 Silicon Valley HBOシリーズ
Silicon Valley HBOシリーズは、第4シーズンの第4エピソードで、ホットドッグと非ホットドッグをアプリケーションとして認識する実際のAIアプリケーションをリリースしました(このアプリケーションは
、AndroidとiOSで利用可能になりました !)
これを実現するために、電話で直接動作する特別なニューラルアーキテクチャを開発し、TensorFlow、Keras、およびNvidia GPUを使用してトレーニングしました。
その実用的な利点はばかげていますが、このアプリケーションはディープラーニングとエッジコンピューティングの両方の手頃な価格の例です。 すべてのAI作業はユーザーデバイスによって100%提供され、画像は電話を離れることなく処理されます。 これにより、即時応答(クラウドとデータを交換する必要はありません)、オフラインでの可用性、およびプライバシーの向上が実現します。 また、何百万人ものユーザーがいる場合でも、アプリケーションを0ドルで実行し続けることができます。これは、AIに対する従来のクラウドベースのアプローチよりも大幅にコストを節約できます。
 Not Hotdog AIアプリケーションをトレーニングするために接続されたeGPUを備えた開発者のコンピューター
Not Hotdog AIアプリケーションをトレーニングするために接続されたeGPUを備えた開発者のコンピューターこのアプリケーションは、GPUが接続された同じラップトップで、手動で選択したデータを使用して、1人の開発者がシリーズ専用に映画スタジオによって開発されました。 この点で、限られた時間とリソース、非技術的な会社、個々の開発者などのアマチュアで今日達成できることのデモンストレーションとして役立ちます。 この精神で、この記事では、他の人が自分のアプリケーションを作成するために繰り返すことができるステップの詳細な概要を提供しようとします。
アプリ
シリーズを視聴せず、
アプリケーションをテストしなかった
場合は (そうすべきです!)、写真を撮り、写真にホットドッグが表示されているかどうかについて意見を表明します。 これは、最新のAI研究およびアプリケーション、特にImageNetに敬意を表する単純な使用法です。
ホットドッグを認識するために、おそらく世界中の誰よりも多くのプログラムリソースを割り当てましたが、それでもアプリケーションはひどい、および/または洗練された方法で誤解されることがあります。
その逆もあり、時には困難な状況でホットドッグを認識することもあります...
Engadgetが書いているように 、
「これは信じられない。 20分で、このアプリケーションで、過去2年間にShazamで歌をタグ付けして認識したよりも多くの食べ物を認識できました。プロトタイプから生産まで
Hacker Newsを読んだとき、あなたは次のように考えました。
「彼らはこのために最初のラウンドで1,000万ドルを集めましたか? このアプリは
週末にかけて
開発できます!」このアプリは、あなたに同じように感じさせるでしょう。 最終的に、最初のプロトタイプは実際に週末にGoogle Cloud Platform Vision APIとReact Nativeを使用して作成されました。 しかし、最終的にアプリケーションカタログに入ったアプリケーションの最終バージョンを作成するには、外部から評価するのが難しい意味のある改善を行うのに数か月(1日数時間)の追加作業が必要でした。 全体の精度、トレーニング時間、分析時間の最適化に数週間を費やし、開発をスピードアップするためにさまざまな設定やツールを試し、週末を通してiOSとAndroidの許可を考慮してユーザーインターフェースを最適化しました(このトピックについては話しません)。
多くの場合、技術的なブログや科学記事ではこの部分を省略し、最終版をすぐに表示することを好みます。 しかし、他の人が私たちの間違いや行動から学ぶのを助けるために、到達した最終的なアーキテクチャを説明する前に、私たちにとってうまくいかなかったアプローチの要約リストを提示します。
V0:プロトタイプ
 画像の例と、Google Cloud VisionドキュメントのAPIの対応する問題
画像の例と、Google Cloud VisionドキュメントのAPIの対応する問題プロトタイプの作成にReact Nativeを選択したのは、実験用のシンプルなサンドボックスを提供し、多くのデバイスのサポートを迅速に提供するのに役立つためです。 エクスペリエンスは成功し、プロジェクトの最後までReact Nativeを去りました。プロセスを常に簡素化するわけではなく、アプリケーションの設計を意図的に制限する必要がありましたが、最終的にReact Nativeはその仕事を果たしました。
プロトタイプに使用された別の主要コンポーネントである
Google Cloud Vision APIから、すぐに拒否しました。 3つの主な理由があります。
- 最初の、そして最も重要なことは、ホットドッグの認識精度があまり良くなかったことです。 多種多様なオブジェクトを認識するのは素晴らしい仕事ですが、特定の特定のものをあまりよく認識せず、2016年の実験中にサービスのパフォーマンスが低下したかなり一般的な性質のさまざまな例がありました。
- その性質上、クラウドサービスは常にデバイスでのネイティブ実行よりも遅くなり(ネットワークラグが痛い!)、オフラインでは機能しません。 デバイスの外部に画像を転送するという考えは、法律上およびプライバシー上潜在的に意味があります。
- 最終的に、アプリケーションが普及した場合、Google Cloudでの作業にはかなりの費用がかかります。
このため、一般的に「エッジコンピューティング」と呼ばれるものの実験を開始しました。 私たちの場合、これは、ラップトップでニューラルネットワークをトレーニングした後、モバイルアプリケーションに直接転送し、ニューラルネットワークの実行フェーズ(または結論の結論)がユーザーの電話で直接実行されることを意味します。
V1:TensorFlow、Inception、およびRetraining
TensorFlow開発チームの
Pete Wardenとの楽しい会議のおかげで、TensorFlowをiOSデバイスに統合することでTensorFlowを直接実行できることがわかり、この方向で実験を開始しました。 React Nativeの後、TensorFlowはスタックの2番目の不可欠な部分になりました。
TensorFlowのObjective-C ++カメラのサンプルをReact Nativeシェルに統合するのにたった1日しかかかりませんでした。 学習用のスクリプトを学習するのにかなり時間がかかりました。これは、より具体的なマシンビジョンタスクで動作するようにInceptionアーキテクチャを再トレーニングするのに役立ちます。 Inceptionは、Googleが画像認識用に作成したニューラルアーキテクチャのファミリーの名前です。 インセプションは事前トレーニング済みシステムとして利用できます。つまり、トレーニングフェーズが完了し、重みが設定されます。 多くの場合、画像認識ニューラルネットワークは、20,000を超えるさまざまな種類のオブジェクト(およびその中のホットドッグ)を認識する最高のニューラルアーキテクチャを探すための毎年の競争であるImageNetでトレーニングされます。 ただし、Google Cloud Vision APIのように、競争は認識可能なオブジェクトの可能な最大数を奨励し、20,000を超える特定のオブジェクトの初期精度はそれほど高くありません。 このため、再トレーニング(「転送学習」とも呼ばれます)は、完全にトレーニングされたニューラルネットワークを取得し、それを再トレーニングして、作業中の特定のタスクをより適切に完了することを目的としています。 これには通常、スタックからレイヤー全体を削除するか、必要なオブジェクト(ホットドッグなど)をより正確に認識するために、ニューラルネットワークの個々のタイプのオブジェクト(椅子など)を区別する機能をゆっくり消去することによって、ある程度の「忘却」が伴います。
ニューラルネットワーク(この場合はInception)は、1400万のImageNetイメージでトレーニングできますが、ホットドッグの認識を劇的に改善するために、ホットドッグの数千枚の写真でそれを再トレーニングすることができました。
トレーニングを転送することの大きな利点は、ニューラルネットワークを最初からトレーニングした場合よりもはるかに速く、少ないデータでより良い結果が得られることです。 複数のGPUで完全なトレーニングを行うには数か月かかり、数百万枚の画像が必要になりますが、再トレーニングはラップトップで数千枚の写真を使って数時間で行うことができます。
私たちが直面した最も困難なタスクの1つは、ホットドッグを考慮するべきものとそうでないものの正確な定義でした。 「ホットドッグ」の定義は驚くほど複雑であることが判明しました(カットソーセージは考慮されますか、もしそうなら、どの種ですか?)そして文化的解釈の対象となります。
同様に、私たちの問題の「オープンワールド」の性質は、ほぼ無限の量の入力に対処しなければならないことを意味しました。 一部のコンピュータービジョンタスクは、比較的限られた入力データセット(たとえば、機械的欠陥のあるまたは欠陥のないボルトのX線)を処理しますが、セルフィー、自然画像、さまざまな料理を処理するためのアプリケーションを準備する必要がありました。
このアプローチは有望であり、結果にある程度の改善をもたらしたと言うだけで十分ですが、いくつかの理由で中止しなければなりませんでした。
まず、私たちのタスクの性質は、トレーニング用のデータの強い不均衡を意味しました。ホットドッグ自体よりもホットドッグではないものの例がたくさんあります。 実際には、ホットドッグの3つの画像とホットドッグではない97の画像でアルゴリズムをトレーニングし、最初の0%と2番目の100%を認識すると、名目上の精度は97%になります! この問題は、TensorFlow再トレーニングツールによって直接対処されず、本質的にゼロからディープラーニングモデルを確立し、重みをインポートし、より制御された方法でトレーニングを実行するように強制します。
この時点で、私たちは弾丸を噛み、TeraFlowの上に優れた使いやすい抽象化を提供するディープラーニングライブラリであるKerasで作業を開始することを決定しました。私たちのような不均衡なデータセットで。
この機会を利用して、VGGなどの他のニューラルアーキテクチャをテストしましたが、1つの問題が残っていました。 それらのどれも、iPhoneで快適な作業を提供しませんでした。 メモリを消費しすぎてアプリケーションがクラッシュし、結果を生成するのに最大10秒かかることがありましたが、これはUXの観点からは理想的ではありません。 この問題を解決するために多くのことを試みましたが、最終的に、これらのアーキテクチャは大きすぎてモバイルデバイスで動作できないことを認識しました。
V2:KerasおよびSqueezeNet
 SqueezeNet対AlexNet、コンピュータービジョンアーキテクチャの祖父。 出典: SqueezeNetの科学記事現在の状況を説明するために、これはプロジェクト開発の歴史の約半分です。 この時点で、UIは90%以上の準備が整っており、変更する必要はほとんどありませんでした。 しかし今では、ニューラルネットワークの準備が最大でも20%であることが明らかです。 問題と優れたデータセットを十分に理解していましたが、完成したニューラルアーキテクチャのコードは0行しか書かれておらず、携帯電話で確実に動作するコードはありませんでした。精度も大幅に向上します。
SqueezeNet対AlexNet、コンピュータービジョンアーキテクチャの祖父。 出典: SqueezeNetの科学記事現在の状況を説明するために、これはプロジェクト開発の歴史の約半分です。 この時点で、UIは90%以上の準備が整っており、変更する必要はほとんどありませんでした。 しかし今では、ニューラルネットワークの準備が最大でも20%であることが明らかです。 問題と優れたデータセットを十分に理解していましたが、完成したニューラルアーキテクチャのコードは0行しか書かれておらず、携帯電話で確実に動作するコードはありませんでした。精度も大幅に向上します。私たちの直前の問題は単純でした:InceptionとVGGが大きすぎる場合、再訓練できるより単純な、事前に訓練されたニューラルネットワークはありますか? いつも最高のジェレミー・ハワードからのヒント(この男は一生どこにいましたか?)Xception、Enet、およびSqueezeNetを試しました。 組み込みのディープラーニングシステムのソリューションとしてこのシステムを明示的に配置し、GitHubで事前にトレーニングされたKerasモデルを利用できることから、非常に迅速に
SqueezeNetを選択し
ました (オープンソース)。
それで、違いはどのくらいですか? VGGのようなアーキテクチャは、約1億3800万のパラメーター(基本的にニューロンとそれらの間の値をモデル化するために必要な数の数)を使用します。 インセプションは大幅な進歩を示しており、必要なパラメーターはわずか2300万です。 比較のために、SqueezeNetは125万個のパラメーターで動作します。
これには2つの利点があります。
- トレーニング段階では、より小さなニューラルネットワークがはるかに速くトレーニングされます。 メモリ内に配置するためのパラメーターが少ないため、トレーニングを少し良く並列化(大きなパケットサイズ)でき、ニューラルネットワークはより速く収束します(つまり、理想的な数学関数に近づきます)。
- 本番環境では、モデルははるかに小さく、はるかに高速です。 SqueezeNetは10 MB未満のRAMを消費しますが、Inceptionのようなアーキテクチャは100 MB以上を必要とします。 違いは非常に大きく、アプリケーションで使用可能なメモリが100 MB未満のモバイルデバイスで作業する場合は特に重要です。 また、小さなニューラルネットワークは、大きなニューラルネットワークよりもはるかに高速に最終結果を計算します。
もちろん、私は何かを犠牲にしなければなりませんでした。
- 小さいニューラルネットワークアーキテクチャでは利用可能な「メモリ」が少なくなります。複雑な状況(20,000個の異なるオブジェクトの認識など)や、狭いクラスのタスクでの複雑な状況の処理(たとえば、ニューヨークのホットドッグの違いを理解する場合)スタイルとシカゴスタイル)。 その結果、通常、小規模なニューラルネットワークは、大規模なネットワークよりも精度が低くなります。 20,000個のImageNetオブジェクトを認識しようとすると、SqueezeNetは58%の認識精度しか示しませんが、VGGの認識率は72%です。
- 小さなニューラルネットワークは再訓練が困難です。 技術的には、InceptionとVGGの場合と同じアプローチを使用してSqueezeNetに何かを「忘れ」させ、それを再訓練してホットドッグと非ホットドッグを区別することを妨げるものは何もありません。 実際には、学習のペースを調整するのが難しく、結果は常にSqueezeNetをゼロから学習するよりも満足のいくものではありませんでした。 それはまた、私たちの使命の「開かれた世界」の性質によるものかもしれません。
- 理論的には、小規模なニューラルネットワークを再トレーニングする必要はほとんどありませんが、いくつかの「小さな」アーキテクチャでこれに遭遇しました。 オーバーフィットとは、ネットワークの専門性が高すぎることを意味し、一般的にホットドッグを認識することを学習する代わりに、トレーニングしたホットドッグの特定の写真のみを正確に認識することを学習します。 人間の例えは、ホットドッグが通常はパンのソーセージで、場合によっては調味料などで構成されていることを抽象化せずに示すホットドッグの特定の写真を思い出すことです。ホットドッグのまったく新しいイメージが表示される場合これはホットドッグではないと言う傾向があります。 通常、小規模ネットワークには「メモリ」が少ないという事実があるため、特殊化するのが難しいのは容易に理解できます。 しかし、場合によっては、小規模ネットワークの精度が最大99%に跳ね上がり、突然トレーニング段階では見られなかった画像の認識が停止しました。 入力にセミランダムストレッチ/ディストーション画像を追加し、1000個の各画像で1.00回ではなく、特定の方法で学習することで1000個の画像のバリエーションを変更して、この1000個の画像を具体的に記憶する可能性を減らすと、通常、効果は拡張データを追加すると消えました。 代わりに、ホットドッグ(バン、ソーセージ、調味料など)の「兆候」を認識し、トレーニングセット内の特定の画像の特定のピクセル値に過度に結び付かないほど柔軟性と汎用性を維持する必要があります。
 Kerasブログ拡張例
Kerasブログ拡張例この時点で、ニューラルネットワークのアーキテクチャを調整する実験を開始しました。 特に、バッチ正規化の使用を開始し、さまざまなアクティベーション機能を試しました。
- バッチ正規化は、スタック内のさまざまな段階で値を「平滑化」することで、ニューラルネットワークの学習を高速化するのに役立ちます。 なぜこれが機能するのかはまだ明確ではありませんが、その効果はよく知られています:ニューラルネットワークの収束がはるかに速くなります。
- アクティベーション関数は、「ニューロン」をアクティベートするかどうかを決定する内部の数学関数です。 多くの科学記事でReLU(Rectified Linear Unit)について言及されていますが、ELUでより良い結果が得られました。
バッチ正規化とELUをSqueezeNetに追加した後、ゼロから学習したときに90%を超える精度を達成したニューラルネットワークをトレーニングできましたが、非常に脆弱でした。つまり、同じニューラルネットワークは、場合によっては再トレーニングまたは学習不足になる可能性がありました実際の条件でのテストに直面しました。 データセットに追加の例を追加し、データ拡張を使用した実験を行っても、通常の結果を示すネットワークをセットアップするのに役立ちませんでした。
そのため、この段階は有望であり、初めてiPhoneで完全に機能し、1秒未満で結果を計算する機能的なアプリケーションを初めて提供しましたが、最終的に4番目の最終アーキテクチャに移行しました。
3. DeepDogアーキテクチャ
from keras.applications.imagenet_utils import _obtain_input_shape from keras import backend as K from keras.layers import Input, Convolution2D, SeparableConvolution2D, \ GlobalAveragePooling2d \ Dense, Activation, BatchNormalization from keras.models import Model from keras.engine.topology import get_source_inputs from keras.utils import get_file from keras.utils import layer_utils def DeepDog(input_tensor=None, input_shape=None, alpha=1, classes=1000): input_shape = _obtain_input_shape(input_shape, default_size=224, min_size=48, data_format=K.image_data_format(), include_top=True) if input_tensor is None: img_input = Input(shape=input_shape) else: if not K.is_keras_tensor(input_tensor): img_input = Input(tensor=input_tensor, shape=input_shape) else: img_input = input_tensor x = Convolution2D(int(32*alpha), (3, 3), strides=(2, 2), padding='same')(img_input) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(32*alpha), (3, 3), strides=(1, 1), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(64 * alpha), (3, 3), strides=(2, 2), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(128 * alpha), (3, 3), strides=(1, 1), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(128 * alpha), (3, 3), strides=(2, 2), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(256 * alpha), (3, 3), strides=(1, 1), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(256 * alpha), (3, 3), strides=(2, 2), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) for _ in range(5): x = SeparableConvolution2D(int(512 * alpha), (3, 3), strides=(1, 1), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(512 * alpha), (3, 3), strides=(2, 2), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = SeparableConvolution2D(int(1024 * alpha), (3, 3), strides=(1, 1), padding='same')(x) x = BatchNormalization()(x) x = Activation('elu')(x) x = GlobalAveragePooling2D()(x) out = Dense(1, activation='sigmoid')(x) if input_tensor is not None: inputs = get_source_inputs(input_tensor) else: inputs = img_input model = Model(inputs, out, name='deepdog') return model
設計
最終的なアーキテクチャは、2017年4月17日にGoogle
がMobileNetsで公開した科学記事の影響を大きく受けています。 これは、おそらく私たちのタスクには単純すぎるSqueezeNetと、モバイルでの使用には不必要に重い過負荷のInceptionおよびVGGアーキテクチャとの間で有利な位置を占めることを意味します。 この記事では、ニューラルネットワークのサイズと複雑さを調整するいくつかの可能性、特にメモリ/ CPU消費と精度のバランスを選択する可能性について説明します。
締め切りの1か月前に、科学記事の結果を再現しようとしました。 記事の公開後1日以内にKerasの
実装が GitHubで既に公開されたのは、イスタンブール工科大学の学生であるRefik Kan Mullyのおかげです。これは、Keras SqueezeNetの見事な実装を行ったときにすでに使用した成果です。 ディープラーニングコミュニティの規模、資格、オープン性、およびREFICなどの才能の存在-これが、ディープラーニングを現代のアプリケーションでの使用に適したものにしているだけでなく、この業界での仕事を他の技術業界よりも刺激的にしています私は自分の人生に関与していました。
最終的なアーキテクチャでは、元のMobileNetsアーキテクチャおよび一般に受け入れられているルールから、特に次のように大幅に移行しました。
- XCeptionに関する科学記事(深さの畳み込みについて詳しく説明している)は、実際にはこれがこのタイプのアーキテクチャの精度の低下につながることを示唆しているため(Redditが義務的に述べているように) QuickNetに関する科学記事の著者)。 また、この方法は、ニューラルネットワークのサイズの削減にも役立ちます。
- ReLUの代わりにELUを使用しました。 SqueezeNetの実験と同様に、ここでELUはReLUと比較して収束速度と最終的な精度が向上しています。
- PELUは使用しませんでした。 有望ではありますが、このアクティベーション関数は、どのように使用してもバイナリ状態になる傾向があります。 徐々に改善する代わりに、ニューラルネットワークの精度は、パケットごとに約0%から約100%の間で変化しました。 これが発生する理由は明らかではありません。これは、何らかの実装エラーまたはユーザーエラーが原因である可能性があります。 画像の幅と高さの軸をマージしても、状況は変わりませんでした。
- SELUは使用しませんでした。 iOSとAndroidのバージョンのリリース間の小規模な調査では、PELUと非常によく似た結果が示されました。 SELUを単独で活性化機能の特効薬として単独で使用することはできず、科学記事のタイトルで示されているように、狭く定義されたSNNアーキテクチャの一部として使用する必要があると考えられます。
- ELUと共にバッチ正規化を引き続き使用しました。 これがオプションであることを示す多くの指標がありますが、バッチ正規化なしで行ったすべての実験で、ニューラルネットワークは収束を完全に拒否しました。 その理由は、アーキテクチャのサイズが小さいことです。
- アクティベーションの前にバッチ正規化を適用しました。 これは最近いくつかの論争の主題ですが、収束の活性化後のBNの配置の実験では、収束もありませんでした。
- ニューラルネットワークを最適化するために、 循環学習率と(クラスメート)Brad Kenstlerの優れたKeras実装を使用しました。 CLRは、ニューラルネットワークの最適な学習ペースを推測しようとするゲームをプレイします。 さらに重要なことは、学習のペースを上げたり下げたりすることで、CLRは認識精度を達成するのに役立ちます。これは、私たちの経験では、従来のオプティマイザーよりも高いです。 これらの両方の理由から、将来のニューラルネットワークのトレーニングにCLR以外の何かを使用する理由を理解することはできません。
- タスクでは、値を調整する必要はありませんでした または MobileNetsアーキテクチャから。 私たちのモデルは、以下の場合にタスクに十分に小さい 、そして計算は十分に高速です 、したがって、最大の精度を達成することに集中することを選択しました。 ただし、これらの変更は、古い携帯電話または組み込みプラットフォームでアプリケーションを実行しようとする場合に役立ちます。
それでは、このスタックは正確にどのように機能しますか? ディープラーニングはブラックボックスの評判が悪いことが多く、多くのコンポーネントは確かに不可解である可能性がありますが、私たちのニューラルネットワークはしばしば、それらのマジックトリックの機能に関する情報を表示します。 このスタックから個々のレイヤーを取得し、特定の入力画像でどのようにアクティブ化されるかを確認できます。これにより、各レイヤーがソーセージ、ロール、またはホットドッグの他の最も顕著な兆候を認識する能力がわかります。

トレーニング
ソースデータの品質が最も重要でした。 ニューラルネットワークは初期データと同程度の品質であり、トレーニングセットの品質を向上させることは、おそらくこのプロジェクトに取り組んでいる間、ほとんどの時間を費やした3つのことの1つです。 それを改善するために、次の重要なステップを踏んだ。
- より多くの画像とより多様な画像(高さ/幅、背景、照明条件、文化的特徴、遠近感、構図など)を検索します。
- 制作中に予想される写真に画像タイプを一致させます。 私たちは、人々が主に本物のホットドッグや他の食べ物を撮影するか、あらゆる方法でランダムなオブジェクトを使ってシステムの裏をかこうとすると仮定したため、データセットはこの仮定を反映していました。
- 同様のオブジェクトの例をできるだけ多く挙げてください。 一部の料理は他の料理よりもホットドッグに似ています(たとえば、ハンバーガーやサンドイッチ、または裸のホットドッグの場合、これらは若いニンジンまたは調理済みのチェリートマトです)。 データセットにはこれが反映されています。
- 予想される歪み:携帯電話のほとんどの写真は、デジタルSLRまたは理想的な照明条件で撮影された「平均的な」写真よりも悪化します。 モバイル写真は鈍く、ノイズが多く、斜めに撮影されています。 積極的なデータ増強は、この問題を解決するための重要なツールでした。
- さらに、ユーザーは実際のホットドッグにアクセスできない可能性があるため、Google検索結果からホットドッグを撮影しようとするため、特殊な歪み(角度のずれ、写真が斜めに撮影された場合、画面からのフラッシュの反射、モアレ効果)モバイルカメラで撮影したLCDスクリーン)。 これらの特定の反射は、 畳み込みニューラルネットワークからのノイズ抵抗の(不在)に関する最近公開された科学論文で説明されているように、ニューラルネットワークを欺くほぼ不思議な能力を備えていました 。 Kerasでチャンネルシフトを使用すると、これらの問題のほとんどが解決されました。
 モアレとフラッシュによる歪みの例。 元の写真: ウィキメディアコモンズ
モアレとフラッシュによる歪みの例。 元の写真: ウィキメディアコモンズ- 一部の境界ケースはキャッチするのが困難でした。 たとえば、球面収差(ソフトフォーカス)または背景の多数のぼかしがあるホットドッグの画像は、ニューラルネットワークを誤解させることがあります。 a)ソフトフォーカスのあるホットドッグの写真があまり多くないため(これを考えるとお腹が空いています)、b)ニューラルネットワークの容量をソフトフォーカスに費やすのは危険です。実際にはほとんどの写真はモバイルのものです。電話にはそのようなサインはありません。 結局、この問題は概して未解決のままにしておくことにしました。
最終的な形式では、データセットは15万枚の画像で構成され、そのうちホットドッグは3,000枚のみでした。 アンバランスの49:1の比率は、Keras 49:1のホットドッグに有利なクラスの重量設定で指定されました。 残りの147,000枚の写真のほとんどは異なった料理であり、わずか3000個だけがニューラルネットワークが一般化をやや良くし、ホットドッグに赤い服を着た男性の画像を撮らないようにするための食べ物ではありませんでした。
データ拡張ルールは次のとおりです。
- 携帯電話の向きに注意を払わないようにアプリケーションをプログラムしたため、回転を±135°以内で適用しました。これは平均よりもはるかに強力です。
- 高さと幅が20%歪んでいます。
- 30%の範囲の割礼。
- 10%の範囲でズームします。
- チャネルは20%シフトします。
- ニューラルネットワークが一般化を支援するランダムな水平反転。
これらのパラメーターは、正確な実験とは対照的に、実験と実際の条件でのアプリケーションの使用方法に関する理解に基づいて、直感的に導き出されます。
データ処理パイプラインの最終段階では、パトリックロドリゲスの
Kerasにマルチプロセスイメージジェネレーターを使用しました。 Kerasにはマルチスレッドとマルチプロセスの組み込み実装がありますが、Patrickライブラリは、発見する時間がなかったという理由で、実験で一貫して高速に動作しました。 このライブラリにより、学習時間が3分の1短縮されました。
ネットワークは、外部GPU(eGPU)が接続された2015 MacBook Proラップトップ、つまりNvidia GTX 980 Ti(おそらく、今日始めたら1080 Tiを購入する)でトレーニングされました。 128個の画像のパケットでニューラルネットワークをトレーニングすることができました。 ネットワークは合計240の時代を訓練しました。 これは、15万枚の画像すべてを240回通過したことを意味します。 約80時間かかりました。
ニューラルネットワークを3段階でトレーニングしました。
- 第1ステージは112時代(8時代のステップサイズで7フルCLRサイクル)続き、学習率は0.005から0.03で、三角形2のルールで(これは最大学習率が16時代ごとに半分になることを意味します)。
- 第2ステージはさらに64時代(8時代のステップサイズで4 CLRサイクル)継続し、学習率は0.0004から0.0045で、三角形ルール2でした。
- 3番目のステージは、さらに64時代(8時代のステップサイズで4 CLRサイクル)継続し、学習率は0.000015から0.0002で、三角形2の規則があります。

学習のペースは、CLR科学記事の著者が推奨する線形実験を実施することで決定されましたが、直感的なようです。ここでは、各段階での最大指標は、以前の最小値の約2倍であり、認識精度が半減する場合の学習ペースを半分にするための業界標準に対応します学習プロセスは成長を止めました。
時間を節約するために、Ubuntuの下でPaperspace P5000インスタンスのトレーニングの一部を費やしました。 場合によっては、パッケージのサイズが2倍になり、各段階での最適な学習率も2倍になりました。
携帯電話でニューラルネットワークを起動する
比較的コンパクトなニューラルアーキテクチャを設計し、モバイルコンテキストの特定の状況に対処するようにトレーニングしたとしても、アプリケーションを正しく動作させるためには、まだ多くの作業が必要でした。 ファーストクラスのニューラルネットワークアーキテクチャを変更せずに実行すると、数百メガバイトのRAMがすぐに消費されます。これは、現代のモバイルデバイスではほとんど耐えられません。 ネットワーク自体の最適化に加えて、画像処理方法とTensorFlow自体のロード方法でさえ、ニューラルネットワークの速度、使用されるRAMの量、および障害の数に大きな影響を与えることがわかりました。
これはおそらくプロジェクトの最も神秘的な部分です。 このトピックに関する情報を見つけることは非常に困難です。おそらく、今日のモバイルデバイスで動作するディープラーニングアプリケーションの数が少ないためです。 ただし、TensorFlow開発チーム、特にPete Warden、Andrew Harp、Chad Whipkaには、既存のドキュメントと質問に答えてくれた彼らの善意に感謝しています。
- ニューラルネットワークの重みを丸めることで、サイズを約25%圧縮できました。 実際、トレーニング中に取得した任意のストック値を使用する代わりに、この最適化は最も一般的なN個の値を選択し、ニューラルネットワークのすべてのパラメーターをこれらの値にします。これにより、zipアーカイブ内のニューラルネットワークのサイズが大幅に削減されます。 ただし、これは解凍後のサイズやメモリ消費には影響しません。 ニューラルネットワークはすでにタスクに十分なほど小さく、丸めがアプリケーションの認識精度にどのように影響するかを調査する時間がなかったため、この改善を生産に実装しませんでした。
-Osスイッチを使用して実稼働用にコンパイルすることによるTensorFlowライブラリの最適化。- TensorFlowから不要なフラグメントを削除:ライブラリは最初に仮想マシンをサポートし、加算、乗算、連結などを含む多数の任意のTensorFlow操作を解釈できます。前にTensorFlowライブラリから不要なフラグメントを削除することでサイズ(およびメモリ消費)を大幅に節約できます iOS用のコンパイル。
- 他の改善も可能です。 たとえば、別のプロジェクトでは、作成者は比較的単純な手法でAndroidのバイナリを1 MB削減することができたため、iOSのTensorFlowコードをタスクに最適化できる他の領域があるかもしれません。
iOSでTensorFlowを使用する代わりに、Appleの組み込みのディープラーニングライブラリ(BNNS、MPSCNN、およびそれ以降のCoreML)を調査しました。 Kerasでニューラルネットワークを設計し、TensorFlowを使用してトレーニングし、すべての重み値をエクスポートし、BNNSまたはMPSCNNでニューラルネットワークを再実装(またはCoreML経由でインポート)して、パラメーターを新しい実装にロードします。 ただし、最大の障害は、新しいAppleライブラリがiOS 10以降でのみ利用可能であり、古いバージョンのiOSをサポートしたかったことです。 iOS 10以降が普及し、これらのフレームワークが改善されると、将来モバイルデバイスでTensorFlowを実行する必要がなくなる可能性があります。
その場でニューラルネットワークを展開することでアプリケーションの動作を変更する
JavaScriptをその場でアプリケーションに埋め込むのが素晴らしいと思うなら、その場でニューラルネットワークを実装してみてください! 本番環境で使用した最後のトリックは、
CodePushの使用と、アプリケーションディレクトリで公開された後のニューラルネットワークの新しいバージョンを活発に導入するためのAppleの比較的自由な使用条件でした。 これは主にリリース後の認識精度を高めるために行われますが、理論的には、この方法を使用して、AppStoreで2回目のレビューを行うことなくアプリケーションの機能を大幅に改善できます。
#import <CodePush/CodePush.h> … NSString* FilePathForResourceName(NSString* name, NSString* extension) { // NSString* file_path = [[NSBundle mainBundle] pathForResource:name ofType:extension]; NSString* file_path = [[[[CodePush.bundleURL.URLByDeletingLastPathComponent URLByAppendingPathComponent:@] URLByAppendingPathComponent:name] URLByAppendingPathExtension:extension] path]; if (file_path == NULL) { LOG(FATAL) << << [name UTF8String] << << [extension UTF8String] << ; } return file_path; } …
import React, { Component } from 'react'; import { AppRegistry } from 'react-native'; import CodePush from "react-native-code-push"; import App from './App'; class nothotdog extends Component { render() { return ( <App /> ) } } require('./deepdog.pdf') const codePushOptions = { checkFrequency: CodePush.CheckFrequency.ON_APP_RESUME }; AppRegistry.registerComponent('nothotdog', () => CodePush(codePushOptions)(nothotdog));
そうでなければ何をしますか
うまくいかなかったり、テストする時間がなかったものがたくさんありますが、今後検討するアイデアをいくつか紹介します。
- 拡張オプションのより徹底的なチューニング。
- アプリケーションがオブジェクトの2つ以上のカテゴリを区別するかどうか、ホットドッグを認識するための最終的な制限など、抽象化レベルの最終測定を含む、最初から最後までの精度の測定(認識限界が0を超える場合、アプリケーションは「ホットドッグ」と言う結論に達しました) 、90、デフォルト値の0.5と比較)、重みの丸め後など。
- アプリケーションにフィードバックメカニズムを組み込む-ユーザーがプログラムの誤った結果に失望を表明できるようにするため、またはニューラルネットワークを積極的に改善するため。
- 現在の224×224ピクセルよりも画像認識に高い解像度を使用します-具体的には、値を増やして
UX / DX、AIバイアス、不吉な谷の効果
最終的に、開発者(DX)とAIアプリケーションの開発における組み込みバイアスとのユーザーインタラクション(UX)の明白で重要な影響は言うまでもありません。 おそらくこれらのトピックはそれぞれ別の記事(または別の本)に値しますが、これらの3つの要因が私たちの仕事に与える具体的な影響は次のとおりです。
UX(ユーザーインタラクション)は、通常のアプリケーションよりもAIアプリケーションの開発のあらゆる段階でおそらくより重要です。 現在、完璧な結果をもたらすディープラーニングアルゴリズムはありませんが、ディープラーニングとUXの適切な組み合わせが理想と区別できない結果をもたらす多くの状況があります。 UXに関する正しい期待は、ニューラルネットワーク設計の正しい方向を導き出し、避けられないAI障害のケースを適切に処理する際に非常に貴重です。 ユーザーと対話することを考えずにAIアプリケーションを作成することは、確率的勾配降下なしでニューラルネットワークを学習するようなものです。
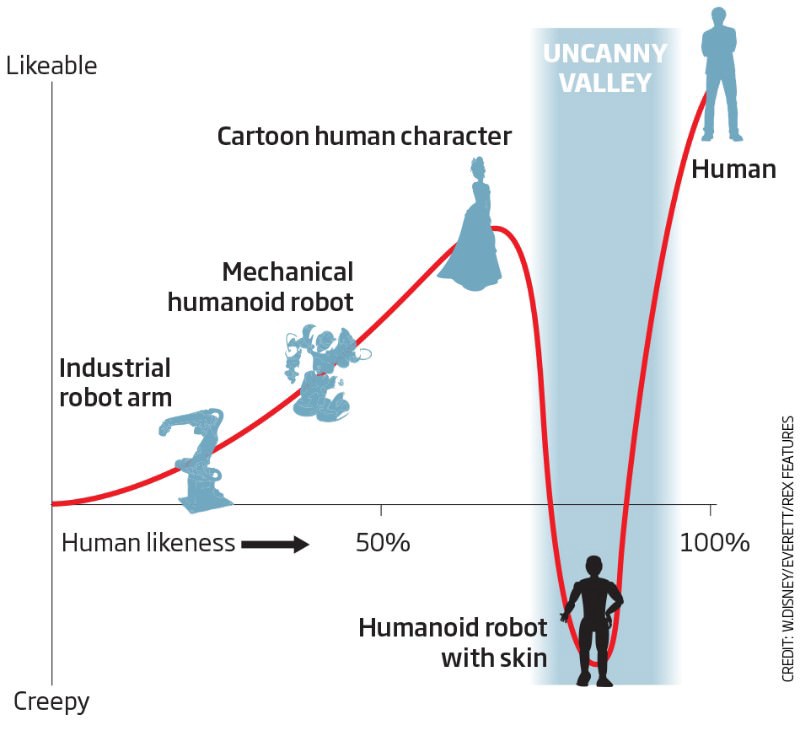 出典: 新科学者DX(開発者との相互作用)
出典: 新科学者DX(開発者との相互作用)も非常に重要です。これは、ニューラルネットワークのトレーニング時間が、プログラムのコンパイルの期待とともに、新しいhemoであるためです。
DXを優先リストの最初に確実に配置する(したがって、Kerasを選択する)と確信しています。これは、後続の実行(GPUの手動並列化、マルチプロセッシングのデータ拡張、TensorFlowパイプライン、caffe2 / pyTorch)。TensorFlowのような比較的愚かなドキュメントを含むプロジェクトでさえ、ニューラルネットワークのトレーニングと実行のために十分にテストされ、広く使用され、見事にサポートされた環境を提供することにより、開発者とのやり取りを大幅に促進します。同じ理由で、独自の開発GPUよりも安くて便利なものを見つけるのは困難です。画像をローカルで表示および編集し、お気に入りのエディターでコードを遅延なく編集する機能-これにより、AIプロジェクトの開発の品質と速度が大幅に向上します。ほとんどのAIアプリケーションは、より文化的なバイアスに直面しますアプリケーションよりも。しかし、たとえば、最初に文化的特徴を考えた最も単純な場合でも、ニューラルネットワークをトレーニングして、フランス語のホットドッグ、アジアのホットドッグ、およびこれまで考えもしなかったさらに多くの奇妙なものを認識しました。AIは人間よりも「良い」決定を下さないことを覚えておくことが重要です。AIは人間と同じバイアスの影響を受け、人間の学習中に感染が発生します。