機器および主要なソフトウェアの動作を監視することは、システム管理の基本です。 しかし、私たちは皆、それらを異なる方法で理解しています。 IT分野で10年以上働いてきた私の監視に対する姿勢は、次の3つの段階を経ています。
拒否します。 何も監視しないでください。ユーザー自身が問題が発生したときに通知します。
怒り 。 可能性と不可能性のすべてを監視し、あまり関心のない人を含む全員に、30秒以内にWebサーバーのCPU負荷が95%であることを通知します。
謙虚さ 。 プロセッサ/メモリ/ディスク上のビジネスを気にしないでください。 彼は、インフラストラクチャの変更後にそれが良くなったか悪くなったかにもっと興味を持っています。 事前に働かなければなりません。
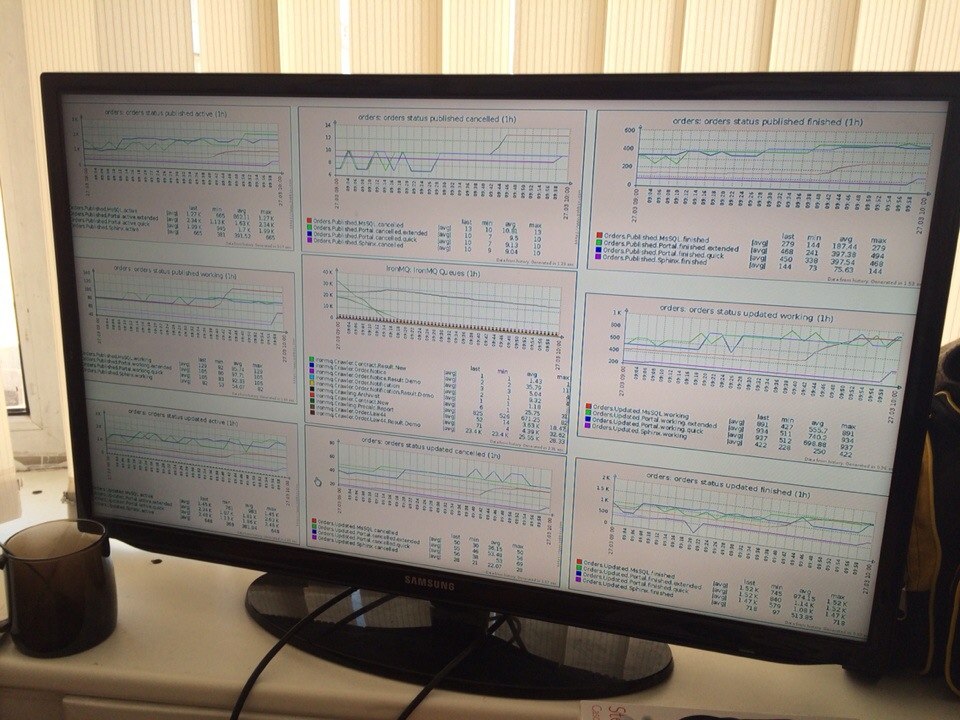
カットの下-私の関係の進化の詳細。
否認
それはすべて遠い昔の銀河で始まりました。 私は大学で学び、「あなたはプログラマーです」という2つの場所で働きました。
- 貿易および製造会社:3台のサーバー、10人のユーザー。 これらの写真には、サーバールームがあります。
- 州立大学:4台のサーバー、40人の仕事。

当時、私は監視のようなものの存在さえ疑いませんでした。 私は、何かが壊れた場合、あなたは単純に恥ずかしさに自分自身を投げ、問題を英雄的に解決できると心から信じていました。
当時の監視に対する私の姿勢は次のように説明できます。
- ユーザーが自分で何かが壊れたときに知らせてくれます。私たちは常にサイトで作業しているので、いつ壊れるかを確認します。 私は気にしません、プログラマーはそこに何かを書きました。
幸いなことに、この期間は長続きしませんでした-私はここで何かが間違っていたのではないかと疑い始めました。
怒り
得られた経験の影響で、監視の私のビジョンは変わり始めました。 このプロセスは、仕事の変更と一致しました。 大学と製造会社を辞めた後、私は大規模な外注会社で働き始めました。
- 最初の会社には3つのオフィス、100人のユーザー、1つのデータセンターのラック、2人のシステム管理者がいました。 サーバーパークは、私から5,000 kmにある100台のマシンで構成され、ホスティングには1,200台のクライアントがいました。
- 2番目の会社には400台のサーバーがあり、そこにはわずか12,000 km、2つの企業サイト、1人のシステム管理者がいました。

その時までに、私はすでにそれを考えていました:
- すべてを監視する必要があります。 誰も必要としないものを含む。 すべてのイベントは重要であり、それらに関する情報は最大人数に送信する必要があります。 上司を含む。 SMSで。 夜に。 サーバーのプロセッサが35秒間95%でロードされましたか? 説明する時間はありません。SMSを送信することが急務です。
同時に、ツールは積極的に開発および変換されました。 当初、すべての種類のメトリック(空き領域、利用可能な更新の数、バックアップの結果など)を制御するスクリプトが多数あり、サードパーティサービスのRed Alert、Lazy Farmer(社内開発-サイト検証サービスを置き換える試み)もありました。
この構成では、監視システムは約1年間存在していましたが、この間に多くの欠点が明らかになりました。
- スクリプトによる多数のサーバー遅延。
- 不明なリソース使用率。
- 問題の原因を見つけるのは難しいです。
問題は、あなたの人生をどのように簡素化するかでした。 Dude / Nagios / Zabbixでオプションを検討しています。 選択の主な基準は展開の速度であり、選択はZabbixにかかっていました。
その中で、すべてが監視に置かれ、手が届きました:
- WiFiに接続しているユーザーの数。
- プリンターで印刷されたページの数。
- ルーターの空きメモリ。
- ルーター上のVPNトンネルの数。
- サーバーの温度。
- サーバーのカバーを開きます。
- スイッチのネットワークインターフェイスのビジネス。
- ...などなど。
また、実装の機能について言及し、Zabbixと連携したいと思います。
- サーバーは遠く離れており、多くのメトリックがあります。 ギャップが現れ始めたとき、彼らはZabbixプロキシを導入しました。
- トンネルがクラッシュすると、サーバーが使用できないことを示すアラートが大量に生成されるため、依存関係を構成する必要がありました。
- アラートを使用して同じタイプのアクションを自動化しました。最初に、システムは(ディスクのクリーニングなどのために)自動的にそれを修正しようとし、障害が発生した場合にのみアラートを送信します。 アラートに対する反応時間を短縮するために、SMS配信を設定しました。
- SMSの形で24時間アラートが送信されるのを防ぐために、サーバーに5秒間CPUが100%でロードされたというアラートを構成する必要はありません。
- 複雑なメトリックを監視する場合、プロセスのリソース消費により一部の値が失われました。 データは監視サーバーに送信されましたが、すべてを登録する時間はありませんでした。
- Sphinxには、構成を変更できるサービスがたくさんあります。 新しいサーバーは自動的に検出および監視されます。 Webサーバーが実行されている場合もありますが、ユーザーにはページではなく図が表示されます。 そのような場合、Web上でユーザースクリプトを実行し、問題が発生した場合は、システムがアラートを送信しました。
- 通常、顧客はすべてのタスク/問題を1か所に表示したいので、ビジネスプロセスにとって重要なイベントが発生したときにタスクを作成しました。
- 未処理の例外のコレクションは長くて退屈なので、イベントが発生すると、イベントログでそれを処理し、タスクを作成しました。
- 顧客は手紙を読まないため、Skype(zabbix2skype)で手紙を書きました。
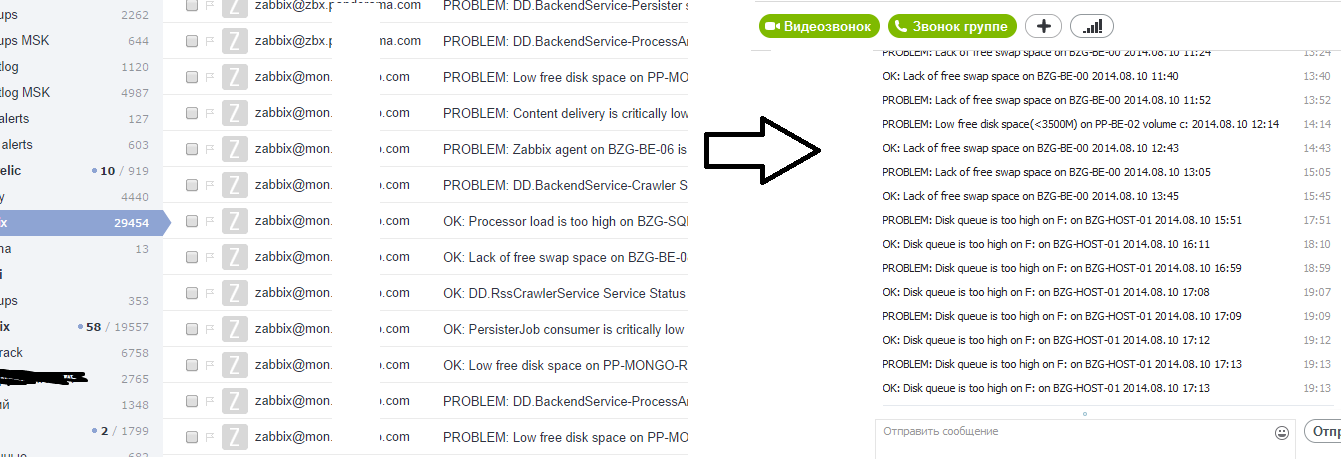
- Quis custodiet ipsos custodes? 誰が監視を監視しますか? 自分の答えを見つけられませんでした。
謙um
数年後、私は謙虚になりました。 繰り返しますが、この期間は仕事の変更と部分的に一致しました。 3つのデータセンター、数千台のサーバー、数千人の従業員、ロシア連邦全体のオフィスだけでなく。
私は、ビジネスはCPUの負荷やその他の技術的な詳細に関心がないことに気付きました。 所有者と管理者は、他のカテゴリーで考えます:ダウンタイム/情報システム/利益の損失...
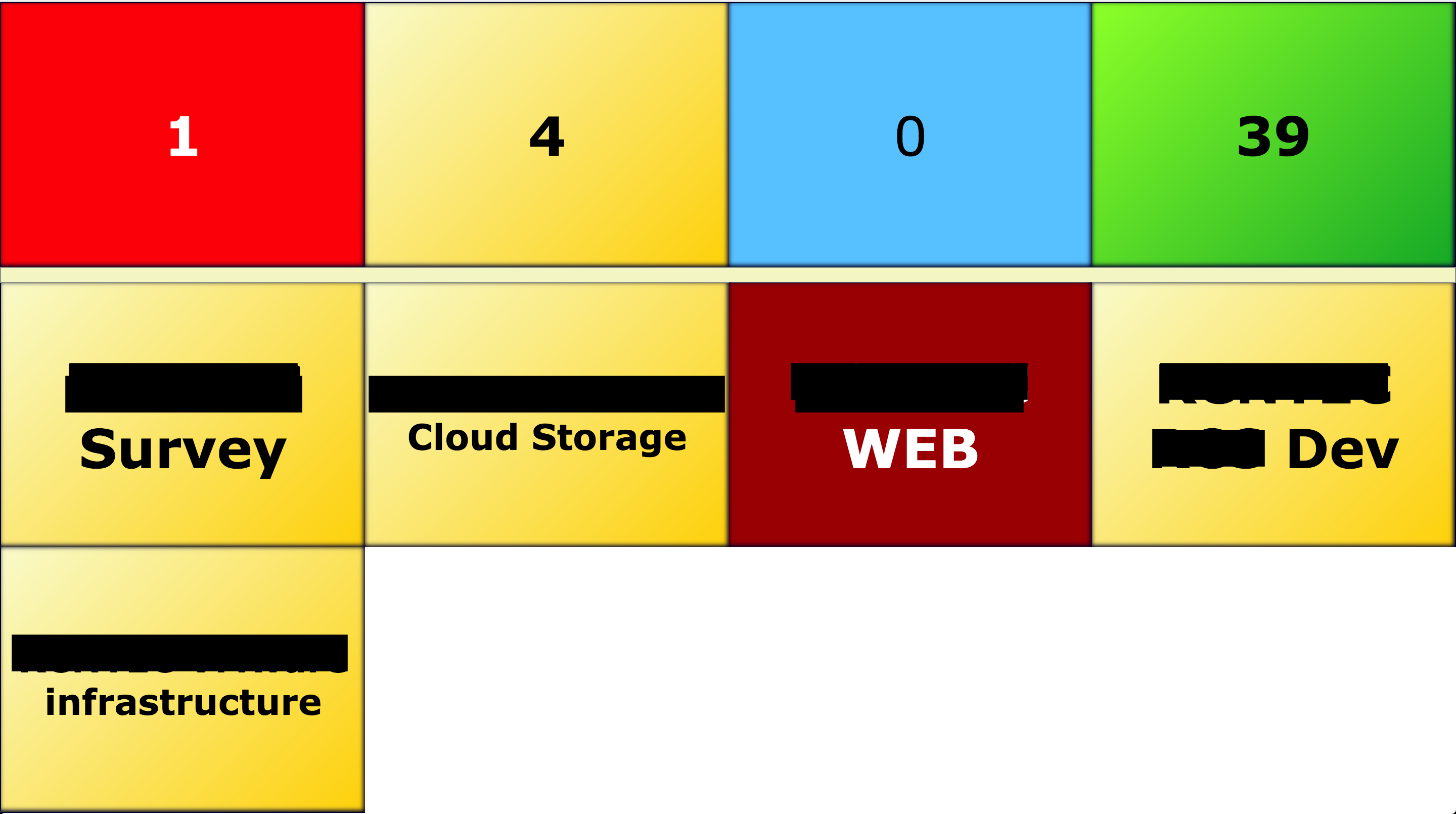
Zabbixが好きでしたが、顧客のビジネスと緊密に統合する他のシステム(サードパーティのソリューション、ファイルによって大幅に変更された、または自己記述型)があることを知りました。
私が思いついた主なアイデア:誰もが同じ絵を見て関係を理解できるように、サーバーを情報システムに結合する必要があります。
- すべてを頭の中に入れることはできません。インフラストラクチャに関する知識のリポジトリが必要です(サーバーの責任者、所在場所など)。監視設定(エージェントの代わりにSNMP)を簡素化および統合する必要があります。
- 監視システムには、ITの専門家でなくても状況を理解できる使いやすいインターフェイスがあることが重要です。
- 情報システムが機能しない場合、これは3泊で全員に警告を発する理由にはなりません。 許容されるダウンタイムとリアクションの期間について顧客と交渉する必要があります。
- 特効薬はありません。追跡するメトリックを選択するとき、通知ルールを作成するとき、一般的なアクションを自動化するときなどに妥協する必要があります。
そのため、要するに、監視の概念、その目的、および実装方法が進化しました。 もちろん、このプロセスは、私が働いていた会社や私と一緒に働いていた人々の一般的な状況に大きく影響されました。
UPD: ロシア語版