
gccgoでコンパイルしたときに最適な結果を表示するGoベンチマークとその理由は何ですか?
これらの質問への回答は控えめです。
はじめに
現時点では、Goプログラミング言語には最も成熟した実装が2つあります。
- gc(5g / 6g / 8g /など)-最初の「標準」実装。
- gccgoは、Go用GCCコンパイラのフロントエンドです。
問題ステートメント:gccgoのコンパイル時に実行する時間が短い標準Go配布キットからベンチマークを見つけます。 有意な偏差ごとに、観察された効果の原因を見つけます。
以前の同様の比較は2013年に実行されました。
Go 1.2rc5とgccgoのベンチマーク 。
結果の再現と検証に重要となる可能性のある技術的な詳細の欠落は、 githubリポジトリで確認できます 。
何をどのように測定したか
gccgoはgcリリースに遅れているため、Goバージョン1.8.1(GCC 7.2)が使用されました。
標準ライブラリパッケージの多くのBenchmark*関数、および$GOROOT/test/bench/go1すべてのテストは、起動と測定の対象となりました。
完全なリストはpackages.txtにリストされています 。
GCCの場合、フラグ「 -O3 -march=native 」が使用されました。
Intel CoreおよびIntel Xeonの結果が利用可能です。
両方のマシンで、 AVX2とFMAが利用できました。
テストマシンの詳細については、 / statsセクションをご覧ください。
ベンチスタットを使用して、統計的に有意な偏差を特定しました。
追加のチェックは、Goヒントバージョン(1.10)との比較でした。
Go 1.10の不一致のいくつかは修正されましたが、gcgoの利点の一部はgcの特別なアプローチにより永遠に残る場合があります。gcgoではコンパイル時間が重要な指標です。
全体像:すべての結果が1つの図に
一般的な図を作成する前に、次のアクションを実行しました。
- ゼロランタイムタイプの異常が削除されました(以下の説明)。
- 同じランタイム(
gccgo.time=gc.time )のベンチマークはgccgo.time=gc.time 。 - ランタイムの差は、対数を使用して平滑化されます。
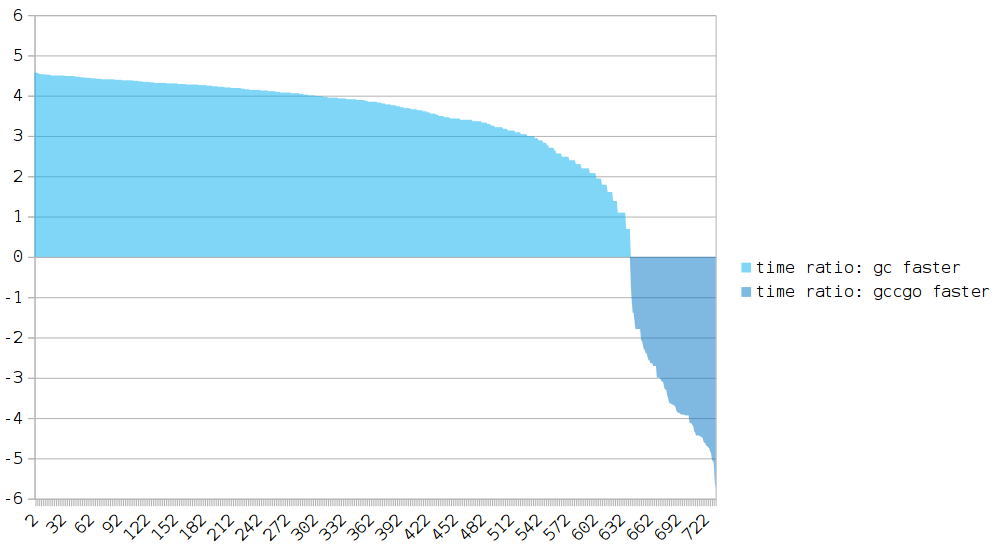
X軸:ベンチマーク。
Y軸:gccgoとgcの実行時比率。
Yの値が0より大きい場合、gccgoによってコンパイルされたプログラムの実行は遅くなります。
ほとんどのテストでは、gcの結果が大幅に向上しています。
gccgoに対する主な利点は、 エスケープ分析です。
gccgoを支持する逸脱もあります(118/808テスト)。
検索の絞り込み
いずれの場合もパフォーマンスのわずかな不一致は避けられないため、118件すべてを調査する代わりに、次のようにフィルタリングします。
- 最初に、デルタが10%未満のすべての結果を削除します。
- 残りのテストでは、Go 1.10と比較しましょう。
Go 1.10でgccgoに追いついた(または追い越した)ものを削除します。 - 残っているものはすべて、より詳細に検討されます。
最初の2つの段落は、あなたが見ることができる中間テーブルにつながりました
/人が読むことができるセクション。
=> ~62 . => ~39 1.10. => ~26 .
実際に...118のテストすべてが調査されました。
それらのいくつかは十分に安定して見えませんでした。
結果の一部については、明確な説明が見つかりませんでした。
このため、最終フォーマットでは、上記のフィルタリングを実行することが決定されました。
何度も参照されるリポジトリでは、「生の」データを見つけることができます。
誰もがより正確だと考える分析を行うことができます。
最も興味深い結果
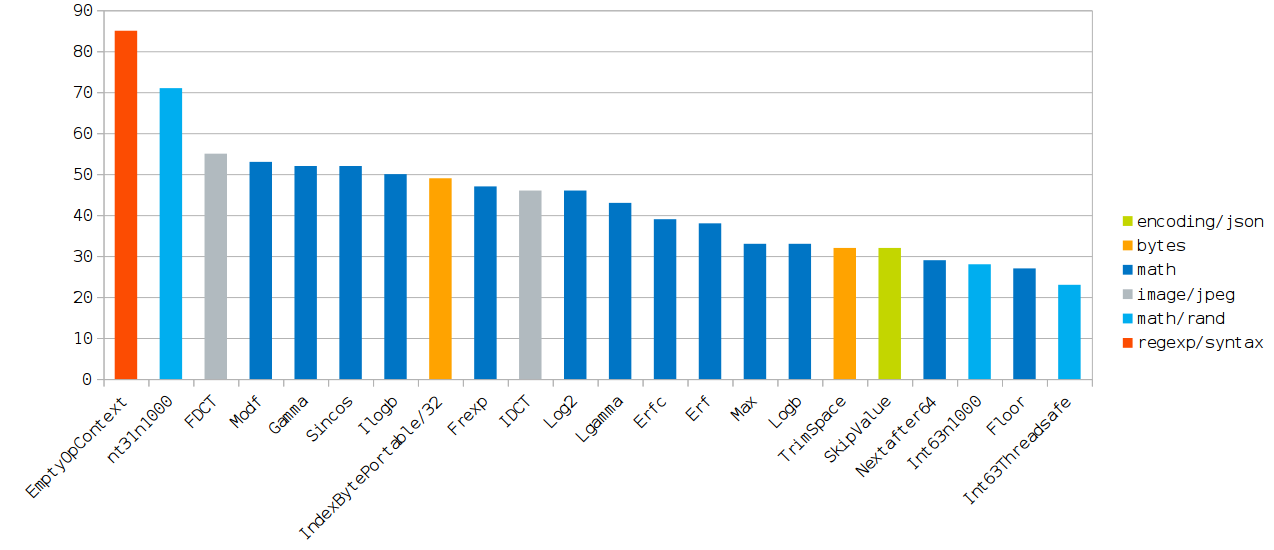
(チャートはクリック可能です。)
以下の表では、各テストには、観測された加速度がgcよりも高くなる最も重要な理由が1つ以上割り当てられています。
それらが除去されると、パフォーマンスはほぼ同じになります。
ほとんどすべての理由は、GCC最適化フラグの形式でまとめられています。
これらのフラグは、パフォーマンスギャップの削減につながる最適化フラグの最小セットを選択(オン/オフ)することで検出されました。
GCC最適化フラグの説明は、 ここにあります 。
| 役職 | 最も重要な理由 |
|---|
EmptyOpContext | 未使用の呼び出し結果[1] |
Int31n1000 | 未使用の呼び出し結果。 -finline-functions |
FDCT | -ftree-loop-vectorize |
Modf | -mavx |
Gamma | -mfma |
Sincos | -mfma |
Ilogb | -mfma |
IndexBytePortable/32 | 短いサイクルの減速[2] |
Frexp | 未使用の呼び出し結果。 -finline-functions |
IDCT | -ftree-loop-vectorize |
Log2 | -mfma ( -mfma依存) |
Lgamma | -mfma |
Erfc | -mfma |
Erf | -mfma |
Max | -mfma ; -finline-functions |
Logb | -mavx |
TrimSpace | -finline-functions |
SkipValue | -msse4.1 |
Nextafter64 | -finline-functions ; -ftree-loop-vectorize |
Int63n1000 | -finline-functions |
Floor | -mavx ( -mavx命令) |
Int63Threadsafe | -finline-functions |
[1]ベンチマークは関数のパフォーマンスをテストし、無視します
結果を返します。 これにより、オプティマイザーが呼び出しを削除する場合があります。
[2] n=32テストでは、同様のスローダウンが観察されます。
この結果を自由な文脈で再現することはできませんでした。
記事の残りの部分では、観察された結果につながった最も重要な最適化を分析します。 また、gccgoではまったく機能しないが、これまでのところ gcでは機能する、まったく正しいベンチマークではないというトピックについても触れています。
gccgo =インライン化の改善
デフォルトでは、Go 1.10は緑豊かな関数のみを埋め込むことができます。 リーフ関数は、他の関数への呼び出しを含まない関数です。 含まれる関数の「埋め込み予算」がその本体を埋め込むことによって超えられない場合、例外は他のリーフ関数です。
簡略化して、インライン関数の制限を次に示します。
「関数の価格」の計算は、最適化の前に行われます。
これにより、関数が埋め込まれているかどうかが重要な場合、コード構造を意味的に同等に変更する必要がありますが、最適化なしで低価格になるという事実につながります。
さらに、現在のモデルには欠点があります。インライン呼び出しをカスケードすると、関数の合計価格が高くなります。 これにより、埋め込みラッパー関数は、インラインの観点からそれほど自由ではありません。
特別なコンパイラフラグを使用して、関数が埋め込まれているかどうかを確認できます。 結論に近いgcflags="-l=4"の効果についてgcflags="-l=4" 。
gccgo =より良い定数折りたたみ
Goで同様のベンチマークをどのくらいの頻度で見ましたか?
func foo(i int) int { } func BenchmarkFoo(b *testing.B) { for i := 0; i < bN; i++ { foo(50)
foo(50)呼び出す行のコメントに注意してください。
オプティマイザーは、呼び出し自体とBenchmarkFoo内のサイクル全体の両方を削除できます。
gccgoの場合、これは0ナノ秒を実行するベンチマークを取得する確実な方法です。
// YCbCrToRGB/(0|128|255) YCbCrToRGB/*. // gc.time gccgo.time delta YCbCrToRGB/* 12.1ns ± 0% 0.0ns -100.00% (p=0.008 n=5+5) RGBToYCbCr/* 12.8ns ± 0% 0.0ns -100.00% (p=0.008 n=5+5) YCbCrToRGBA/* 13.8ns ± 0% 0.7ns ± 0% -94.78% (p=0.000 n=5+4) NYCbCrAToRGBA/* 18.5ns ± 0% 1.0ns ± 6% -94.72% (p=0.008 n=5+5)
以下は、かなり一般的なイディオムです。
var sink int func BenchmarkBar(b *testing.B) { for i := 0; i < bN; i++ { sink = bar(50) } }
彼女には2つの問題があります。
- 関数の定数引数。
- グローバル(エクスポートされていない)変数を割り当てると、不必要な最適化が魔法のようにキャンセルされるという仮定。
Go標準ライブラリのベンチマークを含め、これらの問題は両方とも発生します。
gccgoは、グローバル変数の値を埋め込むことができますが、プログラム内では変更されません。 gc(少なくとも今のところ)では、定数とローカルデータのみがこの最適化の対象です。
sink値がどこでも使用されていない場合、この変数が変更されるかどうかは関係ありません。 エクスポートされていない未使用の関数と同様に、gccgoは誰も「読み取らない」変数を削除します。
関数呼び出しが組み込まれている場合(これはgccgoでより頻繁に発生します)、コンパイル段階でループ本体(ループ自体と一緒になる可能性があります)が完全に計算されるリスクがあります。
実際のアプリケーションでは、コンパイル段階でサイクル全体を「ロール」することはできませんが、一部のGoベンチマークはこの最適化の対象となります。
それらでは、100%の魔法の加速が得られます。
gccgo =より良いマシン依存の最適化
gcコンパイラーは、 SSE2以降の拡張機能から命令を生成しません。
これにより、x64バイナリの移植性が向上しますが、最適性が低下する可能性があります。
-march=nativeようなフラグのおかげで、gccgoは生成できます
アプリケーションを実行する予定の特定のマシンに対してより効果的なコード。
また、AVX拡張機能にアクセスしないとその有効性が非常に制限されるため、ベクトル化をマシン依存の最適化に起因させることもできます。
現在のバージョンのgcでは、複数の動きを1つに結合することを考慮しない限り、ベクトル化自体はありません(SSEを使用して最大16バイト)。
Goには従来の組み込み関数がないため、最大の加速を実現するにはアセンブラーの実装を記述する必要があります。
Assembler Go 1.10は、最新のx86_64で使用可能なほとんどの命令をサポートしています。
Go 1.11では、AVX512( golang#22779-AVX512 design )を使用できる可能性があります。
アセンブラー関数は組み込みではないため、アセンブリー言語でアルゴリズム全体を実装しない限り、パフォーマンスが低下する場合があります。
|
gccgo =より良い呼び出し規約
GOARCH=386とGOARCH=amd64両方でGOARCH=amd64 gcはスタックを使用して引数を渡し、関数の結果を返します。 64ビットモードでは、より多くのレジスタを使用できるため、これらの目的でスタックを使用することは最適ではありません。
しばらくの間、 レジスタベースの呼び出し規約の議論がありました。
この段階で潜在的なパフォーマンスの向上を判断するのは簡単ではありません。オプティマイザはreg->reg動作にのみ有益な変換を実行しないためreg->reg 。 現在、 mem->reg->memという形式の動きは、はるかに特徴的です。
上記の説明で説明した5〜10%は、個々の機能で15〜30%になる可能性があります。
新しい呼び出し規約の主な欠点の1つは、Goの内部にさえ存在するすべての既存のアセンブラコードの無効化です。
|
ミッドスタックインライン化を有効にする
関数の埋め込みに優れた機能を使用しているためにgccgoが最良の結果を示したベンチマークでの-gcflags="-l=4"効果を-gcflags="-l=4"みましょう。
比率はgccgo.time/gc.timeとして評価されます。
| 役職 | 比 | 後の比率 |
|---|
math/rand/Int31n1000 | 0.77 | 1.00 (+0.23) |
math/rand/Int63n1000 | 0.82 | 0.93 (+0.11) |
math/rand/Int63Threadsafe | 0.80 | 1.00 (+0.20) |
math/Frexp | 0.84 | 0.84(=) |
math/Max | 0.73 | 0.73(=) |
math/Nextafter64 | 0.61 | 0.81 (+0.20) |
bytes/TrimSpace | 0.70 | 0.80 (+0.10) |
( 注 :これらのテストは、別の実験として、異なる構成で実行されました。)
Go 1.9 / 1.10での-l=4使用に関するRuss Coxの意見:
-l = 4は明示的にテストされておらず、実稼働での使用はサポートされていません。
そのようにして、壊れるプログラムを取得した場合、両方の部分を保持することになります。
投稿リンク
おわりに
gccgoの適切なパフォーマンス測定は、gcgoよりも困難です。
Go(類似の「問題」)よりもC ++のベンチマークを実装する可能性が高いように感じます。
特定のタスクについては、gccgoによってパフォーマンスがいくらか向上する場合があります。
たとえば、正しいGCC最適化フラグをオンにしたときの数学的計算は、測定可能な加速を受け取りますが、アプリケーションの残りの部分はヒットします。
最も一般的なGoプログラムの機能を考えると、アプリケーションのより重要な部分の速度が低下する可能性が最も高くなります(単純なコマンドラインユーティリティは例外になる可能性があります)。
すべてのパフォーマンス測定と同様に、この調査は、比較に使用された特定のバージョンのコンテキストで評価する必要があります。
gccgoの重要な前進は、定性的なエスケープ分析です。
次の革命のgcについては、上記の呼び出しの新しい規則と関数の完全な統合に名前を付けることができます。