すべての良いと容赦なく来る!
この非常に波乱に満ちた年は終わりに近づいており、今年立ち上げた最後のコース「
フルスタックPython開発者 」があり
ます。一般的に。
行こう
今週、メインのCPythonプロジェクトで最初の
プルリクエストを行いました。 拒否されました:-(しかし、私の時間を完全に無駄にしないために、CPythonがどのように機能するかについての結論を共有し、Python構文を変更することがいかに簡単かを示します。
Python構文に新しい
機能を追加する方法を紹介します。 この機能はインクリメント/デクリメント演算子であり、ほとんどの言語の標準演算子です。 確認するには、REPLを開いて次を試してください。
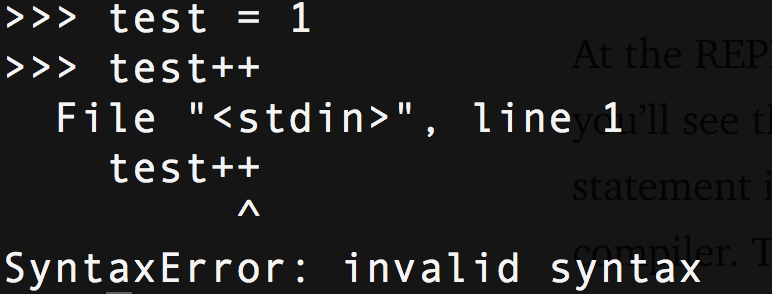
レベル1:PEP
Python構文の変更の前に、変更の理由、設計、および動作を説明するアプリケーションがあります。 すべての言語の変更は、コアPythonチームによって議論され、BDFLによって承認されています。 インクリメント演算子は承認されていない(おそらく承認されない)ため、練習する良い機会になります。
レベル2:文法
Grammarファイルは、Python言語のすべての要素を説明する単純なテキストファイルです。 CPythonだけでなく、PyPyなどの他の実装でも使用され、一貫性を維持し、言語セマンティクスのタイプを調和させます。
これらのキーの内部でトークンが形成され、レクサーによって解析されます。
make -jを入力
make -jと、コマンドはそれらをCヘッダーの列挙と定数のセットに変換します。 これにより、将来それらを参照できます。
stmt: simple_stmt | compound_stmt simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
そのため、
simple_stmtは単純な式であり、たとえば
import pdb; pdb.set_trace()を入力したときに、セミコロンを含む場合と含まない場合があります
import pdb; pdb.set_trace() import pdb; pdb.set_trace() 、および改行NEWLINEで終了します。
Pass_stmt単語のスキップ、
break_stmt作業の中断。 シンプルでしょ?
インクリメントとデクリメントの式を追加しましょう:言語に存在しないもの。 これは、yieldステートメント、拡張および標準割り当て、つまり、式の構造の別のバージョンになります。 foo = 1。
可能な小さな式のリストに追加します(これはASTで明らかになります)。
Incr_stmtがインクリメントメソッドになり、
decr_stmtがデクリメントになります。 どちらもNAME(変数名)に従い、小さなスタンドアロン式を形成します。 Pythonプロジェクトをまとめると、コンポーネントが生成されます(今ではありません)。
-dオプションを指定してPythonを実行し、これを試してみると、次のようになります。
Token <ERRORTOKEN>/'++' … Illegal token
トークンとは何ですか? 調べてみましょう...
レベル3:レクサー
returnを呼び出すときにPythonが行うステップは、字句解析、解析、コンパイル、解釈の4つです。 字句解析は、トークンに入力したばかりのコード行を分割します。 CPython lexerは
tokenizer.cと呼ば
tokenizer.cます。 ファイル(たとえば、
python file.py )から
文字列 (たとえば、REPL)を読み取る関数があります。 また、ファイルの先頭でエンコードに関する特別なコメントを処理し、ファイルをUTF-8などとして分析します。ネスト、非同期、およびyieldキーワードを処理し、割り当てのセットとタプルを検出しますが、文法的にのみです。 彼は、これらのものが何であるか、またはそれらをどうするかを知りません。 彼はテキストだけを気にします。
たとえば、8進数の値に
o表記を使用できるようにするコードは
tokenizerにあります。 実際に8進数値を作成するコードはコンパイラーにあります。
Parser / tokenizer.cに2つのことを追加しましょう。新しい
INCREMENTトークンと
DECREMENTトークンは、コードの各部分に対してトーク
INCREMENTによって返されるキーです。
/* */ const char *_PyParser_TokenNames[] = { "ENDMARKER", "NAME", "NUMBER", ... "INCREMENT", "DECREMENT", ...
次に、++または-が表示されるたびに、
INCREMENTまたは
DECREMENTトークンを返すチェックを追加します。 2文字の演算子用の関数はすでに存在するため、ケースに従って拡張します。
@@ -1175,11 +1177,13 @@ PyToken_TwoChars(int c1, int c2) break; case '+': switch (c2) { + case '+': return INCREMENT; case '=': return PLUSEQUAL; } break; case '-': switch (c2) { + case '-': return DECREMENT; case '=': return MINEQUAL; case '>': return RARROW; }
それらは
token.h定義されてい
token.h
-dを指定してPythonを実行し、ステートメントを実行しようとすると、次のようになります。

It's a token we know - !
レベル4:パーサー
パーサーはこれらのトークンを受け入れ、相互の関係を示す構造を生成します。 Pythonおよび他の多くの言語の場合、これは抽象構文ツリー(またはAST)です。 コンパイラはASTを取得し、1つ(または複数)のコードオブジェクトに変換します。 最後に、インタープリターは、それが表すコードを実行するすべてのコードオブジェクトを受け入れます。
コードをツリー形式で提示します。 上位レベルはルートであり、関数はブランチにすることができ、クラスはブランチでもあり、クラスメソッドはそこからブランチします。 式はブランチ上の葉です。
ASTは
ast.pyおよび
ast.c定義されてい
ast.c ast.cは、変更する必要があるファイルです。 ASTコードは、トークンタイプを処理するメソッドに分割され、
ast_for_stmtはステートメントを処理し、
ast_for_exprは式を処理します。
incr_stmtおよび
decr_stmtを可能な式として
decr_stmtします。 test + = 1などの拡張式とほとんど同じですが、正しい式(1)はなく、暗黙的です。
これは、インクリメントとデクリメントのために追加する必要があるコードです。
static stmt_ty ast_for_expr_stmt(struct compiling *c, const node *n) { ... else if ((TYPE(CHILD(n, 1)) == incr_stmt) || (TYPE(CHILD(n, 1)) == decr_stmt)) { expr_ty expr1, expr2; node *ch = CHILD(n, 0); operator_ty operator; switch (TYPE(CHILD(n, 1))){ case incr_stmt: operator = Add; break; case decr_stmt: operator = Subtract; break; } expr1 = ast_for_testlist(c, ch); if (!expr1) { return NULL; } switch (expr1->kind) { case Name_kind: if (forbidden_name(c, expr1->v.Name.id, n, 0)) { return NULL; } expr1->v.Name.ctx = Store; break; default: ast_error(c, ch, "illegal target for increment/decrement"); return NULL; } // PyObject 1 PyObject *pynum = parsenumber(c, "1"); if (PyArena_AddPyObject(c->c_arena, pynum) < 0) { Py_DECREF(pynum); return NULL; } // ++/-- expr2 = Num(pynum, LINENO(n), n->n_col_offset, c->c_arena); return AugAssign(expr1, operator, expr2, LINENO(n), n->n_col_offset, c->c_arena);
これは、定数値1の新しいタイプの式ではなく、拡張割り当てを返します。演算子は、トークン
incr_stmtまたは
decr_stmtタイプに応じて、AddまたはSub(tract)のいずれか
decr_stmt 。 コンパイル後にPython REPLに戻ると、新しい演算子が表示されています!
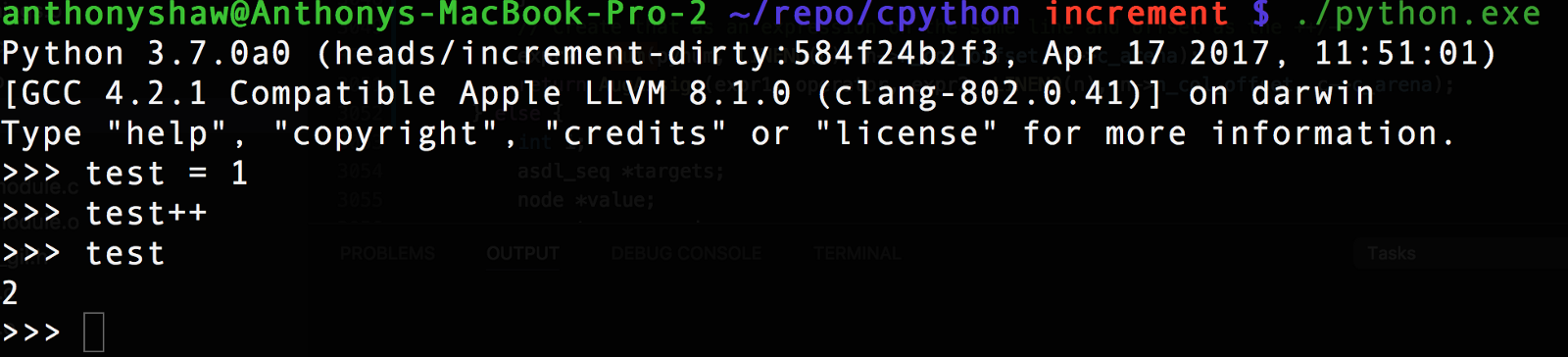
REPLでは、
ast.parse ("test=1; test++).body[1]を試すことができます
ast.parse ("test=1; test++).body[1]を参照すると、戻り型
AugAssignが表示されます
AugAssignはステートメントをコンパイラーで処理できる式に変換しました。コンパイラーによって使用されます。
レベル5:コンパイラー
次に、コンパイラは構文ツリーを取得し、各ブランチを「訪問」します。 CPythonコンパイラには、
compile_visit_stmtと呼ばれるステートメントにアクセスするためのメソッドがあります。 これは、ステートメントのタイプを定義する単なる大きなswitchステートメントです。
AugAssignタイプがあるため、
compiler_augassignを呼び出して詳細を処理します。 次に、この関数はステートメントをバイトコードのセットに変換します。 これは、マシンコード(01010101)と構文ツリーの間の中間言語です。
バイトコードシーケンスは、.pycファイルにキャッシュされるものです。 static int compiler_augassign(struct compiler *c, stmt_ty s) { expr_ty e = s->v.AugAssign.target; expr_ty auge; assert(s->kind == AugAssign_kind); switch (e->kind) { ... case Name_kind: if (!compiler_nameop(c, e->v.Name.id, Load)) return 0; VISIT(c, expr, s->v.AugAssign.value); ADDOP(c, inplace_binop(c, s->v.AugAssign.op)); return compiler_nameop(c, e->v.Name.id, Store);
結果は、VISIT(ロード値は1)、ADDOP(演算子に応じてバイナリ演算コード演算を追加(減算、加算))、およびSTORE_NAME(名前のADDOP結果を保存)になります。 これらのメソッドは、より具体的なバイトコードで応答します。
disモジュールをロードすると、バイトコードが表示されます:

レベル6:通訳
最終レベルはインタープリターです。 バイトコードのシーケンスを受け取り、マシン操作に変換します。 これが、Python.exeとPython for MacおよびLinuxがすべて別個の実行可能ファイルである理由です。 一部のバイトコードには、特定のOS処理と検証が必要です。 たとえば、ストリーミング処理APIは、Windowsスレッドとは非常に異なるGNU / Linux APIで動作するはずです。
!
さらに読むために。
インタプリタに興味があるなら、CEPのプラグインアーキテクチャであるPyjionについて話しました。これは
PEP523になり
ました。まだプレイしたい場合は、待機トークナイザーへの変更とともに
GitHubでコードを起動しました。
終わり
いつものように、私たちは質問、コメント、コメントを待っています。