ETL(Extract、Transform、Loading)プロセスのステージEおよびT、つまりデータの抽出と変換では、
Apache Stormを使用します。生データの無効化に関連するほとんどのエラーはこのステージで発生するため、
ELKスタック (Elasticsearch、Logstash、Kibana)を使用して、これらすべてを一元的に記録したいという要望。
ロシア語ではないが、元のチュートリアルでさえ、Javaアプリケーションの世界でデフォルトであるlog4j2形式のログでの作業が記述されていないことに驚いた。
この省略を修正-カットオフの下には、以下に基づいてlog4j2ログの集中コレクションを設定するためのチュートリアルがあります。
- Docker内のELK
- Logstashと連携するためのlog4jの構成
- Logstashを構成してログに適切にインデックスを付ける
- Stormの簡単なセットアップとElasticsearchとGrafanaの統合という形でのいくつかのボーナス

DockerとLogstashのセットアップのELK
ELKをDockerコンテナ内にインストールすることについてはすでに書か
れていますが、この記事の著者はfilebeatを使用し、何らかの理由でアプリケーションホストに追加のソフトウェアをドラッグしたくありませんでした。さらに、
log4j2は SMSおよび登録なしでデータを直接送信
できますTCPソケットへ。
画像をダウンロードする
短い検索の後、ELKの最新バージョン(執筆時点ではELK 6.0.0)では、Dockerイメージ
sebp / elkのみが
すぐに使用できることがわかりました-それを使用しますが、ファイルビートなしで動作するようにイメージを修正しますこれにはTCPソースを使用します。
cd /usr/local/src git clone https://github.com/spujadas/elk-docker cd elk-docker
独自のLogstash構成を作成する
TCP経由でログを受信するためのファイルと、Elasticsearchに書き込むためのファイルの2つを作成するだけです。
[root@host01 elk-docker]
kvフィルター (キー値)に注意してください-必要なパラメーターをキーと値のペアに分割するため、log4j2形式のログを正しく処理できるのは彼です。
再帰パラメーターは、フィルターが値フィールドでネストされたキーと値のペアを検索しないようにするために必要です。
add_tag => "%{loggerclass}" -このレコードを生成したプロセスのJavaクラスを各レコードに追加します。たとえば、デバッグ段階で特定のコンポーネントの作業(エラー)を確認する必要がある場合に非常に便利です。
また、この段階で、ElasticsearchまたはKibanaに必要なプラグインのインストールをDockerfileに追加できます(Logstashにも必要ですが、私が理解している限り、すべての公式プラグインは既にイメージにインストールされているため、非常にカスタムが必要な場合)。 。
コンテナを集める
Dockerfileを少し変更する理由(diffのみを提供します):
diff --git a/Dockerfile b/Dockerfile index ab01788..723120e 100644 --- a/Dockerfile +++ b/Dockerfile @@ -128,9 +128,7 @@ ADD ./logstash-beats.crt /etc/pki/tls/certs/logstash-beats.crt ADD ./logstash-beats.key /etc/pki/tls/private/logstash-beats.key # filters -ADD ./02-beats-input.conf /etc/logstash/conf.d/02-beats-input.conf -ADD ./10-syslog.conf /etc/logstash/conf.d/10-syslog.conf -ADD ./11-nginx.conf /etc/logstash/conf.d/11-nginx.conf +ADD ./02-tcp-input.conf /etc/logstash/conf.d/02-tcp-input.conf ADD ./30-output.conf /etc/logstash/conf.d/30-output.conf # patterns
つまり、ファイルビート、syslog、nginxを操作するためのイメージから標準入力を削除し、そこに設定ファイルを追加します
あとは、新しい画像を収集するだけです。
docker build -t https://docker-registry-host.lan:5000/elk .
この場合、ローカルのdocker-registryでも公開しました(またはdockerハブで公開できます)
ELKを起動する
起動は標準ですが、最初にホストマシン上にディレクトリを作成します。ここには、Elasticseachデータを格納し、コンテナが停止した後に消えないようにします
mkdir -p /mnt/data1/elk/data
ELKを実行します。
sysctl vm.max_map_count=524288
-e ES_HEAP_SIZE="4g" -e LS_HEAP_SIZE="1g"注意して
-e ES_HEAP_SIZE="4g" -e LS_HEAP_SIZE="1g" 、-必要なメモリサイズは、集約するログの数によって異なります。 私の場合、デフォルトでインストールされた256 MBでは十分ではなかったため、Elasticsearchに4 GB、Logstashに1 GBをそれぞれ割り当てました。 これらのパラメーターは、負荷に基づいて直感的に選択する必要があります。1秒あたりのデータ量と使用されるメモリの量の対応について明確な説明が見つからなかったためです。
約40秒後、コンテナーが起動し、
host01.lanのKibanaにアクセスできます
。5601 / app /
kibana #のように表示されます。
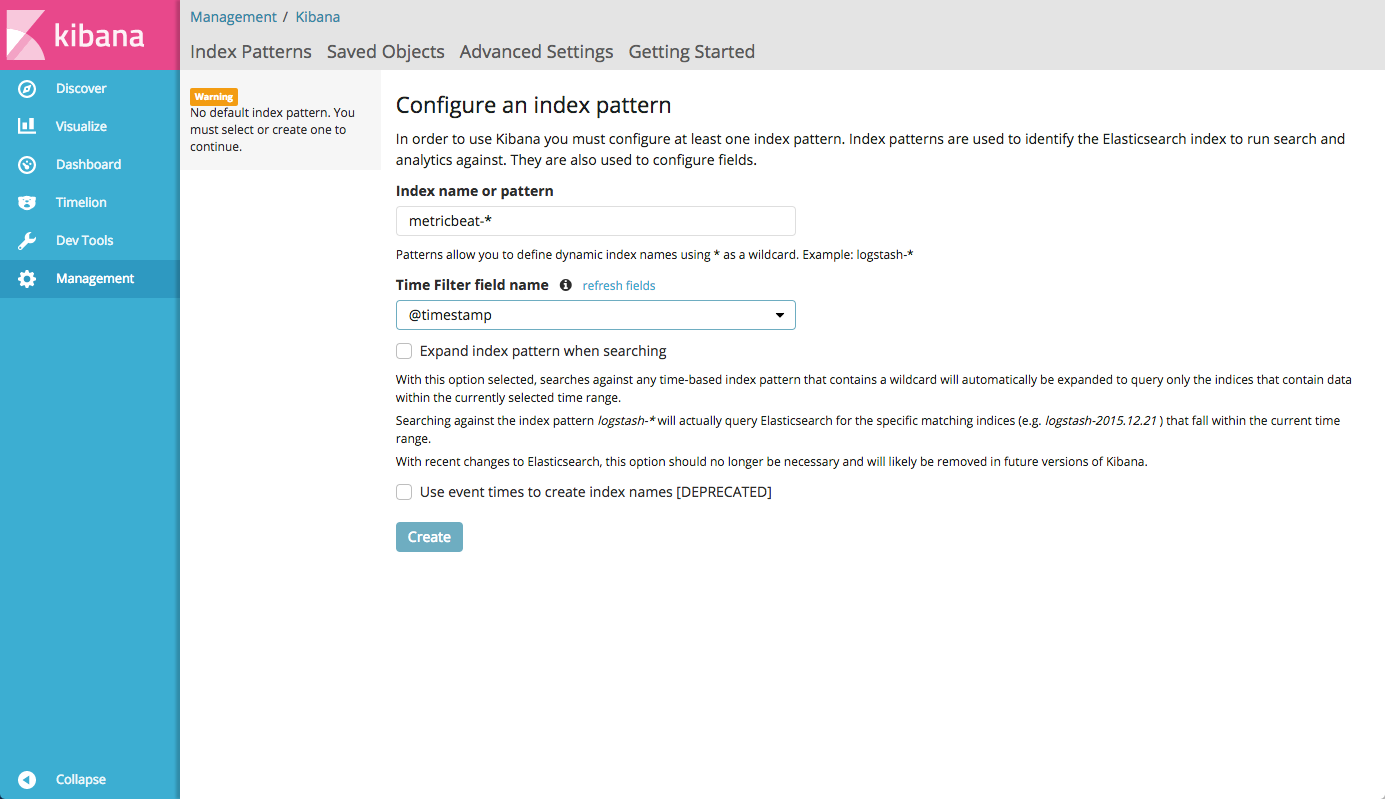
storm-%{+YYYY.MM.dd}形式を
storm-%{+YYYY.MM.dd} Elasticsearchインデックス設定ファイル
storm-%{+YYYY.MM.dd}で指定したため、
storm-%{+YYYY.MM.dd}起動時に、インデックスパターンを
storm-*として設定します。
Apache Stormのインストールと構成(オプション)
Stormのインストールに関して多くのマニュアルが書かれており、
公式文書は非常に詳細です。 この部分はオプションです。Stormのセットアップに興味がない場合は、次の部分に進んでください。
Storm 1.0ブランチを使用します(歴史的な理由と、誰もがコードを1.1.xに移植するのが面倒なので、動作するためです)。このブランチから1.0.5(執筆時点)の最新バージョンをインストールします。
インストールは非常に簡単です。
mkdir /opt/storm cd /opt/storm wget http://ftp.byfly.by/pub/apache.org/storm/apache-storm-1.0.5/apache-storm-1.0.5.tar.gz tar xzf apache-storm-1.0.5.tar.gz ln -s apache-storm-1.0.5 current
また、クォーラムが機能するには、Zookeeperサーバーが必要です。 それらのセットアップは別の記事のトピックなので、ここでは説明しません
zookeeper-{01..03}.lanという名前のサーバーに構成されていると仮定します
zookeeper-{01..03}.lanstorm.yaml構成ファイルを作成します
--- /opt/storm/current/conf/storm.yaml storm.zookeeper.servers: - "zookeeper-01.lan" - "zookeeper-01.lan" - "zookeeper-01.lan" storm.local.dir: "/opt/storm" nimbus.seeds: ["storm01.lan", "storm02.lan"]
ここでは、Zookeeperクラスターに加えて、Nimbusサーバーを指定する必要があります。Nimbusサーバーは、Stormのトポロジの元のコーディネーターとして機能します
スーパーバイザーによるApache Storm起動の管理
デフォルトでは、Apache Stormはそれ自体で悪魔化されておらず、
公式マニュアルにはデーモンモードでの自動起動については何も記載されていません。 したがって、
Pythonスーパーバイザーを使用しますが、もちろん任意のプロセスオーケストレーター(RunIT、daemonizeなど)を使用できます
pipを介してCentOS 7.3にスーパーバイザーをインストールしましたが、meld3依存関係をパッケージからインストールする必要があります。 ご使用のシステムでは、インストールは異なる場合があります(実際は異なります)が、細部のみが異なります
yum install python-pip -y
次に、Apache Stormを実行するための構成ファイルを作成する必要があります。ここでは、Stormの構成にいくつかのコンポーネントがあることに注意する必要があります。
- NimbusはAPIを提供するオーケストレーターであり、クラスターノード間のタスク(トポロジ、エグゼキューター)のバランスを制御します。
- UI-ここではすべてがシンプルです-これは、現在のステータスに関するすべてを表示できるWebインターフェースです
- スーパーバイザーは、インストールしたものではなく、独自の内部のものです。Nimbusサーバーからタスクを受け取り、作業を行うワーカー内で実行します。
トポロジーで説明 - Logviewer -Webベースのインターフェースを介して各クラスターマシンのログを表示できます
それぞれについて、サーバーの役割に応じて
/etc/supervisord/conf.d/構成ファイルを作成する必要があります
たとえば、5台のStormサーバーがあります。
storm01.lanニンバス( storm01.lanをセットアップする上記を参照)、UI、スーパーバイザーstorm02.lanニンバス、スーパーバイザーstorm03.lanスーパーバイザーstorm04.lanスーパーバイザーstorm05.lanスーパーバイザー
そして、各サーバーで、logviewerプロセスを開始します(Kibanaのログを見ることができるので、実際には必要ありませんが、Storm UIのリンクが無効にならないようにします)。
したがって、5つのサーバーすべてで、次の2つのファイルを作成します。
[root@storm01 ~]
次に、storm01.lanおよびstorm02.lanサーバーで、Nimbusを実行する同様のファイルを作成します。
[root@storm01 ~]
さて、UIをインストールすることにした最初のサーバーで、UIを実行する別のファイルを作成します。
[root@storm01 ~]
ご覧のとおり、Stormはすべてのコンポーネントに共通の構成を使用しており、必要な役割のみを変更しているため、構成ファイルはほぼ同じです。
これで、supervisordを実行するApache Stormの構成が完了しました。残りはログのコレクションを構成することだけです。
ログをELKに送信するためのLog4J2の構成
Apache Stormの場合、インストールでは、2つのファイルがロギングを管理します。
/opt/storm/current/log4j2/cluster.xml Stormサービスログの構成を制御します(Nimbus、Supervisor、UI)/opt/storm/current/log4j2/worker.xmlワーカーのロギングの構成を制御します。つまり、Storm内で実行されているトポロジ(アプリケーション)に直接
ただし、
Log4J2形式は汎用であるため、この構成を任意のJavaアプリケーションに簡単に適合させることができます。
ファイルworker.xml:
<?xml version="1.0" encoding="UTF-8"?> <configuration monitorInterval="60"> <properties> <property name="defaultpattern">logdate=(%d{ISO8601}) thread=(%thread)) level=(%level) loggerclass=(%logger{36}) message=(%msg)%n</property> </properties> <appenders> <RollingFile name="A1" fileName="${sys:storm.log.dir}/${sys:logfile.name}" filePattern="${sys:storm.log.dir}/${sys:logfile.name}.%i.gz"> <PatternLayout> <pattern>${defaultpattern}</pattern> </PatternLayout> <Policies> <SizeBasedTriggeringPolicy size="100 MB"/> </Policies> <DefaultRolloverStrategy max="9"/> </RollingFile> <RollingFile name="METRICS" fileName="${sys:storm.log.dir}/${sys:logfile.name}.metrics" filePattern="${sys:storm.log.dir}/${sys:logfile.name}.metrics.%i.gz"> <PatternLayout> <pattern>${defaultpattern}</pattern> </PatternLayout> <Policies> <SizeBasedTriggeringPolicy size="2 MB"/> </Policies> <DefaultRolloverStrategy max="9"/> </RollingFile> <Socket name="logstash" host="host01.lan" port="5044"> <PatternLayout pattern="${defaultpattern}" charset="UTF-8" /> </Socket> <Async name="LogstashAsync" bufferSize="204800"> <AppenderRef ref="logstash" /> </Async> </appenders> <loggers> <root level="INFO"> <appender-ref ref="A1"/> <appender-ref ref="LogstashAsync"/> </root> <Logger name="METRICS_LOG" level="info" additivity="false"> <appender-ref ref="METRICS"/> <appender-ref ref="LogstashAsync"/> </Logger> </loggers> </configuration>
そして、cluster.xmlファイル:
<?xml version="1.0" encoding="UTF-8"?> <configuration monitorInterval="60"> <properties> <property name="defaultpattern">logdate=(%d{ISO8601}) thread=(%thread)) level=(%level) loggerclass=(%logger{36}) message=(%msg)%n</property> </properties> <appenders> <RollingFile name="A1" fileName="${sys:storm.log.dir}/${sys:logfile.name}" filePattern="${sys:storm.log.dir}/${sys:logfile.name}.%i"> <PatternLayout> <pattern>${defaultpattern}</pattern> </PatternLayout> <Policies> <SizeBasedTriggeringPolicy size="100 MB"/> </Policies> <DefaultRolloverStrategy max="9"/> </RollingFile> <Socket name="logstash" host="host01.lan" port="5044"> <PatternLayout pattern="${defaultpattern}" charset="UTF-8" /> </Socket> <Async name="LogstashAsync" bufferSize="204800"> <AppenderRef ref="logstash" /> </Async> </appenders> <loggers> <root level="INFO"> <appender-ref ref="A1"/> <appender-ref ref="LogstashAsync"/> </root> </loggers> </configuration>
ご覧のように、ワーカーに使用される追加のMETRICSロガーを除き、構成は似ています(Stormトポロジでメトリックを使用する場合)。
構成ファイルの重要な点を考慮してください。
- ロギングに使用するパターン、キー値形式で書き込む(Logstashでkvフィルターを使用したことを思い出してください)、必要なエンティティ、すなわち日付、スレッド、ロギングレベル、クラス(Elasticsearchのタグにもなります) )そして実際には、このクラスによって送信されたメッセージ:
<property name="defaultpattern">logdate=(%d{ISO8601}) thread=(%thread)) level=(%level) loggerclass=(%logger{36}) message=(%msg)%n</property>
- デフォルトのアペンダーA1が担当するディスク(Apache Storm組み込みのlogviewerを介してログを表示するために必要)に加えて、TCP経由でLogstashにメッセージを直接送信できるSocketAppenderも使用します。
<Socket name="logstash" host="host01.lan" port="5044"> <PatternLayout pattern="${defaultpattern}" charset="UTF-8" /> </Socket>
ここで、afterホストでは、ELKを使用してdockerコンテナーを実行しているサーバー(ホストマシン)と、構成で指定したポートを示します。 - また、ロギングを非同期にします。そうしないと、Stormトポロジー
が危険にさらされ、Logstashが応答を停止するか、このマシンとの接続に問題がある場合にブロックされます。
<Async name="LogstashAsync" bufferSize="204800"> <AppenderRef ref="logstash" /> </Async>
ここのバッファサイズはランダムに取得されますが、私のスループットには十分すぎるほどです。
Apache Stormの起動とロギングの確認
これで、実際のセットアップが完了しました。Stormを実行してログを見ることができます
各サーバーで次のコマンドを実行します。
systemctl enable supervisord systemctl start supervisord
次に、supervisordはすべてのApache Stormコンポーネントを起動します。
仕事と小さなボーナスをチェックしてください!
これでKibanaにアクセスして、次のようなチャートを楽しむことができます。

ここでは、サーバー間でINFOレベルのメッセージが配信されています
Grafanaとの統合
私の場合、Grafanaは美しいグラフとダッシュボードを描くメイン監視システムとして使用され、素晴らしい機能を備えています-Elasticsearchからグラフを作成できます(そして、私の意見ではKibanaよりも美しいです)
Grafanaのデータソースに移動してElasticsearchを追加し、ELKを実行するホストマシンのアドレスを示します。

その後、たとえば各サーバーの警告の数を調べるグラフを追加できます。

古いログのクリーニング
ご存知のように、ディスクはゴムではなく、Elasticsearchはデフォルトでは回転しません。 私のインストールでは、これは問題になる可能性があります。なぜなら、1日でインデックスに約60 GBのデータが格納されるからです。
古いログを自動的にクリアするために、python-package
elasticsearch-curatorがありますpipを使用してelkコンテナーを実行するホストマシンにインストールします。
[root@host01 ~]
そして、2つの設定ファイルを作成します。1つはElasticsearchへの接続を記述し、もう1つはアクションを設定します。 廃止されたインデックスをクリアする直接アクション:
[root@host01 ~]
ここでは、インデックスパターン、この場合は
storm- 、接尾辞の形式(年、月、日)、およびログを保存する日数を示します。
次に、cronにコマンドを追加して、1日1回キュレーターを実行します。
/bin/curator --config /mnt/elk/conf/curator/curator.yml /mnt/elk/conf/curator/rotate.yml
結論と免責事項
このチュートリアルは100%完全であると主張せず、いくつかのことを省略します。これは、それ自体がチートシートであると想定されているためです。
Storm、Log4J2、およびELKの束を特定のガイドの形で作成する方法の詳細な説明を見つけることは、私にとって本当に困難でした。 もちろん、ドキュメントを読むのに数時間費やすことができますが、同様のタスクに遭遇した人が私の簡単なガイドを使用する方が簡単で迅速であると思うことを願っています。
コメント、追加、ログの集中収集の事例、および実務で遭遇した困難や機能に非常に喜んでいます。 コメントへようこそ!
便利なリンク