私は黙示録、エイリアン、サル、ターミネーターがどのように私たちの惑星を奴隷にするかについての物語が大好きです。そして、幼少の頃から人類の最後の日をもっと近づけることを夢見ていました。
ただし、空飛ぶ円盤を構築する方法やウイルスを合成する方法はわかりません。そのため、ターミネーター、より具体的にはこれらの勤勉な労働者がジョンコナーを見つけるのに役立つ方法について説明します。
私の縫製ターミネーターはいくらか単純化されます-彼は歩くことができず、撃つこともできません。 彼ができる唯一のことは、コナーの声が聞こえればそれを認識することです(まあ、たとえば、チャーチルも見つける必要があるなら)。
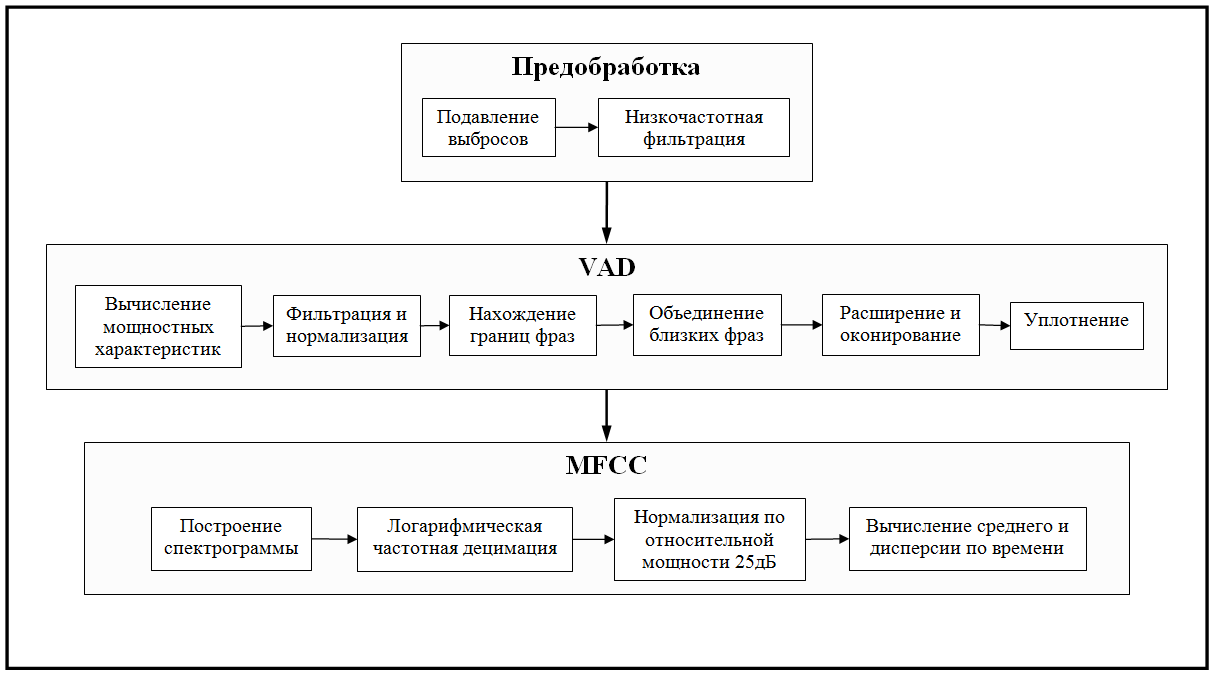
一般的なスキーム
認識システムは、登録モードと識別モードの2つのモードで機能します。 言い換えれば、音声の例を持っている必要があります。
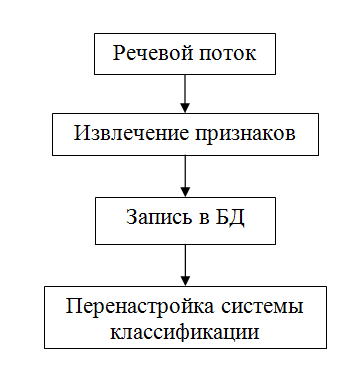
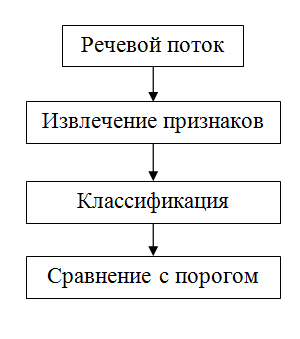
上の写真は、各モードでのシステムの一般的なスキームを示しています。 ご覧のとおり、これらのモードは非常に似ています。 仕事のために、音声オーディオストリームをキャプチャし、その主な機能を計算する必要があります。 違いは、これらの兆候をどうするかです。 何らかの方法でそれらを登録するとき、将来の使用のために何らかの形で覚えておく必要があります。 結局のところ、生の生データよりも主な機能を使用する方がはるかに効率的です。 この段階のシステムにはフィードバックがなく、音声を確実に認識できないため、識別中は何も保存できません。
分類子
「サイン」とは何ですか? 実際、これは話者を特徴付ける一連の数字、つまり多次元空間のベクトルにすぎません。 そして、分類器のタスクは、この多次元空間を実数の空間にマッピングするための関数を構築することです。 言い換えれば、彼の仕事は、類似性の尺度を特徴付ける数値を取得することです。
- ユークリッド ユークリッド距離
- SVM 分割超平面
- MLP
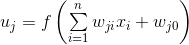 非線形関数のネットワーク
非線形関数のネットワーク
実験
バイナリ分類
バイナリ分類では、話者の性別認識問題が選択されました。 したがって、3つの明確に定義された可能な結果のみがあります。男性の声、女性の声、不明です。
2つのシリーズの実験が行われました。 最初のケースでは、システムが構成された同じデータに対して検証が実行されました。 2番目のケースでは、システムにデータがない人の音声録音でテストが実行され、メソッドの一般化の能力がテストされました。
ユークリッド
この場合、男性と女性の音声の特徴ベクトルの平均値が計算され、その後、各平均とテスト音声のユークリッド距離が見つかり、それに基づいて選択が行われました。
しきい値を計算するために、グループ内およびグループ間の距離の平均値が見つかりました。その後、統一への正規化が行われました。

しきい値に対する正の値は、女性の声の分類です。 マイナス-男性。
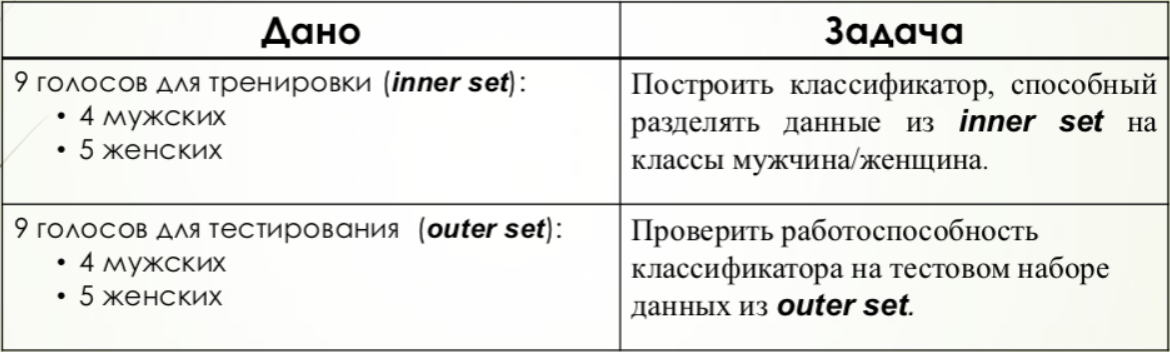
SVM
この方法では、正の値が女性の声に対応するバイナリ値を含む配列が作成されました。 このバイナリ配列は、トレーニング属性のマトリックスとともにアルゴリズムの入力に送られ、その後テストが行われました。
この場合、すべての正の結果が1つのクラスに対応し、負のクラス-別のクラスに対応する必要があるため、しきい値は0です。 ただし、他の方法との比較を改善するために、結果は2倍に圧縮され、0.5シフトされました。
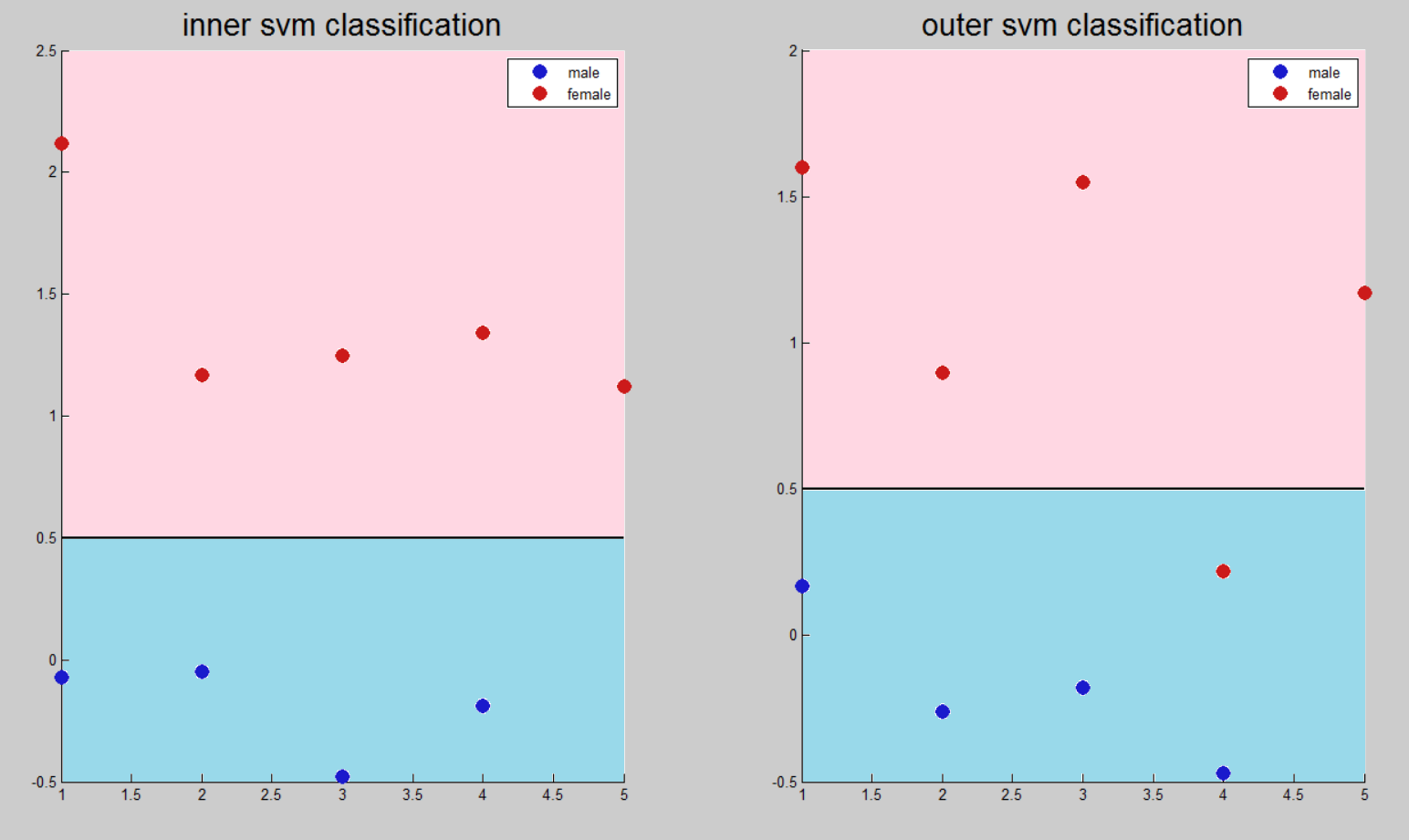
MLP
多層パーセプトロンのタスクは、バイナリ分類ではなく関数を近似することです。 この点で、分割しきい値はありませんが、ニューラルネットワークが結果を生成する理想値に近い間隔があります。
女性の声の兆候のベクトルを調整するとき、値1は男性の声に対応して設定されました-0。
認証タスク
アルゴリズムを一般化する可能性をテストするために、元のセットに対応しないセットでテストを追加で実行しました。
元のテーブルには9列と9行があります。これは、検証がそれぞれの原則に従って行われたためであり、元のセットにはわずか9人のサンプルが含まれています。 一般化されたテーブルには9列と8行があります。これは、テストセットには元のセットと異なる人が8人しかいないためです。
ユークリッド
「トレーニング済み」セットによる分類。 このアルゴリズムでは、トレーニング自体が行われないため、「学習セット」の概念は適用されません。 クラス内およびクラス間の距離と正規化の距離の平均値が計算されます。最初のケースには値1が割り当てられ、それ以外の場合は-0が割り当てられます。
その結果、認証マトリックスには、理想的には主対角線上のユニットと他のすべてのセルのゼロを含める必要があります。
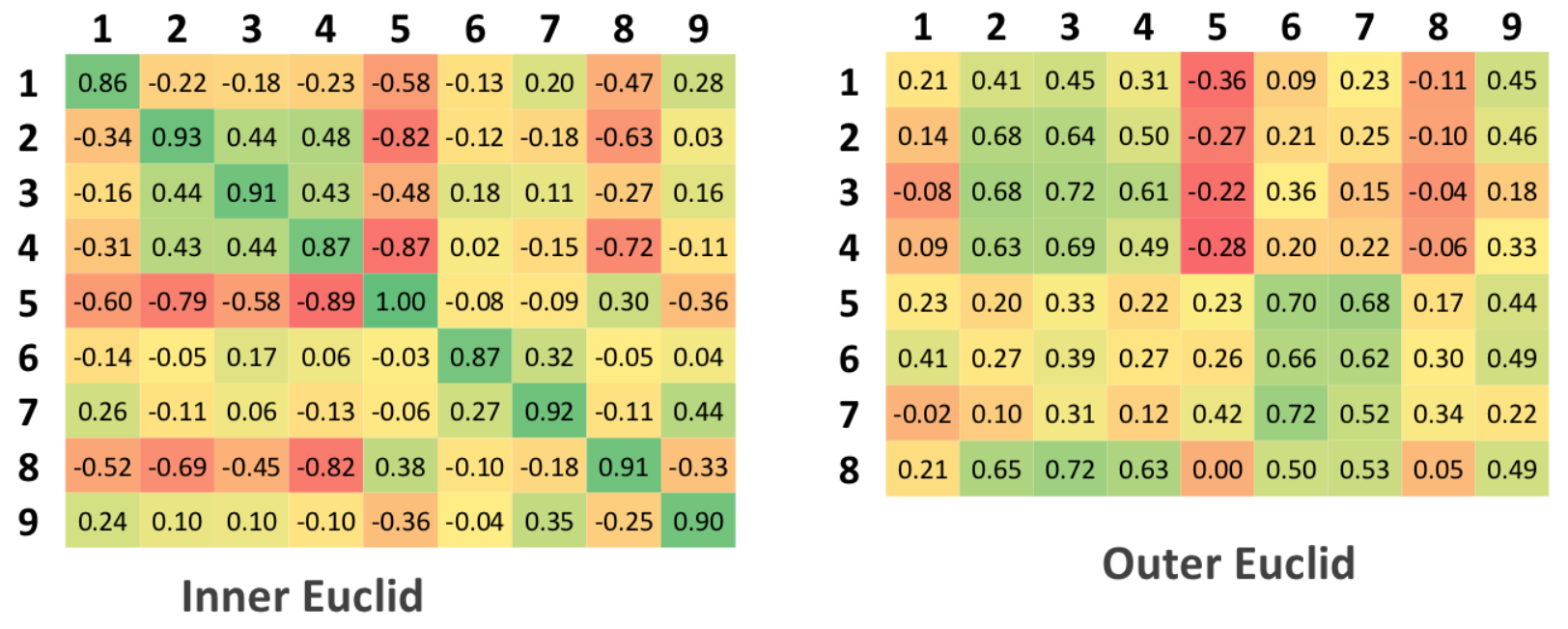
テスト中のマトリックスの場合、理想的には、認証マトリックスの主対角にある値よりも大きい値はないはずです。これは、アルゴリズムが元のデータとテストされたデータの間の不一致を検出できたという事実に対応します
SVM
サポートベクターマシンはマルチクラス分類ではなくバイナリの問題を解決するため、9人の異なるSVMが認証問題用にコンパイルされ、それぞれが特定の個人用に構成され、残りはネガティブと見なされます
分類の例。
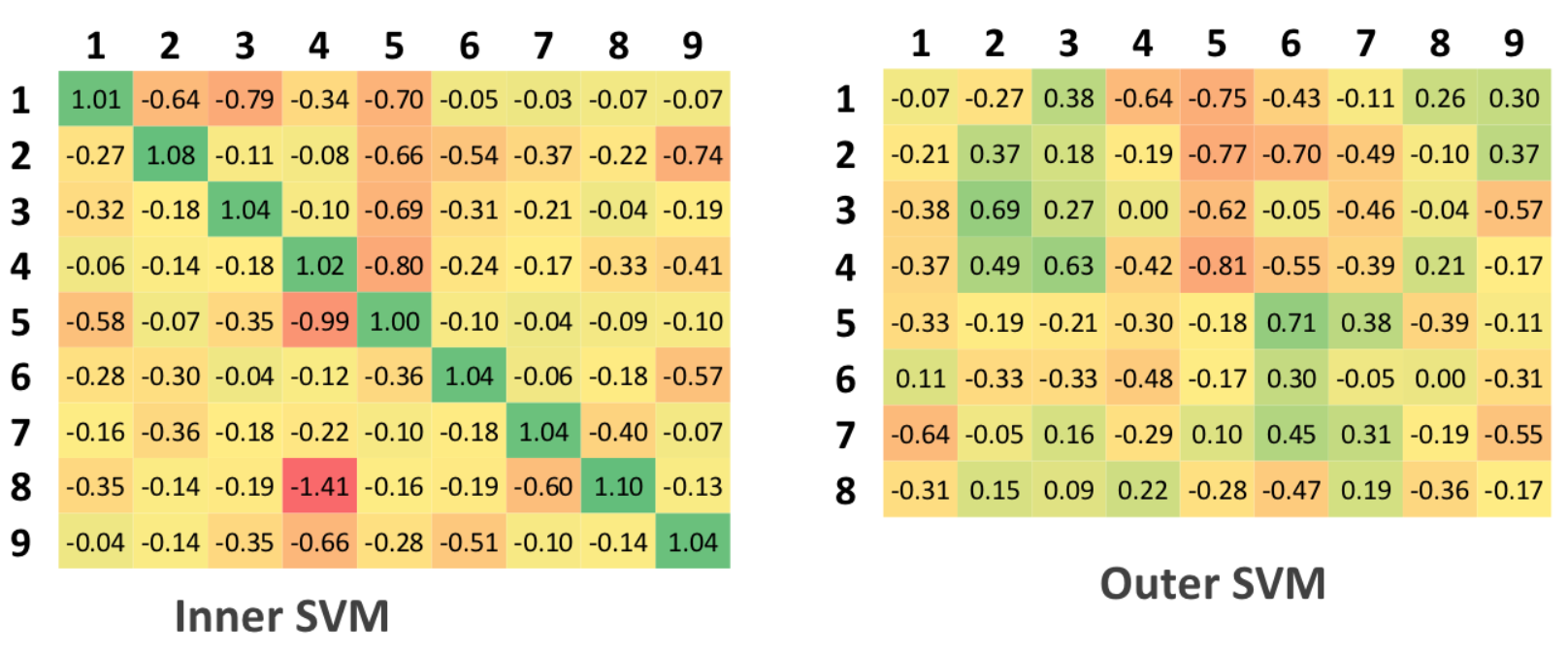
SVMのこれらのテーブルの解釈は、ユークリッドアルゴリズムのテーブルに似ています。 0.5はしきい値です。
MLP
多層パーセプトロンを使用するために、セットアップ段階でシステム出力値として9次元ベクトルが提供されました。 この場合、出力の各入力特徴ベクトルについて、MLPは分類問題の原因となる9つの関数の値を近似しました。
バイナリ分類の場合については、入力ベクトルのクラスを一意に分類するしきい値はありませんが、理想値に近い一定の間隔があります。 間隔からの出口は、特定のレベルの信頼区間でネットワークが明確な答えを出すことができないことを示します。
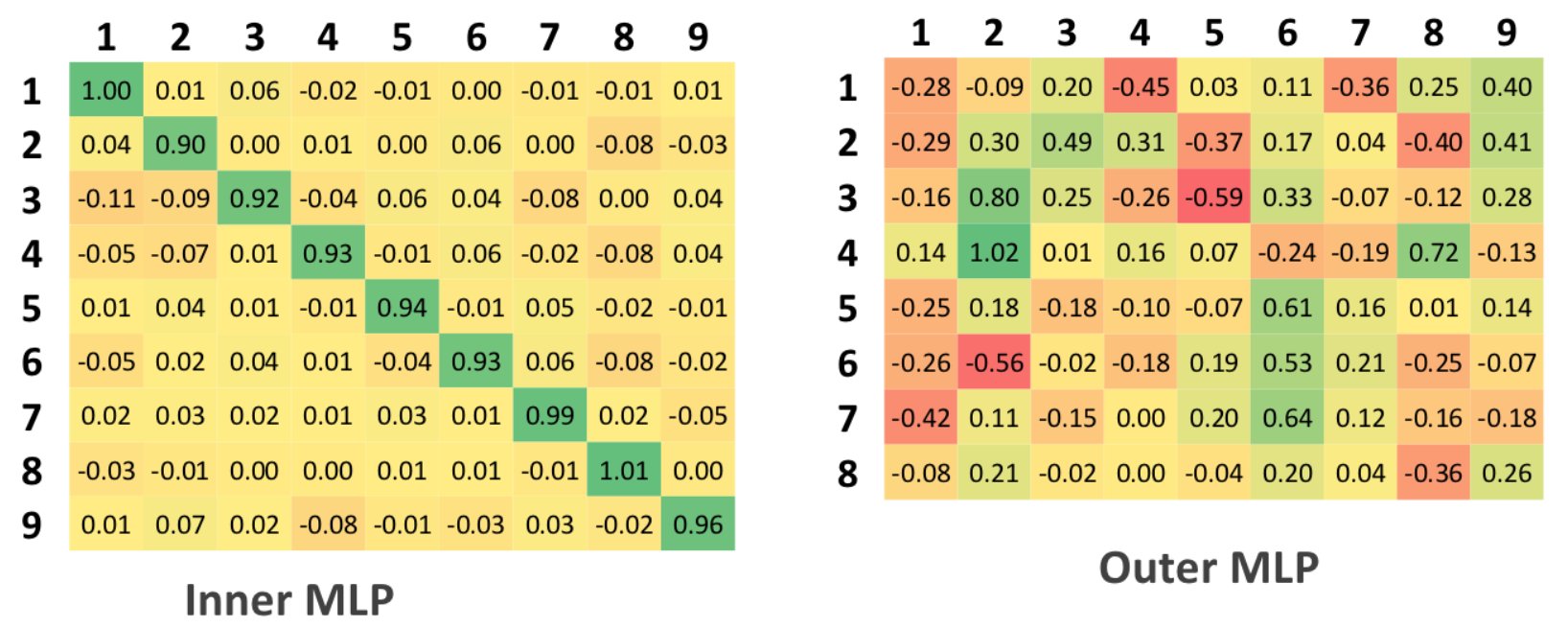
さらに、信頼区間は0.5を超えることはできません。これは、理想的な分類値間の値の半分に等しい値であるためです。
分類方法の比較
実験中に得られた最も注目すべき結果は、ユークリッド法による低レベルの精度と、多層パーセプトロンをチューニングするための非常に高い計算コストです:MLPチューニング期間は、同じデータセットでSVMチューニング期間を数百回超えました。
バイナリ分類の結果は、すべての方法で誤って分類されたTanya Ebyの声を除き、テストセット全体で3つの方法すべてが定性的に実行されたことを示しています。 この結果は、この女性の無礼な声で説明できます。
判明したように、ニューラルネットワークシステムのマルチクラス分類問題のソリューションは、「内部」認証と「外部」認証の場合で著しく異なります。 最初のケースで両方のニューラルネットワーク方法が問題に対処した場合、2番目のケースでは両方とも多くの誤った分類を行いました。
識別システムの2つの主な特徴として、 第1種と第2種のエラーを受け入れることができます。 レーダーの理論では、それらは通常「誤警報」または「目標を逃す」と呼ばれ、識別システムで最も確立された概念はFAR(False Acceptance Rate)およびFRR(False Rejection Rate)です。 最初の数字は、2人のバイオメトリック特性が誤って一致する確率を特徴付けます。 2番目は、許可された人物へのアクセス拒否の確率です。 システムが優れているほど、同じFAR値のFRR値は低くなります。
以下は、認証タスク用に作成したシステムのFAR / FRRグラフです。
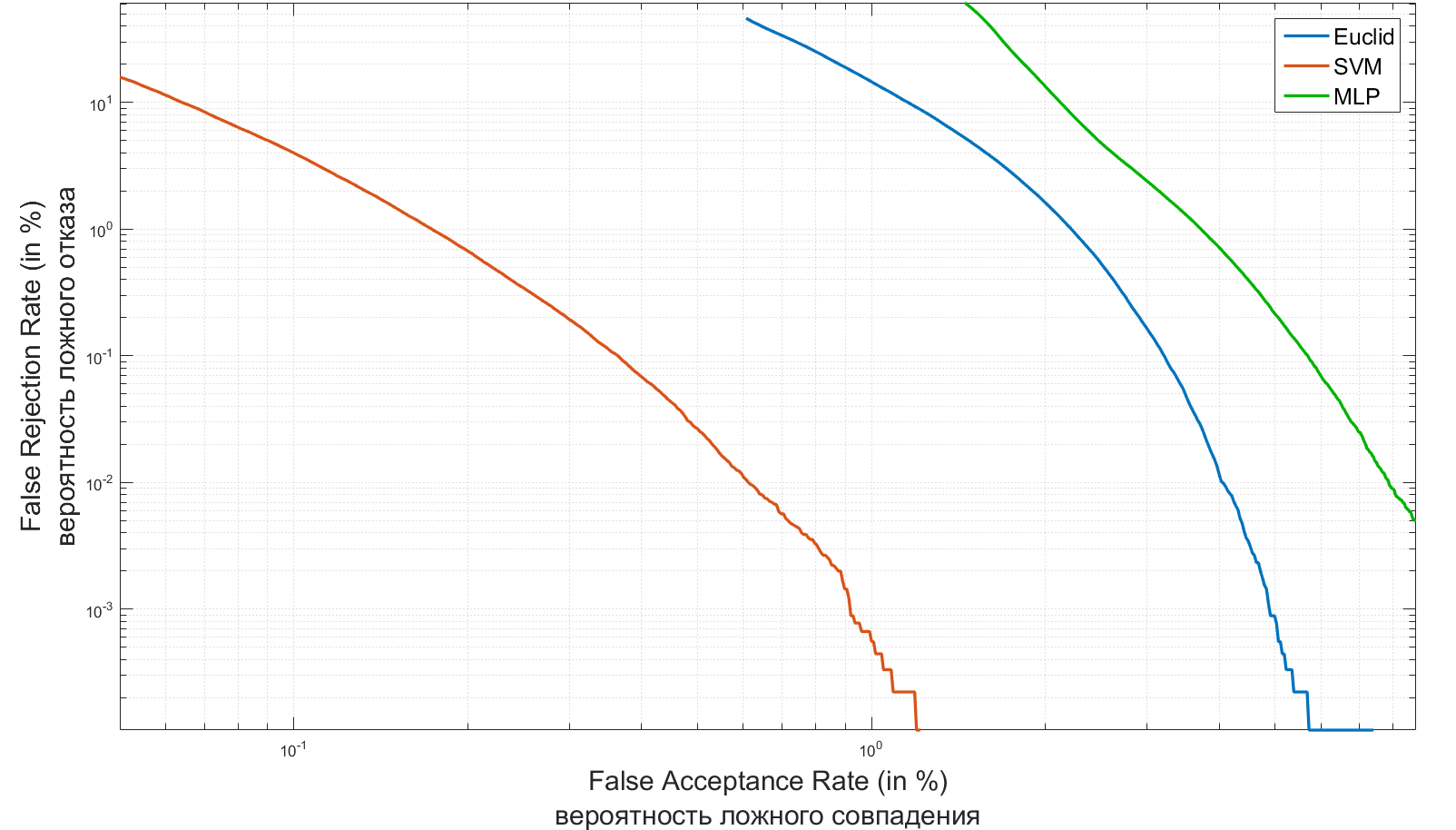
生体認証システムの概要とFAR / FRR値の評価については、 こちらをご覧ください 。
ユークリッド :
- 最速かつ最も簡単なアルゴリズム
- ズーム劣化
- 低品質の分類
SVM :
- 最高の汎化能力
- トレーニング段階で小さなコンピューティングリソースが必要
- N個の異なるSVMを作成する必要性
MLP :
- 最小の学習エラー
- 分類概念の欠如
- トレーニング段階でコンピューティングリソースを要求する
- 新しいスピーカーを登録するときにシステム全体を再トレーニングする必要がある
サウンドキャッチャー
システムは、すべてのオーディオ情報をオーディオストリーム配列と量子化周波数値の形式で受け取ります。
配列は、 mp3、flac、wav、またはその他の形式のファイルから読み取ることで形成され、必要なフラグメントが切り出され、1つのトラックで平均され、定数成分が減算されます。
オーディオストリーミングfilename = 'sample/Irina.mp3'; [x, fs] = audioread(filename);
特徴抽出
前処理
私たちのターミネーターは、予算がかかりますが、デジタル処理なしでは彼もできません。 事前フィルタリングのタスクは、さらなる処理のアルゴリズムに最も影響を与えるオーディオ録音のノイズ特性を取り除くことでした。 これらの特性は、「放射」と「低周波」ノイズを選択しました。
排出量
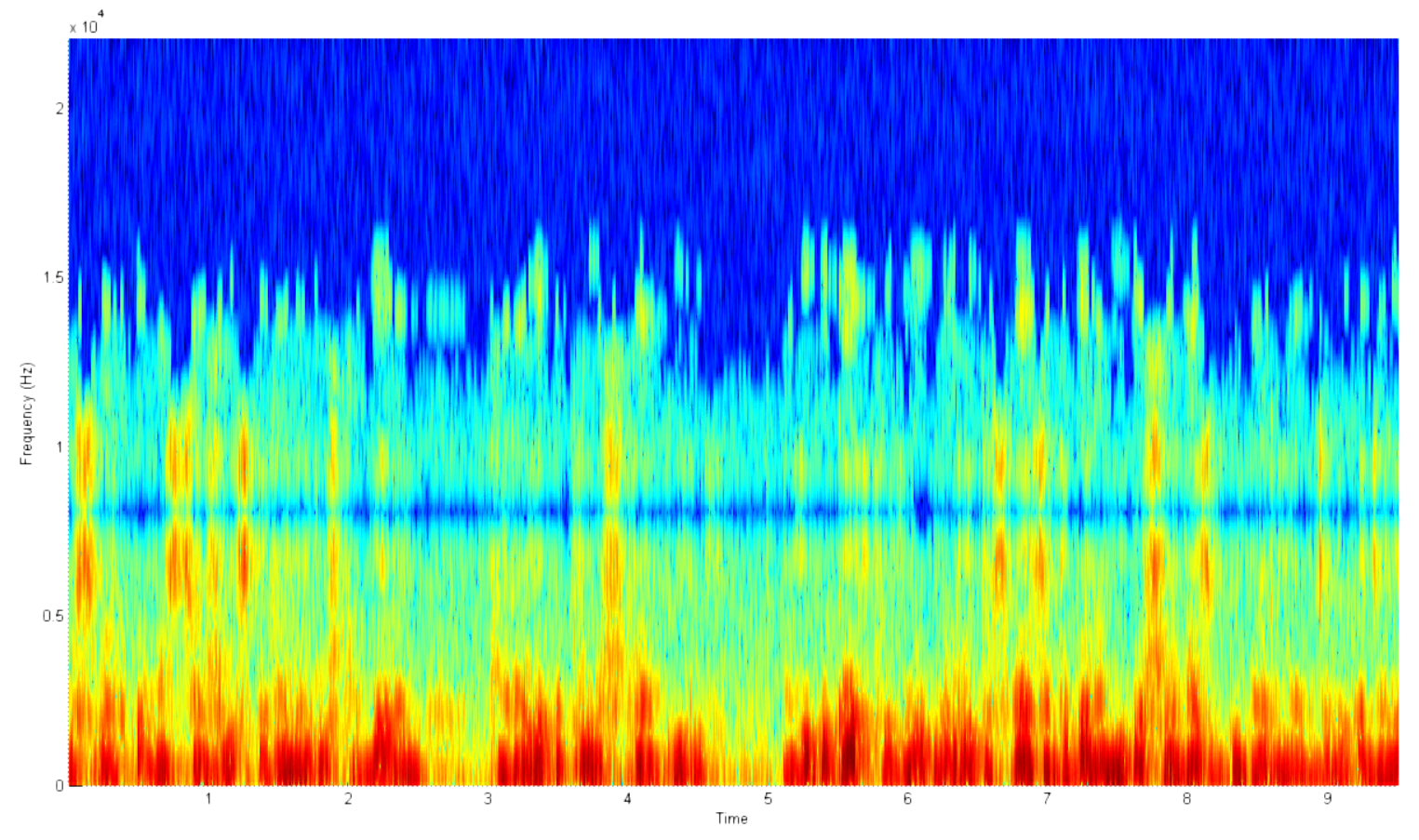
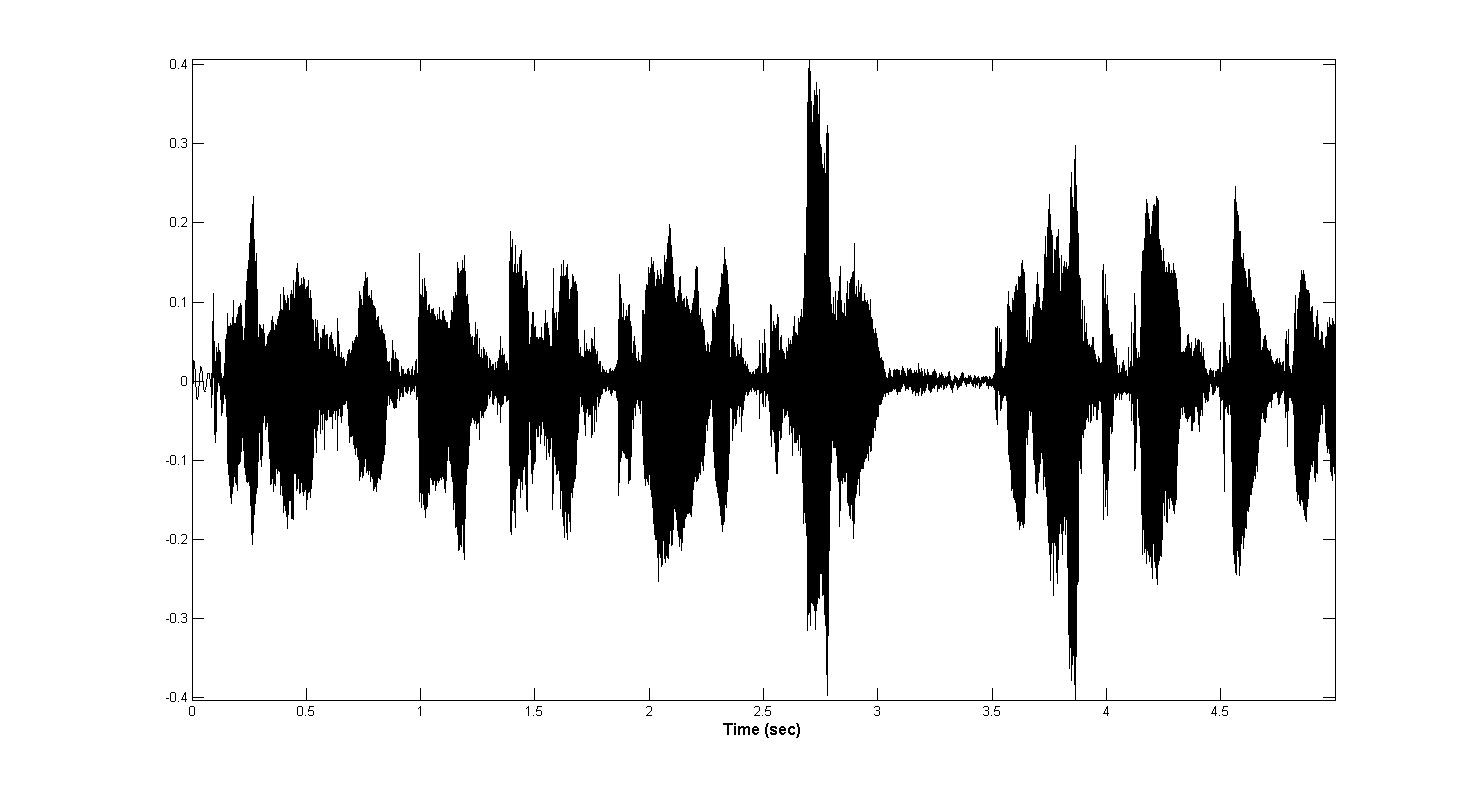
音声を録音したマイクの品質は非常に異なっていました。 貧弱な録音機器は、短期間の電力放出をもたらしました。 これらのノイズ現象は、音声アクティビティを見つけるためのアルゴリズムに大きな困難をもたらします。 このような「排出」の例を下の図に示します。
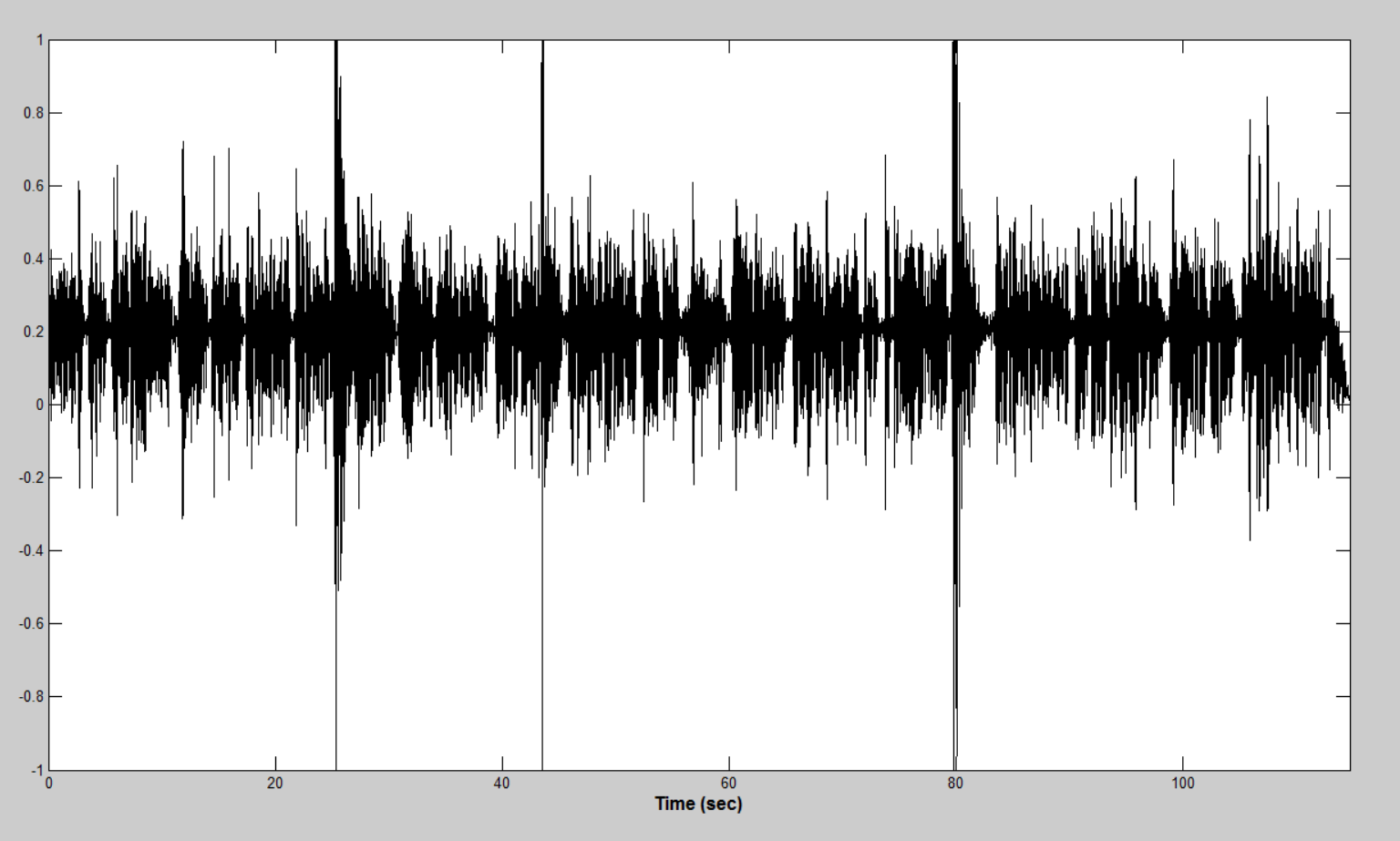
アルゴリズムのアイデアは、短いセクションのエネルギーを連続的に計算し、平均エネルギー値と比較し、セクションのエネルギーが平均値を超える場合に反転Tukeyウィンドウを掛けることで抑制することです。
いくつかのしきい値。 よりスムーズなフィルタリングと正確な検出のために、オーディオファイルの中間セクションが重複して選択されました。
外れ値関数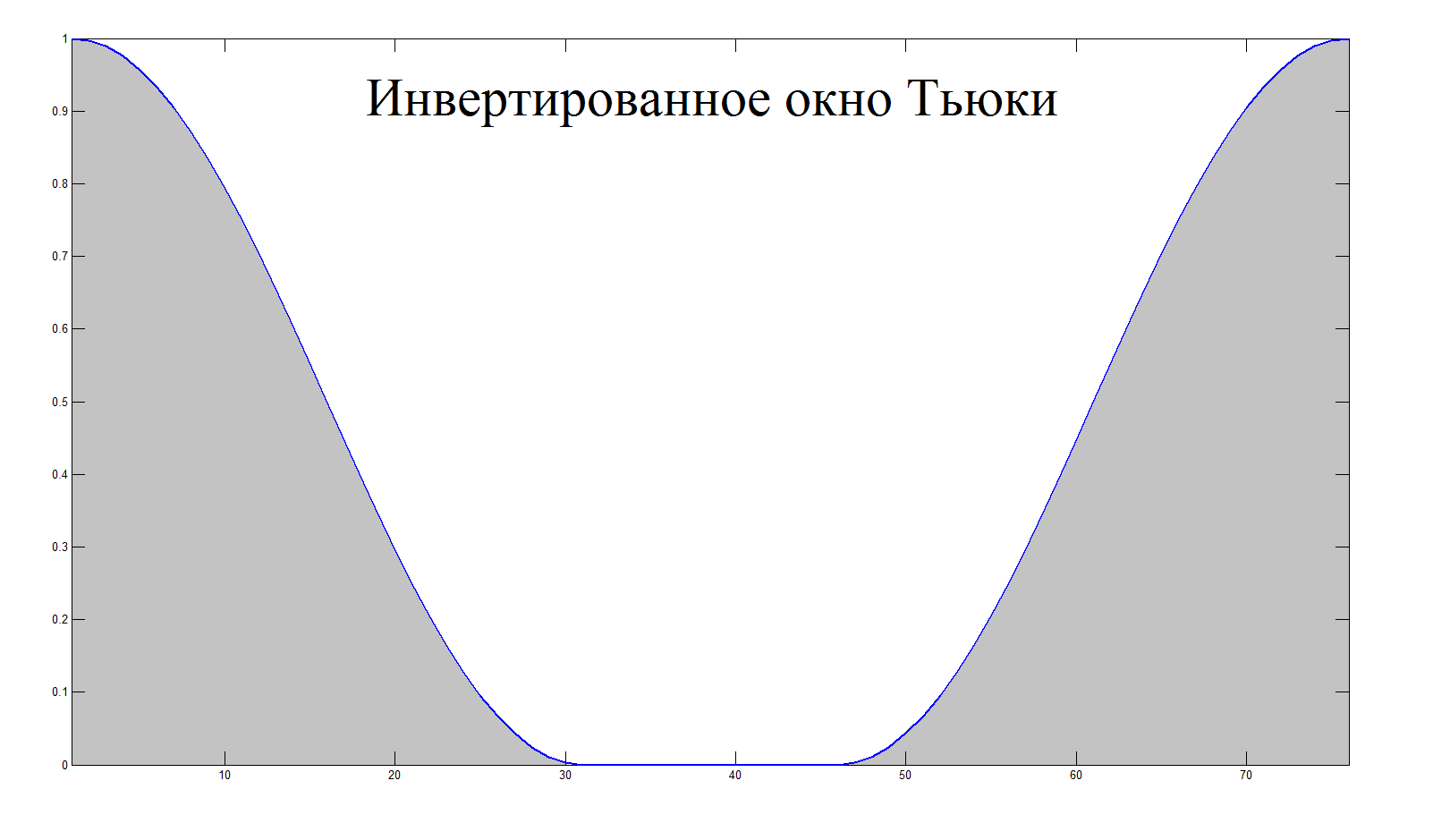
function [ y ] = outlier_suppression( x, fs ) buffer_duration = 0.1; % in seconds accumulation_time = 3; % in seconds overlap = 50; % in percent outlier_threshold = 7; buffer_size = round( ((1 + 2*(overlap / 100))*buffer_duration) * fs); sample_size = round(buffer_duration * fs); y = x; cumm_power = 0; amount_iteration = floor(length(y) / sample_size); for iter = 1 : amount_iteration start_index = (iter - 1) * sample_size; start_index = max(round(start_index - (overlap / 100)*sample_size), 1); end_index = min(start_index + buffer_size, length(x)); buffer = y(start_index : end_index); power = norm(buffer); if ((accumulation_time/buffer_duration < iter) && ((outlier_threshold*cumm_power/iter) < power)) buffer = buffer .* (1 - tukeywin(end_index - start_index + 1, 0.8)); y(start_index : end_index) = buffer; cumm_power = cumm_power + (cumm_power/iter); continue end cumm_power = cumm_power + power; end end
処理後、上記のサンプルは次のようになります。
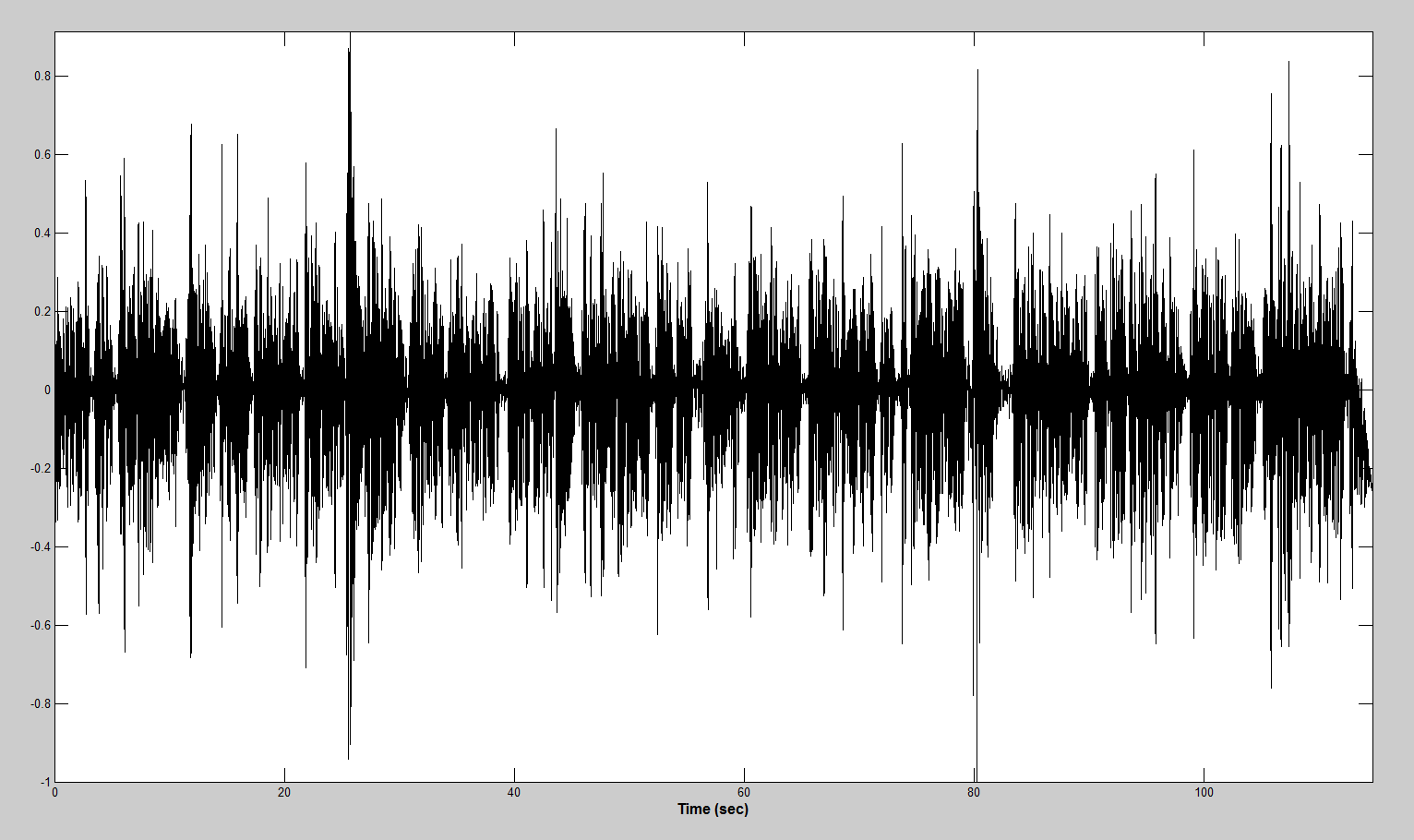
低周波ノイズ
低周波の高調波は、一定のエネルギー成分を短時間で生成するという点で危険であり、必要な対策を講じないと音声アクティビティとして誤って認識される可能性があります。
このようなコンポーネントを取り除くために、30 Hzのカットオフ周波数を持ち、遅延帯域で20 dBの抑制を提供する楕円形の3次HPFが選択されました。 楕円フィルターの選択は、通過フィルターとホールドバンドの間の遷移ゾーンでの周波数応答の減衰が(バターワースフィルターとチェビシェフフィルターに比べて)急勾配になるためです。 これに対する代償は、通過帯域と遮断帯域の両方に均一な周波数応答の脈動が存在することです。
以下は、それぞれフィルタリングの前後の信号です。

音声アクティビティ検出
音声アクティビティの一時的なセクションを識別するために開発したシステムは、信号とノイズの電力特性のみに基づいています。 ある意味では、これは、標準の単純な計算とスペクトル時間行列の複雑な処理との間の妥協になりました。 ボーナスは、配列の次元の急激な減少(数千回)でした。これは、データへのアクセスの強度を考えると、非常に有用であることが判明しました。
電力特性の計算
信号とノイズの電力特性として、次の式が使用されました。

電力計算機能 function [ signal_power_array, noise_power_array ] = compute_power_arrays(x,fs) buffer_duration = 10 * 10^(-3); % in seconds overlap = 50; % in percent sample_size = round(buffer_duration * fs); buffer_size = round( ((1 + 2*(overlap / 100))*buffer_duration) * fs); signal_power_array = zeros(floor(length(x) / sample_size), 1); noise_power_array = zeros(length(signal_power_array), 1); for iter = 1 : length(signal_power_array) start_index = (iter - 1) * sample_size; start_index = max(round(start_index - (overlap / 100)*sample_size), 1); end_index = min(start_index + buffer_size, length(x)); buffer = x(start_index : end_index); signal_power_array(iter) = norm(buffer); noise_power_array(iter) = norm(abs(diff(sign(buffer)))); end end
パフォーマンスの平滑化と正規化結果のパワー配列はフィルタリングされ、0から1に正規化されます
信号の電力値は、一定の値の加法性ノイズエネルギーによってバイアスされる可能性があるため、一定の成分を計算して減算する必要があります。 これはbase_value()関数で行われます。
function [ value ] = base_value( array ) [nelem, centres] = hist(array, 100); [~, index_max] = max(nelem); value = centres(index_max); end
フレーズの境界を見つける
フレーズの境界を見つけるために、信号パワーの配列が両方向に渡されます。 いずれの場合も、エネルギーの減少が求められ、配列は2方向に通過するため、フレーズの開始と終了の両方が見つかります。
フレーズ結合
多くの場合、計算されたフレーズの期間は100ミリ秒未満です。 これに関して、短い間隔の短いフレーズを1つに結合するアルゴリズムが開発されました。 このために、隣接するセクションのエネルギーが比較され、それらが設定されたしきい値よりも小さい場合、これらのセクションが結合されます。 同時に、結合されたフレーズのエネルギーは、それぞれの期間とパワーに比例して再計算されました。
しきい値との比較、アクティビティ識別子の作成、同じクラスの隣接セクションの結合。 活動期間と落ち着きの間のスムーズな移行のために、フレーズは各方向に50ミリ秒拡張されます(可能な場合)。 この前に、インデックスを時間間隔と比較するために、パワーアレイインデックスがオーディオストリームインデックスに再計算されます。
音声アクティビティのすべての領域が検出され、各フレーズの開始インデックスと終了インデックスが計算された後、アクティビティセクションの完全なオーディオ信号を含む配列が作成されます。 これらのセクションにKaiserウィンドウ関数を掛けて、スペクトルの広がりを減らします。 変曲値が小さいため、カイザーウィンドウが選択されます。
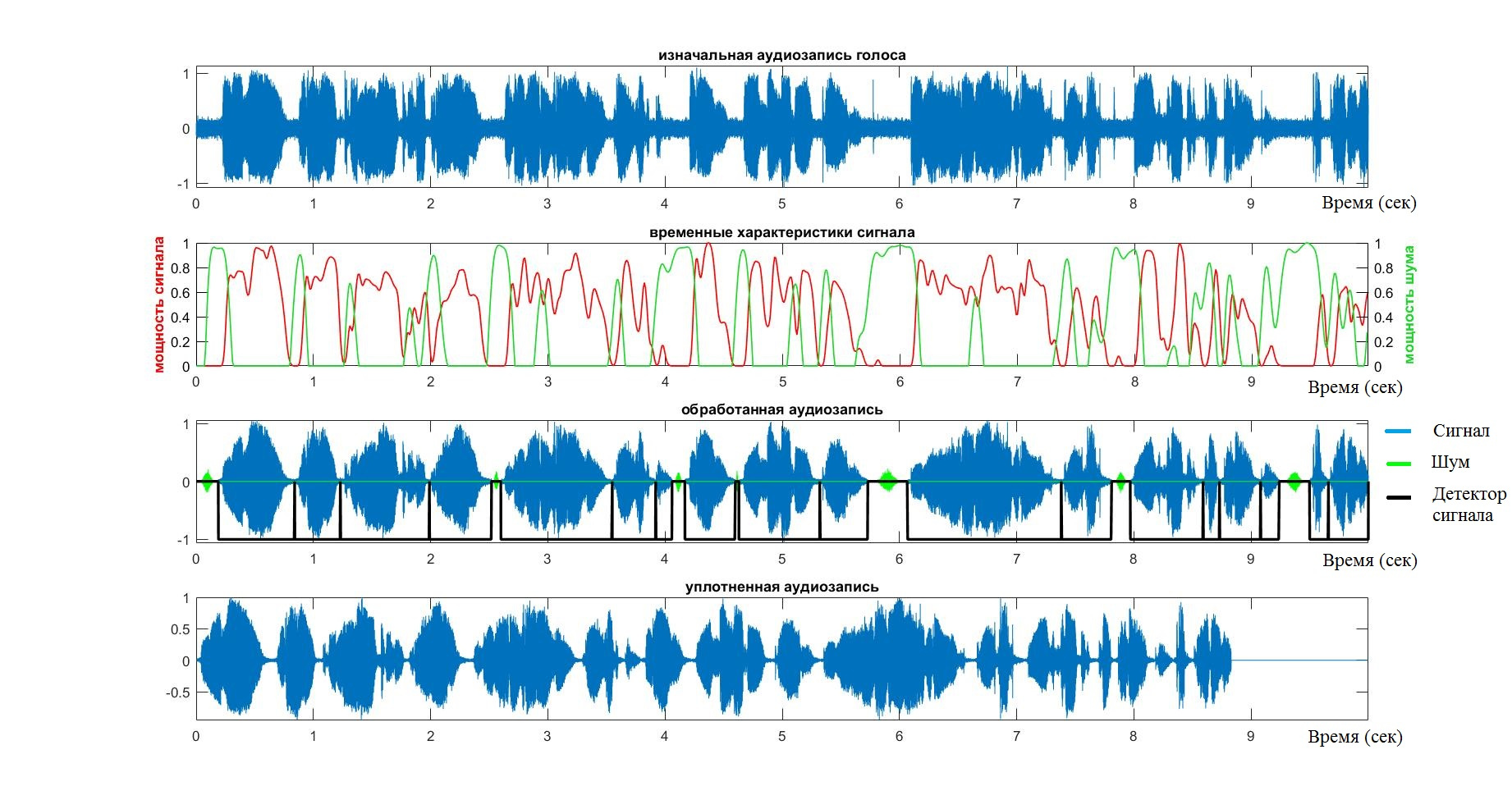
これに関して、VADシステムの作業は完了したと見なすことができます。 出力には、音声信号のみを含む配列があります。 アルゴリズムの操作の段階をもう一度検討し、その作業の妥当性を検証するために、次のチャートに注意する価値があります。
- オーディオストリームは青色でマークされています。
- 赤色-音声信号の力
- 緑-ノイズに関連するすべて
テスト中
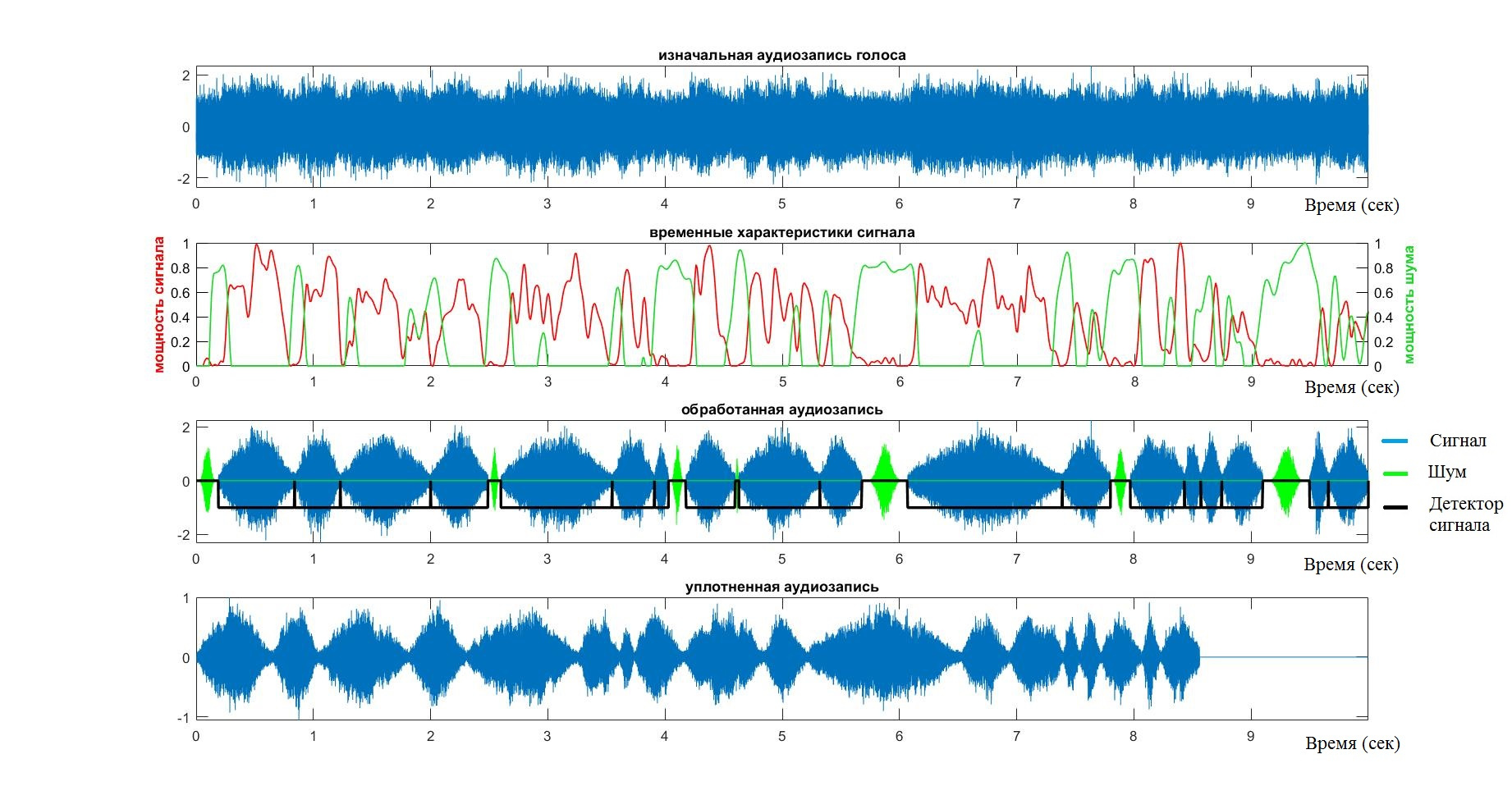
VADシステムの有効性、精度、安定性を確認するために、システムはさまざまな人々の約20のオーディオ録音でテストされました。 すべての場合において、テストは目と「耳」で行われました。グラフを見て、圧縮された信号を聞きました。 間違いは言葉の欠落、または逆に落ち着いた時期の採用と考えられていました。
アルゴリズムが単純なケースのタスクに対応していることを確認した後、背景にさまざまなノイズを追加し始めました。
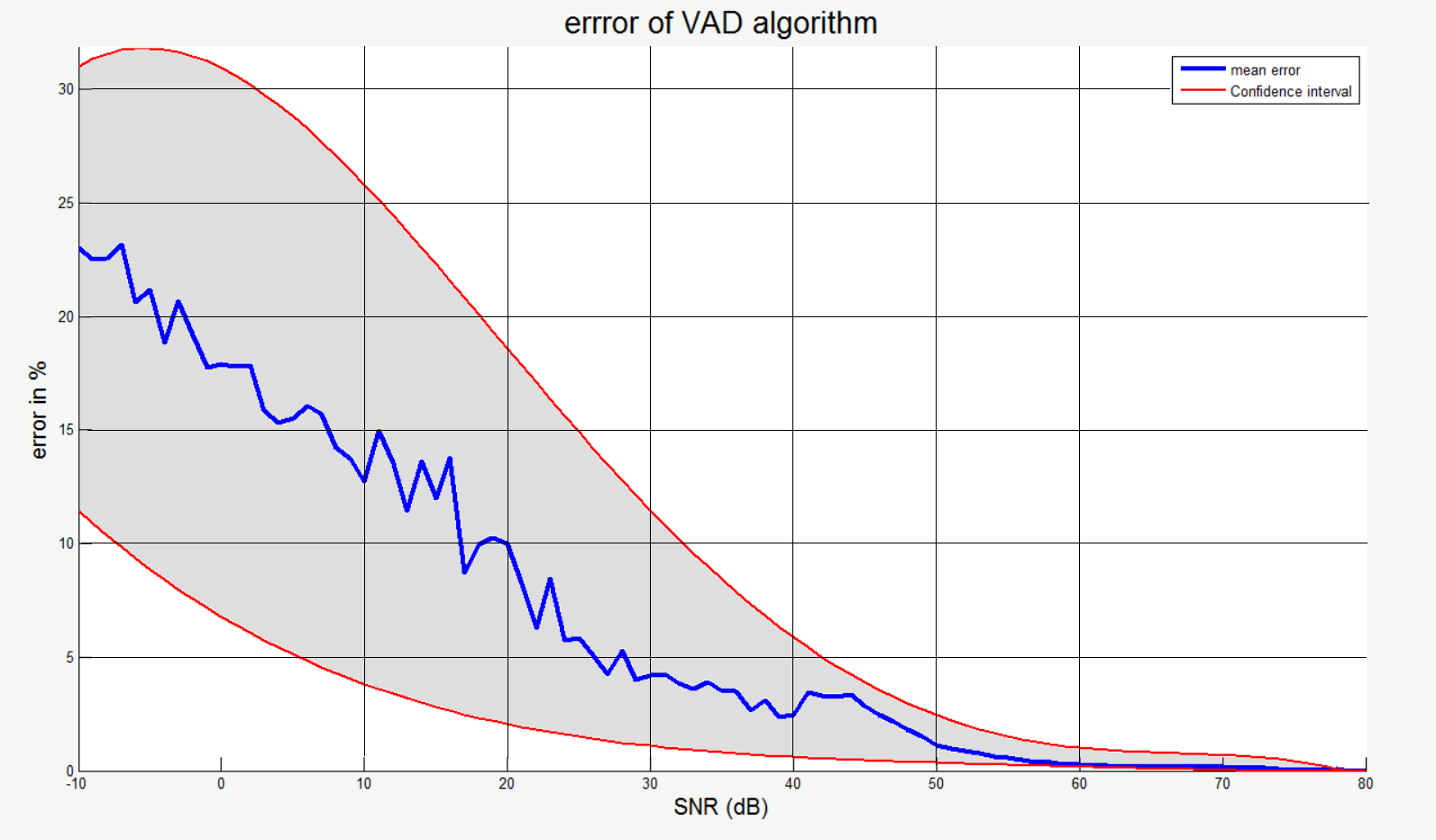
この場合、アルゴリズムがサイレントケースで機能することを確認して、それを参照として使用し、参照インデックスとテストセット間のハミング距離を見つけました。 したがって、大きな参照セットとテストセットを受け取ったので、 SNRに応じて(ハミングによる)アルゴリズムエラーの統計グラフを作成しました。 ここで、青い線は平均値を示し、赤い線は信頼区間の境界を示します。
Mfcc
正直に言うと、ここにはMFCCはありません。 MFCCの目標と手段は私のものと同じなので、この用語を使用します。 これに加えて、この用語は確立されており、その省略形は4文字のみです。 メインMFCCメソッドとの違いは、この場合、計算効率の理由から時間領域への逆変換が使用されず、チョーク畳み込みの代わりに対数間引きが使用されることです。
MFCCについては 、 こちら 、 こちら 、 こちら 、またはこちらをご覧ください 。
スペクトルの対数間引き
対数間引きの問題では、最初と最後の要素が1と最大周波数に等しい少数の点から配列が作成されましたが、すべての内部点は指数関数の結果です。 したがって、作成された配列からサンプリングするポイントを選択し、元の関数の値を平均すると、より小さな次元の配列がポイント間に割り当てられました。
アイデアは、元のスペクトルのインデックス空間全体に値が対数的に分布するインデックスの配列を作成することです。
function [ index_space ] = log_index_space( amount_point, input_length, decimation_speed ) index_space = exp(((0:(amount_point-1))./(amount_point-1)).*decimation_speed); index_space = index_space - index_space(1); index_space = index_space ./ index_space(end); index_space = round((input_length - 1) .* index_space + 1); end
インデックスの配列をコンパイルした後、残っているのは初期スペクトルの必要なポイントを選択し、ポイント間の平均エネルギーを蓄積することだけです。
スペクトル間引き function [ y ] = decimation_spectrum( freq_signal, index_space ) y = zeros(size(index_space)); min_value = min(freq_signal); freq_local = freq_signal - min_value; for iter = 2 : (length(index_space)-1) index_frame = index_space(iter - 1) : index_space(iter + 1); frame = freq_local(index_frame); if (4 < length(index_frame)) gw = gausswin(round(length(index_frame) / 2)); frame = filter(gw, 1, frame) ./ (round(length(index_frame)) / 4); end y(iter) = median(frame); end y(1) = mean(y); y(end) = y(end-1); y = y + min_value; end function [sample_spectr,log_space]=eject_spectr(sample_length,sample,fs,band_pass) %% set parameters band_start = band_pass(1); band_stop = band_pass(2); decimation_speed = 2.9; amount_point = 800; %% create spaces spectrum_space = 0 : fs/length(sample) : (fs/2) - (1/length(sample)); spectrum_space = spectrum_space(spectrum_space <= band_stop); sample_index_space = ... log_index_space(amount_point, length(spectrum_space), decimation_speed); %% create spectral density sample_spectr = 10*log10(abs(fft(sample,length(sample))) ./ (length(sample)*sample_length)); sample_spectr = sample_spectr(1 : length(spectrum_space)); sample_spectr = decimation_spectrum( sample_spectr, sample_index_space ); end
対数デシメーションの例を以下に示します。上のグラフは16000ポイント以上を含む0〜5000 Hzの対数スペクトルで、下のグラフは800ポイントの次元を持つ主要コンポーネントの選択された配列です。
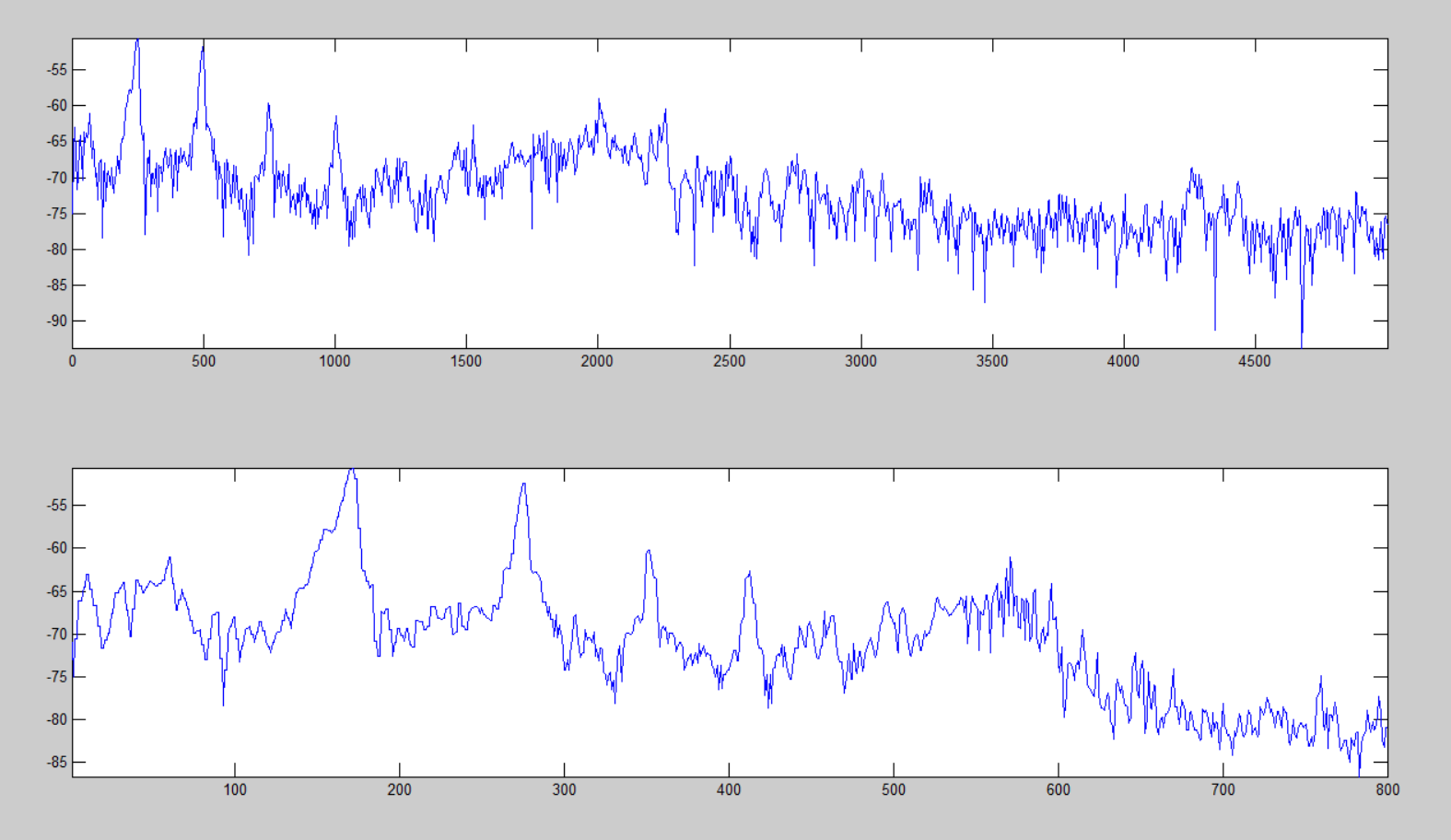
LogLogスペクトログラムの構築
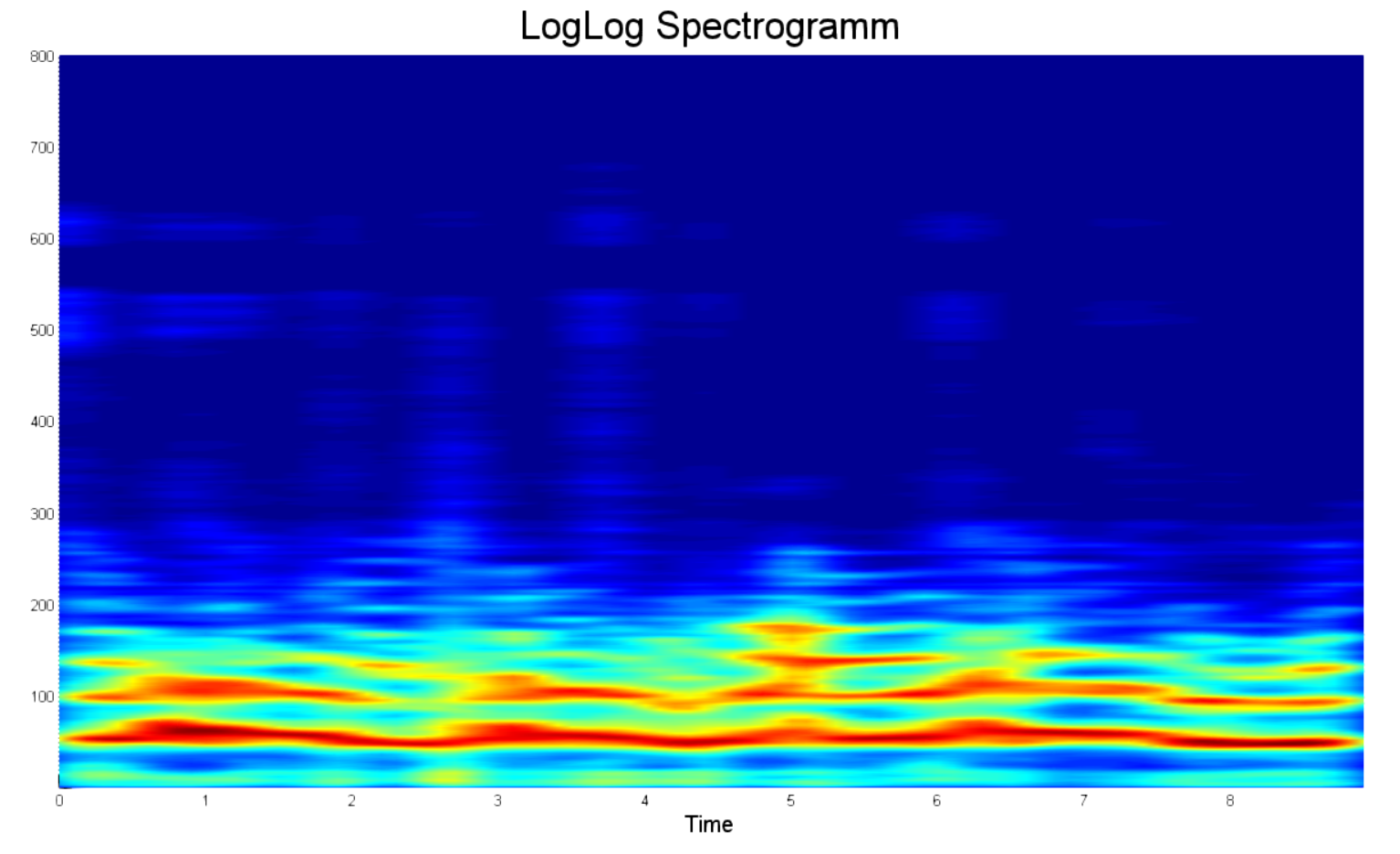
何言ってるの? なぜこれらすべての努力が必要なのでしょうか? matlabを使用して従来のスペクトログラムを1行で作成し、前述のすべてを浴びることができないのはなぜですか? しかし、それはできません。だからです。 以下の例は、典型的な音声スペクトログラムを示しています。 その欠点は何ですか?
- 膨大な数のポイント。 いいえ、たくさんあります。 そのため、15秒の録音のスペクトログラムを作成しようとして、コンピューターがメモリ不足になりました。
- ほとんどの情報はノイズに関するものです。 普通の人がその周波数で話すことがないのに、なぜ20 kHzのスペクトルが必要なのですか?
- 2.5〜3秒、および4.5〜5秒では、音声アクティビティはありません。 これがノイズです。 さらに、ターゲット周波数帯にあるため、将来的に分類システムに壊滅的な影響を及ぼす可能性があります。
- 明確な絶対電力スケールはありません。 オーディオ録音のボリュームは異なる場合があるため、スペクトル内の合計パワーは、同じ人物であっても異なる時間に大きく異なる場合があります。
- 対数ではありません。 人間の声の大きさ、および力の観点からの聴力の分解能は対数です。
- 対数周波数スケールではありません。 この点で、本当に有用な情報はスペクトルのごく一部に集中しています。
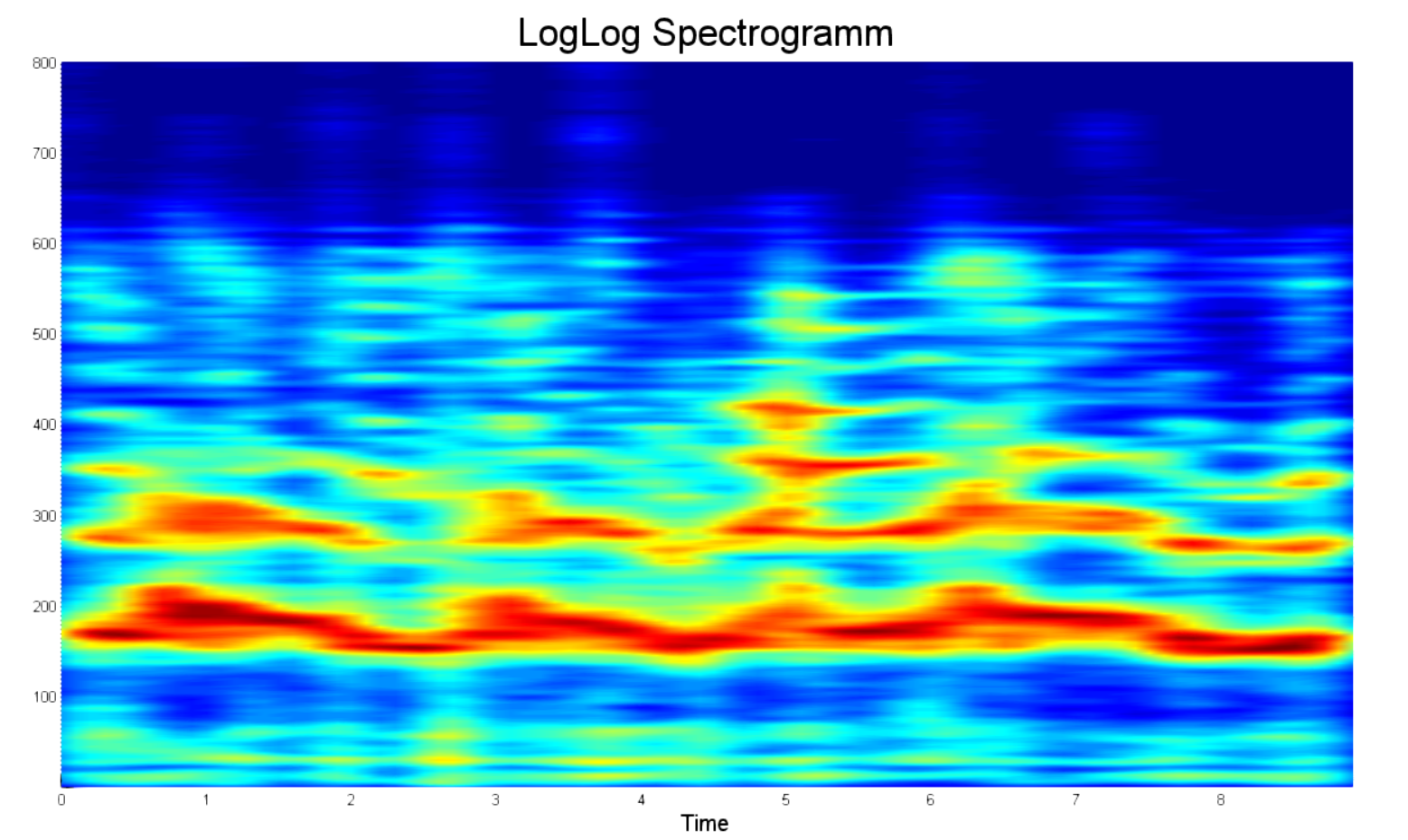
2つのスペクトログラムをより明確に比較するために、上記と同じ周波数範囲で処理されたLogLogスペクトログラムの例を以下に示します。 あなたの目を引く最初のものは何ですか?
- まず、これらは顕著なパワーピークです。 これで、目で2人のスペクトルを区別できます。
- 第二に、穏やかなゾーンはありません、それらは切り取られます。 したがって、期間は短くなります。
- 第三に、各周波数トラックに800ポイントしかない。 はい、上記の例のように、20,000ではなく800ポイントです。 これで、誤って再生時間を間違えたときにコンピューターを再起動する必要がなくなりました。
- 第四に、パワースペクトルの正規化。 スペクトルパワーを25デシベルに制限することが決定されました。 最大値と25デシベル以上異なるものはすべて、ゼロに等しいと見なされました。
同時に、ほとんどの情報は依然としてノイズに関するものです。 したがって、以下に示すように、8kHzの周波数サンプルをトリミングすることは理にかなっています。
統計処理
現時点では何がありますか? 800次元のランダムプロセスがあり、その実装は、スピーカーの発音、ムード、イントネーションに依存します。 ただし、プロセス自体のパラメーターは、話者の音声経路の物理パラメーターのみに依存するため、一定です。 主な問題は、そのようなパラメーターの数とそれらの評価方法です。
「TSCがあなたと共に来ますように」
それぞれを紹介してみませんか 合計として処理 異なるガウス過程? したがって、それだけで判明 さまざまなプロセス。 このアプローチのために、彼らは名前-GMMを思いつきました。
だから、これだけに対処することが残っている 。 スペクトログラムを取得し、ヒストグラムを作成し、それから出来上がります:
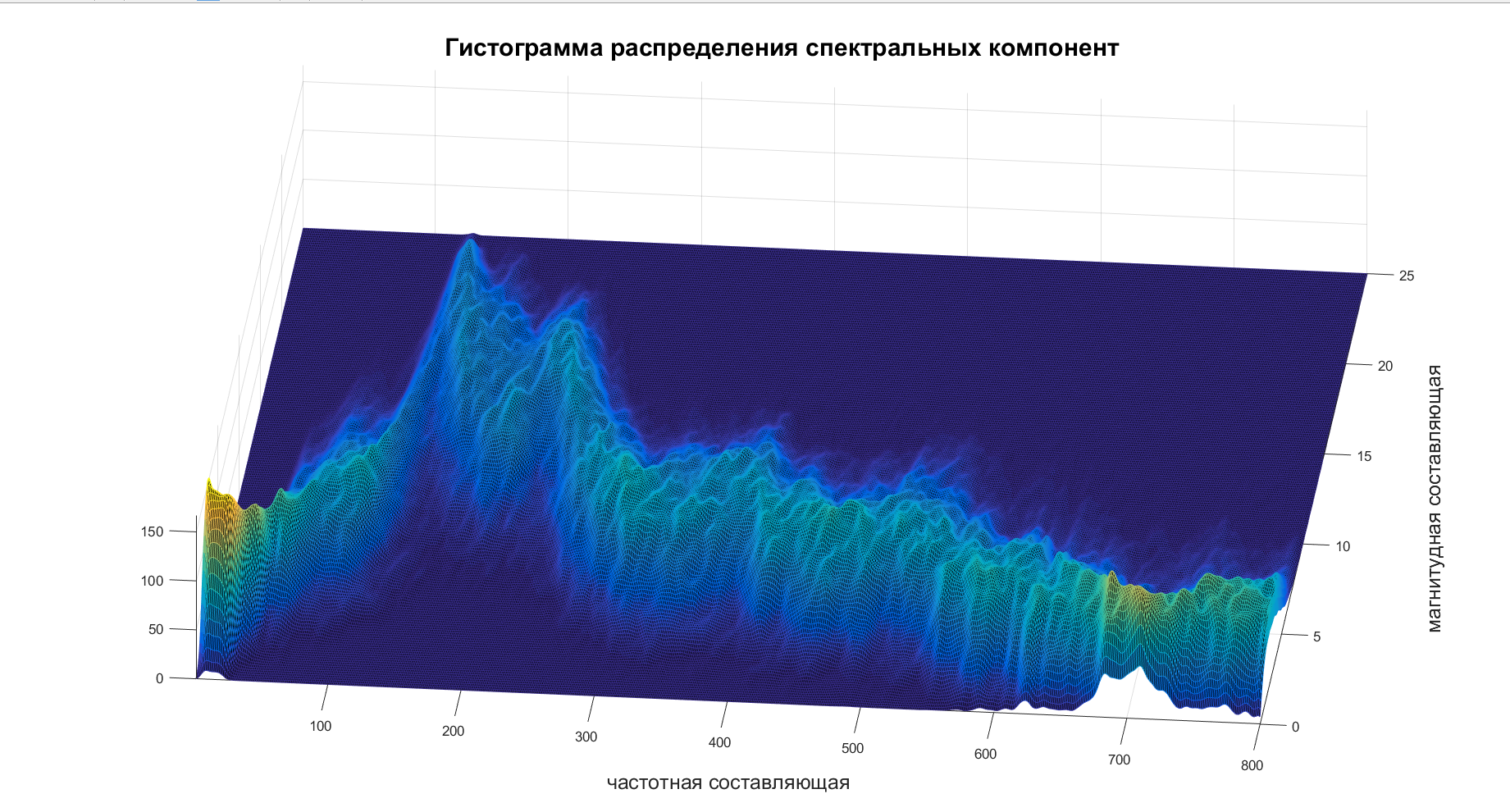
これらのヒストグラムのいくつかを表示した後、私の怠lazは決定的な勝利を祝い、 。 それを追求して、彼女は、共分散行列をコンパイルし、各周波数成分が独立していることを考慮するために、さまざまな周波数の通信共分散行列をスコアリングすることを提案しました。 怠azine-彼女はそのようなものです。
現在は、 MOの推定値と各周波数成分の標準偏差を計算し、主要成分を1つのベクトルに結合するだけです。
std_spectr = std(spectrum_array, 0, 1); mean_spectr = mean(spectrum_array, 1); principal_component = cat(2, mean_spectr, std_spectr);
おわりに
生体認証技術では、静的メソッドは、精度と反応率において動的メソッドよりも大幅に優れています。 ただし、これにも関わらず、動的な方法には多くの利点があります。これらは純粋に実用的であり、認識プロセスに影響を与えませんが、顧客にとって最も重要な場合があります。
動的機能に基づいてシステムを実装する場合、次のようなメリットがあります。
- 設備の低コスト
- 低ノイズ感度
- 人の登録とデータ収集のシンプルさ。