多くの知恵には多くの悲しみがあるためです。
そして知識を増やせば、悲しみが増します。
•伝道の書1:18
この記事は、いかなる理由でも不寛容または差別を表現する口実として使用することはできません。
記事の最初の部分では、次のような問題を概説しました。 孤独/孤独になる確率は、人の名前に依存します。 相関という言葉を使用する方がより正しいでしょうが、この問題については言語の自由をもう一度許可し、誰もがこの声明を正しく理解することを望みます。 しかし、前の記事へのコメントをありがとう。
コメントの一つで、私は名前と孤独と相関するいくつかの第三の要因がある可能性が高いと言った。 例として、リンゴの例を挙げました。孤独は少女が食べるリンゴの数に依存しており、何らかの理由でカティアという少女はマーシャよりも多くのリンゴを食べると仮定します。 特定のマーシャまたはカティアそれぞれについて、これは絶対に何も意味しないことは明らかですが、平均すると、リンゴを異なる量で食べるため、一部は他よりも単独であることがわかります。
実際、問題はまったく同じものに要約されます。同じ名前の人が他の人よりも多くのリンゴを食べるのはなぜですか? ただし、この相関関係の説明はより単純な場合があります。
チェリーピッキングと統計的有意性
続行する前に、前の記事で選択についていくつかコメントします。これは、引き続き作業するためです。 一方では、質の高い議論が本当に好きです。 一方、私は、サンプルがまさにそれであった理由と、結果が統計的に有意であるかどうかを尋ねる人々を理解しています。 統計的有意性については意図的に何も書いていません。なぜなら、2つの「ランダム」プロセスが異なるシステム、異なる人、ステータス設定の仕組みでまったく同じように振る舞う状況は、私にはまったく信じられないからです。 名前の選択については、ランダム性の要素があります(女の子の友達の名前だけでなく、頻度の意味で欠落していた分布の部分も埋めようとしました)が、量を制限することを除いて、意図的に何もしませんでした。完全に私の欲求に関係なく部品。
しかし、(コメントの1つに書かれているように)労働者の要求で、私はOdnoklassnikiに十分な統計がある100個の完全にランダムな名前を取り、名前自体が混ざった場合にどうなるかを確認しました。 一部の人が予測したように( uを数えた後)まったく同じ分布になった場合、結果は統計的に有意ではないと言うことができ、最良の場合、名前の頻度のみに依存することについて話すことができます。 ただし、Mann-Whitney検定ではp-value = 0.000256れました。 初期分布とミキシングで何が起こったのかは完全に異なっています。
したがって、私たちの研究にとって十分に代表的であると考えて、元のテーブルを引き続き使用します。
ボンドに問題がありますか?
サンクトペテルブルク州立大学での私の経験は、私に次のような考えを促しました(彼女は私を一人で訪れたのではないようです) 。 つまり、映画「カジノ・ロワイヤル」の写真にあるボンドとベスパーのこの対話はすべて、確率的な意味での一種のトートロジーです。
IQテストはあまり代表的ではないことはよく知られており、ソーシャルネットワーク上でIQを直接測定することは不可能です。 しかし、次の仮定を立てることができます。高等教育を受けた人は、平均して、そうでない人よりも賢い。 もちろん、ほぼ全員が高等教育を受けているため、これはまあまあの基準です。 したがって、多かれ少なかれエリートの教育機関を採用することができますが、専門分野の多様性は十分でした。 したがって、私たちは次のことを試みます:サンクトペテルブルク市では、サンクトペテルブルク州立大学の学生の間で、モスクワでは、モスクワ州立大学の学生の間でそれぞれ名前の分布を見ます。 これも投機的な仮定ですが、私たちの目的にとっては平均してかなり実行可能です。
次のことをしましょう。サンクトペテルブルク州立大学とモスクワ州立大学で特定の名前で勉強した人を見つけて、目的の都市でその名前を持つすべての人数で割ります。 実際には、レイラの名前はここで削除する必要があります。 「地域的な特異性」がありますが、完全を期すために何も触れません。
前の記事で行ったサンクトペテルブルクとモスクワの都市のテーブルを比較してみましょう。
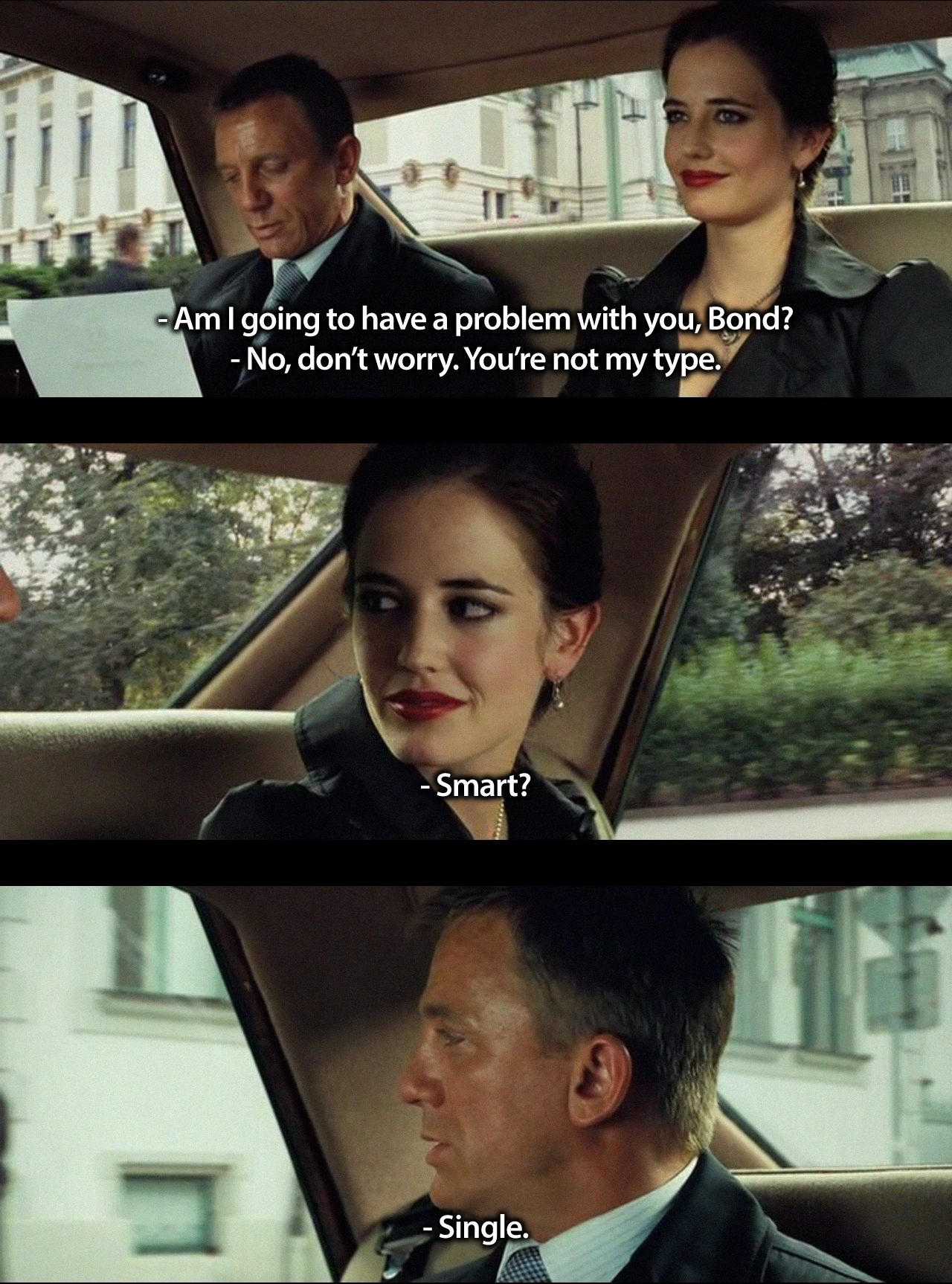
ここでp = edu / all 、つまり サンクトペテルブルクの同じ名前の人の総数のうち、サンクトペテルブルク州立大学で勉強したか、または勉強している、特定の名前の女の子(VK統計による)の割合。
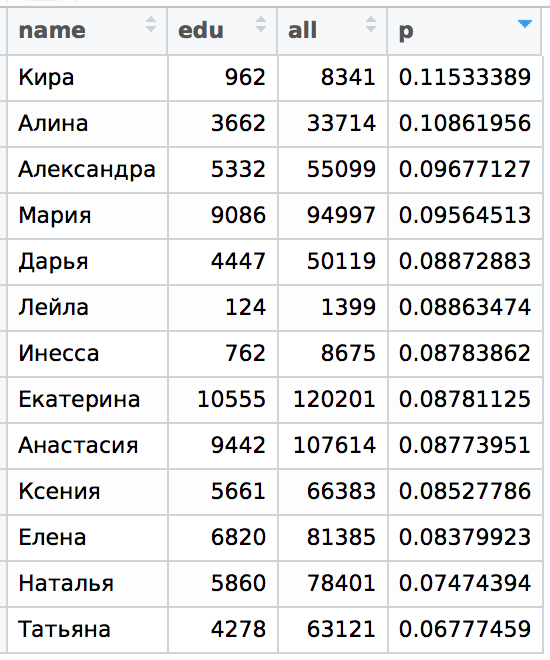
現在、MSUでも同じです:
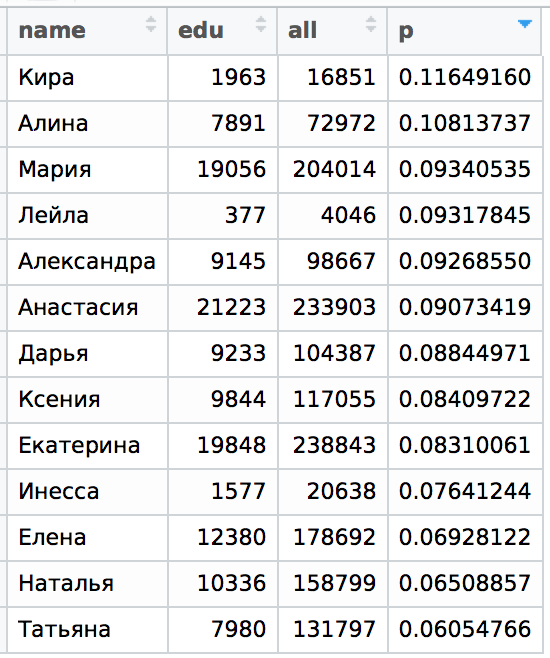
前の記事の表を比較してもう一度見てみましょう。 サンクトペテルブルクの分布は次のqです( qは「孤独」の統一された指標で、表記の全範囲は記事の最初の部分にあります )。
モスクワの場合、分布は次のとおりです。
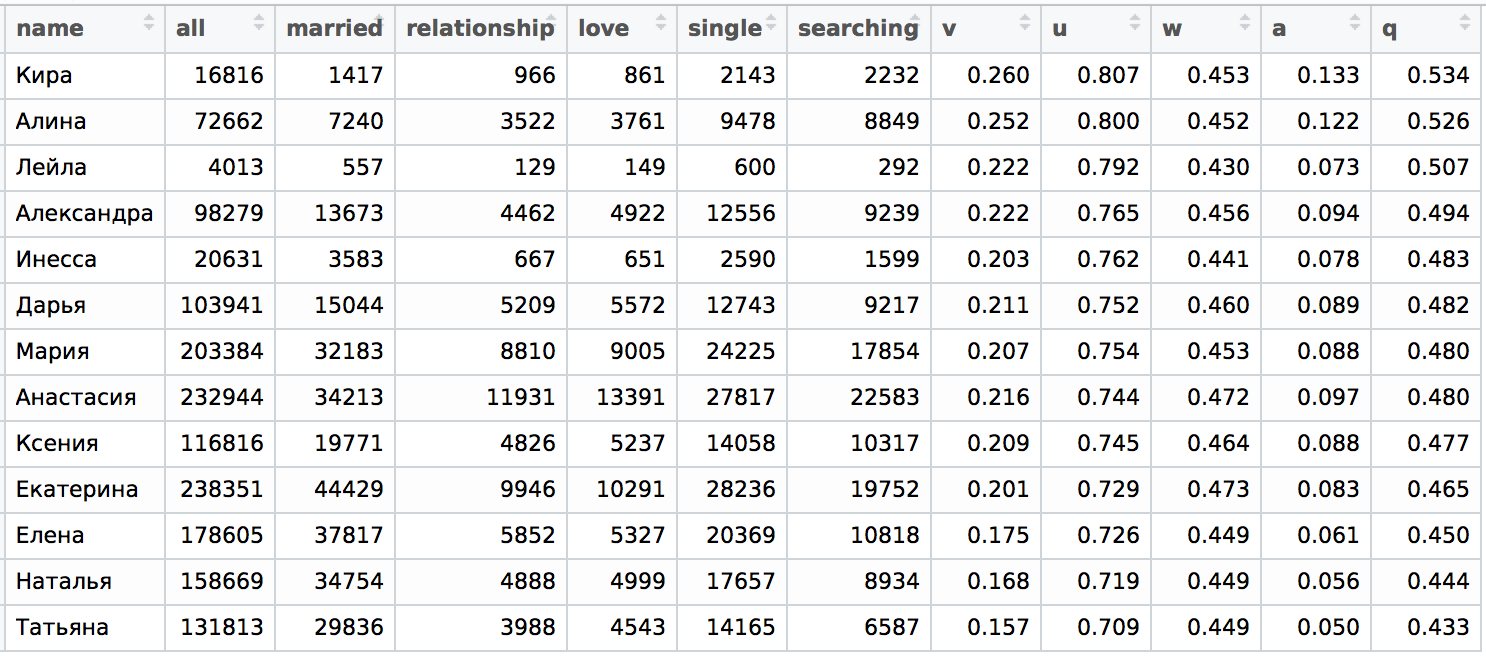
pとqで並べ替えると、少なくともテーブルの上部と下部がほぼ同じであることがわかりますが、平均は少し混合されていますが、部分間に有意な順列はありません。 イネッサという名前の場合、若干の矛盾があります。正確な分析のためには、イナとイネッサの名前を分けて、モスクワとサンクトペテルブルクの分布の詳細を確認する必要があります。 しかし、ここではこれを行いません。定性的な評価のみに限定します。 これを行うために、サンクトペテルブルクの場合のp 「依存」 qを構築します。
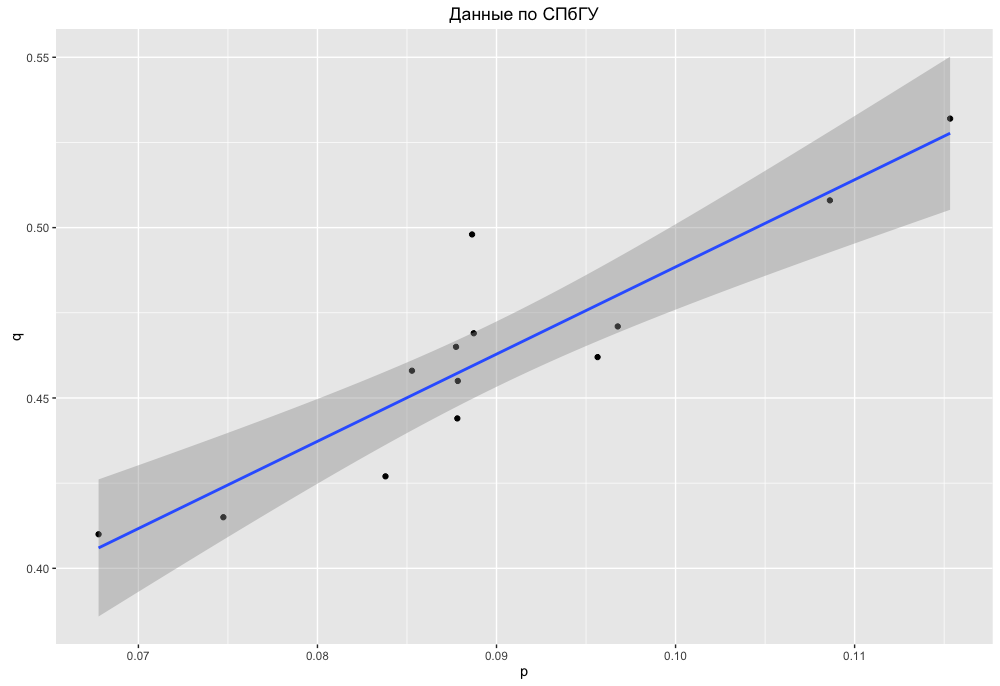
現在、MSUの同じスケジュール:

つまり、より知的で教育水準の高い女の子がより独り立ちしていることがわかります。 これはもちろんすべて条件付きであり、たとえば、これは後の結婚を意味するだけである可能性があります。
大学ランキング
実際、孤独と良い教育との間に相関関係がある場合、おそらく、孤独は教育と知性の質の尺度と見なすことができます(もちろん、確率的な意味で)。 したがって、私はすぐに思い出すことができるいくつかの良い大学(そしてVKでの検索でなんとか見つけることができました)を取り、それらのために非常に指標q 、 u 、 vを計算することを決めました。前回の記事で私は多くの名前を数えました。 名前の場合と同様に、 q取得およびソートしました(追加のパラメーターとして、性別による多様性d = all / (all + all_m)を計算しました。ここで、 all_mは大学の若者の数です)。
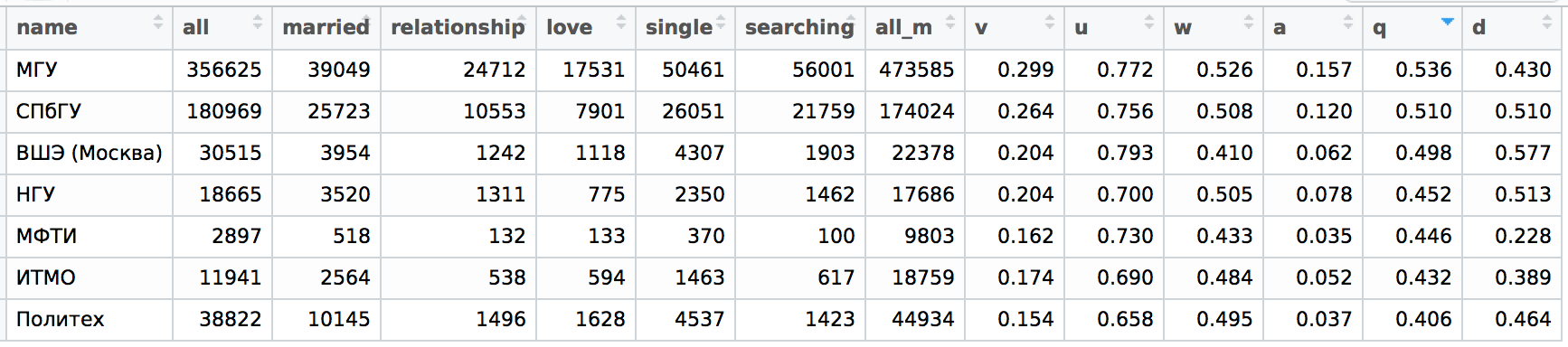
これは何かを思い出させますか? そうです、大学の評価をグーグルで検索すると、次のことがわかります(これは国の評価のトップです)。
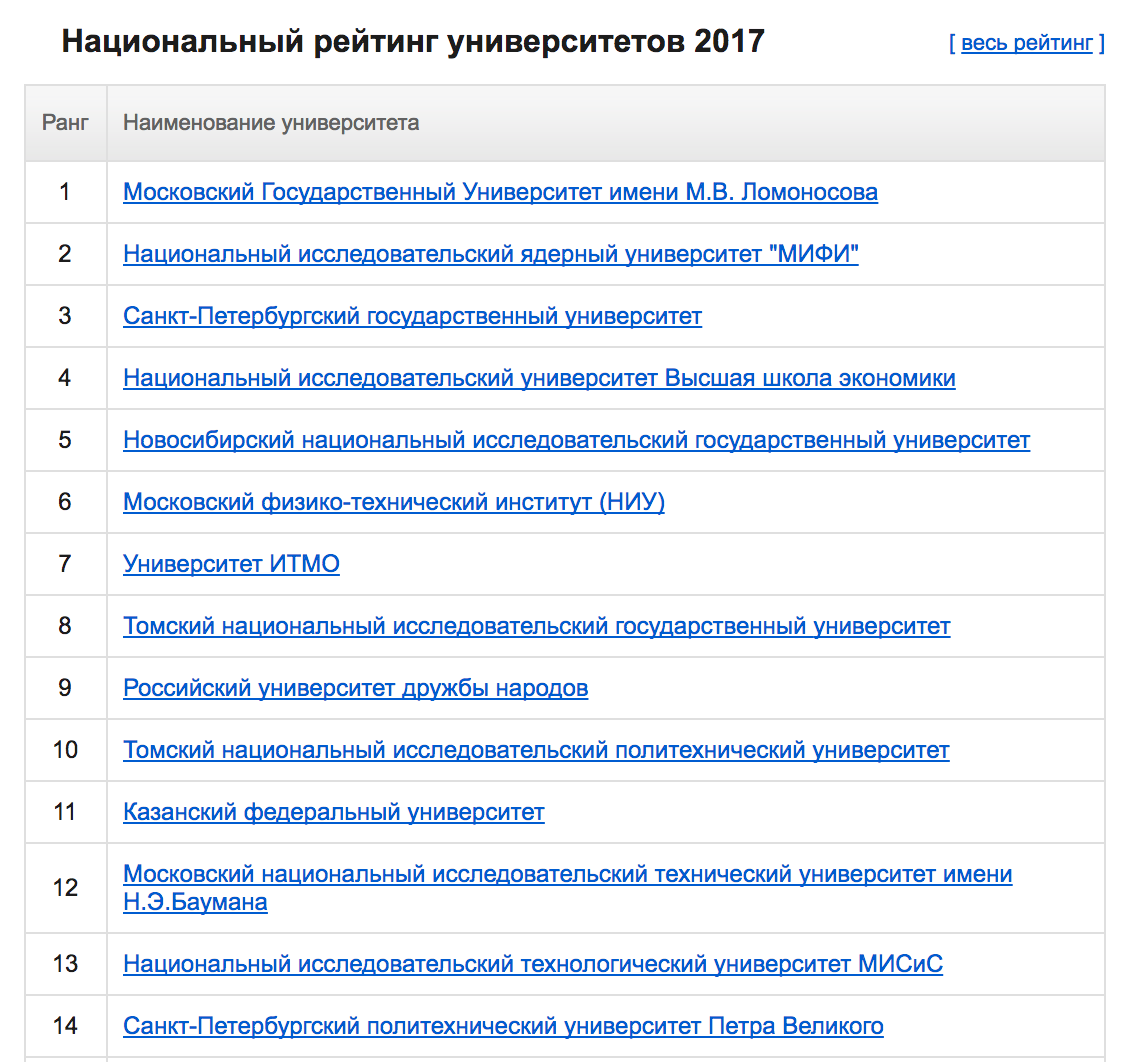
完全な評価を参照したい人は、ここに行きます: National University Ranking 2017 。 もちろん、すべての大学が私の表にリストされているわけではなく、これは低い評価の大学(たとえば、Herzen State Pedagogical University)には機能しませんが、これは間違いなく考えさせられます。
結論の代わりに
何が起こっているのかを理解するのにどれだけ近づいたかを言うのは困難です。 しかし、教育と孤独の相関関係は、もはや名前と孤独の相関関係ほどおかしく見えません。
ここでは、前の記事の結果の統計的有意性を確認するためだけにOdnoklassnikiデータを使用し、その他はすべてVKontakteデータに基づいて構築されました。