
こんにちは トラフィックソースを分析するためのタスクの1つの実装に基づいて、マーケティング担当者向けの説明記事を作成することにしました。 これは、マーケティング担当者がGoogleアナリティクスAPIなしではできない場合です。 この記事はWeb開発者の利益のために書かれているため、マーケティング担当者は「すべてのゴミ」に気を取られません。
実用的な例で技術に精通します。 行こう!
挑戦する
サイトには約150,000人のユーザーが登録されています。 10月に製品を購入した1,500人のユーザーがどのソースから来たのかを理解する必要があります。
見込み客を引き付けるために、フリーミアムモデルを使用します。販売サイクルは最大1年です。
追加設定から、Googleアナリティクスの統合段階で、ユーザー
IDを接続し、その値を
カスタムディメンション1 (スコープ:ユーザー)に複製して、レポートでUserIDを操作できるようにしました。
解決策
アルゴリズム
必要な最初のソースを決定するには:
- Query Explorerサービスを開きます。
- 認証を行い、アカウント、プロパティ、ビューを選択します。
- レポートをコンパイルするには:
- 終了日 :ユーザー登録日+ 5日(念のためマージンを付けて)
- 開始日 :ユーザー登録日-25日(マージンがある場合、ユーザーは登録前にサイトと対話できます)
- 指標 :ga:セッション
- 寸法 :
ga:sourceMedium-ソース/チャンネル
ga:dateHourMinute-時刻。日付、時間、分を含みます。 - sort :ga:dateHourMinute-最初のセッションが最初の行に表示されるようにします。
- フィルター :ga:dimension1 == 158384-ユーザーID。
- 次のようになります。
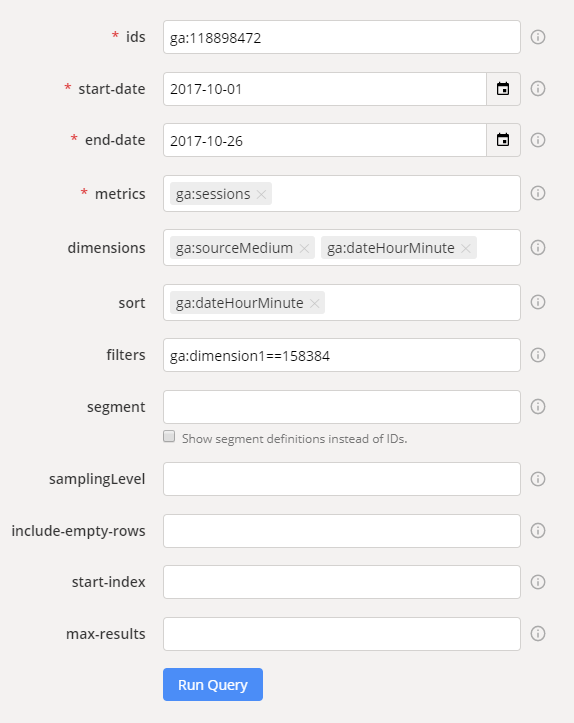
- [クエリの実行]をクリックして、クエリを実行します。
結果
リクエストを実行すると、結果の表が表示されます:

すなわち 登録前の一定の期間に、最初のセッションはソースyandex / organicからのものであったことがわかります。
一人のユーザーのために。 しかし、1500の自動化のために組み立てる方法は?
自動化
クエリ結果のあるテーブルの下には、2つのテキストフィールドがあります。
このレポートおよび
クエリURI API への直接リンク 。
「
現在のaccess_tokenを含める... 」というチェックマークが付いた2番目のフィールドに興味があり
ます 。
フィールドの内容はおよそ次のとおりです。
https://www.googleapis.com/analytics/v3/data/ga?ids=ga%3A118898472&start-date=2017-10-01&end-date=2017-10-26&metrics=ga%3Asessions&dimensions=ga%3AsourceMedium%2Cga%3AdateHourMinute&sort=ga%3AdateHourMinute&filters=ga%3Adimension1%3D%3D158384&access_token=ya29.Gl30BMgGpR89kexsBJS8VMIWimIEghKVHubx9iQH7RljCyQNLjX2LLBQ9AyCCRW9K0TjfJEvwe6qY3SIRKbkm8idMZjdygbN647O7JUgXqcGyDt5b63Y2FjDbeQabfA
ブラウザでリンクを開くと、リクエストをJSON形式で実行した結果が表示されます。
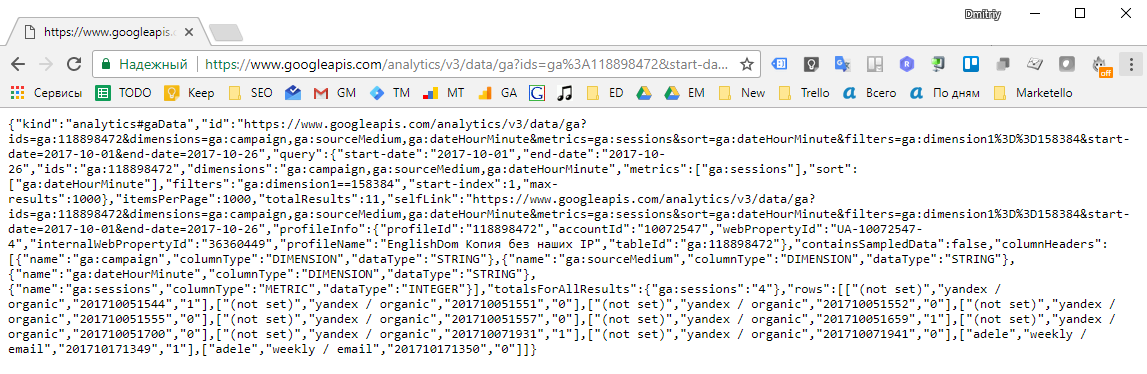
すなわち クエリURLのデータdimension1、start-date、end-dateを置き換える-ユーザーごとにこのような情報を取得できます。
ユーザーデータファイル
次の形式の行を含む通常のtxtファイルを作成しました(UserID start-date end-date):
123456 2017-10-01 2017-10-26 123457 2017-10-02 2017-10-27
開始日と終了日の準備は簡単です-ExcelまたはGoogleスプレッドシートで:
開始日:=日付(年(B2)、月(B2)、日(B2)-25)
終了日:=日付(年(B2)、月(B2)、日(B2)+5)
ここで、B2はユーザー登録の日付のセルです。
スクリプトを作成する
Pythonを言語として選択しました-単に私が現在それを学んでいるからです。
スクリプト操作アルゴリズム:
- ユーザー情報を含むファイルを開きます。
- ファイルの各行は「タブ」で分割されます。
- Query Explorerで作業するときに受け取ったQuery Stringの文字列からデータを置き換えます。
- このリンクから情報を取得します。
- 応答テキストをJSONに変換して、対話できるようにします。
- 各ユーザーの回答のバックアップを作成します。これはusers /%userID%.txtに保存されます
- 「行」セクションを循環してみましょう。
- うまくいった場合は、画面にユーザーIDとソース/メディアを書き込みます。
- うまくいかない場合は、UserIDを書き込むだけです。
import json import requests with open('users_regs.txt') as f: for line in f: value = line.split("\t") source = 'https://www.googleapis.com/analytics/v3/data/ga?ids=ga%3A118898472&start-date=' + value[1] +'&end-date=' + value[2].strip('\n') +'&metrics=ga%3Asessions&dimensions=ga%3AsourceMedium%2Cga%3AdateHourMinute&sort=ga%3AdateHourMinute&filters=ga%3Adimension1%3D%3D' + value[0] +'&access_token=ya29.Gl3wBOWAecjWj4GgW0Gj920Sx2SBtVBkCHZjOsPNu6MWnN1XnsNwwzVzPVBcdVwDf_7lWJd0mege38pP1PSNvc9aBA7wbndUn-h6vqS5bbbEhSOKHp4cjQvVSQiN5R4' r = requests.get(source) l = json.loads(r.text) with open('users/' + value[0]+'.txt', 'w') as outfile: json.dump(l, outfile) try: for row in l["rows"]: print(value[0] + " " + row[0]) break except: print(value[0]) メトリクス= GAの%3Asessions&寸法= GA%3AsourceMedium%2Cga%3AdateHourMinute&ソート= GA%3AdateHourMinute&フィルター= GA%3Adimension1%3D%3D' +値[ import json import requests with open('users_regs.txt') as f: for line in f: value = line.split("\t") source = 'https://www.googleapis.com/analytics/v3/data/ga?ids=ga%3A118898472&start-date=' + value[1] +'&end-date=' + value[2].strip('\n') +'&metrics=ga%3Asessions&dimensions=ga%3AsourceMedium%2Cga%3AdateHourMinute&sort=ga%3AdateHourMinute&filters=ga%3Adimension1%3D%3D' + value[0] +'&access_token=ya29.Gl3wBOWAecjWj4GgW0Gj920Sx2SBtVBkCHZjOsPNu6MWnN1XnsNwwzVzPVBcdVwDf_7lWJd0mege38pP1PSNvc9aBA7wbndUn-h6vqS5bbbEhSOKHp4cjQvVSQiN5R4' r = requests.get(source) l = json.loads(r.text) with open('users/' + value[0]+'.txt', 'w') as outfile: json.dump(l, outfile) try: for row in l["rows"]: print(value[0] + " " + row[0]) break except: print(value[0]) h6vqS5bbbEhSOKHp4cjQvVSQiN5R4' import json import requests with open('users_regs.txt') as f: for line in f: value = line.split("\t") source = 'https://www.googleapis.com/analytics/v3/data/ga?ids=ga%3A118898472&start-date=' + value[1] +'&end-date=' + value[2].strip('\n') +'&metrics=ga%3Asessions&dimensions=ga%3AsourceMedium%2Cga%3AdateHourMinute&sort=ga%3AdateHourMinute&filters=ga%3Adimension1%3D%3D' + value[0] +'&access_token=ya29.Gl3wBOWAecjWj4GgW0Gj920Sx2SBtVBkCHZjOsPNu6MWnN1XnsNwwzVzPVBcdVwDf_7lWJd0mege38pP1PSNvc9aBA7wbndUn-h6vqS5bbbEhSOKHp4cjQvVSQiN5R4' r = requests.get(source) l = json.loads(r.text) with open('users/' + value[0]+'.txt', 'w') as outfile: json.dump(l, outfile) try: for row in l["rows"]: print(value[0] + " " + row[0]) break except: print(value[0])
スクリプトファイルの名前はga.pyです。
コマンドラインからスクリプトを実行し、結果を楽しみます。
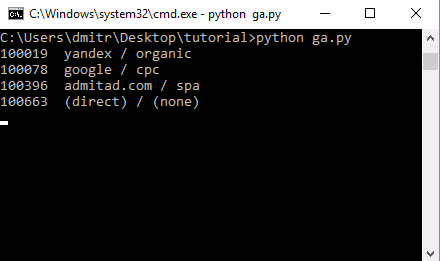
スクリプトの結果は端末に表示され、さらに処理するためにそれらをコピーするだけです。
スクリプトは例として提示されており、自分で結果を単一のファイルまたはデータベースに保存できます。
大量のデータを使用する場合-1時間に1回、新しいトークンを生成し(クエリエクスプローラーを再度開き、[クエリの実行]をクリックして)、スクリプト内のクエリ文字列を置換する必要があります。
頑張って!
リーダーボーナス
オンライン講座
オンラインコースを使用して3か月間の英語学習を無料でご利用いただけます。 これを行うには、2017年12月31日まで
リンクをたどるだけです。
Skype経由で個別に
ITプロフェッショナル向け英語コースの個別レッスンでお会いできることを嬉しく思います。
無料の入門レッスンを受講して、知識レベルに関する包括的なフィードバックを得てから、好みの教師とトレーニングプログラムを選択してください。