最近、タイプミスを修正するためのライブラリが必要になりました。 ほとんどのオープンスペルチェッカー(たとえば、hunspell)はコンテキストを考慮に入れていないため、適切な精度を得るのは困難です。 Peter Norwigのスペルチェッカーをベースとして、言語モデルを(N-gramに基づいて)固定し、(SymSpellアプローチを使用して)加速し、強力なメモリ消費を(ブルームフィルターと完全なハッシュを介して)克服し、すべてライブラリーの形で設計しましたC ++と他の言語用のSwigバインダー。
品質指標
スペルチェッカーを直接書く前に、その品質を測定する方法を考え出す必要がありました。 これらの目的のために、Norwigは既製のタイプミスのコレクションを使用しました。これには、エラーのある単語のリストと正しいバージョンが示されています。 しかし、私たちの場合、このメソッドはコンテキストが不足しているため適切ではありません。 代わりに、単純なタイプミスジェネレータが最初に書かれました。
typoジェネレーターは、入力でワードを受け取り、出力でワードにエラーを与えます。 エラーには次の種類があります。1つの文字を別の文字に置き換える、新しい文字を挿入する、既存の文字を削除する、2つの文字を所定の場所に再配置する。 各タイプのエラーの確率は個別に設定され、タイプミスの全体的な確率(単語の長さによる)と2番目のタイプミスの確率も調整されます。
これまでのところ、すべてのパラメーターは直感的に選択されており、エラーの確率は10ワード中約1、最も単純なタイプのエラー(ある文字を別の文字に置き換える)の確率は他のタイプのエラーの7倍です。
このモデルには多くの欠点があります-タイプミスの実際の統計に基づいていない、キーボードのレイアウトを考慮せず、また一緒にくっつかず、単語を分離しません。 ただし、初期バージョンでは十分です。 また、ライブラリの将来のバージョンでは、モデルが改善されます。
タイプジェネレータを使用すると、任意のテキストを実行して、エラーのある同様のテキストを取得できます。 スペルチェッカーの品質の指標として、このスペルチェッカーを実行した後にテキストに残っているエラーの割合を使用できます。 このメトリックに加えて、次のものが使用されました。
- 訂正された単語の割合(エラーの割合を伴うメトリックとは対照的に、テキスト全体ではなく、エラーのある単語についてのみ考慮されます)
- 壊れた単語の割合(これは、単語に間違いがなかった場合であり、スペルチェッカーは、そこにあると判断して修正したときです)
- N個の候補のリストで正しいバリアントが提案された単語の割合(スペルチェッカーは通常、いくつかの修正オプションを提供します)
スペルチェッカーピーターノーウィグ
Peter Norwigは、簡単なスペルチェッカーについて説明しました。 単語ごとに、すべての可能なバリエーションが生成されます(削除+挿入+置換+置換)。深さは2以下です。結果の単語は、辞書(ハッシュテーブル)に存在するかどうかがチェックされます。最も頻繁に発生する単語は、適切なオプションのセットから選択されます。 このスペルチェッカーの詳細については、 元の記事をご覧ください 。
このスペルチェッカーの主な欠点は、長い時間(特に長い単語)、コンテキストの考慮の欠如です。 後者の修正から始めましょう-言語モデルを追加し、単語の単純な出現頻度の代わりに、言語モデルによって返される推定値を使用します。
N-gram言語モデル
| N-gramは、n個の要素のシーケンスです。 たとえば、音、音節、単語または文字のシーケンス。 |
言語モデルは質問に答えることができます-この文が言語で発生する可能性がどのくらいの確率であるか。 現在、主に2つのアプローチが使用されています。N-gramに基づくモデルと ニューラルネットワークに基づく モデル です 。 ライブラリの最初のバージョンでは、より単純であるため、N-gramモデルが選択されました。 ただし、将来的にはニューラルネットワークモデルを試す計画があります。
N-gramモデルは次のように機能します。 モデルのトレーニングに使用されるテキストによると、Nワードのウィンドウを通過し、各組み合わせが発生した回数(nグラム)をカウントします。 モデルへの要求に応じて、提案のウィンドウを同様に通過し、すべてのn-gramの確率の積を考慮します。 n-gramを満たす可能性は、トレーニングテキスト内のそのようなn-gramの数によって推定されます。
m個の単語の文(w 1 、...、w m )を満たす確率P(w 1 、...、w m )は、この文が構成するサイズnのすべてのn-gramの積にほぼ等しくなります。
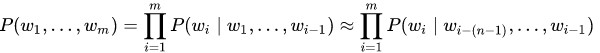
各n-gramの確率は、同じn-gramが最後の単語を除いて出会った回数に対して、このn-gramが出会った回数によって決定されます。
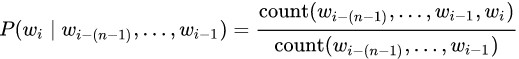
実際には、このようなモデルは次の問題があるため、純粋な形では使用されません。 何らかの種類のn-gramがトレーニングテキストで見つからない場合、文全体が即座にゼロの確率を受け取ります。 この問題を解決するには、スムージング(スムージング)のオプションのいずれかを使用します。 簡単に言えば、これは、すべてのn-gramの出現頻度に単位を追加することです。より複雑な形式では、高次n-gramがない場合に低次n-gramを使用します。
最も一般的なスムージング手法はKneser – Ney smoothingです。 ただし、n-gramごとに追加の情報を保存する必要があり、より単純な平滑化と比較してゲインは強くありません(少なくとも、5000万n-gramまでの小さなモデルの実験では)。 簡単にするために、各n-gramの確率を、すべての次数のn-gramの積として、たとえば、トライグラムの場合の平滑化と見なします。
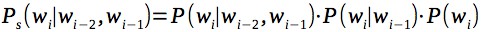
ここで、言語モデルを作成したら、タイプミスの候補の中から、コンテキストを考慮して言語モデルが最高のスコアを与える修正を行う候補を選択します。 さらに、多数の誤検知を回避するために、元の単語を変更するための小さなペナルティを評価に追加します。 この罰金を変更すると、誤検知の割合を調整できます。たとえば、テキストエディターでは、誤検知の割合を高くし、テキストの自動修正を低くすることができます。
シンスペル
ノルウェー語のスペルチェッカーの次の問題は、候補者がいない場合の作業速度が遅いことです。 したがって、15文字の単語では、アルゴリズムは約1秒間機能しますが、このようなパフォーマンスは実用に十分ではありません。 パフォーマンスを高速化するためのオプションの1つはSymSpellアルゴリズムで、著者によれば、これは100万倍高速に動作します。 SymSpellは、次の原則に従って機能します。辞書の各単語について、元の単語を参照して、削除が個別のインデックスに追加されるか、1つ以上の文字(通常1および2)を削除することで元の単語がすべて取得されます。 候補の検索時に、単語に対して同様の削除が行われ、インデックス内でのそれらの存在がチェックされます。 このようなアルゴリズムは、エラーのすべてのケースを正しく処理します-文字の置き換え、再配置、追加および削除。
たとえば、置換を検討します(この例では距離1のみを検討します)。 元の辞書に「 test 」という単語を含めます。 そして、「 テンポ 」という単語を入力しました。 インデックスには、「 test 」という単語のすべての削除、つまりeats 、 tst 、 tet 、 tesが含まれます。 単語「 tempo 」の場合、削除はemt 、 tmt 、 tet 、 emtになります。 「 tet 」の削除はインデックスに含まれています。つまり、「 test 」という単語は「 temt 」というタイプミスの単語に対応します。
完全なハッシュ
次の問題はメモリ消費です。 200万文のテキスト(Wikipediaから100万+ニューステキストから100万)でトレーニングされたモデルは、7 GBのRAMを占有しました。 このボリュームの約半分は言語モデル(発生頻度のnグラム)で使用され、残りの半分はSymSpellのインデックスで使用されました。 このようなメモリ消費により、アプリケーションの使用はあまり実用的ではなくなりました。
品質が著しく低下し始めたため、辞書のサイズを縮小したくありませんでした。 判明したように、これは新しい問題ではありません。 科学記事では、言語モデルによるメモリ消費の問題を解決するさまざまな方法が提案されています。 興味深いアプローチの1つ(記事「 効率的な最小完全ハッシュ言語モデル」を参照)は、 完全ハッシュ (またはCHDアルゴリズム)を使用してn-gramに関する情報を保存することです。 完全ハッシュは、固定データセットに衝突しないハッシュです。 衝突がない場合、キーを比較する必要がないため、キーを保存する必要がなくなります。 その結果、発生頻度を格納するn-gramの数に等しい配列をメモリに保持できます。 これにより、n-gram自体が発生頻度よりもはるかに多くのスペースを占有するため、メモリを大幅に節約できます。
しかし、1つの問題があります。 モデルを使用すると、n-gramが入力されますが、これはトレーニングテキストにはありません。 その結果、完全なハッシュは、他の既存のn-gramのハッシュを返します。 この問題を解決するために、この記事の著者は、n-gramごとに別のハッシュを保存することを提案しています。これにより、n-gramが一致するかどうかを比較できます。 ハッシュが異なる場合、このn-gramは存在しないため、発生頻度はゼロと見なされます。
たとえば、n1、n2、n3の3つのn-gramがあり、これらは10、15、および3回出会っただけでなく、ソーステキストでは発生しなかったn-gram n4もあります。
| n1 | n2 | n3 | n4 |
| 完全なハッシュ | 1 | 0 | 2 | 1 |
| 2番目のハッシュ | 42 | 13 | 24 | 18 |
| 頻度 | 10 | 15 | 3 | 0 |
発生頻度と追加のハッシュを保存する配列を作成しました。 完全ハッシュの値を配列のインデックスとして使用します。
n-gram n1を満たすと仮定します。 その完全ハッシュは1、2番目のハッシュは42です。インデックス1の配列に移動し、そこにあるハッシュを比較します。 一致するため、頻度はn-gram 10です。次に、n-gram n4を考えます。 その完全ハッシュも1ですが、2番目のハッシュは18です。これは、インデックス1にあるハッシュとは異なります。つまり、発生頻度は0です。
実際には、16ビットのCityHashがハッシュとして使用されました。 もちろん、ハッシュは誤検知を完全に除外するわけではありませんが、最終的な品質指標に影響を与えないように頻度を減らします。
発生頻度自体も、非線形量子化により、32ビット数から16ビット数までよりコンパクトにエンコードされました。 小さい数字は1〜1、大きい数字は1〜2、1〜4などに対応していました。再び量子化は最終的なメトリックに影響しませんでした。
ほとんどの場合、ハッシュと発生頻度の両方をさらに強力にパッケージ化できますが、これはすでに次のバージョンに含まれています。 現在のバージョンでは、モデルは最大260 MBまで縮小しました。品質は低下せず、10倍以上でした。
ブルームフィルター
言語モデルに加えて、SymSpellアルゴリズムからのインデックスがまだあり、これも多くのスペースを占有しました。 これについては既成のソリューションがなかったので、もう少し考えなければなりませんでした。 言語モデルのコンパクトな表現に関する科学記事では、 ブルームフィルターがよく使用されました。 彼はこの仕事を手伝うことができるようでした。 ブルームフィルターを額に直接適用することはできませんでした-削除されたインデックスからの各単語には、元の単語へのリンクが必要で、ブルームフィルターは値の保存を許可せず、存在を確認するだけです。 一方、ブルームフィルターがそのような削除がインデックス内にあることを示している場合、挿入を実行し、インデックスでそれらをチェックすることにより、元の単語を復元できます。 SymSpellアルゴリズムの最終的な適応は次のとおりです。
ブルームフィルターに元の辞書から削除された単語をすべて保存します。 候補を検索する場合、最初に元の単語から目的の深さまで削除します(SymSpellと同様)。 ただし、SymSpellとは異なり、各削除の次のステップは、元の辞書に結果の単語を挿入して確認することです。 そして、ブルームフィルターに保存された削除のインデックスは、その中にない削除の挿入をスキップするために使用されます。 この場合、誤検知は私たちを恐れません-私たちは少し余分な作業を行います。
結果として得られるソリューションのパフォーマンスは実際には低下せず、使用されるメモリは非常に大幅に削減されました-最大140 MB(約25倍)。 その結果、合計メモリサイズが7 GBから400 MBに削減されました。
結果
次の表は、英語のテキストの結果を示しています。 トレーニングには、ウィキペディアからの30万文とニューステキストからの30万文が使用されました(テキストはここにあります )。 最初のサンプルは2つの部分に分割され、95%がトレーニングに、5%が評価に使用されました。 結果:
| エラー | 上位7つのエラー | 修正率 | トップ7修正率 | 壊れた | スピード
(1秒あたりの単語数) |
| ジャムスペル | 3.25% | 1.27% | 79.53% | 84.10% | 0.64% | 1833 |
| ノービグ | 7.62% | 5.00% | 46.58% | 66.51% | 0.69% | 395 |
| ハンスペル | 13.10% | 10.33% | 47.52% | 68.56% | 7.14% | 163 |
| ダミー | 13.14% | 13.14% | 0.00% | 0.00% | 0.00% | - |
JamSpellは、結果のスペルチェッカーです。 ダミー-何もしない修正プログラムは、ソーステキストのエラーの割合を明確にするために提供されます。 NorvigはPeter Norwigのスペルチェッカーです。 Hunspellは、最も人気のあるオープンソースのスペルチェッカーの1つです。 実験の純度を高めるために、文学テキストのチェックも実施しました。 「シャーロックホームズの冒険」というテキストのメトリック:
| エラー | 上位7つのエラー | 修正率 | トップ7修正率 | 壊れた | スピード
(1秒あたりの単語数) |
| ジャムスペル | 3.56% | 1.27% | 72.03% | 79.73% | 0.50% | 1764 |
| ノービグ | 7.60% | 5.30% | 35.43% | 56.06% | 0.45% | 647 |
| ハンスペル | 9.36% | 6.44% | 39.61% | 65.77% | 2.95% | 284 |
| ダミー | 11.16% | 11.16% | 0.00% | 0.00% | 0.00% | - |
JamSpellは、1つの候補の場合と上位7つの候補の場合の両方のテストで、HunspellおよびNorwigのスペルチェッカーに比べて優れた品質とパフォーマンスを示しました。
次の表に、さまざまな言語およびさまざまなサイズのトレーニングセットのメトリックを示します。
| エラー | 上位7つのエラー | 修正率 | トップ7修正率 | 壊れた | スピード | 記憶 |
英語
(30万のウィキペディア+ 30万のニュース) | 3.25% | 1.27% | 79.53% | 84.10% | 0.64% | 1833 | 86.2 Mb |
ロシア語
(30万のウィキペディア+ 30万のニュース) | 4.69% | 1.57% | 76.77% | 82.13% | 1.07% | 1482 | 138.7 Mb |
ロシア語
(1Mウィキペディア+ 1Mニュース) | 3.76% | 1.22% | 80.56% | 85.47% | 0.71% | 1375 | 341.4 Mb |
ドイツ人
(30万のウィキペディア+ 30万のニュース) | 5.50% | 2.02% | 70.76% | 75.33% | 1.08% | 1559 | 189.2 Mb |
フランス語
(30万のウィキペディア+ 30万のニュース) | 3.32% | 1.26% | 76.56% | 81.25% | 0.76% | 1543 | 83.9 Mb |
まとめ
その結果、同様のオープンソリューションを凌ぐ高品質で高速なスペルチェッカーが実現します。 使用例は、テキストエディター、メッセンジャー、機械学習タスクでのダーティテキストの前処理などです。
ソースは 、MITライセンスの下でgithubで入手できます 。 ライブラリはC ++で記述されており、swigを介して他の言語のバインディングを利用できます。 Pythonでの使用例:
import jamspell corrector = jamspell.TSpellCorrector() corrector.LoadLangModel('model_en.bin') corrector.FixFragment('I am the begt spell cherken!')
さらなる改善には、言語モデルの品質の改善、メモリ消費の削減、接着と単語分割の処理能力の追加、異なる言語の機能のサポートが含まれます。 誰かがライブラリの改善に参加したいなら、私はあなたのプルリクエストに喜んでいるでしょう。
参照資料