Robots.txtは、サーバーからダウンロードできるファイルとダウンロードできないファイルを世界中のWebクローラーに伝えます。 彼はインターネット上の最初の番人のようです-要求をブロックしませんが、要求しないように頼みます。 興味深いことに、robots.txtファイルは、自動化されたプロセスがサイトでどのように機能するかについてのウェブマスターの仮定を示しています。 ボットはそれらを簡単に無視できますが、クローラーの動作方法の理想的な動作を示します。
基本的に、これらは非常に重要なファイルです。 そこで私は、地球上で最も訪問された100万のサイトのそれぞれからrobots.txtファイルをダウンロードし、どのパターンが見つかるかを確認することにしました。
Alexaから最大100万のサイトのリストを取得し、各ドメインからrobots.txtファイルをダウンロードする
小さなプログラムを作成しました。 すべてのデータをダウンロードした後、各ファイルをpythonパッケージ
urllib.robotparserに渡し 、結果の調査を開始しました。
 yangteacher.ru/robots.txtで見つかりました
yangteacher.ru/robots.txtで見つかりましたフェンスで囲まれた庭園:Google以外のすべての人を禁止
私のお気に入りのペットには、Googleボットのみがコンテンツのインデックスを作成し、他のすべての人を禁止するサイトがあります。 たとえば、Facebookサイトのrobots.txtファイルは次の行で始まります。
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php
(警告:Facebookのクロールは書面による許可なしでは禁止されていますhttp://www.facebook.com/apps/site_scraping_tos_terms.php参照してhttp://www.facebook.com/apps/site_scraping_tos_terms.php )Facebook自体がハーバード大学のウェブサイト上で学生のクロールを操作し始めたため、これはやや偽善的です。まさにこの種の活動が、他のすべての人を禁止しているのです。
サイトをクロールする前の書面による許可の要件は、開かれたインターネットの理想を直接表しています。 科学的研究を妨げ、新しい検索エンジンの開発に障害をもたらします。たとえば、DuckDuckGo検索エンジンはFacebookページをダウンロードできませんが、Google検索エンジンはダウンロードできます。
この振る舞いを示すサイトに名前を付けて恥をかかせたいという衝動的な衝動で、ドメインをチェックし、Googleがメインページのインデックスを作成できるユーザーをホワイトリストに登録したユーザーを識別する
簡単なスクリプトを書きました。 これらのドメインの中で最も人気のあるものは次のとおりです。
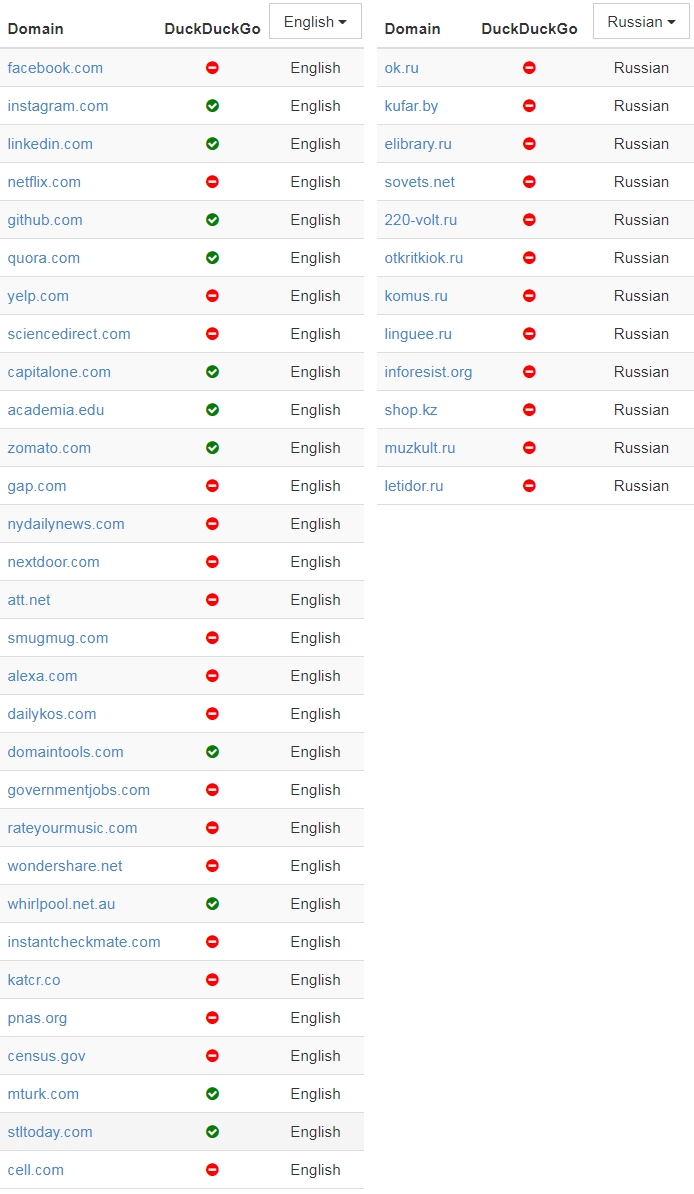 ( 元の記事には、中国語、フランス語、ドイツ語のドメインの同様のリストも記載されています-約Per。)
( 元の記事には、中国語、フランス語、ドイツ語のドメインの同様のリストも記載されています-約Per。)最近の新しい検索エンジンの難しさを示すために、サイトがDuckDuckGoのフロントページのインデックスを許可するかどうかを表に記載しました。
リストの一番上にあるほとんどのドメイン(Facebook、LinkedIn、Quora、Yelpなど)には共通点が1つあります。 それらはすべて、ビジネスの中心的な価値であるユーザー生成コンテンツをホストします。 これは主要な資産の1つであり、企業は無料で提供したくないと考えています。 しかし、公平を期すために、
クロールを禁止する決定に関するFacebookテクニカルディレクターの声明や
、Quoraの
robots.txtファイルの奥深くで
、サイトがWayback Machineを禁止した理由を説明するように、こうした禁止はユーザーのプライバシーを保護するものとしてしばしば提示され
ます 。
リストの下に行くと、結果がより矛盾するようになります。たとえば、
census.govが3つの主要な検索エンジンによるコンテンツへのアクセス
のみを許可するが、DuckDuckGoをブロックする理由は完全にはわかりません。 国勢調査のデータは、Google / Microsoft / Yahooだけでなく、人々のものであると想定するのは論理的です。
私はこの行動のファンではありませんが、悪意のあるボットの数を考えると、特定のクローラーのみをホワイトリストに登録する衝動的な試みを理解できます。
悪い行動のボット
私は別の何かを試してみたかったです:100万個のrobots.txtファイルの集合的な意見を考慮して、インターネット上の最悪のWebクローラーを特定してください。 これを行うために、特定のユーザーエージェントが完全に禁止している異なるドメインの数を計算し、このインジケーターでランク付けしました。
リストには、いくつかの特定のタイプのボットが含まれています。
最初のグループは、SEOおよびマーケティング分析のためにデータを収集するクローラーです。 これらの企業は、分析のためにできるだけ多くのデータを取得することを望んでおり、多くのサーバーに顕著な負荷をかけています。 Ahrefsボット
は、 「
AhrefsBotはGooglebotに次いで2番目にアクティブなクローラーです 」と
自慢しているため、これらの迷惑なボットをブロックしたい理由は明らかです。 Majestic(MJ12Bot)は、競争力のあるインテリジェンスツールとしての地位を確立しています。 これは、競合他社に有益な情報を提供するためにサイトをダウンロードすることを意味します-また、メインページでは「
世界最大のリンクインデックス 」であると主張
しています 。
ユーザーエージェントの2番目のグループは、個人的にオフラインで使用するためにWebサイトをすばやくダウンロードしようとするツールからのものです。
WebCopier 、
Webstripper、 Teleportなどのツールはすべて、Webサイトの完全なコピーをハードドライブにすばやくダウンロードします。 問題は、マルチスレッドのダウンロードの速度です。これらのツールはすべて明らかにトラフィックを詰まらせ、サイトが頻繁にそれらを禁止します。
最後に、Baidu(BaiduSpider)やYandexのような検索エンジンがコンテンツを積極的にインデックスに登録できますが、特定のサイトにとって必ずしもあまり価値のない言語/市場にしか対応していません。 個人的には、これら両方のクローラーが大量のトラフィックを生成しているため、それらをブロックすることはお勧めしません。
求人広告
これは、ロボットによって読み取られることを目的としたファイルに、ソフトウェア開発者、特にSEOスペシャリスト向けの求人広告が含まれることが多い時代の兆候です。
ある意味では、これはrobots.txtファイルの説明だけで構成される世界で最初の(そしておそらく唯一の)ジョブ交換です。
( 元の記事では、robots.txtファイルの67個の空室すべてのテキストを示しています。最も禁止されているボットの2番目の開発者である
Ahrefs.comも
、robots.txtファイルに SEOスペシャリストを検索するための広告を掲載しているという事実には皮肉があり
ます 。 また、pricefalls.comでは、「警告:書面による許可がない場合、価格下落クロールは禁止されています」というエントリの後に
robots.txtファイルでの作業の発表が続き
ます 。
この記事のコードはすべて
GitHubにあります 。