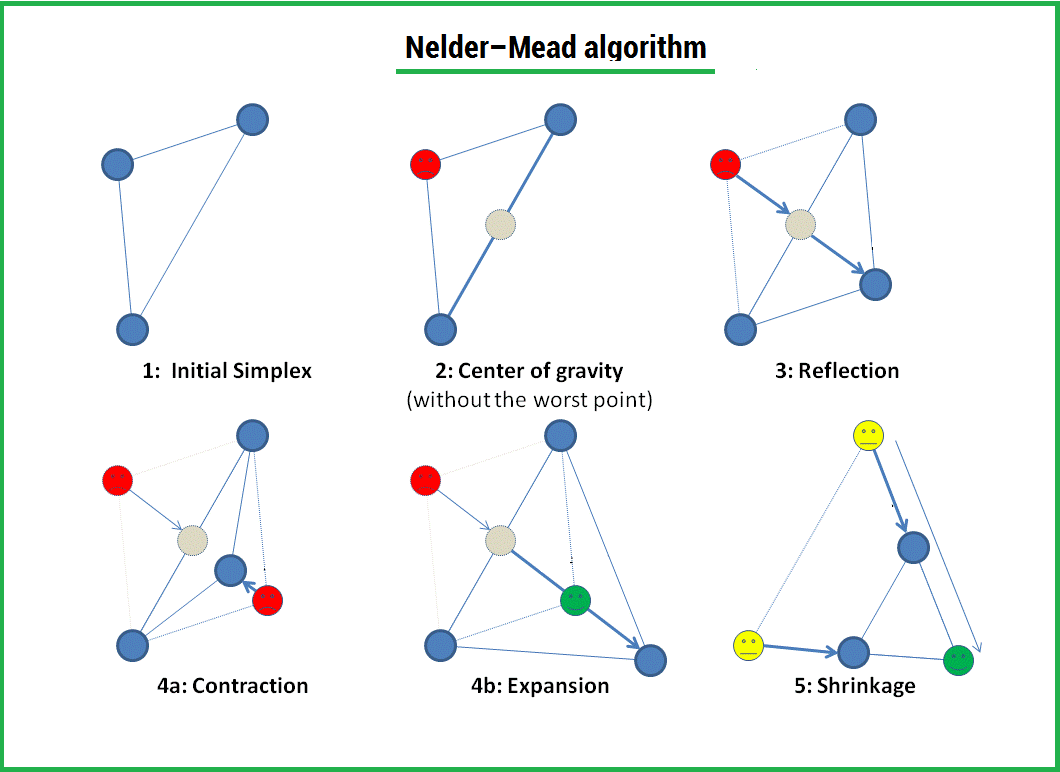
Nelder-Mead法は、いくつかの変数の関数の最適化(最小検索)の方法です。 勾配を使用せずに関数を最適化できる、シンプルで同時に効果的な方法。 収束の理論はありませんが、この方法は信頼性が高く、原則として良好な結果を示します。 数学的計算に使用される一般的なpython言語ライブラリのscipy.optimizeモジュールの最適化関数で使用できます。
このアルゴリズムは、3つの操作を通じて、シンプレックス(
simplex )の形成と、その後の最小方向への変形で構成されます。
1)
反射 (反射);
2)
ストレッチ (拡張);
3)
圧縮 (契約);
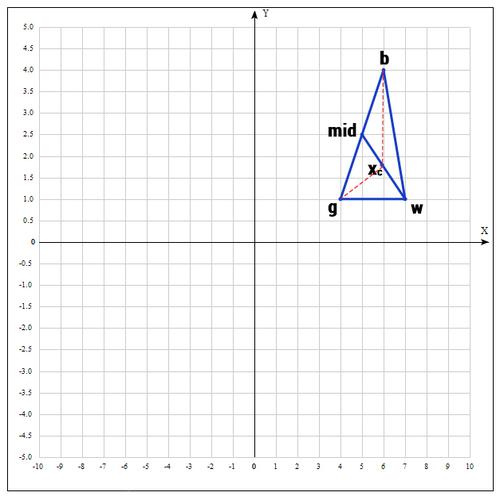
シンプレックスは幾何学的図形であり、三角形のn次元の一般化です。 1次元空間の場合、これはセグメントであり、2次元空間の場合、三角形です。 したがって、n次元のシンプレックスにはn + 1の頂点があります。
アルゴリズム
1)させる
最適化される関数。 最初のステップでは、3つのランダムポイントを選択し(これについては後で説明します)、シンプレックス(三角形)を形成します。 各ポイントで関数の値を計算します:
、
、
。
関数値でポイントを並べ替える
これらの点で、したがって二重の不等式が得られます。
関数の最小値を探しているため、このステップでは、関数の値が最小になる点が最良のポイントになります。 便宜上、次のようにポイントを再指定します。
b =
、g =
、w =
どこが最高、良い、最悪-それぞれ。
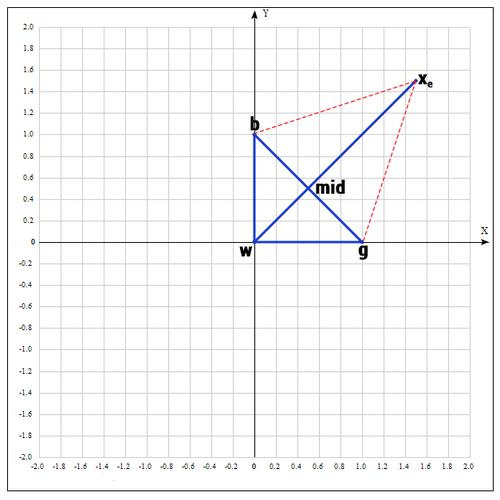
2)次のステップで、ポイントがgとbであるセグメントの中央を見つけます。 なぜなら セグメントの中央の座標は、その端の座標の半和に等しくなります。
より一般的な形式では、これを書くことができます:
3)リフレクション操作を適用します。
ポイントを見つける
次のように:
すなわち 実際には、中点に対する点wを反映します。 原則として、ルール1を採用します。
これは良い点です。 そして、距離を2倍に増やしてみましょう。突然ラッキーになり、ポイントがさらに良くなります。
4)ストレッチの操作を適用します。
ポイントを見つける
次のように:
γとしてγ= 2を使用します。 距離は2倍に増加します。
チェックポイント
:
もし
、それから私たちは幸運だったと私たちはそれが今よりも良い点を見つけた、これが起こらなかった場合、私たちは点で停止します
。
次に、点wを
、最終的に次のようになります:
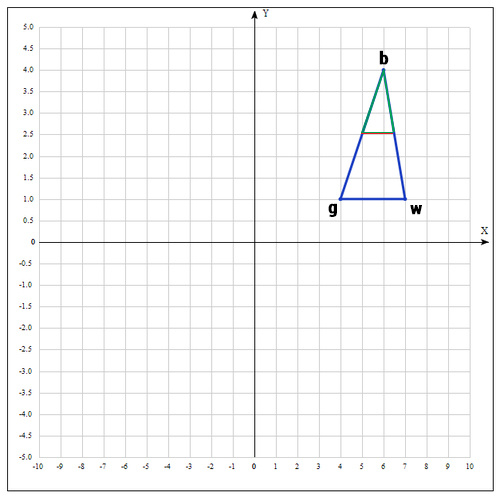
5)まったく運が良くなく、良い点が見つからなかった場合は、圧縮操作を試みます。
操作の名前が示すように、セグメントを縮小し、三角形内の適切なポイントを探します。
良い点を見つけようとする
:
係数βは0.5に等しく、つまり ポイント
wmidセグメントの中央。
別の操作があります-縮小(縮小)。 この場合、シンプレックス全体を再定義します。 「最良の」ポイントのみを残し、残りは次のように決定されます。
係数δは0.5に等しくなります。
基本的に、現在の「最良の」ポイントに向かってポイントを移動します。 変換は次のとおりです。
シンプレックス内のポイントを置き換える必要があるため、この操作は高価であることに注意してください。 幸いなことに、実際に収縮変換が起こることはめったにないことが多くの実験で発見されました。
アルゴリズムは次の場合に終了します。
1)必要な反復回数が実行されました。
2)シンプレックスの面積が特定の値に達しました。
3)現在の最適なソリューションは、必要な精度に達しました。
ほとんどのヒューリスティック手法と同様に、初期化ポイントを選択する理想的な方法はありません。 既に述べたように、シンプレックスを形成するために、互いに近くにあるランダムなポイントを取ることができます。 しかし、MATLABのアルゴリズムの実装で使用されるより良いソリューションがあります。
最初のポイントの選択
ユーザーに適切な解決策のアイデアがある場合はユーザーに委任します。そうでない場合はランダムに選択されます。 残りのポイントは、に基づいて選択されます
、各測定の方向に沿ってわずかな距離で:
どこで
単位ベクトルです。
このように定義されます:
=係数が
定義で
ゼロではありません。
= 0.00025、係数が
ゼロの定義で。
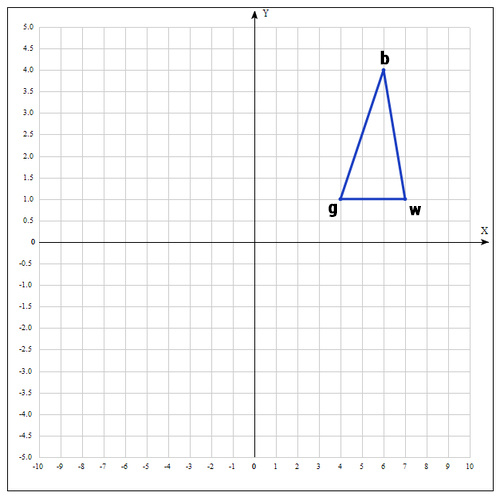
例:
次の関数の極値を見つけます。
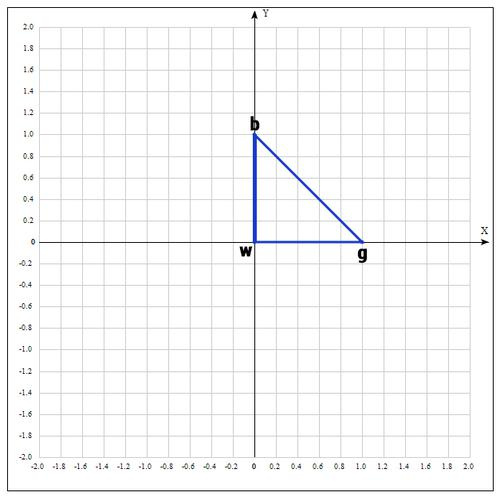
出発点として、次の点を取ります。
各ポイントで関数の値を計算します:
次のようにポイントの名前を変更します。
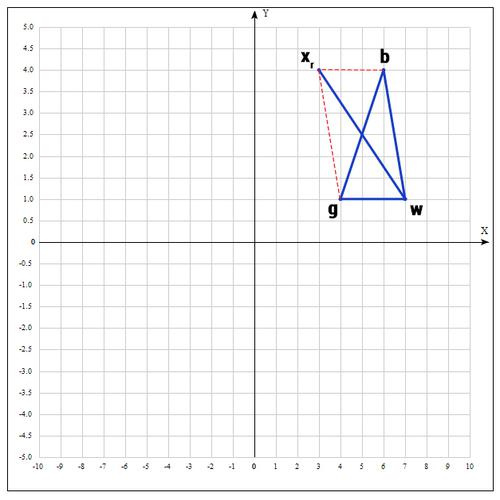
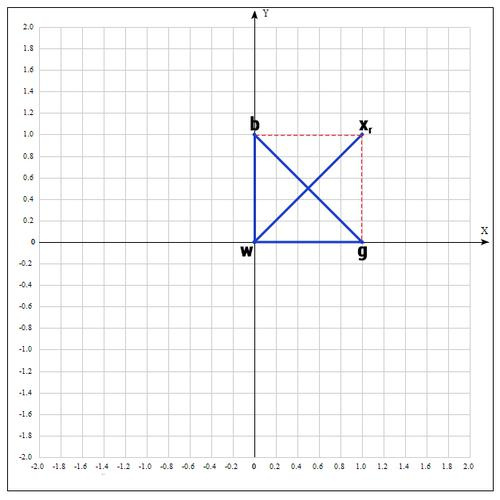
セグメントbgの中央を見つけます。
ポイントを見つける
(反射操作):
α= 1の場合:
チェックポイント
:
なぜなら
セグメントを増やしてみてください(操作のストレッチング)。
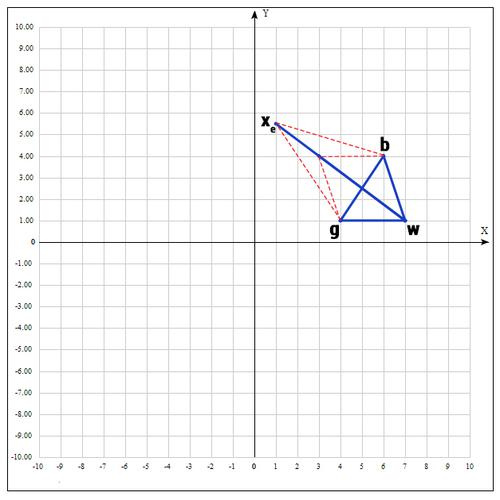
γ= 2の場合:
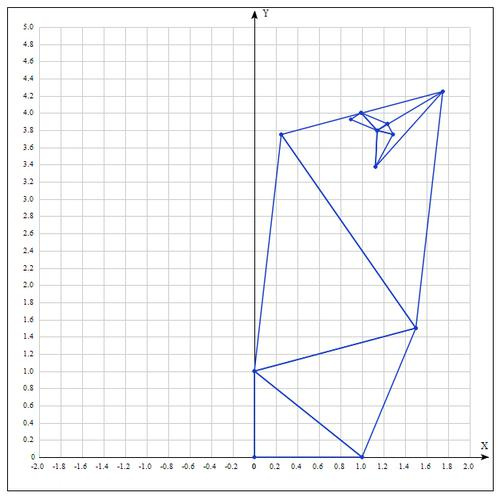
その時点で関数の値を確認してください
:
ポイントが判明した
ポイントbよりも「良い」。 したがって、新しい頂点を取得します。
そして、アルゴリズムは最初からやり直します。
10回の反復の値の表:
| 最高 | いいね | 最悪 |
|---|
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
関数の極値
を分析的に見つけます;ポイントに到達します
。
10回の反復後、かなり正確な近似が得られます。
メソッドの詳細:
Nelder-Meadアルゴリズムは、主に機械学習のパラメーターを選択するために使用されます。 本質的に、シンプレックス法はモデルパラメーターを最適化するために使用されます。 これは、この方法が目的関数をかなり迅速かつ効率的に最適化するという事実によるものです(特に縮小が使用されていない場合-変更)。
一方、収束の理論が欠如しているため、実際には、この方法は、滑らかな(連続的に微分可能な)関数であっても誤った答えを導きます。 また、機能するシンプレックスが最適点から遠く離れている可能性があり、アルゴリズムは、関数をわずかに変更しながら多数の反復を実行します。 この問題を解決するためのヒューリスティックな方法は、アルゴリズムを数回実行し、反復回数を制限することです。
Pythonプログラミング言語での実装:
補助クラスVectorを作成し、演算子をオーバーロードして、ベクターで基本的な操作を実行できるようにします。 私は意図的に補助ライブラリを使用してアルゴリズムを実装しませんでした。 この場合、知覚はしばしば低下します。
記事を読んでくれてありがとう。 彼女があなたにとって有益であり、あなたが多くを学んだことを願っています。
FUNNYDMANはあなたと一緒でした。 最適化!)