キャプチャを入力すると、キャプチャの長さは常に5文字であり、大文字と数字のみを使用していることに気付きました。 コードを確認すると、キャプチャイメージの名前がその文字からのmd5ハッシュであることがわかります。
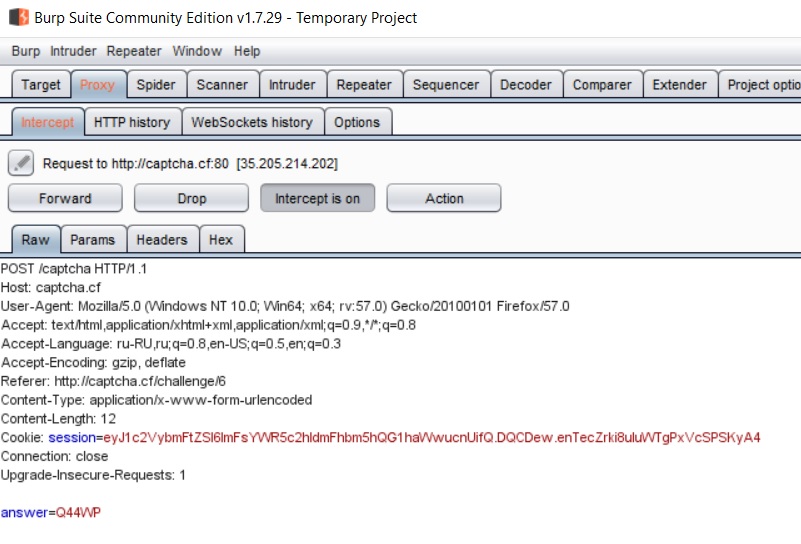
Burp Suiteによる分析では、キャプチャに対する回答である回答フィールドのみが必要であることが示されています。
小さなことは、ページコードから必要なハッシュ値を抽出し、それを使用してキャプチャの値を復元することです。 ただし、ハッシュ関数の逆を計算するのは難しいので、逆に行きましょう。 すべての可能なキャプチャ(大文字と数字のみ、キャプチャの長さは常に5文字のみ)とそれらからのmd5ハッシュの値のペアのテーブルをコンパイルしてみましょう。必要なキャプチャ値をハッシュで検索します。
def chal6(): resp = s.post('http://captcha.cf/challenge/6/start') for i in range(20): m = re.search(r'static/regenbogen/(.*?)\.png', resp.text) hash_ = m.group(1) word = sh.grep(hash_, 'md5_tables/' + hash_[0] + '.md5').split(':')[1].strip() print(hash_, word) resp = s.post('http://captcha.cf/captcha', data={'answer': word})
タスクを完了するには、追加の関数を記述する必要がありました。
- 大文字と数字で構成される5文字の長さの回答に対して、可能なすべてのmd5ハッシュを生成しました。
- 特定の時間にタスクを完了するために、最初の文字ですべてのハッシュをソートしました。 すなわち captchaハッシュの最初の文字を見て、必要な並べ替えブロックを開き、このブロックでのみ検索します。
alphabet = string.ascii_lowercase + string.digits def gen_md5_table(): a = string.ascii_uppercase + string.digits table = itertools.product(a, repeat=5) f = open('md5_table', 'w') for i in table: s = hashlib.md5(bytes(''.join(i), 'ascii')).hexdigest() + ':' + ''.join(i) print(s) f.write(s + '\n') f.close() <i>