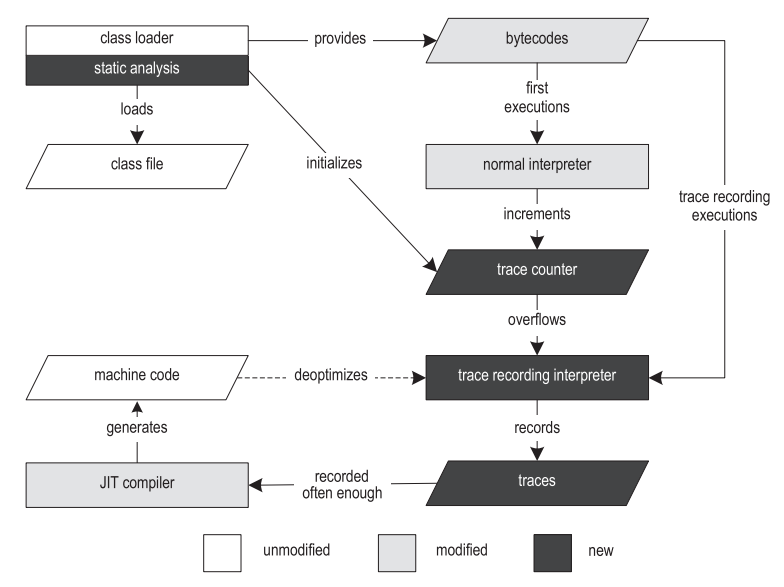 図2.トレーサー仮想マシンの構造
図2.トレーサー仮想マシンの構造実行は、クラスファイルをロード、解析、および検証するクラスローダーから始まります。 クラスローダーは、VMの他の部分を参照する定数プールやメソッドオブジェクトなどのランタイムデータ構造を提供します。 クラスがロードされた後、バイトコードの前処理ステップが実行されます。これにより、ループを見つけ、トレース手順に固有のデータ構造を作成できます。
トラックを記録するために、HotSpot [13]からテンプレートインタープリターを複製し、インストルメントしました。 その結果、普通の通訳者と、トレースを記録した通訳者の両方を得ました。 従来のインタープリターは、変更されていないVMとほぼ同じ速度でバイトコードを実行し、最初の実行に使用されます。 従来のインタープリターがトレースアンカーに遭遇すると、このアンカーの呼び出しカウンターを取得し、1ずつ増やします。 カウンターがオーバーフローすると、アンカーは「ホット」としてマークされ、実行はトレースの記録を伴うインタープリター(以下、「記録インタープリター」と呼ばれます)に切り替わります。 現在の実装では、ループヘッダーにアンカーがあるサイクルトレースと、メソッドエントリにアンカーがあるメソッドトレースの2種類のトレースがサポートされています。
HotSpotは、VMインフラストラクチャの大部分を一緒に使用する2つの異なるJITコンパイラを提供します。 クライアントコンパイラ(クライアントコンパイラ)は、高い起動パフォーマンスを確保し、最も基本的な最適化を実装するために作成されましたが、まともなパフォーマンスを達成するには十分です[19]。 コンパイル時に、コンパイラーは、SSA(静的単一割り当て)[7]にキャストされる高レベルの中間表現(HIR)を生成します。これは、制御フローグラフ(CFG)です。 HIRの構築中および構築後、定数の畳み込み、nullのチェックの排除、インライン化メソッドなどの最適化が適用されます。 最適化されたHIRは、低レベルの中間表現(LIR)に変換されます。これは、マシンコードに非常に近いですが、それでもプラットフォームに依存しません。 次に、LIRは線形スキャン[27]およびコード生成によるレジスタ割り当てに使用されます。
サーバーコンパイラ(サーバーコンパイラ)は、クライアントよりも大幅に多くの最適化を実行し、最高のピークパフォーマンスを生成できる非常に効率的なコードを生成します[21]。 初期JITコンパイルでは、総実行時間に比べてわずかなオーバーヘッドしか発生しないように、長寿命のサーバーアプリケーション向けに設計されています。 サーバーコンパイラは、次のコンパイルフェーズを実行します。解析、最適化に依存しないプラットフォーム、命令の選択、グローバルコードの移動とスケジューリング、グラフ描画用レジスタの割り当て、ピープホール最適化およびコード生成。 サーバーコンパイラは、ループ不変コードモーション、ループアンラッピング、エスケープ分析など、いくつかの追加の最適化を適用できます。
独自のトレーサーJITコンパイラは、HotSpotのクライアントコンパイラに基づいています。 私たちの技術はサーバーコンパイラにも適用できるほど十分に一般化されているという事実にもかかわらず、その複雑な構造は、特に研究プロジェクトの文脈において、コンパイルのトレースに必要な修正にはあまり適していません。 したがって、クライアントコンパイラをベースとして使用することにしました。
トレースが頻繁に作成されるようになると、コンパイラーはまずトレースグラフにそれらをマージします。 この構造は、制御フローグラフ(CFG)とトレースツリー[10]のハイブリッドであり、その中にマージポイントがある場合でも、何らかの利点があれば、いくつかのパスを複製できます。 このレベルでは、一定の折りたたみ、積極的なトレースのインライン化、制御フローの明示的な複製など、一般的なトレース固有の最適化を行います。 この場合に生成されたマシンコードは、その後、インタプリタまたは他のコンパイルされたトレースによって直接呼び出されます。
実行中に積極的な最適化の前提条件に違反した場合、システムは録音インタープリターに対して最適化されません[18]。 最適化解除は、最初に現在のコンパイル済みフレームに存在するすべての値を保存してから、このコンパイル済みフレームを1つ以上の解釈済みフレームに置き換えます。 作成される解釈済みフレームの正確な数は、現在実行されている命令のインライン化の深さに依存します。 その後、解釈されたフレームは以前に保存された値で満たされ、記録インタープリターで実行が継続されます。
記録インタープリターがコードを入力すると、メイントレースのアンカーを使用する代わりに、最適化解除のポイントから直接始まる部分的なトレースを書き込むことができます。 コンパイルされたコードが頻繁に最適化解除されることに気付くために、最適化解除が発生するたびにカウンタが増分されます。 しきい値に達すると、コンパイルされたマシンコードは破棄され、最初に記録されたトレースとすべての部分トレースの両方を使用する新しいコンパイルが開始されます。 これにより、最適化解除の頻度を減らすことができます。たとえば、メソッドの範囲を広げたり、特定の積極的な最適化をオフにしたりできます。
3.トレースの記録
トレースを記録するためのアプローチは、軌道を1つの方法の境界に制限します[14]。 アンカーが非常に頻繁に実行され始めたことがわかった時点で、実行は通常から記録インタープリターに切り替わります。 トレースを記録するために、各スレッドは、現在書き込まれているすべてのトレースを保存するトレースのスタックを保持しています。 制御グラフを変更できる命令に関する情報はスタックの一番上のトレースに格納され、スタックはこのルールをサポートするように適宜変更されます。
トレースの記録中にメソッド呼び出しが行われると、その呼び出しは呼び出しソーストレースに記録されます。 これに加えて、仮想メソッドを呼び出すために、受信クラスも記述されます。 呼び出されたメソッドに入ると、新しいメソッドトレースがスタックにプッシュされ、記録が続行されます。
呼び出されたメソッドが戻ると、対応するトレースがスタックからポップされ、トレースリポジトリに保存されます。 次に、呼び出し元のトラックへのポインタを保存することにより、呼び出し元と呼び出し先のトラックが接続され、さらに録音が呼び出し元のトラックに移動します。 この関係は、メソッドの境界を越えて呼び出しに関する状況依存情報を保存します。これにより、呼び出しの動的なグラフに似たデータ構造が表示されます。
既に保存されているトレースを完全に新しい方法で記録するのではなく、再度記録すると、単純なカウンターの増加が発生します。 トレースの方法が異なる場合、または呼び出されたメソッド内で異なるトレースを呼び出す場合、トレースは異なると考えられます。 したがって、トレースをリンクすると、アプリケーションの任意の部分を通過する完了した各パスの正確な呼び出し情報を取得できます。 記録されたトレースの数を妥当な値に減らすために、サイクルのトレースと再帰メソッドを親トレースに関連付けません。 同じアンカーに対してトレース記録が一定回数実行された直後に、このアンカーのすべての重要なトレースがすでに記録されていると想定され、最適化されたマシンコードにコンパイルされます。
図3は、addDataメソッドの記録が開始されたトレース記録の例を示しています。
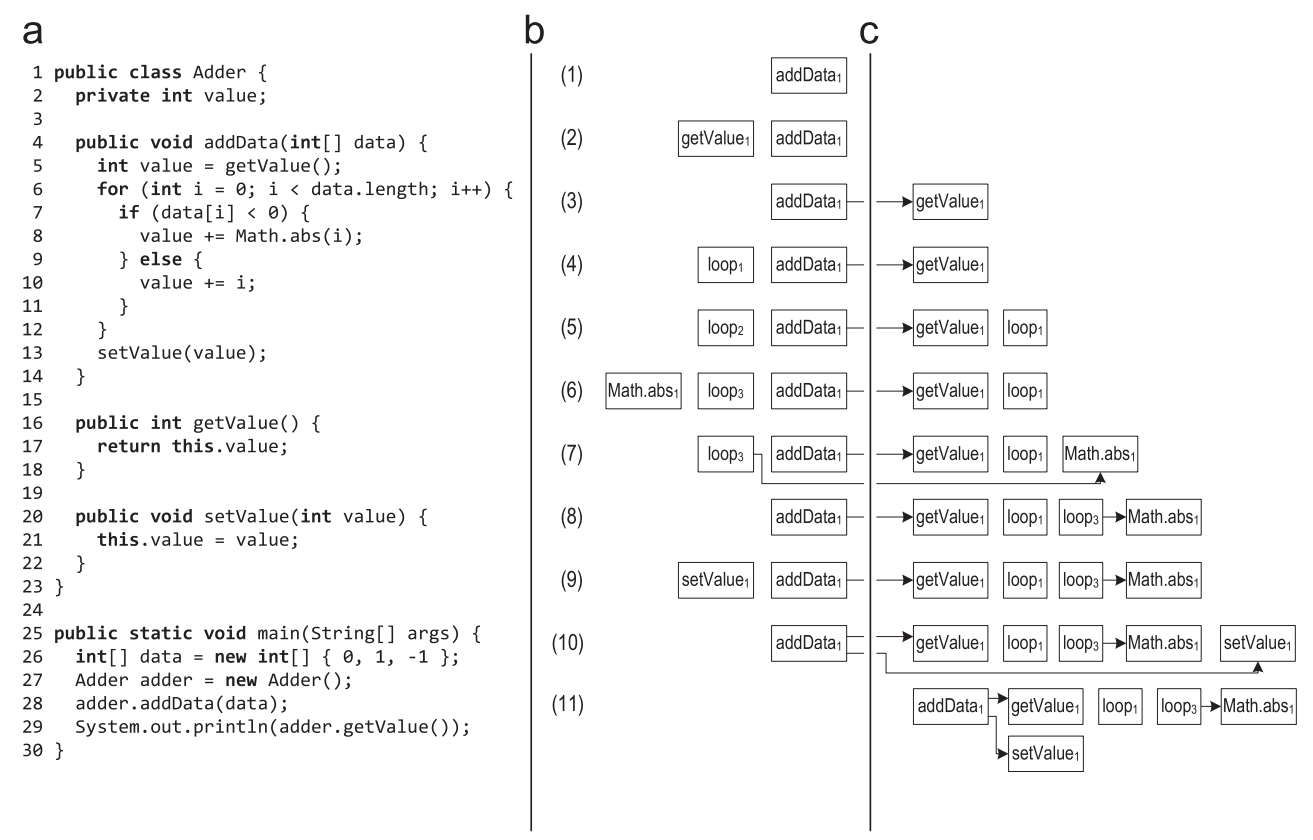 図3.トレースの記録中のトレースのスタック:(a)ソースコード(b)トレースのスタック(c)リポジトリに保存されたトレース
図3.トレースの記録中のトレースのスタック:(a)ソースコード(b)トレースのスタック(c)リポジトリに保存されたトレース- addData()メソッドのアンカーがホットとしてマークされると、実行は記録インタープリターに切り替わり、メソッドトレースがトレーススタックに配置されます。 このメソッドは、仮想getValue()メソッドが呼び出されるまで最初から実行されます。 仮想呼び出しを行うとき、呼び出しクラスと受信クラスは呼び出しトレースに保存されます。
- getValue()メソッドを入力すると、メソッドの新しいトレースがトレースのスタックに配置され、その中に記録が継続されます。
- getValue()が戻ると、対応するトレースがスタックから取得され、トレースストアに保存されます。 その後、getData()トレース内のgetValue()トレースへのポインターを保存することにより、トレースが接続されます。 addData()の実行と書き込みが続行され、ループヘッダーに到達します。
- サイクルを記録するために、新しいサイクルトレースがスタックにプッシュされます。
- ループの最初の反復の後、実行がループヘッダーに戻ると、このループのトレースがスタックから取得され、保存されます。 ループの次の反復では、新しいループトレースがスタックにプッシュされます。 2番目の反復は最初の反復と同じ方法で実行されるため、システムはそのようなトレースがすでに記録されていることを理解し、新しいトレースに保存せず、古い保存済みトレースのカウンターを増やすだけです。
- ループの3回目の反復は異なる方法で行われ、Math.abs()メソッドが呼び出され、そのために新しいメソッドトレースがスタックに配置されます。
- Math.abs()が戻ると、対応するトレースが保存され、呼び出し元のトレースに関連付けられます。
- その後、実行はループヘッダーに到達し、ループが終了します。 サイクルトレースはスタックから取得され、保存されます。
- ループを終了すると、仮想setValue()メソッドが呼び出されます。 呼び出しクラスと受信クラスは呼び出しトレースに保存され、setValue()に入ると新しいメソッドトレースがスタックにプッシュされます。
- setValue()が戻ると、対応するトレースがスタックから取得され、保存され、呼び出しトレースに関連付けられます。
- 最後に、addData()メソッドも返され、スタックから取得されて保存されます。
- その後、スタックは空になり、実行は通常のインタープリターに戻ります。
この例では、呼び出されたメソッドとループについて、トレースがコンパイルされなかったことを意味していました。 getValue()メソッドのトレースがプリコンパイルされている場合、getValue()を呼び出すと、メソッドを解釈するのではなく、コンパイルされたマシンコードが実行されます。 記録インタープリターは、スタックに新しいメソッドトレースを配置できず、呼び出されたメソッドの制御フローを作成できません。 この場合、トレースを記録するアプローチでは、メソッドの境界を越えるときに制御フローに関する特定の情報を確実に保持できませんでした。 コンパイルされたコードを呼び出す必要はなく、代わりに、記録インタープリターでこのコードの実行を少なくとも1回強制し、必要な情報をすべて受信します。 ただし、これにより、アプリケーションがより長く解釈されるため、起動パフォーマンスが大幅に低下します。
最高の記録パフォーマンスのために、頻繁に実行されるすべての操作(特定の命令に関する情報の記録など)は、アセンブラーテンプレートの形式で記録インタープリターに直接実装されます。 記録されたトレースの保存など、より複雑な操作は、Cで記述されたインタープリターランタイムに実装されます。 トレースを記録するためのインフラストラクチャも効率的なマルチスレッド化をサポートしているため、Javaのどのスレッドでも通常のインタープリターと記録インタープリターを個別に切り替えることができます。 各スレッドは、スレッドローカルバッファを使用してトレースを記録し、最高の書き込みパフォーマンスを実現します。
記録中、複数のスレッドが、記録されたトレースを保存するデータ構造で同時に動作できます。 ほとんどのアンカーでは、記録されるトレースの数が非常に少ないため、新しいトレースを保存する必要はほとんどありませんが、実行カウンターの増加は常に必要です。 したがって、保存されたトレースは、読み取り時に最小数のロックとアトミック命令を使用するデータ構造に保存します。 システムが新しいトレースを見つけると思われる場合、他の記録スレッドのこのデータ構造をブロックし、ロック下で、このトレースが本当に新しいかどうかを再確認してから、リポジトリに追加します。 この単純な方法により、最も一般的なケースでは、同期とアトミックマシン命令が回避され、マルチスレッドアプリケーションの書き込みパフォーマンスが大幅に向上します。
4.トレースのはめ込み
メソッドのインライン化は、メソッド呼び出しを実際の実行可能コードのコピーに置き換えます。 インラインヒューリスティックは、静的と動的に分類できます。
HotSpotクライアントコンパイラは、単純な静的メソッドインラインヒューリスティックを使用します。このメソッドでは、メソッドサイズが固定制限と比較されます。 仮想メソッドは、静的クラス階層分析(CHA)[8]を使用してインラインになります。 この分析は、ロードされたサブクラスのいずれかによってメソッドがオーバーライドされているかどうかを判断します。その場合、楽観的にインライン化できます。 次に、楽観的なインラインメソッドをオーバーライドする別のサブクラスがロードされると、生成されたマシンコードは破棄されます。 対照的に、動的インラインヒューリスティックはプロファイルからの情報を使用し、それに基づいてメソッドがインラインかどうかを決定します。
トレーサーJITコンパイラーは、トレースに関する記録情報を使用して、両方のタイプのヒューリスティックを同時にサポートします。 メソッドのインライン化と同様に、トレースのインライン化は呼び出しを実際の実行可能コードのコピーに置き換えます。 これにより、コンパイル領域が増加し、パフォーマンスが向上します。
4.1。 後続インライン化の利点
インライン化のトレースには、インライン化方法に比べていくつかの利点があります。
- トレースのインライン化は、メソッド全体ではなく、頻繁に実行されるトレースのみを処理します。 ブロックコンパイラは、プロファイル情報を使用して、メソッドのほとんど使用されない部分のコンパイルを回避しようとします[9,25,26]。 これにより、トレースのインライン化と同様の効果を得ることができますが、これは単なる追加の二次アプローチです。
- 記録されたトレースには、メソッドのどの部分が使用され、誰が正確に使用したかに関する状況依存情報が含まれています。 この情報はメソッドの境界を越えるときに保存され、一般的に非常に頻繁に使用されるが特定の送信者が現在必要としないメソッドの部分をインライン化しないために使用できます。
- トレースには、仮想コールの受信者に関する情報が含まれており、トレースをリンクした結果、この情報も状況依存です。 呼び出しの特定の場所は、非常に特定のタイプの受信者を持つメソッドのみを呼び出すことが判明する場合があります。 この情報は、仮想メソッドの積極的なインライン化に使用できます。 ブロックコンパイラは、仮想呼び出しの積極的なインライン化のためにプロファイル情報も使用しますが、ほとんどのコンパイラではこの情報は状況依存ではありません。
4.2。 実装
インライン化は、現在の呼び出しサイトでインライン化する必要があるトレースの最大サイズを計算することから始まります。 これは主に、呼び出しのこの場所との関連性に依存します(パート5.1を参照)。 次に、コールのこの場所で呼び出されたトレースをインライン化する価値があるかどうかを決定するヒューリスティックが使用されます。 トレースが多すぎるとコードが肥大化するため、それはこれらのトレースのサイズに大きく依存します。
インライン化のトレースは、通常はトレースが受信者のバイトコード全体をカバーしないことを除いて、インライン化メソッドに似ています。 インライン化する必要があるトレースを取得し、そこからグラフを作成し、メソッド呼び出しをこのグラフの内容に置き換えます。 次に、インラインバイトコード内にあるすべてのリターン操作が、call命令に続く命令による直接ジャンプに置き換えられ、例外スロー命令が送信者のトレースにある例外ハンドラに関連付けられます。
図4(a)は、2つの方法の制御フローグラフを示しています。 これらのメソッドを通過する2つのトレースを図4(b)に示します。 トレースの記録がかなり頻繁に実行され始めた後、記録されたトレースはコンパイルのために送信されます。 図4(c)に、トレースをインライン化した後に得られたグラフを示します(ただし、コントロールグラフの明示的な複製はありません)。 次に、トレースグラフが最適化されたマシンコードにコンパイルされます。
削除されたブロックのいずれかを今後実行する必要がある場合、コンパイルされたコードはインタープリターに対して最適化されません。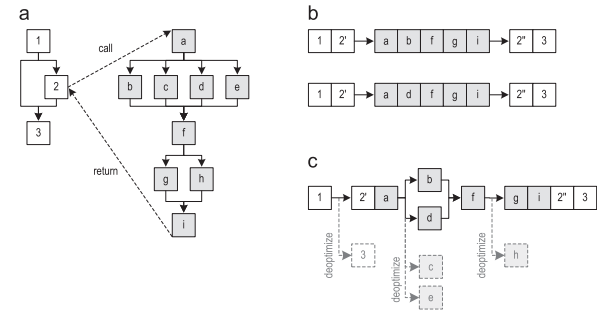 図4.インライン化をトレースするメソッド:(a)制御フローグラフ(b)トレースを記録(c)インライン化後のトレースグラフトレースグラフがブロック3が含まれていません。これは、制御フローのマージを回避するため、素晴らしいアイデアです。マージが行われた場合、これによりコンパイラの最適化が制限されます。実行不可能なエッジを削除すると、マシンコードがより最適化されます。ほとんどの場合、現在の送信者によって呼び出されるトレースのみをインライン化します。ただし、送信者に対してトレースレコードが有効になる前に受信者のトレースがコンパイルされた場合、この送信者は必要なコンパイル済みトレースを知りません。これらの場合、送信者が受信者に渡す特定のパラメーターを使用しているため、現在の送信者が呼び出すことができないことを証明できるものを除き、すべての受信者のトレースはインライン化に適していると控えめに信じています。この背後には、ブロックコンパイラのデッドコード除去(DCE)に似たテクノロジがありますが、ベースブロックの代わりにトレース全体を削除できます。インライントレースの数をさらに減らすために、まれにしか実行されないトレースも除外します(パート4を参照)。5)。仮想メソッドを呼び出すために、記録されたトレースに関する情報はHotSpotクライアントコンパイラからのCHAと組み合わされ、現在の呼び出し場所の特定の受信者クラスを決定できます。 CHAが1つの特定のターゲットメソッドを定義している場合、呼び出されたメソッドのトレースは、クライアントコンパイラがメソッドをインライン化するのと同じ方法でインライン化されます。 CHAがいくつかの可能なターゲットメソッドを見つけた場合、記録された送信側クラスを使用して、メソッドトレースを積極的にインライン化しようとします。これを行うために、実行時チェックを追加します。これは、実際の受信者タイプを期待されるタイプと比較し、タイプが一致しない場合はインタープリターを非最適化します。 CHAと状況依存のトレース情報を組み合わせることにより、ほとんどのブロックコンパイラよりも頻繁に仮想メソッドをインライン化できます。本当に必要な場合にのみランタイムチェックを作成します。メソッドのトレースのインライン化に加えて、循環トレースのインライン化のサポートを開始しました。図5(a)は、巡回トレースを呼び出したメソッドのトレース用に作成されたトレースのグラフを示しています。ループトレイルはまだインライン化されていないため、ループはブラックボックスとして表示されますが、これはコンパイラーにはまだ不明です。次のステップでは、循環トレース専用の個別のトレースグラフを作成します-図5(b)。さらにインライン化すると、送信側グラフのブラックボックスがループグラフに置き換えられ、ジャンプ命令を使用して、ループからのすべての出口が正しい継続ブロックに関連付けられます。この例では、ブロックbはブロックeに接続され、ブロックcはブロックdに接続されています。これにより、図5(c)に示すトレースグラフが表示されます。
図4.インライン化をトレースするメソッド:(a)制御フローグラフ(b)トレースを記録(c)インライン化後のトレースグラフトレースグラフがブロック3が含まれていません。これは、制御フローのマージを回避するため、素晴らしいアイデアです。マージが行われた場合、これによりコンパイラの最適化が制限されます。実行不可能なエッジを削除すると、マシンコードがより最適化されます。ほとんどの場合、現在の送信者によって呼び出されるトレースのみをインライン化します。ただし、送信者に対してトレースレコードが有効になる前に受信者のトレースがコンパイルされた場合、この送信者は必要なコンパイル済みトレースを知りません。これらの場合、送信者が受信者に渡す特定のパラメーターを使用しているため、現在の送信者が呼び出すことができないことを証明できるものを除き、すべての受信者のトレースはインライン化に適していると控えめに信じています。この背後には、ブロックコンパイラのデッドコード除去(DCE)に似たテクノロジがありますが、ベースブロックの代わりにトレース全体を削除できます。インライントレースの数をさらに減らすために、まれにしか実行されないトレースも除外します(パート4を参照)。5)。仮想メソッドを呼び出すために、記録されたトレースに関する情報はHotSpotクライアントコンパイラからのCHAと組み合わされ、現在の呼び出し場所の特定の受信者クラスを決定できます。 CHAが1つの特定のターゲットメソッドを定義している場合、呼び出されたメソッドのトレースは、クライアントコンパイラがメソッドをインライン化するのと同じ方法でインライン化されます。 CHAがいくつかの可能なターゲットメソッドを見つけた場合、記録された送信側クラスを使用して、メソッドトレースを積極的にインライン化しようとします。これを行うために、実行時チェックを追加します。これは、実際の受信者タイプを期待されるタイプと比較し、タイプが一致しない場合はインタープリターを非最適化します。 CHAと状況依存のトレース情報を組み合わせることにより、ほとんどのブロックコンパイラよりも頻繁に仮想メソッドをインライン化できます。本当に必要な場合にのみランタイムチェックを作成します。メソッドのトレースのインライン化に加えて、循環トレースのインライン化のサポートを開始しました。図5(a)は、巡回トレースを呼び出したメソッドのトレース用に作成されたトレースのグラフを示しています。ループトレイルはまだインライン化されていないため、ループはブラックボックスとして表示されますが、これはコンパイラーにはまだ不明です。次のステップでは、循環トレース専用の個別のトレースグラフを作成します-図5(b)。さらにインライン化すると、送信側グラフのブラックボックスがループグラフに置き換えられ、ジャンプ命令を使用して、ループからのすべての出口が正しい継続ブロックに関連付けられます。この例では、ブロックbはブロックeに接続され、ブロックcはブロックdに接続されています。これにより、図5(c)に示すトレースグラフが表示されます。 図5.サイクルトレースのインライン化:(a)メソッドトレースグラフ(b)サイクルトレースグラフ(c)ループインライン化後の状態ループトレースインライン化中、特定のサイクルで記録されたすべてのトレースがインライン化の候補であると考えます。これが必要なのは、サイクリックトレースが呼び出し側トレースに直接リンクされないため、コンテキスト固有の呼び出し情報が利用できないためです。ただし、このサイクルに含まれるパラメーターとローカル変数に関する情報を使用し、それらのおかげで、現在の送信者が呼び出すことができないことを証明できるトレースを削除します。さらに、頻繁に実行されないトレースも削除します。より複雑なケースは、インラインループに出力があり、その継続が送信者グラフに存在しない場合です。図5(a)では、たとえば、ブロックdは記録されていないために消える場合があります。それにもかかわらず、図5(b)に示すように、サイクルからの両方の出口は記録された循環トレースで表すことができます。これが発生する可能性のある方法の1つは、メソッドトレースが記録される前にループトレースがコンパイルされたことです。最初[15]、継続に関連付けられなかったループのすべての出口に最適化ポイントを明示的に追加することでこの問題を回避し、ループがこのパスに沿って終了するたびに実行が最適化されました。ここで、現在の送信者には不明な、サイクルの終了で終わる循環トレースを削除します。これにより、インライン化の候補の数が減り、生成されるマシンコードの量が減ります。
図5.サイクルトレースのインライン化:(a)メソッドトレースグラフ(b)サイクルトレースグラフ(c)ループインライン化後の状態ループトレースインライン化中、特定のサイクルで記録されたすべてのトレースがインライン化の候補であると考えます。これが必要なのは、サイクリックトレースが呼び出し側トレースに直接リンクされないため、コンテキスト固有の呼び出し情報が利用できないためです。ただし、このサイクルに含まれるパラメーターとローカル変数に関する情報を使用し、それらのおかげで、現在の送信者が呼び出すことができないことを証明できるトレースを削除します。さらに、頻繁に実行されないトレースも削除します。より複雑なケースは、インラインループに出力があり、その継続が送信者グラフに存在しない場合です。図5(a)では、たとえば、ブロックdは記録されていないために消える場合があります。それにもかかわらず、図5(b)に示すように、サイクルからの両方の出口は記録された循環トレースで表すことができます。これが発生する可能性のある方法の1つは、メソッドトレースが記録される前にループトレースがコンパイルされたことです。最初[15]、継続に関連付けられなかったループのすべての出口に最適化ポイントを明示的に追加することでこの問題を回避し、ループがこのパスに沿って終了するたびに実行が最適化されました。ここで、現在の送信者には不明な、サイクルの終了で終わる循環トレースを削除します。これにより、インライン化の候補の数が減り、生成されるマシンコードの量が減ります。4.3。 コンテキスト依存
私たちの記録インフラストラクチャは、トレースのサイズを1メソッドの固定深さに制限しているため、トレースコンパイラはトレースの積極的なインライン化に大きく依存しています[15]。トレース記録メカニズムは、メソッドが境界を接するときに状況依存情報を保存するため、各送信者は、受信者のどの部分をインライン化する必要があるかがわかります。これにより、コンパイラは、一般的に非常に頻繁に実行されるが現在の送信者には関係のないメソッドの部分のインライン化を回避できます。これにより、生成されるマシンコードの量が減り、マージポイントの数が減ります。これは通常、ピークパフォーマンスにプラスの効果をもたらします。ブロックコンパイラは、プロファイル情報を使用して、実行されないコードを削除します。ただし、プロファイル内の情報は通常、コンテキスト依存ではないため、メソッドのどの部分をどの送信者が正確に必要とするかを決定できません。プロファイル内の状況依存情報は、原則として、ブロックコンパイラ用にも作成できますが、トレースの作成とトレースコンパイラにより、このプロセスが大幅に簡素化されると考えています。図6は、JDKのArrayListクラスのindexOf()メソッドを示しています。 図6. ArrayList.indexOf()メソッドメソッドの最初の部分は、null検索のまれなケースを処理し、2番目の部分は、null以外のオブジェクトのリストを検索します。ほとんどの送信者には、メソッドの2番目の部分のみが必要です。ただし、メソッドの最初の部分を実行するアプリケーションに少なくとも1人の送信者が表示される場合、ブロックコンパイラプロファイルの情報は、最初の部分も実行されたことを示します。したがって、ブロックコンパイラはindexOf()メソッドをインライン化するたびに、このめったに実行されないコードをインライン化します。状況依存の情報があり、送信者がメソッドの一部を必要としない場合、トレーサコンパイラは上記の問題を回避できます。インライン化はインライン化する場合に読みやすいため、トレースコンパイラは、より積極的なインライン化ポリシーを使用できます。たとえば、ボリュームが大きすぎて完全にインライン化できないメソッドに従うトレースをインライン化できます。これにより、ブロックコンパイラよりも多くのJavaバイトコードをインライン化することなく、コンパイル領域が増加します。特に、複雑なアプリケーションの場合、これによりマシンコードが最適化され、ピークパフォーマンスにプラスの効果があります。図7(a)は、Appendableをラップし、appendLine()メソッドを提供するLineBuilderクラスを示しています。
図6. ArrayList.indexOf()メソッドメソッドの最初の部分は、null検索のまれなケースを処理し、2番目の部分は、null以外のオブジェクトのリストを検索します。ほとんどの送信者には、メソッドの2番目の部分のみが必要です。ただし、メソッドの最初の部分を実行するアプリケーションに少なくとも1人の送信者が表示される場合、ブロックコンパイラプロファイルの情報は、最初の部分も実行されたことを示します。したがって、ブロックコンパイラはindexOf()メソッドをインライン化するたびに、このめったに実行されないコードをインライン化します。状況依存の情報があり、送信者がメソッドの一部を必要としない場合、トレーサコンパイラは上記の問題を回避できます。インライン化はインライン化する場合に読みやすいため、トレースコンパイラは、より積極的なインライン化ポリシーを使用できます。たとえば、ボリュームが大きすぎて完全にインライン化できないメソッドに従うトレースをインライン化できます。これにより、ブロックコンパイラよりも多くのJavaバイトコードをインライン化することなく、コンパイル領域が増加します。特に、複雑なアプリケーションの場合、これによりマシンコードが最適化され、ピークパフォーマンスにプラスの効果があります。図7(a)は、Appendableをラップし、appendLine()メソッドを提供するLineBuilderクラスを示しています。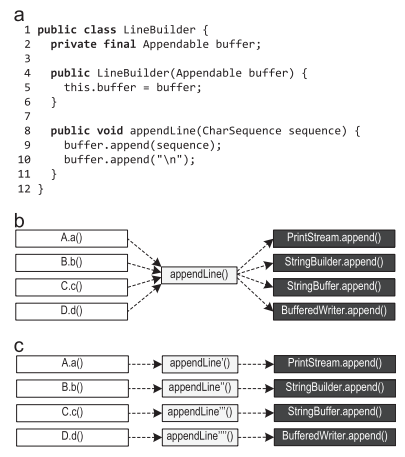 図7.状況依存情報:(a)パターン(b)可能なメソッド呼び出し(c)優先インライン化複数のLineBuilderオブジェクトを使用してPrintStream、StringBuilder、StringBuffer、BufferedWriterなどの異なるクラスのインスタンスをラップする場合、9行目と10行目のappend()呼び出しは、図7(b)に示すようにインライン化が容易ではないポリモーフィック呼び出しになります。たとえば、appendLine()でのスケジューリングが呼び出しの場所に依存する場合、呼び出しのさまざまな場所で異なるLineBuilderオブジェクトが使用されるため、図7(c)に示すように、インライン化が推奨されます。トレースに関する状況依存情報には、仮想コールの受信者も格納されます。したがって、トレースコンパイラは、図7(c)からこの優先インライン化を正確に実行し、利用可能な状況依存情報を使用して、仮想呼び出しの積極的なインライン化を行うことができます。コンパイラが状況依存情報をプロファイルに書き込まず、検出されたすべての型(printStream、StringBuilder、StringBuffer、buffer.Reader with buffer.append()など)を収集するだけの場合、そのような仮想呼び出しをインライン化するのに十分な情報が見つかりません。トレースコンパイラの以前のバージョンでは、呼び出されたメソッドが常に同じ受信者タイプに属することがトレースレコードに示されていた場合、タイプ情報のみを使用していました。このようなインライントレースは、「タイプガード」によって保護されます。「タイプガード」は、実際の受信者のタイプを予想されるタイプと比較し、タイプが一致しない場合はインタープリターに対して非最適化します。この記事では、トレースのインライン化を次の方法で拡張しました。
図7.状況依存情報:(a)パターン(b)可能なメソッド呼び出し(c)優先インライン化複数のLineBuilderオブジェクトを使用してPrintStream、StringBuilder、StringBuffer、BufferedWriterなどの異なるクラスのインスタンスをラップする場合、9行目と10行目のappend()呼び出しは、図7(b)に示すようにインライン化が容易ではないポリモーフィック呼び出しになります。たとえば、appendLine()でのスケジューリングが呼び出しの場所に依存する場合、呼び出しのさまざまな場所で異なるLineBuilderオブジェクトが使用されるため、図7(c)に示すように、インライン化が推奨されます。トレースに関する状況依存情報には、仮想コールの受信者も格納されます。したがって、トレースコンパイラは、図7(c)からこの優先インライン化を正確に実行し、利用可能な状況依存情報を使用して、仮想呼び出しの積極的なインライン化を行うことができます。コンパイラが状況依存情報をプロファイルに書き込まず、検出されたすべての型(printStream、StringBuilder、StringBuffer、buffer.Reader with buffer.append()など)を収集するだけの場合、そのような仮想呼び出しをインライン化するのに十分な情報が見つかりません。トレースコンパイラの以前のバージョンでは、呼び出されたメソッドが常に同じ受信者タイプに属することがトレースレコードに示されていた場合、タイプ情報のみを使用していました。このようなインライントレースは、「タイプガード」によって保護されます。「タイプガード」は、実際の受信者のタイプを予想されるタイプと比較し、タイプが一致しない場合はインタープリターに対して非最適化します。この記事では、トレースのインライン化を次の方法で拡張しました。- , , . , , , , (override) . , « » (method guard), . , .
- , , « » , switch, . , , . , .
- – . 8(a) , . , . , 8(b), 2' / , . switch , . , .
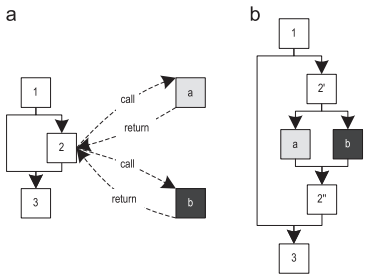 8. : (a) (b)HotSpotサーバーコンパイラは、ポリモーフィックコールもインライン化しますが、呼び出されるメソッドの数は最大2つに制限されます。これは、多数のメソッドが簡単にコードの膨張を引き起こす可能性があるためです。トレーサーコンパイラーは、記録されたトレースに関する状況依存情報を持っているため、メソッドの一部をより選択的にインライン化します。したがって、全体的には頻繁に実行されたものの、現在の送信者には不要なメソッドの一部をインライン化することを回避できます。さらに、記録された型情報も状況依存であるため、インライン化の候補の数が減ります。したがって、トレーサーコンパイラにはインラインメソッドの数に制限はありませんが、特定の呼び出し場所の実行頻度に応じて、すべてのインラインメソッドの総数を制限します。ポリモーフィックコールの数が多いアプリケーションの場合、これにより、インライン化が大幅に改善され、コードの過剰な膨張の問題なしにパフォーマンスが向上します。
8. : (a) (b)HotSpotサーバーコンパイラは、ポリモーフィックコールもインライン化しますが、呼び出されるメソッドの数は最大2つに制限されます。これは、多数のメソッドが簡単にコードの膨張を引き起こす可能性があるためです。トレーサーコンパイラーは、記録されたトレースに関する状況依存情報を持っているため、メソッドの一部をより選択的にインライン化します。したがって、全体的には頻繁に実行されたものの、現在の送信者には不要なメソッドの一部をインライン化することを回避できます。さらに、記録された型情報も状況依存であるため、インライン化の候補の数が減ります。したがって、トレーサーコンパイラにはインラインメソッドの数に制限はありませんが、特定の呼び出し場所の実行頻度に応じて、すべてのインラインメソッドの総数を制限します。ポリモーフィックコールの数が多いアプリケーションの場合、これにより、インライン化が大幅に改善され、コードの過剰な膨張の問題なしにパフォーマンスが向上します。4.4。 ネイティブメソッド
Javaコードは、Java Native Interface(JNI)を使用してネイティブメソッドを呼び出すことができます。このメカニズムは主に、他の方法ではJavaで表現できないプラットフォーム固有の機能を実装するために使用されます。これらのメソッドに対してJavaコードは実行されないため、トレースを書き込むことはできません。HotSpotは、最も重要なプラットフォーム固有のメソッドにコンパイラ組み込み関数を使用するため、JITコンパイラはそのようなメソッドをインライン化できます。トレーサーJITコンパイラーが、コンパイラーの組み込み関数として実装されたネイティブメソッドの呼び出しを含むトレースグラフをコンパイルする場合、ブロックコンパイラーとまったく同じインライン展開を行います。ただし、トレーサーコンパイラには1つの利点があります。トレースはメソッドよりも小さいため、トレーサーコンパイラは、ブロックコンパイラのインラインJavaメソッドよりも積極的にトレースをインライン化できます。これにより、コンパイルの範囲が拡張され、ネイティブメソッドを呼び出すコードは、このネイティブメソッドに入るパラメーターを正確に認識します。 JITコンパイラはこの情報を使用して、インラインコンパイラ組み込み関数を積極的に最適化できます。図9(a)は、プリミティブ配列のコピーに使用されるネイティブSystem.arraycopy()メソッドを実装するための擬似コードを示しています。 図9.プリミティブ配列をコピーするSystem.arraycopy()メソッドの疑似コード:(a)非最適化コード(b)最適化コードSystem.arraycopy()に渡されたパラメーターに関するどの情報がコンパイラーに知られているかに応じて、コンパイラーは組み込み関数を最適化できます。図9(b)は、コンパイラーがパラメーター値を最適に活用できるメソッドの最適化バージョンを示しています。この特定の例に必要なパラメーター情報は、ソース配列と宛先配列がSystem.arraycopy()がインラインである同じコンパイル領域にある場合に利用可能になります。つまり、コンパイル領域を増やすことで、インラインコンパイラ組み込み関数のパフォーマンスを向上させることができます。
図9.プリミティブ配列をコピーするSystem.arraycopy()メソッドの疑似コード:(a)非最適化コード(b)最適化コードSystem.arraycopy()に渡されたパラメーターに関するどの情報がコンパイラーに知られているかに応じて、コンパイラーは組み込み関数を最適化できます。図9(b)は、コンパイラーがパラメーター値を最適に活用できるメソッドの最適化バージョンを示しています。この特定の例に必要なパラメーター情報は、ソース配列と宛先配列がSystem.arraycopy()がインラインである同じコンパイル領域にある場合に利用可能になります。つまり、コンパイル領域を増やすことで、インラインコンパイラ組み込み関数のパフォーマンスを向上させることができます。4.5トレースフィルタリング
トレースがすでに記録されている場合、このトレースが非常に重要であり、頻繁に実行される可能性が高くなります。ただし、記録されたトラックがまれにしか実行されない場合があります。これらのトレースを捨てることで、重要なパスのみがコンパイルされることを保証できます。図10(a)は、記録されたすべてのトレースをマージした後のトレースのグラフを示しています。グラフの端には、実行頻度が注釈として付けられています。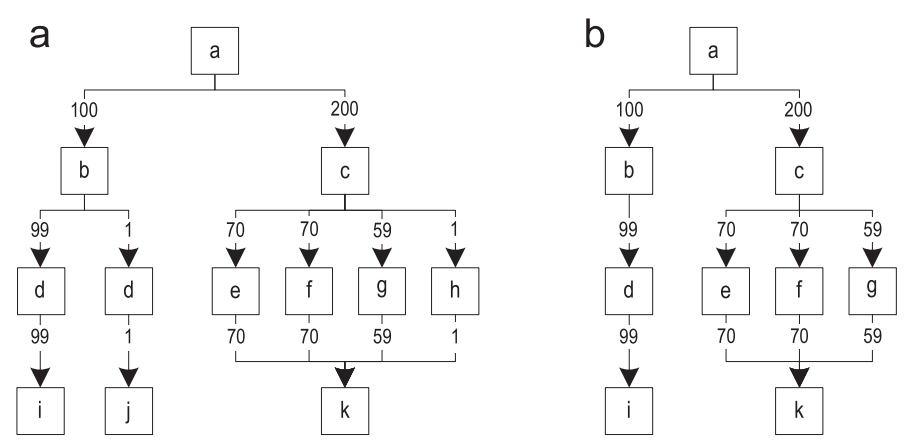 図10.まれにしか実行されないトレースのフィルタリング:(a)元のトレースグラフ(b)フィルタリング後のトレースグラフ各ブロックについて、最も頻繁に実行される出力エッジを決定し、この周波数を同じブロックの他のすべての出力エッジと比較します。次に、100分の1の頻度でエッジを削除します。すべてのブロックを処理した後、使用できないブロックをグラフから削除します。図10(b)は、フィルタリング後の結果のグラフを示しています。トレースに関する記録された情報は、特定の時間枠でのみ観察されたプログラムの動作を保存します。実行の後の段階では、めったに実行されない(したがってリモートの)パスが再び重要になる可能性があります。プログラムの動作は時間とともに変化します。事前にコンパイルされていないパスの実行が開始されるため、これにより頻繁に最適化が解除されます。不必要に頻繁に最適化解除が検出されると、古いコンパイル済みマシンコードは破棄され、新しいコンパイルが開始されます。このコンパイルにより、頻繁に最適化が解除されるケースのトレースのフィルタリングが回避されます。トレースのフィルタリングには、個別に対処する必要があるいくつかの難しいケースがあります。
図10.まれにしか実行されないトレースのフィルタリング:(a)元のトレースグラフ(b)フィルタリング後のトレースグラフ各ブロックについて、最も頻繁に実行される出力エッジを決定し、この周波数を同じブロックの他のすべての出力エッジと比較します。次に、100分の1の頻度でエッジを削除します。すべてのブロックを処理した後、使用できないブロックをグラフから削除します。図10(b)は、フィルタリング後の結果のグラフを示しています。トレースに関する記録された情報は、特定の時間枠でのみ観察されたプログラムの動作を保存します。実行の後の段階では、めったに実行されない(したがってリモートの)パスが再び重要になる可能性があります。プログラムの動作は時間とともに変化します。事前にコンパイルされていないパスの実行が開始されるため、これにより頻繁に最適化が解除されます。不必要に頻繁に最適化解除が検出されると、古いコンパイル済みマシンコードは破棄され、新しいコンパイルが開始されます。このコンパイルにより、頻繁に最適化が解除されるケースのトレースのフィルタリングが回避されます。トレースのフィルタリングには、個別に対処する必要があるいくつかの難しいケースがあります。- , , (. 5( c )). , . , , . .
- . , . , , .
5.
この部分で示されるすべてのインラインヒューリスティックは、最初に呼び出し場所の関連性を計算し、次に関連性の値を使用してインライン化するサイズを計算するという点で類似しています。インライン化の必要性に関する具体的な決定は、インライン化することを決定したトレースの実際のサイズと最大サイズの単純な比較です。評価のために、いくつかのヒューリスティックとさまざまな関連度計算アルゴリズムの組み合わせを使用しました。5.1。 呼び出しサイトの関連性
呼び出しの場所の関連性は、この呼び出しの場所が配置されているトレースグラフ内のブロックの関連性によって決まります。 3つの異なる関連度計算アルゴリズムをテストし、図11に示すトレースグラフAとBの2つの例を使用してその動作を説明しました。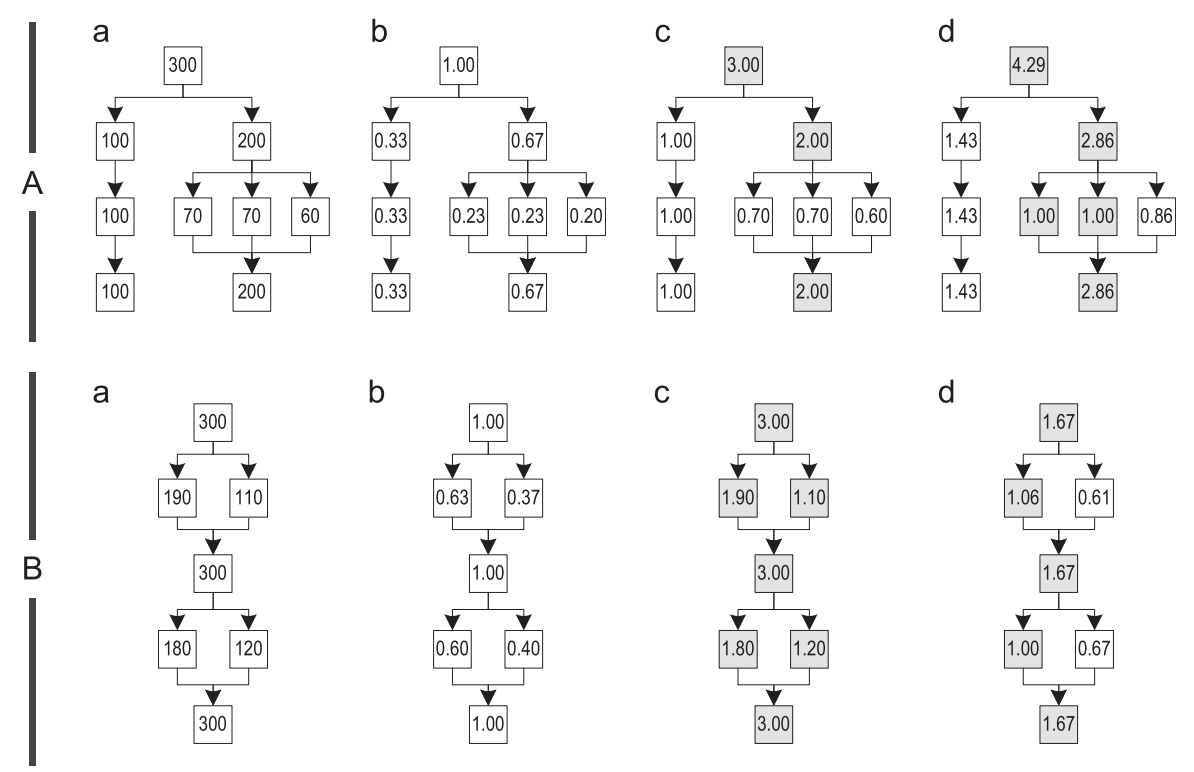 図11.異なる関連度計算アルゴリズム:(a)実行回数のカウント(b)シンプル(c)最も頻繁なトレース(d)パスベースの例Aは、同一のブロックを持つ可能性が低い4つの異なるトレースから構築されています。例Bは、4つのトレースで構築されたグラフを表していますが、それらの各ブロックは少なくとも1つ以上のトレースに共通です。ブロックの関連性を計算するには、まず各ブロックが記録されたトレースが実行される頻度を決定します。図11(a)は、各ブロックに対応する実行頻度の注釈が付けられたグラフを示しています。次に、実行頻度を初期値で割ることにより、各ブロックの関連性を計算します。この値に応じて、関連性のスケールが異なります。次のアルゴリズムのいずれかを使用して、初期値を選択します。
図11.異なる関連度計算アルゴリズム:(a)実行回数のカウント(b)シンプル(c)最も頻繁なトレース(d)パスベースの例Aは、同一のブロックを持つ可能性が低い4つの異なるトレースから構築されています。例Bは、4つのトレースで構築されたグラフを表していますが、それらの各ブロックは少なくとも1つ以上のトレースに共通です。ブロックの関連性を計算するには、まず各ブロックが記録されたトレースが実行される頻度を決定します。図11(a)は、各ブロックに対応する実行頻度の注釈が付けられたグラフを示しています。次に、実行頻度を初期値で割ることにより、各ブロックの関連性を計算します。この値に応じて、関連性のスケールが異なります。次のアルゴリズムのいずれかを使用して、初期値を選択します。- Simple : – , . ]0,1], , , 11(b).
- Most frequent trace : , , - . , , , , . , , , ]0,1] , . 11( c ), , , 1, B.
- Path-based : . . «» , , . (. 11(d)). , . , , , , , , [1; ∞], ]0,1[.
5.2。構成
静的および動的の15のインラインヒューリスティックから始めました。各ヒューリスティックについて、適切なパラメーターの体系的な検索を実行しました。この評価中、すべての動的ヒューリスティックはすべての静的ヒューリスティックよりも優れていたため、この記事では静的ヒューリスティックの詳細な結果は示しません。さらに、良好なピークパフォーマンスまたは少量の生成されたマシンコードを示した動的なヒューリスティックオプションのみを説明します。- Minimum code : 35 , . 1 , 1 – . «path-based», . «simple», , , . .
- Balanced : 40 , , . 1 , 1 . , , . «path-based» , .
- Performance : – 150 , , 1. . , «path-based». , , .
- Greedy : , – 250 , 1. , , «most frequent trace». , . , , 6, . , , .
ブロックコンパイラと同様に、すべてのヒューリスティックは、ゲッターセッターなどの小さなメソッドが一般的に常にインラインであることを検証します。 小さなトレースを呼び出すには、インライン化よりも多くのマシンコードが必要になる場合があるため、これは理にかなっています。 HotSpotサーバーコンパイラで使用されるもう1つの戦略は、レシーバーが既に個別にコンパイルされている場合、またはコンパイルによって多数のマシンコードが生成される場合、メソッドのインライン化を回避することです。 これは、十分に広いコンパイル領域には、適切なコンパイラ最適化のための十分な情報がすでにあるため、コンパイル領域を特定の境界を超えて増やすことはお勧めできません。 この手法は、パフォーマンスに測定可能な影響を与えることなく、生成されるマシンコードの量を減らすため、すべてのインラインヒューリスティックに使用します。
ネストされたトレースをインライン化する可能性を減らすために、インライントレースが親の呼び出し場所から関連性を継承することを確認します。 これを行うには、呼び出された各ブロックの関連性に呼び出し元ブロックの関連性を掛けます。 ただし、継承の関連性の最大値を1に制限します。そうしないと、インライン化のレベルに応じて関連性が高くなる可能性があります。 繰り返しますが、関連性の継承は、パフォーマンスに測定可能な悪影響を与えることなく、生成されるマシンコードの量を減らします。これが、すべてのヒューリスティックによって使用される理由です。
6.テストと評価
JDK8 [20]で開発中のアーリーアクセスバージョンのb12を使用して、HotSpot VMのIA-32アーキテクチャ用のトレーサーJITコンパイラを実装しました(2013年-翻訳者コメント)。 インラインヒューリスティックをテストするために、SPECjbb2005 [23]、SPECjvm2008 [24]、およびDaCapo 9.12 Bach [3]を選択しました。これらは多数の異なるチェックをカバーしているためです。 ベンチマークが開始されたベンチマークの構成は次のとおりです:2.66 GHzの周波数で4コアのIntel Core-i5プロセッサー、4n256 kb L2キャッシュ、8 MB共有L3キャッシュ、8 GBメインメモリ、およびオペレーティングシステムではなくWindows 7 Professional。
結果は、変更されていないブロッククライアントコンパイラHotSpotを基準にして表示されます。これは100%と見なされます。 トレーサーJITコンパイラーの場合、生成されるマシンコードの量には、インタープリターで失敗するために必要な最適化解除に関する追加情報など、トレーサーコンパイルに固有のデータも含まれます。 上記のベンチマークはそれぞれ10回実行されました。結果は、95%の信頼区間でこれらの結果の平均を示しています。
6.1。 SPECjbb2005
このベンチマークは、すべての操作が、いわゆるウェアハウスに分割されたインメモリデータベースで実行されるクライアント/サーバービジネスアプリケーションをシミュレートします。 ベンチマークは異なる数の倉庫で実行され、各倉庫は個別のスレッドで処理されます。 4コアのスタンドを使用したため、1秒あたりのビジネスオペレーション(1秒あたりのビジネスオペレーション、ボップ)で測定される公式スループットSPECjbb2005は、倉庫4〜8のパフォーマンスの幾何平均として定義されます。 1200MBサイズのヒップがすべての測定に使用されました。
図12は、SPECjbb2005のピークパフォーマンス、生成されたマシンコード、およびコンパイル時間を示しています。 トレーサーコンパイラオプションはすべて、ピーク速度の点でクライアントコンパイラよりも大幅に高速でした。 より積極的なトレースインライン化はピークパフォーマンスの向上につながりましたが、生成されるマシンコードの量の増加につながり、コンパイルブロックが非常に大きくなるため、コンパイルに時間がかかりました。 SPECjbb2005のピークパフォーマンスは、トレースのインライン化の積極性が高まるため、「パフォーマンス」構成から明らかに改善されます。 貪欲な構成によりピークパフォーマンスが向上しましたが、ほんのわずかであり、はるかに多くのマシンコードが生成されました。 コンパイル時間と生成されるマシンコードの量の観点から、「最小コード」構成は、適切なピークパフォーマンスを提供しながら、特に効率的であることが証明されました。
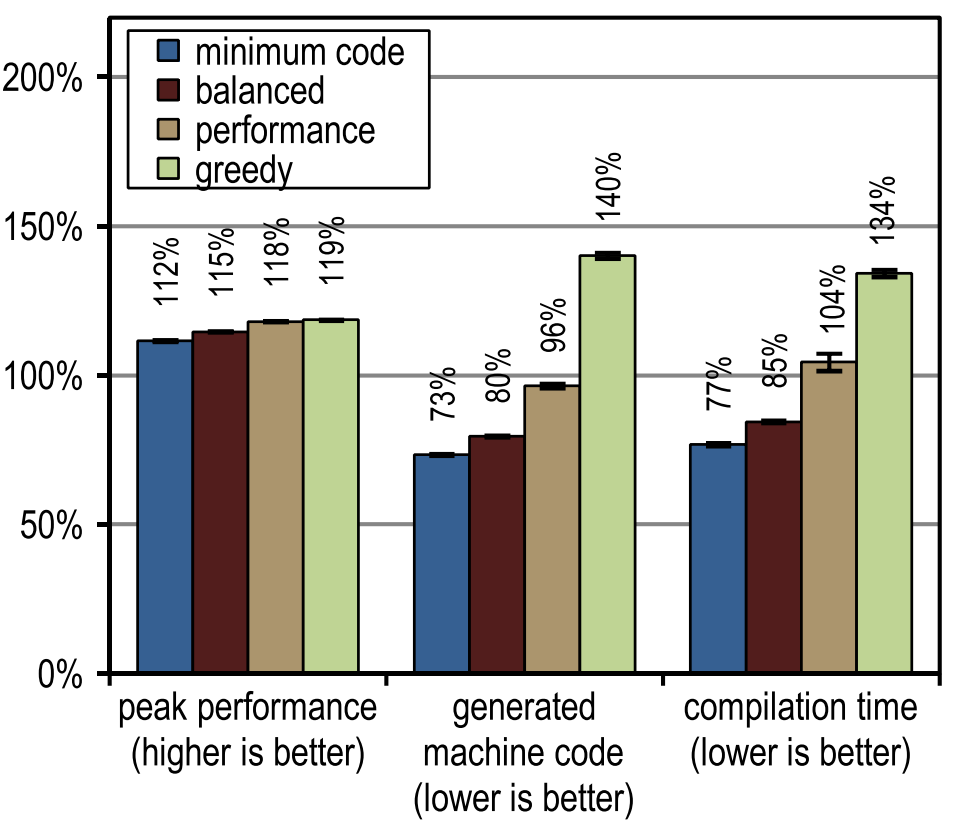 図12. SPECjbb2005の結果
図12. SPECjbb2005の結果図13は、異なる数の倉庫と異なるインラインヒューリスティックに対するSPECjbb2005のピークパフォーマンスを反映しています。 各倉庫は個別のスレッドで処理され、スタンドにはコアが4つしかないため、4つの倉庫で最大のパフォーマンスが達成されました。 この図は、ウェアハウスの数に関係なく、構成がブロッククライアントコンパイラを追い越すことを示しています。
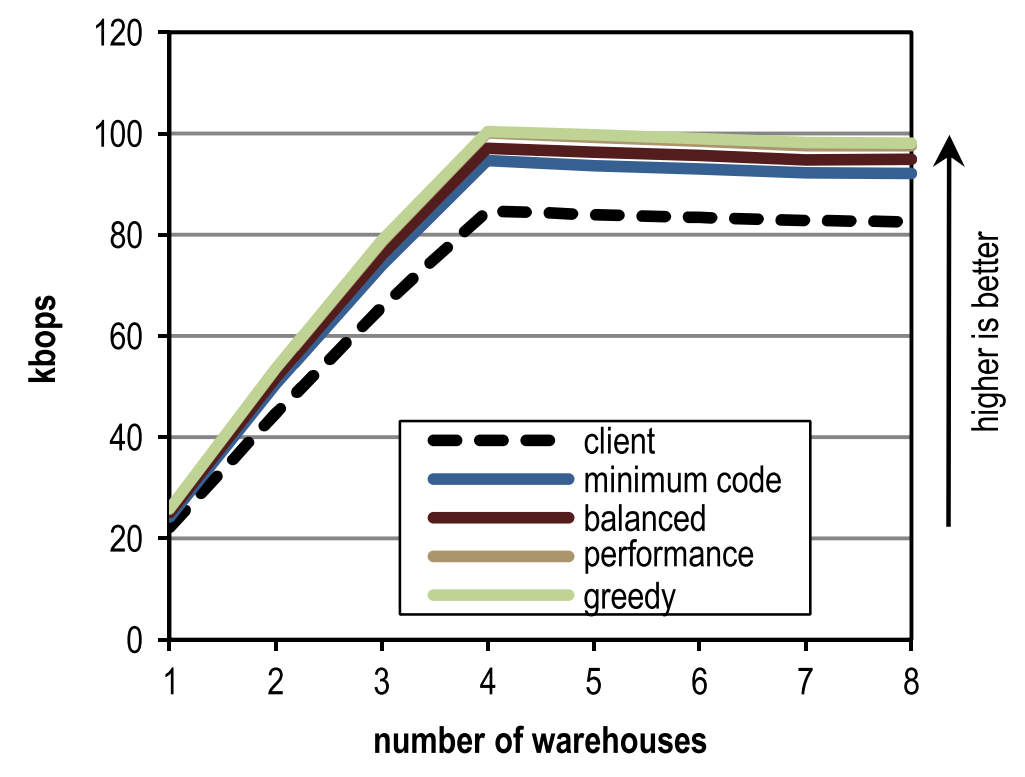 図13. SPECjbb2005の異なる数の倉庫のピークパフォーマンス
図13. SPECjbb2005の異なる数の倉庫のピークパフォーマンス6.2。 SPECjvm2008
SPECjvm2008は、ピークパフォーマンスを測定する9つのカテゴリのテストで構成されています。 個々のテスト結果の直後に、すべての結果の幾何平均が表示されます。 すべてのテストで1024 MBのヒップが使用されました。
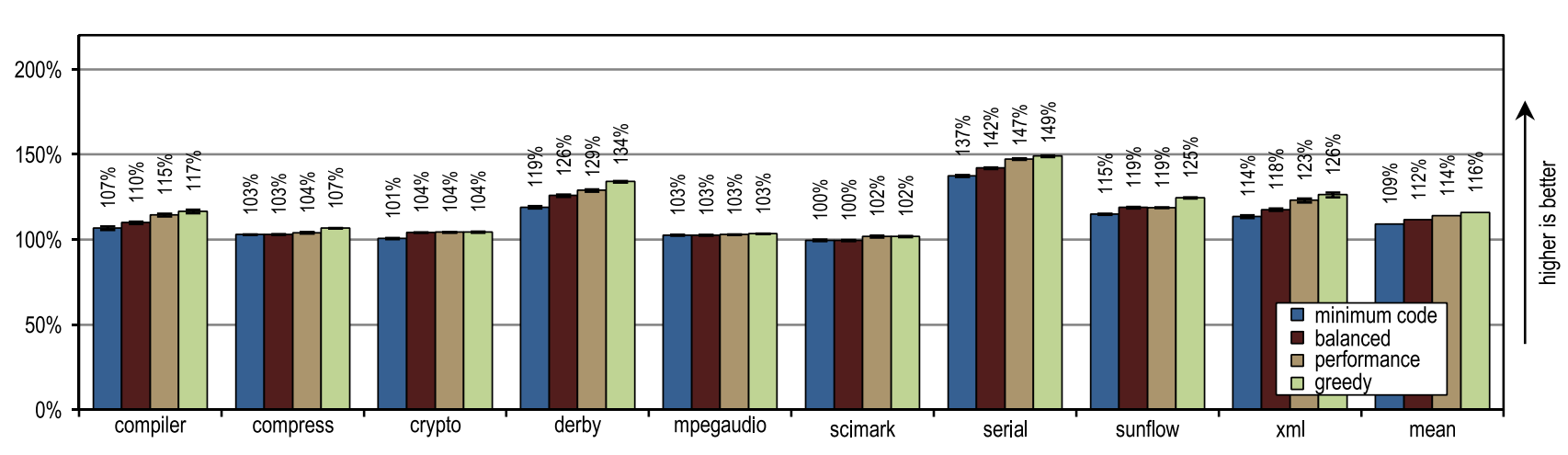 図14. SPECjvm2008のピークパフォーマンス
図14. SPECjvm2008のピークパフォーマンス図14は、すべての構成がHotSpotブロッククライアントコンパイラよりも優れていることを示しています。 これらの構成は、ダービーおよびシリアルテストで最大の加速を示しました。 それらのトレースのインライン化により、HotSpotクライアントコンパイラで使用されるメソッドのインライン化よりも大きなコンパイル領域に到達できました。 貪欲な構成など、非常に積極的なトレースインライン化ポリシーは、特にダービーおよびサンフローベンチマークのピークパフォーマンスの向上につながりませんでした。 さらに、トレースの積極的なインライン化により、生成されるマシンコードの量とJITコンパイルの時間が増加しました(図15および16を参照)。
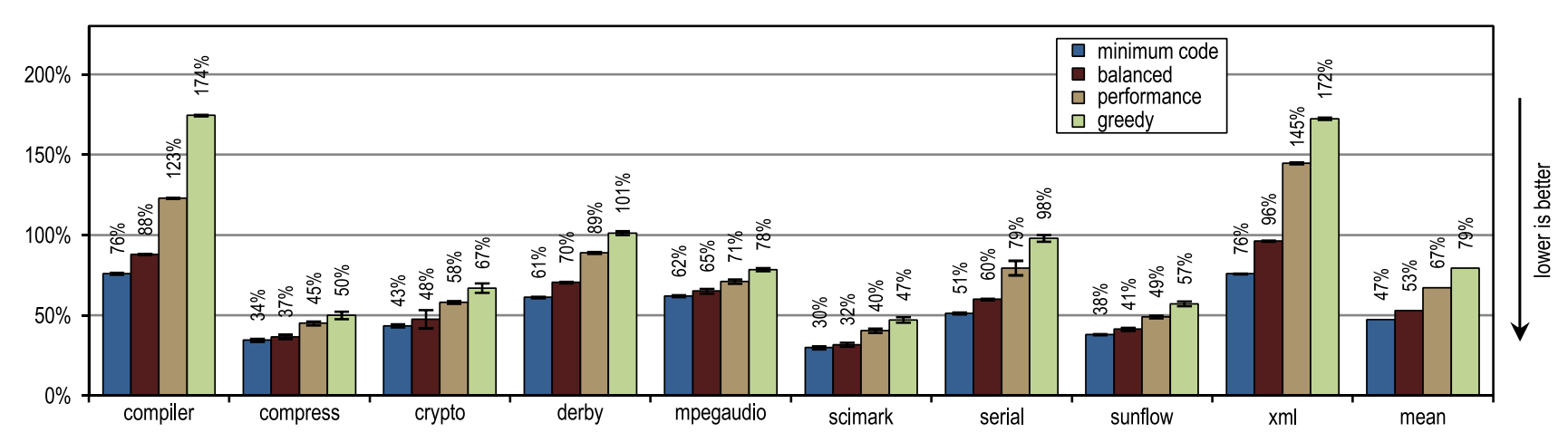 図15. SPECjvm2008で生成されたマシンコードの量
図15. SPECjvm2008で生成されたマシンコードの量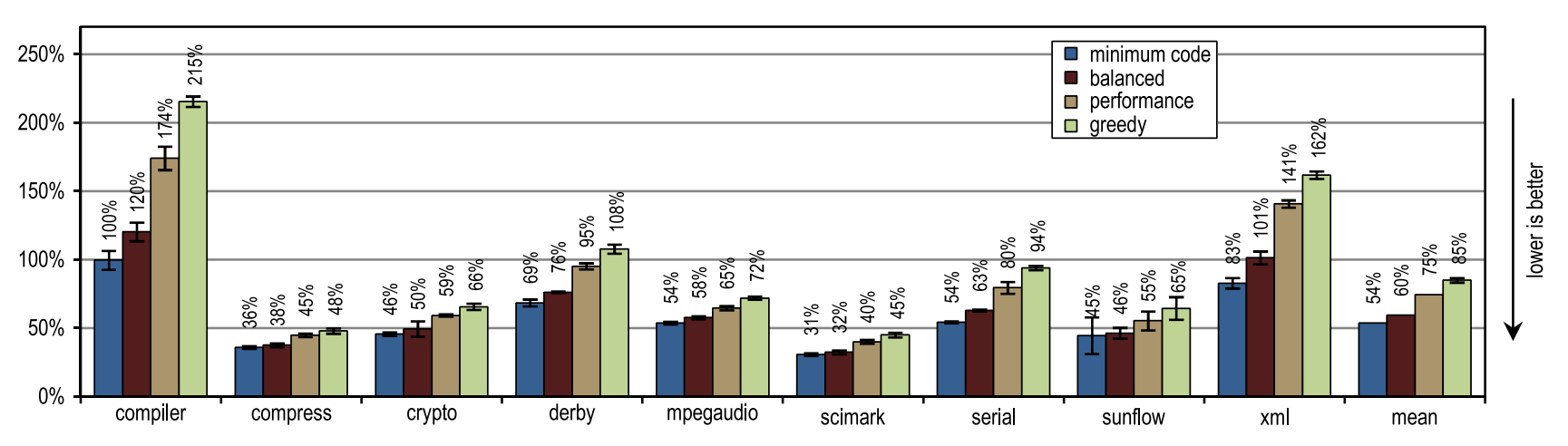 図16. SPECjvm2008でのコンパイル時間
図16. SPECjvm2008でのコンパイル時間HotSpotブロッククライアントコンパイラーはパフォーマンスクリティカルなループですべての呼び出しをインライン化することもできたため、暗号、mpegaudio、およびscimarkループを頻繁に使用する小規模なテストでは、ピークパフォーマンスの増加はほとんどありませんでした。 これらのテストのサイズが小さいため、トレーサーコンパイラは同等のコンパイル領域のみを達成できました。 しかし、トレーサーコンパイラーは、メソッドのコンテンツ全体ではなくトレースをインライン化するため、生成されるマシンコードの作成が少なくなり、コンパイル時間が短縮されました(図15および16を参照)。
図15は、生成されるマシンコードの量がインライン化サイズに依存するため、大量のコードが突然生成されることを示しています。 それにもかかわらず、最も積極的なインラインヒューリスティックが使用されている場合でも、小規模で集中的にループベンチマークを使用しても、コードが過度に増加することはありません。 このようなベンチマークでは、インラインヒューリスティックは非常に保守的である必要があり、あまり積極的に行動しないでください。
6.3。 ダカポ
DaCapo 9.12 Bachは、Javaで記述された14のアプリケーションで構成されています。 デフォルトのデータサイズとヒープサイズ1024 MBを使用して、各テストを20回繰り返し実行したため、実行時間が収束しました。 各テストの最速開始と、すべての結果の幾何平均のみを示します。 すべての測定には、1024 MBのヒップサイズが使用されました。
図17はDaCapo 9.12 Bachのピークパフォーマンスを示し、図18は生成されたマシンコードの量を示しています。 貪欲なインラインヒューリスティックは最高のピークパフォーマンスを示しましたが、変更されていないHotSpotクライアントコンパイラよりも多くのマシンコードを生成しました。 特に、luindex、pmd、sunflowは、最大のインラインサイズを提供するため、greedyを使用することで恩恵を受けています。 ただし、一部のテストでは、このヒューリスティックは非常に攻撃的であるため、ピークパフォーマンスに大きな変化を与えずに過剰な量のマシンコードが生成されます。
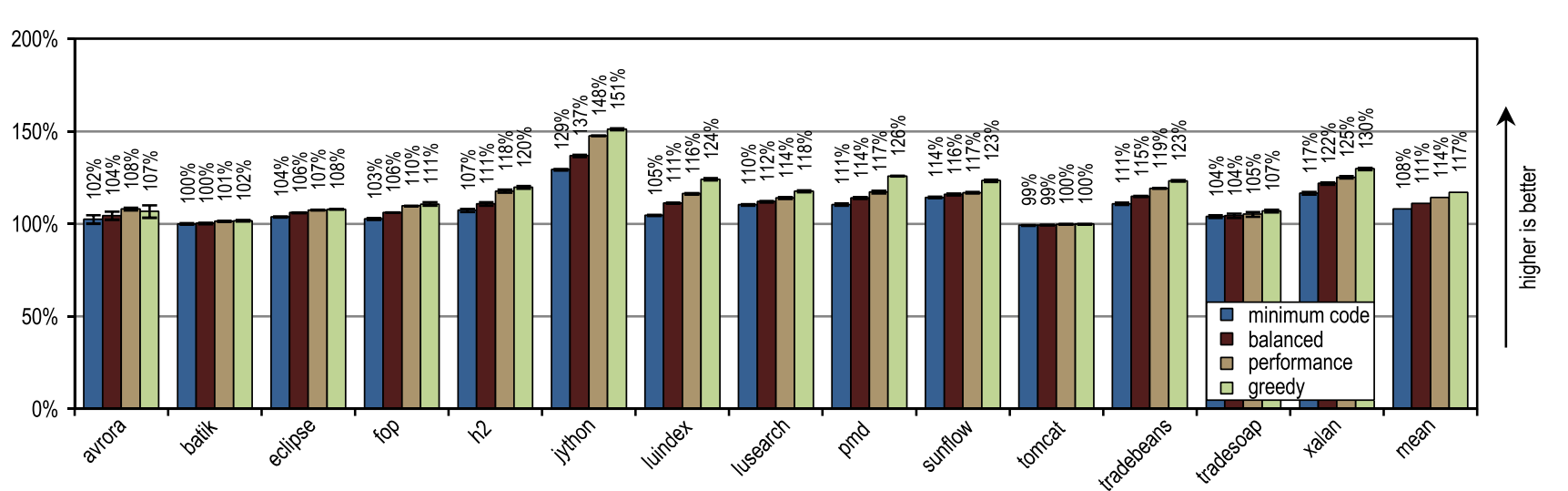 図17. DaCapo 9.12 Bachのピークパフォーマンス
図17. DaCapo 9.12 Bachのピークパフォーマンス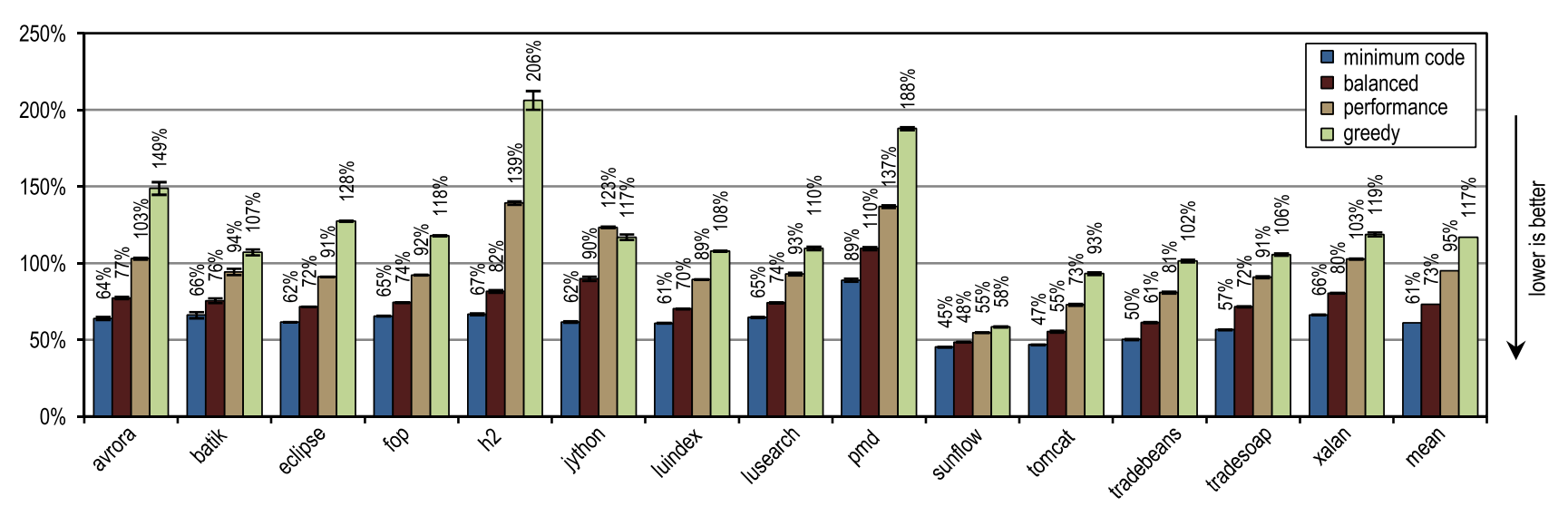 図18. DaCapo 9.12 Bachで生成されたマシンコードの量
図18. DaCapo 9.12 Bachで生成されたマシンコードの量構成は、多数の仮想呼び出しを行うjythonテストで最も有利になりました。 トレーサコンパイラは、記録されたトレース情報を使用して、仮想メソッドを積極的にインライン化します。 ここで彼はコンパイル領域を増やして、高いピークパフォーマンスを実現しました。
平均して、「貪欲」を除くすべてのインラインヒューリスティックは、HotSpotブロッククライアントコンパイラよりも少ないマシンコードを生成し、より高い平均ピークパフォーマンスを示しました。 トレースのサイズを固定最大値と比較した静的ヒューリスティックの1つは、「最小コード」構成とほぼ同じピークパフォーマンスを達成しましたが、より多くのマシンコードを生成しました。 定義により、コンパイルされたトレースには頻繁に使用されるパスのみが含まれていたため、静的ヒューリスティックに非常に適したこの結果が達成されました。 ただし、大きなフローのないメソッドの場合は、トレースのサイズを固定のしきい値と単純に比較するだけで十分です。 最大インラインサイズが引き続き小さい限り、この静的なヒューリスティックはまともな結果を示しますが、最大インラインサイズが大きくなると、パフォーマンスにプラスの影響を与えることなく、大量のマシンコードが生成されます。
JITコンパイルに必要な時間に関して、図19は、トレーサーコンパイラが非常に効率的であり、最も攻撃的な貪欲な構成でも、平均してHotSpotブロッククライアントコンパイラが必要とするのと同じコンパイル時間しか必要ないことを示しています。
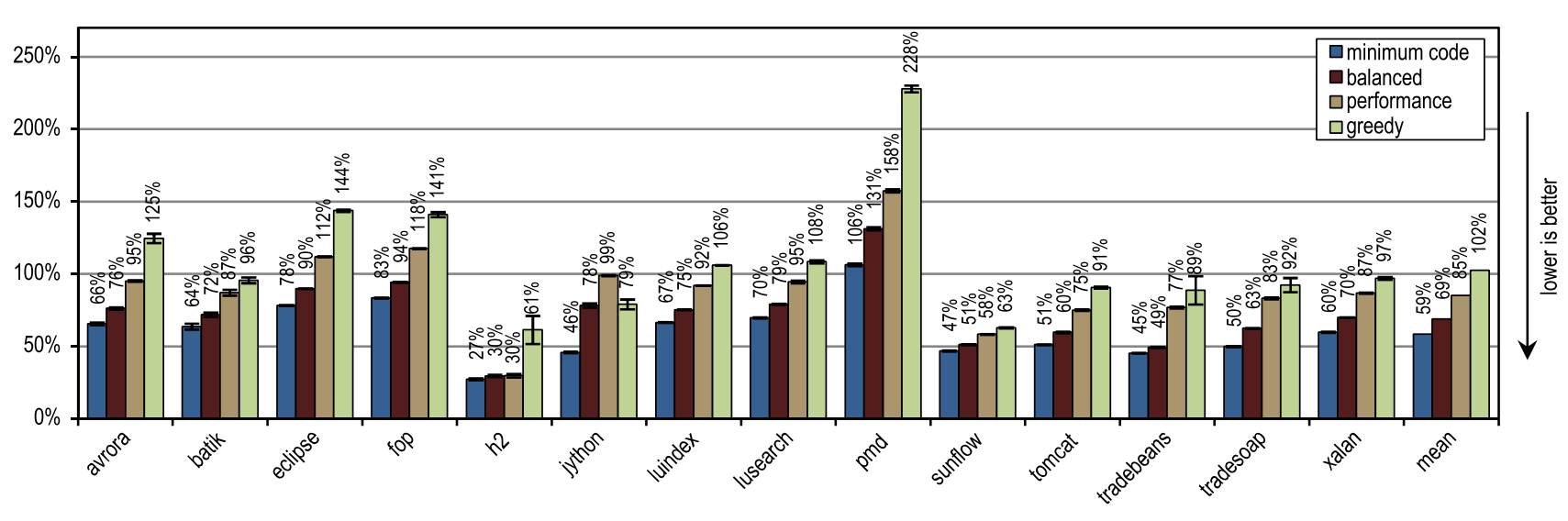 図19. DaCapo 9.12 Bachでのコンパイル時間
図19. DaCapo 9.12 Bachでのコンパイル時間6.4。 高レベルの最適化
インライン化メソッドと同じように、トレースのインライン化は、コンパイル領域を増やすため、他のコンパイラーの最適化にプラスの効果をもたらす最適化です。 図20は、HotSpotブロッククライアントコンパイラとトレーサコンパイラの両方で使用されるさまざまな高レベルの最適化のピークパフォーマンスへの寄与を比較しています。 1としてマークされた最適化は、バイトコード解析中に直接適用されるローカル最適化であり、2としてマークされた最適化は、グラフ構築後の別のフェーズで実行されるグローバル最適化です。
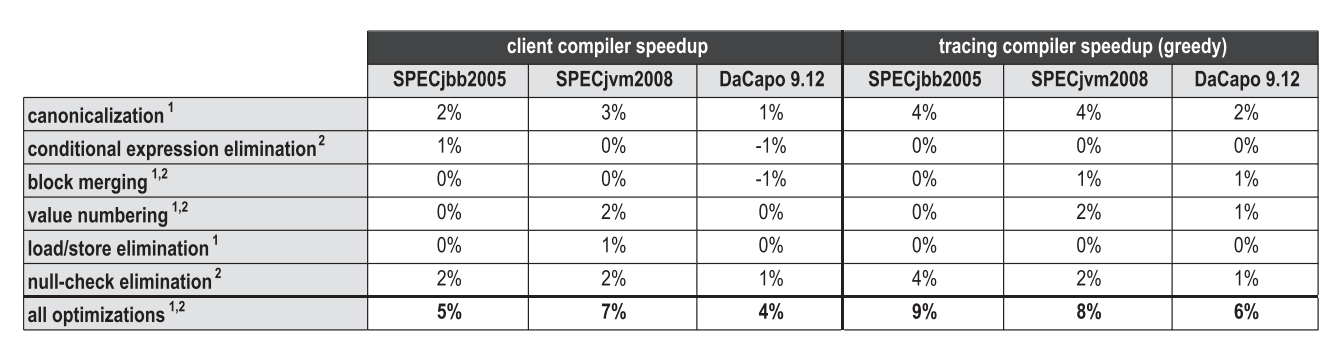 図20.ピークパフォーマンスに対する高度な最適化の影響
図20.ピークパフォーマンスに対する高度な最適化の影響一般に、トレースの積極的なインライン化はコンパイル領域を増やし、多くの最適化にプラスの影響を与えます。 ただし、ベンチマークと特定の最適化によっては、問題のまったく異なる側面が明らかになります。 SPECjbb2005の場合、トレースのインライン化により、正規化テストの効率が特に向上しました。また、定数の畳み込みやデッドコードの削除などの単純な最適化のパフォーマンスをテストするときも向上しました。 ただし、SPECjvm2008には、トレーサーコンパイラがはるかに大きなコンパイル領域に到達することができない、非常に多くの小規模で集中的に使用するテストループが既に含まれています。 したがって、高レベルの最適化が少なくともいくつかの利点を得た可能性は低いです。 DaCapo 9.12 Bachでは、リストされたすべての最適化のパフォーマンスが薄い層で塗りつぶされました。
6.5。 サーバーコンパイラ
HotSpotには、ほとんどの仮想マシンインフラストラクチャを一緒に再利用する2つの異なるJITコンパイラが含まれています。 トレーサーコンパイラは、アプリケーションの最適な開始時間のために作成されたクライアントコンパイラ上に構築され、最も基本的な最適化のみを実装しますが、それでもまともなピークパフォーマンスをもたらします。 サーバーコンパイラ(サーバーコンパイラ)は、長寿命のサーバーアプリケーション向けに設計されており、より多くの最適化を実行するため、非常に効率的なコードが生成されます。 サーバーコンパイラは、配列境界のチェックの削除、ループ不変コードモーション(ループからの引き出し)、ループのアンラッピング、エスケープ分析など、いくつかの追加の最適化を適用できます。 したがって、生成されるコードのピークパフォーマンスは向上しますが、ベンチマークSPECjbb2005、SPECjvm2008、およびDaCapo 9.12 Bachでは6〜31倍(平均13)長くコンパイルされます。 サーバーは主に長寿命のアプリケーションを実行するため、長いコンパイルでは総実行時間に比べてわずかなオーバーヘッドしか発生しません。
貪欲な構成の最高のピークパフォーマンスをHotSpotサーバーコンパイラと比較し、結果を図21に示します。
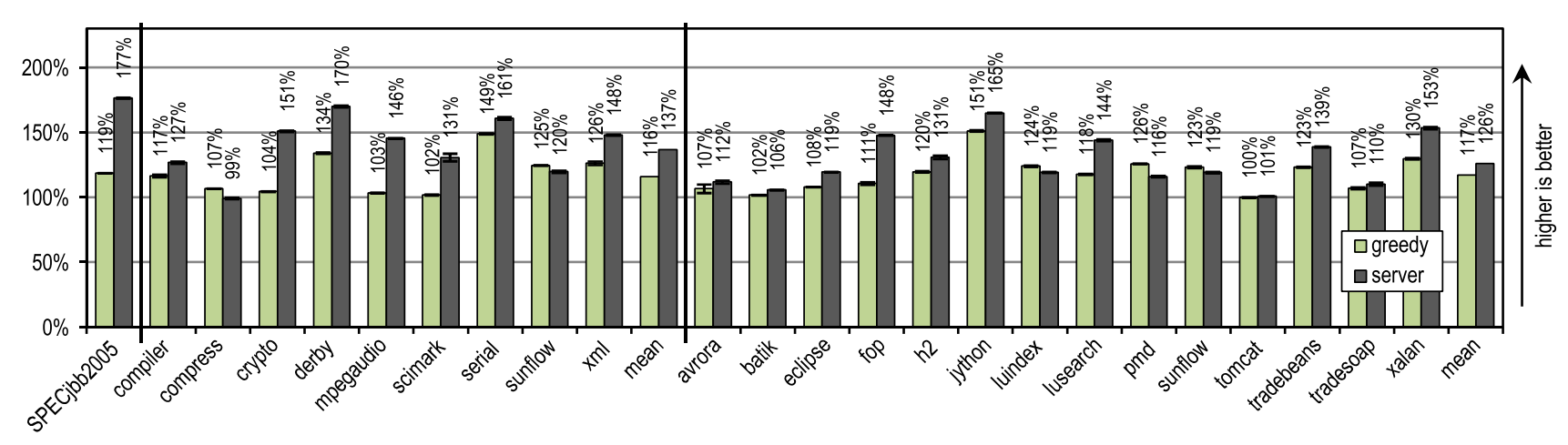 図21. SPECjbb2005、SPECjvm2008、およびDaCapo 9.12 Bachのピークパフォーマンス
図21. SPECjbb2005、SPECjvm2008、およびDaCapo 9.12 BachのピークパフォーマンスSPECjbb2005は、完了するまでに長い時間がかかり、サーバーコンパイラーが生成できる最適化から大きな利点を受け取りました。そのため、トレーサーコンパイラーはパフォーマンスの67%しか達成できません。
SPECjvm2008の貪欲な構成は、サーバーコンパイラのパフォーマンスが平均85%に達しました。 このベンチマークには、暗号化、mpegaudio、scimarkなど、ループを集中的に使用する多くのテキストが含まれています。サーバーコンパイラは、アレイの境界のチェックの削除を使用し、スマートループ最適化を使用するため、著しく高いピークパフォーマンスを示します。 それでも、トレースを積極的にインライン化した結果、トレーサーコンパイラは圧縮およびサンフローベンチマークでサーバーコンパイラを追い越しました。
はるかに少ないループを使用する非常に複雑なテストを含むDaCapo 9.12バッハ[14]で、トレーサーコンパイラは平均93%のサーバーコンパイラパフォーマンスを達成しました。 トレーサーコンパイラは最も基本的な最適化のみを実行したという事実にもかかわらず、luindex、pmd、sunflowテストでのサーバーコンパイラのピークパフォーマンスを超えていました。 これは、積極的で状況依存のインライン化によって可能になります。
6.6。 打ち上げ速度
HotSpotクライアントコンパイラ、サーバーコンパイラ、およびトレーサJITコンパイラの両方-これらはすべて、バックグラウンドでのマルチスレッドコンパイルを考慮して開発されました。 次のシナリオでスタートアップのパフォーマンスをテストしました。
- 最初のシナリオでは、1つのアプリケーションスレッドが実行されていましたが、VMは最大4つのJITコンパイラスレッドを使用していました。 したがって、4コアスタンドでは、最大3コアがJITコンパイル専用に占有されていました。
- 2番目のシナリオでは、4つのアプリケーションスレッドが4つのJITコンパイラスレッドと同時に実行されました。 4コアベンチで、JITコンパイラスレッドはアプリケーションスレッドと競合し始めました。 JITコンパイルは起動速度にプラスの効果があるため、HotSpot VMはJITコンパイラーを使用してスレッドに高い優先度を与えます。
表示されるすべての結果は、単一のJITコンパイルストリームを使用した「クライアント」構成のパフォーマンスによって正規化されます。 SPECjbb2005の起動速度の結果は表示しませんでした。 このベンチマークは、ピークパフォーマンスを測定するように設計されており、わずか30秒後に最初の結果が表示されます。その後、すべての構成がピークパフォーマンスに近づきます。
SPECjvm2008では、テストごとに1つの操作を実行して起動速度を測定しました。 図23は、HotSpotクライアントコンパイラとトレーサコンパイラの両方が、アプリケーションスレッドがコンパイラスレッドと競合するシナリオで良好な結果を達成していることを示しています。 コンパイル時間が重要な場合。
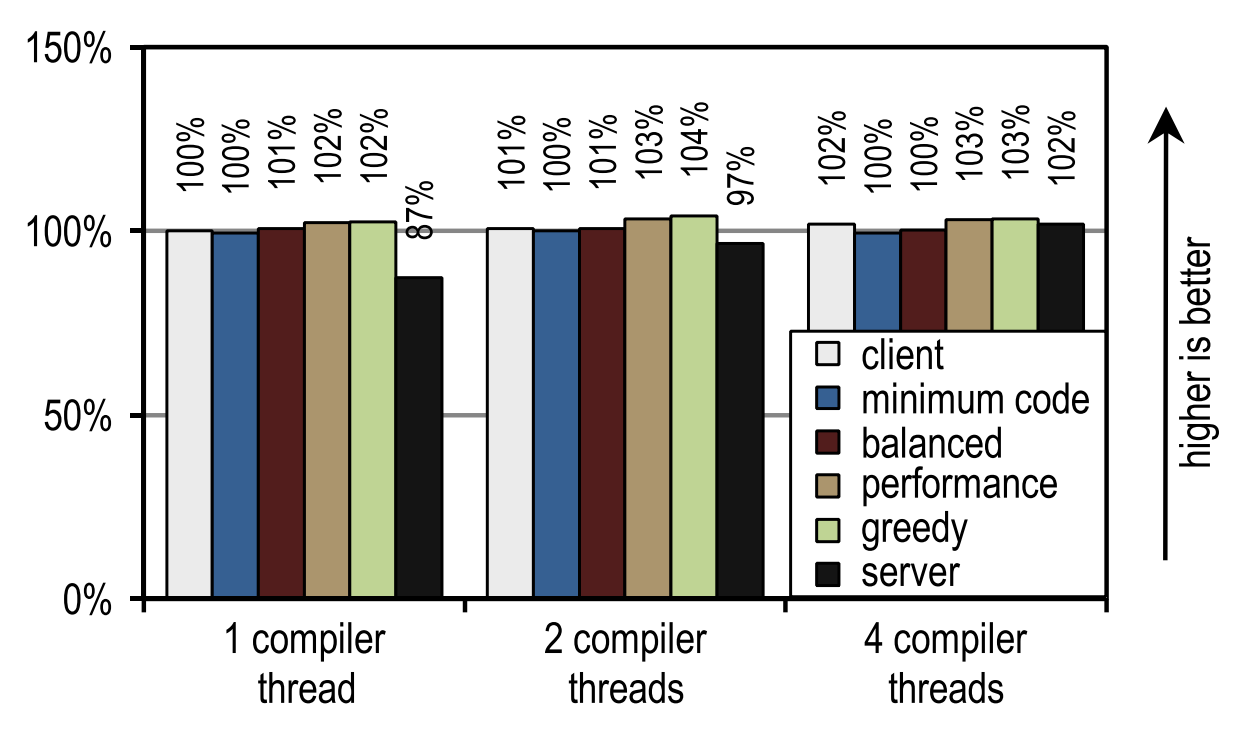 図23. 4つのアプリケーションスレッドでのSPECjvm2008の起動時間
図23. 4つのアプリケーションスレッドでのSPECjvm2008の起動時間図22は、他の方法ではアイドル状態になるカーネルをJITコンパイルに使用できる別のシナリオを示しています。
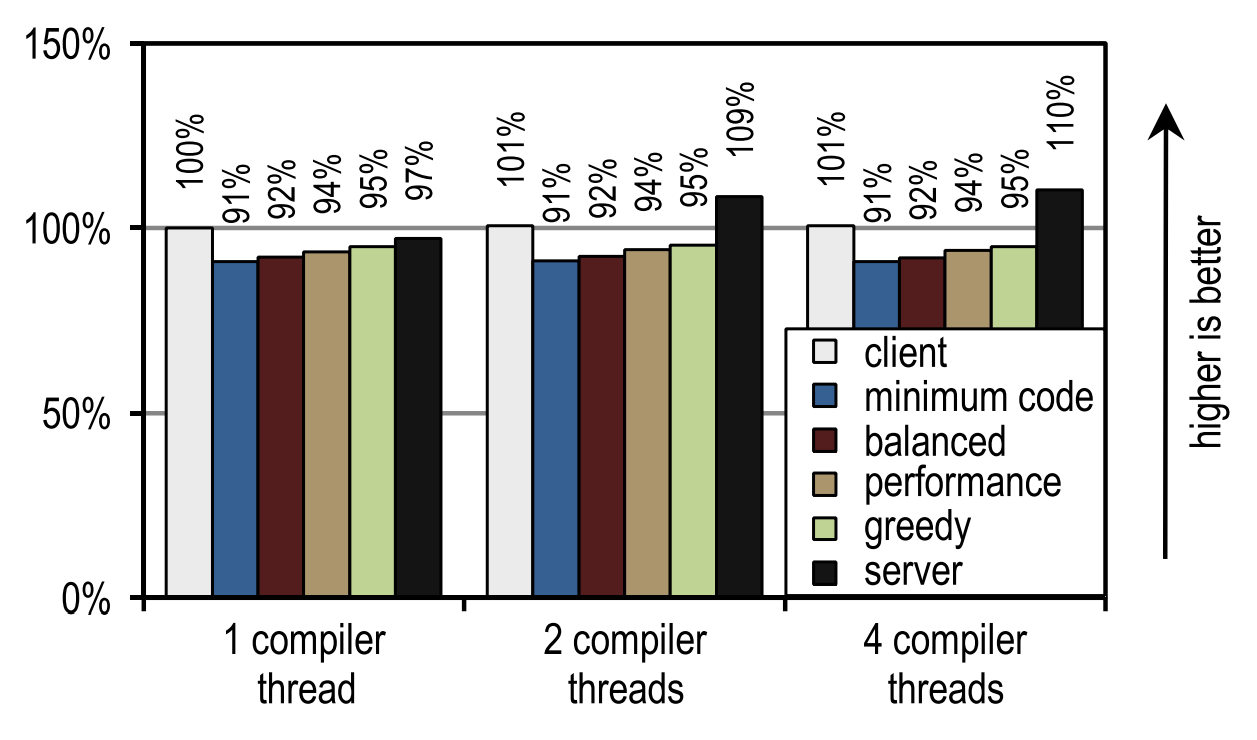 図22. 1つのアプリケーションスレッドでのSPECjvm2008の起動時間
図22. 1つのアプリケーションスレッドでのSPECjvm2008の起動時間この場合、HotSpotサーバーコンパイラーは、最高の起動速度を示します。SPECjvm2008には、コンパイルする必要がほとんどなく、最も深いループをコンパイルした直後にピークパフォーマンスに達するいくつかの小さなテストが含まれているためです。 これは、ループを特に最適化するサーバーコンパイラにとって理想的なケースです。したがって、コンパイル可能なアイドルカーネルがある場合、起動速度に影響するピークパフォーマンスに利点があります。
この画像は、両方のJITコンパイラーが比較的短いコンパイル時間を必要とするため、コンパイラースレッドの数がクライアントコンパイラーまたはトレーサーコンパイラーに影響を与えないことも示しています。 サーバーコンパイラはより多くの時間を必要とするため、複数のコンパイルストリームがある場合、特にこれらの目的に使用できるアイドルカーネルがある場合、強力な利点があります。
DaCapo 9.12 Bachの場合、テストごとに1回の反復を実行して起動速度を測定しました。 テスト結果を図24および25に示します。
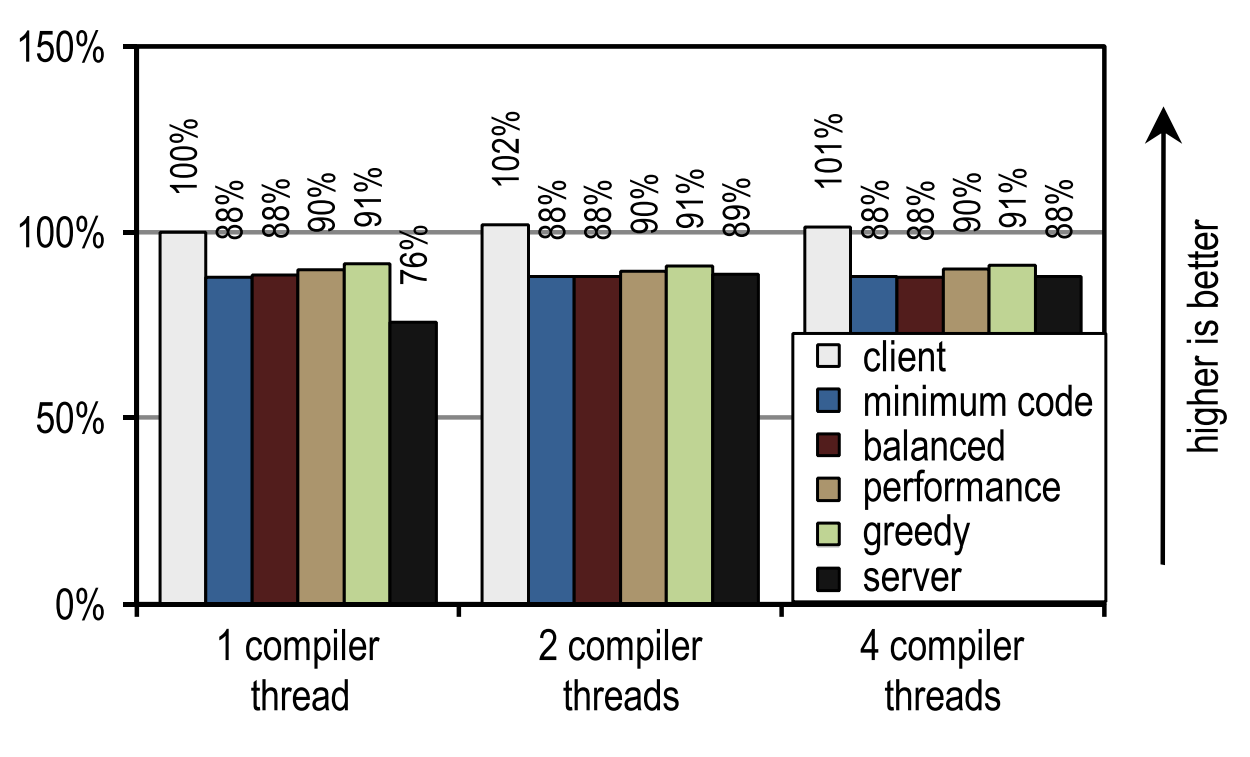 図24. 1つのアプリケーションスレッドでのDaCapo 9.12バッハの起動時間
図24. 1つのアプリケーションスレッドでのDaCapo 9.12バッハの起動時間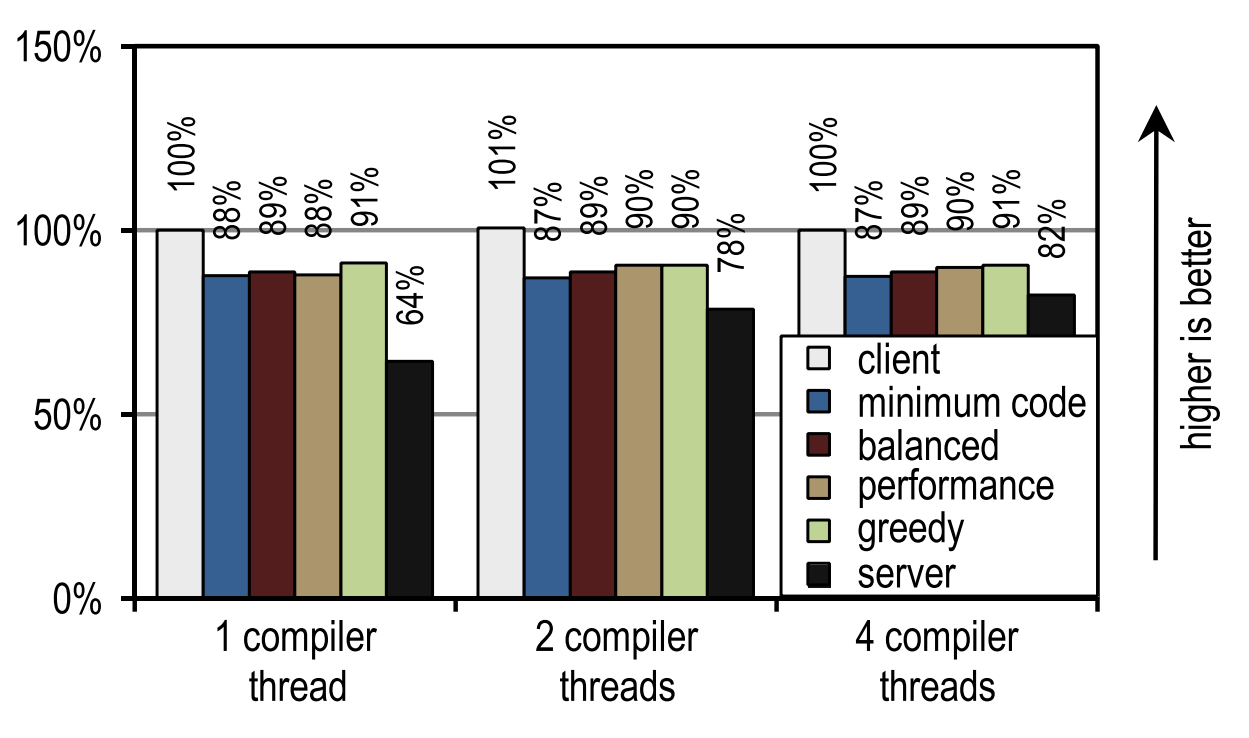 図25. 4つのアプリケーションスレッドでのDaCapo 9.12 Bachの起動時間
図25. 4つのアプリケーションスレッドでのDaCapo 9.12 Bachの起動時間繰り返しますが、コンパイルスレッドの数はクライアントコンパイラまたはトレーサコンパイラのいずれにも影響しません。
対照的に、サーバーコンパイラは、複数のスレッドをJITコンパイルに使用できる場合に活用します。ただし、JITコンパイルにすべてのアイドルカーネルを使用する場合でも、構成のいくつかはサーバーコンパイラよりも常に高速です。これは、DaCapo 9.12 BachがSPECjvm2008 [14]のテストよりもかなり複雑であるため、JITコンパイル速度がアプリケーションの起動速度の主要な要因であるためです。DaCapo 9.12 Bachのテストでは、トレーサー構成はHotSpotクライアントコンパイラよりも起動が約10%遅いことを示しています。通常、トレースコンパイラはHotSpotクライアントコンパイラよりもJITコンパイルに必要な時間が短いという事実にもかかわらず、この場合、起動時に通常発生するトレースと非最適化の記録に追加のオーバーヘッドが発生するため、起動速度が低下します。ただし、ピークパフォーマンスが大幅に向上することで、この欠点が補われます。HotSpotクライアントコンパイラとは異なり、トレーサーコンパイラは、良好な起動速度を実現するためにアイドルカーネルを必要としません。7.関連作品
Bala et al。[1]は、ネイティブ命令フローを最適化するために、Dynamoシステムのトレーサーコンパイルを実装しました。ホット命令シーケンスは、インタプリタの下でバイナリアプリケーションを実行することで識別されます。次に、これらのトレースがコンパイルされ、それらによって生成されたマシンコードが直接実行されます。解釈によるオーバーヘッドは、コンパイルされたトレースの数の増加とともに減少し、遅かれ早かれ加速につながります。それらとは対照的に、バイトコードで適切なトレースアンカーを識別し、クラスロード中に静的分析を使用します。個々のトレースを1つのメソッドの深さに制限し、記録されたトレースをリンクして、メソッドの境界を越えるときに状況依存情報を保存します。これにより、コンパイル時までインライン化の必要性に関する決定を延期できます。録音中に直接行う代わりに。Rogers [22]は、頻繁に実行されるベースブロックにマークを付けてコンパイルするJava用のこのようなJITコンパイラを実装しました。複数のメソッドに拡張できる関連ブロックが非常に頻繁に実行される場合、それらは1つのエンティティとしてグループ化および最適化されます。ブロックコンパイルと比較して、コンパイルされるバイトコードは少なく、最大18%です。私たちのシステムはトレースを記録およびコンパイルし、トレースの状況依存インライン化を使用してピークパフォーマンスを向上させながら、非常に控えめな量のマシンコードを生成します。次のアプローチは、Javaの多くのトレースコンパイルオプションで実装されています[2,11,12,18]。ただし、これらすべてのアプローチには共通点があります。トレースはいくつかの方法に拡張できるため、トレースの記録中にインライン化を行う必要があります。対照的に、1つの方法がトレースをキャプチャするための最大可能領域であり、リンクがトレース間の情報を保存するために使用されると仮定します。これにより、インライン化の必要性に関する決定をコンパイル時まで、つまりより多くの有用な情報が利用可能になるまで延期できます。したがって、インライン化は読みやすく、単純なヒューリスティックを使用して、ピークパフォーマンスを向上させ、生成されるマシンコードを減らします。Gal et al。[11,12]は、リソースが限られているハードウェアにトレーサーコンパイラを実装しました。トレースは、逆ブランチの頻繁に実行されるターゲット、および既存のトレースのサイド出口で実行されます。トレースはいくつかの方法に拡張できるため、記録中にインライン化が発生します。トレースを記録した後、それはマシンコードにコンパイルされ、他のコンパイルされたトレースにリンクされ、ツリーのような構造を形成します。コンパイルされたトレースのこの単純な構造は、多くの最適化を簡素化しますが、過剰なテール複製と肥大化コードにつながる可能性があります。 AndroidのDalvik VM [4.6]でも同様のアプローチが使用されています。対照的に、コンパイルする前に、個々のトレースをトレースグラフにマージして、不必要な重複を回避します。Bebenita et al。[2]は、Maxine VMのトレーサコンパイルを実装しました。 Maxineは、初期実行にインタープリターではなく基本的なJITコンパイラーを使用します。この基本的なJITコンパイラは、トレースの記録に使用されるインストルメンテーションを生成するように変更されています。 JITコンパイルの開始前でも、記録されたトレースは「トレースの領域」にマージされ、マージポイントに明示的な制御フローがあります。これにより、過剰なテールの重複が回避されます。あらゆる種類のループ最適化の結果として、JITコンパイラーは、ループを頻繁に使用するテストで優れた加速を実現します。ただし、ループの使用頻度が低いテストでメソッドをコンパイルすると、動作が非常に悪くなります。 DaCapo 9などのループをほとんど使用しない複雑なアプリケーションに焦点を当てているため、私たちの作業は彼らのアプローチを補完するものです。12バッハ・ジソン。トレーサーコンパイラーでは、これらのアプリケーションで優れた加速を達成しましたが、同時に、コンパイラーはまだスマートループ最適化を実行していないため、ループを含むすべてのテストで加速はほとんどありませんでした。井上ら[18]は、トレーサJITコンパイラをIBM J9 / TR JVMに追加し、ブロックJITコンパイラを修正しました。外部のマージポイントなしで線形および循環トレースを記録し、最適化されたマシンコードにコンパイルします。ピークパフォーマンスに関しては、トレーサーコンパイラは、同様に最適化されたブロックJITコンパイラのパフォーマンスを達成します。 Wu et al。[28]は、短命のトレースとそれらの不必要な重複を避けて、この作業を拡張しました。これはピークパフォーマンスに影響しませんが、生成されるマシンコードの量とコンパイル時間の両方を削減します。また、既存の工業品質のJVMに基づいて作業を行っていますが、個々のトレースを1つの方法の深さに制限しています。したがって、インライン化の決定をコンパイル時まで延期できます。ピークパフォーマンスが向上します。BradelとAbdelrahman [5]は、Jikes RVMのインラインメソッドにトレースを使用しました。トラックは、フィードバックを考慮してオフラインシステムを使用して記録されます。次に、頻繁に実行されるコールポイントがすでに記録されているトレースで識別され、この情報がメソッドのインライン化に使用されます。 SPECjvm98およびJava Grandeベンチマークでテストした結果、パフォーマンスが10%向上しただけでなく、生成されたマシンコードの量も47%増加しました。システムはインタープリターでの実行中にトレースを記録し、その後、トレースが通過したメソッドの部分のみをコンパイルしてインライン化します。これにより、ピークパフォーマンスが向上し、生成されるマシンコードの量を減らすことができます。Hazelwood and Grove [16]は、ブロックコンパイラで状況依存のインライン化を実装しました。呼び出し情報のタイマーサンプリングと記録は、コンパイル時にインライン化を決定するために使用されます。生成されたコードの量とコンパイル時間は、パフォーマンスを変更せずに10%減少しました。このシステムでは、記録されたトレースにさらに詳細な状況依存情報が含まれています。インラインヒューリスティックに応じて、これによりピークパフォーマンスが向上するか、生成されるマシンコードの量が減少します。メソッドのインライン化はよく研究されている問題であり、関連する文献でよく検討されています。したがって、残りの作業はメソッドのセクション全体をインライン化するのではなく、メソッドの個々のセクションのインライン化手法に集中しており、これは私たちの作業に近いものです。ただし、これらの方法は、トレースのコンパイルを補完するものです。メソッドの一部は明示的に除外されており、わが国では生成されたマシンコードの量はトレースレコードを使用して達成されます。メソッドの部分コンパイル[9、26]は、プロファイル情報を使用して、メソッドのめったに実行されない部分を検出し、それらをコンパイルから破棄します。これにより、コンパイル時間が短縮され、起動速度が向上します。また、ピークパフォーマンスに良い影響を与える可能性があります。私たちのアプローチはさらに選択的です、なぜなら頻繁に実行されるトレースのみを記録およびコンパイルします。さらに、コンパイル時に保存されたリソースを使用して、より積極的で状況依存のインライン化を提供し、ピークパフォーマンスを向上させます。Suganuma et al。[25]は、領域を使用したコンパイルを実装しました。この場合、メソッドのほとんど実行されない部分は、ヒューリスティックおよびプロファイル情報を使用してコンパイルから除外されます。次に、重いインライン化メソッドを使用して、多くの場合、実行されたコードが1つのコンパイル単位にグループ化されます。これにより、ベンチマークSPECjvm98およびSPECjbb2000でコンパイル時間が20%以上短縮され、ピークパフォーマンスが平均で5%向上します。トレースが通過するメソッドの頻繁に実行される部分のみをコンパイルし、生産性を高めるためにこれらのトレースのインライン化を使用します。8.結論
この記事では、トレースを記録するときに通常どおりに行うのではなく、JITコンパイル中にインレイするJavaトレーサーコンパイラを紹介しました。ここのトレースは、メソッドの実際に実行可能な部分のみをキャプチャするため、より適しています。インライン化の決定をJITコンパイルの瞬間まで延期すると、トレースのより選択的なインライン化が可能になります。その瞬間により多くの情報が利用できるからです。さらに、記録されたトレースはすべてコンテキスト依存であるため、呼び出しの特定の場所に基づいてメソッドのさまざまな部分をインライン化します。これにより、適度な量のマシンコードを生成しながら、トレースをより積極的にインライン化できます。さらに、コンパイルする前にめったに実行されないトレースを削除することをお勧めします。最も頻繁に実行されるトレースのみがマシンコードに変わります。ベンチマークSPECjbb2005、SPECjvm2008、およびDaCapo 9.12 Bachでのテストにより、正しくインライン化するトレースは、インラインメソッドよりも少ないマシンコードを生成しながら、ピークパフォーマンスを向上できることが示されました。さらに、トレースをインライン化するとコンパイル領域が拡大し、メインコンパイラの最適化の効率が向上し、最終的にピークパフォーマンスが向上することも示しました。謝辞
この作品を作成するにあたり、著者はオーストリア科学基金(FWF)を支援しました:プロジェクト番号P 22493-N18。 OracleおよびJavaは、Oracleおよび/またはその関連会社の登録商標です。他のすべての名前も、それぞれの所有者の登録商標です。この翻訳は、JUG.RUチームが主催するJokerやJPointなどの会議に参加することで得られる感情的な向上なしには実現できなかったでしょう。ある日、会議から家に帰ると、何かを書かなければならないことに気づきます。参照資料
- Bala V, Duesterwald E, Banerjia S. Dynamo: a transparent dynamic optimization system. In: Proceedings of the ACM SIGPLAN conference on programming language design and implementation. ACM Press; 2000. p. 1–12.
- Bebenita M, Chang M, Wagner G, Gal A, Wimmer C, Franz M. Trace-based compilation in execution environments without interpreters. In: Proceedings of the international conference on the principles and practice of programming in Java. ACM Press; 2010. p. 59–68.
- Blackburn SM, Garner R, Hoffman C, Khan AM, McKinley KS, Bentzur R, et al. The DaCapo benchmarks: Java benchmarking development and analysis. In: Proceedings of the ACM SIGPLAN conference on object-oriented programming systems, languages, and applications. ACM Press; 2006. p. 169–90.
- Bornstein D. Dalvik VM Internals. Presented at the Google I/O developer conference, 2008. 〈http://sites.google.com/site/io/dalvik-vm-internals〉.
- Bradel BJ, Abdelrahman TS. The use of traces for inlining in Java programs. In: Proceedings of the international workshop on languages and compilers for parallel computing, 2004. p. 179–93.
- Cheng B, Buzbee B. A JIT compiler for Android's Dalvik VM. Presented at the Google I/O developer conference, 2010. 〈http://www.google.com/events/ io/2010/sessions/jit-compiler-androids-dalvik-vm.html〉.
- Cytron R, Ferrante J, Rosen BK, Wegman MN, Zadeck FK. Efficiently computing static single assignment form and the control dependence graph. ACM Transactions on Programming Languages and Systems 1991;13(4):451–90.
- Dean J, Grove D, Chambers C. Optimization of object-oriented programs using static class hierarchy analysis. In: Proceedings of the European conference on object-oriented programming. Springer-Verlag; 1995. p. 77–101.
- Fink S, Qian F. Design, implementation and evaluation of adaptive recompilation with on-stack replacement. In: Proceedings of the international symposium on code generation and optimization. IEEE Computer Society; 2003. p. 241–52.
- Gal A, Eich B, Shaver M, Anderson D, Mandelin D, Haghighat MR, et al. Trace-based just-in-time type specialization for dynamic languages. In: Proceedings of the ACM SIGPLAN conference on programming language design and implementation. ACM Press; 2009. p. 465–78
- Gal A, Franz M. Incremental dynamic code generation with trace trees. Technical Report. Irvine, USA: Donald Bren School of Information and Computer Science, University of California; 2006
- Gal A, Probst CW, Franz M. HotpathVM: an effective JIT compiler for resource-constrained devices. In: Proceedings of the international conference on virtual execution environments. ACM Press; 2006. p. 144–53.
- R. Griesemer, Generation of virtual machine code at startup. In: OOPSLA workshop on simplicity, performance, and portability in virtual machine design. Sun Microsystems, Inc.; 1999
- Häubl C, Mössenböck H. Trace-based compilation for the Java HotSpot virtual machine. In: Proceedings of the international conference on the principles and practice of programming in Java. ACM Press; 2011. p. 129–38.
- Häubl C, Wimmer C, Mössenböck H. Evaluation of trace inlining heuristics for Java. In: Proceedings of the ACM symposium on applied computing. ACM Press; 2012. p. 1871–6.
- Hazelwood K, Grove D. Adaptive online context-sensitive inlining. In: Proceedings of the international symposium on code generation and optimization. IEEE Computer Society; 2003. p. 253–64.
- Hölzle U, Chambers C, Ungar D. Debugging optimized code with dynamic deoptimization. In: Proceedings of the ACM SIGPLAN conference on programming language design and implementation. ACM Press; 1992. p. 32–43
- Inoue H, Hayashizaki H, Wu P, Nakatani T. A trace-based Java JIT compiler retrofitted from a method-based compiler. In: Proceedings of the international symposium on code generation and optimization. IEEE Computer Society; 2011. p. 246–56
- Kotzmann T, Wimmer C, Mössenböck H, Rodriguez T, Russell K, Cox D. Design of the Java HotSpot client compiler for Java 6. ACM Transactions on Architecture and Code Optimization 2008;5(1):7.
- Oracle corporation. Java platform, standard edition 8 developer preview releases; 2011 〈http://jdk8.java.net/download.html〉
- Paleczny M, Vick C, Click C. The Java HotSpot server compiler. In: Proceedings of the Java virtual machine research and technology symposium. USENIX, 2001. p. 1–12.
- Rogers I. Optimising Java programs through basic block dynamic compilation. PhD thesis. Department of Computer Science, University of Manchester; 2002年。
- Standard Performance Evaluation Corporation. The SPECjbb2005 Benchmark; 2005 〈http://www.spec.org/jbb2005/〉.
- Standard Performance Evaluation Corporation. The SPECjvm2008 benchmarks; 2008 〈http://www.spec.org/jvm2008/〉.
- Suganuma T, Yasue T, Nakatani T. A region-based compilation technique for dynamic compilers. ACM Transactions on Programming Languages and Systems 2006;28:134–74.
- Whaley J. Partial method compilation using dynamic profile information. SIGPLAN Notices 2001;36:166–79
- Wimmer C, Mössenböck H. Optimized interval splitting in a linear scan register allocator. In: Proceedings of the ACM/USENIX international conference on virtual execution environments. ACM Press; 2005. p. 132–41.
- Wu P, Hayashizaki H, Inoue H, Nakatani T. Reducing trace selection footprint for large-scale java applications without performance loss. In: Proceedings of the ACM international conference on object oriented programming systems languages and applications. ACM Press; 2011. p. 789–804.
著者
ChristianHäublは、オーストリアのリンツにあるJohannes Kepler大学の博士課程の学生で、トレーサーJavaコンパイラーに取り組んでいます。彼は、両方ともヨハネスケプラー大学リンツでコンピューターサイエンスとネットワークおよびセキュリティの学位を取得しています。彼はコンパイルと仮想マシンに関連する分野に興味がありますが、セキュリティとWebアプリケーションに切り替えることがあります。クリスチャン・ウィマー-Oracle Labsの研究者は、MaxineVM、Graalコンパイラ、および動的コンパイルと最適化に関連する他のプロジェクトに従事しました。彼の研究対象は、コンパイラ、仮想マシン、コンポーネントソフトウェアアーキテクチャ用のセキュアシステムに関連しています。彼はリンツのヨハネスケプラー大学でコンピューターサイエンス(監督:ハンスペッターメッセンベック教授)から博士号を取得しました。 Oracleに入社する前は、カリフォルニア大学のコンピューターサイエンス学部で博士課程の学生でした。彼は、Secure Systems and Software LaboratoryのMichael Franz教授と、コンパイラの最適化、動的プログラミング言語、および言語セキュリティについて働いていました。ハンスペッター・メッセンベック-リンツ・ヨハネス・ケプラー大学のコンピューター・サイエンス教授、クリスチャン・ドップラー自動ソフトウェア工学研究所所長。1987年にリンツ大学で博士号を取得し、1988年から1994年までETHチューリッヒで助教授を務め、ニクラウスワース教授とオベロンシステムについて研究しました。現在の研究対象は、プログラミング言語とコンパイラ、オブジェクト指向プログラミングとコンポーネントプログラミングです。彼は、プログラミング教育に関するいくつかの本の著者です。翻訳者
Oleg Chirukhin-このテキストを書いている時点では、Sberbank-Technologyでアーキテクトとして働いており、自動化されたビジネスプロセス管理システムのアーキテクチャの開発に従事しています。Sberbank Technologiesに入社する前は、政府サービスや電子医療記録を含むいくつかの政府情報システムの開発、およびオンラインゲームの開発に参加していました。現在の研究対象には、仮想マシン、コンパイラ、プログラミング言語が含まれます。