
Avitoリポジトリ、写真、メディアスピーカーについては既に説明しましたが、主な質問は未解決のままでした。プラットフォームとは何か、プラットフォームのアーキテクチャ、コンポーネントの構成、使用するスタックです。 あなたは、Avitoのハードウェアコンポーネント、使用されている仮想化システム、ストレージなどについて話すように頼みました。
ハードウェア
長い間、当社のサーバーはスウェーデンのBasefarmデータセンターにありましたが、昨年1月から2月にかけて、モスクワのDataspaceデータセンターに移動するという大規模なタスクに対処しました。 興味深い場合は、別の記事で移行について説明します(データベースの移行については、既に
Highload 2016で話しました )。
この移動はいくつかの理由により引き起こされました。 第一に、ロシア連邦市民の個人データの保管に関するセンセーショナルな法律第242-。 第二に、ハードウェアをより詳細に制御できるようになりました。スウェーデンのデータセンターのアジャイルワーカーが常に数日間簡単な注文を実行できるとは限りませんでした。 ここでは、スタッフがすべてを迅速に行います。いずれにしても、私たちはいつでも個人的にDCに来て、発生した問題の解決に参加することができます。
サーバー
サーバーはいくつかの機能グループに分けられ、各グループには独自の鉄の構成があります。 たとえば、PHPバックエンドのサーバーは、イメージストレージの第1レベルの役割も果たします(以下のイメージの詳細)。これらのサーバーには、少しのRAM、小さなディスク、強力なプロセッサがあります。 それどころか、Redisクラスターのサーバーには大量のRAMがあり、プロセッサーはそれほど強力ではありません。 このような特定の構成により、多くのサーバーがユニバーサル構成であり、一部のリソースが常に使用されなかった以前と比較して、サーバーのコストを大幅に削減できました。
ネットワーク
ネットワークは、コアとアクセスレベルという古典的な2レベルのスキームに従って構築されています。 フォールトトレランスのために、各アクセスレベルスイッチは2つの異なるルートスイッチに光学的に接続されています。 LACPリンクはこれらの2つのリンクの上に作成されます(複数の物理リンクの上に1つの仮想リンクを使用すると、すべての物理リンクを完全に利用でき、物理リンクの障害に対する抵抗力が追加されます)。
ソフトウェア部
仮想化
ハードウェアの仮想化は使用しませんが、オペレーティングシステムレベル(別名コンテナー)での仮想化は非常に均一です。 これは主にLXCです(OpenVZがずっと前に使用されていた)が、今ではDocker(Kubernetesを使用)に興味を持ち、ゆっくりと移行しており、Kubernetesクラスターで新しいマイクロサービスをすぐに開始しています。
プロファイルmitapおよびCodefest 2017でKubernetesを使用する方法について説明しました。
画像保存
イメージリポジトリの履歴について
は、記事で詳しく説明
しています 。 現在、2レベルの構造になっています:最初のレベルは小さな画像(検索結果で使用されるため、多くの場合、要求されます;最大640x640までの解像度)と大きな画像のキャッシュ、第2レベル-アナウンスカードからのみ利用可能な大きな画像です。 外部から第2レベルのサーバーへの直接アクセスはなく、すべてが第1レベルを通過します(したがって、キャッシュに落ち着きます)。 プロファイルが異なるため、異なるレベルでの負荷、各レベルの構成とサーバーの数も異なります。最初のレベルでは小さなディスクを持つサーバーが多数あり、2番目のレベルでは大きなディスクを持つサーバーが数個(5倍以下)です。
必要なすべてのイメージ許可は、ロード時にバックエンドで生成されます。 いくつかの人気のないサイズの画像はサーバーに保存されませんが、その場でnginxによって生成されます。 ウォーターマークの場合も同様です:ほとんどのアクセス許可では、バックエンドにすぐに適用されますが、ウォーターマークのないパートナー(およびウォーターマークのあるサイト)には一部のアクセス許可が付与されるため、オンザフライでnginxと重ね合わせられます。

詳細を確認すると、第1レベルと第2レベルの100の仮想画像ノードがあり、対応するレベルの物理サーバーに均等に分散しています。 仮想ノードの物理ノードへのバインドは、DNSのCNAMEレコードを使用して規制され、最初のレベルの場合はサーバー上の外部IPを使用します。
サーバーの負荷を軽減し、トラフィックとエネルギーを節約するために、CDNを使用していますが、プラットフォームには独立して動作するのに十分なリソースがあり、特定のプロバイダーに縛られていません。
プラットフォームデバイス
着信トラフィックは、異なるレベル(L3、L4、L7)でバランスが取られます。
プラットフォームの内部構造は、「モノリスからマイクロサービスへの移行中」と説明できます。 機能は「サービス」と呼ばれる部分に分割されます。これらはまだマイクロサービスではありませんが、もはやモノリスではありません。
サービスデバイスは一般的です。nginxのフロントエンド、バックエンド-サービス自体、およびデータベース、キャッシュ、その他のサービスなど、必要なすべてのデータソースへの特定のプロキシセット。
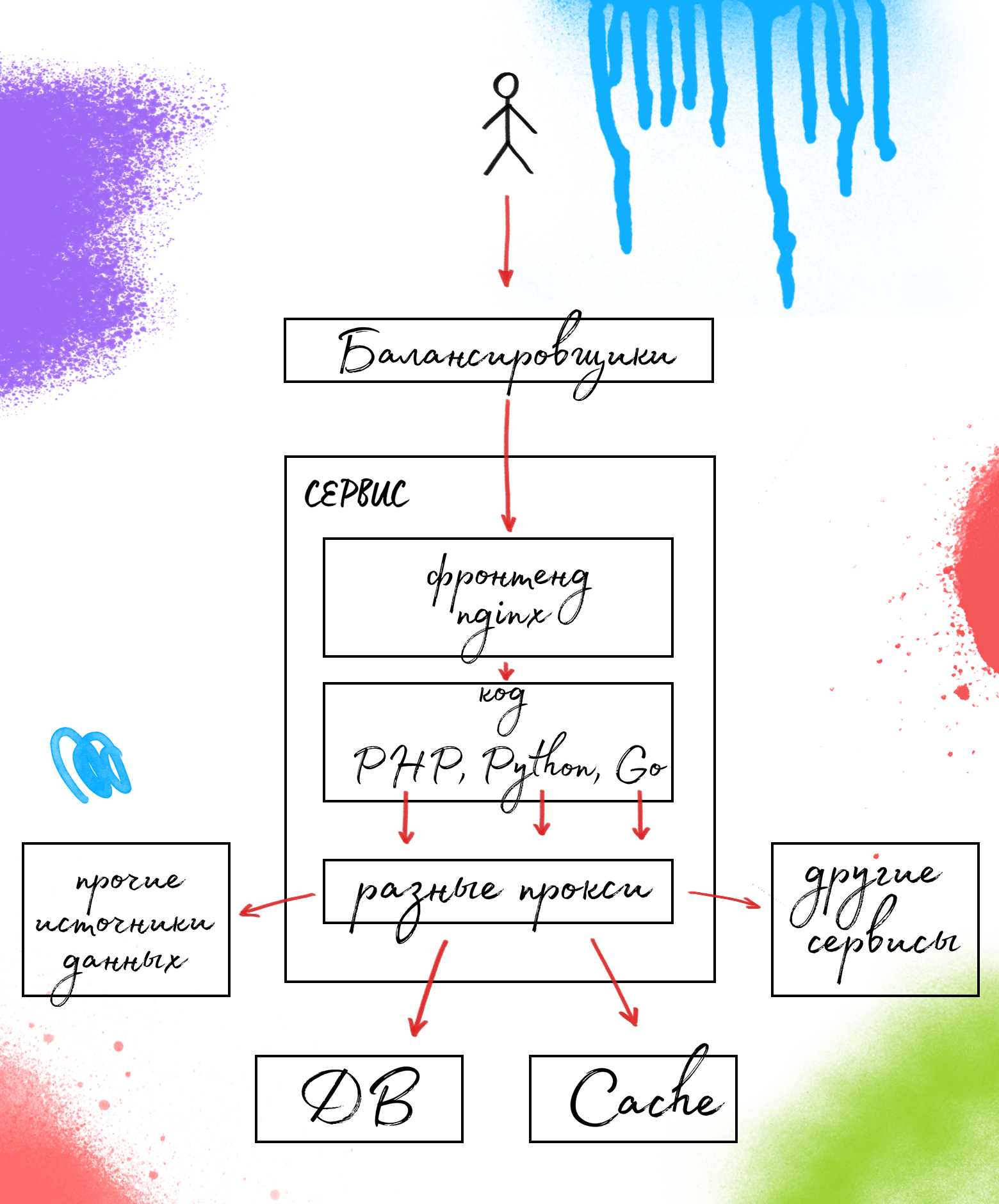
使用されているプロキシの詳細については、
Highload Junior 2016での私の講演を
ご覧ください 。
おわりに
多くの場合、負荷の高いプロジェクトには、継続的なサポートを必要とする複雑なアーキテクチャ、5階建てのソリューションが必要です。 これは間違っています-システムが複雑になるほど、トラブルが多くなり、最も重要でないバグが発生します。 したがって、単純化のためです。 私たちは、KISSの原則を順守し、本質を生み出さず、開発、サポート、および管理の両方において単純であるべきことを複雑にしません。
このようなデバイスプラットフォームを使用すると、簡単にスケーリングできるため、多くの問題を回避できます。 現在、私たちは過渡期にあり、Dockerとマイクロサービスという現代的で便利なことに目を向けています。 すぐに何が出てくるかを説明します。