みなさん、こんにちは。GraphQLの蓄積された知識を共有したいと思います。これは、約100の記事/ドックの読み取りとGraphQLを使用してAPIを構築した月に基づいて形成されました。
それでは、GraphQLとは何ですか?
GraphQLは、データを取得するためのデータ構造とメソッドを宣言するための標準であり、クライアントとサーバー間の追加レイヤーとして機能します。
GraphQLの主な機能の1つは、データの構造と量がクライアントアプリケーションによって決定されることです。
単純なユーザーリクエストの例を考えてみましょう。
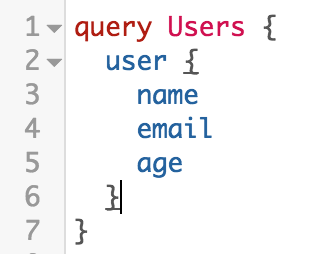
クライアントは、JSON形式に非常に類似した宣言的なグラフのような構造を使用して、受信するデータを正確に示します。
この場合、クライアントは3つのフィールド(名前、電子メール、および年齢)を要求します。 ただし、名前などの単一のフィールドと、GraphQLサーバーのユーザータイプで定義されている任意の数のフィールドの両方を要求できます。
このアプローチでは、利便性に加えて、トランスポートレベルでのリクエスト数またはデータ量を削減しました。
GraphQLを使用すると、複数のソースからのデータを簡単に集約できます。簡単なクライアント/サーバーアーキテクチャを見てみましょう。

クライアントアプリケーションと1つのサーバーがあります。 データ転送は非常にシンプルに見えますが、
どのデータ転送プロトコルがこれに使用されるかは関係ありません。 httpの場合、リクエストを送信してレスポンスを取得します。すべてが非常に簡単です。

前述したように、GraphQLはクライアントとサーバーの間の追加のレイヤーであり、このアーキテクチャを見ると、GraphQLの使用は一種の冗長に見えます。
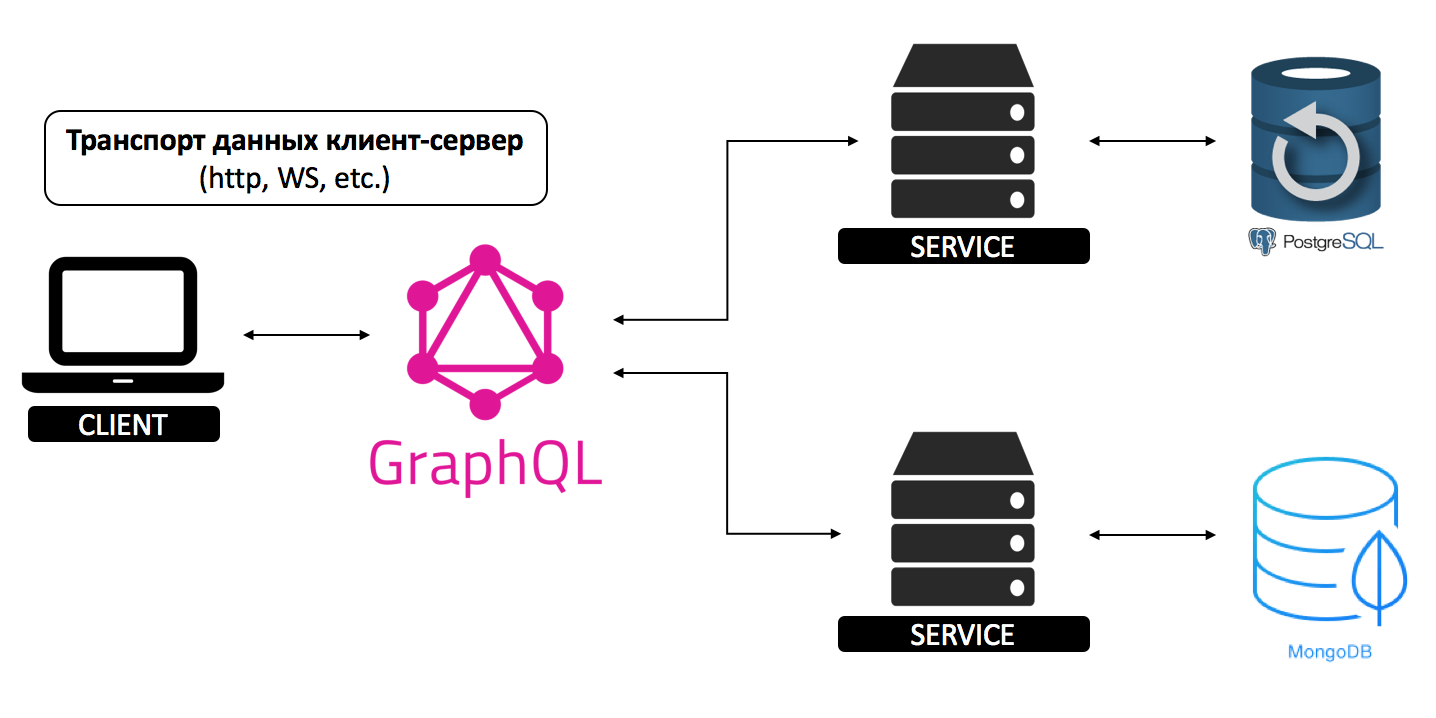
しかし、別のサービスが追加されるとすぐに、すべてが適切に配置されます。
サービスは任意のプログラミング言語で記述でき、異なるデータベース、SqlまたはNoSqlと対話でき、異なるAPIを使用できます。 このようなアーキテクチャでの作業は非常に難しくなり、新しいサービスを追加するたびに多くのリソースが必要になります。
これは、プロジェクトのスケーリングに関する古典的な問題であり、複数のサービスを使用する場合は、おそらくある種の「API Gateway」を使用するでしょう。GraphQLは、この標準化されたAPIゲートウェイです。 クライアントサーバーデータ転送は、任意のプロトコル(http、ssh、ws、cliなど)を使用して実行できます。
クライアントは、GraphQLクエリを使用してGraphQLサーバーにリソースを要求します。 GraphQLサーバーはクエリを分析し、再帰的にグラフを調べて、各フィールドに対して「リゾルバー」機能を実行します。 要求に関するすべてのデータが収集されると、GraphQLサーバーは応答を返します。
新しいサービスを追加しても、既存のアプリケーションには影響しないことに注意してください。 クライアントが受信するデータを決定するという事実により、既存のタイプを拡張することを恐れることはできません。
型システム
GraphQLは型システムを使用してデータを記述します。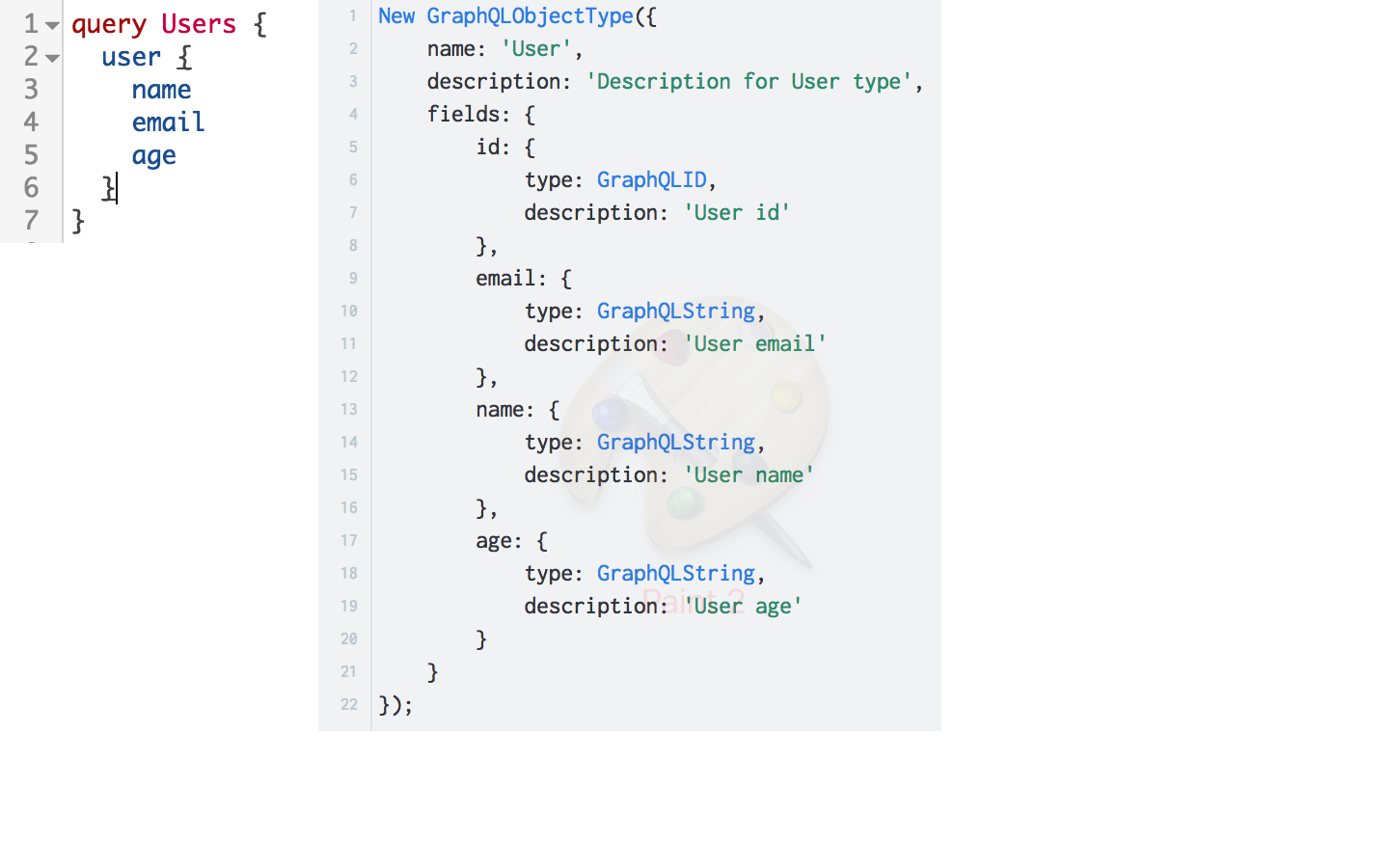
GraphQLでは、フィールドは基本タイプとユーザータイプの両方で表すことができます。 この例では、ユーザーフィールドはユーザータイプUserで表されます。 ユーザータイプは、基本タイプで表される一連のフィールドを記述します。
したがって、ネストの不定レベルのグラフのような構造が実現されます。GraphQL APIとREST APIを比較する
- データ転送プロトコルへの依存。
GraphQLはデータ転送プロトコルに依存せず、任意のもの(http、ws、ssh、cliなど)を使用できます。
RESTはhttpプロトコルに基づいており、それに依存しています。
- 単一のエントリポイント。 (エントリーポイント)
GraphQLでは、データを操作するために、常に単一のエントリポイントであるGraphQLサーバーを使用します。 構造、フィールド、クエリパラメーターを変更することで、さまざまなデータを処理します。
REST APIでは、各ルートは個別のエントリポイントを表します。
- さまざまなデータ形式を返す機能。
GraphQLはJSON形式のみを返すことができます。
この場合のRESTはより柔軟です。 REST APIは、さまざまな形式(JSON、XMLなど)でデータを返すことができます。これは、httpリクエストのヘッダーとAPI自体の実装に依存します。
- 宣言、ドキュメント、開発ツール
GraphQLは、コードでドキュメントを直接記述する機能を提供します(インラインドキュメント)。
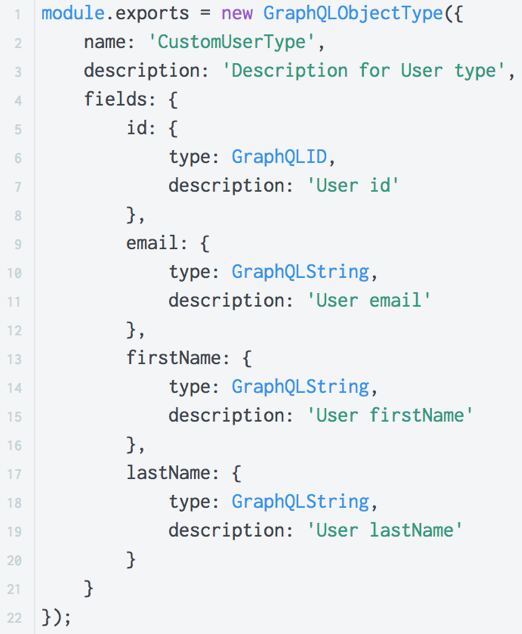
GraphQLでは、作成した任意のタイプを記述できます。 これを行うには、タイプを作成するときに、「説明」フィールドにこのタイプの目的を説明する必要があります。 さまざまなユーティリティ、IDEがこのドキュメントを解析できるため、GraphQLの操作が大幅に簡素化されます。
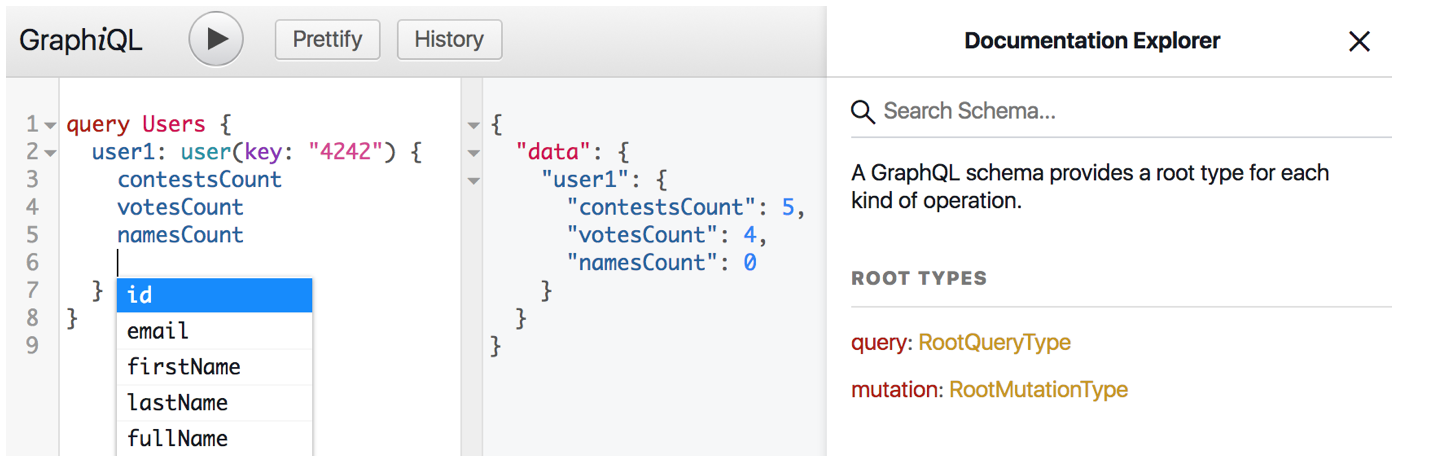
また、GraphQLには、ブラウザで動作する独自のIDEがあり、GraphiQLと呼ばれます。
GraphiQLはクエリ履歴を保存し、構文を強調表示し、現在のタイプからリクエストできるフィールドを要求し、ドキュメントを解析します。 これにより、クエリの記述が大幅に簡素化されます。
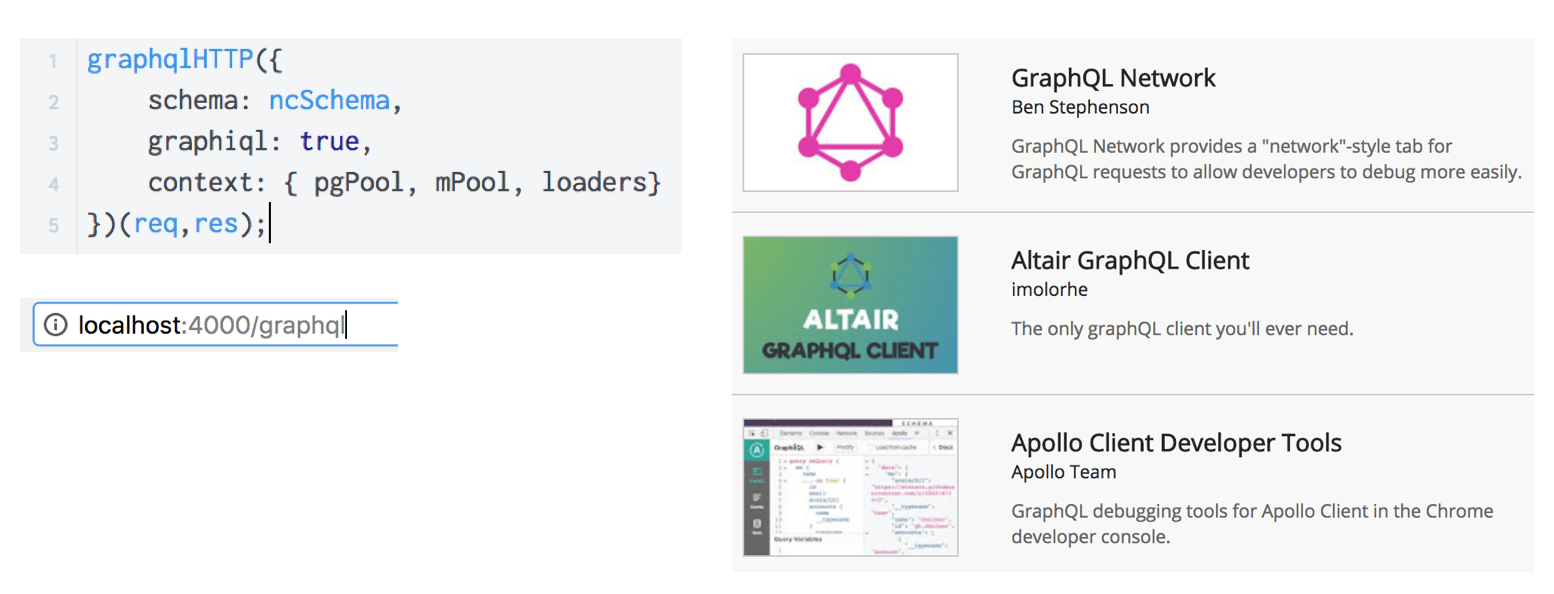
GraphiQLは、graphiql = true設定を使用し、パス<ドメイン名> / graphiqlを使用して、GraphQL構成を通じて有効にできます。 または、ブラウザの拡張機能の1つを使用できます。拡張機能は、ほぼ同じ機能を持ちますが、UIが異なります。
RESTには同様の機能はありませんが、SWAGGERを使用して実装することは可能です。

- クライアント上でデータの構造と量を形成する機能
実際、これはGraphQLの主な機能の1つであり、データの形式と構造はクライアント側で決定されます。 RESTでは、形式とデータ構造はサーバー上で厳密に定義されます。
- リクエストに引数を渡す

前の段落から結論を出すと、GraphQLはGraphQLの単一のエントリポイントであるため、どのレベルのネストにも引数を渡すことができるため、おそらくすでに答えを知っています。
RESTでは、各パスは個別のエントリポイントとして表されます。この場合、リクエスト全体に対してのみ引数を渡すことができます。
最初のパートのこの終わりに、2番目のパートがまもなく追加されます。 ありがとうございます!)