
私たちが愛する映画で言ったように、「飛んで、急いで、絵を買って」。 後者はもちろん、それとは何の関係もありませんが、コンパイラの新しいベータ版に「飛び込む」ときです。 今日は、
Intel Parallel Studio XE 2018 Betaパッケージ、特にコンパイラコンポーネントの新機能について説明します。
C ++、C ++、Fortran 2008、2015、OpenMP 4.5、5.0 、およびコンパイラはそれらをサポートするだけでなく、完璧で効率的で安全なものを生成する必要がありますコード。 さらに、最新の
Skylakeおよび
KNLプロセッサーを ざっと見られるようにする新しい
AVX512命令
セットは、現代のコンパイラーの武器の一部になりつつあります。 しかし、最良の部分は新しいキーです。これにより、負担をかけずにパフォーマンスをさらに向上させることができます。 さあ、行こう!
ここで
ベータ版をダウンロードできることをすぐに言わなければなりません:
Intel Parallel Studio XE 2018ベータ前調査私がお話しすることはすべて、このバージョンのコンパイラと
Update 1に含まれており、近日中に公開されます。 後に最終製品に含まれることになるのは難しい質問ですが、「王」、ほとんどすべてです。 新しいバージョン
18.0ベータ版には何がありますか?
コードセキュリティ
マイクロソフトは、ハッカーに対抗し、ますます多くの新しいテクノロジーを考案することに苦労しています。 まず、C ++コンパイラでは、
/ GS:strongオプションを使用してスタック保護の最大レベルをデフォルトに設定しました。これにより、バッファオーバーフローに対処できます。 これはパフォーマンスを低下させるために行われますが、安全性が最も重要です。 WindowsのIntelはMicrosoftコンパイラと完全な互換性を保とうとしているため、新しいバージョンからは、デフォルトで
/ GS:strongも含めています。
/ GS:partialを使用すると、その効果を制限し、パフォーマンスをわずかに改善できます。
さらに、新しい
CET (Control-Flow Enforcement Technology)テクノロジーが開発されています。これにより、リターン指向プログラミングの方法(
ROPおよび
JOP攻撃)を使用した攻撃に対処できます。 保護のアイデアの1つは、別の保護された
シャドウスタックが表示され、リターンアドレスが書き込まれる/複製されることです。 関数から戻ると、プロシージャによって返されたアドレスと
シャドウスタックに入れたアドレスの正確性をチェックします。 さらに、新しい
ENDBRANCH命令が
追加され、
call / jmpを介した間接的な移行が可能なプログラム内の領域を示します。
ステートマシンが実装され、プロセッサが
call / jmp命令の1つを処理するとすぐに、
IDLE状態から
WAIT_FOR_ENDBRANCHに切り替わります。 実際、この状態では、次に実行する命令は
ENDBRANCHでなければなりません。 より多くの詳細は上記の記事に記載されており、C / C ++およびFortran用のインテル®コンパイラーは、
-cf-protectionオプションによりCETをサポートしています。 デフォルトでは有効になっていないため、使用するとパフォーマンスに影響する可能性があります。
誰が新しい防御をテストする準備ができていますか? 重要な点は、CETを完全に動作させるにはOSとRTLのサポートが必要ですが、まだ利用可能ではないということです。
性能
次に、アプリケーションをさらに高速かつ生産的にする新しいコンパイラオプションについて説明します。
関数分割と呼ばれるコンパイラの最適化があります。 なぜそれが必要なのかを理解するために、コードを埋め込むことと、効果の1つがそのサイズを大きくすることであるという事実を覚えておく価値があります。 したがって、関数自体のサイズが大きい場合、呼び出しの場所に埋め込みたい場合、
インライン化は意味がありません。 これらの場合、関数の分割と部分的な
インライン化により、コードのサイズが過度に増加することを防ぎ、その利点を維持できます。 その結果、関数は2つの部分に分割され、一方(
hot )が組み込まれ、もう一方(
cold )が組み込まれません。
実際、
Profile-Guided Optimization (
PGO )を使用する場合、この最適化はIntelの32ビットWindowsコンパイラーに長く存在していました。 ちなみに、
gccでのこの最適化に関する興味深い
投稿があります。 アイデアは簡単です-インストルメンテーションを実行してアプリケーションをコンパイルし、それを実行して実行方法に関するデータを収集し(プロファイル)、ランタイムからこのデータを考慮してコードを再構築し、取得した知識を適用してより強力な最適化を行います。
PGOで
関数分割を使用できる理由が明らかになりました。各関数について、実行されている量とインライン化が必要なものがわかっているためです。
開発者が
-ffnsplit [= n] (Linux)または
-Qfnsplit [= n] (Windows)
スイッチを追加して、この最適化を「
手動 」で制御できるようになりました。これにより、コンパイラーはブロック実行確率
nの関数パーティションを実行します少ない。
PGOが有効かどうかは関係ありませんが、このパラメーター
nを指定する必要があります。 指定しない場合、この最適化は
PGOからの動的情報がある場合にのみ実行されます。
nの値は
0〜100の範囲で指定できますが、最も興味深いのは前半です。 たとえば、
PGOと32ビットWindowsコンパイラでは、値
5が使用されました。つまり、実行確率が
5%未満の場合、このブロックはインラインになりません。
PGOについて話している場合は、Studioの新しいバージョンでは快適な変更が行われたと断言できます。 以前は、この最適化はインスツルメンテーションでのみ機能していましたが、
VTuneプロファイラーからのサンプリングを使用して機能するようになりました。 データとコードのサイズに制限があり、インストルメンテーションがそれを大幅に増加させる可能性がある
リアルタイムおよび
組み込みシステムで従来の
PGOを使用することは不可能であるため、このような機能の実装が促されました。 さらに、このようなシステムでは、
I / O操作を実行することはできません。
VTuneからのハードウェアサンプリングにより、アプリケーションの実行のオーバーヘッドを大幅に削減できますが、メモリ使用量は増加しません。 この方法は統計データを提供します(計測中に正確です)が、従来の
PGOが 「停止」するシステムに適用できます。
新しいPGOモードでの作業スキームは、ダイアグラムの形式で表すことができます。
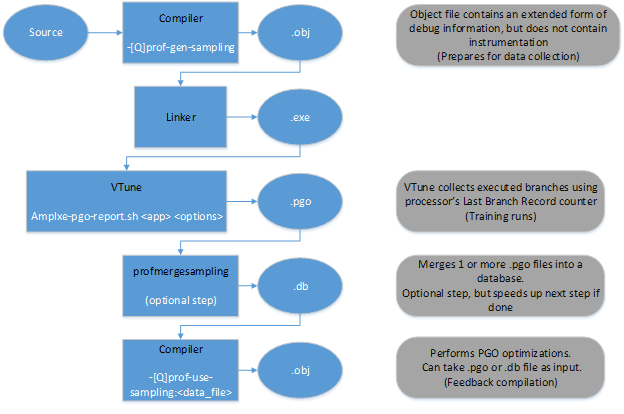
前と同様に、後続の統計収集のためにコードをコンパイルする必要があります。 これは、
-prof-gen-sampling (Linux)または
/ Qprof-gen-samplig (Windows)オプションを使用して行われるようになりました。
出力では、拡張デバッグ情報(サイズが
5〜10%増加します)を備えたバイナリが取得されますが、インストルメンテーションはありません。 そして、アプリケーションを起動してプロファイルを生成する
VTuneからの特別なスクリプトが必要です。 その後(複数のプロファイルをマージする必要がない場合)、
-prof-use-sampling (Linux)または
/ Qprof-use-samplingキー(Windows)を
使用して、受け取ったデータでコードを再コンパイルします。 これらのオプションを使用するには、VTuneが必要です。そのため、コンパイラーだけでなく、プロファイラーもインストールする必要があります。 ベータパッケージには両方があります。
次に、スカラー数学関数のベクトル類似物を提供する
SVML(Short Vector Math Library)ライブラリの数学関数の操作について説明します。
新しいバージョンのリリースに伴い、
SVMLにすぐにいくつかの変更が加えられました。 動的ディスパッチ中のオーバーヘッドを除去するために、コンパイル段階で、指定された
-xスイッチの値を使用して必要な関数の直接呼び出しが生成されます。 その前に、使用しているプロセッサを実行時にチェックし、必要なバージョンの関数を呼び出しました。 また、
オーバーヘッドは 、数学関数(指数など)を集中的に使用する通常の関数では大きく
ありませんが、
10%に達する可能性があります。 これは、アプリケーションの財務セグメントでの計算で特に要求されます。
それでも、「古い」コンパイラの動作を返す必要がある場合は、
-fimf-force-dynamic-target (Linux)または
/ Qimf-force-dynamic-target (Windows)オプションが役立ちます。
別の変化は同じ金融分野から来ました。 数学を扱う場合、パフォーマンスだけでなく、結果の再現性も重要です。 この
-fp-model (Linux)および
/ fp (Windows)を処理するための素晴らしいオプションについてはすでに
書いています。 そのため、浮動小数点数を扱うモデルを
正確に設定する(
-fp-model precise (Linux)または
/ fp:precise (Windows))ので、パフォーマンスに悪影響を与える
SVMLからベクトル数学関数を使用する
必要がなくなりました、しかし結果の再現性に非常に肯定的です。 現在、開発者は、パフォーマンスが数値結果の安定性に影響しないことを確認しています。
-fimf-use-svml (Linux)または
/ Qimf-use-svml (Windows)
スイッチを使用すると、標準の
LIBMライブラリーから呼び出す代わりに
SVMLからスカラー関数を使用するようコンパイラーに指示できます。 また、
SVMLのスカラーバージョンとベクトルバージョンが同じ結果を提供することを確認したため、
正確なモデルを使用するときに、ベクトル数学関数を使用できます。
さまざまなバッファを使用する場合、
memcpy 、
memsetなど、多数の関数が使用されます。 呼び出しがある場合、コンパイラーは内部ロジックを使用して、さまざまな方法で実行できます。適切なライブラリー関数の呼び出し、
rep命令の生成、またはループ時の操作の展開(コンパイル時のサイズがわかっている場合)。 そのため、彼は常に適切なアプローチを正しく推測するとは限らないため、オプション
-mstringop-strategy (Linux)または/
Qstringop-strategy (Windows)があり、これらを使用して、バッファ/文字列を処理するそのような関数の処理をコンパイラに指示できます(
文字列 、したがってキーの名前)。
libcall 、
rep、または
const_size_loopをオプションの引数としてそれぞれ指定できます。 たとえば、
-Osスイッチを使用してコンパイルする場合(バイナリのサイズが
重要です )、
-mstringop-strategy = repオプションが暗黙的に使用されます。
AVX-512をサポートするシステムのより生産的なコードについては、オプション
-opt-assume-safe-padding (Linux)または
/ Qopt-assume-safe-padding (Windows)が登場しました。
これにより、コンパイラは、アプリケーションによって割り当てられた各配列または変数の後に
64バイトに安全にアクセスできると想定できます。 以前は、このオプションは
KNCで使用可能でしたが、
AVX-512をサポートする最新のアーキテクチャで使用できるようになりました。 場合によっては、このような「リバティ」により、コンパイラーはマスクされたロード操作の代わりにマスクされていないロード操作を生成できるようになります。 ただし、データを
64バイトで整列させることが重要です。
おわりに
これらはおそらく、コンパイラの最新バージョンに登場した新しい「マジック」オプションの中で最も重要なものです。 しかし、これに加えて、
OpenMP 4.5標準のほぼ全体(
ユーザー定義の削減だけではありません)、および
OpenMP 5.0の新世代の一部(
タスクの
削減など )のサポートが追加されました。
C ++ 11および
C ++ 14標準は 、バージョン
17.0から完全にサポートされ
ていますが、
Fortran 2008の完全なサポートは現在のみ登場しています。 はい。最新の
C ++ 17標準はより大規模なボリュームでサポートされます。これは、まだ最終的に採用されていないことを考慮しています。
結論としては、次のバージョンのコンパイラがあり、コードを最適化してコードのパフォーマンスとセキュリティを向上させる機会をさらに増やし、最新の標準を幅広くサポートしています。 アイダテスト?