TL DR
この記事では、HashicorpのSwarm、Kubernetes、およびNomadに投票するDockerアプリケーションをデプロイします。 このすべてを試してみたのと同じくらい、この記事を読んで楽しんでください。
テクノロジーを使用する場合は、好奇心が必要です。 これは、現場で何が起こっているかを常に学び、最新の状態に保つために必要です。 すべてが非常に速く変化します。
コンテナオーケストレーションは議論の対象として非常にホットなトピックであるため、お気に入りの楽器があったとしても、他の楽器がどのように機能し、それらについて新しいことを学ぶのは興味深いことです。
投票アプリ
以前の記事で投票アプリを使用しました。 アプリケーションはマイクロサービスアーキテクチャで実行され、5つのサービスで構成されています。

- 投票:ユーザーが犬と猫を選択できるフロントエンド
- Redis:音声データベース
- ワーカー:大根から投票を収集し、結果をPostgresデータベースに保存するサービス
- Db:投票結果を保存するPostgresデータベース
- 結果:フロントエンドは投票結果を表示します
githubリポジトリにあるように、アプリケーションにはいくつかの構成ファイルがあります:
https :
//github.com/dockersamples/example-voting-appDocker-stack.yml-アプリケーションの本番プレゼンテーションで使用する準備ができました。 ファイル自体は次のとおりです。
version: "3" services: redis: image: redis:alpine ports: - "6379" networks: - frontend deploy: replicas: 1 update_config: parallelism: 2 delay: 10s restart_policy: condition: on-failure db: image: postgres:9.4 volumes: - db-data:/var/lib/postgresql/data networks: - backend deploy: placement: constraints: [node.role == manager] vote: image: dockersamples/examplevotingapp_vote:before ports: - 5000:80 networks: - frontend depends_on: - redis deploy: replicas: 2 update_config: parallelism: 2 restart_policy: condition: on-failure result: image: dockersamples/examplevotingapp_result:before ports: - 5001:80 networks: - backend depends_on: - db deploy: replicas: 1 update_config: parallelism: 2 delay: 10s restart_policy: condition: on-failure worker: image: dockersamples/examplevotingapp_worker networks: - frontend - backend deploy: mode: replicated replicas: 1 labels: [APP=VOTING] restart_policy: condition: on-failure delay: 10s max_attempts: 3 window: 120s placement: constraints: [node.role == manager] visualizer: image: dockersamples/visualizer:stable ports: - "8080:8080" stop_grace_period: 1m30s volumes: - "/var/run/docker.sock:/var/run/docker.sock" deploy: placement: constraints: [node.role == manager] networks: frontend: backend: volumes: db-data:
通常、このファイルには6つのサービスがあり、アプリケーションアーキテクチャには5つのサービスしかありません追加のサービスは、サービスが展開されている場所を示すインターフェイスを提供する優れたツールであるビジュアライザーです。
Docker swarm
Docker Swarmは、Dockerコンテナーのクラスターを管理および作成するためのツールです。 管理者と開発者は、Swarmを使用して、ノードのクラスターを単一の仮想システムとして作成および管理できます。Swarmコンポーネント
Swarmクラスターはいくつかのノードで構成され、一部はマネージャーとして機能し、他はエグゼキューターとして機能します。
- 管理ノードはクラスターの内部状態を担当します
- ノードの実行はタスクを実行します(=コンテナーの起動)
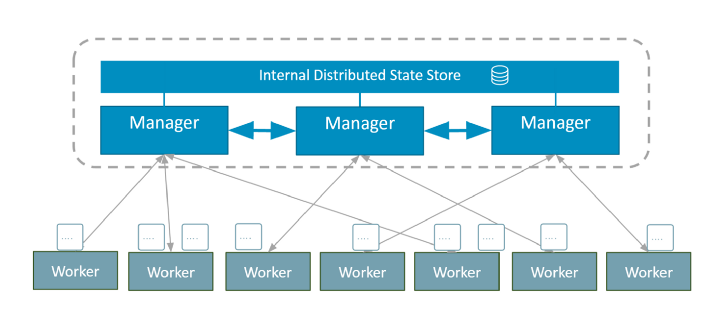
マネージャーは、内部分散ストレージを共有して、一貫したクラスター状態を維持します。 これは、Raftログによって確認されます。
Swarmでは、サービスはアプリケーションのデプロイ方法とコンテナ内での動作方法を定義します。
Dockerをインストールする
Dockerがまだインストールされていない場合は、OS用の
Docker CE(Community Edition)を
ダウンロードでき
ます 。
Swarmを作成する
Dockerをインストールすると、1つのチームだけがSwarmの実行から私たちを分離します
$ docker swarm initSwarmクラスターに必要なのはこれだけです。 これは単一ノードのクラスターですが、関連するすべてのプロセスを持つクラスターのままです。
アプリケーションの展開
githubのアプリケーションリポジトリで利用可能な構成ファイルのうち、Swarmを介してアプリケーションをデプロイするにはdocker-stack.ymlが必要です。
$ docker stack deploy -c docker-stack.yml app Creating network app_backend Creating network app_default Creating network app_frontend Creating service app_visualizer Creating service app_redis Creating service app_db Creating service app_vote Creating service app_result Creating service app_worker
スタックはポピーのドッカーで実行されているため、ローカルマシンからすぐにアプリケーションにアクセスできます。 投票インターフェース(ポート5000)を使用して猫または犬を選択し、ポート5001で結果を確認できます。
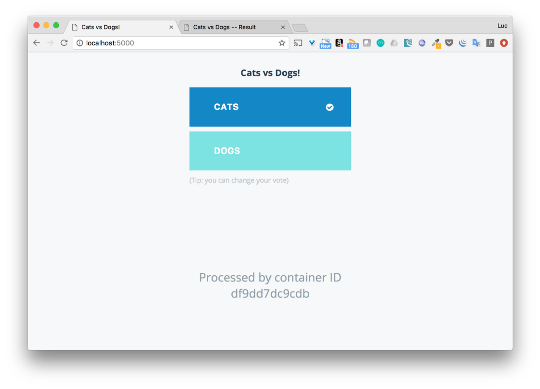
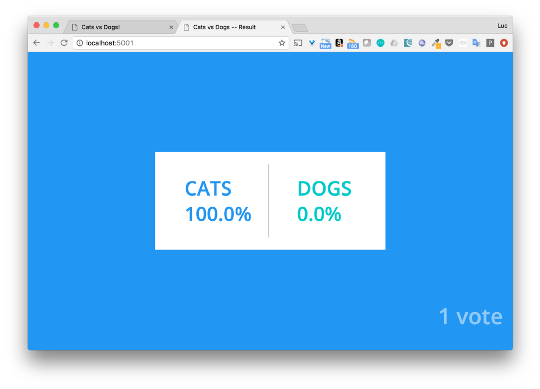
ここでは詳細に立ち入らず、Swarmを使用してアプリケーションを簡単にデプロイできることを示したかっただけです。
複数のノードを使用してSwarmを介してアプリケーションをデプロイする方法の詳細な説明が必要な場合は、
この記事を読むことができます。
クベルネテス
Kubernetesは、コンテナ化されたアプリケーションの展開、スケーリング、および管理を自動化するためのオープンソースプラットフォームです。Kubernetes Concept
Kubernetesクラスターは、1つ以上のマスターとノードで構成されます。
- ウィザードは、クラスターの管理(クラスターの状態の管理、タスクのスケジューリング、クラスター内のイベントへの応答など)を担当します。
- ノード(以前はミニオンと呼ばれていました。はい、漫画「怪盗グルーの月泥棒」のように)は、アプリケーションコンテナーを起動するためのランタイムを提供します(ポッド経由)
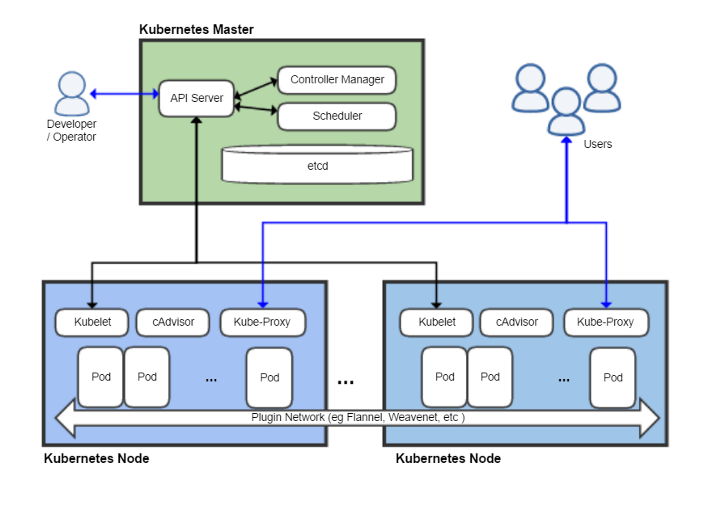
コマンドを入力するには、kubectl CLIを使用します。 以下では、いくつかの使用例を検討します。
アプリケーションのデプロイ方法を理解するには、いくつかの高レベルのKubernetesオブジェクトについて知る必要があります。
- ポッドは、ノードに展開できる最小単位です。 これは、連携して動作するコンテナのグループです。 ただし、Podにはコンテナが1つだけ含まれていることがよくあります。
- ReplicaSetは、特定の数の炉床レプリカを提供します。
- DeploymentはReplicaSetを管理し、ローリングアップデート、ブルー/グリーンデプロイメント、テストなどを可能にします。
- サービスは、ハースの論理セットとそれらにアクセスするためのポリシーを定義します。
このパートでは、アプリケーションサービスごとに展開とサービスを使用します。
kubectlをインストールする
Kubectlは、Kubernetesでアプリケーションを展開および管理するためのコマンドラインです。
インストールには、公式ドキュメント(https://kubernetes.io/docs/tasks/tools/install-kubectl/)を使用します。 たとえば、Macにインストールするには、次のコマンドを入力します。
$ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectlミニキューブのインストール
MinicubeはKubenetesの包括的な設定です。 ローカルVMを作成し、すべてのKubernetesプロセスが実行されているノードクラスターを起動します。 間違いなく、これは運用クラスタをインストールするために使用すべきツールではありませんが、開発とテストに使用すると本当に便利です。
Minicubeをインストールすると、1つのノードでクラスターをインストールするために必要なコマンドは1つだけです。
$ minikube start
Starting local Kubernetes v1.7.0 cluster…
Starting VM…
Downloading Minikube ISO
97.80 MB / 97.80 MB [==============================================] 100.00% 0s
Getting VM IP address…
Moving files into cluster…
Setting up certs…
Starting cluster components…
Connecting to cluster…
Setting up kubeconfig…
Kubectl is now configured to use the cluster.記述子Kubernetes
Kubernetesでは、
Deploymentによって制御される
ReplicaSetを介してコンテナーが起動されます。
以下は
Deploymentを説明する.ymlファイルの例です。
ReplicaSetは、2つの
Nginxレプリカの起動を提供します。
// nginx-deployment.yml apiVersion: apps/v1beta1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 # tells deployment to run 2 pods matching the template template: # create pods using pod definition in this template metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
展開を作成するには、kubectl CLIを使用する必要があります。
マイクロサービスで構成されるアプリケーションを作成するには、サービスごとに展開ファイルを作成する必要があります。 これは手動で行うことも、
Komposeを使用することもできます。
Komposeを使用してデプロイメントとサービスを作成する
Komposeは、Docker構成ファイルをKubernetesが使用する記述子ファイルに変換するツールです。 このサービスの方が便利で、移行プロセスを高速化します。
注:
Komposeはオプションで、すべてを手動で作成できますが、展開プロセスを大幅に高速化します
- Komposeは、Docker Composeファイルで使用されるすべてのオプションを考慮しません。
- Komposeは、次のコマンドを使用してLinuxまたはMacにインストールできます。
# Linux
$ curl -L https://github.com/kubernetes/kompose/releases/download/v1.0.0/kompose-linux-amd64 -o kompose
# macOS
$ curl -L https://github.com/kubernetes/kompose/releases/download/v1.0.0/kompose-darwin-amd64 -o kompose
$ chmod +x kompose
$ sudo mv ./kompose /usr/local/bin/komposeKomposeでdocker
-stack.ymlを開始する前に、少し変更して各サービスのデプロイキーを削除します。 このキーは認識されないため、記述子ファイルの生成時にエラーが発生する場合があります。 ネットワークに関する情報を削除することもできます。 Komposeでは、docker
-stack-k8s.ymlを呼び出す新しいファイルを
提供します。
version: "3" services: redis: image: redis:alpine ports: - "6379" db: image: postgres:9.4 volumes: - db-data:/var/lib/postgresql/data vote: image: dockersamples/examplevotingapp_vote:before ports: - 5000:80 depends_on: - redis result: image: dockersamples/examplevotingapp_result:before ports: - 5001:80 depends_on: - db worker: image: dockersamples/examplevotingapp_worker visualizer: image: dockersamples/visualizer:stable ports: - "8080:8080" stop_grace_period: 1m30s volumes: - "/var/run/docker.sock:/var/run/docker.sock" volumes: db-data:
docker-stack-k8s.ymlファイルから、次のコマンドを使用してアプリケーションの記述子
を生成します。
$ kompose convert --file docker-stack-k8s.yml
WARN Volume mount on the host "/var/run/docker.sock" isn't supported - ignoring path on the host
INFO Kubernetes file "db-service.yaml" created
INFO Kubernetes file "redis-service.yaml" created
INFO Kubernetes file "result-service.yaml" created
INFO Kubernetes file "visualizer-service.yaml" created
INFO Kubernetes file "vote-service.yaml" created
INFO Kubernetes file "worker-service.yaml" created
INFO Kubernetes file "db-deployment.yaml" created
INFO Kubernetes file "db-data-persistentvolumeclaim.yaml" created
INFO Kubernetes file "redis-deployment.yaml" created
INFO Kubernetes file "result-deployment.yaml" created
INFO Kubernetes file "visualizer-deployment.yaml" created
INFO Kubernetes file "visualizer-claim0-persistentvolumeclaim.yaml" created
INFO Kubernetes file "vote-deployment.yaml" created
INFO Kubernetes file "worker-deployment.yaml" created各サービスについて、展開ファイルとサービスが作成されることがわかります。
警告は1つだけ受け取りました。 Dockerソケットに接続できないため、
ビジュアライザーと接続されます。 このサービスの開始は試みませんが、残りに焦点を合わせます。
アプリケーションの展開
kubectlを使用して、記述子ファイルで指定されたすべてのコンポーネントを作成します。 ファイルが現在のフォルダーにあることを示します。
$ kubectl create -f .
persistentvolumeclaim "db-data" created
deployment "db" created
service "db" created
deployment "redis" created
service "redis" created
deployment "result" created
service "result" created
persistentvolumeclaim "visualizer-claim0" created
deployment "visualizer" created
service "visualizer" created
deployment "vote" created
service "vote" created
deployment "worker" created
service "worker" created
unable to decode "docker-stack-k8s.yml":...注:変更した構成ファイルを現在のフォルダーに残したため、解析できないためエラーが発生しました。 しかし、この間違いはリスクなしで無視できます。これらのコマンドを使用すると、作成された
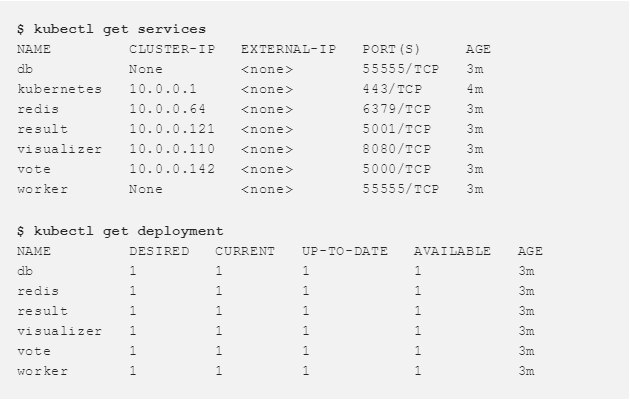
サービスと
デプロイメントを確認できます。
外の世界からアプリケーションにアクセスできるようにします
投票と
結果のインターフェースにアクセスするには、それらのために作成されたサービスをわずかに変更する必要があります。
投票用に生成された記述子は次のとおりです。
apiVersion: v1 kind: Service metadata: creationTimestamp: null labels: io.kompose.service: vote name: vote spec: ports: - name: "5000" port: 5000 targetPort: 80 selector: io.kompose.service: vote status: loadBalancer: {}
サービスのタイプを変更し、
ClusterIPを
NodePortに置き換えます。
ClusterIPはサービスを内部で利用可能にし、
NodePortはポートをクラスターの各ノードで公開し、世界中で利用できるようにします。
投票と
結果の両方に外部からアクセスできるようにする
ため 、
resultに対しても同じことを行います。
apiVersion: v1 kind: Service metadata: labels: io.kompose.service: vote name: vote spec: type: NodePort ports: - name: "5000" port: 5000 targetPort: 80 selector: io.kompose.service: vote
両方のサービス(
投票と
結果 )に変更を加えたら、それらを再作成できます。
$ kubectl delete svc vote
$ kubectl delete svc result
$ kubectl create -f vote-service.yaml
service "vote" created
$ kubectl create -f result-service.yaml
service "result" createdアプリケーションへのアクセス
次に、
投票および
結果サービスの詳細を取得し、それらが提供するポートを取得します。
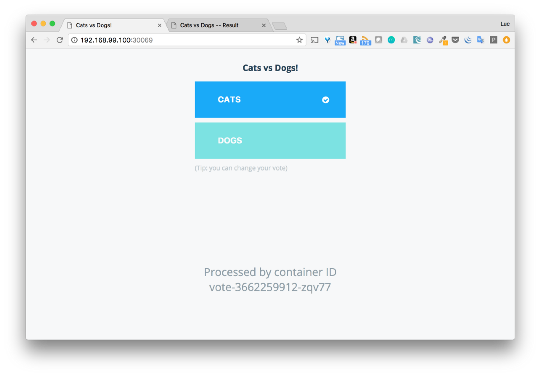
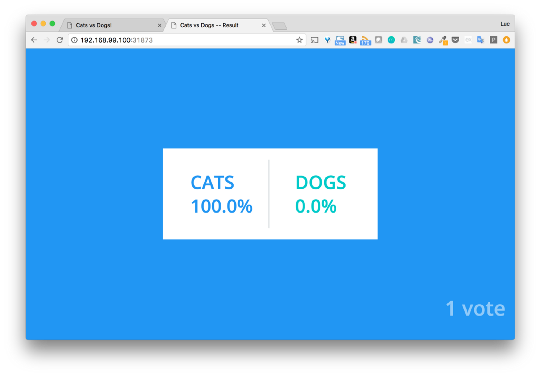
 投票
投票はポート30069で利用でき、
結果は31873です。今度は投票して結果を確認します。
Kubernetesの基本コンポーネントを理解した後、アプリケーションを簡単にデプロイできました。 Komposeは私たちを大いに助けてくれました。
ハシコープの遊牧民
Nomadは、マシンのクラスターを管理し、それらでアプリケーションを実行するためのツールです。 マシンとアプリケーションホストを抽象化し、ユーザーが実行したいことを言うことができるようにします。 そして、Nomadは、それがどこでどのように起動されるかについて責任を負います。ノマドコンセプト
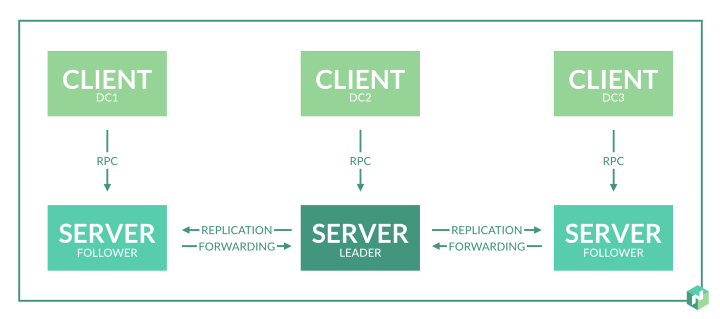
Nomadクラスターは、
サーバー (サーバー)モードまたは
クライアント (クライアント)モードで動作できる
エージェントで構成されています。
- サーバーはコンセンサスプロトコルを担当します 。これにより、サーバーはリーダーを選択し、状態を複製できます。
- クライアントはサーバーと対話するため非常に軽量ですが、クライアント自体はほとんど何もしません。 クライアントノードはタスクを実行します。
Nomadクラスターでは、いくつかのタイプのタスクを起動できます。
アプリケーションをデプロイするには、Nomadの基本概念を理解する必要があります。
- ジョブ-Nomadが実行するタスクを決定します。 これは、ジョブファイル(hclテキストファイル、Hashicorp構成言語)で説明されています。 ジョブには1つ以上のタスクグループが含まれる場合があります。
- グループには、同じマシン上にあるいくつかのタスクが含まれます。
- タスク-実行中のプロセス、この場合はDockerコンテナー
- ジョブ内のタスクのマッピングは、割り当てを使用して行われます。 割り当ては、ジョブ内のタスクが特定のノードで実行されるようにするために使用されます。
設置
この例では、Docker Machineを使用して作成されたDockerホストでアプリケーションを実行します。 ローカルIP-192.168.1.100。 まず、Consulを実行します。Consulは、サービスの検出と登録に使用されます。 Nomadを起動し、アプリケーションをJob in Nomadとしてデプロイします。
サービスの登録と発見のための領事
サービスを検出して登録するには、NomadのJobのように機能しないConsulなどのツールをお勧めします。 領事
はリンクからダウンロードできます。
このコマンドは、Consulサーバーをローカルで起動します。
$ consul agent -dev -client=0.0.0.0 -dns-port=53 -recursor=8.8.8.8使用されるオプションを詳しく見てみましょう。
- -devは、サーバーとクライアントでConsulクラスターを設定するフラグです。 このオプションは、開発とテストにのみ使用してください。
- -client = 0.0.0.0を使用すると、ホストインターフェイスを介してConsulサービス(APIおよびDNSサーバー)に到達できます。 これは、Nomadがlocalhostインターフェイスを介してConsulに接続し、docker-bridge(172.17.x.xなど)を介してコンテナに接続するために必要です。
- -dns-port = 53は、Consul DNSサーバーが使用するポートを定義します(デフォルトは8600)。 DNSをコンテナから使用できるように、標準の53ポートをインストールします。
- -recursor = 8.8.8.8は、Consulが処理できない要求を処理する別のDNSサーバーを定義します
Nomadは
このリンクからダウンロードできます。
ノードを持つクラスターを作成する
Nomadをダウンロードしたら、次の設定でエージェントを起動できます。
// nomad.hcl bind_addr = "0.0.0.0" data_dir = "/var/lib/nomad" server { enabled = true bootstrap_expect = 1 } client { enabled = true network_speed = 100 }
エージェントはサーバーとクライアントの両方として機能します。
bind_addrは、タスクを外部から受け入れることができるように、どのインターフェイスでも動作する必要があることを指摘します。 次の設定でNomad Agentを起動します。
$ nomad agent -config=nomad.hcl
==> WARNING: Bootstrap mode enabled! Potentially unsafe operation.
Loaded configuration from nomad-v2.hcl
==> Starting Nomad agent...
==> Nomad agent configuration:
Client: true
Log Level: INFO
Region: global (DC: dc1)
Server: true
Version: 0.6.0
==> Nomad agent started! Log data will stream in below:注:デフォルトでは、NomadはローカルのConsulインスタンスに接続します。単一ノードクラスターをインストールしました。 一意のメンバーに関する情報は次のとおりです。
$ nomad server-members
Name Address Port Status Leader Protocol Build Datacenter Region
neptune.local.global 192.168.1.100 4648 alive true 2 0.6.0 dc1 globalアプリケーションの展開
Swarmを使用してアプリケーションをデプロイするには、すぐに構成ファイルを使用できます。 Kubernetesを介してデプロイするには、同じ構成ファイルからの記述子が必要です。 これはすべて、Nomadを通じてどのように行われますか?
まず、Kompose for Hashicorpに似たツールはありません。そのため、コンマのNomadへの移行を簡単にすることができます(ちなみに、オープンソースプロジェクトにとっては良い考えです)。
Jobs 、
groups 、
tasksを記述するファイルは手動で作成
する必要があります。
これについては、
Redisおよび
Voteサービスのジョブについて説明する際に詳しく見ていきます。 他のサービスについては、このようになります。
Redisのジョブの定義
このファイルは、アプリケーションのRedisの一部を定義します。
// redis.nomad job "redis-nomad" { datacenters = ["dc1"] type = "service" group "redis-group" { task "redis" { driver = "docker" config { image = "redis:3.2" port_map { db = 6379 } } resources { cpu = 500 # 500 MHz memory = 256 # 256MB network { mbits = 10 port "db" {} } } service { name = "redis" address_mode = "driver" port = "db" check { name = "alive" type = "tcp" interval = "10s" timeout = "2s" } } } } }
ここに何が書かれているか見てみましょう:
- ジョブ名-redis-nomad
- ジョブの種類-サービス(つまり、長時間の操作)
- グループには任意の名前が付けられます。 1つの操作を含む
- タスクRedisはdocker-driverを使用します。つまり、コンテナーで実行されます。
- タスクはRedisイメージを使用します:3.2
- リソースを含むブロックでは、CPUとメモリの制限が示されます。
- ネットワークブロックは、dbポートが動的でなければならないことを示します
- サービスブロックは、Consulの登録方法を定義します。サービスの名前、IPアドレス、およびヘルスチェックの定義
ジョブが正しく実行されるかどうかを確認するには、
planコマンドを使用します。
$ nomad plan redis.nomad + Job: "nomad-redis" + Task Group: "cache" (1 create) + Task: "redis" (forces create) Scheduler dry-run: - All tasks successfully allocated. Job Modify Index: 0 To submit the job with version verification run: nomad run -check-index 0 redis.nomad When running the job with the check-index flag, the job will only be run if the server side version matches the job modify index returned. If the index has changed, another user has modified the job and the plan's results are potentially invalid.
すべてが機能しているようです。 次に、このジョブを使用してタスクを展開します。
$ nomad run redis.nomad ==> Monitoring evaluation "1e729627" Evaluation triggered by job "nomad-redis" Allocation "bf3fc4b2" created: node "b0d927cd", group "cache" Evaluation status changed: "pending" -> "complete" ==> Evaluation "1e729627" finished with status "complete"
プレースメントが作成されたことがわかります。 彼のステータスを確認してください:
$ nomad alloc-status bf3fc4b2 ID = bf3fc4b2 Eval ID = 1e729627 Name = nomad-redis.cache[0] Node ID = b0d927cd Job ID = nomad-redis Job Version = 0 Client Status = running Client Description = <none> Desired Status = run Desired Description = <none> Created At = 08/23/17 21:52:03 CEST Task "redis" is "running" Task Resources CPU Memory Disk IOPS Addresses 1/500 MHz 6.3 MiB/256 MiB 300 MiB 0 db: 192.168.1.100:21886 Task Events: Started At = 08/23/17 19:52:03 UTC Finished At = N/A Total Restarts = 0 Last Restart = N/A Recent Events: Time Type Description 08/23/17 21:52:03 CEST Started Task started by client 08/23/17 21:52:03 CEST Task Setup Building Task Directory 08/23/17 21:52:03 CEST Received Task received by client
コンテナは正しく起動されています。 Consul DNSサーバーをチェックして、サービスも正しく登録されていることを確認しましょう。
$ dig @localhost SRV redis.service.consul ; <<>> DiG 9.10.3-P4-Ubuntu <<>> @localhost SRV redis.service.consul ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 35884 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 2 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;redis.service.consul. IN SRV ;; ANSWER SECTION: redis.service.consul. 0 IN SRV 1 1 6379 ac110002.addr.dc1.consul. ;; ADDITIONAL SECTION: ac110002.addr.dc1.consul. 0 IN A 172.17.0.2 ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Wed Aug 23 23:08:36 CEST 2017 ;; MSG SIZE rcvd: 103
タスクはIP 172.17.0.2によってホストされ、そのポートは先に示したように6379です。
投票のための仕事の定義
投票サービスのジョブを定義します。 次のファイルを使用します。
// job.nomad job "vote-nomad" { datacenters = ["dc1"] type = "service" group "vote-group" { task "vote" { driver = "docker" config { image = "dockersamples/examplevotingapp_vote:before" dns_search_domains = ["service.dc1.consul"] dns_servers = ["172.17.0.1", "8.8.8.8"] port_map { http = 80 } } service { name = "vote" port = "http" check { name = "vote interface running on 80" interval = "10s" timeout = "5s" type = "http" protocol = "http" path = "/" } } resources { cpu = 500 # 500 MHz memory = 256 # 256MB network { port "http" { static = 5000 } } } } } }
ただし、Redisに使用したファイルとはいくつかの違いがあります。
- 投票は操作名のみを使用してredisに接続します。 投票サービスで使用されるapp.pyファイルの一部の例を次に示します。
// app.py def get_redis(): if not hasattr(g, 'redis'): g.redis = Redis(host="redis", db=0, socket_timeout=5) return g.redis
この場合、
redisを使用してIPコンテナーを
取得するには 、
投票の あるコンテナーがConsul DNSサーバーを使用する必要があります。 コンテナからのDNSクエリは、Dockerブリッジ(172.17.0.1)を介して実行されます。
dns_search_domainsは、サービスXがConsul内のX.service.dc1.consulとして登録されていることを判別します
- ポート5000の投票サービスがクラスターの外部からアクセスできるように、静的ポートを設定します。
他のサービスに対して同じ設定を行うことができます:worker、postgres、result。
アプリケーションへのアクセス
すべてのジョブが実行されている場合、ジョブのステータスを確認し、すべてが機能することを確認できます。
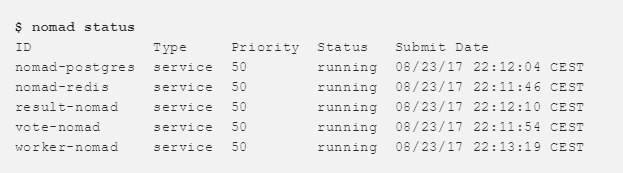
これは、Consulインターフェースでも見ることができます。
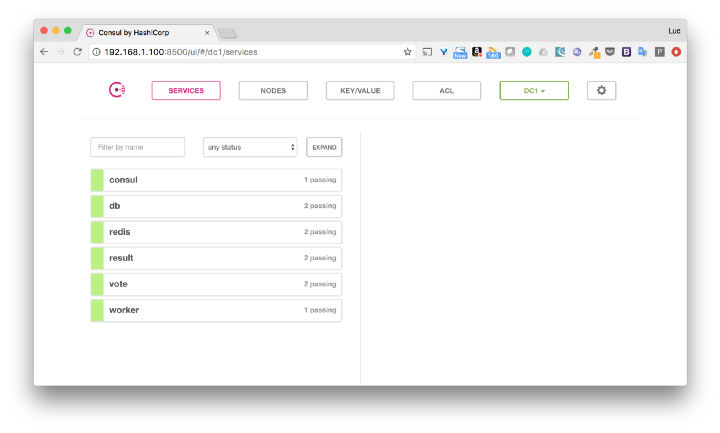
IPノード(この例では192.168.1.100)
により 、
voteおよび
resultを使用してインターフェースにアクセスできます。
まとめ
ここに、そのような投票投票がデモンストレーションの面で素晴らしいアプリケーションです。 オーケストラを使用してコードを変更せずに展開できるかどうかを知りたいと思いました。 はい、タンバリンとの特別なダンスがなくてもできます。
この記事がSwarm、Kubernetes、Nomadの基本を理解するのに役立つことを願っています。 また、Dockerで起動しているものとオーケストラの使用方法を知ることも興味深いでしょう。