
今日は、クラウドサービス契約のサービスレベル契約の読み方についてお話します。 SLAは標準です:顧客は要求段階でそれを必要とします、プロバイダーはすべての材料の大切なナインを示します。 私はそれを否定しません-SLAがなければ悪いのですが、契約がどのような責任の範囲に影響するかは必ずしも明確ではありません。 それが何であるか、いつプロバイダーに実行するか、契約を振るタイミング、そしてその場で問題を探すタイミングを把握してみましょう。
簡単な例: VMはクライアント上で動作を停止し、クライアントは問題がインフラストラクチャにあるとすぐに考えます。 そして彼は、アクセシビリティについてSLAに何があるのかを見ています。 または、OSが実際にハングし、クライアントネットワークが遅れる場合があります-何でも想定できます。 問題がOS内にある場合、リソースプロバイダーはここでは役に立ちません。
クライアント仮想マシンを管理しない場合、内部のアプリケーションはブラックボックスになります。 同時に、最も頻繁に発生する障害はアプリケーション側でのみ発生します。 ディスクがいっぱいになる、アカウントがブロックされる、DNSが失敗する、設定が正しくないためにアプリケーションコンポーネントが対話を停止するなど、何でも起こります。 または、システム時刻が正しく設定されていないか、不要な更新プログラムがインストールされていることが判明する場合があります。 このような問題はSLAの違反ではなく、クライアント側で解決されます。 それで、彼はいつ行動しますか?
SLA-その理由と理由
SLAは、サービスの一種の保証カードです。 ただし、これはメイン契約に9が含まれる単なる条項ではありません。 これは、提供されたサービスのすべてのパラメーターが記録されるデプロイされたアプリケーションです。 適切に設計されたアプリケーションは、クライアントとサービスプロバイダーの両方を保証します。
SLAには、サービスの主要パラメーターの保証値が含まれています。 重要なポイント:保証- 低くないことを意味します。 そのため、仮想インフラストラクチャのSLAでは、クライアントVMのオペレーティングシステムの前にインジケーターが考慮されます。 VM内のオペレーティングシステムとアプリケーションは、クライアント管理者の関心事です。 何かが故障した場合は、まず自分自身で確認してください。 インフラストラクチャ自体が故障した場合、プロバイダーはあなたが監視する前にそれを知るでしょう。
優れた仮想インフラストラクチャSLAには、次のものが含まれる必要があります。
- 仮想リソースとインターネットアクセスの可用性。
- 有効な値を持つ仮想インフラストラクチャおよびインターネットアクセスのパラメーター。
- これらのパラメータを測定および監視する方法。
- インシデント、リクエスト、それらの簡単な説明、および対応と排除の時間の優先順位。
- 保証されたパラメーターの違反に対する罰則。
順番に始めましょう。
在庫状況
アクセシビリティ-これらは、SLAとして最も頻繁に発行される非常に9つです。 可用性のパーセンテージは、月または年ごとにサービスが利用できない時間と分に変換されます。
例:
| 在庫状況 | 月額シンプル | シンプルな年 |
|---|
| 99% | 7時間 18分 17.5秒 | 3日15時間 39分 29.5秒 |
| 99.9% | 43分 49.7秒 | 8時間 45分 57秒 |
| 99.95% | 21分 54.9秒 | 4時間22分 58.5秒 |
| 99.982% | 7分 53.4秒 | 1時間34分 40.3秒 |
すべてのオプションはここで表示できます 。
すべてが明らかであるように思えますが、キャッチは何ですか?
月または年。 私が二階を選んだのも不思議ではありません-月と年です。 SLAで大事にされたナインを見るとき、それらが関係している期間に注意を払ってください。 ほとんどの場合、プロバイダーはその月について話します。 つまり、99%の可用性により、1年ではなく、1か月あたり7時間以上のダウンタイムが発生します。 この瞬間を明確にして、後で失望しないようにします。
9つのインフラストラクチャ。 サービスに一定レベルのフォールトトレランスが必要な場合は、この可用性を確保するような方法で仮想インフラストラクチャを構築する必要があります。 したがって、99.95%の可用性レベルを達成するには、少なくともアクティブ/パッシブクラスターが必要です。 99.982%(Tier IIIデータセンターの可用性のレベル)を超えたい場合は、複数のデータセンターに分散したシステムを構築する必要があります。
仮想インフラストラクチャ構成を選択するとき、質問に答えます。ファイブナインが必要ですか? ナインはそれ自体が目的ではありません。 まず、9が多いほど、システムのコストが高くなります。 後続の各正直9は、コストの権利にゼロを追加します! 第二に、すべてのサービスが地理的に分散したクラスターを必要とするわけではありません。
クラウドリソースを選択する場合は、現在解決しているタスクを決定します。テスト環境またはコールドリザーブを構築するか、重要なサービス(オンラインストア、支払いシステム、またはCRM)を配置します。
累積可用性。 アプリケーションのアクセシビリティが99.5%であり、クラウドのアクセシビリティが99.95%であり、デプロイされるデータセンターが99.982%である場合、出口では99.5%以下のアクセシビリティがあります。 サービス全体の可用性は、最も弱いリンクの可用性より高くなることはないためです。 サービスを選択するときにこれを覚えて、オオバコの骨折を治療しようとしないでください。 保護された地理的に分散したクラスターは、1日おきに落ちるアプリケーションを保存しません。
アクセシビリティシングルではない
ITサービスの可用性は重要な考慮事項です。 しかし、稼働率が100%であっても、ネットワークの遅延、IOPSの不足、ストレージの高遅延などの問題により、仮想マシンを鈍らせるのは困難です。 したがって、適切なSLAには、インフラストラクチャのすべての品質メトリックが必要です。 何を探し、何を求めて努力しますか?
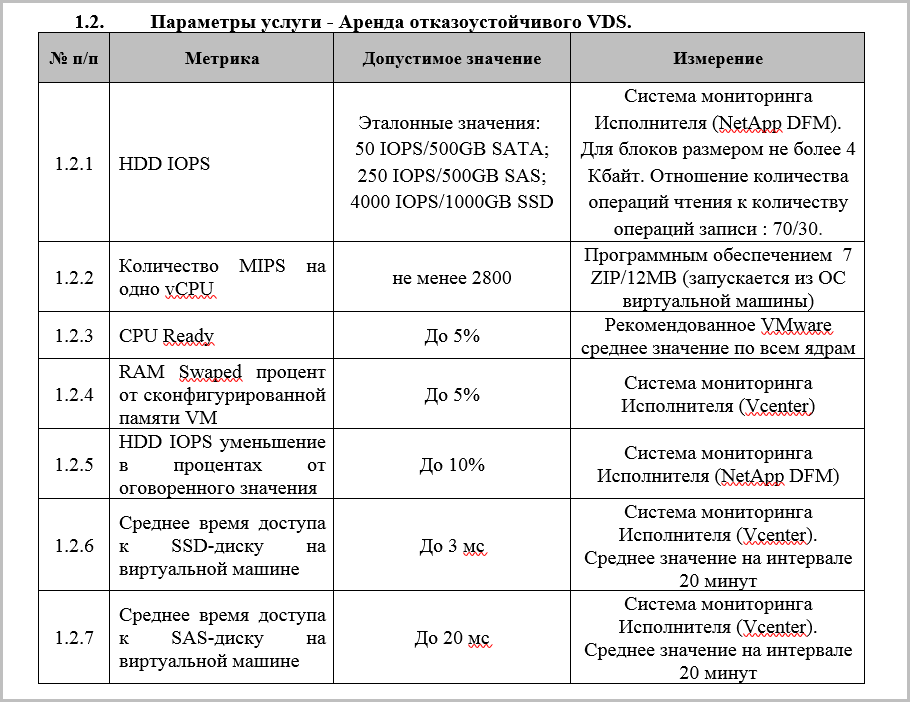
- VCPUパフォーマンス。 これは、1秒あたりの処理済みリクエスト数(MIPS-1秒あたり100万命令)によって決まります。 プロバイダーがこれらの同じMIPSを測定する方法を示す必要があります。 指定された値により、VMコアの推定パフォーマンスを機器と比較できます。
- 設定されたVMメモリのスワップファイルサイズ(RAMスワップ)の許容パーセンテージ。 VMがメモリではなくディスク上のファイルを受信するとき、これは非常に悪いです。 この項目は、重大なパフォーマンス低下からVMを保護します。
- ストレージパフォーマンス/ IOPS。 通常、1秒あたりの操作数(IOPS-1秒あたりの入力/出力操作)で測定されます。 読み取り/書き込み用のブロックのサイズは、ディスクの種類によって異なります。 ロードパターンも異なります。テスト中の読み取り/書き込み操作の比率から決定されます。 テストは次のように実行されます。特定のキュー項目数を持つ特定の数の並列書き込み/読み取りプロセスがディスクに送信されます。 結果:特定のサイズのブロックを使用して、ストレージシステムが一度に処理できるI / O操作の数。 ブロックサイズ、プロセス数、および負荷パターンは、IOPSパラメーターを明確に理解するためにSLAで最適にキャプチャされます。 また、SLAでは、基準値からのIOPSの許容される減少は固定されており、10%以下です。
- ストレージパフォーマンス/仮想マシンの平均ディスクアクセス時間(レイテンシ)。 このインジケータは、IOPSと同じくらい重要です。 さらに、レイテンシを指定しないIOPSはほとんど意味がありません。 ストレージシステムが大量のデータブロックをVMに送信するとします。 しかしめったにありません。 遅延はストレージドライブの種類によって異なりますが、50ミリ秒を超える場合は、VMの速度が満足できないため、「インシデント」セクションを開きます。
- 平均ネットワーク遅延。 ここで、クリティカルインジケータは5ミリ秒です。 SLAでは、ネットワーク遅延のみがプロバイダーのデータネットワーク内に収まることが重要です。 原則として、これはあなたの通信プロバイダーとのジャンクションへのセクションです。
- パケット損失率。 パケット損失は、システム設定のエラーまたは通信チャネルの問題です。そうすべきではありません。 同時に、場合によっては、たとえば、VMがバックアップされると、1秒以内にパケット損失が発生する場合があります。 したがって、このパラメーターの標準は0〜1%の範囲です。 ネットワーク遅延の場合のように、責任が終了するプロバイダーに確認してください。
SLAは、各パラメーターの測定および監視の方法も規定する必要があります。 たとえば、次のように:
お問い合わせ、インシデント、技術的作業
まず、リクエストとインシデントの概念を拡張します。 リクエストとは、定期的な作業のリクエストです。 インシデント-何かが壊れて機能しない場合。たとえば、マシンが非常に愚かであるか、応答しない。 プロバイダーで何かが壊れている場合、インシデントの通知は監視システムから送られます。 すべてのリクエストとインシデントが優先されます。 これにより、生と死の質問に迅速に対応し、すべてを時間通りに修復できます。 登録の段階でアプリケーションのステータスを判断することが重要です。 弊社との連携については、サポートサービスに関する記事で説明しました。
インシデント解決。 起こりうる損傷を予測しないでください。 ただし、サービスが利用できない典型的な理由は、SLAに明記する必要があります。 繰り返しますが、契約はプロバイダー側の問題にのみ影響し、VM内のエラーには適用されないことに注意してください。 サービスが完全に利用できなくなるか、部分的に低下するかによって、すべてのインシデントに優先順位が付けられます。 優先度ごとに、最大消去期間が決定されます。
異なるタイプのディスクを使用する場合、それらのそれぞれにインシデントを登録することを忘れないでください:

最優先のインシデントの例。
IaaS SLAでは、インシデントを3つの優先順位に分けています。 それぞれが24時間処理されますが、実行時間は異なります。
インシデントを実行する時間をどのように考慮しているかをプロバイダに確認し、これがアプリケーションに記述されていることを確認します。 原則として、実行時間は、インシデントの登録に関するクライアントへの通知からその決定の瞬間までの時間と見なされます。
さらに、SLAは、1か月あたりプロバイダーで開くことができるアプリケーションの数を制限する場合があります。
リクエスト処理。 そうです:優れたSLAは、リクエストを処理するための時間を明確にします。 これは、ルーチンタスクのサービスのシャットダウンを正しく優先し、点滅させないために必要です。 そして、プロバイダーを保護します。 私たちはサービスの停止について話しているわけではないので、このセクションはしばしば読まれませんが、無駄です。 ここでは、プロバイダーの勤務時間中に要求が受け入れられ、ソリューションに少なくとも12時間割り当てられることが記録されています。
リクエストを3つのタイプに分割します。これらは作業と実行時間の性質が異なります。
- サービスリクエスト。 これは、顧客の現在のリソースのサービスに関する作業です。バックアップからのVMの復元、OSのインストール、ネットワーク設定の変更。
- 変更リクエスト。 契約に基づく顧客サービスの構成の変更に取り組みます:リソースの追加または削除、新しいVMの拡張または追加。 これには、SLA設定の変更が含まれます。
- 情報のリクエスト。 新しいサービスのクライアントインフラストラクチャとアプリケーションに関するすべてのレポート。
定期的なメンテナンスと通知。 インフラストラクチャは生物です。 サービスが必要です:アップグレード、重要な更新のロール、スケジュールされた作業の実行(サーバー上のファームウェアの更新など)。 サービスを停止せずにすべての作業を実行できるわけではありません。 したがって、SLAは、そのような作業の通知手順、作業時間、およびサービスの中断の可能性のある時間を修正します。 計画された作業の通知期間が十分であること、およびサービスを停止する最大時間が記録されていることを確認してください。
私たちにとってはこのように見えます:

ペナルティの賦課。 ペナルティには2つのタイプがあります。インシデントへの応答時間を超過することと、単純なサービス(この場合は仮想インフラストラクチャ)です。 制裁を課す手順が詳細であるほど、クライアントとプロバイダーの両方がより安全であると感じます。 条件が明確でない場合は、契約に署名する前にプロバイダーに質問して、驚きや失望がないようにします。
SLAに上記のすべてのポイントがある場合、透過的な保証と可用性のレベルを備えたサービスを利用できます。 SLAに横たわるのは、罰金から逃れることができないため、採算が取れません。 しかし、不活性なアプリケーションまたは不適切なVM設定のためにSLAで失敗することも失敗します。
質問がある場合は、伝統的にコメントを待っています。 健全なクラウドをお祈りします!