ANTLRは、主要なプログラミング言語の1つで文法記述用のパーサーを作成できるパーサージェネレーターです。 Java自体で書かれており、Javaでうまく機能します。
チュートリアル:
1)Oracle Java JDKおよびIntellij Ideaをインストールし(すでにインストールされている場合はこの手順をスキップできます)、Intellij Ideaを実行します
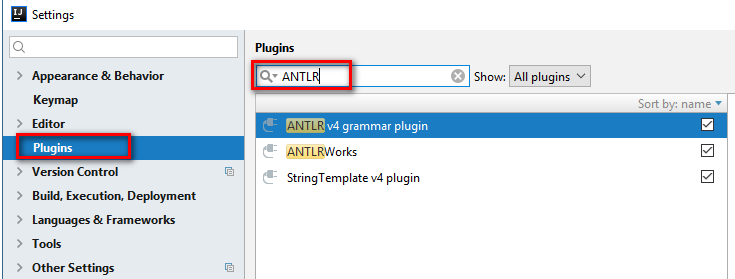
2)ファイル設定プラグイン

検索フィールドにANTLRと入力し、ANTLR v4文法プラグインをインストールします。 すべてのリポジトリで追加の検索が必要になる場合があります。
3)Mavenプロジェクトの場合、pom.xmlに追加するか、新しいプロジェクトを作成します。
依存関係で
<dependency> <groupId>org.antlr</groupId> <artifactId>antlr4-runtime</artifactId> <version>4.7</version> </dependency>
およびプラグインで
<plugin> <groupId>org.antlr</groupId> <artifactId>antlr4-maven-plugin</artifactId> <version>4.7</version> <executions> <execution> <goals> <goal>antlr4</goal> </goals> </execution> </executions> </plugin>
詳細https://github.com/antlr/antlr4/blob/master/doc/java-target.md
4)次に、拡張子が.g4の文法ファイルを作成して手動で追加します。 ファイル名は、最初の行の文法の後の単語と一致する必要があります。 ほぼ次のように構成されています。解析する必要があるものを取得し、個別のトークンに分割します。 トークンについては、たとえば、すべての英字[a-zA-Z];、すべての数字[0-9]などのトークンを記述します。たとえば、ファイルHello.g4の公式サイトからサンプルの内容を取得しました。
// Define a grammar called Hello grammar Hello; r : 'hello' ID ; // match keyword hello followed by an identifier ID : [az]+ ; // match lower-case identifiers WS : [ \t\r\n]+ -> skip ; // skip spaces, tabs, newlines
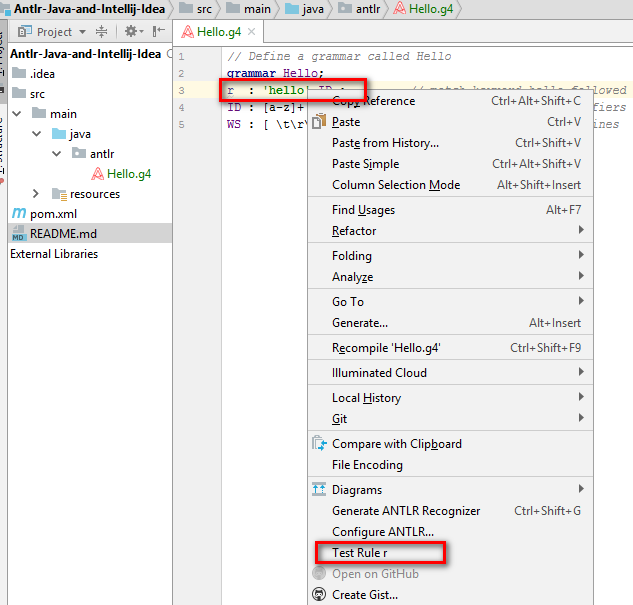
5)次に、rで始まるファイルの2行目を右クリックし、メニュー項目Test Rule rを選択します
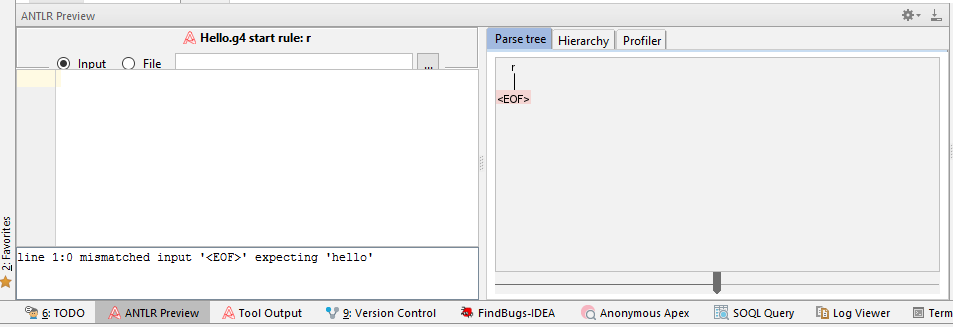
文法チェッカーウィンドウが下に開きます。 この場合、プラグインはエラーを表示します。これはおそらく、これがテストケースであるという事実によるものですが、パーサーが生成されます。 これについてはhttps://github.com/antlr/antlr4/issues/118で読むことができますが、今のところは無視してください。 しかし、実際のプロジェクトでは、これらのエラーにもっと注意を払う必要があります。
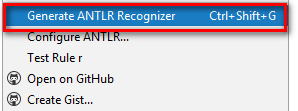
6)右マウスボタンで文法ファイルをクリックし、[Configure ANTLR Recoqnizer]メニュー項目を選択して、パーサーを生成します
その後、成功メッセージが右下隅に表示されます
7)次に、ファイルをもう一度右クリックして、[Configure ANTLR]メニュー項目を選択し、
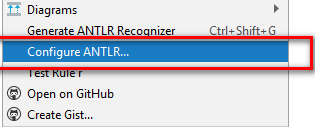
ファイル生成を設定するためのウィンドウが表示されます
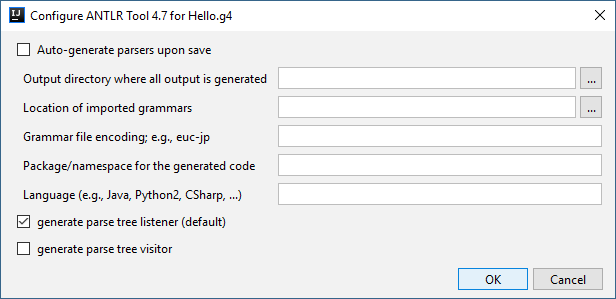
このウィンドウで、宛先フォルダーとプログラミング言語(この場合はJava)、訪問者またはリスナーが必要かどうか、およびその他の必要な情報に関するデータを入力し、「OK」をクリックします。
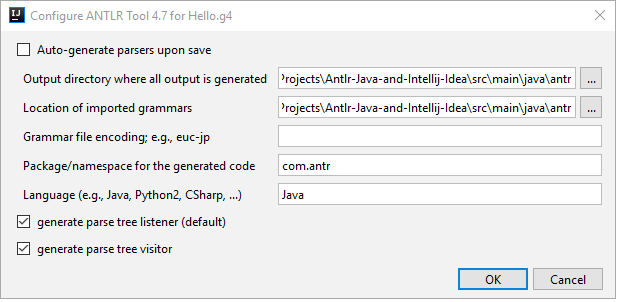
そして、ANTLRは認識用のファイルを生成します。 ただし、出力ディレクトリは指定されていますが、多くの場合、プロジェクトのルートに新しいgenフォルダーが作成され、javaはこれらのファイルを認識しません。
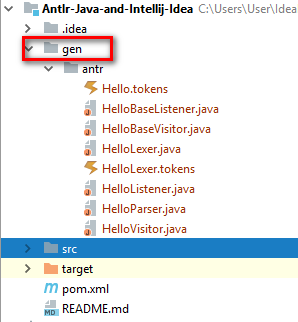
Javaでこれらのファイルを表示するには、genフォルダーの「Generated Sources Root」で「Mark Directory As」とマウスの右ボタンでマークする必要があります。

そして、次のようになります。
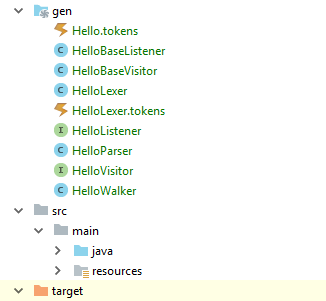
8)ANTLRは次のクラスを生成しました。
HelloParser.javaクラスは、パーサークラス、つまりHello文法に対応するパーサーの説明です。
public class HelloParser extends Parser { ... }
HelloLexer.javaクラスは、HelloInit文法に対応するレクサークラスまたはレキシカルアナライザーの説明です。
public class HelloLexer extends Lexer { ... }
Hello.tokens、HelloLexer.tokensは、トークンに関する情報を含むヘルパークラスですHelloListener.java、HelloBaseListener.java、HelloBaseVisitor、HelloVisitorは、構文ツリーを走査するときに特定のアクションを実行できるメソッドの説明を含むクラスです
9)その後、HelloWalkerクラスを追加します(このクラスはオプションですが、このコードを変更してMainに追加し、情報を表示できます)
public class HelloWalker extends HelloBaseListener { public void enterR(HelloParser.RContext ctx ) { System.out.println( "Entering R : " + ctx.ID().getText() ); } public void exitR(HelloParser.RContext ctx ) { System.out.println( "Exiting R" ); } }
10)そして最後に、メインクラス-プログラムへのエントリポイント
public class Main { public static void main( String[] args) throws Exception { HelloLexer lexer = new HelloLexer(CharStreams.fromString("hello world")); CommonTokenStream tokens = new CommonTokenStream(lexer); HelloParser parser = new HelloParser(tokens); ParseTree tree = parser.r(); ParseTreeWalker walker = new ParseTreeWalker(); walker.walk(new HelloWalker(), tree); } }
11)mainメソッドを実行し、コンソールの出力で正常に解析された解析を取得します
Entering R : world Exiting R
→プロジェクトコードはこちらに掲載されています