新しいApache ML Grid機械学習ライブラリの機能
Apache Ignite 2.0には、高度に最適化されたスケーラブルなApache Ignite Memory-Centric Platform APIに基づいたApache Ignite Machine Learning Grid(
ML Grid )のベータ版が含まれています。
ソース: xkcd新しいライブラリの能力とその使用方法については、私たちの話が途切れています。
リリース2.0では、ライブラリには主に、従来のデータ構造とスパースデータ構造の両方を使用した、ベクトルおよび行列代数のローカルおよび分散操作などの基本機能が含まれています。 データ自体は、通常のJVMメモリ、オフヒープメモリ、およびIgnite分散キャッシュに保存できます。
Apache Mahoutや
Coltなど、他の一般的な機械学習ライブラリを既に使用している人にとっては、多くのものがおなじみでしょう。 これは偶然ではありません。ApacheIgnite MLグリッドAPIの設計における目標の1つは、典型的な機械学習ライブラリに既に慣れている人にとっての使いやすさでした。
多くのユーザーは、ML Gridが登場する前であっても、Igniteを使用してマトリックスおよびベクトル演算を高速化しています。 Igniteを使用すると、計算グリッドとデータグリッドを共有して、スパースデータセットを非常に効率的に処理できます。 また、ML Gridの登場により、はるかに簡単になります。
次のリリースでは、ライブラリの機能、特に機械学習の問題を解決するために使用される一般的なアルゴリズムの分散バージョンの追加をさらに拡張する予定です。
リリース2.0の分散代数アルゴリズムに基づいて、Apache Igniteコミュニティは、分類、回帰分析、k-meansによるクラスター分析、決定木などをライブラリに追加することを計画しています。およびk-means)。
より遠い計画では、Ignite MLスタックの一部としてのPythonおよびRライブラリーの開発について説明します。
新しいモジュールによって提供される可能性はまだ控えめです。すでに述べたように、これは主に基本的な機能を備えたベータ版です。 そして、次のリリースを待たずに、今すぐ新しいAPIを使用する方法を学びたい場合は、ネタバレの下で-投稿の2番目の部分...
Ignite Apache 2.0でMLグリッドを操作する方法Ignite Apache 2.0でMLグリッドを操作する方法
おそらく、ML Gridを使い始めてML Gridを使い始める最も早い方法は、リリースに含まれているサンプルの実行結果とコードを収集、実行、および調査することです。 MLの例は、Apache Igniteディストリビューションの
examplesディレクトリにあります。
Githubのこのリンクからサンプルコードを取得することもできます。
サンプルを開始するためのステップバイステップの手順:
- 8以上のJavaバージョンをインストールします。
- Apache Ignite 2.0以降をダウンロードします。
- IDEでサンプルプロジェクトを開きます-たとえば、IntelliJ IDEAまたはEclipse。
- プロジェクト設定でMaven mlプロファイルをアクティブにします(Ignite 2.0ではデフォルトでオフになっています)。
- IDEでsrc / main / mlディレクトリを開き、以下で説明するようにMLグリッドの例を実行します。
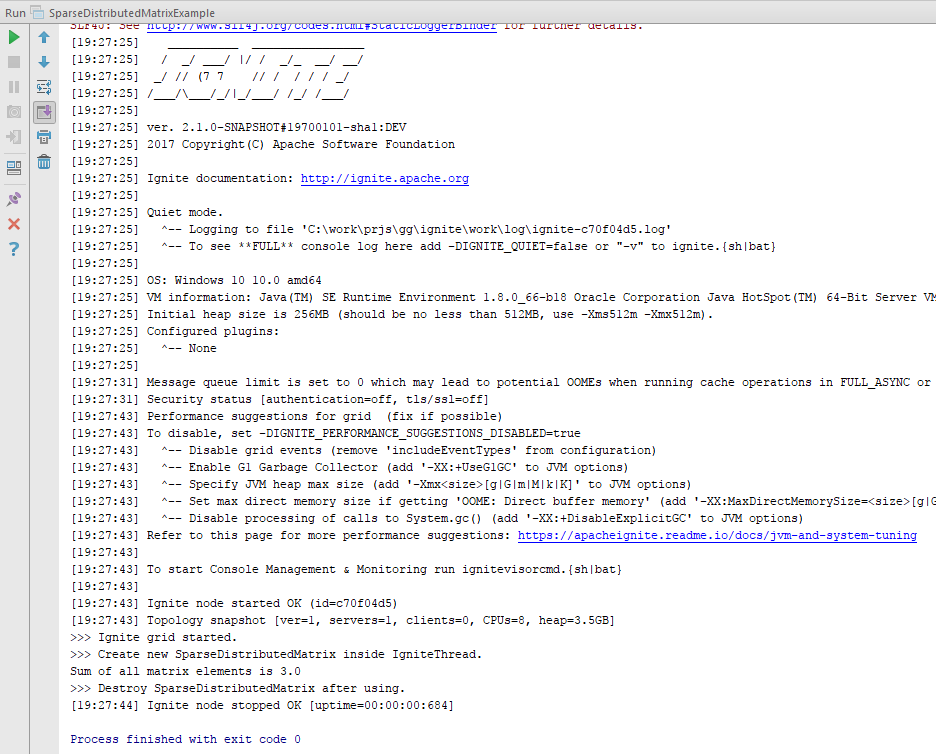
- 興味のあるサンプルを見つけて実行します。
(スクリーンショットのSparseDistributedMatrixExample ):

- 例の実行とコンソールへのデータの出力を確認します。
- TracerExampleの例を実行するとき、ブラウザに表示される内容に注意してください。

- 必要に応じて、サンプルコードを編集して再度実行し、変更の結果を確認します。
TracerExampleの例のコードが次のように変更された場合:
その後、実行されると、ブラウザにより効果的な出力が表示されます。
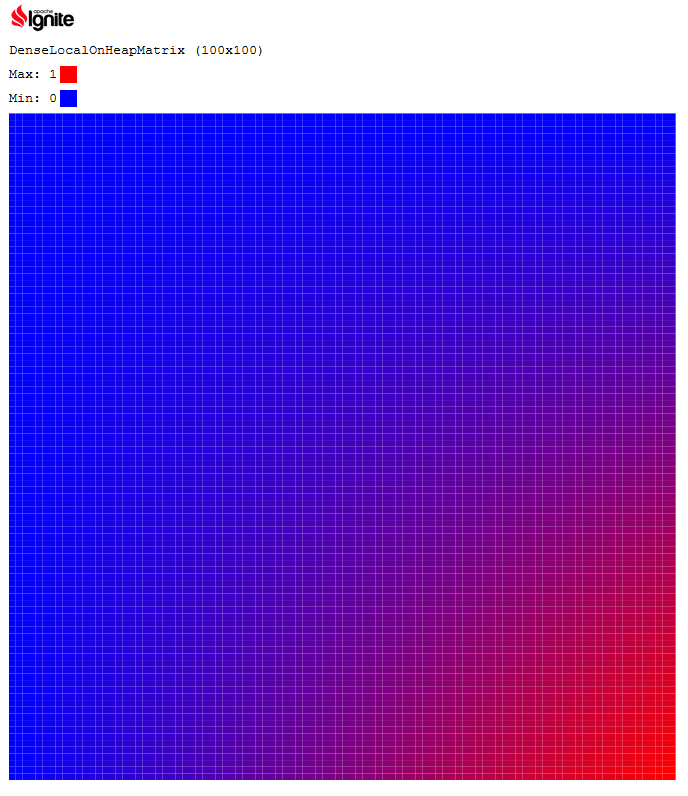
このようにして、Ignite MLで行列代数メソッドがどのように実装されるかについて、より実質的なアイデアを得ることができます。
この例では、サイズ100 x 100のマトリックスが最初に作成され、次にその要素に垂直インデックスと水平インデックスの積に比例する値が入力されます。 最後に、 トレーサーAPIを使用して、マトリックスがHTMLでレンダリングされます。
MLグリッドの例では、特別な構成は必要ありません。 それらはすべて単純に開始、実行、停止でき、ユーザーの介入なしに結果が自動的にコンソールに表示されます。 上記に加えて、
トレーサAPIの例を実行すると、ブラウザが起動され、結果のHTMLが追加で表示されます。
また、javadocsには、ML Gridクラスおよびメソッドの使用に関するドキュメントがあります。
ソースコードビルド
最新のApache Ignite MLグリッドのjarビルドは、Mavenリポジトリで入手できます。 ソースコードからライブラリを自分でビルドすることもできます。
- Apache Igniteの最新ソースバージョンをダウンロードします。
- 必要に応じて、ローカルのMavenリポジトリーを空にして、以前のビルドの影響を排除します。
- Javaのバージョンが少なくとも8であることを確認してください。
- プロジェクトのルートディレクトリからApache Ignite Memory-Centric Platformをビルドしてインストールします。
mvn clean install -DskipTests -Dmaven.javadoc.skip = true -P java8
- プロジェクトルートディレクトリからMLグリッドをビルドしてインストールします。
mvn install -Pml -DskipTests -U -pl modules / ml -am
- ローカルのMavenリポジトリーでML Grid jarアセンブリーを見つけます。
{user_dir} /。m2 / repository / org / apache / ignite / ignite-ml / {ignite-version} / ignite-ml- {ignite-version} .jar
- ソースコードからMLグリッドの例を収集する必要がある場合は、プロジェクトのルートディレクトリから次のコマンドを実行します。
cd examples mvn clean package -DskipTests -Pml
必要に応じて、プロジェクトのルートディレクトリにある
DEVNOTES.txtファイルと
ignite-ml MLコンポーネント
ディレクトリにある READMEの追加ドキュメントを参照できます。