こんにちは、HabraUser! 今日は、Dockerについての別の記事を紹介します。 そのような記事がすでにたくさんあるのに、なぜこれをしているのですか? いくつかの答えがあります。 第一に、それらのすべてが、私がドッカーを学習する私の最初の段階で、私自身が非常に役立つものを説明しているわけではありません。 第二に、私はこの理論について人々に少し理論を直接教えたいと思います。 重要な理由の1つは、この短期間のドッカーの研究で蓄積されたすべての経験(私は6か月以上作業してきました)を何らかの形式に設定し、最後まですべてを整理することです。 さて、最後に、私がすでに踏んでいる熊手を説明し(熊手に助言を与える)、熊手を説明します。その解決策は箱から出してドッカーに単に提供されておらず、鋭い欲求で破裂している段階で考える価値がある問題についてこの技術がすべてに適しているわけではないという認識に至るまで、周囲の世界全体をコンテナに移します。
この記事では何を検討しますか?
パート0(理論)で、コンテナ、それが何であるか、そして何を食べるかについて説明します
パート1から5には、rabbitmqキューを使用してPythonでマイクロサービスを作成するという理論と実践があります。
パート6-あとがき
パート0.0:タイヤのウォームアップ
Dockerとは何ですか? これは、Linux名前空間を使用して、アプリケーションを相互に分離する新しい方法です。 管理、拡張、移行が非常に簡単であり、アプリケーション開発やパッケージ構築から5分間のテスト(1-2コマンドの実行チェック、クローズアンドフォーゲットなど、ごみもクリーンアップされる)まで、幅広いタスクに適しています。
オフサイトで詳細をご覧ください。 最初の段階では、コンテナがレイヤーで構成されていることを想像するだけです。 ファイルシステムの状態のスナップショットから。 これについては少し後で説明します。
この記事のラボインフラストラクチャは、Linuxを搭載した同じOSでも、一連の仮想マシン\ vps \何でも再現できます。 Debian OSを搭載した同じ専用サーバーですべてを行いました。 以下、同じDebian 9 OSで作業していると仮定します。OSからOSへのコマンドとアプローチは異なる場合があり、1つの記事ですべてを説明するのは非現実的であるため、最も馴染みのあるサーバーOSが選択されました。 仮想マシンをインストールして、インターネットへのアクセスを許可するのが難しくないことを願っています。
docker-ceをインストールする必要があります(
公式の男 )
私はすでに書かれたものを噛むつもりはないので、ここでドキュメントへのリンクを提供し、リストで
純粋な Debian9 x64にインストールするためのコマンドを提供します。 スーパーユーザーに代わって実行されるコマンドは#文字で始まり、通常のユーザーコマンドは$で始まります。
パート0.1 VMとの比較
Dockerはプロセス(タスク)を分離する手段であり、これはDockerを仮想マシンとして扱うことは不可能であることを覚えておくことが重要です。 これは、具体的にはLinuxカーネルのコンテナー化ツール(cgroups +名前空間)のラッパーです。 しかし、仮想化のような多くの同様の機能があります。
- 独立性-コンテナは、ドッカーサービスを搭載した任意のOSに移動でき、コンテナは機能します。 (正式に-はい、実際、互換性がポニー、虹、蝶と同じくらいバラ色かどうかはわかりません。他の経験がある場合は、共有してください)
- 自給自足-コンテナは、起動された場所であればどこでも機能を実行します。
それでも、通常の仮想化とは異なります。
- コンテナの内部には、プロセスの操作に必要な最小限のソフトウェアセットがあります。 これは本格的なOSではなく、監視、残りの場所の監視などを行う必要があります。
- 仮想化への異なるアプローチが使用されます。 それについて読んでください 。 私は原則そのものを意味します-おなじみのホストOSはありません。
- コンテナとコンテナが生成するデータには特別な注意を払う必要があります。 コンテナはデータ処理ツールですが、ストレージツールではありません。 例として、コンテナは釘打ち機であり、入力データは板と釘であり、作業の結果は釘を板に打ち込むことです。 同時に、釘のあるボードは釘打ち機自体の一部ではありません。結果は分離され、ツールは分離されます。 出力をコンテナ内に保存しないでください(できますが、ドッカーウェイではありません)。 したがって、コンテナはワーカー(作業済み、キューにレポートされる)であるか、または、たとえばWebサーバーの場合、外部ボリュームを使用する必要があります。 (これはすべて非常に簡単で、現時点では悲しいことはありません)。
パート0.2コンテナ内のプロセス
Dockerが何であるかがわかったので、双眼鏡で中身を見てみましょう。 次の仮定を覚えておく必要があります。
- コンテナは存続しますが、コンテナが生まれるプロセスは存続します。
- コンテナ内では、このプロセスのpid = 1
- pid = 1のプロセスの近くで、他のプロセスを(OSの機能の範囲内で)好きなだけ生成できますが、pid = 1のプロセスを強制終了(再起動)すると、コンテナは終了します。 (ポイント1を参照)
- コンテナ内には、 FHS標準に従って通常のディレクトリレイアウトが表示されます。 場所は、元のディストリビューション(コンテナの取得元)と同じです。
- コンテナ内で作成されたデータは、コンテナ内に残り、他のどこにも保存されません(ホストOSからこのレイヤーにアクセスすることもできます)。 コンテナを削除すると、すべての変更が失われます。 したがって、データはコンテナに保存されず、ホストOSに取り出されます。
パート0.3これらのコンテナの入手先 保管方法
公式および非公式の画像のパブリックストアとプライベートストアがあります。 これらはdocker registryと呼ばれます。 最も人気のあるのは
Dockerハブです。 サービスをドッキングするとき、最初にハブに行き、誰かがすでにこれを行っているかどうかを確認しますか?
また、学習時にあなたにとって大きな助けになります。 完成したDockerfileがハブに表示されるため、クールなおじさんと、これをどうやってやるのかを覗くことができます。 それらの多くはgithubおよび他の同様のリソースに保存されます。
パブリックレジストリに加えて、プライベートのものもあります-有料と無料。 サービスに苦しんで、「はい、これらの人にレジストリ内のこのパフドッカーバッカナリアをすべて見てみましょう」と叫ぶときは、有料のものが必要になります。 そして真実は、DevOpsドッカーを積極的に使用するとき、人や自動化が何百ものコンテナを構築するとき、遅かれ早かれそれをきれいにして維持する方法から燃え始めます。
もちろん、すべてがそれほど悪いわけではありません。 1日数十人と1日に2、3ビルドの場合、レジストリが機能します。 さらに個人的な使用のために。
レジストリが役立つのはなぜですか? それは、あなた、他の人、または自動化の間での保管とコンテナの交換の単一の場所です。 そしてこれは本当にクールなことです。 完成したコンテナは、たった1つのチームで配置およびピックアップできます。重量が1ポンド(VMに比べて)であれば、プラス面はすぐにわかります。 Dockerはツールであり、Dockerレジストリには作業コンテナのデータは保存されないことを覚えておく必要があります。 したがって、開発者は非常に便利なワークフローを持つことができます。開発者は製品を作成し、新しいコンテナを構築し、それをリポジトリにプッシュします。 テスターはそれを受け取り、テストし、先送りします。 Devopsは、たとえば、プロッドのロール紙容器を使用します。 また、サーバーが1台であろうと100台であろうと、ansibleとレジストリを使用して、コンテナをprodにローリングすることはあなたにとって絶対に重要ではありません。 これがCIの全体です-ビルドサーバーによって新しいバージョンを自動的にダウンロードできます。 そのため、個人で使用する場合でも、レジストリでVPS \ DSを取得することを強くお勧めします。コンテナを交換することは非常に便利です。
リポジトリから画像をダウンロード:
docker pull wallarm/node
画像をリポジトリにアップロード:
docker push example.com:5000/my_image
また、プライベートリポジトリにログインする必要があります。これにはコマンドが必要です
docker login
ユーザー名とパスワードを入力する必要があります。
次の1つのコマンドでレジストリを開始できます。
docker run -d -p 5000:5000 --restart=always --name registry registry:2
オフサイトの
詳細 。 SSL、認可-これはすべて可能です。
パート0.4コンテナーとイメージ(イメージ)
Dockerイメージはレイヤーのセットです。 各レイヤーは、Dockerfileでのチームの作業の結果です。 大まかに言えば、画像はコンテナを起動するためのテンプレートです。 このイメージに基づいて起動されるのは、コンテナまたはインスタンスのみです。 つまり 1つのイメージから、このイメージのいくつかの同一コピー(コンテナー)を実行できます。 そして、いくつかの操作の後、このコンテナからテンプレートを作成できます-新しいイメージ。 この不名誉はすべて/ var / lib / dockerに保存されます。
ドキュメントシステム内のイメージのリストは、次のコマンドで表示できます。
コンテナリスト:
docker ps
-aスイッチも停止したことを示し、-sスイッチはそのサイズを示します。 つまり 実際、このコンテナが実行時にどれだけディスクスペースを占有するか。
パート0.5コンテナとイメージに名前を付ける方法
画像には、命名に関連する3つのフィールドがあります。
1)リポジトリ
2)タグ
3)画像ID
リポジトリ-本物または非本物、これはあなたの画像がどこからまたはどこからダウンロード/アップロードされるか、またはあなたがそれをどこにもアップロードするつもりがない場合は単なる作り上げの名前です。
タグは通常、製品のバージョンです。 理論的には、これは任意の文字セットです。 (許可リスト[a-z0-9.-]などから)。タグがない場合、
最新の単語
が自動的に使用されます。 タグは、シンボルを介して配置されます:リポジトリに代わって、プッシュ\プル時に指定されていない場合は自動的に置換されます。
ImageID-ローカルで生成された画像の一意のID。この方法で操作できます。
したがって、あなたまたはコンテナの作成者は、リポジトリおよび/またはタグ、およびシステムにローカルに影響を与えます-ID。 しかし、ところで、誰も異星人のリポジトリ名を再利用することを気にしません、別の質問はあなたがそれをプッシュ(プッシュ、ロード)できないものです
例:
1/2 / 3-blah.blah.blah-ローカルイメージの名前、あなたがそれを発明した
projects / my_first_dockerはローカルイメージの名前でもあります
projects / my_first_docker:latestは同じ名前ですが、タグが付いています。 前のものと同等。
projects / my_first_docker:1.13.33-ただし、これはこのリポジトリ内のイメージの特定のバージョンです。
projects / my_first_docker:1.13.34
projects / my_first_docker:1.13.35
...など-これらはすべて同じプロジェクトですが、画像のバージョンは異なります。
Dockerの優れた機能の1つは、レイヤーの再利用です。 これは、レイヤーが変更されていない場合、イメージの新しいバージョンが他のコンテナーのレイヤーを使用できることを意味します。 たとえば、debianルートレイヤーは、すべてのdebianベースのコンテナーで使用されます。 2番目のレイヤー、たとえばnginxをインストールし、3番目のレイヤーが構成を配置する場合、構成を変更して新しいイメージを作成すると、2つの古いレイヤーと1つの新しいレイヤーで構成されます。 しかし、喜んで大急ぎしないでください。 この再利用により多くのスペースを節約できますが、ドッカーはくしゃみごとに作成するこれらのレイヤーを整理できます。 再利用のためにこれらの層は互いに地獄のような依存関係を持ち、最終的に、多くのコンテナが組み立てられる大規模なインストールでは、これは私が上記で述べた非常にパフなバカナリアになります。 しかし、あなたに起こることとして言われたことを受け取らないでください。私は、オフィス全体が自動化と相まって何かを終日収集するときに、1日に数十の新しいビルドを搭載した負荷システムについて話します。 通常のサーバーにはそのようなバッカナリアはありません-そこには数個のコンテナしかありません。 一方で、非常に簡単にクリーニングされます-rm -rfだけです。 あなたにとって最も重要なのはコンテナです。コンテナはリポジトリにあり、単純に自動的に再度ダウンロードされます。 とにかく、作業の結果をコンテナに保存しないでください。
その他の例:
wallarm / node-これは、Wallarm社の最高のWAFがすでにハブのパブリックドッカーからダウンロードされたイメージです。
debian:stretch-debianイメージ、イメージのバージョン-stretch(数字ではなく単語)
centos:7-debianに似ています。
mongo:3.2-パブリックリポジトリからダウンロードされたmongodbバージョン3.2イメージ
nginx-最新の安定したnginx-同様に。
そして、ほとんどの場合、ハブで必要なソフトウェアのさまざまなバージョンを確認できます。 たとえば、mongoを使用すると、3.2と3.4と3.6の両方、さらには開発バージョンもダウンロードできます。 およびさまざまな中間体。 そして他のたくさん。
それがどれほど便利か想像してみてください-Monga 3.2が回転しているので、近くで別のバージョンを試してみてください。 新しいバージョンのコンテナをダウンロードして実行するだけです。 また、仮想マシンを選択して構成したり、クリーニングしたりする必要はありません。 Dockerイメージを削除する必要があるのは、docker rmiコマンドを入力するだけだからです。 そして、それは比類のない軽量です。 たとえば、200メートル。 また、さらにクールにしたい場合は、alpine linuxベースの既製のソリューションを使用できます。 bind9-alpine。 1つの悪魔。 3構成 15メガバイト!!! これは、すぐに使用できる完全なインストールです。
覚えておいてください。同じイメージには、任意の数のリポジトリ名とタグを含めることができますが、同じイメージIDを持つことになります。 同時に、この画像のすべてのタグが削除されるまで、画像は削除されません。 つまり debianイメージをダウンロードして新しいタグを要求すると、リストには2つのイメージがありますが、名前は同じですが、imageidは同じです。 debian:stretchを削除すると、タグの1つを削除するだけで、画像自体は生きたままになります。
既存のイメージに別の名前を設定するには、次のコマンドを使用します。
docker tag <existing image name> <new image name>
画像を削除するには:
docker rmi <image>
ただし、コンテナには2つの名前があります。
1)コンテナID
2)名前
id-ここでも同じ-これは、イメージの実行中の特定の一意のインスタンスの一意の名前です。 簡単に言えば、実行中のイメージの一意の名前です。 イメージは何度でも実行でき、各コピーには一意の名前が付けられます。
名前-しかし、これは男性とスクリプト作成にとってより便利な名前です。 事実、さまざまなイメージを起動することで、起動したコンテナの名前を確認したり、コンテナの起動時にこの排気を行うまで、起動した名前を正確に知ることはできません。 stdoutにログインできる場合、コンテナ名は失われます。 そのため、-nameキーを使用して実行中のコンテナの名前を事前設定し、すぐにわかる名前で操作できます。
コンテナリスト:
docker ps
コンテナを削除するには:
docker rm <container>
パート0.6さて、これらはすべて外国のコンテナですが、どうやってゼロから自分のものを作ることができますか?
コンテナを作成するには、ビルドメカニズム-docker buildがあります。 Dockerfileの命令セットを使用して、独自のイメージを構築します。 内部にコンテナを構築するとき、shシェルが使用され、コマンドが実行されます。
次のことを知っておく必要があります。
- 完了した各コマンド-このコマンドによって生成された変更の結果でファイルシステムレイヤーを作成します。 つまり たとえば、apt install htopコマンドを実行すると、このコマンドの実行結果(バイナリ、ライブラリなど)を含むレイヤーが作成されます。 最終的に、そのような各レイヤーは互いに重ね合わされ、元の(オペレーティングシステムのイメージ)に重ねられ、最終結果が得られます。 これにより、いくつかの制限が生じます。
- レイヤーは互いに独立しています。 これは、コンテナ内のビルドプロセス中に実行されるサービスは、それ自体のレイヤー内にのみ存在することを意味します。 顕著な例は、mysqlでデータベースをいっぱいにする試みです。 これは通常どのように起こりますか? mysqlサーバーを起動し、次のコマンドでデータベースに入力する必要があります。 これは、ここでは機能しません。 mysqlの起動結果(ログなど)を保存するレイヤーが作成され、mysqlが終了します。 次のレイヤー(ベースフィルコマンドの実行時)では、マッスルは起動されなくなり、エラーが発生します。 この問題の解決策は、&&を使用してチームを統一することです。
- 3)ただし、永続データは最初のコマンドから最後のコマンドまで互いに重ね合わされ、レイヤーごとに永続的に保存されます。 したがって、最初のコマンドでファイルを作成すると、最後のコマンドでアクセスできます。
パート0.7最後に、「これはDockerの方法ではありません」
Dockerは、ビルド内のほとんどのごみ層です。 さらに、停止したコンテナの束を残すことができます。 1つのコマンドですべてを削除する
docker system prune
これは港湾労働者の方法ではありません。
ドッカーは、設計上、1つのプロセス(任意の数の子孫を含む)を仮想化します。 もちろん、1つのコンテナに10個のプロセスを詰め込むことを邪魔することはありません。
これは、たとえばスーパーバイザーを使用して実行できます。
しかし、あなたは言う、彼らのすべての人生が一緒になり、共有されるべきではないサービスについてはどうですか? 各友人がdrugug用に生成するコンテンツを使用しますか?
これを美しく正確に行うために、docker-composeがあります-これは、コンテナのNとその関係を記述するyamlファイルです。 交差するコンテナ、相互に開くポート、共有するデータ。
作成の場合、実際にはプロジェクトを簡単に管理できます。 たとえば、nginx + uwsgi + mongoバンドルは3つのコンテナですが、nginx以外のユーザーはuwsgiに、mongo以外のユーザーはmongoに行きません。 そして、彼らは常に一緒に住んでいます。 (これはプライベートケースです)。 ここでは、次の状況が発生します-アプリケーション(api)は頻繁に更新されます-あなたはそれを毎日書いてプッシュします。 また、たとえば、nginxまたはmongodbのリリースははるかに少ない頻度で行われます。おそらく1か月、さらに長くなります。 では、変更がすべて1か所で発生するたびに、なぜこの重量級を構築するのでしょうか? nginxを更新するときが来たら、タグ名とプロジェクトの再構築全体を変更し、nginxで新しいコンテナをダウンロードするだけです。
パート1:練習はいつですか?
この段階で、コンテナに触れて必要なコマンドを教えることができます。 私は、手動でチュートリアルからチームを運転することのサポーターです。 したがって、スクリーンショットのみ。
1. debianイメージをダウンロードしてみましょう

2.何が起こったのか見てみましょう。 私の場合、フィルターにdebianという単語を使用しました。 そうしないと、他の画像の束が結論に落ちてしまいます。 使用する必要はありません。 その結果、異なるタグを持つ2つの同一のimageidがあります(最初の2つがあります)。
Z.Y. 未来へこんにちは! debian10に住んでいてこの記事を読んでいる人にとっては、私のものと同じ結果にはならないでしょう。 理由をご理解いただければ幸いです。

3. debian:stretch image内でbashプロセスを実行します。 そのpidを見てください-それは1に等しいです。 すなわち これが私たちが踊っている主なプロセスです。 注意してください-ps auxを簡単に実行できませんでした-コンテナに必要なパッケージがありません。 aptを使用して、通常どおり配信できます。

4.コンテナを終了し(exit | Ctrl + D)、bashの再起動を試みます-これは上部コンソールにあります(スクリーンショットを簡単にするために、別のコンソールを開くことができます)。 下部のウィンドウで-実行中のコンテナのリストを参照してください
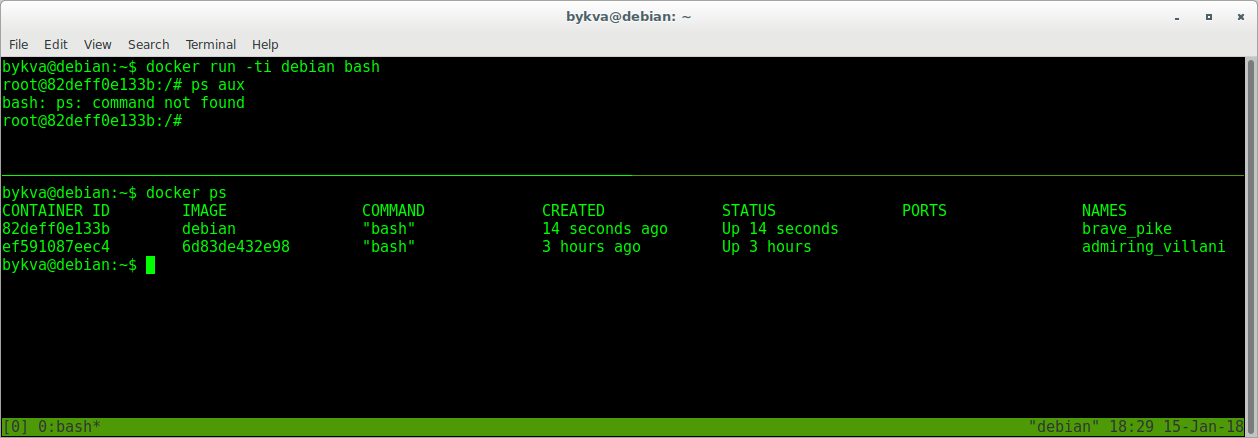
わあ! procpsはどこに行きましたか? はいどこにもありません。 彼はここにいませんでした。 イメージを再起動したときに、インストールされたプログラムなしで同じキャストを使用しました。 そして、私たちの仕事の結果はどこに行きましたか? そしてそこに彼は嘘をついている-終了状態で。 以前に立ち上げて後で停止した他のコンテナの束のように。
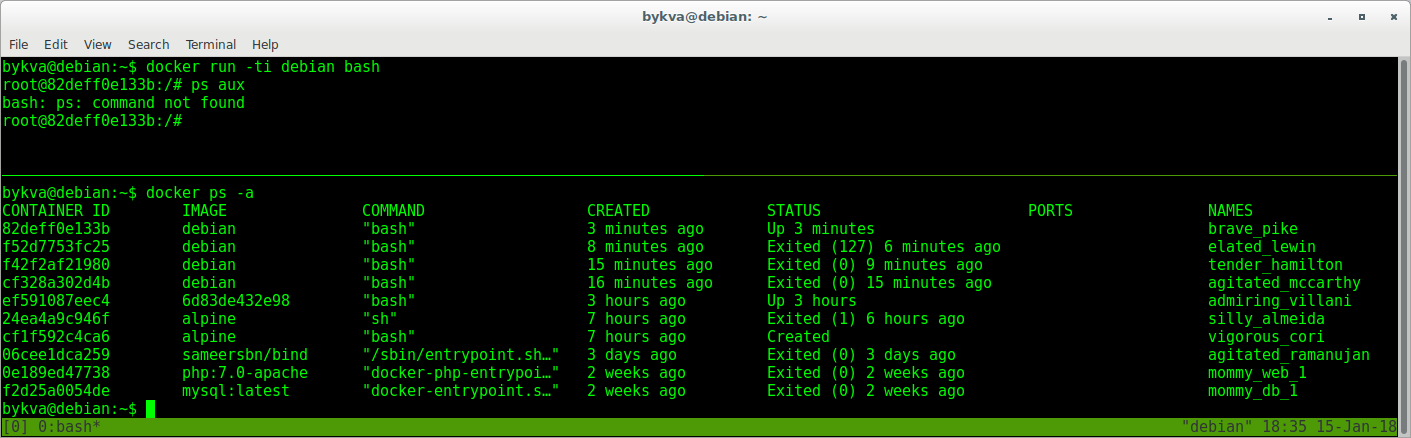
これはすべてゴミです。 しかし、それはまだ復活することができます:
1.最初のターミナルでコンテナを終了します
2. 2番目のターミナルで、コンテナのIDをコピーします。これは、停止したものとしてtimeshtampによって適切です
3. 1つのターミナルで、startコマンドでこのコンテナを起動します。 彼はバックグラウンドに行く
4. 2番目のターミナルで、実行中のコンテナのリストを確認します。タイムスタンプまでに、7秒間実行されているコンテナは明らかに私たちのものです。
5.耳を切ります。 execコマンドを使用して既に実行中のコンテナーに接続し、2番目のbashインスタンスを実行します。
6. ps auxを実行します-最初のbashはpid 1とともに存在することに注意してください。 コンテナ内でpid = 7のbashを使用して管理します。 そして今、外に出ればコンテナは生きます。
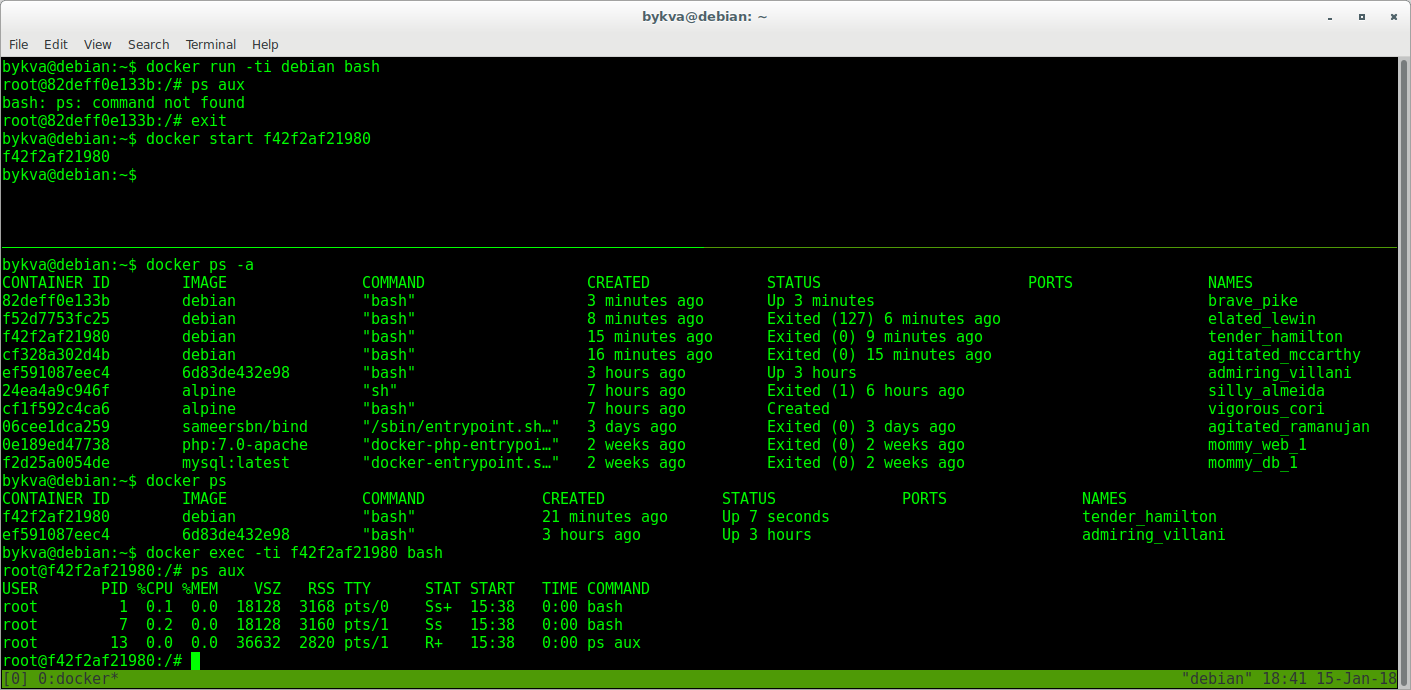
だから:
run -Xのイメージを取得し、プロセスYでコンテナーZを作成します
exec-コンテナーZを取得し、その中のプロセスNを開始しますが、プロセスYは以前と同様に機能します。
結論:
1)仮想化するプロセスのみが生きている場合、コンテナはバックグラウンドとフォアグラウンドの両方で生きることができます。
2)コンテナはイメージからデプロイされたインスタンスです
3)データを損失することなくコンテナを停止および起動できます(ただし、価値はありません。これはdocker-wayではありません)
パート2:独自のdockerイメージを作成する
dockerfileの使用方法を学習します。
以下に2つの開発アプローチを示します。
1)準備を整えて自分自身を弱体化させる
2)最初から自分で行う
最初のオプションは、すべての作業が完全に完了していることを確信している場合です。 たとえば、nginxで既製の公式コンテナを入手できるのに、なぜnginxをインストールするのか。 これは、同じチームに所属していないシステムや、たとえば、debianでは古いバージョンがあり、ドッカーハブでは最新の安定したシステムで構築されているシステムに特に当てはまります。 さらに、自動アセンブリはすでに行われています-新しいバージョンがすぐに到着します。
2番目のオプション-あなたは妄想的であるか、画像の作者のアプローチが好きではありません(例えば、公式のものはありませんでしたが、Vasya Pupkinのハブにのみありました)。 誰もワシリーがそれをどのようにしたかを気にせず、それから自分で行ってください。
まあ、または、jenkinsでdebパッケージをビルドするためのdockerイメージなど、独自のロジックを作成する場合は、どこにも見つかりません。しかし、これは非常に便利です!Dockerfileは、指定したイメージのクリーンコンテナで実行される一連の命令を含むファイルであり、出力ではイメージが取得されます。指定する必要がある最も重要なことは、FROMおよびCMDディレクティブです(原則的には、必ずしもそうではありません)。そのようなファイルの例を示します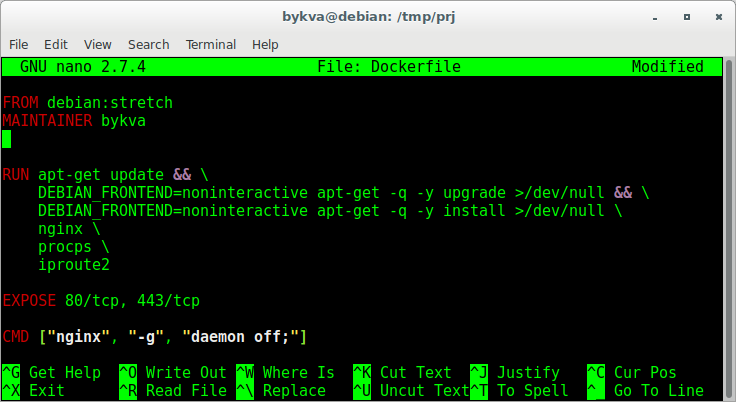 。FROM-基礎として使用するイメージ。MAINTAINERは、この開発の作成者(この新しいイメージの作業を開始する人)です。RUNは、コンテナー内で実行されるコマンドであり、それに基づいて新しいイメージが取得されます。注意してください-通常のbash転送と&&-コードを読みやすく、美しくします。また、ロジックを記述するために、少なくとも10個のRUN-コマンド(ただし、それぞれが新しい行)を記述することもできます。EXPOSE-docker-composeを使用する場合、どのポートで、どのプロトコルでコンテナーの外部からアクセス可能になります。ここで覚えておく必要があるのは、これはすぐに利用できるという意味ではないことです。
。FROM-基礎として使用するイメージ。MAINTAINERは、この開発の作成者(この新しいイメージの作業を開始する人)です。RUNは、コンテナー内で実行されるコマンドであり、それに基づいて新しいイメージが取得されます。注意してください-通常のbash転送と&&-コードを読みやすく、美しくします。また、ロジックを記述するために、少なくとも10個のRUN-コマンド(ただし、それぞれが新しい行)を記述することもできます。EXPOSE-docker-composeを使用する場合、どのポートで、どのプロトコルでコンテナーの外部からアクセス可能になります。ここで覚えておく必要があるのは、これはすぐに利用できるという意味ではないことです。つまり
つまり、host:container mappingを使用してこのポートのマッピングを開始するまで、中に入ることはできません。したがって、どの段階でどのポートを登録したかを知る必要があります:1)コンテナー内で、アプリケーションは0.0.0.0:80をリッスンします(そして常に0.0.0.0 !!!、localhostにバインドできません-この方法でアプリケーションは外部からアクセスできなくなります)。 mysqlに関してもです。コンテナの起動時にマッピングを指定するまで、誰もアプリケーションに接続しないことに注意してください。2)docker run -p 80:80 imageそして、この方法でのみ-ポート80のホストを参照して、ポート80のコンテナにマップします。コンテナが起動したとき、このポートは開いていて、コンテナ内でアプリケーションはポート80をリッスンします。したがって、ホストポート80からアプリケーションの80ポートに転送されます。当然、ポートはどれでも作成できます。そのため、nginxが内部でポート80をリッスンしている多くのコンテナーを起動でき、外部からのマッピングは次のように実行できます:8000:80、8001:80、8002:80 ...など、アイデアは明確です。したがって、1つの構成で1つのイメージを作成し、それを複数回並行して独立して実行できます。CMD-これが重要な場所です。これは、コンテナの起動時に実行され、この間ずっと機能するコマンドです。はい覚えていますか?プロセスの実行中、コンテナは存続します。ここでのアプローチはsystemdの場合と同じです-プロセスはバックグラウンドに移行しないでください-必要はありません。プロセスはこのコンテナ内で1つだけです。したがって、ところで、ロギングへのさまざまなアプローチ。たとえば、出力をSTDOUTまたはログに残すことができます。主なことは、開始後のプロセス(メインプロセス)がライブのままであることです。フォークフォークは好きなだけ使用できます。CMDに加えて、別のタイプのシャーマニズムがあります-ENTRYPOINT。これは通常、CMD値を引数として受け取るシェルスクリプトです。次のことを覚えておく必要があります。1)コンテナでプロセスを開始する最後のコマンド= sum ENTRYPOINT + CMD。2)エントリポイントとcmdの組み合わせの任意のバリアントをdockerファイルに書き込むことができます-どちらか一方、または両方を一度に残します。例:
ENTRYPOINT ["/entrypoint.sh"]CMD ["haproxy"、 "-c"、 "/etc/haproxy/haproxy.conf"]合計。コンテナが起動すると、次のコマンドが起動されます。sh -c "/entrypoint.sh haproxy- c /etc/haproxy/haproxy.conf "。スクリプト内でこれらの引数をどうするかは、あなたが決めるのはあなた次第です。なぜこの複雑さが必要なのですか?適任者はエントリーポイントを作成して、あらゆる機会を明らかにします。純粋に自分でイメージを作成する場合は、純粋にCMDを1つだけ残し、ENTRYPOINTをまったく作成しないでください。シナリオ1:引数なしでコンテナーを起動する:docker run haproxyはENTRYPOINT + CMDを実行します:sh -c "/entrypoint.sh haproxy -c /etc/haproxy/haproxy.conf"どちらもコンテナに縫い付けられています。 entrypoint.shスクリプトでは、作成者は次のロジックを作成しました。最初の引数がhaproxyの場合、haproxy = haproxy -db -W $ @。そして、結果を実行します。その結果、次のコマンドが起動されます。 haproxy -db -W -c /etc/haproxy/haproxy.conf"
シナリオ2:引数を指定してコンテナーを開始します。docker run haproxy bashwhere bash-dockerfileからのCMDコマンドをオーバーライドします。その結果、ENTRYPOINT + CMDは以下を提供します:sh -c "/entrypoint.sh bash"著者のロジックによれば、最初の引数が!= Haproxyの場合、このプロセスを開始するだけです。その結果、コンテナを単純にシェルに入力します。シナリオ3:私は適切な場所で設定を使用してhaproxyの起動を指定します。docker run haproxy haproxy -c /opt/haproxy.confここで、最初のhaproxyはイメージの名前であり、その後ろにあるのは内側に渡された引数のみです。 CMDを再定義すると、結果は次のようになります。sh -c "/entrypoint.sh haproxy -c /opt/haproxy.conf"そして、アプリケーションが起動します。 haproxy -db -W -c /opt/haproxy.conf"
これは、入力を操作することでできることの原始的な例です。 ENTRYPOINTとCMDの組み合わせをさまざまに使用するための多数のシナリオを検討できます。 Dockerfileにアクセスできないエンドユーザーでコンテナを起動する方法をいくつか提供できることを覚えておいてください。示したコマンドに加えて、他にも多くのコマンドがあります。たとえば、ADD、COPY-コンテナー内にデータセットを配置できます。また、ADDがアーカイブをソースとして指定すると、指定した場所にコンテンツを展開して配置します。まれにしか変更されないファイルのセットに便利です。Dockerfile内の順序は重要です! (最適化の観点から)Dockerfileに変更を加え、その後イメージを再構築すると、変更の開始元のコマンドセットに影響します。例:
COPY config config RUN apt install 100500-programms-pack
構成の少なくとも1つの文字を変更すると、100500プログラムのパックをインストールするたびに何度も呼び出します。しかし、これらの行が逆の順序で配置されている場合、ビルドはほぼ瞬時に行われます-なぜなら これらのプログラムを含むレイヤーは既に存在します。パート3:FSコンテナーとホストの通信
それでは、コンテナからホストOSのデータにアクセスする方法を見てみましょう。これにはいくつかの理由があります:ファイル転送、設定、または単に処理されたデータをディスクに保存する。前に述べたように、コンテナをオフにした場合のようにデータは消えませんが、それらはこのコンテナに残ります。後でそれらを引き出すことは不必要で愚かな作業です。 Docker Way-コンテナー内にホストディレクトリ\ファイルをマウントします。さらに簡単な場合は、外部のフォルダー\ファイルを内部のフォルダー\ファイルにマッピングします。これはマウントであるため、一方の変更は常に他方に表示されます。したがって、ホストOSから構成に変更を加えることにより、コンテナー内のサービスの動作を変えることができます。また、その逆-ホスト上のデータベースを、厳密に定義された便利な1つの場所に保存します。またはログ。このことは-vスイッチで行われます: -v /source/folder:/destination/folder -v /path/to/file:/path/to/config
この場所では、便利な人への別のリンク、つまり、簡単な説明付きのdockerチームの記事コレクションを提供できます。 タイツ場合によっては、設定よりも環境変数を転送する方が簡単です。そして、Dockerを使用すると、Dockerfile(ENVキー=値)でビルド用に配線され、コンテナーを起動するときにキーを介して、およびそのような変数が多数ある場合は別のファイルを介して配線できます。パート4:サービスの便利なランチャー
すでにいくつかのコンテナを自分で構築している場合、問題が発生します。どのように努力せずにそれらを自動的に起動できますか?答えは簡単です-systemdを通して!たとえば、ファイルを作成します。
そしてそこに行を置きます: [Unit] Description=my first docker service Requires=docker.service After=docker.service [Service] Restart=always RestartSec=3 ExecStartPre=/bin/sh -c "/usr/bin/docker rm -f my-project 2> /dev/null || /bin/true" ExecStart=/usr/bin/docker run --rm -a STDIN -a STDOUT -a STDERR -p 80:80 -v /etc/my-project/:/etc/my-project --name my-project:2.2 ExecStop=/usr/bin/docker stop my-project [Install] WantedBy=multi-user.target
ここで注意すべきこと:ExecStartPre-スタートアップ\再起動で実行され、my-projectという名前の何らかの障害コンテナが突然あった場合に強制終了するコマンド。さて、あなたはそれがどこから来たのか(グリッチ、曲がった手)を決して知らない-このラインで、いずれにせよ、私たちはそれを開始することを妨げるものを打ち負かし、いずれにせよコマンドを積極的に終了します。--rm-キーを使用すると、コンテナが停止した後に削除できます。サービスを停止した後、ゴミは残りません--name my-project-コンテナの名前-a STDIN -a STDOUT -a STDERR-stdにアタッチ*-プロセスの入力/出力/エラーフローに接続します。バックグラウンドでは、これはログに書き込まれないすべてのものがsystemd-p log-コンテナー内のホスト->ポート80の0.0.0.0:80にマッピングされることを意味します-v-フォルダーをキーの構成にマッピングしますいくつかの異なるポートを指定できます。特に、プロトコル(tcpまたはudp)も指定できます。デフォルトはtcpです。保存して、閉じて、実行します: systemctl restart my-project.service && journalctl -u my-project.service --no-pager -f
ここで、サービスを通常のsystemdデーモンとして管理し、journalctl-デーモンの標準出力を確認します。パート5:現実に近づく。インフラを構築する
次の合成例があります:send.py-> rabbitmq-> read.pyすなわち
3つのコンテナがあり、最初のコンテナがタスクをキューに入れ、最後のコンテナが読み取りを行います。これらはすべてsystemdで管理されます。sender.pyは5秒ごとに1〜7の乱数をキューに入れ、ワーカー(receiver.py)はこの番号を読み取り、受信した数値と等しいアイドル秒数で作業をシミュレートします。マイクロサービスを適切な人が行うようにしようとします-サービスコードはコンテナ内にあり、設定とログは外部にあります。これにより、新しいコンテナを作成せずにキューアドレス、ログイン、パスワードなどを変更できます。ファイルを修正してコンテナを再起動するだけです。したがって、/ etcおよび/ var / logにディレクトリが必要であり、それぞれログと設定をマッピングします。一般に、このアプローチは便利です。 1つまたは複数のマイクロサービスが近くに共存できるドッカーを備えたサーバーにアクセスすると、構成またはログを探す場所が常にわかります。そして最も重要なことは、サーバーが完全にクリーンであることです。 ssh yes docker、他に何が必要ですか? (もちろん、たとえば監視サービスやパペットなど、多くのものがありますが、サービスに依存するすべての要素をすでに取り除いています。そして最も重要なことは、サービスがホストOSに依存しなくなったことです。サーバー全体をDebian上に置き、コンテナ内に何でも入れます。はい、これらの同じ議論は仮想化につながりますが、ここでの話ははるかに軽量です。仮想化されたOS全体ではなく、サーバー全体にツールをドラッグしているため)1. RabbitMQRabbitMQは、アプリケーション間のメッセージングマネージャーです。この場合、プリミティブキューが使用されます。タスクはこのキューに配置され、ワーカーによって受け入れられます。コンテナ内でハードコードするキュー設定を構成します。合計で、rabbitmqフォルダーに3つのファイル(Dockerfileとconfigsの2つのファイル)があります。それらの内容はリストの下のネタバレです。jsonファイル定義でキュー、ユーザー、アクセス権を設定します。 mkdir -p ~/Documents/my_project/{sender,receiver,rabbitmq} cd ~/Documents/my_project/rabbitmq
/etc/systemd/system/my_project-rabbitmq.service [Unit] Description=my first docker service Requires=docker.service After=docker.service [Service] Restart=always RestartSec=3 ExecStartPre=/bin/sh -c "/usr/bin/docker rm -f rabbitmq 2> /dev/null || /bin/true" ExecStart=/usr/bin/docker run --rm -a STDIN -a STDOUT -a STDERR -p 5672:5672 --name rabbitmq rabbitmq:1.0 ExecStop=/usr/bin/docker stop rabbitmq [Install] WantedBy=multi-user.target
〜/ドキュメント/ my_project / rabbitmq / rabbitmq.confmanagement.load_definitions = /etc/rabbitmq/definitions.json
〜/ドキュメント/ my_project / rabbitmq / definitions.json {"rabbit_version":"3.7.2","users":[{"name":"username","password_hash":"P2bFyWm2oSwuzoRDw37nRYgagL0ciZSGus3kYnkG1aNaUWeD","hashing_algorithm":"rabbit_password_hashing_sha256","tags":""},{"name":"guest","password_hash":"SjeLNFEWLHwuC5QRAaZIF/SX/uMasQFyt5+dELgKK03TgsC8","hashing_algorithm":"rabbit_password_hashing_sha256","tags":"administrator"}],"vhosts":[{"name":"virtualhost"},{"name":"/"}],"permissions":[{"user":"guest","vhost":"/","configure":".*","write":".*","read":".*"},{"user":"username","vhost":"virtualhost","configure":".*","write":".*","read":".*"}],"topic_permissions":[],"parameters":[],"global_parameters":[],"policies":[],"queues":[],"exchanges":[],"bindings":[]}
〜/ドキュメント/ my_project / rabbitmq / Dockerfile FROM rabbitmq:management ADD rabbitmq.conf /etc/rabbitmq/rabbitmq.conf ADD definitions.json /etc/rabbitmq/ RUN chown rabbitmq:rabbitmq /etc/rabbitmq/rabbitmq.conf /etc/rabbitmq/definitions.json CMD ["rabbitmq-server"]
2.メッセージの送信者 cd ~/Documents/my_project/sender
/etc/systemd/system/my_project-sender.service [Unit] Description=my first docker service Requires=docker.service After=docker.service [Service] Restart=always RestartSec=3 ExecStartPre=/bin/sh -c "/usr/bin/docker rm -f sender 2> /dev/null || /bin/true" ExecStart=/usr/bin/docker run --rm -a STDIN -a STDOUT -a STDERR -v /etc/my_project/sender:/etc/my_project/sender --name sender sender:1.0 ExecStop=/usr/bin/docker stop sender [Install] WantedBy=multi-user.target
〜/ドキュメント/ my_project / sender / Dockerfile FROM debian:stretch RUN apt-get update > /dev/null && apt-get -y -q install \ python3-pip > /dev/null RUN pip3 install pika pyyaml COPY sender.py /opt/ CMD ["/usr/bin/python3", "/opt/sender.py"]
/etc/my_project/sender/sender.yaml -- rabbitmq: username: username password: MTIzNDU2Nzg5MA== host: 192.168.136.181 port: 5672 virtualhost: virtualhost queue: queue
3.受信者-または私たちの勤勉な労働者。 cd ~/Documents/my_project/receiver
/etc/systemd/system/my_project-receiver.service [Unit] Description=my first docker service Requires=docker.service After=docker.service [Service] Restart=always RestartSec=3 ExecStartPre=/bin/sh -c "/usr/bin/docker rm -f receiver 2> /dev/null || /bin/true" ExecStart=/usr/bin/docker run --rm -a STDIN -a STDOUT -a STDERR -v /etc/my_project/receiver:/etc/my_project/receiver --name receiver receiver:1.0 ExecStop=/usr/bin/docker stop receiver [Install] WantedBy=multi-user.target
/etc/my_project/receiver/receiver.yaml --- rabbitmq: username: username password: MTIzNDU2Nzg5MA== host: 192.168.136.181 port: 5672 virtualhost: virtualhost queue: queue
〜/ドキュメント/ my_project / receiver / receiver.py 〜/ドキュメント/ my_project / receiver / Dockerfile FROM debian:stretch RUN apt-get update > /dev/null && apt-get -y -q install \ python3-pip > /dev/null RUN pip3 install pika pyyaml RUN mkdir /var/log/receiver COPY receiver.py /opt/ CMD ["/usr/bin/python3", "/opt/receiver.py"]
さあ、耳を傾けて見てください。設定されたパラメーターは、ラインをすくい上げるワーカーの能力を超えています。隣の労働者と一緒に別の港湾労働者を持ち上げて、彼らがどのようにすくい上げるかを賞賛してください。スケーラビリティは一見簡単です。労働者を別の場所に移動します-そして彼はそこからラインをかき集めます。主なものはネットワーク接続です。パート6:現実
ほとんどの場合、パラメータを手動で選択する必要があります。特に、完成したプロジェクトをdockerに転送する場合。ログを書き込む場所、構成ファイルの場所、そしてコンテナから削除できるように構成ファイルを作成する方法に転送する必要があるポートを徹底的に把握する必要があります。そして最も重要なのは、それが何であるか、あなたのサービスがどのコンポーネントで構成されているかです! Dockerfileを使用することの優れた点の1つは、目の前に一連の指示があり、イメージを完成品の状態にすることです。サービスのインストールがansible \ puppet \ chefのような自動構成システムに登録されていない場合、高い確率で、これを行う方法についての完全な指示がありません。突然近くにいくつかのサービスがあった場合はさらにそうです。それらを共有することはとても楽しいです!また、サービスのパッケージバージョンへの依存は、おとぎ話にすぎません。はい、人々はvirtualenvのようなものを思いつきましたが、すべてがあなたからしっかりと分離されているとき、それははるかに楽しいことを認めなければなりません。残念ながら、この世界ではすべてが、ドッカーハブで既製のイメージを取得して使用するほどスムーズではありません。上記に加えて、サービスを開始する方法も選択する必要があります。たとえば、/ etc / init.d / uwsgi startなどは機能しなくなります。なんで?
uwsgiをdockerにプッシュしようとした私の小さな歴史を以下に示します。Dockerでuwsgiを実行する場合、正確に2つの問題があります。両方とも作成者の初期化スクリプトにあります。1)/etc/init.d/uwsgi startはエラーで失敗します。そのように、箱から出してすぐに。ソースに飛び込み、問題を探し始めます。このコマンドの実行にあります。 start-stop-daemon --start --quiet \ --pidfile "$PIDFILE" \ --exec "$DAEMON" \ --test > /dev/null \ && return 2
この段階までは、すべてが正常に機能し、プロセスが開始されます。最も重要なのは、initスクリプトが失敗した後でも動作を開始することです。問題は、Docker内で/ proc / {id} / exeを読み取る権利がないことです。その後、プロセスがないとみなされ、設定された動作に従って、リターンコード0が発行され、条件が正であり、つまり正しい部分&&が実行され、結果として、リターンコード2(リターン2)が元の関数に発行され、起動エラーが発生します(これは作成者によって定められました) )さまざまなソフトウェアを起動するときのこの横棒に関する議論は、14歳から続いています:github.com/moby/moby/issues/6800。回避策:このタスクのためにいくつかのソリューションを選択しましたが、それらのすべてが最後のものほど良くありません。a)--startasの--execキーの上にあるコードの/ usr / share / uwsgi / init / specific_daemonファイルを修正します。マナによると(いいえ、冗談です、マナによると同じように動作するため、フォーラムによると)startasスイッチを使用すると、/ proc / {id} / exeチェックはスキップされ、プロセスがそのpidで実行されているかどうかがチェックされます。 (https://chris-lamb.co.uk/posts/start-stop-daemon-exec-vs-startas)b)キー--cap-add = SYS_PTRACEでコンテナーを起動します。この場合、編集する必要はありません。c)author initスクリプトを使用しないでください。2)/etc/init.d/uwsgi startを実行した後、スクリプトは正常に動作して終了します。Dockerはその後自然に終了します(理由を覚えていますか?)。さらに、悪魔は起動スクリプトの作成者によってハードコードされており、設定で必要かどうかを指定することはできません。この時点で、私はまだびっくりして最初に起動スクリプトを修正しましたが、それが動作する方法ではないことに気づき、1つの起動ラインと1つの設定ファイルを実行するだけで、それをあきらめなければなりませんでした。その結果、何が行われたか:1)以下のパラメーター(およびデフォルト構成の残りのパラメーター)が構成に追加されました。 ... stats = 0.0.0.0:9090 socket = 0.0.0.0:3031 pidfile = /run/uwsgi/pid socket = /run/uwsgi/socket ...
2)Dockerfile内: ... COPY app.ini /etc/uwsgi/apps-enabled/app.ini RUN mkdir /run/uwsgi && chown www-data /run/uwsgi CMD ["/usr/bin/uwsgi", "--ini", "/etc/uwsgi/apps-enabled/app.ini"]
したがって、アイテム1とアイテム2の悪魔化キーからその左のチェックを取り除き、権利を設定し、自分でpid \ socketを配置します。さらに、通常のコミュニティ編集ドッカーはセキュリティについて特に考えていません。コンテナ内で更新することはできません!再起動するとすべてが失われます。したがって、この問題はドロドロの自己手紙または開発アプローチのいずれかによって解決されます。新しいソフトウェアバージョンが非常に頻繁に公開される場合、最新バージョンでコンテナを構築し、ソフトウェア全体を更新します。Dockerにはいくつかの問題があります。それらのいくつかは、抽象化の追加レベル-kubernetes \ docker swarmによって解決できます。また、kubernetesを介して、舵を取ることもできます。作品は間違いなくクールですが、それは別の話です;)...ふう。
久しぶりです。Dockerの使用方法のごく一部について説明しようとしました。コンテナ化の範囲ははるかに広いです。読んでくれてありがとう!コメントや提案を待っています。そして、私は毎日の管理情報を私の電報チャンネルに公開しています。