
前の記事
「SDAccel-知り合い」で 、ザイリンクスFPGAでOpenCLを使用する基本について説明しようとしました。 今こそ、ADM-PCIe-KU3モジュールでのデータ転送に関する実験結果を共有するときです。 双方向のデータ転送を確認します。 プログラムのソースコードはGitHubに投稿されています:
https :
//github.com/dsmv/sdaccel 装備品
すべての実験は、Alpha-Data ADM-PCIe_KU3モジュールで実行されました

中心的な要素は、Xilinx Kintex UltraScale KU060 FPGAです。
2つのSODIMM DDR3-1600モジュールがFPGAに接続されています。 メモリ幅は72ビットです。これにより、エラー訂正付きのメモリコントローラを使用できます。
2つのQSFPモジュールを接続することが可能です。 各QSFPモジュールは、最大10 Gb / sの伝送速度を持つ4つの双方向リンクです。 これにより、低遅延ネットワークカードの実装を含め、1G、10G、40Gイーサネットを使用できます。 興味深い特性もあります-GPS受信機から2番目のマークを入力します。 しかし、この作業では、これはすべて使用されません。
NIMBIXサーバー
NIMBIXサーバーは、SDAccel開発環境を含むさまざまなコンピューティングサービスを提供し、さらに重要なことに、選択したハードウェアモジュールでプログラムを実行します。
電卓モデル
OpenCLシステムとは何かを思い出させてください。
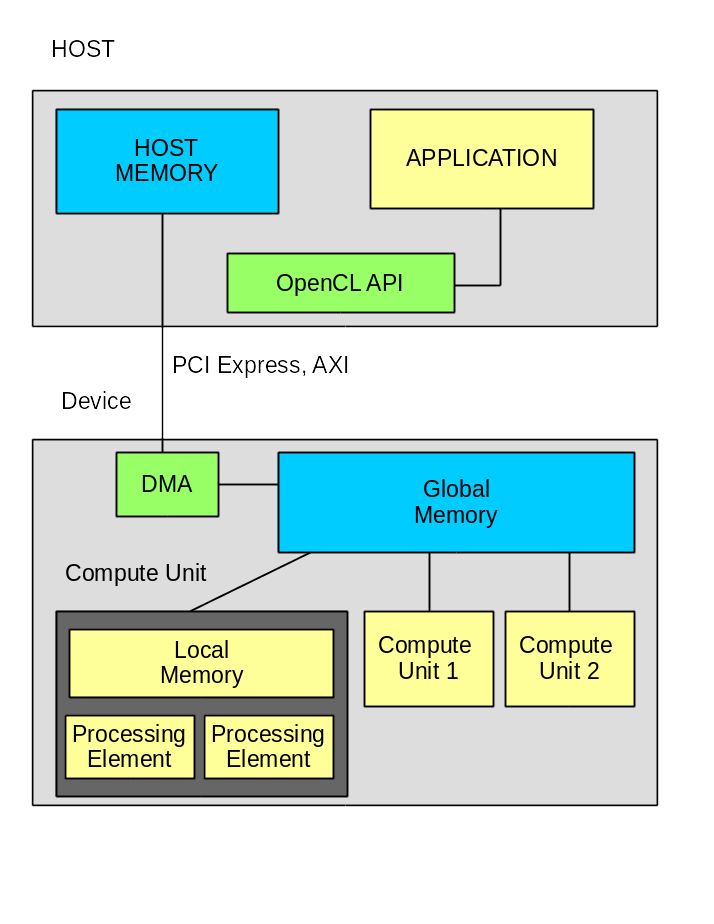
このシステムは、ホストコンピューターとコンピューターで構成され、バスを介して相互接続されています。 この場合、PCI Express v3.0 x8です。
アプリケーションソフトウェアは2つの部分で構成されています。
- コンピューターのHOSTプログラム。
- 電卓で動作する1つ以上の関数。
データはグローバルメモリを介してのみ交換されます。この場合、これらは2つのSODIMMモジュールです。
アプリケーションソフトウェアには、誰かが提供しなければならないインフラストラクチャが必要です。 この場合、ザイリンクス。 インフラストラクチャには次のものが含まれます。
- openclライブラリ-OpenCL標準機能の実装。
- モジュールドライバー-モジュールとの相互作用を提供します。
- DSAパッケージ。 これは、独自のFPGAファームウェアを開発するための基礎です。
DSAパッケージには、PCI Express、ダイナミックメモリ、および場合によっては他のノード用のコントローラーを含む基本的なファームウェアが含まれています。 基本ファームウェアには、OpenCLリージョンと呼ばれる要素があります。 OpenCLカーネルのすべての機能が実装されるのは、この要素内です。 ファームウェアは、パーシャルリコンフィギュレーションテクノロジーを使用してPCI Express経由でOpenCLリージョン内にダウンロードされます。 ザイリンクスがダウンロード速度を大幅に向上させたことに注意してください。 以前のバージョンでダウンロードに数分かかった場合、約5秒かかります。 また、バージョン2017.2では、ファームウェアをまったく再ダウンロードできないことが発表されました。
現在、2つのパッケージが、SDAccelパッケージの一部としてADM-PCIe-KU3モジュールで利用できます。
- xilinx:adm-pcie-ku3:2ddr:3.3
- xilinx:adm-pcie-ku3:2ddr-xpr:4.0
どちらのパッケージも、2つのメモリコントローラーとPCI Express v3.0 x8をサポートしています。 接尾辞-xprに注意してください。 これは重要な違いです。 xprなしのオプションは、DDRコントローラーとPCI Expressの位置を修正します。 xprバリアントはPCI Expressの位置のみをキャプチャし、DDRコントローラーはOpenCLアプリケーション機能のトレースに関与します。 この違いは結果の違いにつながります。 xprを使用しないバリアントはより高速に作成され、xprを使用するバリアントはより最適なトレースを取得できます。 このプロジェクトでは、xprなしのオプションでは1時間11分、xprオプションでは1時間32分でした。 ログはこちらです。
ところで、各DSAパッケージには独自のドライバーが含まれています。
CHECK_TRANSFERプログラム
このプログラムは、3つのモードでの連続データ転送を検証するように設計されています。
- FPGAからSODIMおよびコンピューターへ
- コンピューターからSODIMMおよびFPGAへ
- 双方向同時送信
私の意見では、データをチェックせずに作業の速度をチェックすることはあまり意味がありません。 そのため、OpenCLを使用して、テストシーケンスジェネレーターノードとテストシーケンス検証ノードをFPGAに実装しました。
OpenCL標準は、デバイスのグローバルメモリを介してのみデバイスとコンピューター間の交換を提供します。 これは通常、SODIMMの動的メモリです。 そしてここで、最大速度でデータを転送する可能性について非常に興味深い質問が生じます。 ADM-PCIe-KU3は2つのSODIM DDR3-1600を使用します。 1つのSODIMMの交換レートは約10 GB /秒です。 PCI Express v3.0 x8バスの交換速度は約5 GB / sです(これまでのところ、はるかに少ないことが判明しています)。 すなわち PCI Expressからの1つのブロックをメモリに書き込むと同時に、FPGA内で処理するために2番目のブロックを読み取ることができます。 そして、まだ結果を返す必要がある場合はどうなりますか? PCI Expressは、高速で双方向のフローを提供します。 ただし、メモリバスは1つであり、速度は読み取りと書き込みに分割されます。 これは、2番目のSODIMMが必要な場所です。 処理用のバッファを配置するモジュールを指定する機会があります。
オペレーティングシステム
SDAccelは特定のLinuxシステムでのみ機能します。 利用可能なシステムのリストで、CentOS 6.8、CentOS 7.3、Ubuntu 16.04、RedHat 6.8、RedHat 7.3。 CentOs 6.7で始めた最初の実験。 それから、Ubuntu 16.04を使用しようとしましたが、すべてが動作しませんでした。 現在、CentOS 7.3を使用していますが、このシステムに非常に満足しています。 ただし、SDAccelをセットアップする際には、いくつかの微妙な点があります。 主な問題は、デフォルトでネットワークインターフェースの名前が「enp6s0」であることです。 この名前は、ザイリンクスライセンスサーバーでは認識されません。 通常の「eth0」が必要です。
セットアップはこちら: https : //github.com/dsmv/sdaccel/wiki/note_04---Install-CentOS-7-and-SDAccel-2017.1
Qt 5.9.1はインストールされますが、機能しません。 新しいgccおよびgitコンパイラが必要です。 これも解決されています。詳細はこちら: https : //github.com/dsmv/sdaccel/wiki/note_05---Install-Qt-5.9.1-and-Git-2.9.3
開発システム
開発には、2つのシステムを使用します。
- SDAccel 2017.1-カーネル開発および小規模なホストテストプログラム用
- Qt 5.9.1-より複雑なプログラムの開発用。 Qtは、HOSTプログラムの開発にのみ使用されます。
GitHubプロジェクトの組織
dsmv / sdaccelリポジトリは、SDAccelの例を開発するために設計されています 。 現時点では、check_transferプログラムは1つだけです。 プロジェクトでは、多くのGitHub機能が使用されます。
メインプログラムディレクトリ
- 有用-システムを構成するための有用なスクリプト
- qt-Qtソースのディレクトリ
- sdx_wsp / check_transfer-作業ディレクトリSDAccel
このプロジェクトでは、QtとSDAsselのソースは同じですが、ディレクトリは異なります。 ただし、Qtではさらに複雑なプログラムが開発されることが予想されます。
2つの出力モード
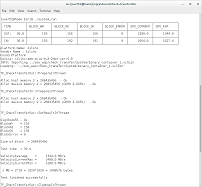
(画像をクリックすると拡大します)
図は、プログラムの実行中の端末の外観を示しています。 テーブルに注意してください。 これは、テストの現在のステータスを示す表です。 作業中、実際に何が起こっているのかを知ることは非常に興味深いです。 さらに、時間制限のないモードがあります。 テーブルは非常に役立ちます。 残念ながら、問題があります。 SDAccelはEclipseに基づいて作られています。 外部端末の環境からプログラムを実行する方法を学ぶことができませんでした。 また、ビルトインターミナルでは、テーブルが機能しません。 テーブルなしで起動モードを作成する必要がありました。 ところで、NVIDIAデバイスをプログラミングするためのNsight Eclipse Editionシステムは、外部端末でプログラムを実行することもできません。 それとも、私は何かを知らないのでしょうか?
メガバイトかメガバイトか?
私は、1キロバイトが1024バイトであることを確実に知っている人々に属します(また、1キロメートルで1,024メートルと仮定します)。 しかし、これはすでに違法です。 混乱を避けるために、プログラムは両方のモードで測定でき、現在のモードがログに表示されます。
プログラムコードの一部を見てみましょう。
カーネルgen_cnt
gen_cnt()のコアコードは非常に単純です。 この関数は、指定されたサイズの配列をテストデータブロックで埋めます。
__kernel __attribute__ ((reqd_work_group_size(1,1,1))) void gen_cnt( __global ulong8 *pOut, __global ulong8 *pStatus, const uint size ) { uint blockWr; ulong8 temp1; ulong8 checkStatus; ulong8 addConst; checkStatus = pStatus[0]; temp1 = pStatus[1]; addConst = pStatus[2]; blockWr = checkStatus.s0 >> 32; __attribute__((xcl_pipeline_loop)) for ( int ii=0; ii<size; ii++) { pOut[ii] = temp1; temp1.s0 +=addConst.s0; temp1.s1 +=addConst.s1; temp1.s2 +=addConst.s2; temp1.s3 +=addConst.s3; temp1.s4 +=addConst.s4; temp1.s5 +=addConst.s5; temp1.s6 +=addConst.s6; temp1.s7 +=addConst.s7; } blockWr++; checkStatus.s0 = ((ulong)blockWr)<<32 | 0xAA56; pStatus[0] = checkStatus; pStatus[1] = temp1; }
変数temp1は、ulong8型です。 これは、8つの64ビット数のベクトルである標準OpenCLタイプです。 s0..s7という名前またはtemp1.s [ii]でベクターの要素にアクセスできます。 これは非常に便利です。 ベクトルの幅は512ビットです。 これは、SODIMMの内部バス幅に対応します。 最適化要素の1つは、正確に512ビットデータのみをメモリと交換することです。 pStatusポインターには、ステータス情報を持つブロックが含まれ、現在の値と定数がそこから読み取られます。 各64ビットフィールドは、独自の定数を使用します。 これにより、単純なカウンターだけでなく、より複雑なカウンターを作成できます。 これまでのところ、プログラムは単純なカウンターのみを実行します。 関数の最後に、現在のデータ値と塗りつぶされたブロックの数が記録されます。
検証を実装するために、2つの関数を作成しました。1つはcheck_read_input-動的メモリからデータを読み取り、パイプに書き込みます。 2番目のcheck_cnt_m2aは、パイプからデータを読み取り、チェックします。 おそらくこの場合、2つのカーネルへの分割とパイプを介した接続は冗長です。 しかし、私はこの技術のテストに興味がありました。
ここにコード
ホストプログラムの構造
このプログラムは、仮想クラスTF_TestおよびTF_TestThreadの使用に基づいています。 これらのクラスに基づいて、2つのテストクラスが開発されました。
基本クラスTF_Testには次の関数が含まれます。
| 役職 | 予定 |
|---|
| 準備() | 準備する |
| 開始() | 打ち上げ |
| 停止() | やめて |
| StepTable() | テーブル表示ステップ |
| isComplete() | テスト完了 |
| GetResult() | 出力結果 |
main()関数は、各クラスのインスタンスを1つ作成し、実行を開始します。
各テストクラスは独自の実行スレッドを作成し、モジュールとのやり取りが行われます。 メイン関数は、クラスごとにPrepare()を呼び出します。 この関数内で、ストリームが作成され、メモリが割り当てられ、すべての準備が実行されます。 両方のクラスの準備が整ったら、開始が呼び出され、メインのテストサイクルが開始されます。 Ctrl-Cを押すか、指定されたテスト時間の終わりにStop()を呼び出します。 クラスは動作を停止し、isComplete()関数を使用してこれをmain()に通知します。 停止後、結果を取得するためにGetResult()が呼び出されます。 テスト中、メイン()関数は100ミリ秒ごとにStepTableを呼び出してテーブルを更新します。 これにより、データ交換を妨げることなくステータス情報を更新できます。
このアプローチは、テストプログラムの構築に非常に便利であることが判明しました。 ここでは、すべてのテストが同じテンプレートに基づいて構築されています。 結果として、それらは並行して実行することも、個別に実行することもできます。 このプログラムでは、テストの1つを同時に起動するモードと、同時に起動するモードの両方を簡単に構成できます。
OpenCLプログラム実行モード
SDAccelシステムは、プログラム実行の3つのモードを提供します。
- エミュレーションCPU-すべてがホストプロセッサで実行されます
- Emulation-HW-OpenCL関数はVivadoシミュレーターで実行
- システム-実際のハードウェアで動作します。
詳細については、前の記事をご覧ください 。
3つの環境の速度を比較することは興味深いです。 比較は非常に明白です:
| エミュレーションCPU | エミュレーションhw | システム |
|---|
| 200 MB /秒 | 0.1 MB /秒 | 2000 MB /秒 |
順序をわかりやすくするために、数値を丸めました。 実際、エミュレーションCPUとエミュレーションHWの速度の違いは、FPGAファームウェアの開発では、C / C ++などに切り替える必要があることを示しています。 4つの注文で勝つことは、C ++のすべての欠点をカバーしています。 VHDL / Verilogでの開発が消滅することはなく、これらの言語を使用して究極のパフォーマンスを実現する必要がある可能性が高いことに注意してください。 VHDL / VerilogでOpenCLカーネルを作成する可能性は非常に有望に見えます。これにより、高い開発速度と極端なFPGAパフォーマンスを組み合わせることができます。 しかし、これは別の研究と別の記事のトピックです。
トレース結果
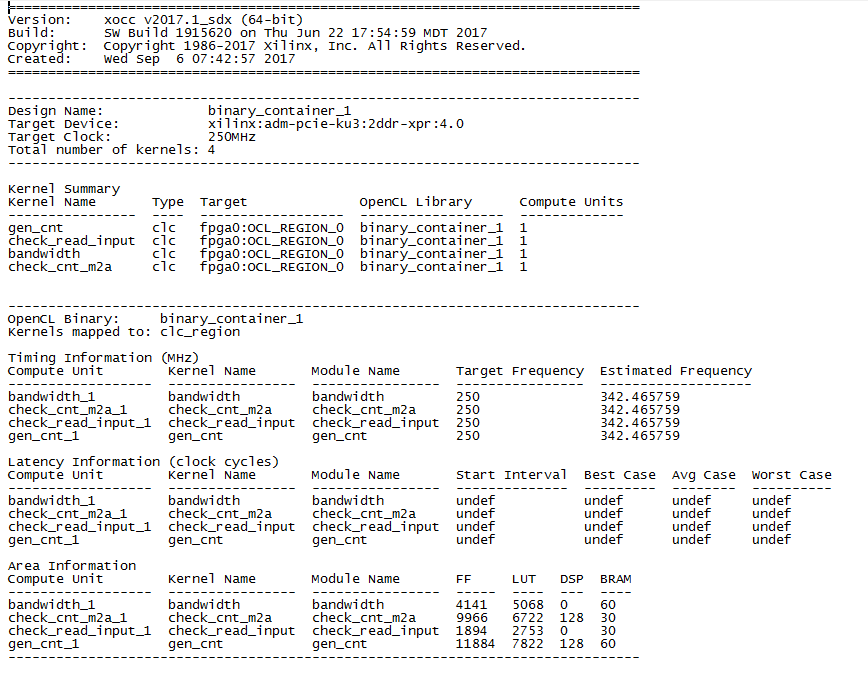
これが何が起こったのかです。 gen_cntのDSPの数に注意してください。 8個の64ビットカウンターを実装するには、128個のDSPブロックが必要でした。 これは、カウンターあたり16ブロックです。 おそらくこれは、オプティマイザーがサイクルの開示に取り組んでいる結果です。
FPGAとGPUの最適化方法の違い
最終的な結果を得るには、さまざまな最適化方法を適用する必要があります。 GPUの構造は固定されています。 相対的に言えば、1つのGPUプロセッサー要素が1つの操作を実行できる場合、100の操作を並列に実行するには、100のプロセッサー要素を使用する必要があります。 しかし、FPGAではこれが唯一のオプションではありません。 はい、1つのカーネルを記述し、FPGAに複数のインスタンスを配置できます。 しかし、これは大きなオーバーヘッドにつながります。 ザイリンクスでは、16個以下のカーネル、またはメモリポートを使用することをお勧めします。 ただし、1つの要素の内部には、並列化に関する制限はありません。 実際、gen_cntの例はこれを示しています。 そこには、8つの64ビット加算器がすぐにコードに書き込まれます。 さらに、オプティマイザーが機能し、ループを開始しました。 GPUの場合、この例は別の方法で記述する必要があります。たとえば、1つのカーネルを作成して64ビットの読み取り値を取得し、一度に8つのインスタンスを実行します。
エミュレーションHWが表示できるもの
このモードでは、メモリアクセスバスで何が起こっているかを表示できます。 この図は、check_read_input()関数を使用してメモリからデータを読み取るプロセスを示しています。
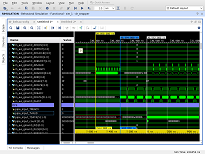
(クリックして拡大)
まず、データがどれだけ遅延するかを確認できます。 最初の要求から最初のデータまでの遅延は512 nsです。 第二に、読み取りは16ワード(サイズが512ビット)のブロックで実行されることがわかります。 VHDLで開発する場合、より大きなブロックサイズを使用します。 しかし、どうやらコントローラーはブロックを組み合わせることができ、これにより速度が低下することはありません。 第三に、データの受信にギャップがあることは明らかです。 それらも説明可能です。 OpenCLの動作周波数は250 MHz、SODIMM DDR3-1600のメモリバス周波数は200 MHzです。 ギャップは、200 MHzバスから250 MHzバスへの移行に正確に対応しています。
結果
結果はおもしろいですが、高速化が期待されています。
シングルテスト
| パソコン | 入力[MiB / s] | 出力[MiB / s] |
|---|
| Intel Core-i5、PCIe v2.0 x8 | 2048 | 1837 |
| Intel Core-i7、PCIe v3.0 x8 | 2889 | 2953 |
双方向テスト
| パソコン | 入力[MiB / s] | 出力[MiB / s] |
|---|
| Intel Core-i5、PCIe v2.0 x8 | 1609 | 1307 |
| Intel Core-i7、PCIe v3.0 x8 | 2048 | 2057 |
比較のために、同様のFPGAを使用したモジュールでは、記録入力速度は5500 MiB / sでしたが、いくつかの理由で5000に減らす必要がありました。したがって、交換速度を上げる機会があります。
次は何ですか
作業は継続されます。
- SDAccel 2017.2機能の調査
- Alexander Kapitanov( capitanov )によるFPFFTKライブラリに基づく畳み込みノードの実装
- 10Gイーサネットをサポートするものを含む、独自のDSAパッケージの開発
- そして最も重要なこと-独自のモジュールの開発、名前はすでに存在します-DSP135P
PSテストプログラムテンプレートの開発を支援してくれたウラジミールカラコゾフに感謝します。