Black Engineのマーケティングディレクターであり、Product Managementコースの大学院生である Natalya Garakhanovaは、ビッグデータの神話を暴きます。ビッグデータは最近トレンドになっています。 しかし、それは何ですか、誰もが理解しているわけではありません。
多くの人は、ビッグデータは単なる膨大なデータの配列であるか、単純で安価な方法で格納するものだと考えています。
ビッグデータはまったく主題ではなく、膨大な量の構造化データと非構造化データを処理するためのアプローチ、ツール、および方法の組み合わせです。 これらは、ビジネスと科学の重要な問題の解決に役立つテクノロジーです。 技術の本質を理解していないため、この記事で私が説明しようとした神話が生じました。

神話1.ビッグデータベースのマシンが人々に取って代わります。
神話は、作業タスクの約80%を自動化できるという統計に基づいています。 これは教育の観点からすると大きな問題です。他の職業では膨大な数の人員を再訓練する必要があります。 いくつかの点で、この神話は正しいです。 多くの人々は現在の活動をあきらめなければなりません。 しかし、基本的な失業はありません。
知識の新しい領域は、新しい職業を生み出します。
たとえば、ビッグデータを使用して効果的なターゲット広告のシステムの設計を開始する場合、数学とマーケティングの交差点に新しい知識の専門家が必要になります。 システムの動作とメカニズムの状態を監視するのは彼です。 現在、このような人々はすでに「データ管理プラットフォームオペレーター」の地位に現れ始めています。
プロセスを制御および監視するには、常に人でなければなりません。
人々が仕事なしで放置されることを恐れないでください。 それは人類の歴史の中で何度もあるように、他の職業が表示されます。 結局のところ、印刷機は印刷の歴史を一度変え、書籍の人口調査を不要にした。
神話2.データは1か所で収集する必要があります。
トレーニングアルゴリズムの必要性は、データを1か所に集約する企業とサービスの出現につながります。 これは、セキュリティおよびユーザー情報へのアクセスに問題を引き起こす可能性があります。
人工知能、アルゴリズム、およびマシンをトレーニングするためのデータの集約は、以前ほど重要ではなくなりました。 現在、GoogleやAppleなどの企業は、デバイスを分散型機械学習ネットワークの一部にするために積極的に取り組んでいます。
Googleのデバイスには、同時に機能する1つのネットワークがあります。 アップルは、ビッグデータに基づく新技術の分野でその足跡をたどっています。 たとえば、Googleの特許「Federated Learning」は分散学習に関するものです。 電話機からのデータは特定のデータセンターには流れませんが、モデルが到着し、学習し、携帯電話の他のモデルと、または共通のハブを介して通信を開始します。 このようにして、プライバシーが維持されます。
モデルは複雑でも単純でもよいアルゴリズムですが、興味のある質問には答えが返されます。 数式または単語によって数学的に定義できます。 原則として、私たちの法律は、人間の行動を容認できる(罰せない)と容認できない(罰する)に分類できるモデルです。
モデルは、物理現象を記述するための一連の式である場合もあれば、さまざまな単語や語句を正しい(読み書き可能な)ものと誤った(読み書きできない)ものに分ける言語規則がある場合もあります。 厳密な数学的定式化に頼らずに一般化する場合、モデルは利用可能なデータのトレーニングに基づいて取得する形式化された基準です。
神話3.誰もがビッグデータを必要とする
処理のために大量のデータを処理する必要がある知識の領域があります。 しかし、ビッグデータが必ずしも具体的な結果をもたらすとは限りません。
ガートナーは、さまざまな業界でどのケースが最も人気があるかについて調査を行ってきました。 すべてのデータは、ビジネスで実装されたケースのヒートマップの形式で提示されました。 ボックスが赤くなるほど(割合が大きくなるほど)、調査対象の企業の多くは、ビジネスのビッグデータに基づいて実装されたケースを調査しました。
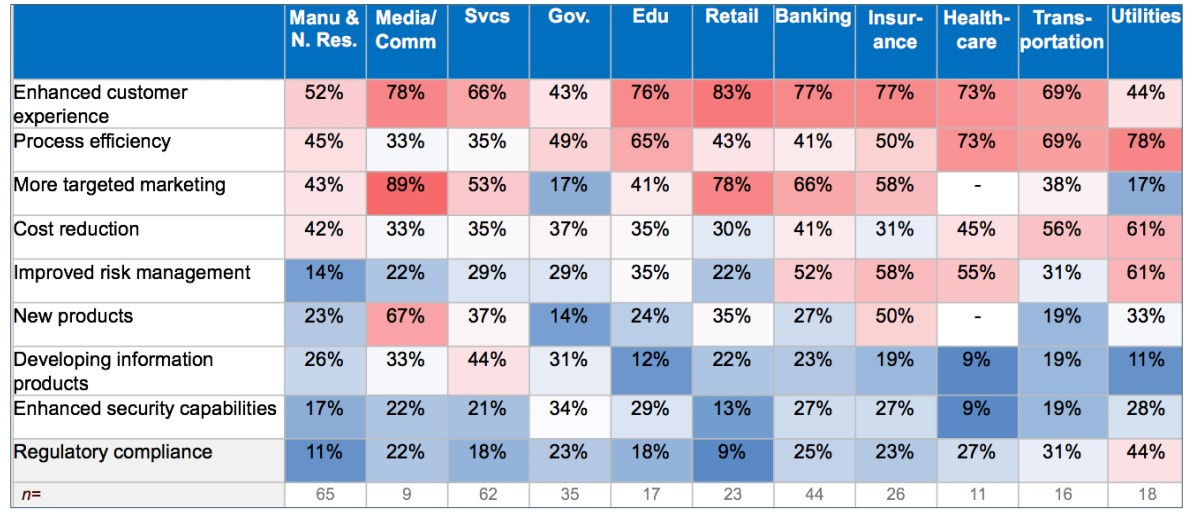
この調査からわかるように、ほとんどのケースはマーケティング、ターゲティング、顧客体験の分野で実施されています。 つまり、顧客分析と顧客サービスの最も関連性の高い分野-B2C販売の分野です。 すべてのケースのうち、公的部門で実施されたケースはほとんどありませんが、この部門のプロセス効率の分野が最も重要です。 新製品の範囲は、この分野ではまだ重要ではありません。
しかし、そのような調査はTech Pro Researchによって実施されました。
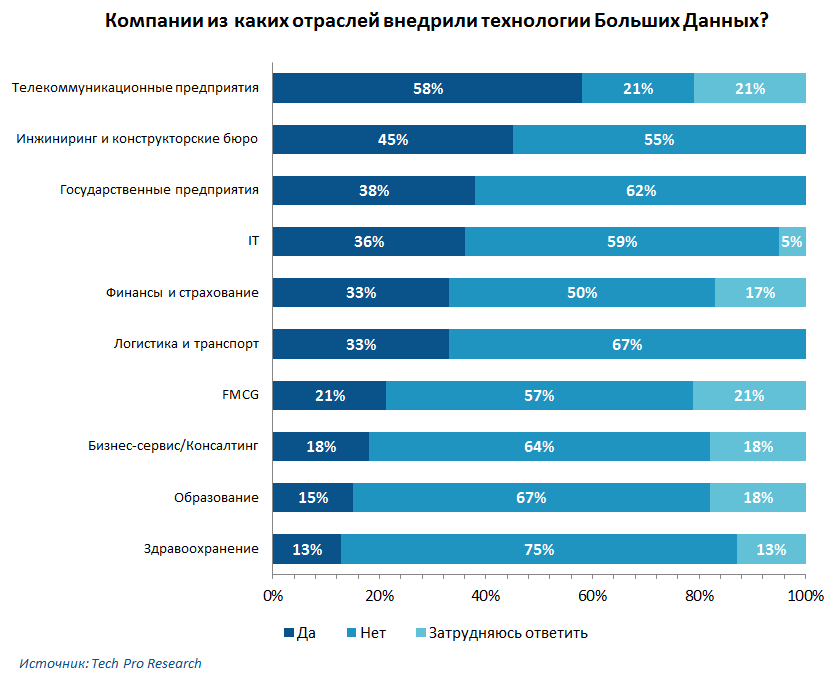
興味深いことに、教育と健康の分野では、ビッグデータはそれほど人気がありませんでした。 しかし、金融機関、政府機関、エンジニアリング、ITはこれらの方法を積極的に使用しています。 さらに、テレコムはビッグデータ技術を導入するための最も人気のある分野です。
貴社が以下の場合、ビッグデータは必要ありません。
- 従業員は、従来のCRMシステムを使用して顧客データを処理および自動化できます。
- ビジネスプロセスの計画、会計、および制御は、ERPシステムを使用して完全に実装されます。
- 以前は、さまざまな情報ソースからのデータが結合され、処理され、評価され、BIシステムを使用して得られた結果が得られ、上記のすべてで問題は発生しませんでした。
神話4.ビッグデータは大企業にのみ適しています。
別の神話は、成功事例の実証によって成功裏に暴かれました。 これは、中小企業ではデータ収集自体が問題になる可能性があるという事実に基づいています。
Google AnalyticsやYandex.Metricaなどのシステムは、リソースの出席を評価するためだけに使用され、それらを使用して追加のレポートは生成されません。 多くの企業は依然として古き良きExcelにデータを保存しており、この場合、ビッグデータメソッドの使用について話すのは時期尚早であることは明らかです。 ロシアのITでは、基本的に誰もが同じGoogleアナリティクスを参照しています。これはビッグデータを使用する最もシンプルなシステムですが、データの収集と整理に効果的です。 ビッグデータに基づいたオンラインストアのマルチチャネルパーソナライズ用プラットフォームであるRetail Rocketの使用に成功している人もいます。
また、高度な技術を試してみたい人のために、小規模企業でもデータを取得できる余裕があり、ビジネスを構築したり、組織およびマーケティングプロセスを改善したりできるデータ交換があります。
西洋では、このトピックはより積極的に議論されています。 例には、Folwerwonk、YouTube Analytics、およびTweriodが含まれます。 中小企業の中には、ビッグデータに基づいたコンピューティング専用に構築されたAmazonプラットフォームなどのクラウドソリューションの使用に成功しているところもあります。
さらに進んで独自のインフラストラクチャを開始する企業があります。たとえば、ペタバイトのデータのリポジトリとして機能し、信頼性が高くスケーラブルな分散コンピューティングに使用されるオープンソースプロジェクトであるHadoopです。
中小企業が研究や生産の目的でタスクの範囲を拡大したい場合、ビッグデータを使用するとデータが体系化されるだけでなく、処理速度も向上します。
神話5.すべてのデータを処理する必要があります。
この神話は、分散ファイルシステムからモデルを構築する必要がある場合によく見られます。 ソリューションプロバイダーは、「すべてのデータを処理する必要がある」と主張しています。 ここには矛盾があります。 処理された情報の量と作業の結果の間には相関関係はありません。 処理されたデータの量が増えても、最終モデルの精度の向上には影響しません。
数学計算に基づいた有名な理論は、モデルの割り当てのために特別に選択された小さなセグメントからモデルを構築するときに最良の結果が得られることを示しています。
数学の観点から見ると、各サンプルオブジェクトは、モデルトレーニングのランダムサブサンプルに陥る確率が等しくなります。 また、その精度は要素の数ではなく、サンプルの品質に依存します。 特定の調査に対する数千の回答から、結果全体の非常に正確な予測を構築することが判明しました。
多いほど良いというわけではありません。
ビッグデータの真の意味は、可能な限り多くのデータを処理することではなく、データ全体がセグメントに分割されてクラスターに分割されることを保証し、小さなクラスターに対して多数のモデルを構築することです。
神話6.ビッグデータは即座に魔法のような結果をもたらします。
この神話は、ビッグデータを使用し始めたばかりの企業では一般的です。 推奨を計算するだけでは十分ではありません。たとえば、どの製品を誰にターゲット設定するか、どの製品をどの製品とともに配信するかなどです。 実際の手配ができることが重要です。 多くのプロジェクトはこのステップで停止します。
ビッグデータには多くの作業が必要です。 これには、複雑なプロジェクトの作成、データの収集、インフラストラクチャの作成、モデルの設計、およびプロセスの改善に必要なデータの検索が含まれます。
主なタスクは、生産のビジネスプロセスにモデルを埋め込み、見つかったソリューションを有益に使用することです。
これは、ビッグデータに関する迷信や誤解のほんの一部です。 ビッグデータは魔法の杖ではありません。 これは、熟練したアナリストの手でビジネスプロセスを正しく構築するのに役立つツールです。
Netologyの編集者から
ビッグデータコースのNetologyリクルート:
誰のために:エンジニア、プログラマー、アナリスト、マーケティング担当者-ビッグデータテクノロジーを掘り下げ始めたばかりの人。
- 技術の歴史と基礎の紹介。
- ビッグデータを収集する方法。
- データ型;
- 基本的および高度なビッグデータ分析方法。
- 大規模なデータアレイを操作するためのプログラミング、ストレージ、および処理アーキテクチャの基礎。
クラス形式:オンライン。
詳細はリンクから→
http://netolo.gy/dAZ誰のために:ビッグデータで働いている、またはそれをしようとしているスペシャリスト、およびデータサイエンスの分野でキャリアを積むことを計画している人。 トレーニングには、少なくとも1つのプログラミング言語(できればPython)を知っていて、高校の数学(できれば大学)でプログラムを覚えておく必要があります。
コーストピック:- 基本的なツール、Hadoop、クラスターコンピューティングでトレーニングを表現します。
- 決定木、k最近傍法、ロジスティック回帰、クラスタリング。
- データの次元削減、分解方法、スペースの修正。
- 推奨システムの紹介。
- 画像認識、マシンビジョン、ニューラルネットワーク;
- ワープロ、配信セマンティクス、チャットボット。
- 時系列、ARMA / ARIMAモデル、複雑な予測モデル。
クラス形式:オフライン、モスクワ、デジタル10月センター。 Yandex Data Factory、Rostelecom、Sberbank-Technology、Microsoft、OWOX、Clever DATA、MTSの専門家が教えています。
詳細はリンクから→
netolo.gy/dA0