最近
、AWSの年間メンテナンスで100万ドル以上を
節約する方法について話しました。 さまざまな問題と解決策について詳しく話しましたが、最も一般的な質問は「AWSにあまりにも多くを費やしていることは知っていますが、これらの費用をどうやって理解可能な部分に分割できるのでしょうか?」
一見したところ、問題は非常に単純に思えます。
AWSの費用を数か月ごとに簡単に分類し、そこで終了できます。 EC2で1万ドル、S3で1000ドル、ネットワークトラフィックで500ドルなど。 しかし、何か重要な欠落があります-製品と開発グループの組み合わせが、コストの大部分を占めています。
そして、数百のインスタンスと数百万のコンテナが変更される可能性があることに留意してください。 すぐに、最初は単純な分析問題のように見えたものが、想像を絶するほど複雑になります。
この記事の続きでは、私たちが使用する一連のツールに関する情報を共有したいと思います。 インスタンスが数個あるか数万個あるかに関係なく、AWSコストの分析方法に関するいくつかのアイデアを提供できることを願っています。
「製品ライン」によるグループ化
AWSで大規模な操作を行う場合、おそらく2つの問題に既に直面しているでしょう。
第一に、開発グループの1つが突然予算を増やした場合、気付くことは困難です。
AWSの請求書は月額10万ドルを超えており、各AWSコンポーネントのコストは急速に変化しています。 特定の週ごとに、5つの新しいサービスを展開し、DynamoDBのパフォーマンスを最適化し、数百の新しいクライアントを接続できます。 この状況では、1つのチームが先月よりもEC2に今月20,000ドル多く費やしたという注意を逃しがちです。
第二に、新しい顧客サービスにかかる費用を予測することは困難です。
明確にするために、当社のセグメントは、データウェアハウス、S3、または企業の内部情報システム内のサードパーティツールに分析データを送信する単一のAPIを提供しています。
顧客は必要なトラフィック量と使用する製品を非常に正確に予測しますが、この予測を特定の金額に換算する際に常に問題が発生しています。 理想的には、「100万の新しいAPI呼び出しにはXドルかかるため、クライアントから少なくともYドルを取得する必要があります。」
この問題の解決策は、インフラストラクチャを「製品ライン」と呼ぶものに分割することでした。 私たちの場合、これらの指示は次のように漠然と定式化されています。
- 統合(セグメントからさまざまな分析プロバイダーにデータを送信するコード)。
- API(クライアントライブラリからセグメント内のデータを受信するサービス)。
- データウェアハウス(セグメントデータをユーザーデータウェアハウスにロードするパイプライン)。
- WebサイトとCDN。
- 内部システム(上記のすべての共通ロジックおよびサポートシステム)。
プロジェクト全体を分析すると、
ここですべてを測定
することはほとんど不可能であるという結論に達し
ました 。 その代わりに、アカウントのコストの一部、たとえば80%を追跡し、これらのコストを最初から最後まで追跡するタスクを設定します。
企業がアカウントの80%を分析することは、100%を目指してデータ収集の段階で行き詰まって結果を出さないことよりも便利です。 コストの80%をカバーすること(「これで十分」と言う意欲)により、何度も何度もデータを選択する必要がなくなり、1ドルの節約にはなりません。
収集してから分析
製品エリアごとにコストを分類するには、請求システムのデータをダウンロードする必要があります。つまり、次のデータを収集し、その後結合します。
- AWS CSVの請求情報は、すべての費用項目でAWSを生成するCSVです。
- ラベル付きAWSリソース—請求CSVでタグ付けできるリソース。
- ラベルのないリソースは、「製品ライン」でリソースの消費をマークするために特別なデータパイプラインを必要とするEBSやECSなどのサービスです。
このすべてのデータの製品ラインを特定したら、それらをRedshiftで分析するためにロードできます。
1. AWS CSV請求書
コストの分析は、AWSからのCSVファイルの解析から始まります。
請求ポータルで対応するオプションを有効にできます。Amazonは、毎日S3に詳細な請求情報を含むCSVファイルを保存します。
詳細とは、非常に詳細な意味です。 レポートの典型的な行は次のとおりです。
record_type | 明細
record_id | 60280491644996957290021401
product_name | Amazon DynamoDB
rate_id | 0123456
subscription_id | 0123456
価格設定プランID | 0123456
usage_type | USW2-TimedStorage-ByteHrs
操作| 標準ストレージ
availability_zone | us-west-2
reserved_instance | N
item_description | 最初の25 GBの無料GB月を超えて使用されるGB月あたり0.25ドル
usage_start_date | 2017-02-07 03:00:00
usage_end_date | 2017-02-07 04:00:00
usage_quantity | 6e-08
blended_rate | 0.24952229400
blended_cost | 0.00000001000
unblended_rate | 0.25000000000
unblended_cost | 0.00000001000
resource_id | arn:aws:dynamodb:us-west-2:012345:table / a-table
statement_month | 2017-02-01
これは、2月7日の夜3:00から4:00の間の唯一のテーブルをDynamoDBデータベースに格納するための、0.00000001という驚くべき金額、つまり100万分の1のアカウントです。 通常、CSVにはこのようなレコードが約600万件含まれています。 (
残念なことに、それらのほとんどは100万分の1セントよりも重要な量です )。
S3からRedshiftにデータを転送するには、Herokuの
awsdetailedbillingツールを使用します。 これは開始するのに適した場所ですが、特定のAWSコストを製品ラインに関連付ける通常の方法がありませんでした(つまり、統合またはデータウェアハウジングに特定のインスタンス時間を使用しました)。
さらに、コストの約60%はEC2にあります。 これはコストの大部分を占めますが、AWSが生成するCSVからのみEC2インスタンスと特定の製品ライン間の接続を理解することは絶対に不可能です。
インスタンスの名前だけで製品ラインを識別できなかった重要な理由があります。 実際、ホストで1つのプロセスを開始する代わりに、
ECS(Elastic Container Service)を集中的に使用してホストに
数百のコンテナーを配置し、リソースを大幅に集中的に使用しています。
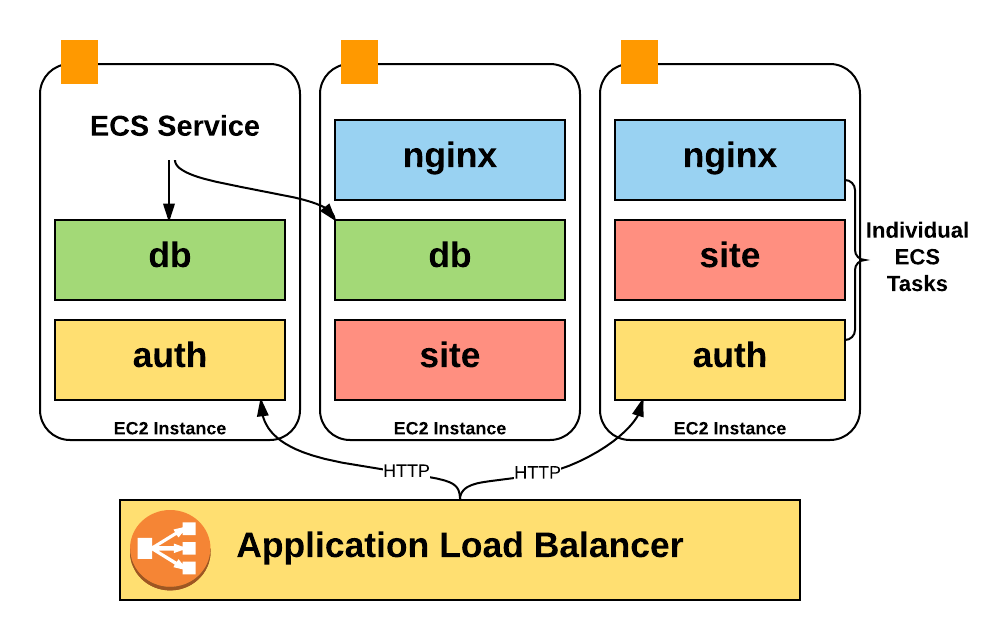
残念ながら、AmazonアカウントにはEC2インスタンスのコスト
しか含まれていないため、インスタンスで実行されているコンテナーのコストに関する情報はありませんでした:定期的に実行されていたコンテナーの数、使用したプールの部分、関与したCPUおよびメモリユニットの数。
さらに悪いことに、CSVの
どこにもコンテナの自動スケーリングに関する情報が反映されてい
ません 。 このデータを分析用に取得するには、情報を収集するための独自のツールを作成する必要がありました。 次の章では、このパイプラインの仕組みについて詳しく説明します。
ただし、AWS CSVファイルは、サービスの使用に関する非常に優れた詳細データを提供し、これが分析の基礎となりました。 それらを当社の製品ラインに接続するだけです。
注:この問題はどこにも行きません。 インスタンスクロックの請求は、「何にお金を使うのか」という質問の観点からますます懸念されるようになります。これは、ECS、Kubernetes、Mesosなどのシステムを使用する多数のインスタンスで多くのコンテナーを起動する企業が増えているためです。 EC2の各インスタンスは、同じ物理サーバー上の他のインスタンスと連携して動作するXenハイパーバイザーであるため、Amazon自体が長年にわたってこの問題を正確に経験しているという事実には皮肉があります。2. AWSタグ付きリソースのコストデータ
最も重要ですぐに処理できるデータは、AWSの「タグ付き」リソースから取得されます。
デフォルトでは、請求CSVにはタグが含まれていません。 したがって、あるEC2インスタンスまたはバケットが別のEC2インスタンスまたはバケットとどのように動作するかを区別することはできません。
ただし、
コスト配布タグを使用して、各ユニットの費用の横に表示されるラベルをアクティブ化でき
ます 。
これらのタグは、多くのAWSリソース、S3バケット、DynamoDBテーブルなどによって公式にサポートされています。 CSVでコスト配布タグを表示するには、AWS請求コンソールで対応するオプションを有効にできます。 1日程度で、選択したタグ(
product_areaを選択した)が、詳細なCSVレポートの対応するリソースの横に新しい列として表示され始めます。
最適化を行っていない場合は、すぐにコスト分散タグを使用してインフラストラクチャをマークアップできます。 これは基本的に「無料」のサービスであり、機能するためのインフラストラクチャは必要ありません。
機能をアクティブにした後、2つのタスクがありました。1)既存のインフラストラクチャ全体をマークアップする。 2)すべての新しいリソースが自動的にタグ付けされることを確認します。
既存のインフラストラクチャのマークアップ
既存のインフラストラクチャのタグ付けは非常に簡単です。特定のAWS製品ごとに、最も高いコストのリソースのリストをRedshiftに要求し、それらのリソースにタグを付ける方法を指示するまでSlackのユーザーに迷惑をかけます。 90%以上のリソースにコストをかけてタグを付けたら、手順を完了します。
ただし、
新しいリソース
にタグを付けるには、自動化とツールが必要です。
このために
Terraformを使用します。 ほとんどの場合、Terraform構成は、AWSコンソールを介して追加されるのと同じコスト割り当てタグの追加をサポートしています。 S3バケットのTerraform構成の例を次に示します。
resource "aws_s3_bucket" "staging_table" { bucket = "segment-tasks-to-redshift-staging-tables-prod" tags { product_area = "data-analysis"
Terraformは基本的な構成を提供しますが、新しいリソース
aws_s3_bucket Terraformファイル
aws_s3_bucketれる
aws_s3_bucket 、
product_areaタグが添付されるようにする必要がありました。
幸いなことに、Terraformの構成はHCL(Hashicorp Configuration Language)で記述されており、コメントを保存する構成パーサーがあります。 そこで、すべてのTerraformファイルを調べて、
product_areaタグなしでタグ付けされるリソースを探す検証関数を作成しました。
func checkItemHasTag(item *ast.ObjectItem, resources map[string]bool) error { // looking for "resource" "aws_s3_bucket" or similar t := findS3BucketDeclaration(item) tags, ok := hclchecker.GetNodeForKey(t.List, "tags") if !ok { return fmt.Errorf("aws_s3_bucket resource has no tags", resource) } t2, ok := tags.(*ast.ObjectType) if !ok { return fmt.Errorf("expected 'tags' to be an ObjectType, got %#v", tags) } productNode, ok := hclchecker.GetNodeForKey(t2.List, "product_area") if !ok { return errors.New("Could not find a 'product_area' tag for S3 resource. Be sure to tag your resource with a product_area") } }
Terraformの構成とリポジトリの継続的な統合を確立し、これらのチェックを追加したため、
product_areaタグなしでタグ付けするリソースがある場合、テストはパスしません。
これは理想的ではありません。テストは細かく、技術的には、AWSコンソールでタグなしリソースを直接作成することができますが、システムはこの段階では十分に機能します。 新しいインフラストラクチャを記述する最も簡単な方法は、Terraformを使用することです。

コスト配分タグからのデータの処理
リソースをマークアップした後、それらのアカウンティングは簡単なタスクです。
- リソースIDを
product_areaタグと一致させるために、各リソースのproduct_areaタグを検索します。 - すべてのリソースのコストを合計します。
- 製品エリアのコストを追加し、結果を要約表に書き込みます。
SELECT sum(unblended_cost) FROM awsbilling.line_items WHERE statement_month = $1 AND product_name='Amazon DynamoDB';
AWSサービスのコストを分割することをお勧めします。セグメント製品ライン用とAWSサービス用の2つのテーブルがあります。
通常のAWSのコスト割り当てタグを使用して、約35%のコストを割り当てました。
予約されたインスタンスの分析
このアプローチは、ラベル付きのアクセス可能なインスタンスに適しています。 ただし、場合によっては、AWSは「予約」の前払いを行います。 予約は、割引料金での前払いと引き換えに、一定量のリソースの可用性を保証します。
私たちの場合、昨年12月のCSVアカウントからのいくつかの大きな支払いは、今年のすべての月にわたって分配される必要があることがわかりました。
これらの費用を正しく考慮するために、この期間の個別の(ブレンドされていない)費用のデータを使用することにしました。 クエリは次のようになります。
select unblended_cost, usage_start_date, usage_end_date from awsbilling.line_items where start_date < '2017-04-01' and end_date > '2017-03-01' and product_name = 'Amazon DynamoDB' and resource_id = '';
サブスクリプションコストは「$ X0000 of DynamoDB」の形式で記録されるため、リソースや製品ラインに起因することはありません。
代わりに、各リソースのコストを製品エリアに追加し、割合に従ってサブスクリプションコストを分配します。 データウェアハウスがEC2費用の60%を費やした場合、これらの目的のために加入者の60%が前払いされたと仮定します。
これも完璧ではありません。 アカウントの大部分が前払いから取得された場合、そのような配布戦略は、稼働中のインスタンスの実行コストのわずかな変更によって歪められます。 この場合、各リソースの使用に関する情報に基づいて経費を配分する必要があります。経費よりも要約することは困難です。
3.タグなしのAWSリソースからのコストデータ
DynamoDBインスタンスとテーブルのパーティション分割は優れていますが、他のAWSリソース
はコスト共有タグを
サポートしていません 。 これらのリソースでは、コストデータを正常に取得してRedshiftに転送するために、Rab-Goldbergスタイルの単純なワークフローを作成する必要がありました。
この場合のタグなしリソースの最大の2つのグループは、ECSとEBSです。
ECS
ECSシステムは、各サービスが動作する必要があるコンテナの数に応じて、サービスの規模を継続的に増減します。 彼女はまた、多数の個々のインスタンスの再バランスとコンテナへのパッケージングを担当しています。
ECSは、「予約されたCPUとメモリ」の数に応じて、ホスト上でコンテナを実行します。 各サービスは必要なCPUパーツの数を示し、ECSは十分なリソースを備えたホストに新しいコンテナーを配置するか、必要なリソースを追加するためにインスタンスの数をスケーリングします。
これらのECSアクションはいずれもCSV請求レポートに直接反映されませんが、ECSはすべてのインスタンスの自動スケーリングを実行する責任があります。
簡単に言うと、各コンテナが使用する特定のマシンの「パーツ」を理解したかったのですが、CSVレポートでは、インスタンスごとの「全体ユニット」の内訳のみが提供されます。
特定のサービスのコストを決定するために、独自のアルゴリズムを開発しました。
- ECSタスクが開始または停止するときに、すべてのイベントにCloudwatchサブスクリプションを設定します。
- このイベントに関連するデータ(サービス名、CPU /メモリ使用量、開始または停止、EC2インスタンスID)をKinesis Firehoseに送信します(個々のイベントを蓄積するため)。
- Kinesis FirehoseからRedshiftにデータを送信します。
すべての開始/停止/サイズデータがRedshiftに到着したら、このタスクがECSで動作した時間(120秒など)に、このマシンで使用したCPUユニットの数(最大4096-この情報はインスタンスで実行されている各サービスのCPU秒数を計算します。
アカウントからのインスタンスの総コストは、使用されるCPU秒数に応じてサービス間で分割されます。
これも理想的な方法ではありません。 EC2インスタンスは常に100%の電力で動作するわけではありませんが、過剰は現在、このインスタンスで動作するすべてのサービスに分配されています。 これは、過剰費用の正しい分配または誤った分配である可能性があります。 しかし(そして、ここでこの記事の一般的なトピックを見つけることができます)これで十分です。
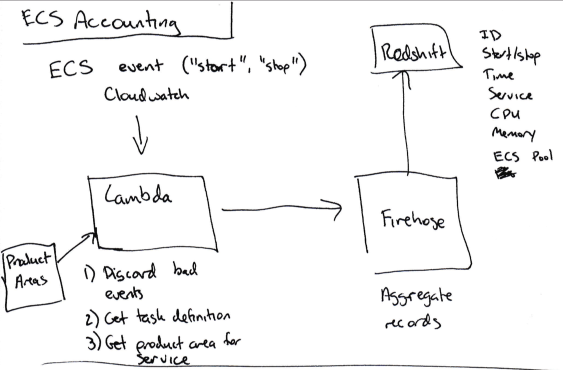
さらに、各ECSサービスを対応する製品ラインと関連付ける必要があります。 ただし、ECS
はコスト共有タグをサポートしていないため、AWSでそれらをマークすることはできません。
代わりに、各ECSサービスのTerraformモジュールに
product_areaキーを追加します。 このキーは、AWSに送信されるメタデータにはつながりませんが、すべてのサービスの
product_areaキーを読み取るスクリプトを生成します。
このスクリプトは、新しいデータを送信するたびに、DynamoDBのメインブランチでサービス名と製品の方向のbase64エンコードマップを公開します。
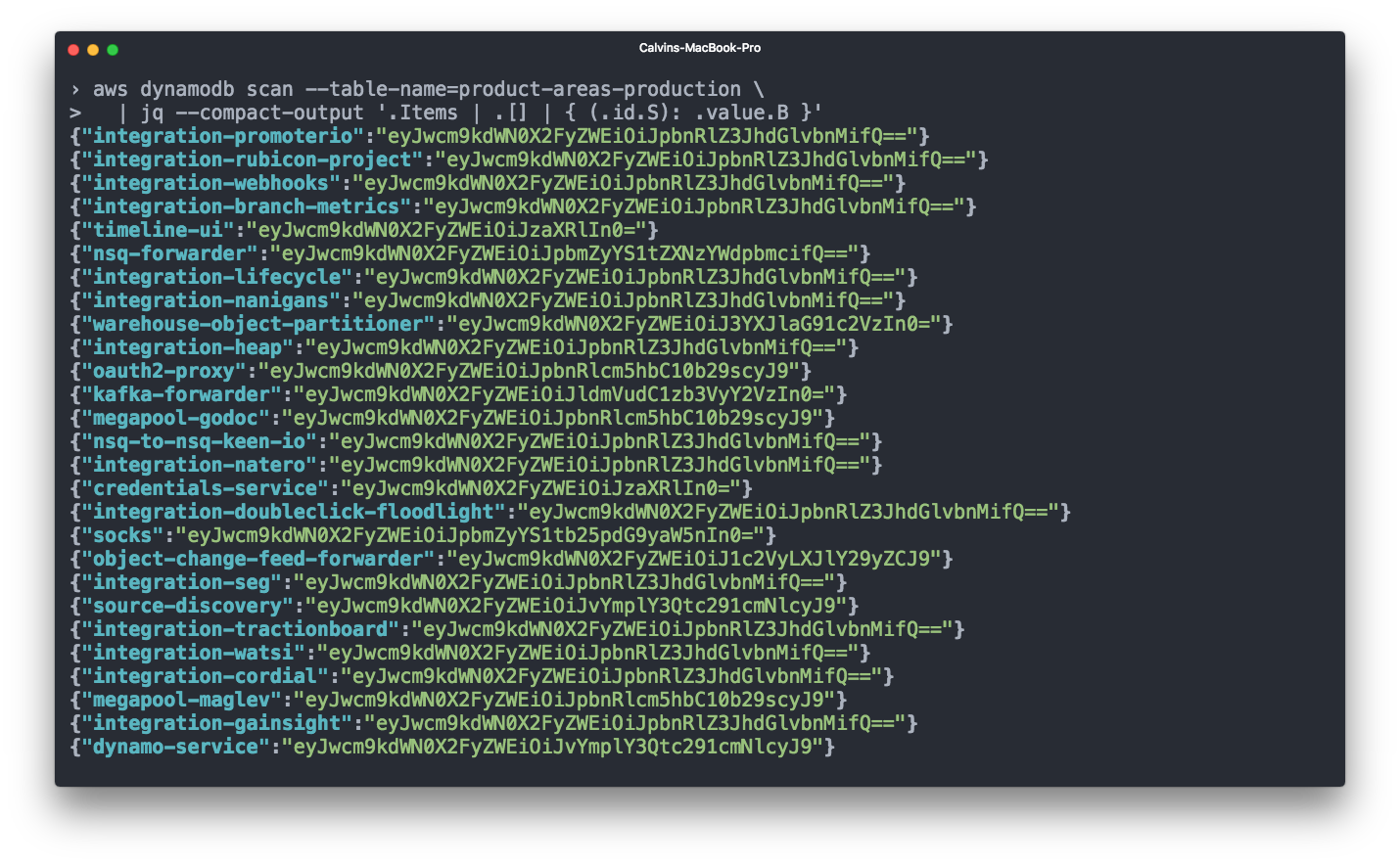
最後に、テストでは、製品ラインでタグ付けされた各新しいサービスをチェックします。
Ebs
Elastic Block Storage(EBS)もアカウントの大部分を占めています。 EBSボリュームは通常EC2インスタンスに接続されており、会計上、EBSボリュームのコストと対応するEC2インスタンスを考慮することは理にかなっています。 ただし、AWS CSV請求では、
どの EBSボリュームがどのインスタンスに接続されているかは表示さ
れません。
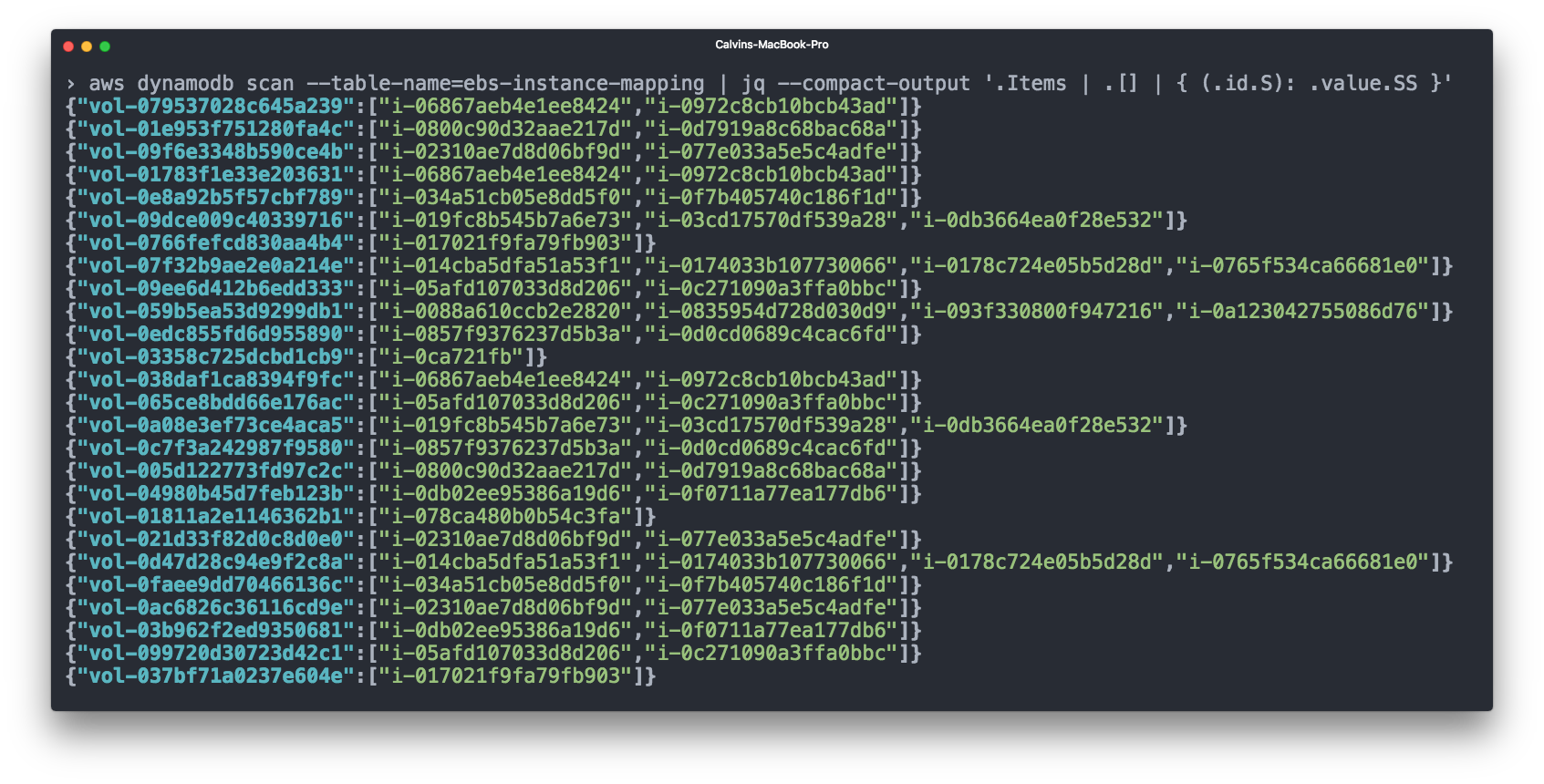
これを行うために、再びCloudwatchを使用しました。「ボリューム接続」や「ボリューム切断」などのイベントにサブスクライブし、DynamoDBテーブルにEBS => EC2接続を登録しました。
次に、ECSのコストを考慮する前に、EBSボリュームのコストを対応するEC2インスタンスのコストに追加します。
アカウント間でデータを結合する
これまで、単一のAWSアカウントのコンテキストですべての費用について説明してきました。 しかし実際には、これは異なる物理AWSアカウント間で共有される実際のAWS設定を反映していません。
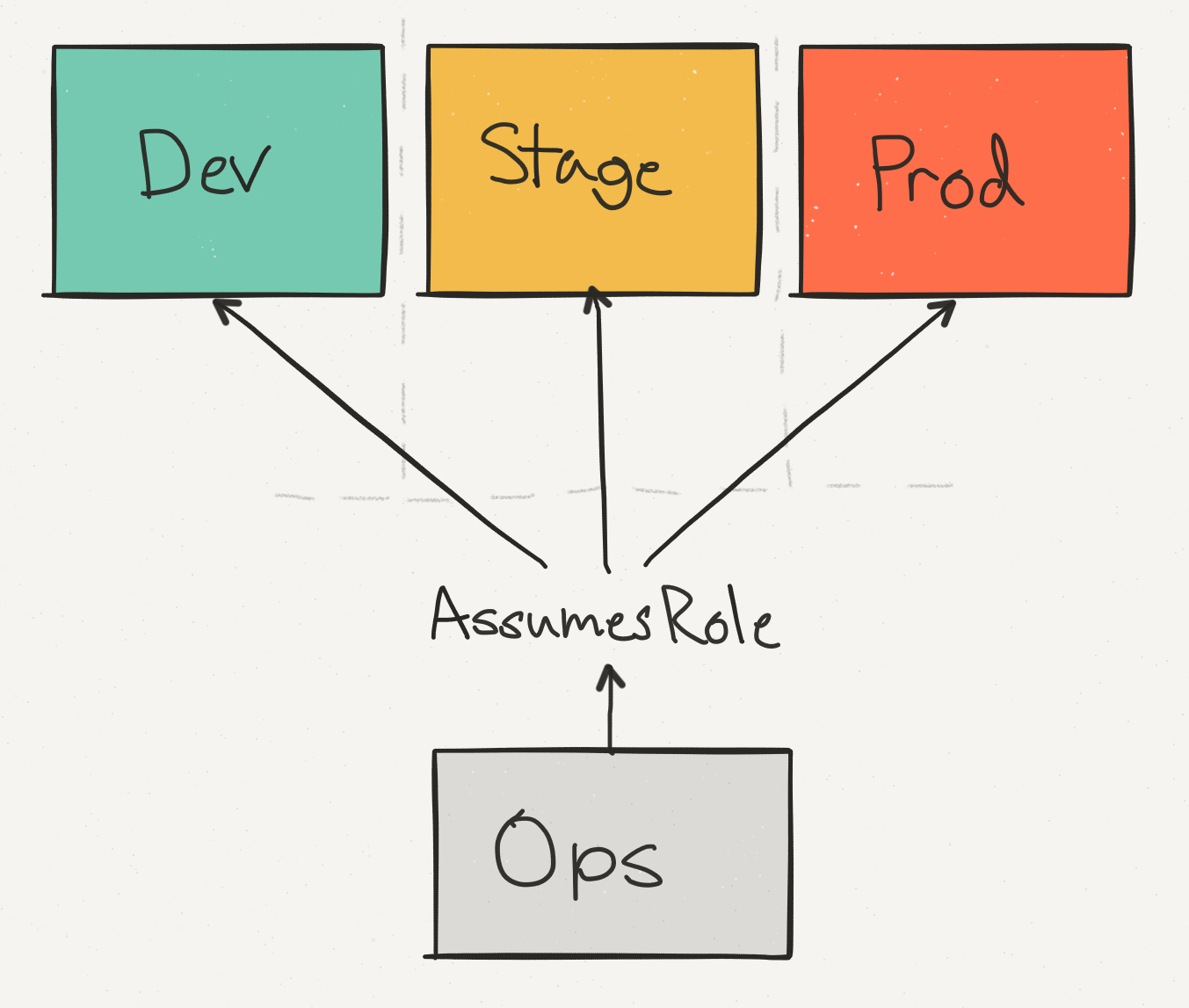
運用アカウント(Ops)を使用して、すべてのアカウントのデータと請求を統合するだけでなく、エンジニアが本番環境で変更を実装するための単一のアクセスポイントを提供します。 StageステージをProductionステージから分離します。これにより、DynamoDBテーブルを削除するなどのAPI呼び出しが適切なチェックで安全に処理されることを確認できます。
Prodアカウントはこれらの費用アカウントの中で支配的ですが、ステージアカウントの費用もAWSアカウント全体のかなりの部分を占めています。
ステージアカウントから実稼働環境のRedshiftクラスターにECSサービスに関するデータを書き込む必要がある場合、問題が始まります。
「アカウント間」を記録できるようにするには、CloudwatchサブスクリプションプロセッサがFirehose(ECSの場合)またはDynamoDB(EBSの場合)での記録のために本番環境での役割を引き受ける必要があります。 Stageアカウント(sts.AssumeRole)およびProdアカウントに適切な機能の適切なアクセス許可を追加する必要があるため、これは簡単ではありません。エラーがあると、アクセス許可が混乱します。
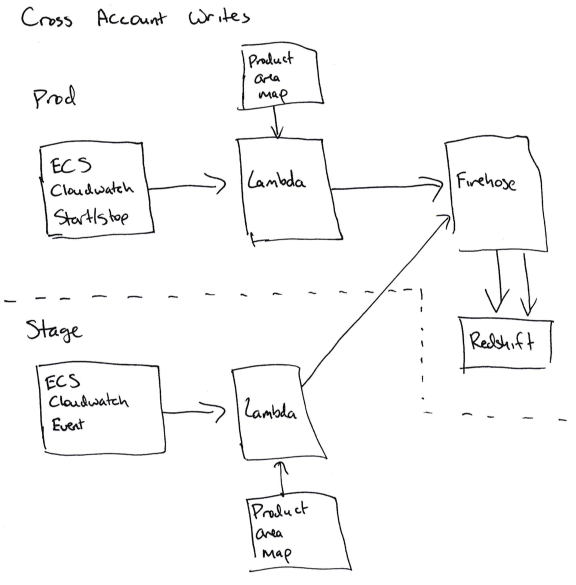
私たちにとって、これはアカウンティングコードがStageアカウントで機能せず、すべての情報がProdアカウントのデータベースに入力されることを意味します。
同じデータをサブスクライブするStageアカウントに2つ目のサービスを追加できますが、それは記録されませんが、この場合、Stageアカウンティングコードにランダムな問題が発生する可能性があると判断しました。
統計出力
最後に、適切なデータ分析のためのすべてがあります。
- CSVでリソースをマークアップしました。
- 各ECSイベントが開始および停止するときのデータ。
- ECSサービス名を関連製品ラインにバインドします。
- EBSボリュームを接続済みインスタンスにバインドします。
これをすべて分析チームに提供するために、AWSデータを売り込みました。 各AWSサービスについて、このAWSサービスのセグメント製品ラインとそのコストをまとめました。
このデータは、3つの異なるテーブルに表示されます。
- 特定の月の各ECSサービスの総費用。
- 特定の月の各製品ラインの総コスト。
- 特定の月の(AWSサービス、セグメント製品ライン)の総コスト。 たとえば、「データウェアハウジングは先月DynamoDBに1,000ドルを費やしました。」
個々の製品ラインの総コストは次のようになります。
月| product_area | cost_cents
--------------------------------------
2017-03-01 | 統合| 500
2017-03-01 | 倉庫| 783
また、セグメントの製品ラインに関連するAWSサービスコストは次のとおりです。
月| product_area | aws_product | cost_cents
-------------------------------------------------- -
2017-03-01 | 統合| ec2 | 333
2017-03-01 | 統合| ダイナモドブ| 167
2017-03-01 | 倉庫| 赤方偏移| 783
これらの各テーブルには、各月の合計を含む合計テーブルと、現在の月のデータを毎日更新する追加のサマリーテーブルがあります。 ピボットテーブルの一意の識別子は各パスに対応しているため、そのパスのすべての行を見つけることでAWSスコアを統合できます。
結果として得られるデータは、高レベルのメトリックと経営陣への報告に使用される黄金の「真実の源」として効果的に機能します。 サマリーテーブルは、1か月間のランニングコストを監視するために使用されます。
注:AWSは、月末のわずか数日後に「最終」請求書を発行するため、月末に請求レコードを最終としてマークするロジックは正しくありません。 CSVファイルのinvoice_idフィールドに「推定」という単語ではなく整数が表示されたときに、最終的なAmazonスコアを見つけることができます。最後のヒント
終了する前に、プロセス全体で、少しの準備と知識で多くの時間を節約できる場所があることに気付きました。 ソートなしの場合、これらの場所は次のとおりです。
- データを集約したり、ある場所から別の場所にコピーしたりするスクリプトが開発者の手に届くことはめったにありません。また、彼らの作業はよく監視されていません。 たとえば、スクリプトの1つはS3バケットから別のS3バケットにCSV請求データをコピーしましたが、CSVファイルが十分に大きくなったときにLambdaハンドラーがコピー中に十分なメモリを持っていなかったため、毎月27〜28日にエラーでクラッシュしました。 Redshiftデータベースには大量のデータがあり、毎月もっともらしいように見えるため、これに気付くまでにしばらく時間がかかりました。 それ以降、Lambda関数の監視を追加して、スクリプトがエラーなしで実行されるようにしました。
- これらのスクリプトが適切に文書化されていることを確認してください。特に、それらがどのように関与し、どのような構成が必要であるかについての情報が必要です。 これらのスクリプトが言及されている他の場所のソースコードへのリンク。 たとえば、S3バケットからデータをリクエストするすべての場所で、バケットにデータを書き込むスクリプトへのリンクを配置します。 また、S3バケットのルートディレクトリにREADMEファイルを書き込むことを検討してください。
- Redshiftリクエストは、最適化せずに非常に低速で実行できます。 会社のRedshiftスペシャリストに相談し、Redshiftで新しいテーブルを作成する前に必要なクエリを検討してください。 この場合、CSV請求テーブルに正しいソートキーがありませんでした。 テーブルを作成した後、並べ替えキーを追加することはできなくなりますので、事前にこれを処理しない場合は、正しいキーで2番目のテーブルを作成し、そこに書き込み操作を転送してから、すべてのデータをコピーする必要があります。
- 正しいソートキーを使用すると、ピボットテーブルのパス中のクエリステージの実行時間が約7分から10〜30秒に短縮されました。
- 最初は、スケジュールに従ってピボットテーブルを更新するスクリプトを実行することを計画しました。Cloudwatchは1日に何度もAWS Lambda関数を実行できます。 ただし、パッセージサイズは一貫しておらず(特にRedshiftにエントリが含まれている場合)、最大Lambdaタイムアウトを超えていたため、代わりにECSサービスに転送しました。
- 当初、ピボットテーブル更新コードにはJavaScriptを選択しました。これはLambdaで動作し、当社のほとんどのスクリプトがJavaScriptで記述されているためです。 ECSに切り替える必要があることがわかっている場合は、64ビット数の追加、作業の並列化およびキャンセルのサポートが強化された別の言語を選択します。
- Redshiftで新しいデータの書き込みを開始するたびに、データを変更する(たとえば、新しい列を追加する)か、データ分析に関する整合性エラーを修正し、変更に関する日付と情報を記載したREADMEファイルにメモを追加します。 これは、データ分析チームのスタッフにとって非常に役立ちます。
- ブレンドされた費用は、このタイプの分析にはあまり役に立ちません-ブレンドされていない費用に固執します。 特定のリソースに対してAWSが請求する金額を正確に示します。
- CSVレポートには8行または9行があり、Amazonはサービスの名前を示していません。 これらは請求書の合計金額を表しますが、特定の月の混合されていない費用を要約する試みを断念します。 これらの数値が費用の合計から除外されていることを確認してください。
ボトムライン
良いAWSスコアを取得するのは簡単ではありません。 これには、ツールの開発と設定、およびAWSでの高価なリソースの特定の両方のために、大量の作業が必要です。
私たちが達成した最も重要な勝利は、定期的な「1回限りの分析」ではなく、コストの単純な継続的予測の可能性です。
これを行うために、データ収集全体を自動化し、Terraformと継続的インテグレーションシステムにタグサポートを実装し、開発チームのすべてのメンバーにインフラストラクチャに正しくタグを付ける方法を説明しました。
すべてのデータはPDFの自重ではありませんが、Redshiftで継続的に更新されます。 新しい質問に答えて新しいレポートを生成する場合は、SQLクエリを使用して即座に結果を取得します。
さらに、すべてのデータをExcel形式にエクスポートしたため、新しいクライアントにかかる費用を正確に計算できます。 また、特定のサービスや製品分野に多額の資金が突然流入し始めるかどうかも確認できます。これは、予定外の費用が会社の財政状態に達する前に見られます。
この記事はお客様のインフラストラクチャと完全には一致していませんが、このストーリーがお客様のビジネスの成長に合わせてコストをよりよく理解し、管理するのに役立つことを願っています。