転送エンティティは、常にフローごとの順序でパケットを転送します
ゼロ、1つ以上の転送エンティティ自身の送信インターフェイス
また、パケットを自身の受信インターフェイスに転送することはありません。
ブライアンピーターセン。 ハードウェア設計ネットワーク
私たちの時間の最も驚くべき成果の1つは、ノリリスクに座っている間に、タイの友人とチャットすると同時に、彼の夕方の飛行機のチケットを購入し、クレジットカードで支払うことです。ボットは、父親が部屋に入ったときに息子がタブを切り替える速度で取引所で取引を行います。
そして、10分後、彼は電話でアプリケーションを介してタクシーを注文し、道路で現金を受け取る必要さえありません。
空港で、彼は何時間も支払ったコーヒーを購入し、ベルリンで娘とビデオ通話をし、着陸する1時間前にオンラインキンツを起動します。
この間に、数千のMPLSタグがハングアップして削除され、さまざまなテーブルへの数百万の呼び出しが発生し、セルラーネットワークの基地局がギガバイトのデータ、数十億のパケットを電子および光子の形で光の速度で世界中のデータセンターに急送します。
それは電気の魔法ではありませんか?
QoSへの旅では、何度も約束されたトピックで、別の会議を行います。 今回は、通信機器のパッケージの寿命に目を向けます。 この青いボックスを開き、ガットします。
 クリック可能およびズーム可能。
クリック可能およびズーム可能。今日:
- パッケージの運命と経路について簡単に
- 飛行機(飛行機でもあります):転送/データ、制御、管理
- 誰がトラフィックをどのように処理するか
- チップタイプ:CPUからASICまで
- ネットワークデバイスのハードウェアアーキテクチャ
- 生涯の旅
今後は、飛行機について少しお話しし、いくつかの定義を紹介しましょう。
したがって、
2つのプレーンがあります。ネットワークデバイスのアーキテクチャは、コントロールとデータプレーンの2つの部分に非常に明確に分割されています。 これはエレガントなソリューションであり、数年前に物理トポロジからトラフィックパスを抽象化してパケットスイッチングを発生させ、今日の業界全体の基盤となっています。
データプレーンは、入力インターフェイスから週末へのトラフィックの転送です。宛先に少し近づきます。 データプレーンは、ルーティング/スイッチング/ラベル
テーブル (以降、
転送テーブルと呼ばれます)によって導かれます。 遅延の場所があります-すべてが迅速に発生します。
コントロールプレーンは、ネットワークステータスを監視し、転送テーブル(BGP、OSPF、LDP、STP、BFDなど)を設定するプロトコルのレイヤーです。 ここで速度を落とすことができます-主なことは、適切なテーブルを構築することです。
そのような分離が必要な理由は、対応する章を読んでください。
SDSMの以前の
14の部分はすべてコントロールプレーンに関するものであったため、今回は転送プレーンについて説明します。
そしてまず、トランジットとローカルパケットの概念を紹介します。
トランジットパケットは、データプレーンでのみ処理されるパケットであり、コントロールプレーンへの送信を必要としません。 ノードをすばやく透過的に通過します。
ほとんどの場合、これはユーザー(クライアント)データであり、その送信元および宛先アドレスはデバイス(および、一般的にはプロバイダーのネットワーク全般)の外部にあります。
通過トラフィックの中には、プロトコルトラフィックが存在する可能性があります-プロバイダーのネットワーク内部ですが、このノード向けではありません。
たとえば、BGPまたはターゲットLDP。
ローカルは3つの異なるタイプに分けられます。
- このデバイス上のアプリケーションを対象としています。 つまり、宛先アドレスが彼に属している(構成されている)。 デバイスがリッスンするブロードキャスト(ARP)またはマルチキャスト(OSPF Hello)宛先アドレス。
ここで、内部転送ヘッダーのアドレスについて話していることを理解することが重要です。たとえば、BGPまたはOSPFの場合はIP、ISISまたはSTPの場合はMACです。
同時に、 DIPが外部でDMACがローカルのパケットは、コントロールプレーンではなく外部の出力インターフェイスに配信する必要があるため、転送中のままです。
- このデバイスによって生成されます。 つまり、CPU上、コントロールプレーン上で作成され、データプレーンに送信されます。
- コントロールプレーンでの処理が必要な通過パケット。 例として、TTLの有効期限が切れたパケットがあります-ICMP TTL Expired in Transitを生成する必要があります。 または、IPオプションがインストールされたパケット:ルーターアラートまたはレコードルート。
この記事では全員についてお話します。 しかし、主にトランジットに関するものです-プロバイダーがお金を稼ぐのは彼らの上にあるからです。
1.パッケージの運命と経路について簡単に説明します
パッケージとは、IPパケット、フレーム、セグメントなど、あらゆるレベルのPDUを意味します。 これが情報の形成されたパッケージであることは私たちにとって重要です。
記事全体では、パケットを転送する特定のモジュラーノードについて検討します。 読者を混乱させないために、 これがルーターであると判断します 。
ヘッダー、プロトコル、およびパケットの特定のアクションに合わせて調整されたこの記事のすべての引数は、ルーター、ファイアウォール、スイッチのいずれであっても、すべてのネットワークデバイスに適用できます。タスクは、宛先に近い次のノードにパケットを転送することです。
噂や不適切な批判を避けるため、著者は実際の状況は特定のデバイスに依存することを認識しています。 ただし、この記事の目的は、ネットワーク機器の動作原理を一般的に理解することです。
出発点として次のスキームを選択します。
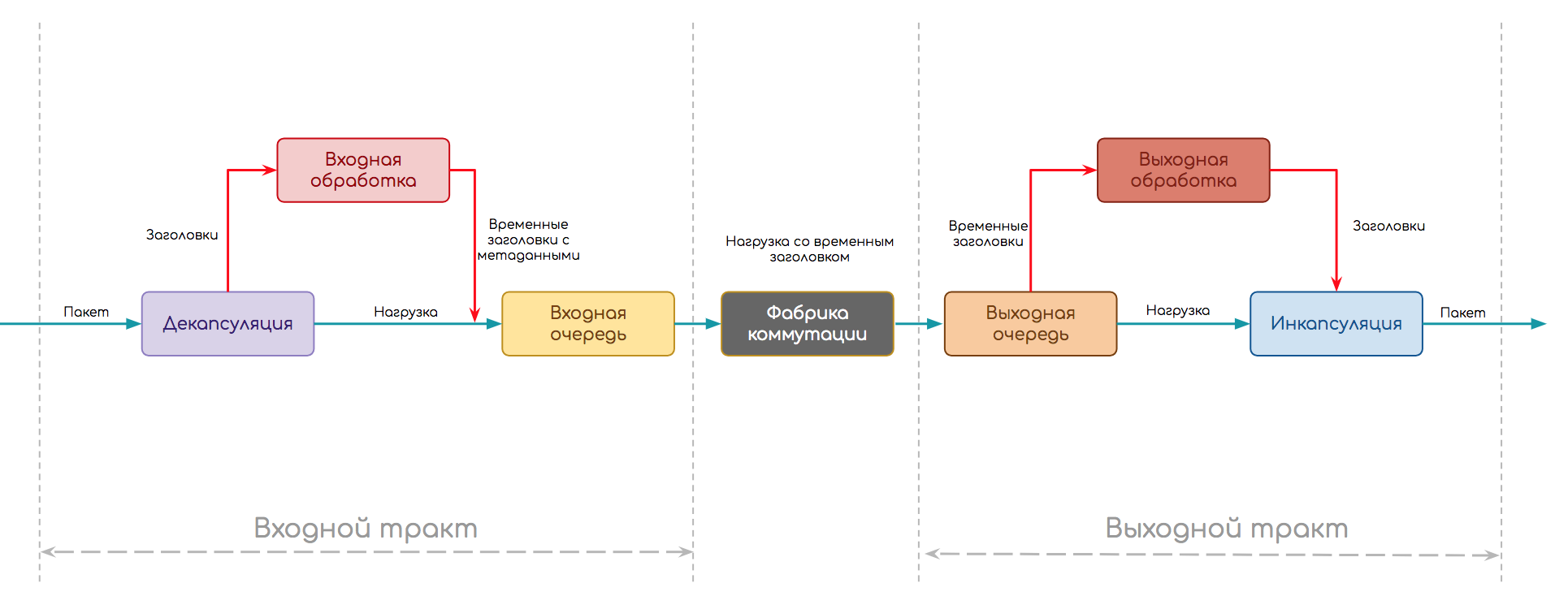
トラフィック処理が実装されているデバイスの種類に関係なく、パケットはこのようにする必要があります。
- パスは、入力パスと出力パスの2つの部分に分かれています。
- 入力時に、カプセル化解除が最初に発生します-ペイロードからのヘッダーの分離とプロトコルに固有のその他のもの(たとえば、チェックサムの計算)
- 次に、入力処理(イングレス処理)の段階-ヘッダー(ロード)のないパケット自体がバッファー内で弱まり、ヘッダーが分析されます。 ここでは、ポリシーをパッケージに適用したり、宛先と出力インターフェイスを検索したり、コピーを作成したりできます。
- 分析が完了すると、ヘッダーはメタデータ(一時ヘッダー)に変換され、パケットに接着され、入力キューに転送されます。 これにより、処理可能な量を超えて出力パスに送信することはできなくなります。
- さらに、パケットは出力キューに移動するための明示的な許可を待つ(または要求する)ことも、単にそこに転送してそこに行き、それを把握することもできます。
- 複数の出力パスが存在する可能性があるため、パケットはスイッチングファクトリに送られます。その目的は、正しいファクトリにパケットを配信することです。
- 出力路にもキューがあります-出力です。 その中で、パケットは出力処理を期待します:ポリシー、QoS、複製、シェーピング。 将来のパケットヘッダーもここで形成されます。 また、出力キューは、インターフェースにスキップできる以上のデータを転送しないために役立ちます。
- 最後の段階は、準備されたヘッダーにパケットをカプセル化して渡すことです。
この単純化されたスキームは、多かれ少なかれ普遍的です。 プロトコルスタックを見て、少し複雑にしましょう。 たとえば、IPルーターは最初に電気インパルスからビットストリームを復元し、次に使用されるチャネルプロトコルのタイプを認識し、フレーム境界を決定し、イーサネットヘッダーを削除し、その下にあるものを見つけて(IPにします)、さらに処理するためにIPパケットを送信する必要があります。
次に、回路は次のようになります。
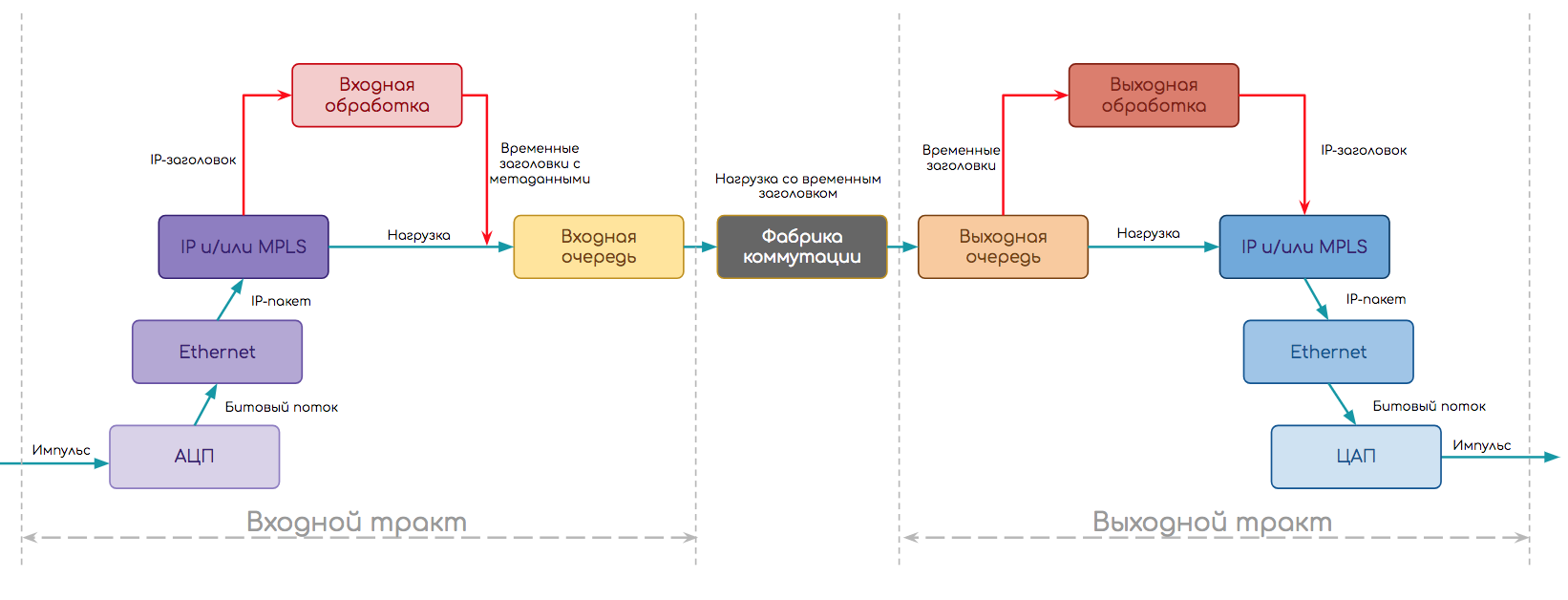
- 最初に物理層モジュールを作成しました。
- ADCを使用して、ビットストリームを復元しました-ある意味、物理層のカプセル化解除。
- 特定のタイプのポート(イーサネット)で作業している彼は、イーサネットモジュールが出力インターフェイスになることを認識しています。
- 次に、 イーサネットモジュールでカプセル化解除と入力処理が行われます。
- フレーム境界、プリアンブル、 IFG 、 FCS
- チェックサム計算
- 見出しの削除、フィールドの分析
- ポリシーの施行
- 宛先アドレスの決定-ローカルです-そして、出力インターフェースはIPモジュールになります。
- IP入力処理:
- 見出しの削除、フィールドの分析
- ポリシーの施行
- 宛先アドレス分析
- 転送テーブルで出力インターフェイスを見つける
- 一時的な内部ヘッダーの形成
- データで一時ヘッダーを接着し、出力パスにパケットを送信します。
- 入力キューで処理しています。
- 交換工場からの出荷。
- 出力キューでの処理。
- 出力パスで、 IPモジュールは出力処理を実行します。
- ポリシーの実施、形成
- メタデータ(一時ヘッダー)に基づく最終ヘッダーの形成と、イーサネットモジュールへの転送。
- イーサネットモジュールでの次のアウトバウンド処理
- 次のノードのMACアドレスをARPテーブルで検索します
- イーサネットヘッダー
- チェックサム計算
- ポリシーの施行
- 物理モジュールへの降下。
- そして、 物理層モジュールは、ビットストリームを電気的なインパルスに分割し、ケーブルに転送します。
*操作手順は概算であり、実装によって異なる場合があります。
上記のすべての手順は、数百の小さな手順に分解され、それぞれをハードウェアまたはソフトウェアで実装する必要があります。
それが問題です-ハードウェアまたはソフトウェアで 。 IPネットワークの発足以来、IPネットワークの世界に出没し続けており、通常どおり、開発は周期的に行われています。
要素ベースが存在する些細なものがあります... mmm ... 60年代以来。 たとえば、
ADC 、ハードウェアキュー、またはCPU。 そして、比較的最近ブレークスルーとなったものがあります。 機能の一部は常にハードウェアであり、一部は常にソフトウェアであり、一部はその猿のように急いでいます。
この記事では、主にハードウェアデバイスについて説明し、途中で仮想デバイスについてのみ説明します。
2.レベルと平面

これらの概念を何度も使用してきたので、定義を行う時が来ました。 機器の操作では、3つのレベル/平面を区別できます。
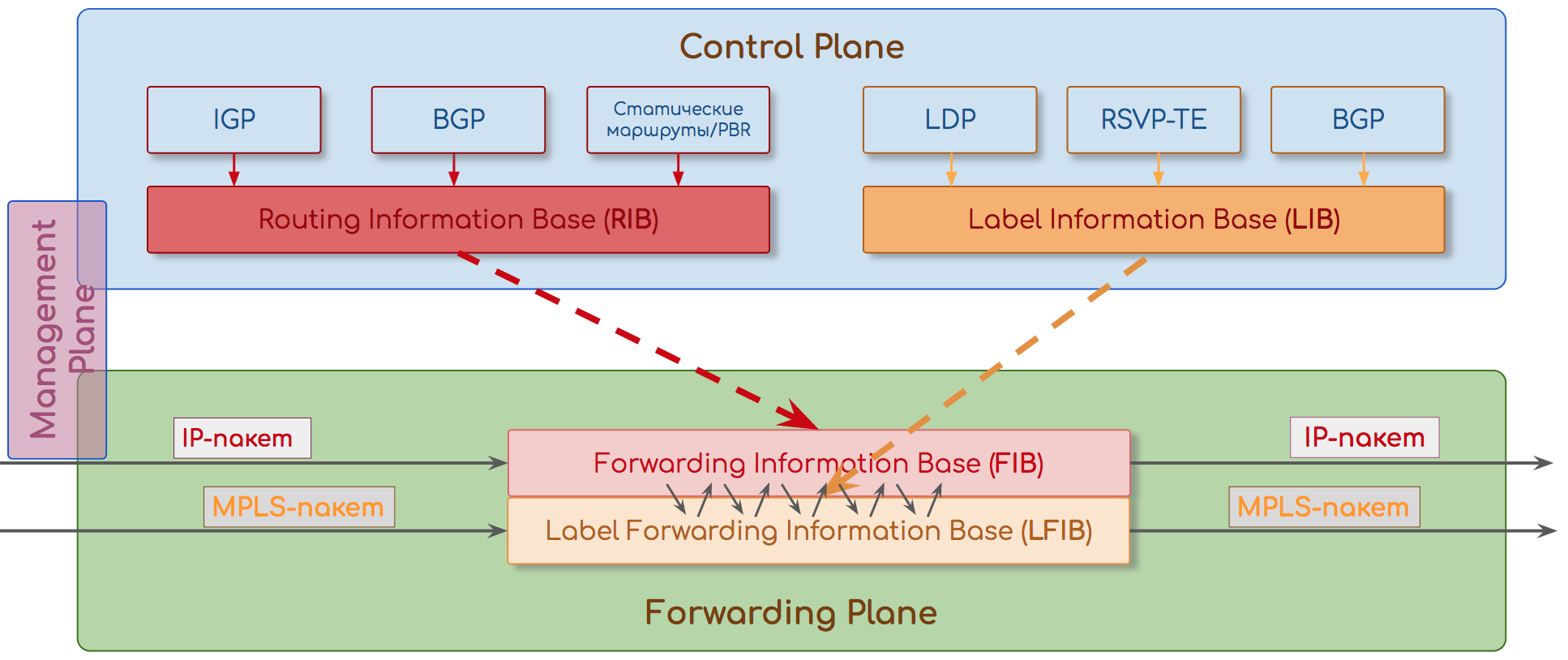
転送/データプレーン
フォワーディングプレーン。
ネットワークの主なタスクは、あるアプリケーションから別のアプリケーションにトラフィックを配信することです。 そして、帯域幅と遅延の両方の面で、できるだけ早くそれを行います。
したがって、ノードの主なタスクは、ヘッダーを変更してポリシーを適用する時間を確保しながら、着信パケットをできるだけ早く正しい出力インターフェイスに転送することです。
そのため、スイッチングテーブル、ルーティングテーブル、ラベルテーブル、近隣テーブルなど、あらかじめ設定されたパケット転送テーブルがあります。
これらは、回線(インターフェイス)速度で動作する特別なCAM、TCAMチップに実装できます。 そして、それらはソフトウェアであり得る。
例:
- イーサネットフレームを受信し、チェックサムを計算し、MACアドレステーブルにSMACがあるかどうかを確認します。 MACアドレステーブルでDMACを見つけ、インターフェイスを決定し、フレームを転送します。
- MPLSパケットを受信し、入力インターフェイスと入力ラベルを定義します。 ラベルテーブルを検索し、出力インターフェイスと出力ラベルを定義します。 スイープ。 渡します。
- パケットのストリームが到着しました。 出力インターフェイスはLAGでした。 どのインターフェイスに送信するかは、フォワーディングプレーンでも決定されます。
データと転送プレーンの違いほとんどの場合、データと転送プレーンは同一であると考えられています。
ただし、場合によっては分離されます。
データプレーンとは、ペイロードを操作することを意味します。入力インターフェイスから出力インターフェイスにパケットを配信し、バッファで処理するプロセスです。
また、転送プレーンはヘッダーを処理し、転送の決定を下しています。
このようなもの:
コントロールプレーン
コントロールプレーン。
頭全体。 テーブルを
事前に設定し 、トラフィックを送信します。
ここでは、ハードウェアで実行するのが高価または不可能な複雑なアルゴリズムを備えたプロトコルが機能します。
たとえば、
ダイクストラのアルゴリズムはチップ上に実装できますが、困難です。 また、最適なBGPルートを選択したり、FECおよびラベル配布を決定したりすることも困難です。 さらに、このすべてのために、再利用がほとんどできない別のチップまたはチップの一部を作成する必要があります。
このような状況では、利便性と価格を優先して、1秒未満の収束を犠牲にすることをお勧めします。
したがって、ソフトウェアは汎用CPUで実行されます。
ゆっくりですが、柔軟になります-すべてのロジックはプログラム可能です。 実際、コントロールプレーンの速度は重要ではありません。 計算されたルートがFIBにインストールされると、すべてが回線速度ではなくなります。
コントロールプレーンの速度の問題は、ネットワークの中断、変動の際に発生しますが、同じコントロールプレーンでサイディングが事前に準備されている場合、TE HSB、TE FRR、IP FRR、VPN FRRメカニズムによって比較的うまく解決されます。
例:
- IGPを使用してネットワークを開始しました。 Helloの生成、セッションパラメータの調整、データベースの交換、最短ルートの計算、ルーティングテーブルへのインストール、定期的なキープアライブによる連絡の維持が必要です。
- BGPアップデートが到着しました 。 コントロールプレーンは、BGPテーブルに新しいルートを追加し、最適なルートを選択してルーティングテーブルにインストールし、必要に応じて更新を送信します。
- 管理者はLDPを有効にしました。 プレフィックスごとに、 FECが作成され、ラベルが割り当てられ、ラベルテーブルに配置され、アナウンスメントがすべてのLDPネイバーに送信されます。
- スタック上に2つのスイッチを収集しました。 メインプレーンの選択、インターフェイスのインデックス作成、転送テーブルの更新は、コントロールプレーンのタスクです。
コントロールプレーンの操作と実装は普遍的です。CPU+ RAM:少なくとも仮想ネットワークデバイスでは、ラックマウントルーターでも同じように動作します。
このシステムは、1つのプログラムのさまざまな機能ではなく、思考実験ではありません。これらは、相互に作用する物理的に分離されたパスです。
それはすべて、異なるボード上のプレーンの分離から始まりました。 次に、スタック可能なデバイスが登場しました。1つはインテリジェントな操作を実行し、もう1つはインターフェイスの付属物にすぎませんでした。
昨日、それはCisco Nexus 5000スイッチ+ Nexus 2000ファブリックエクステンダーのようなシステムで、2000は5000のリモートインターフェイスボードとして機能します。
パラレルユニバースのどこかで、SDN流出1.0は静かに生きています-コントロールプレーンが外部コントローラーに持ち込まれ、トランスファーテーブルが完全に愚かなスイッチに注がれるOpenflowのようなメカニズムを備えています。
私たちの現実と近い将来は、SDNコントローラーによって構成されたオーバーレイネットワークであり、サービスはより高い階層レベルの物理トポロジから抽象化されます。
そして、各記事で詳細に深く没頭しているという事実にもかかわらず、私たちは自由にグローバルに考えることを学びます。
コントロールプレーンとフォワーディングプレーンの分離により、データ転送をプロトコルおよびネットワーク構築の作業から切り離すことができました。これにより、スケーラビリティと耐障害性が大幅に向上しました。
したがって、1つのコントロールプレーンモジュールで複数のインターフェイスモジュールをサポートできます。
コントロールプレーンで障害が発生した場合、
GR、NSR 、
GRES、および
ISSUメカニズムは、転送プレーンが何も起こらなかったかのように動作し続けるのに役立ちます。
管理面
観測面または悪魔。 それは、そのタスクをコントロールプレーンに関連付ける独立したプレーンに常に区別されるわけではなく、時にはそれを強調して、モニタリングと呼ばれます。
このモジュールは、ノードの構成と操作を行います。 次のようなパラメータを監視します。
- 温度
- リソース使用率
- 電源
- ファン速度
- ボードとモジュールのパフォーマンス。
例:
- インターフェースが落ちた-事故が発生し、ログと監視システムへのはしご
- チップの温度が上がりました-ファンの速度が上がります
- あるボードが定期的なリクエストへの応答を停止したことを発見しました-ボードを再起動します-それは突然上昇します。
- オペレーターがSSH経由で接続して診断情報を削除します-CLIはコントロールプレーンからも提供されます。
- Netconf構成が到着しました-管理プレーンが検証して適用します。 必要に応じて、行われた変更と必要なアクションについてコントロールプレーンに指示します。
だから:
フォワーディングプレーン -フォワーディングテーブルに基づくトラフィック転送-これは、まさにオペレーターが利益を得るものです。
コントロールプレーン -転送プレーンの条件を作成するために必要なサービスレベル。
管理プレーン -デバイスの全体的なステータスを監視するモジュール。
一緒になって、パケット交換ネットワークの自己完結型ノードを構成します。
コントロールとフォワーディング/データプレーンへの分離は抽象的ではありません-それらの機能は、ボード上の異なるチップによって実際に実行されます。
コントロールプレーンは通常、CPU + RAM +メモリカードの束に実装され、ASIC、FPGA、CAM、TCAMの転送プレーンに実装されます。
しかし、ネットワーク機能の仮想化の世界では、すべてが混同されています。この発言は記事の終わりまで行います。
3.トラフィック処理方法の歴史
Forwarding Planeでは、10 Gb / s、100 Gb / s-簡単です-有料で使用できます。 パフォーマンスに影響を与えないポリシー。 しかし、常にそうではありませんでした。
難点は何ですか?
まず第一に、それは上記の経路を整理することの問題です。1本のケーブルからの電気インパルスをどう処理し、それを別のケーブルに転送する方法は正しいです。
これを行うために、ネットワークデバイスにはさまざまなチップがたくさんあります。
 これは、Ciscoインターフェイスボードの例です。
これは、Ciscoインターフェイスボードの例です。そのため、たとえば、超小型回路(ASIC、FPGA)は、
ADC /
DAC 、チェックサム計算、パケットバッファリングなどの簡単な操作を実行します。
また、パケットヘッダーを解析、分析、生成できるモジュールも必要です。
そして、どこで、どのインターフェースで、パケットを転送する必要があるかを決定するモジュール。 あなたは神のすべてのパッケージに対してこれをする必要があります。
また、このパケットをまったくスキップできるかどうかを監視する必要があります。 つまり、ACLに準拠しているかどうかを確認し、流量を制御し、超過した場合は破棄します。
アドレス変換、ファイアウォール、バランシングなどのより複雑な機能をここに入力することもできます。
従来、すべての複雑なアクションはCPUで実行されていました。 ルーティングテーブルでの適切なルートの検索はプログラムコードとして実装され、ポリシーの満足度のチェックも実装されました。 プロセッサはこれに対処しましたが、彼だけがそれに対処しました。
これが何を脅かすかは理解できます。パフォーマンスが低下するほど、デバイスがより多くのトラフィックを処理する必要があり、より多くの機能がハングアップします。 そのため、ほとんどの機能は次々に別のチップに委任されました。
そして、通常のx86サーバーから、ルーターは、あいまいな詳細とインターフェイスでいっぱいの専用ネットワークボックスに変わりました。 そして、イーサネットハブはインテリジェントスイッチに変身しています。
ヘッダーの解析と分析、および出力インターフェイスの検索のための機能は、ASIC、FPGA、ネットワークプロセッサに引き継がれました。
キューイング、QoS、輻輳管理も特殊なASICです。
セッション数が食べられないため、ステートフルファイアウォールのようなものがCPUに残りました。
別の質問:スイッチングテーブルを格納する必要がある場所。 速いもの。
最初に思い浮かぶのは、古典的なランダムアクセスメモリです。
それに関する問題は、それへの呼び出しがセルのアドレスに行き、そのコンテンツ(またはロシア語ではないコンテンツ)を返すことです。
ただし、着信パケットにはメモリセルのアドレスは含まれず、MAC、IP、MPLSのみが含まれます。
次に、CPUを使用してセルのアドレスを計算し、そこから必要なデータを抽出する、ある種のハッシュアルゴリズムが必要になります。
これは10 Gb / sのポート帯域幅であり、CPUは10 nsごとに1ビットを送信する必要があります。 また、1キロバイトのパケットを送信するのに約80マイクロ秒かかります。
ただし、ハッシュ計算は非常に単純なアルゴリズムであり、自尊心のあるASICがこれを処理します。 エンジニアは質問をされました-ハッシュをどうするか?
そのため、
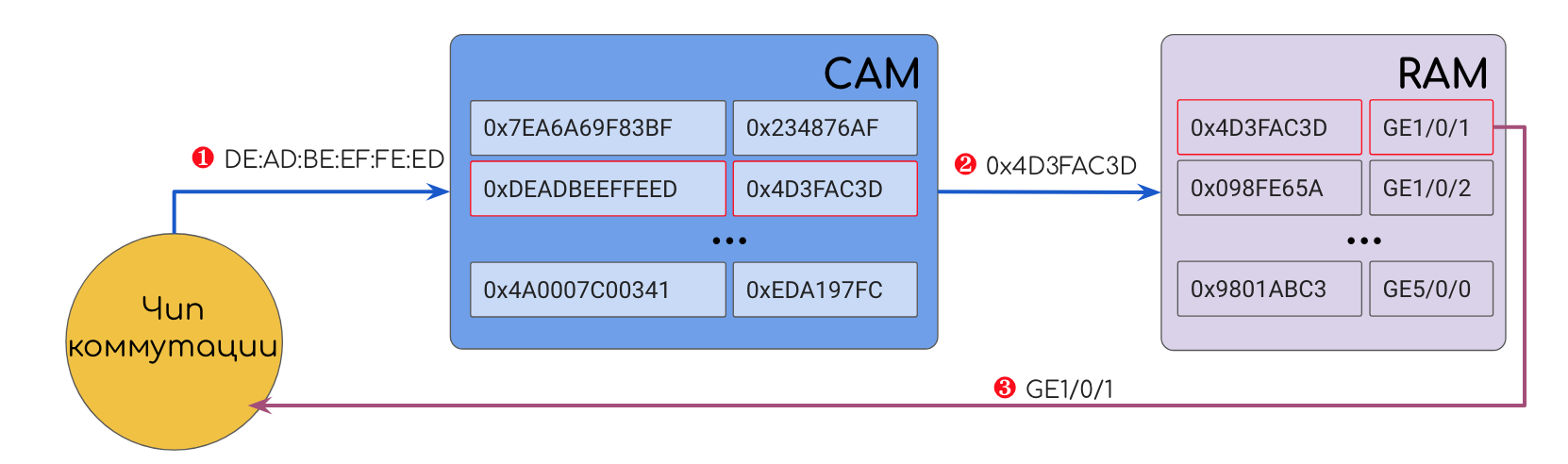
CAM-Content Addressable Memoryがありました 。 そのアドレスは値のハッシュです。 CAMのセルには、応答値(ポート番号など)が含まれているか、通常は通常のRAMのセルアドレスが含まれています。
つまり、イーサネットフレームが到着し、ASICがそれをヘッダーに引き裂き、DMACを引き出しました-CAMを介して駆動し、切望された発信インターフェイスを取得しました。次はCAMの詳細。
IPの何が問題なのですか?!
Ethernetフレームを例にとったのは無駄ではありませんでした。IPはまったく別の話です。MACスイッチングは簡単です。ルートアグリゲーションも最長プレフィックス一致も、48ビットの一意のビットではありません。しかし、IPではすべてです。ルーティングテーブルには、マスクの長さが異なる複数のルートを含めることができます。最も長いルートを選択する必要があります。これは、議論することも回避することもできないIPルーティングの基本原則です。さらに、ワイルドカードマスクを持つ複雑なACLがあります。長い間、この問題の解決策は存在しませんでした。パケット交換ネットワークの夜明けに、IPパケットはCPUで処理されました。そして、これの主な問題は、回線速度での切り替えでさえありませんが、パフォーマンスへの追加設定の影響です。いくつかのホームミクロティックスで表示できるようになりました。ダースACLで構成すると、帯域幅がどのように低下するかがすぐにわかります。インターネットが成長し、政治家が増え、帯域幅の要件が飛躍的に増加し、CPUが障害になりました。さらに、ルートの検索は時々複数回行われなければならないことを考えると、再帰的にさらに深く潜ります。だから、威勢のいい90年代にMPLSが生まれました。コントロールプレーン上で事前に構築するのは素晴らしいアイデアです。MPLSのアドレスは固定長のラベルであるため、ラベルテーブルに1つのエントリが必要です。これは、パッケージで次に何をするかです。同時に、私たちはIPの柔軟性を失うことはありません。それが基本であり、CAMを使用できるからです。さらに、MPLSヘッダーは短く(4バイト対20 IP)、非常にシンプルです。しかし、皮肉なことに、同時に、エンジニアはTCAM-Ternary CAMを開発することで突破口を開きました。それ以降、ほとんど制限はありませんでした(ただし、予約なしではありません)。TCAMからもっと。MPLSについては、この出来事のために、かろうじて生まれて突然死んでいたはずでしたが、その後彼は別の家へとドアを切りました。しかし、我々はすでにこれについて話しました。
ああ、勇敢な新しい世界
SDN NFV . , , , .
- .
- , .
- (Service Chain), Anti-DDoS, IDS/IPS, FW , .
. . CAM, TCAM, NP, ASIC DPDK , — SR-IOV — .
, , CAM/TCAM .
Forwarding Plane.
.
4. -
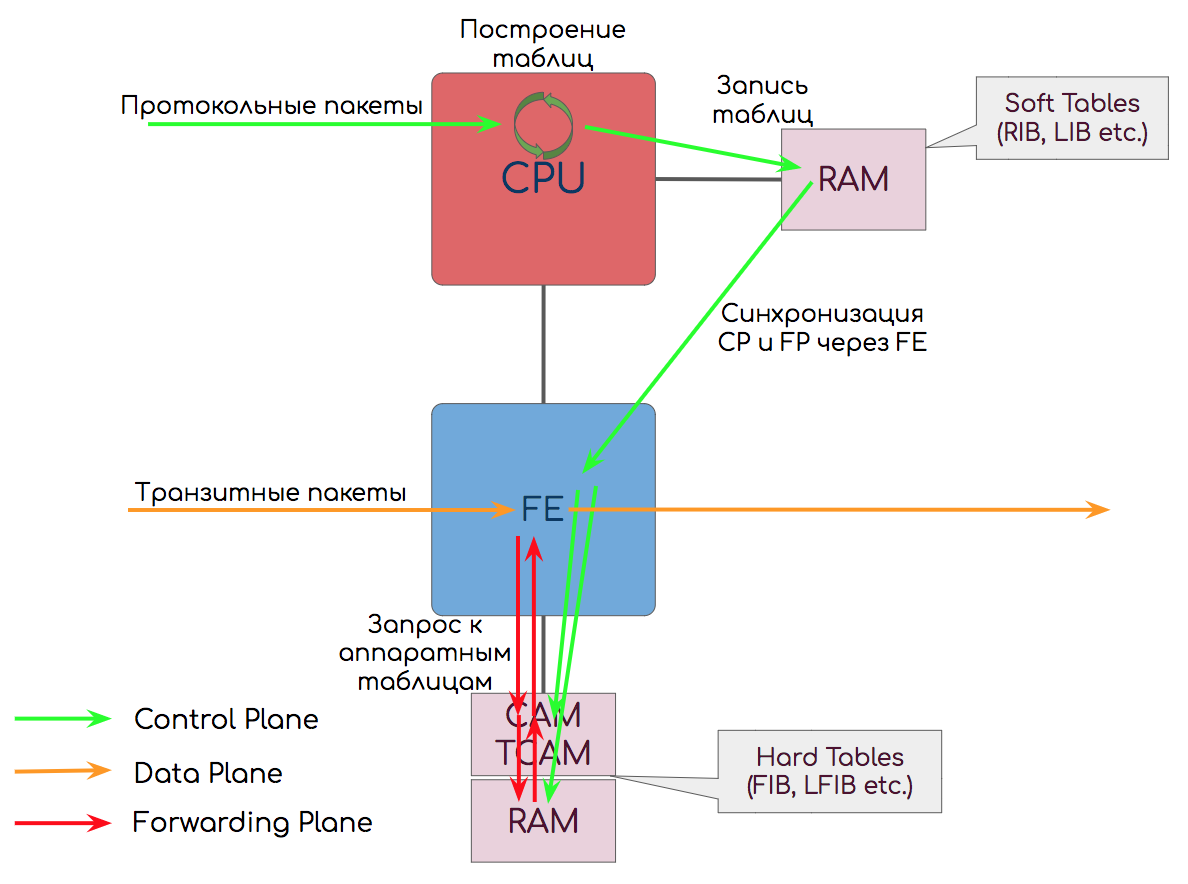
— , .CPU — Central Processing Unit
デバイスの最も遅いが最も柔軟な要素は中央処理装置です。彼はプロトコルパケットと複雑な動作を処理します。 その魅力は、実行中のアプリケーションによって制御され、「マルチタスク」であることです。プログラムコードを調整するだけで、ロジックを簡単に変更できます。SPF、すべてのプロトコルにわたる近隣の設定、ログの生成、クラッシュ、ユーザー管理インターフェイスへの接続(複雑なロジックを持つすべてのアクション)などがSPFで発生します。したがって、実際には、たとえば、高負荷ではコンソールでCPUが快適に動作しなくなることがわかります。同時にトラフィックは自信を持って行きますが。CPUはコントロールプレーン機能を引き継ぎます。ソフトウェア転送を備えたデバイスでは、Forwarding Planeにも参加します。CPUはノード全体に1つでも、分散アーキテクチャのシャーシ内の各ボードに個別に搭載することもできます。CPUは、作業結果をRAM↓に書き込みます。
その魅力は、実行中のアプリケーションによって制御され、「マルチタスク」であることです。プログラムコードを調整するだけで、ロジックを簡単に変更できます。SPF、すべてのプロトコルにわたる近隣の設定、ログの生成、クラッシュ、ユーザー管理インターフェイスへの接続(複雑なロジックを持つすべてのアクション)などがSPFで発生します。したがって、実際には、たとえば、高負荷ではコンソールでCPUが快適に動作しなくなることがわかります。同時にトラフィックは自信を持って行きますが。CPUはコントロールプレーン機能を引き継ぎます。ソフトウェア転送を備えたデバイスでは、Forwarding Planeにも参加します。CPUはノード全体に1つでも、分散アーキテクチャのシャーシ内の各ボードに個別に搭載することもできます。CPUは、作業結果をRAM↓に書き込みます。
RAM-ランダムアクセスメモリ
クラシックRAM-それがなければどこに? 私たちは彼女にセルのアドレスを与えます-彼女は私たちに内容を与えます。いわゆるソフトテーブル(プログラムテーブル)-ルーティングテーブル、ラベル、MACアドレスを格納します。「show ip route」コマンドを実行すると、要求はRAMからソフトテーブルに送られます。CPUはRAMと正確に連携します-彼がルートを計算したとき、またはLSPを構築したとき、結果はそこに書き込まれます。そしてそこから、変更はCAM / TCAM↓のハードテーブルで同期されます。さらに、何らかの理由でインクリメンタルな変更が正しく行われなかった場合に備えて、すべてのテーブルの内容全体が定期的に同期されます。ソフトテーブルは遅すぎるため、データの転送に直接使用することはできません。RAMへのアクセスはCPUを通過し、アルゴリズム検索が必要で、時間がかかります。NFVの予約あり。さらに、キューはRAM(DRAM)チップ(入力、出力、インターフェース)に実装されます。
私たちは彼女にセルのアドレスを与えます-彼女は私たちに内容を与えます。いわゆるソフトテーブル(プログラムテーブル)-ルーティングテーブル、ラベル、MACアドレスを格納します。「show ip route」コマンドを実行すると、要求はRAMからソフトテーブルに送られます。CPUはRAMと正確に連携します-彼がルートを計算したとき、またはLSPを構築したとき、結果はそこに書き込まれます。そしてそこから、変更はCAM / TCAM↓のハードテーブルで同期されます。さらに、何らかの理由でインクリメンタルな変更が正しく行われなかった場合に備えて、すべてのテーブルの内容全体が定期的に同期されます。ソフトテーブルは遅すぎるため、データの転送に直接使用することはできません。RAMへのアクセスはCPUを通過し、アルゴリズム検索が必要で、時間がかかります。NFVの予約あり。さらに、キューはRAM(DRAM)チップ(入力、出力、インターフェース)に実装されます。
CAM-連想メモリ
これは特に扱いにくい種類のメモリです。あなたは彼女に値を伝え、彼女はあなたにセルのアドレスを伝えます。Content-Addressableは、アドレス指定が値(コンテンツ)に基づいていることを意味します。 例えば、値は、例えば、DMACであり得る。CAMはすべてのレコードでDMACを実行し、一致を見つけます。その結果、CAMは出力インターフェイス番号が保存されているクラシックRAMのセルアドレスを表示します。さらに、デバイスはこのセルにアクセスし、あるべき場所にフレームを送信します。最高速度を実現するために、CAMとRAMは非常に近接しています。
例えば、値は、例えば、DMACであり得る。CAMはすべてのレコードでDMACを実行し、一致を見つけます。その結果、CAMは出力インターフェイス番号が保存されているクラシックRAMのセルアドレスを表示します。さらに、デバイスはこのセルにアクセスし、あるべき場所にフレームを送信します。最高速度を実現するために、CAMとRAMは非常に近接しています。このRAMを上記のソフトテーブルを含むRAMと混同しないでください-これらは異なる場所にある異なるコンポーネントです。
 CAMの長所は、テーブルのレコードの数とサイズに関係なく、一定時間の結果を返すことです-O(1)、アルゴリズムの複雑さで表されます。これは、値がすべてのレコードと同時に比較されるという事実により達成されます。同時に!そして、あまり多くはありません。CAMの各ストレージセルの入り口には比較要素があり(コンパレータという用語が本当に好きです)、受信した内容と書き込まれた内容に応じて0(オープン)または1(クローズ)を生成できます。比較要素には、必要な値のみが書き込まれます。特定の値に対応するテーブル内のエントリを見つける必要がある場合、この値はすべての比較要素で同時に実行されます。文字通り、値を運ぶ電気インパルスは、それらが並列に接続されているという事実のために、すべての要素に落ちます。それぞれが非常に単純なアクションを実行し、ビットが一致する場合は各ビットに1を、一致しない場合は0を、つまり、コンタクトを閉じたり開いたりします。したがって、アドレスが目的の値であるセルが回路全体を閉じ、電気信号が通過して供給されます。このようなメモリのアーキテクチャは次のとおりです。写真のソース 。これは
CAMの長所は、テーブルのレコードの数とサイズに関係なく、一定時間の結果を返すことです-O(1)、アルゴリズムの複雑さで表されます。これは、値がすべてのレコードと同時に比較されるという事実により達成されます。同時に!そして、あまり多くはありません。CAMの各ストレージセルの入り口には比較要素があり(コンパレータという用語が本当に好きです)、受信した内容と書き込まれた内容に応じて0(オープン)または1(クローズ)を生成できます。比較要素には、必要な値のみが書き込まれます。特定の値に対応するテーブル内のエントリを見つける必要がある場合、この値はすべての比較要素で同時に実行されます。文字通り、値を運ぶ電気インパルスは、それらが並列に接続されているという事実のために、すべての要素に落ちます。それぞれが非常に単純なアクションを実行し、ビットが一致する場合は各ビットに1を、一致しない場合は0を、つまり、コンタクトを閉じたり開いたりします。したがって、アドレスが目的の値であるセルが回路全体を閉じ、電気信号が通過して供給されます。このようなメモリのアーキテクチャは次のとおりです。写真のソース 。これは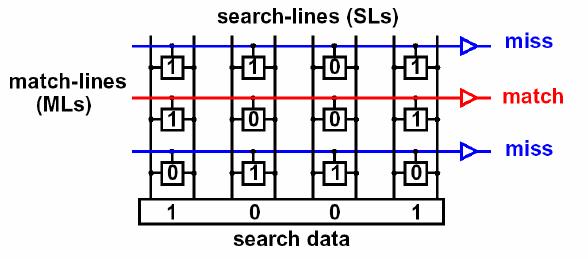 好奇心のあるドキュメントからの写真の 例です。そして、これは実装スキームです:
好奇心のあるドキュメントからの写真の 例です。そして、これは実装スキームです: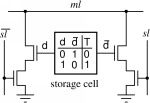 写真のソース 。これは、キーロックペアのようなものです。正しい形状のキーのみが、ロックピンを正しい位置に配置してシリンダーを回転させることができます。しかし、1つのキーの多くのコピーと多くの異なるロック構成しかありません。そして、それらをすべて同時に挿入してクランキングを試みます。目的の値がそのドアの後ろにあり、その鍵で鍵が開きます。CAMを柔軟に使用するために、ヘッダーフィールドから値を直接取得するのではなく、ハッシュを計算します。ハッシュ関数は、次の目的で使用されます。
写真のソース 。これは、キーロックペアのようなものです。正しい形状のキーのみが、ロックピンを正しい位置に配置してシリンダーを回転させることができます。しかし、1つのキーの多くのコピーと多くの異なるロック構成しかありません。そして、それらをすべて同時に挿入してクランキングを試みます。目的の値がそのドアの後ろにあり、その鍵で鍵が開きます。CAMを柔軟に使用するために、ヘッダーフィールドから値を直接取得するのではなく、ハッシュを計算します。ハッシュ関数は、次の目的で使用されます。- , . MAC- 48 16- , 2^32 , , , CAM.
- , (, — ). - — ± — . , .
, , , . Hardware Defined Networking , . - , . , , DMAC+EtherType, .
そのハッシュは、比較要素でエンコードされます。それらと比較されるのは、目的の値のハッシュです。CAMの原理により、これはプログラミングのハッシュテーブルに似ており、チップにのみ実装されています。MPLSスイッチングもこの原理に完全に適合しており、そのためMPLSが当時IPに惹かれていました。例:
- 最初のイーサネットフレームがスイッチポートに届きました。
- スイッチはSMACを抽出し、そのハッシュを計算しました。
- 彼は、要素を比較するCAMでこのハッシュを書き留め、RAMでフレームが来た場所からのインターフェイス番号、およびCAMセル自体のRAMのセルアドレスを書き留めました。
- 元のフレームをすべてのポートに送信しました。
- 繰り返し段落。1-5 ....
- MACアドレステーブル全体がいっぱいです。
- Ethernet-. , SMAC ( CAM) , , .
- DMAC , .
- CAM .
- , .
要約:- CAM .
- CAM () (RAM), — .
- CAM , -. CAM , RAM.
- 一致のチェックはすべてのレコードで同時に発生します。これが、CAMが非常に熱くなる理由ですが、一定の時間で結果が生成されます。
- CAM + RAM は、スイッチングチップによってアクセスされるハードテーブルを保存します。
TCAM-三元連想メモリ
IPの何が問題なのかという質問に戻ります。上記のCAMを使用する場合、DIPですべてのビットに1を返すことはほとんどありません。実際、DIPは常に1つの単一のアドレスであり、ルーティングテーブル内のルートはサブネットであり、さらに小さなルートの集合体です。したがって、ルート/ 32がある場合を除き、完全に一致することはほとんどありません。チップ開発者には2つの質問がありました。- 原則としてこれを実装する方法は?
- いくつかの適切なルートから(最長のマスクで)最適なものを選択する方法は?

答えはTCAMで、
「T」は「3進数
」を意味します。「
0と
1に加えて
、別の
X値が入力されます-「重要ではありません」(CAMはBCAMと呼ばれることもあります-0と1の2つの値があるため、バイナリ)。
次に、スイッチングテーブルで目的のレコードを検索した結果は、最長のチェーンが1で最短が「重要ではない」セルの内容になります。
たとえば、パケットはDIP 10.10.10.10でアドレス指定されます。
ルーティングテーブルには、次のルートがあります。
0.0.0.0/0
10.10.10.8/29
10.10.0.0/16
10.8.0.0/13
.ルートのビットは、マスクに1が含まれる場合は要素を比較し、0の場合は「重要ではない」要素を比較するTCAMに書き込まれます。
目的のレコードを検索するとき、TCAMはCAMと同様に、すべてのセルで目的の値を同時に実行します。 結果は、0、1、および「重要ではない」のシーケンスになります。
「重要ではない」が後に続くユニットのシーケンスを返したレコードのみが、選択の次の段階に関与します。
次に、すべての結果から、ユニットのシーケンスが最も長いものが選択されます。これにより、最長プレフィックス一致ルールが実装されます。
明らかに、私たちは鋭い目で、これがルート10.10.10.8/29になることをすぐに見ました。
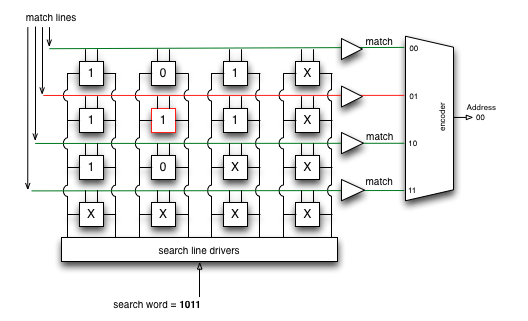 写真のソース 。
写真のソース 。決定は天才の危機にonしているため、私は大きな代償を払わなければなりませんでした。 トランジスタの密度が非常に高いため(各セルには独自のセットがあり、セルの数は数百万個あるはずです)、CPUに劣らず熱くなります-放熱の問題を解決する必要があります。
さらに、その生産は非常に高価であり、以前および現在のネットワーク機器のコストがTCAMの存在と量によって正確に決定されると言うのはcではありません。
熱心な読者がハッシュ関数の問題に注目しました-元の引数をソースとはまったく異なるものに変換するため、0、1、および長さをどのように比較しますか? 回答:ハッシュ関数はここでは使用されません。 上記のアルゴリズムは、実際の手順を大幅に簡略化したものです。この好奇心の強い読者の詳細については、同じ本
Hardware Defined Networkingに送信します。
ただし、メモリ-これはメモリ-のみを格納します。 彼女自身はトラフィックを送信しません-誰かが彼女と対話する必要があります。
著者は、特定のコンポーネントを指定するための一般に受け入れられている用語を見つけることができなかったため、彼は自分の用語装置を使用する自由を取りました。 しかし、彼はいつでも推奨事項に留意し、記事を普遍的な定義に適合させる準備ができています。
パケット伝送を処理するコンポーネントは、スイッチングチップ
FEフォワーディングエンジンと呼ばれます。 ヘッダーを解析し、TCAMで情報を要求し、パケットを出力インターフェイスにリダイレクトするのは彼です。
パッケージの操作は多くの小さなステップに分解されます。各ステップは回線速度で実行する必要があり、合計パス処理時間はネットワーク要件に適している必要があります。
FEは、ネットワークプロセッサ(NP)、FPGA、エレメンタリASICまたはそれらのシーケンスに実装できます。
それでは、基本的なASICから始めましょう。
ASIC-特定用途向け集積回路
名前が示すように、これは特定のタスクの狭い範囲を解決するチップです。 操作アルゴリズムはそれに縫い付けられており、将来変更することはできません。

したがって、ルーチン操作はASIC上で行われ、時間の経過とともに変化することはありません。
ASICは、
ADC 、フレームチェックサム計算、イーサネットからのクロックリカバリ、送受信パケットの統計収集を処理します。
たとえば、おそらく、
DMACフィールドがフレーム内のどこにあるか、その長さ、ブロードキャストキャストフレーム、マルチキャストフレーム、ユニキャストフレームを区別する方法を知っています。 これらの基本定数は変更されないため、それらを使用する関数は、ソフトウェアではなくアルゴリズム化されたハードウェアにすることができます。
ASICの開発とデバッグのプロセスは、最終チップにエラーの余地がないため、非常に時間がかかりますが、完成したら、Kamasに同梱できます。
ASICは、生産が単純で大量であり、エラーの可能性が低く、市場が巨大であるため、安価です。
ジュニパーのドキュメントによると、デバイスの一部では、PFE(パケット転送エンジン)はASICのシーケンスに基づいており、より複雑なマイクロ回路を使用していません。
暗号通貨マイニングファームは、今日のASICを使用する良い例となります。 EvolutionはこのプロセスをCPUからGPUクラスターを介してマイニング専用のASICにもたらし、サイズ、電力消費、および発熱を削減し、プロセスをはるかに安価で信じられないほどスケーラブルにし、競合他社の地図から完全に自家製の暗号ビジネスマンを獲得しました。
プログラマブルASIC
近年、ASICにほとんどの機能を実装する傾向があります。 ただし、行動をプログラムする機会は残したいです。 そのため、いわゆるプログラマブルASICが登場しました。これらは、低コスト、高性能、およびいくつかの真菌を持っています。

FPGA-フィールドプログラマブルゲートアレイ
すべてがASICの力の範囲内にあるわけではありません。 最小限のインテリジェンスとチップの動作に影響を与える能力に関するのは、FPGAのみです。
これは、ファームウェアが決定されるプログラマブルチップであり、機器内での役割を決定します。
ASICと同様に、FPGAはもともといくつかの問題を解決することを目的としていました。
つまり、パケットネットワーク用およびエンジンインジェクターへの燃料供給を制御するためのFPGAです。状況は異なり、ファームウェアで一方を他方に変えることはできません。
そのため、動作を制御してアルゴリズムをアップグレードする機能を備えた専用チップがあります。
FPGAは、パケットルーティング、再マーキング、研磨、ミラーリングに使用できます。
たとえば、外部から
.pcapファイルでCPUに送信されたすべてのBGPおよびLDPパケットをキャッチする必要があることをチップに伝えることができます。
なぜ柔軟性とプログラミングがあるのですか? 多くの例があります:
- 上記の状況では、研磨、ミラーリング、マーキングの新しいルールを設定する必要があります
- 新しい機能を導入する
- ライセンスオプションのアクティベーション
- 既存のアルゴリズムの近代化
- 新しいルールを追加して、ヘッダーフィールドを分析します。たとえば、新しいプロトコルを処理します。
新しいチップを開発したり、トランジスタをはんだ付けしたり、バッチ全体を拒否したりすることなく、上記のすべてを実行できる新しいファームウェアを使用するだけです。
繰り返しますが、誤動作が検出された場合、それを修正できるソフトウェアのパッチを作成し、同時にシステムの残りの部分に影響を与えることなく、この特定のチップのみを更新できます。
FPGAは、主に事前に構築された柔軟性のために、設計と製造が非常に高価です。
FPGAの機能の柔軟性により、ファームウェアを使用してコンポーネントの動作を変更できる場合、FPGAは新しいテクノロジでの実行に使用されることがあります。 そして、ロジックが実行されたら、ASICを実稼働に導入して実装できます。
NP-ネットワークプロセッサ
帯域幅とデバイスで実行されるプロトコルの両方の要件が非常に高いキャリアクラスの機器では、ネットワークプロセッサ-NPという専用のチップがよく使用されます。 ある意味では、特にパケットの処理と送信を目的とした強力なFPGAと考えることができます。

大規模な通信ベンダーは独自のプロセッサー(Cisco、Juniper、Huawei、Nokia)を開発しています。小規模メーカー向けには、Marvell、Mellanoxなどの大手企業からのオファーがあります。
以下に、新しいCisco 400Gb / s全二重NPチップのプレゼンテーションの例を
示します:
tyts 。
これは、Juniper Trioチップセットの説明ですが、NP:
tytsではなく、NISP(Network Instruction Set Processor)として位置付けられています。
Nokia FP4に関するちょっとしたマーケティングと非常に効果的なビデオ:
tytsタスクと機能は、FPGAのものとほぼ同じです。 悪魔は、私たちが登らない細部にあります。
5.スイッチングデバイスのハードウェアアーキテクチャ
通常、結局のところ、安価なスイッチであっても、すべての実装をすべて1つのチップで実行するわけではありません。 それはむしろそれらのさまざまなタイプのカスケードであり、それぞれが一般的な問題の一部を解決します。
次に、この「できる」仕組みの参照モデルを見てみましょう。
このモデルでは、インターフェイスおよび制御モジュールとスイッチングファクトリで構成されるモジュラーシャーシを使用します。
これは、標準のIPであるイーサネットで動作します。
共通バス
共通バス(別名バックプレーン、別名ミッドプレーン)は、すべてのモジュールを相互に接続するデバイスです。
通常、これは、マイクロチップのない銅接点のバッテリーです。

タイトルスポイラーバスに挿入されているボードの背面のように見えます

共有バスHuaweiのように見えます
中央に銅製の接点が詰められたこれら2つのストリップは、工場を切り替えるためのスロットです。
制御モジュール

その上には、CPU、RAM、ソフトウェア、構成とログ、および管理インターフェイスを保存するための読み取り専用メモリがあります。
彼は、管理プレーンとコントロールプレーンを担当しています。
telnet / sshを介してデバイスに接続するときに、それを使用します。
ソフトウェアをRAMにロードし、電源が投入されると他のすべてのモジュールを起動します。
彼は他のモジュールのハートビートを監視します-特別なパッケージの受信は、モジュールが生きていて動作していることを示します。
ハートビートが受信されない場合は、モジュールを再起動できます(プログラムでボードの電源をオフにします)。
プロトコルパケットはCPUに配信され、処理された後、スイッチングテーブルへの更新の書き込み、応答パケットの生成、コンポーネントに関する情報の要求などのアクションを実行します。
制御モジュールは、SPF、LSP、異なるプロトコルを使用した近隣の確立の計算に関与しています。 スイッチングテーブルをRAMソフトテーブルに書き込みます。
これは、さまざまなデバイスの制御ボードの外観ですCisco ASR9000 RSP(ルーティングとスイッチング)。 私たちに近い半分。 バスに最も近いのはスイッチングファクトリです。

Huawei NE40E-X8 MPU

ジュニパーRE100

REジュニパー1800

すべての写真で、CPU、RAM、BIOSバッテリーを簡単に見つけることができます。 HDDを搭載するものもあれば、コンパクトフラッシュを搭載するものもあります。 はい、あなたは正しいです-これは通常のPCです。 さらに、最新の制御ボードは、5〜6歳のコンピューターのレベルで実際にパフォーマンスを発揮します。
インターフェイスモジュールまたはラインカード
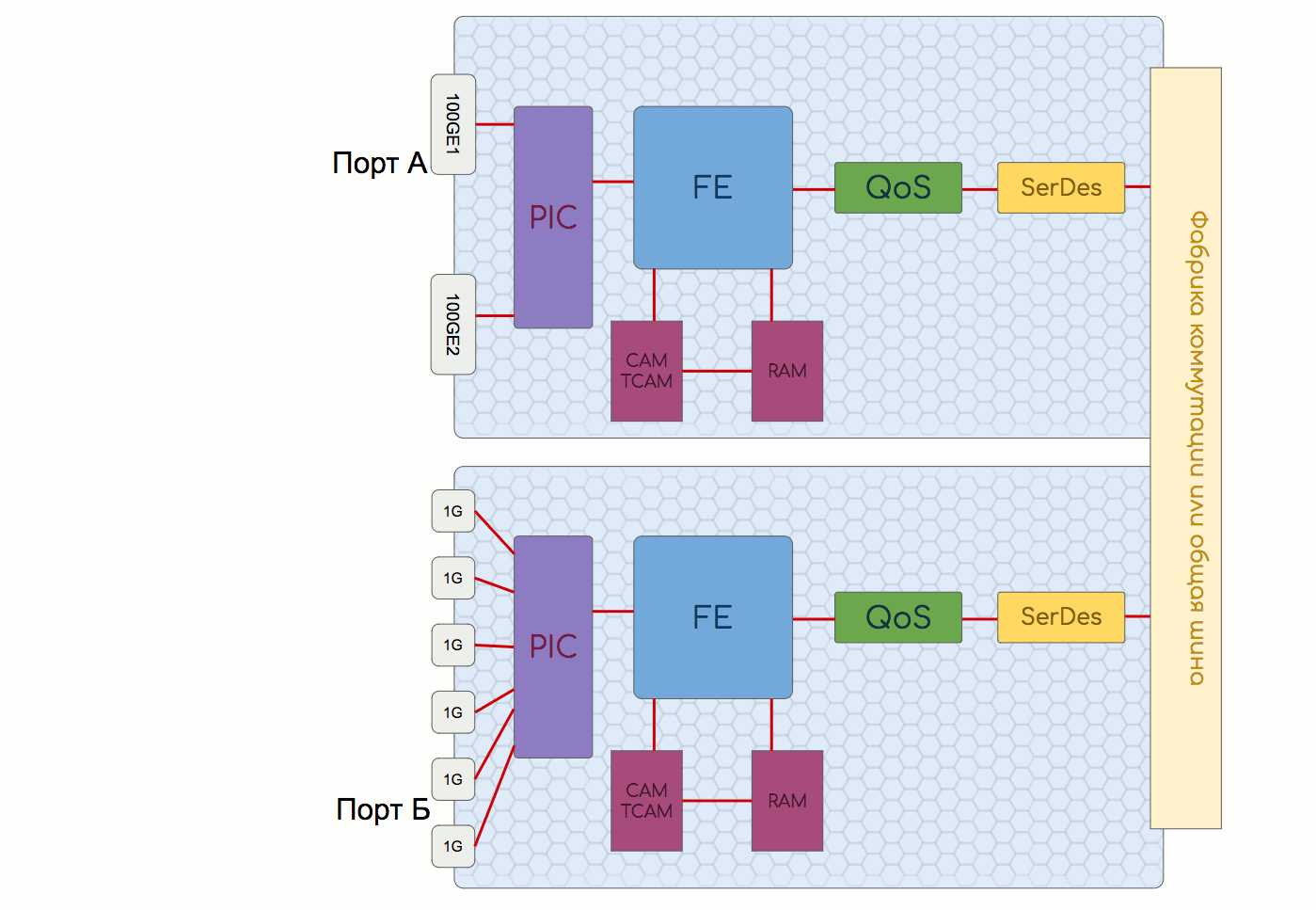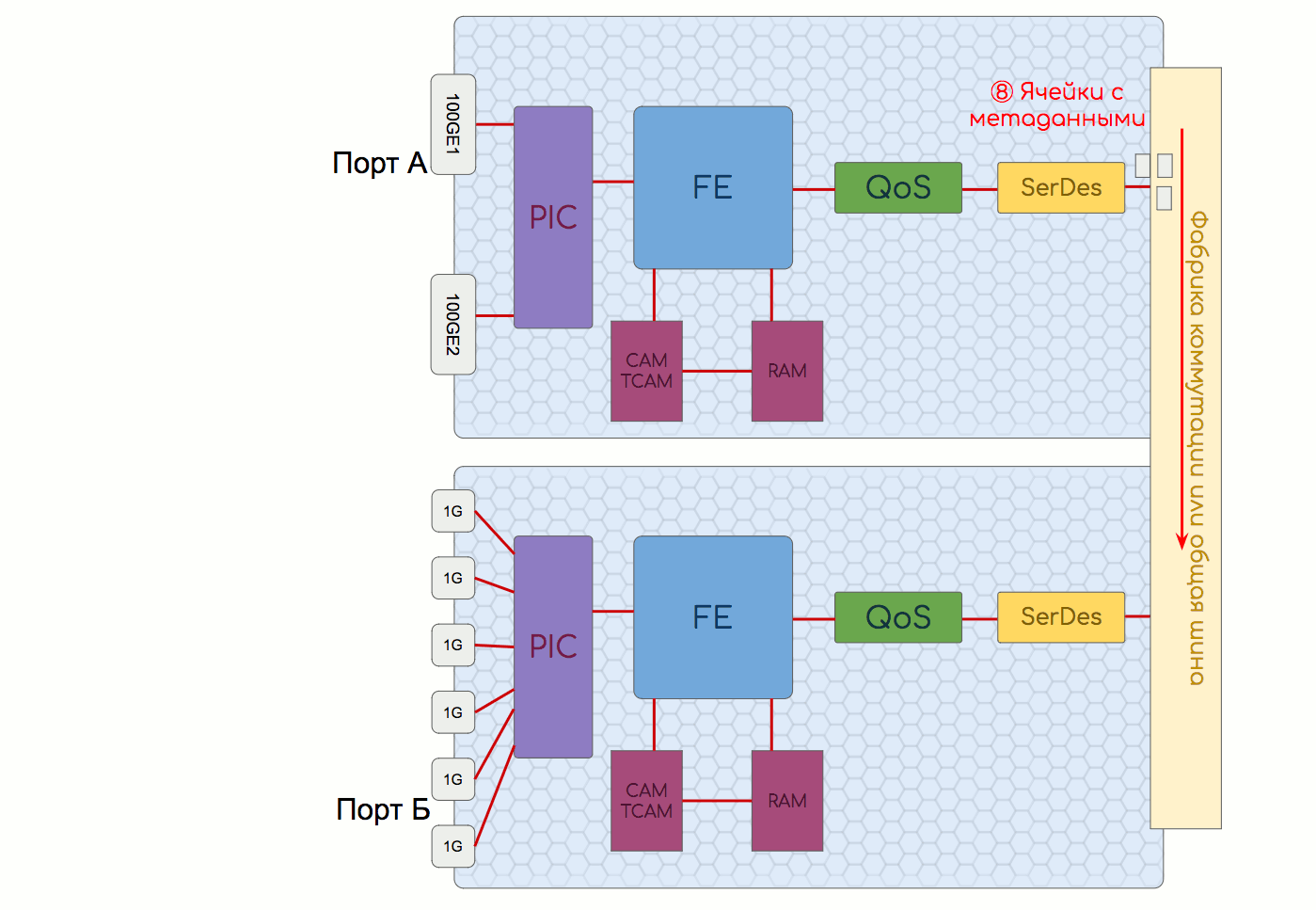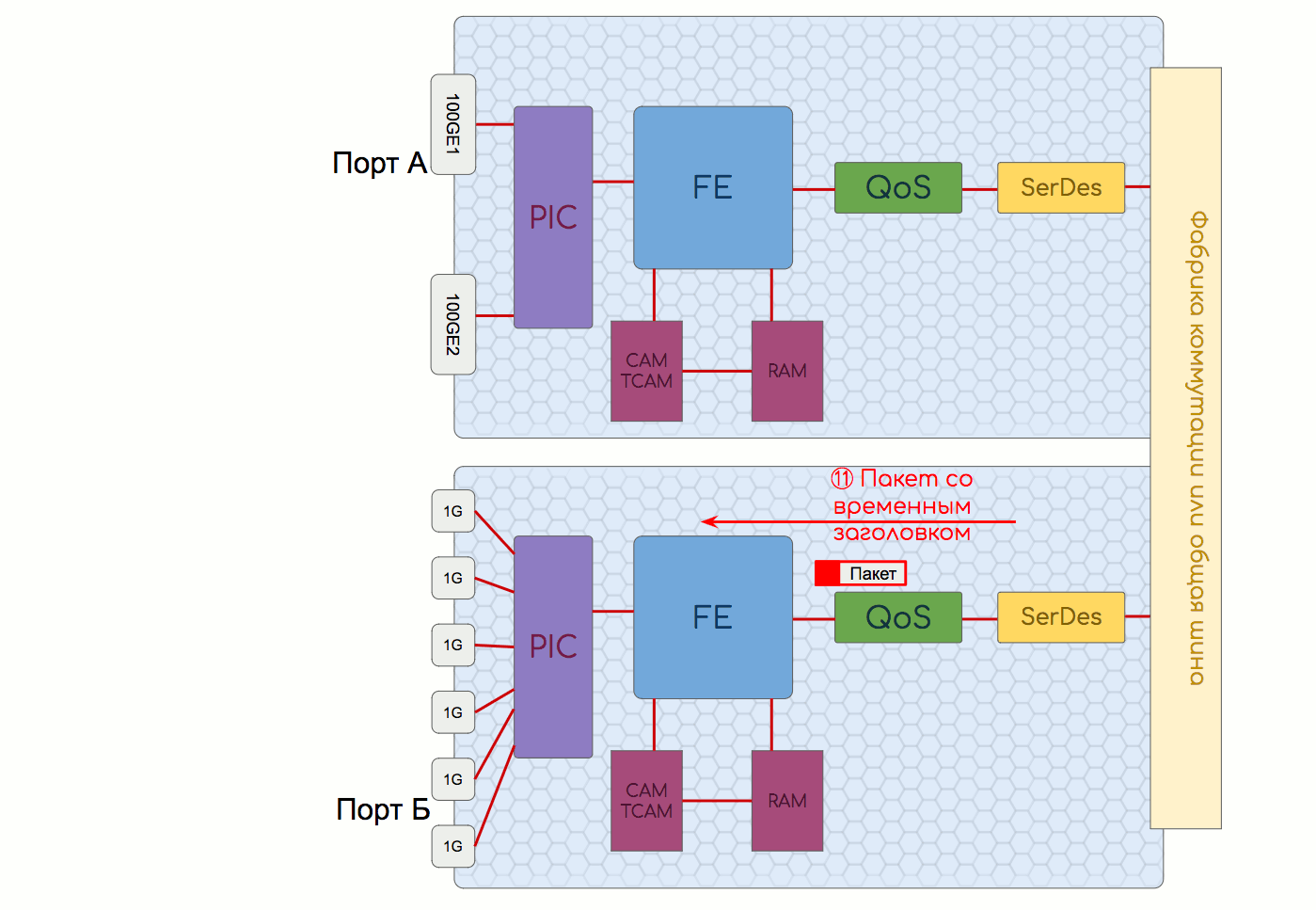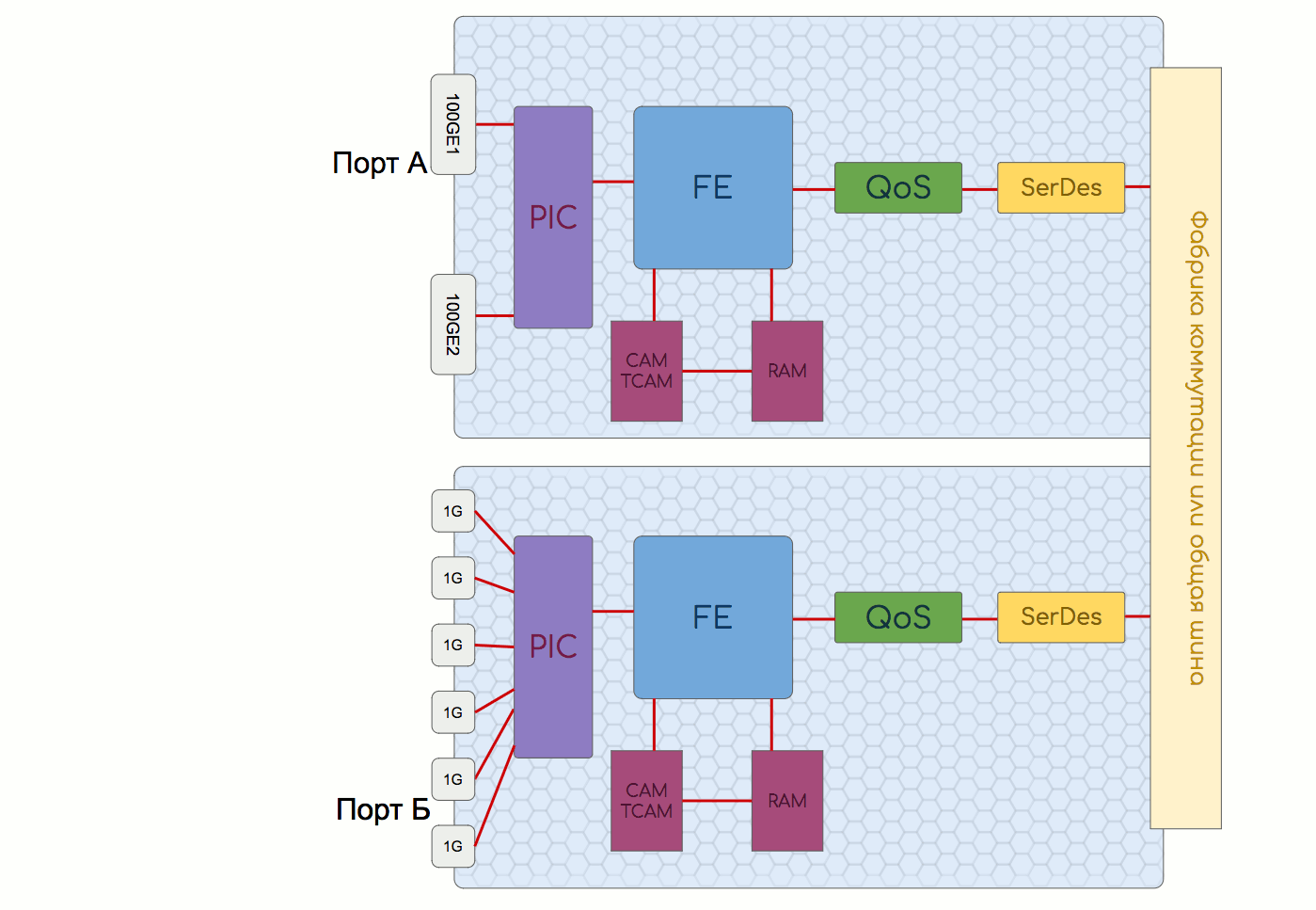
これは、物理インターフェイスとFE(スイッチングチップ)を搭載し、フォワーディングプレーンの機能を実行するモジュールです。
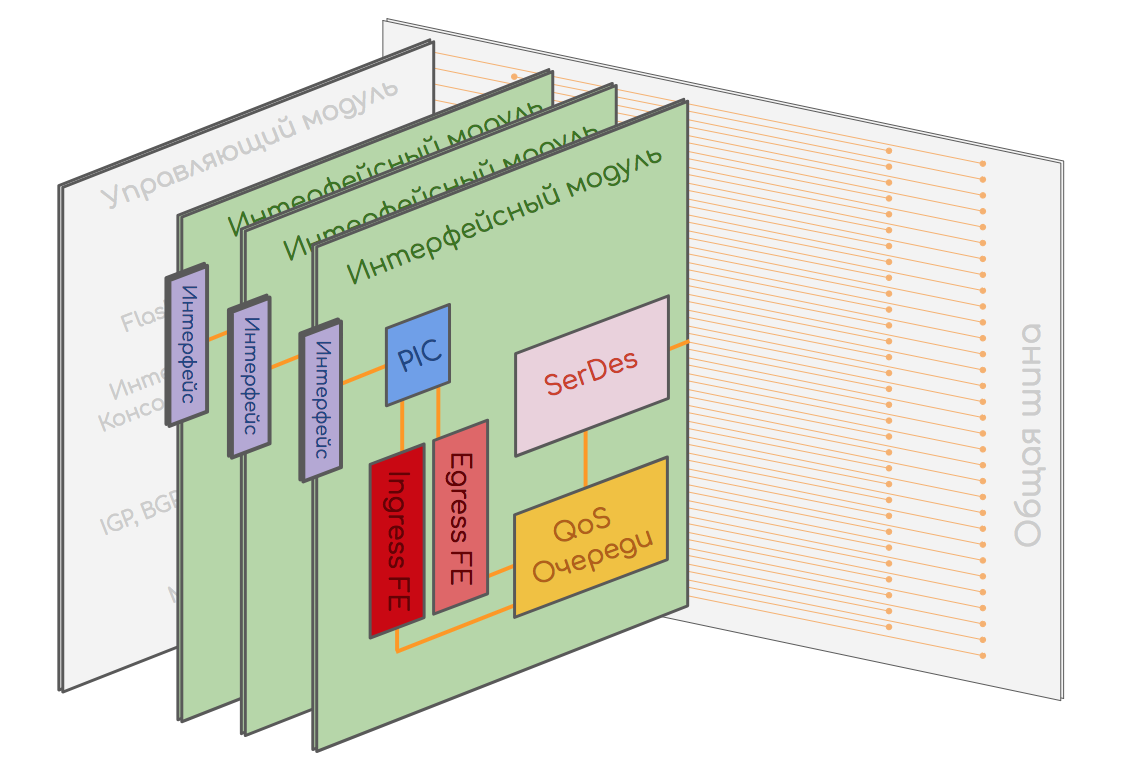
このモジュールは、デバイスのクラスとアーキテクチャに応じて、1つのチップ(System-on-Chip)と多くの個別のチップの両方に実装できる多くのコンポーネントで構成されています。

PIC-物理インターフェイスカード
PICには、基本的なトラフィック操作を実行するインターフェイスとチップがあります。
- 電気インパルスからビットストリームを回復
- ビットのセットからパケットを回復します。
- サービス情報(プリアンブル、 IFGなど)を削除します。
- チェックサムを計算し、
- a)パケット内の値と競合する場合、それをスキップして、 FCSなどの不要なヘッダーを削除します。
- b)勝っていない場合、パケットを破棄し、破棄されたパケットのカウンターをエラーで増やします。
- 統計をカウントします:
- パケット数
- 総トラフィック
- ピーク値
- 港の処分
- ユニキャスト/ブロードキャスト/マルチキャスト番号
- PICは、必要に応じてSynchroEthernet信号を復元することもできます。
ラインカードがモジュール式の場合、インターフェイスカードは取り外しおよび交換が可能です。
PICチップと組み合わせたジュニパーMIC(モジュラーインターフェイスカード)のように見えます 通常、PICチップはASICです。
FE-フォワーディングエンジン
既に上記で説明したように、次のような機能を実装します。
- CAM / TCAMリクエスト
- ソフトテーブルからハードテーブルへの変換
- パケット転送の決定(ACL、ポリシング)
- スイッチング/ルーティング
- 優先マーキング
- ミラーリング
- プロトコルパケットの検出
- CPUからの信号/パケット処理。
さらに
注意してください! これは、記事全体の最も重要なポイントの1つです!
まず、FEは
入力FEと
出力FEに分割されます。 最初は入力パスでパケットを処理し、2番目は出力で処理します。
一方では、この区分は用語です-パッケージはIngress FEに到着し、その後、おそらく別のボードであるEgress FEに送信する必要があります。
一方、分離はしばしば非常に物理的です。これら2つのエンティティは、同じFEチップ、つまりイングレスとエグレスに存在します。 これは論理的です-ボードは入口点または出口点のいずれかになることができるからです。
次に、ノード内のパケットの全体的な運命を決定するのは入力FEです。
- 将来の見出しの種類
- ノード内部および外部転送時の優先度
- FE出力とインターフェース
- LAGまたはECMPの物理メンバーのどちらか
*バッファがオーバーフローしたため、出力パスでパケットを複製または強制終了できるという小さな注意事項があります。3番目に、FEは通過トラフィックのプロトコルパケットを識別し、CPUに送信する必要があります。
したがって、CPUからのパケット(または命令)の受信も彼の仕事です。
FEの隣にはCAM、TCAM、およびRAMがあり、FEは出力インターフェイスとACL検証を求めて連絡します。
ハードテーブルを保存します。
さらに、Ingress FEはBUMトラフィックを複製します-パケットのコピーを各Egress FEに送信します。 Egress FEは、送信するインターフェイスの数と同じ数のコピーをすでに作成しています
QoSまたはTM-トラフィック管理
時にはFE自体に、場合によっては別のチップとして、通常はトラフィック管理と呼ばれるキューと組み合わされたQoSチップが付属します。
出力(出力パス上のキュー)をオーバーフローさせないために、入力キュー(入力パス上のキュー)が必要です。
出力キューは、バックプレッシャーと呼ばれる現象を回避するように設計されています-パケットがFEチップに処理できるよりも早く到着する場合。 このような状況は、イングレスFEでは不可能です。非常に多くのインターフェイスが接続されているため、それらからのトラフィックをダイジェストできます。または、フロー制御を介したイーサネットは、その制御下に置かれます。
しかし、Egress FEでは、トラフィックは多くの異なるボード(Ingress FEを読み取ります)からマージできます。その中でitれているのは、2バイトを送信するようなものです。
キューのタスクは、トラフィックのバーストをスムーズにするだけでなく、避けられなくなったパケットのドロップを管理することでもあります。 つまり、キューから優先度の低いパケットをスローすることは、優先度の高いパケットよりも可能性が高くなります。 さらに、インターフェースレベルで輻輳を監視することが望ましい-10ギガビットインターフェースを介して13 Gb / sのトラフィックを送信する必要がある場合、3つのトラフィックは明確に破棄されますが、400ギガビットFEは輻輳に近くないためです。
スキームは非常に複雑です-2つのキュー、つまりダブルバッファリングを意味し、さらにインターフェースでそれらを詳述する必要があります、別の質問が発生します:1つのインターフェースが過負荷になると、入力キュー全体が起動しますか?
これらの問題は以前は解決されていませんでしたが、今日ではVOQメカニズムである仮想出力キューに対応しています。 VOQは
この投稿で美しく説明さ
れています。
一言で言えば-これは、異なるFE間のすべてのキューの仮想化です。 入力パス上に1つの物理DRAMメモリチップがあり、内部で仮想キューに分割されています。 入力キューの数は、休日の合計数に基づいています。 出力キューは、実際には出力モジュールに配置されなくなりました-同じDRAMにあります-仮想のみです。
したがって(ジュニパーの例を見てみましょう)、それぞれ8つのキューを持つ72の出力インターフェイスがある場合、各インターフェイスモジュールに合計576の入力キューがあります(TMを読み取ります)。 デバイスに6つのモジュールがある場合、3456 VOQをサポートする必要があります。
これにより、輻輳時に1つの出力キューが物理入力全体をブロックするときに、ダブルバッファリングと
行頭ブロッキングの問題の問題がエレガントに除去されます。

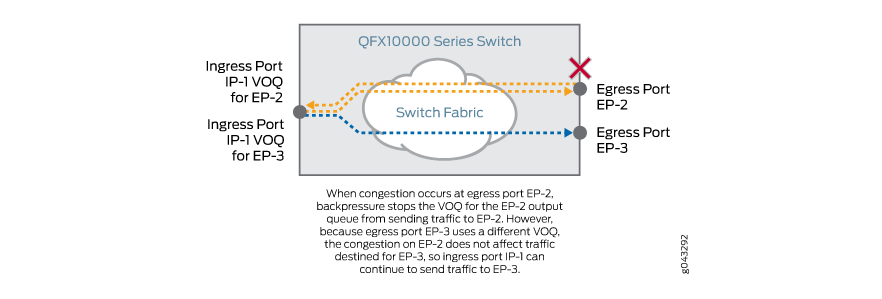
さらに、パケットは必要に応じて入力キューで破棄されるようになり、ファクトリに送信して出力キューを詰まらせる必要がなくなりました。
キューについて他に知っておくべき重要なことは、同じFEの別のインターフェイス宛てのパケットでさえ、入力および出力キューを通過する必要があるということです。
これは、背圧に対する同じ戦いのためです。 キューだけがFEを輻輳から保護し、優先順位に従って不要なトラフィックを廃棄できるため、入力FEと出力FEの間の通過トラフィックの直接ブリッジはありません。
ただし、このような「ローカル」トラフィックは工場に送られるべきではありません。
ただし、次の部分でQoSについて説明します。
SerDes-シリアライザー、デシリアライザー
インターフェイスボード上の別のチップはSerDesです。 複数のスイッチングチップが存在する場合、それぞれの接続性をそれらの間で調整する必要があります。 このために、スイッチングファクトリが使用されます。結局、パケットではなく同じ長さのセルで最適に動作します。 SerDesのタスクは、パケットをファクトリーに送信する前にセルに分割し、それらを収集して戻すことです(シリアライズおよびデシリアライズ)。
分散制御プレーン
分散コントロールプレーンアーキテクチャの場合、インターフェイスボードはCPUとRAMも収容できます。 この場合、コントロールプレーンでの作業のほとんどはローカルCPUで実行でき、コントロールボードにあるものをアンロードします。
ジュニパーのPFEのように見えます転送ASIC(FE)は中央の大きな正方形のラジエーターの下に隠れており、TCAMは左側の小さなラジエーターの下にあります。 ASICの下には、ハードテーブルを保存するための512 MB RAMブロックがあります。
青いワッシャーは、分散コントロールプレーンのCPUです。 フラッシュメモリは左側にあり、RAMは低くなっています(これはソフトテーブルではなく、一時データを保存するためのRAMです)。
同じバッテリーの隣。 つまり、かなりのコンピューターでもあります。

これは、ロジックを実装するラインカードの一部です-ご覧のとおり、ポートはありません。
別に、インターフェイスボードは別のスロットに挿入されます。


スイッチング工場
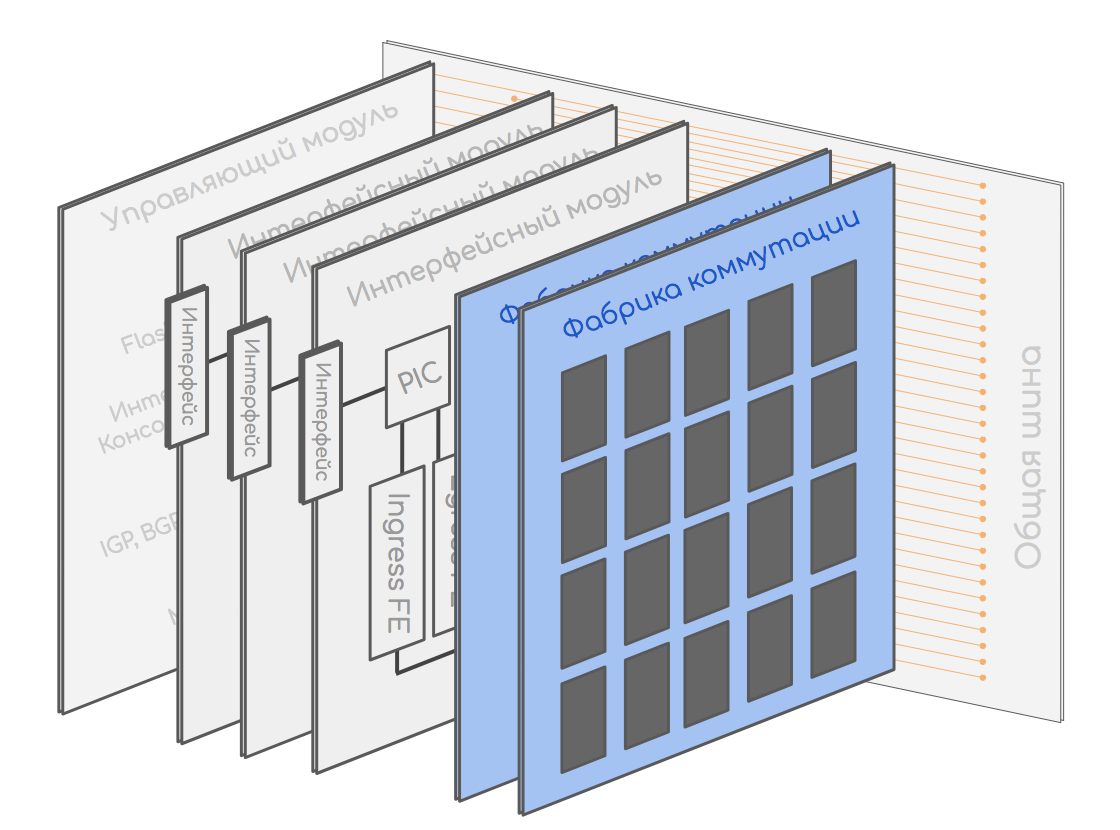
キャリアグレードのハイエンドルーターを使用する場合、通常は最大20個のインターフェイスカードを使用でき、各インターフェイスカードには少なくとも1つのFEスイッチングチップがあります。 各スイッチングチップは、その脚の一部をインターフェイスに向け、一部は背面バスに向けています。 また、銅媒体にはスループットに関する独自の制限があるため、そこには多くの脚があります。1つまたは2つの出口では十分ではありません。
2つのスイッチングチップを相互に接続する方法は? まあ、ちょうど同じ:
 3つのチップを互いに接続する方法は?まあ、おそらくそのようなものですか?
3つのチップを互いに接続する方法は?まあ、おそらくそのようなものですか? 8を編む方法は?
8を編む方法は?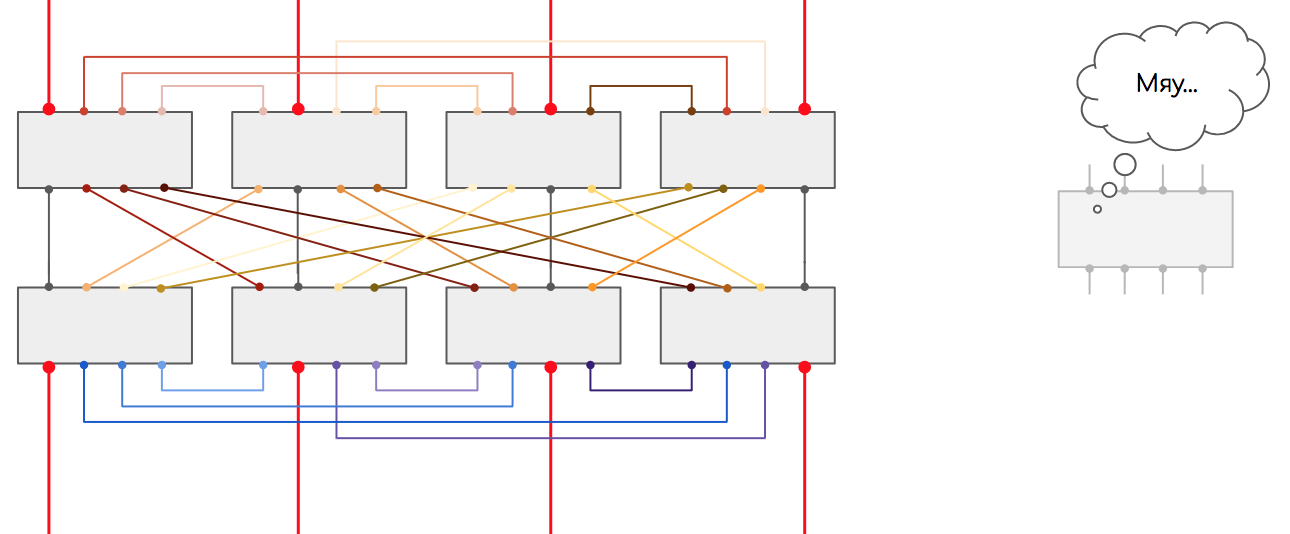 よろしいですか?気になりませんか?8チップのシステムのスループットは、ペアのスループットと同じままです。結局、通信のレッグ数を減らすたびにスループットは変わりません。2番目のポイントは、たとえば16個のチップがあり、それぞれに32個のコンタクトがある場合、完全に接続されたトポロジをどのように作成しますか?各32コアのケーブルの16 * 15/2バンドル?この問題は、ノンブロッキングClosネットワークまたはオーバーサブスクリプションのないネットワークに対処されました。入力スイッチング要素(入力FE)、出力(出力FE)、および中継があります。トランジットのタスクは、入力を週末に接続することです。入力は、トランジットを介して出力に接続されます。
よろしいですか?気になりませんか?8チップのシステムのスループットは、ペアのスループットと同じままです。結局、通信のレッグ数を減らすたびにスループットは変わりません。2番目のポイントは、たとえば16個のチップがあり、それぞれに32個のコンタクトがある場合、完全に接続されたトポロジをどのように作成しますか?各32コアのケーブルの16 * 15/2バンドル?この問題は、ノンブロッキングClosネットワークまたはオーバーサブスクリプションのないネットワークに対処されました。入力スイッチング要素(入力FE)、出力(出力FE)、および中継があります。トランジットのタスクは、入力を週末に接続することです。入力は、トランジットを介して出力に接続されます。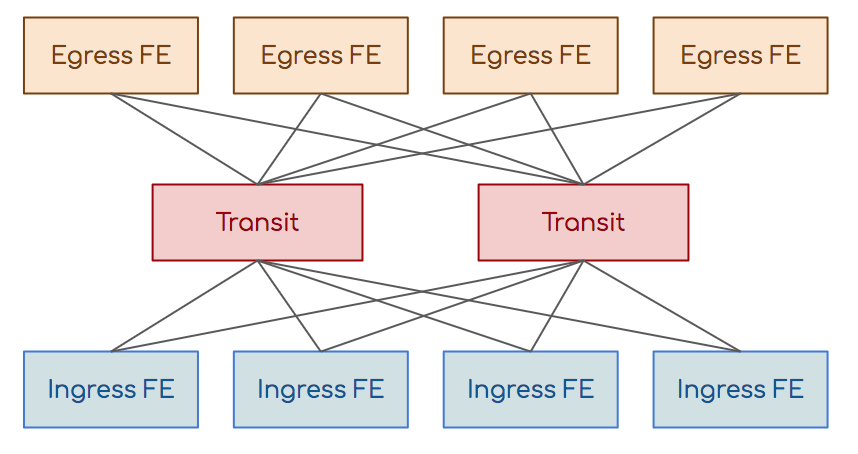 入力と出力は互いに直接関連しておらず、中継も接続されていません。より多くの入力および出力スイッチング要素が必要です-トランジット要素を追加します。もっと必要ですか?新しいカスケードのカスケードを追加します。
入力と出力は互いに直接関連しておらず、中継も接続されていません。より多くの入力および出力スイッチング要素が必要です-トランジット要素を追加します。もっと必要ですか?新しいカスケードのカスケードを追加します。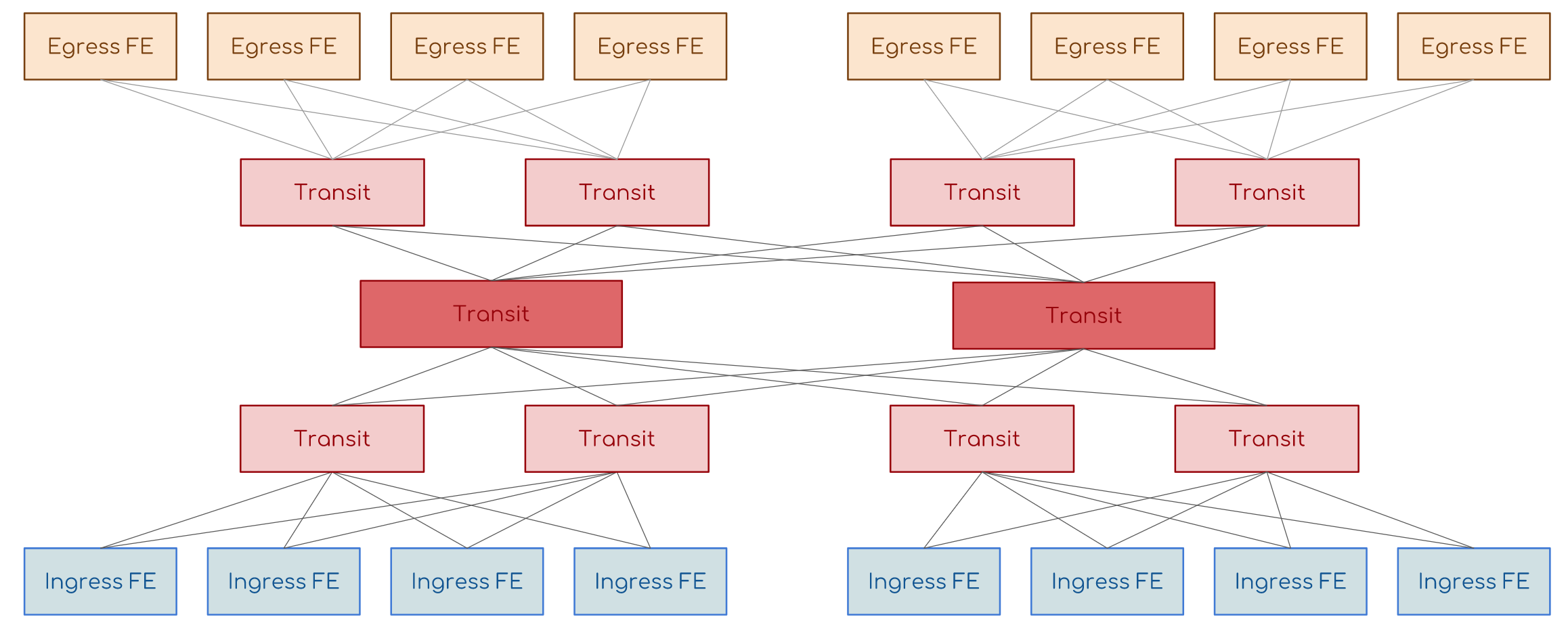 これは、最新のルーターのパッチカードが詰め込まれている場所です。非常に愚かなASICで、入力から出力へのパケットの転送方法のみを知っています。スイッチングボードは背面バスに接続し、他のすべてのボードと接続します。通常、それらはN + 1モードで動作します。つまり、全員が負荷を共有しますが、1つのボードが故障した場合、残りのボードがすべてを処理します。ところで、ボード自体は、Kloseファクトリー階層の上位カスケードと呼ばれます。残っているのは細胞の問題だけです。さて、これらのASICパッケージをすぐに転送しますが、なぜ他のパッケージをカットしますかここで、ECMPから類推できます。異なるパス間でパッケージ単位のバランスを設定したことがある人は、それがどれほどの痛みを引き起こしたか覚えているでしょう。 TCPが中途半端に処理する無秩序なパケット配信は、たとえばIPテレフォニーやビデオを根本的に破壊する可能性があります。パッケージごとのバランシングの問題は、同じスレッドの2つのパケットが簡単に別々の方向に進むことができることです。同時に、それらの1つは小さく、非常に迅速に受信者に到達し、もう1つの過成長アクセラレータは狭いバッファに留まります。だから彼らは乱れた。
これは、最新のルーターのパッチカードが詰め込まれている場所です。非常に愚かなASICで、入力から出力へのパケットの転送方法のみを知っています。スイッチングボードは背面バスに接続し、他のすべてのボードと接続します。通常、それらはN + 1モードで動作します。つまり、全員が負荷を共有しますが、1つのボードが故障した場合、残りのボードがすべてを処理します。ところで、ボード自体は、Kloseファクトリー階層の上位カスケードと呼ばれます。残っているのは細胞の問題だけです。さて、これらのASICパッケージをすぐに転送しますが、なぜ他のパッケージをカットしますかここで、ECMPから類推できます。異なるパス間でパッケージ単位のバランスを設定したことがある人は、それがどれほどの痛みを引き起こしたか覚えているでしょう。 TCPが中途半端に処理する無秩序なパケット配信は、たとえばIPテレフォニーやビデオを根本的に破壊する可能性があります。パッケージごとのバランシングの問題は、同じスレッドの2つのパケットが簡単に別々の方向に進むことができることです。同時に、それらの1つは小さく、非常に迅速に受信者に到達し、もう1つの過成長アクセラレータは狭いバッファに留まります。だから彼らは乱れた。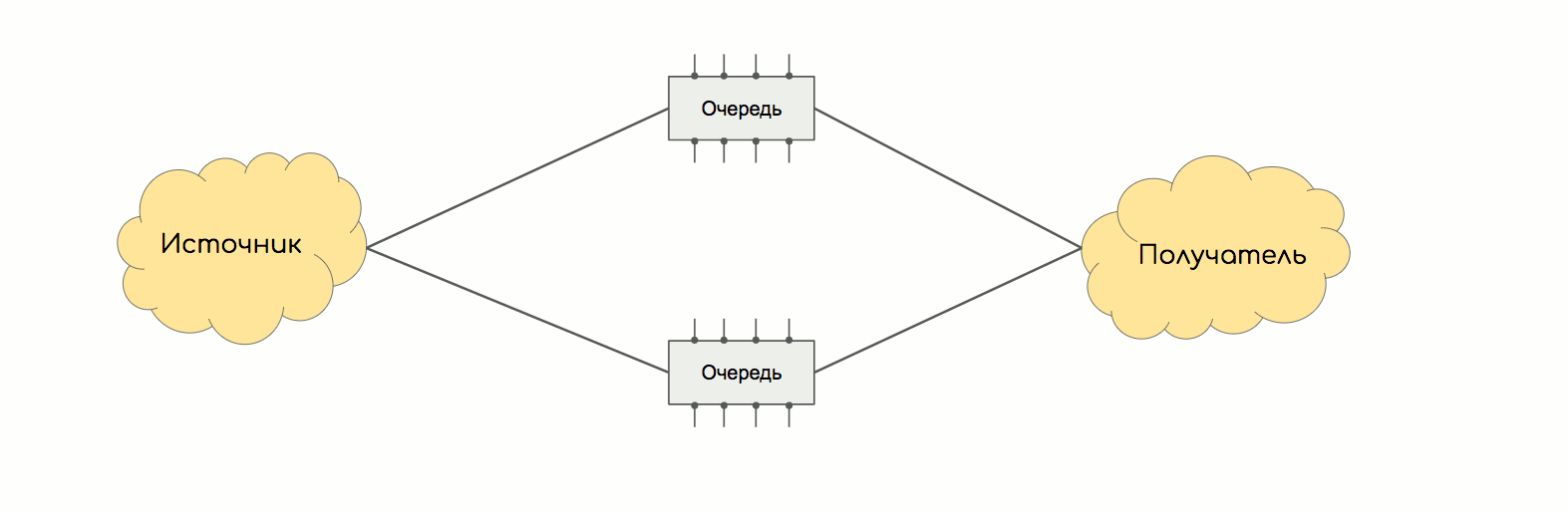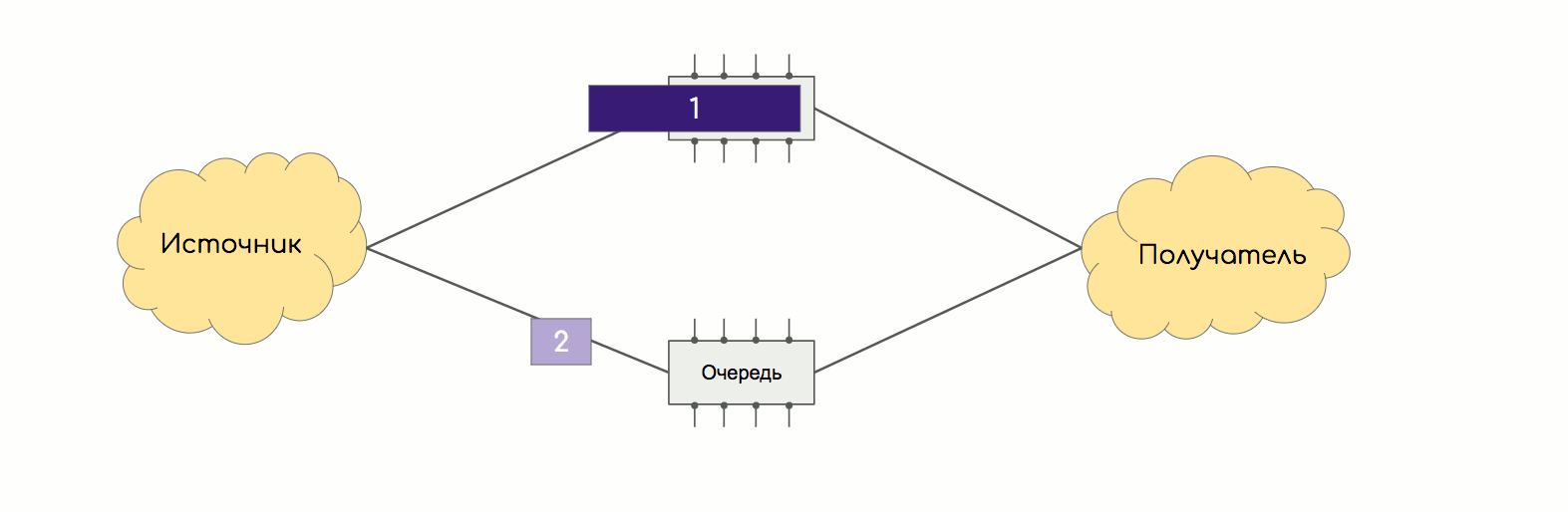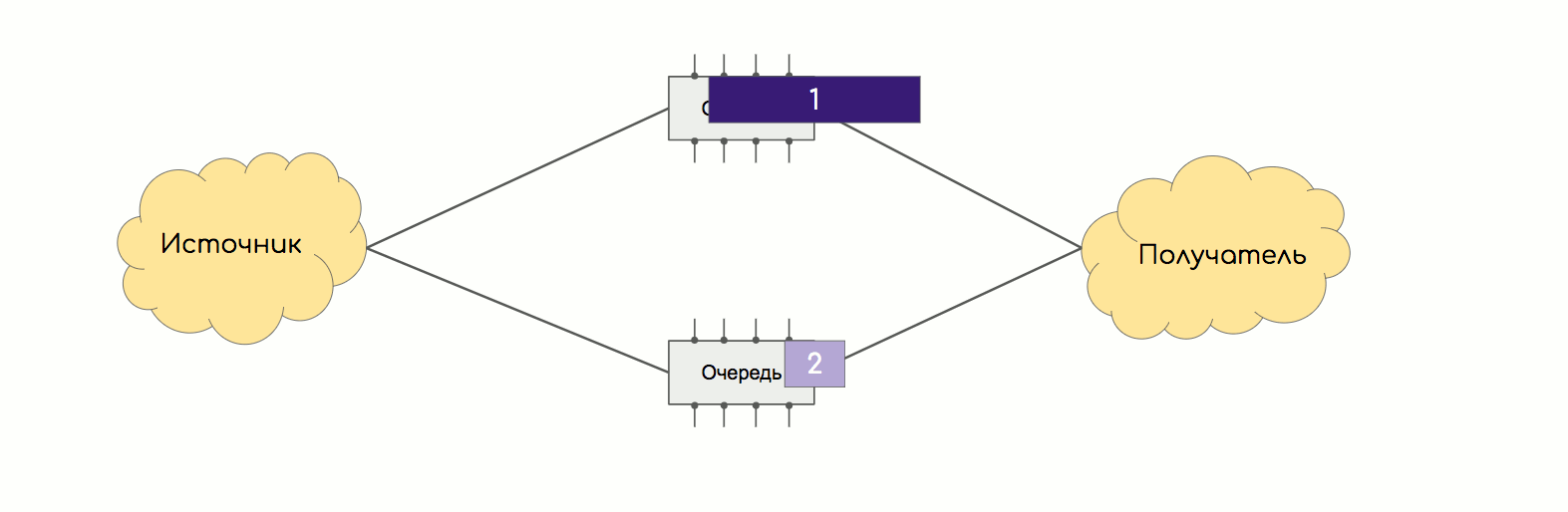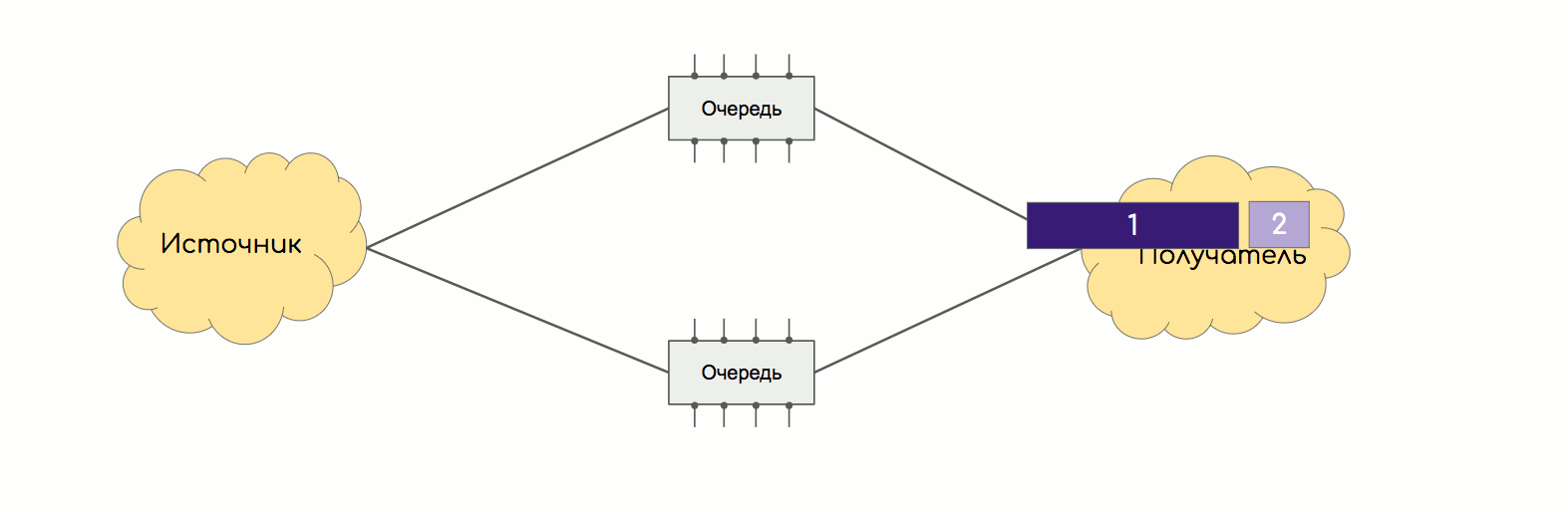 工場でも同じことが起こります。これに対処する良い方法はスレッドバランシングです-ハッシュは値のタプル(SMAC、DMAC、SIP、DIP、プロトコル、SPort、DPort、MPLSラベルなど)によって計算され、同じストリームのすべてのパケットが一方向に送信され始めます。しかし、それは不完全に機能します。多くの場合、1つの非常に油っぽいスレッドが1つのリンクをロードでき、他のスレッドはアイドル状態です。そして、この青いボックス内ではなく、オペレータのネットワーク上でこれに耐えることができます。エレガントなソリューションは次のとおりです。パッケージは同じ小さなサイズのセルにカットされます。セルは線でバランスが取れています。つまり、1つのセルがここにあり、もう1つのセルがそこにあり、3番目のセルが次のリンクにあるなどです。各セルには番号が付けられているため、目的のFEに到達すると、簡単に組み立てて完全なパッケージに戻すことができます。入口から出口までの距離はほぼ同じであるため、セルのサイズは同じで、配送時間もほぼ同じです。電話交換で最初に実装されたチャールズクローゼのアイデアは、イーサネットスイッチとルーターに借用され、現在ではデータセンターネットワークに置き換わり、従来の3レベルモデルに取って代わりました。
工場でも同じことが起こります。これに対処する良い方法はスレッドバランシングです-ハッシュは値のタプル(SMAC、DMAC、SIP、DIP、プロトコル、SPort、DPort、MPLSラベルなど)によって計算され、同じストリームのすべてのパケットが一方向に送信され始めます。しかし、それは不完全に機能します。多くの場合、1つの非常に油っぽいスレッドが1つのリンクをロードでき、他のスレッドはアイドル状態です。そして、この青いボックス内ではなく、オペレータのネットワーク上でこれに耐えることができます。エレガントなソリューションは次のとおりです。パッケージは同じ小さなサイズのセルにカットされます。セルは線でバランスが取れています。つまり、1つのセルがここにあり、もう1つのセルがそこにあり、3番目のセルが次のリンクにあるなどです。各セルには番号が付けられているため、目的のFEに到達すると、簡単に組み立てて完全なパッケージに戻すことができます。入口から出口までの距離はほぼ同じであるため、セルのサイズは同じで、配送時間もほぼ同じです。電話交換で最初に実装されたチャールズクローゼのアイデアは、イーサネットスイッチとルーターに借用され、現在ではデータセンターネットワークに置き換わり、従来の3レベルモデルに取って代わりました。これは、切り替え工場の外観ですHuawei NE40E-X16:

.
Juniper:

Huawei NE40E-X8:

6.生涯の旅
パッケージはデバイス内に正確に存在します。ケーブルでは、電磁パルスです。入力インターフェイスで生成され、PICがビットストリームからそれを復元し、出力で停止し、それらに戻ります。したがって、ライフタイムと同じデバイス内でパッケージを見つけることを検討できます。通過パケットとプロトコルパケットの2つの場合を考えます。
トランジットパッケージ
標準のイーサネット/ IPパケットを扱っているとします。ホストはIPルーターです。パケットは、L3ポートAからL3ポートBへの送信中に続きます。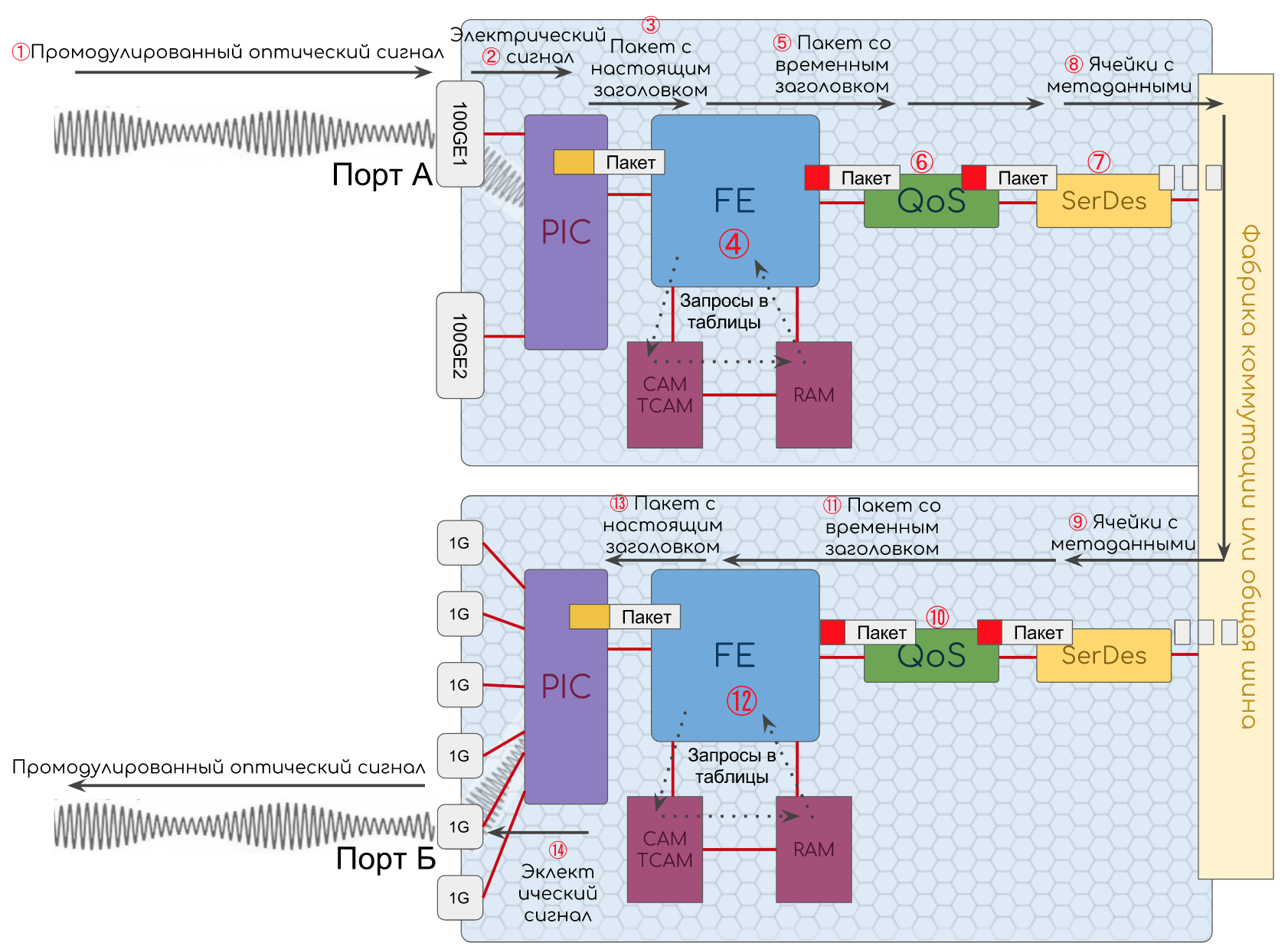
- 光信号がポートに到着します。ここで電気インパルスに変換されます。
- PIC, .
Ethernet Ethernet-. , .
Ethernet . FCS.
, FCS .
— , 1.
PIC : , , Unicast, Broadcast, Multicast. - Ethernet FE.
- FE DMAC , CAM , .
CAM RAM.
Ethernet , DMAC — MAC- . RAM , — Payload IP ( EtherType ).
FE IP (Payload). , .
?
- (IP , MAC, MPLS- .)
- (DSCP, IEEE802.1p, EXP .)
- TTL.
- , , (, , ).
, , .
- TTL 1 , 0. — CPU ICMP TTL Expired in Transit .
- ACL — .
- DIP .
Ingress FE TCAM , IP-. RAM.
FE RAM Egress FE, NextHop.
Ingress FE MAC- Next-Hop' (Adjacenies Tables).
FE (BUM- , L2VPN), LAG ECMP .
( Ethernet), - (BFD, ) CPU (BGP, OSFP .)
- CoS-, . .
, Egress FE:
- Egress FE
- 優先順位
- TTL
- Next Hop (MAC-)
Egress FE , ; — , ; — , , , (DSCP); TTL — , ; Next Hop MAC , DMAC Ethernet-. - . Egress FE.
- , .
- , SerDes .
- .
, .
(2-4), . , .
— , . - SerDes , .
- .
FE (Back Pressure). . CoS, . , .
, .
QoS: , , , .
VOQ (Virtual Output Queue), , : 10 / 13.
PIC. - Egress FE.
- Egress FE :
, TTL, Ethernet, SMAC , DMAC (, MAC Ingress FE, ).
, ( , ). - PIC, , FCS, IFG, .
- , , , .
ほとんどのローカルパケットはCPUで処理されます。ローカルのものは、このノードで作成されたもの、ユニキャスト)、すべて/多くのもの(ブロードキャストまたはマルチキャスト)、またはCPUでの処理を意図的に必要とするもの(TTL期限切れ、ルーターアラート)であることを思い出してください。FEまでの受信トレイはすべて、乗り継ぎの場合と同じです。さらに、スイッチングチップは、CAMを使用して、DMACがローカルデバイスのMACアドレスであることを認識し、EtherTypeを調べます。 BPDUまたはISIS PDUである場合、パケットはすぐに目的のプロトコルに送信されます。IPの場合-TCAMで見ると、そのDIPを見るIPモジュールにそれを渡しますまたローカル-IPv4(またはNext Header IPv6)ヘッダーのProtocolフィールドを調べる必要があることを意味します。プロトコルが決定され、パケットを次に転送するモジュール(BFD、OSPF、TCP、UDPなど)について決定されます。したがって、宛先アプリケーションが見つかるまで、パッケージは最後までデプロイされます。Ingress FEがこれを処理すると、パケットの内容が特別な通信チャネルを介してCPUに送信されます。このステップでは、かなりインテリジェントなデバイスがポリシーを適用して、CPUに送信されるプロトコルパケットの速度を制限します。これにより、telnetパケットだけでプロセッサが過負荷になることはありません。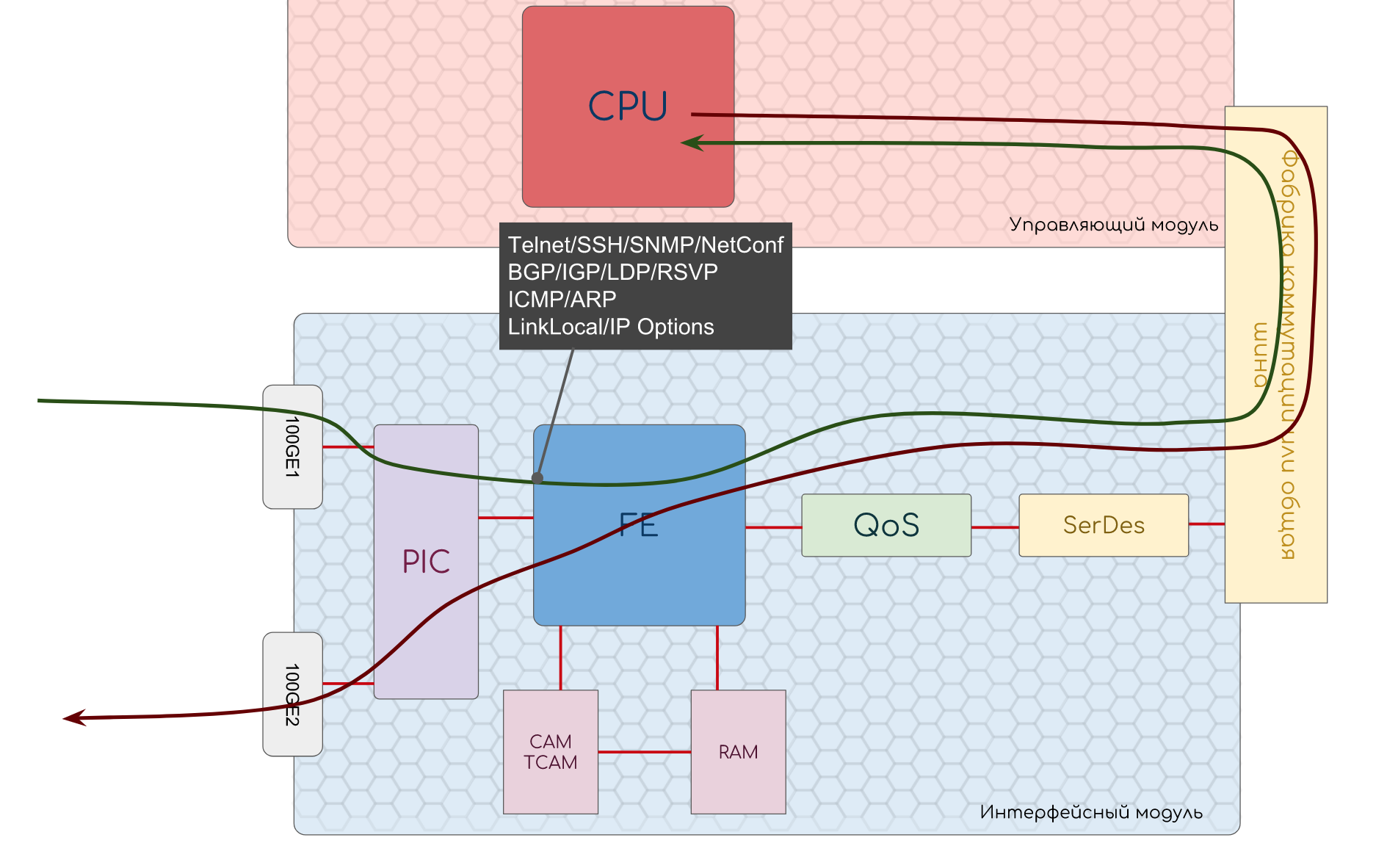 このパッケージがトポロジの変更に関する情報(新しいOSPF、LSAなど)をもたらした場合、コントロールプレーンはソフトテーブル(RAM)を更新する必要があり、変更はハードテーブル(CAM / TCAM + RAM)に送信されます。パケットが応答を必要とする場合、デバイスはそれを形成し、元のソースに送信する必要があります(たとえば、来たBGPアップデートへのTCP Ack)またはそれをどこかに転送します(たとえば、OSPF LSAまたはRSVP Resv)。発信プロトコルパケットはCPU上で形成されます。ソフトテーブルに基づいて、すべてのヘッダーのすべてのフィールドが埋められ、実装に応じて、入力または出力FEにドロップされます。
このパッケージがトポロジの変更に関する情報(新しいOSPF、LSAなど)をもたらした場合、コントロールプレーンはソフトテーブル(RAM)を更新する必要があり、変更はハードテーブル(CAM / TCAM + RAM)に送信されます。パケットが応答を必要とする場合、デバイスはそれを形成し、元のソースに送信する必要があります(たとえば、来たBGPアップデートへのTCP Ack)またはそれをどこかに転送します(たとえば、OSPF LSAまたはRSVP Resv)。発信プロトコルパケットはCPU上で形成されます。ソフトテーブルに基づいて、すべてのヘッダーのすべてのフィールドが埋められ、実装に応じて、入力または出力FEにドロップされます。- , , . , FE, , FE Lookup .
, , ACL, , . , .
, CPU , , .
まだハードウェアで処理されているコントロールプレーンプロトコルがいくつかあります。顕著な例はBFDです。そのタイマーは最大1ミリ秒でスピンアウトします。私たちが思い出すように、CPUは柔軟性がありますが、不器用ではなく、BFDパケットがパス全体を通過してBFDヘッダーに展開するまで、プロセッサが中断されるまで、それに切り替わるまで、パケットを読み取り、新しいパケットを生成し、送信し、数十パスしますそして数百ミリ秒-見て、BFDはすでに崩壊しています。したがって、ほとんどの場合、BFDパケットはチップ上で分解され、答えがその上で準備されます。そして、セッション自体のみがCPUを介して設定されます。この問題の大きなものはさらに進んで、ほとんどの日常的な操作を鉄に移しました。, , Juniper
PPM — Periodic Packet Management , Control Plane :
- Bidirectional Forwarding Detection (BFD)
- Connectivity Fault Management (CFM)
- Link Aggregation Control Protocol (LACP)
- Link Fault Management (LFM)
- Multiprotocol Label Switching (MPLS)
- Real-time Performance Monitoring (RPM)
- Spanning Tree Protocol (STP)
- Synchronous Ethernet (SYNCE)
- Virtual Router Redundancy Protocol (VRRP)
. RTT . , , . . ICMP CPU. . RTT , CPU .
ICMP- ICMP- (NP, ASIC, FPGA), CPU. ping .
, ( OAM ), , CFM .
おわりに
おそらく上記の非常識な量からすでに理解しているように、ベンダーに依存しないユニバーサル言語でハードウェアスイッチングを記述することは不可能です。さらに悪いことに、たとえ1つのベンダーを選んだとしても、その異なる機器ラインや異なるボードでさえ、まったく異なるアーキテクチャを使用しています。したがって、たとえば、シスコにはソフトウェアルーティングを備えたプラットフォームがあり、ハードウェアもあります。または、Huaweiでは、インターフェイスキューをTMチップまたはPICに実装できます。または、シスコがネットワークプロセッサを使用している場合、ジュニパーはASICを管理します。箱入りデバイスの場合、スイッチングファクトリを削除して出力チップを検索する必要があります。SOHOセグメントのルーターでは、確かに、CAM / TCAMはありません。千の異なる方法で行うことができる行の周りの振り付けは、本の中で別の600ページに値します。「次の行は速く動いています。失われたRFCの物語。」仮想化の現代世界について言えることは、彼らが古い支配者を転覆させ、新しい支配者を王位に引き上げるということです。ほぼすべての段落で、経験豊富で迷惑な読者は、より詳細な説明を行う場所を明確にする必要があることに気付くでしょう。そして、彼は正しく...そして同時に間違っています。タイトルに「小さい」と「季節の」のどちらを入れるかについて長い間疑問を抱いていました。そして、これはプロトコルや電気工学の深い知識を必要としないハードウェアスイッチングの無限の世界への紹介にすぎないため、「小さなもの」を置きます。また、さまざまなベンダーの実装の複雑さに没頭し始めた場合、渦巻く渦巻く部品から抜け出すことはできません。この記事が、生涯にわたる個人的な旅の出発点となることを願っています。
謝辞アレクサンダー・クリッパー、アンドレイ・グラズコフ、アレクセイ・クロトフ、linkmeupチームによる校正資料とコメント。機器の写真を提供してくれたMarat Babayan。イラストはArtyom Chernobay。私の2人の雇用主は、忍耐力を示した、または彼らの無知のために、この記事を終えることができました。SDSMのすべての問題:13.最もベテランのネットワーク。パート13。 MPLSトラフィックエンジニアリング12.最もホットなネットワーク。パート12。 MPLS L2VPN11.1。 最小のネットワーク。 №6. MPLS L3VPN11. . . MPLS L3VPN10. . . MPLS9. . .8.1 . №3. IBGP8. . パートエイト。 BGPおよびIP SLA7. . . VPN6. . .5. : . NAT ACL4. : . STP3. : .2. . パート2 1. . パート1 cisco0. . . 計画中