Shane BouldenによるFalconとRHSCLを使用したスケーラブルなREST APIの作成の翻訳。
この記事では、Python Falconフレームワークに基づいてREST APIを作成し、パフォーマンスをテストして、負荷に対応するようにスケーリングを試みます。
APIを実装してテストするには、次のコンポーネントが必要です。
ファルコンを選ぶ理由
FalconはWeb APIを構築するための最小限のWebフレームワークであり、Falconのサイトによると、Flaskよりも最大10倍高速です。 ファルコンは速い!
開始する
PostgreSQLが既にインストールされていることを前提としています(これがなければPostgreSQLはインストールされません)。
orgdbデータベースと
orguserユーザーを作成する必要があります。
このユーザーは、
pg_hba.confファイルのPostgreSQL設定で新しく作成されたデータベースへのパスワードアクセスを登録し、すべての権限を付与する必要があります。
データベース構成が完了しました。 Falconアプリケーションの作成に移りましょう。
APIの作成
このアプリケーションでは、Python3.5を使用します。
virtualenvを作成し、必要なライブラリをインストールします。
$ virtualenv ~/falconenv $ source ~/falconenv/bin/activate $ pip install peewee falcon gunicorn
ファイル「app.py」を作成します。
import falcon from models import * from playhouse.shortcuts import model_to_dict import json class UserIdResource(): def on_get(self, req, resp, user_id): try: user = OrgUser.get(OrgUser.id == user_id) resp.body = json.dumps(model_to_dict(user)) except OrgUser.DoesNotExist: resp.status = falcon.HTTP_404 class UserResource(): def on_get(self, req, resp): users = OrgUser.select().order_by(OrgUser.id) resp.body = json.dumps([model_to_dict(u) for u in users]) api = falcon.API() users = UserResource() users_id = UserIdResource() api.add_route('/users/', users) api.add_route('/users/{user_id}', users_id)
ファイル 'models.py'のモデルについて説明します。
from peewee import * import uuid psql_db = PostgresqlDatabase( 'orgdb', user='orguser', password='123456', host='127.0.0.1') def init_tables(): psql_db.create_tables([OrgUser], safe=True) def generate_users(num_users): for i in range(num_users): user_name = str(uuid.uuid4())[0:8] OrgUser(username=user_name).save() class BaseModel(Model): class Meta: database = psql_db class OrgUser(BaseModel): username = CharField(unique=True)
アプリケーション 'init_tables'および 'generate_users'を構成する2つのヘルパーメソッドを作成しました。 それらを実行してアプリケーションを初期化します。
$ python Python 3.5.1 (default, Sep 15 2016, 08:30:32) Type "help", "copyright", "credits" or "license" for more information. >>> from app import * >>> init_tables() >>> generate_users(20)
orgdbデータベースに
アクセスすると、作成されたユーザーが
orguserテーブルに
表示されます。
これで、APIをテストできます。
$ gunicorn app:api -b 0.0.0.0:8000 [2017-12-11 23:19:40 +1100] [23493] [INFO] Starting gunicorn 19.7.1 [2017-12-11 23:19:40 +1100] [23493] [INFO] Listening at: http://0.0.0.0:8000 (23493) [2017-12-11 23:19:40 +1100] [23493] [INFO] Using worker: sync [2017-12-11 23:19:40 +1100] [23496] [INFO] Booting worker with pid: 23496 $ curl http://localhost:8000/users [{"username": "e60202a4", "id": 1}, {"username": "e780bdd4", "id": 2}, {"username": "cb29132d", "id": 3}, {"username": "4016c71b", "id": 4}, {"username": "e0d5deba", "id": 5}, {"username": "e835ae28", "id": 6}, {"username": "952ba94f", "id": 7}, {"username": "8b03499e", "id": 8}, {"username": "b72a0e55", "id": 9}, {"username": "ad782bb8", "id": 10}, {"username": "ec832c5f", "id": 11}, {"username": "f59f2dec", "id": 12}, {"username": "82d7149d", "id": 13}, {"username": "870f486d", "id": 14}, {"username": "6cdb6651", "id": 15}, {"username": "45a09079", "id": 16}, {"username": "612397f6", "id": 17}, {"username": "901c2ab6", "id": 18}, {"username": "59d86f87", "id": 19}, {"username": "1bbbae00", "id": 20}]
テストAPI
Taurusを使用してAPIのパフォーマンスを評価しましょう。 可能であれば、別のマシンにTaurusをデプロイします。
仮想環境にTaurusをインストールします。
$ pip install bzt
これで、テスト用のスクリプトを作成できます。 次の内容
でbzt-config.ymlファイル
を作成します(正しいIPアドレスを指定することを忘れないでください)。
execution: concurrency: 100 hold-for: 2m30s ramp-up: 1m scenario: requests: - url: http://ip-addr:8000/users/ method: GET label: api timeout: 3s
このテストでは、100人のユーザーからのWebトラフィックを1分以内に数を増やしながらシミュレートし、負荷を2分30秒保持します。
1つのワーカーでAPIを実行します。
$ gunicorn --workers 1 app:api -b 0.0.0.0:8000
これでおうし座を実行できます。 最初の起動時に、必要な依存関係をダウンロードします。
$ bzt bzt-config.yml -report
依存関係をインストールすると、コンソールにテストの進行状況が表示されます。
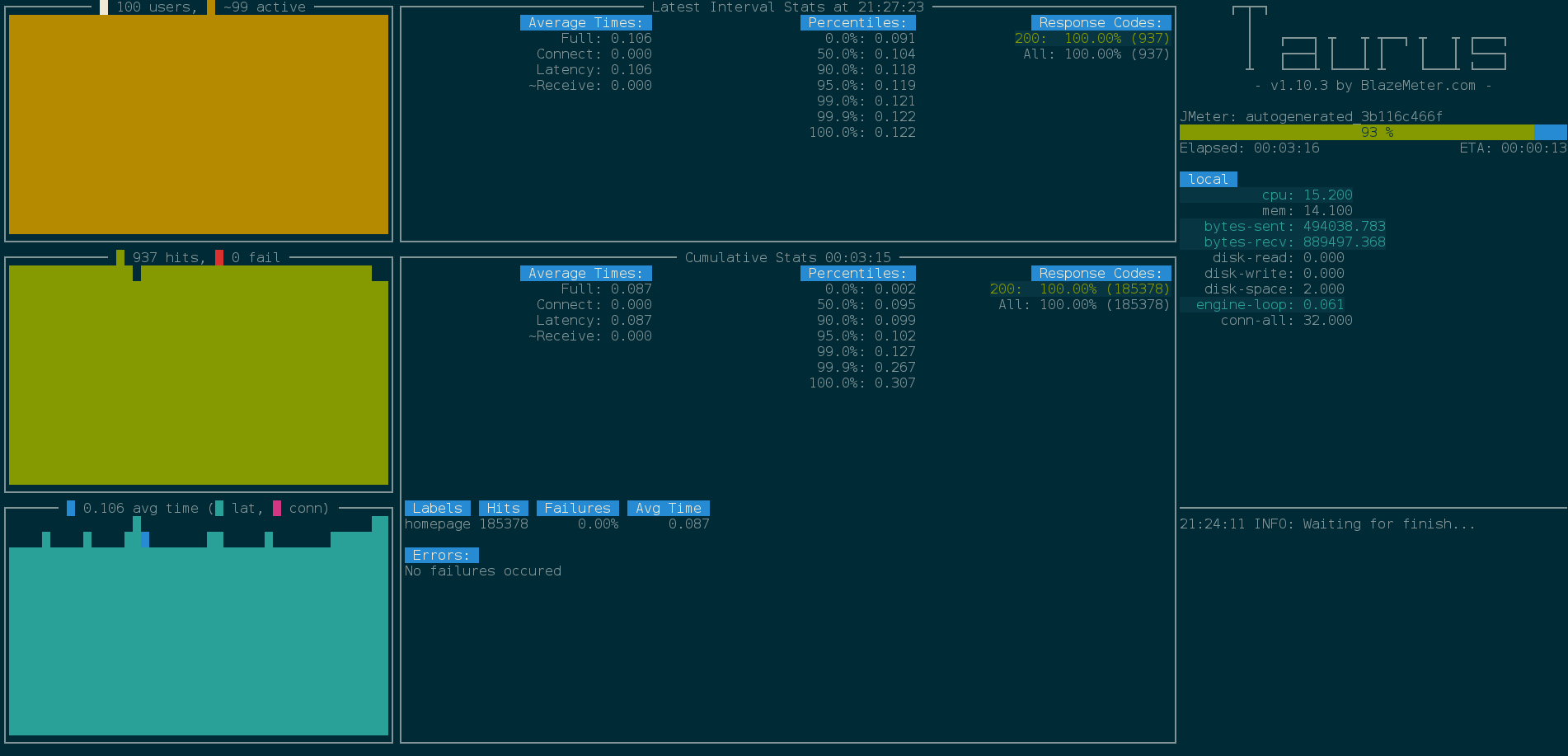 -reportオプション
-reportオプションを使用して結果をBlazeMeterにアップロードし、Webレポートを生成します。
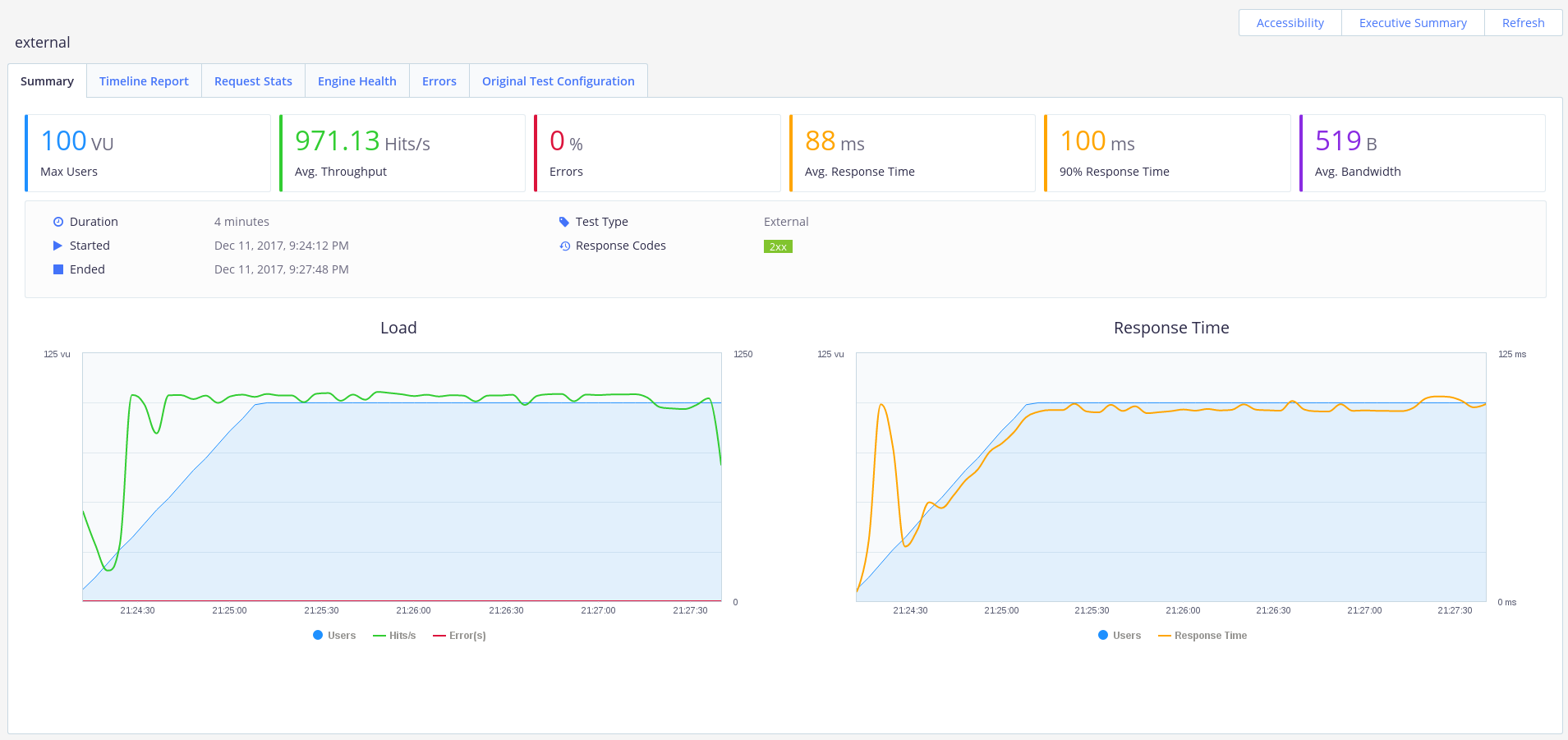
私たちのAPIは100人のユーザーで素晴らしい仕事をしています。 エラーがなく、平均応答時間は0.1秒で、1秒あたり約1000リクエストのスループットに達しました。
さて、500人のユーザーがいる場合はどうなりますか?
bzt-config.ymlファイルで
並行性パラメーターを500に変更し、Taurusを再度実行します。
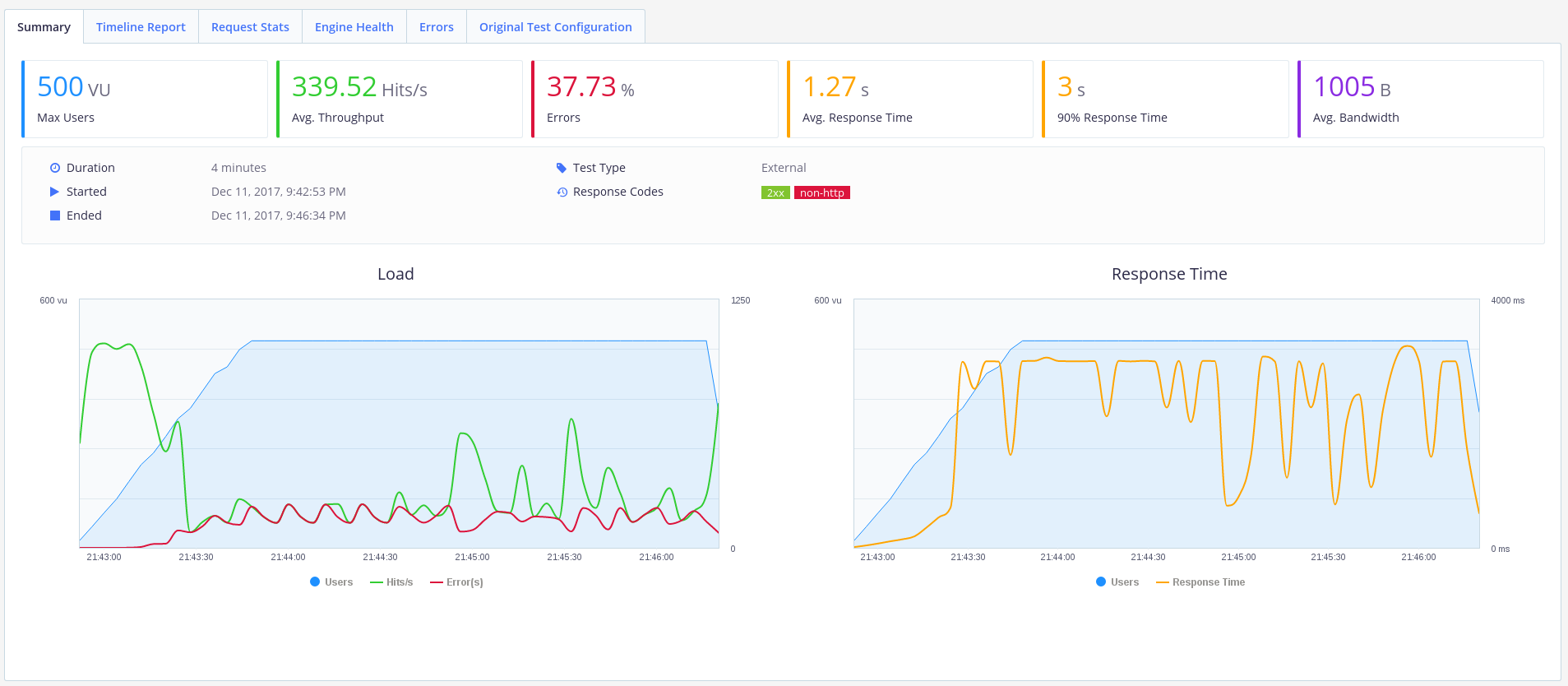
ふむ 私たちの孤独な労働者は負荷に対処しなかったようです。 エラーの40%はそうではありません。
労働者の数を増やしてみましょう。
gunicorn --workers 20 app:api -b 0.0.0.0:8000
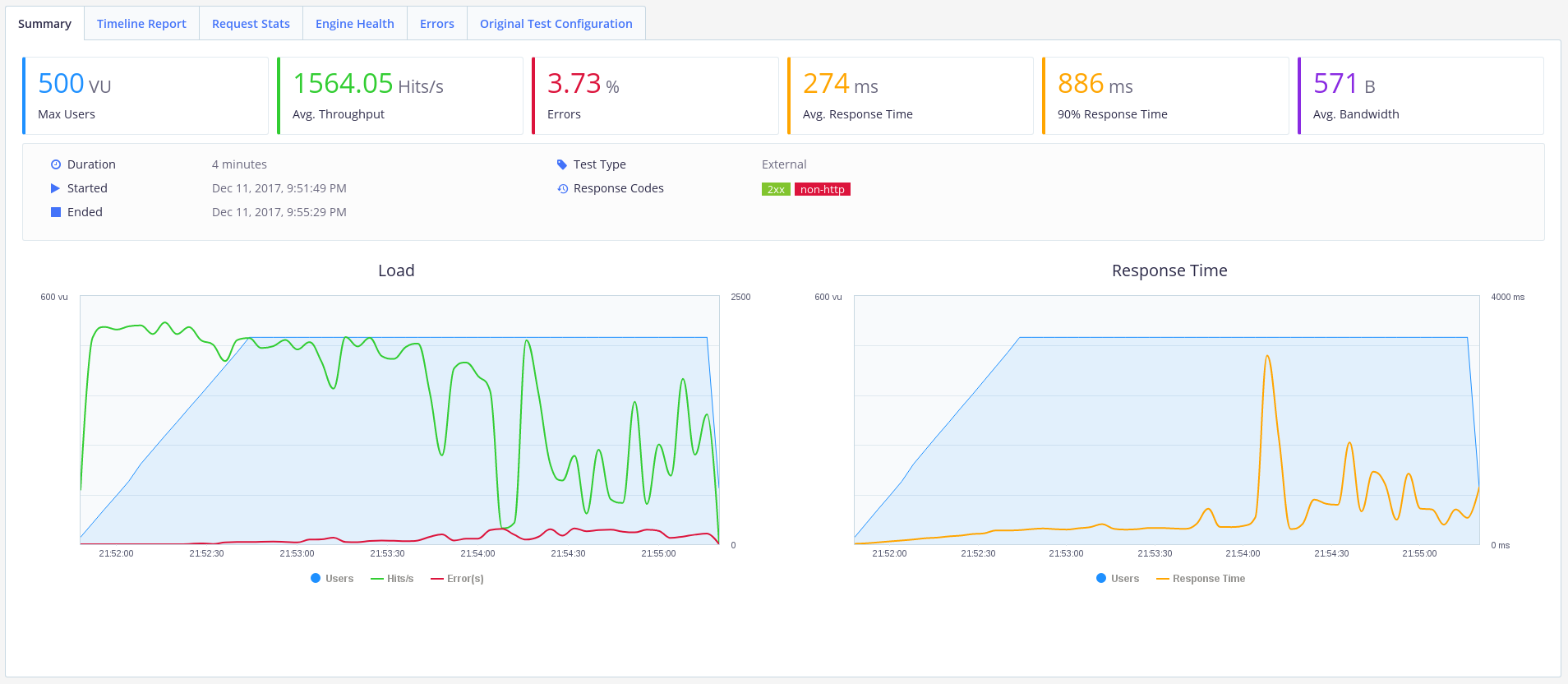
良く見えます。 エラーはまだありますが、スループットは1500リクエスト/秒まで増加し、平均応答時間は270ミリ秒まで減少しました。 このようなAPIはすでに使用できます。
さらなるパフォーマンスの最適化
PgTuneを使用して、PostgreSQLをハードウェア用に構成できます。
今日は以上です。 読んでくれてありがとう!