ご注意 perev。 :この資料は「何が起こると... Kubernetesエディション!」とRackspaceのJamie Hannafordによって書かれたもので、多くのKubernetesメカニズムの優れた例です。 -システム、作業のアルゴリズム、およびそのコンポーネントの相互接続。 記事全体が非常に膨大であるため、その翻訳は2つの部分に分かれています。 最初は、kubectl、kube-apiserver、etcd、および初期化子の作業を扱います。
PS作成者が参照する行番号の関連性が長期間保持されるように、マスターブランチのコードへの元のリンクの一部は翻訳時に最新のものに置き換えられました。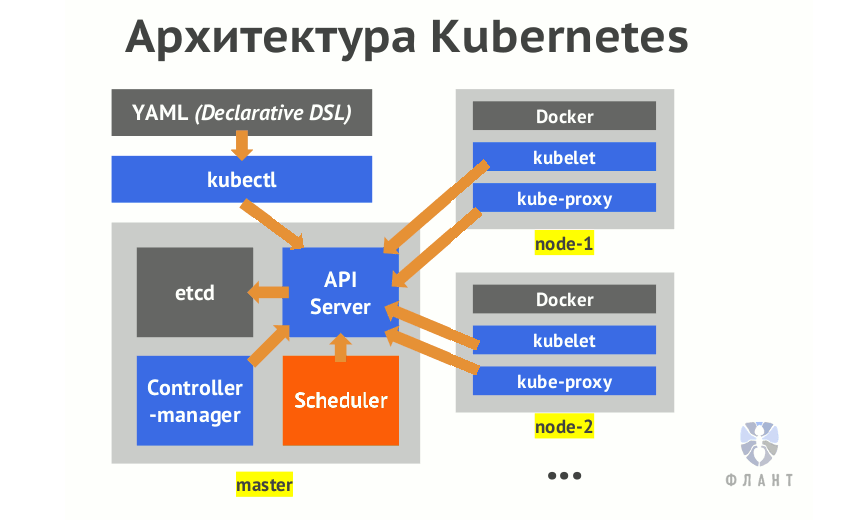
Kubernetesクラスターにnginxをデプロイするとします。 ターミナルに次のようなものを入力します。
kubectl run --image=nginx --replicas=3
...そしてEnterを押します。 数秒で、すべての作業ノードにnginxが分散された3つのポッドが表示されます。 それは動作します-まるで魔法のように、それは素晴らしいです! しかし、実際に何が起こるのでしょうか?
Kubernetesの優れた機能の1つは、このシステムがユーザーフレンドリーなAPIを通じてインフラストラクチャ内のワークロードの展開を処理する方法です。 すべての複雑さは、単純な抽象化によって隠されています。 ただし、K8がもたらす価値を完全に実現するには、内部のキッチンを理解することが役立ちます。 この記事では、クライアントからkubeletへのリクエストのライフサイクル全体を紹介します。必要に応じて、ソースコードを参照して何が起きているかを説明します。
これは生きた文書です。 改善または書き換えが必要な場合は、変更を歓迎します!
(もちろん、 GitHubの元の英語の記事について-約Transl。)kubectl
検証とジェネレーター
それでは始めましょう。 ターミナルでEnterキーを押すだけです。 そして今何?
まず、kubectlはクライアント側の検証を実行します。 彼は、機能していないリクエスト(サポートされていないリソースの作成、
間違った名前の画像の使用など)がすぐに中断され、kube-apiserverに送信されないようにします。 これにより、不要なワークロードが削減され、システムのパフォーマンスが向上します。
検証後、kubectlはkube-apiserverに送信されるHTTPリクエストの作成を開始します。 Kubernetesシステムで状態にアクセスまたは変更しようとするすべての試みは、APIサーバーを通過し、APIサーバーはetcdと通信します。 kubectlも例外ではありません。 HTTPリクエストを作成するために、kubectlはいわゆるジェネレーターを使用します。これは、シリアル化を実装する抽象化です。
ここでは、
kubectl run使用すると、Deploymentsだけでなく、多くのタイプのリソースを指定できることは明らかではないかもしれません。 これが機能
するために 、ジェネレータ名が
--generatorフラグで特に指定されていない限り、kubectlはリソース
のタイプを
計算します。
たとえば、
--restart-policy=Alwaysリソースは展開として扱われ、
--restart-policy=Neverリソースはポッドと見なされます。 Kubectlは、コマンドの記録(ロールアウトまたは監査)など、他のアクションを実行する必要があるかどうか、およびこのコマンドが(
--dry-runフラグの存在により)テスト実行であるかどうかも確認します。
Deploymentを作成することがわかったので、kubectlは
DeploymentV1Beta1ジェネレーターを使用して、提供されたパラメーターから
ランタイムオブジェクトを作成します。 ランタイムオブジェクトは、リソースの総称です。
APIグループとバージョン管理交渉
先に進む前に、Kubernetesは
APIグループごとに分類されたバージョン管理された
APIを使用していることに注意することが重要です。 APIグループは、同様のリソースを分類し、それらとのやり取りを容易にするように設計されています。 さらに、単一のモノリシックAPIの代替としても適しています。 DeploymentのAPIグループは
appsと呼ばれ、最新バージョンは
v1beta2です。 これは、Deployment:
apiVersion: apps/v1beta2の最上部で指定した
apiVersion: apps/v1beta2 。
( 注の翻訳 : Kubernetes 1.8の発表で説明したように、プロジェクトは現在、「ワークロード」に関連するデプロイメントやその他のAPIを含む新しいワークロードAPIグループの作成に取り組んでいます。)一般に、kubectlはランタイムオブジェクトを生成した後
、対応するAPIグループとバージョンの検索を
開始し 、目的のバージョンのクライアントを
収集します-リソースのさまざまなRESTセマンティクスを考慮します。 「
バージョンネゴシエーション 」と呼ばれるこの検出フェーズでは、リモートAPIの
/apisのコンテンツをスキャンして、可能なすべてのAPIグループを取得します。 kube-apiserverはこのパス(
/apis )に沿って構造ドキュメント(OpenAPI形式)を生成するため、クライアントは簡単に検出を実行できます。
パフォーマンスを向上させるために、kubectl
は OpenAPIスキームも
~/.kube/schemaディレクトリに
キャッシュし ~/.kube/schema 。 実際のAPI検出を確認するには、このディレクトリを削除し、
-vフラグの最大値を指定してコマンドを実行してみてください。 APIバージョンを見つけようとしているすべてのHTTPリクエストが表示されます。 そして、それらはたくさんあります!
最後のステップは
、 HTTPリクエストを
送信することです。 それが完了し、正常な応答が受信されると、kubectlは優先出力形式
を考慮して正常なメッセージ
を表示します。
クライアント認証
最後のステップでは、クライアント認証に言及しませんでした(HTTP要求を送信する前に発生します)-それも考慮します。
kubectlリクエストを正常に送信するには、認証する必要があります。 ユーザー資格情報は、ほとんどの場合ディスクに保存されている
kubeconfigファイルに保存されますが、別の場所に配置することもできます。 それを検索するために、kubectlは次のことを行います。
- フラグ
--kubeconfigが--kubeconfig -使用します。 - 環境変数
$KUBECONFIGが$KUBECONFIG -それを使用します。 - それ以外の場合、
~/.kubeなどの目的のホームディレクトリをチェックし、見つかった最初のファイルを使用します。
ファイルの解析後、現在のコンテキスト、現在のクラスター、および現在のユーザーの認証情報が決定されます。 ユーザーがフラグを通じて特別な値(
--usernameなど)を指定した場合、それらに優先順位が与えられ、
kubeconfig指定された値を上書きします。 情報が受信されると、kubectlはクライアント構成をセットアップし、HTTPリクエストのニーズに適したものにします。
- x509証明書は
tls.TLSConfigを介して送信されtls.TLSConfig (ルートCAもここに含まれています)。 - クライアントトークンは
Authorization HTTPヘッダーで送信されます。 - ユーザーとパスワードは、基本的なHTTP認証を通じて送信されます。
- OpenIDを介した認証プロセスは、ユーザーが手動で事前に実行します。その結果、トークンが表示され、上記の対応するアイテムと同様に送信されます。
kube-apiserver
認証
リクエストが送信されました。 次は? Kube-apiserverが登場します。 前述のように、kube-apiserverは、クライアントとシステムコンポーネントがクラスターの状態を保存および取得するために使用するメインインターフェイスです。 この機能を実行するには、要求元を検証し、要求元と一致することを確認する必要があります。 このプロセスは認証と呼ばれます。
apiserverはリクエストをどのように認証しますか? サーバーは最初に起動するときに、ユーザーが提供するすべての
コンソールフラグをチェックし、適切な認証システムのリストを収集します。 例について考えてみましょう:
--client-ca-fileが渡された場合、
--client-ca-fileオーセンティ
--client-ca-fileが追加されます。
--token-auth-fileが指定されている場合、トークン認証システムがリストに追加されます。 要求が受信されるたびに、認証者のチェーンが1つ正常に機能するまで実行されます。
- x509ハンドラーは、HTTP要求が証明機関のルート証明書によって署名されたTLSキーで暗号化されていることを確認します。
- トークンハンドラーは、提供されたトークン(
Authorization HTTPヘッダーで定義されている)が--token-auth-fileディレクティブで指定されたディスク上のファイルに存在することを確認します。 - 同様に、basicauthハンドラーは 、HTTP要求の基本認証の資格情報がローカルデータと一致することを確認します。
どの認証子も成功しなかった場合、要求
は失敗し、集約エラーが返されます。 認証が成功すると、
Authorizationヘッダーがリクエストから削除され、ユーザー情報がそのコンテキストに
追加されます。 これにより、後続の手順(承認および許可コントローラーなど)で以前に確立されたユーザーIDにアクセスできます。
ログイン
さて、リクエストが送信されました。kube-apiserverは、自分が紹介者であることを確認しました。 なんて安心! ただし、それだけではありません。 私たちは自分自身を紹介する人かもしれませんが、この操作を実行する権利はありますか? IDとアクセス権は同じものではありません。 続行するには、kube-apiserverが承認する必要があります。
kube-apiserverが認証を実行する方法は認証に非常に似ています。フラグ値から、各着信要求に使用される認証者のチェーンを収集します。
すべての承認者がリクエストを拒否すると、リクエストは
Forbiddenレスポンスで
終了し、そこで停止します。 少なくとも1人の承認者がリクエストを承認すると、さらに先に進みます。
Kubernetes v1.8リリースに含まれる承認者の例:
- K8sクラスター外のHTTP(S)サービスと対話するwebhook。
- 静的ファイルからポリシーを実装するABAC 。
- RBAC 、RBAC (ロールベースのアクセス制御- 約Transl。 )の役割を実装し、管理者によってKubernetesリソースとして追加されました。
- Nodeは 、クラスターノードのクライアント(kubeletなど)が自分でリソースにのみアクセスできることを確認します。
それぞれの
Authorizeメソッドを見て、どのように機能するかを確認してください。
アクセス制御
OK、kube-apiserverによって認証および承認されています。 残っているものは何ですか? Kube-apiserver自体が私たちを信頼し、継続することを許可しますが、Kubernetesのシステムの他の部分には、許可されているものと許可されていないものについての独自の深い確信があるかもしれません。 これが
アドミッションコントローラーの出番です。
ユーザーが権利を持っているかどうかの質問に承認が答えた場合、アドミッションコントローラーは、クラスター内のより広い範囲の期待とルールへの準拠の要求をチェックします。 これらは、オブジェクトがetcdに転送される前の最後の制御の要塞であり、システム内の残りのチェックを担当します。これは、アクションが予期しない結果またはネガティブな結果をもたらさないことを確認することを目的としています。
これらのコントローラーの動作原理はオーセンティケーターとオーソライザーに似ていますが、1つの違いがあります:アドミッションコントローラーの場合、コントローラーチェーンの単一の障害でこのチェーンを中断し、リクエストを失敗として認識できます。
アドミッションコントローラのアーキテクチャは、拡張性の促進に重点を置いています。 各コントローラーは
plugin/pkg/admissionディレクトリに
plugin/pkg/admissionとして保存され、小さなインターフェイスのニーズを満たすように作成されます。 それぞれがメインのKubernetesバイナリにコンパイルされます。
通常、アドミッションコントローラは、リソース管理、セキュリティ、デフォルト設定、および参照整合性に分類されます。 リソース管理コントローラーの例を次に示します。
InitialResourcesは、以前の使用法に基づいてコンテナリソースのデフォルト制限を設定します。LimitRangerは、リクエストのデフォルト値とコンテナ制限を設定し、特定のリソースの上限を保証します(512 MBのデフォルトメモリ、ただし2 GB以下)。ResourceQuotaは、ネームスペース内のオブジェクト(ハース、rc、サービスのロードバランサー)の数と、消費されたリソース(プロセッサ、メモリ、ディスク)の合計をカウントし、それらの過剰を防ぎます。
etcd
この時点で、Kubernetesは着信リクエストを完全に承認し、先に進むことを許可しました。 次のステップは、kube-apiserverがHTTPリクエストをデシリアライズし、そこからランタイムオブジェクトを作成し(kubectlジェネレーターの動作の逆のようなもの)、データストアを保存することです。 それを詳しく見てみましょう。
kube-apiserverは、リクエストを受け入れるときに何をすべきかをどのように知っていますか? このため、要求の処理の前に、かなり複雑な一連の手順が続きます。 最初から見てみましょう-バイナリファイルが最初に起動されたとき:
- kube-apiserverバイナリを実行すると 、サーバーチェーンが作成され、Kubernetes apiserver集約が有効になります。 これは多くのAPIサーバーをサポートするための基礎です(これについては心配することはできません)。
- これが発生すると、汎用APIサーバーが作成され、デフォルトの実装として機能します。
- 生成されたOpenAPIスキーマは、apiserver構成に入力されます。
- 次に、kube-apiserverは、スキームで定義されたすべてのAPIグループを順番に処理し、それらのそれぞれに対してストレージプロバイダーをセットアップし、 汎用ストレージ抽象化として機能します。 Kube-apiserverは、リソースの状態にアクセスするか、リソースの状態を変更すると、それと対話します。
- 各APIグループについて、グループのすべてのバージョンが順番にソートされ、各HTTPルートへのREST対応が確立されます。 これにより、kube-apiserverはクエリを照合し、結果にロジックを委任できます。
- 特定のケースでは、 POSTハンドラーが登録され、リソース作成ハンドラーに委任されます。
この時点で、kube-apiserverはどのルートが存在するかを認識し、リクエストが一致したときにどのハンドラーとストレージプロバイダーを呼び出す必要があるかを示す内部マッピングを持っています。 HTTPリクエストを受け取ったとします:
- ハンドラーのチェーンがリクエストとパターンの一致(登録済みルート)を見つけることができる場合、このルートに登録されている目的のハンドラーが呼び出されます それ以外の場合は、パスベースのハンドラーが呼び出されます(
/apis呼び出されたときに同じことが起こります)。 このパスに登録されているハンドラーがない場合、not foundハンドラーが呼び出され、404が返されます。 - 幸いなことに、
createHandlerという登録済みのルートがcreateHandlerます。 彼は何をしていますか? まず、HTTPリクエストをデコードし、提供されたJSONデータが目的のバージョンのAPIからのリソースに対する期待と一致することを確認するなど、基本的な検証を実行します。 - 監査と最終入場があります。
- リソースは、ストレージプロバイダーへの委任によってetcdに保存されます。 通常、etcdのキーは
<namespace>/<name>として表され<namespace>/<name>が、これはカスタマイズ可能です。 - 作成中のエラーはすべてキャッチされ、最後にストレージプロバイダーが
get呼び出しを行って、オブジェクトが実際に作成されたことを確認します。 次に、作成後(作成後)に割り当てられたすべてのハンドラーと、追加のファイナライズが必要な場合はデコレーターを呼び出します。 - HTTPリクエストが作成され、返信されます。
たくさんのステップ! このようなapiserverをフォローするのは驚くべきことです。実際にどれだけの作業を行うかを理解しているからです。 そのため、要約すると、展開リソースはetcdに存在するようになりました。 しかし、そこに置くだけでは十分ではありません-この段階ではまだ表示されません...
初期化子
オブジェクトがデータウェアハウスに格納されると、apiserverは完全に表示されず、
初期化子 ( 初期 化子)のセットを
実行するまでスケジューラーに分類されません。 初期化子は、リソースの種類に関連付けられたコントローラーであり、リソースが外部で使用可能になる前にそのリソースでロジックを実行します。 リソースタイプに初期化子が登録されていない場合、この手順はスキップされ、リソースはすぐに表示されます。
多くのブログで
書かれているように、これは一般的な
ブートストラップ操作を実行できる強力な機能です。 例は次のとおりです。
- プロキシサイドカーコンテナを、開いているポート80の下に挿入するか、特定の注釈を付けて挿入します。
- 特定の名前空間のすべてのポッドにテスト証明書付きのボリュームを挿入します。
- 長さが20文字未満のシークレットの作成の防止(たとえば、パスワードの場合)。
initializerConfigurationオブジェクトを使用すると、特定のタイプのリソースに対して実行するイニシャライザーを決定できます。 囲炉裏を作成するたびにイニシャライザを実行したいと想像してください。 次に、次のようなことを行います。
apiVersion: admissionregistration.k8s.io/v1alpha1 kind: InitializerConfiguration metadata: name: custom-pod-initializer initializers: - name: podimage.example.com rules: - apiGroups: - "" apiVersions: - v1 resources: - pods
この構成を作成した後、
custom-pod-initializerが各ポッドの待機フィールド(
metadata.initializers.pending )に追加されます。 初期化コントローラーは既にデプロイされており、新しいポッドのクラスターを定期的にスキャンし始めます。 初期化子は、待機フィールドにその名前
(つまり、初期化子)を発見すると、そのアクションを実行します。 完了すると、彼は名前をウェイティングリストから削除します。 リストの最初に名前があるイニシャライザーのみがリソースを管理できます。 すべての初期化子が完了し、待機リストが空になると、オブジェクトは初期化されたと見なされます。
ほとんどの読者は、潜在的な問題に気付いているかもしれません。 kube-apiserverがまだリソースを表示していない場合、ユーザー空間のコントローラーはどのようにリソースを処理できますか? このために、kube-apiserverには特別なリクエストパラメーター
?includeUninitializedがあり、初期化されていないオブジェクトを含むすべてのオブジェクトを返すことができます。
翻訳者からのPS
近日中に記事の第2部を
公開します:... このリンクで公開します。 DeploymentsおよびReplicaSetsコントローラー、情報提供者、スケジューラー、kubeletの作業について説明します。
ブログもご覧ください。