Apache Igniteでは、永続ストレージ用の名前付きデータキャッシュを定義し、そこにデータをロードしてから、それらを使用してさまざまな操作を実行できます。
Mapの場合と同様に、get / put操作を実行できます。たとえば、javaでは、これらの操作はリードスルーおよびリードスルーと呼ばれます。 つまり 取得操作中にキャッシュがロードされた後、オブジェクトはデータベースからではなくデータベースから取得され、書き込まれるとキャッシュ内で変更され、データウェアハウスに書き込まれます。 オブジェクトをキャプチャしようとしたときに、オブジェクトがキャッシュにない場合は、最初にオブジェクトに書き込まれます。 読み取り操作が既にキャッシュメモリから行われ、非常に高速であることは明らかです。 これはすべて、get / put操作に関連しています。 他の検索操作、たとえば、キーではなくオブジェクトを検索するには、クエリ、キャッシュ内のデータをより速く検索する方法、トランザクションの操作などがあります。
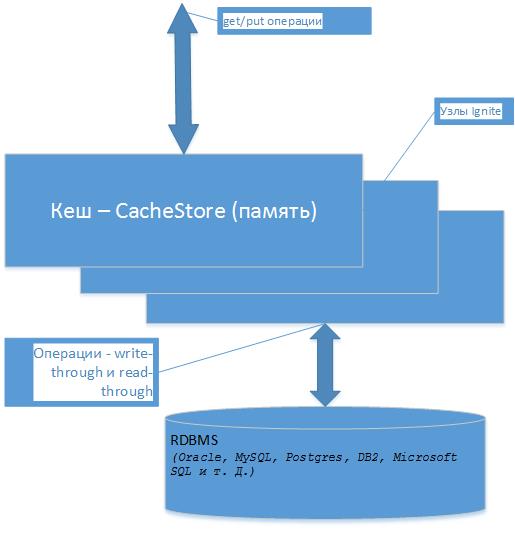
キャッシュでは、データはキーによって書き込まれます。このキーは、たとえばデータベーステーブルの主キーにすることができます。 私の例では、Oracle XEデータベースを使用しました。デフォルトではIgniteがH2データベースを提供しますが、実際にはまだ他のデータベースを処理する必要があると思います。 したがって、データベースエンティティ(テーブル)を取得し、Javaでそのクラスを準備します(ビュー、関数など、すべてのセットをエンティティのデータソースとして使用できます。完全に制御できます)。
キャッシュの要素としてのKLADRテーブルpublic class Kladr implements Serializable { @QuerySqlField(index = true) public Long id; @QuerySqlField public String code; @QuerySqlField public String name; @QuerySqlField public Timestamp upd_date; public Kladr(Long id, String code, String name, Timestamp upd_date) { this.code = code; this.name = name; this.id = id; this.upd_date = upd_date; } public Kladr() {
注釈には、クエリ操作に参加するフィールドとインデックスフィールドが表示されます。
ここで、クラス-CacheStoreAdapterから継承し、そのメインメソッドをオーバーライドする必要があります。
public class CacheKladrStore extends CacheStoreAdapter<Long, Kladr> {
IDがキーになり、Kladrクラス(<Long、Kladr>)がコレクションの要素になることがわかります。
こんな感じ
CacheKladrStore public class CacheKladrStore extends CacheStoreAdapter<Long, Kladr> {
最初のテスト
準備を始める public class CacheKladrStoreExample { private static final String CACHE_NAME = CacheKladrStoreExample.class.getSimpleName(); private static final int ENTRY_COUNT = 50_000; public static void main(String[] args) throws IgniteException {
50,000個のオブジェクトを一括してキャッシュにロードします(上記のCacheKladrStoreのloadCacheを参照)
try (IgniteCache<Long, Kladr> cache = ignite.getOrCreateCache(cacheCfg)) {
loadCache private static void loadCache(IgniteCache<Long, Kladr> cache) { long start = System.currentTimeMillis();
50,000千のオブジェクトのダウンロードには数秒かかります。 私たちの管理下にあるものはどれだけ便利で、どれだけ出荷できますか。
ダウンロードしたIDのキャッシュからデータを読み取ります
getFromCache private static void getFromCache(IgniteCache<Long, Kladr> cache, Long i1, Long i2) { long millis = System.currentTimeMillis(); for (long i = i1; i < i2; i++) { Kladr kladr = cache.get(i); kladr.upd_date = new Timestamp(new java.util.Date().getTime()); } System.out.println("getFromCache otal get values msec.:" + (System.currentTimeMillis() - millis)); }
20,000千のオブジェクトを読み取り、すべてがここで問題なく、すべてがキャッシュから取得され、データベースへの呼び出しはありません。
ただし、キャッシュにない読み取りオブジェクトを呼び出す場合
その後、取得のたびに呼び出されます(CacheKladrStoreを参照)
オブジェクトはデータベースから読み取られてキャッシュに入れられ、操作には1,000個のオブジェクトが必要でした。すでに数秒でした。 そして、すでに繰り返される読み取りでは、テストの前と同じようにキャッシュから取得されます(実際の読み取りスルー)。
トランザクション操作
executeTransaction private static void executeTransaction(IgniteCache<Long, Kladr> cache) { final Long id1 = 100_001L; final Long id2 = 100_009L; try (Transaction tx = Ignition.ignite().transactions().txStart()) {
はい、そうであるように(またはほぼ)、トランザクションを開き、さまざまなオブジェクトを変更します。成功した場合のみ、commit()によってデータベースに書き込まれます。
キャッシュに入れられた変更されたオブジェクトごとに(put)が呼び出されます(CacheKladrStoreを参照)
つまり コミットを呼び出した後、書き込みが呼び出されます。
コンソールへの出力は次のとおりです。

それらはキャッシュ(以前はByzから)から読み取られ、変更されてキャッシュに置かれ、コミットトランザクションの後、データはデータベースとキャッシュにあることがわかりました。
しかし、キャッシュの変更後、データベースに書き込む前に-例外はどうでしょうか?
System.out.println("Read value after id2: " + val); try { throw new RuntimeException("RuntimeException"); tx.commit(); } catch (Exception e) { e.printStackTrace(); } } System.out.println("Read value id1 after commit: " + cache.get(id1));
。 コミットは行われませんが、データはキャッシュにロールバックされます-すべては問題ありません!

例外の後、変更前の前の値が表示されます。
これらはget / putの形式の操作でしたが、アプリケーションロジックはこれに限定されず、コレクションと単一オブジェクトを受け取るために、さまざまな基準に従ってさまざまな検索が必要です。
クエリはキャッシュ内でこれを使用できます。 リクエストは、
すでにキャッシュにあるデータでのみ機能します。
リクエストを介してキャッシュを操作する例:
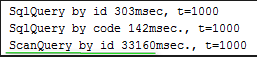
SqlQuery sql = new SqlQuery(Kladr.class, "id = ?"); long start = System.currentTimeMillis(); int t = 0; for (int i = 100_000; i < 101_000; i++) { try (QueryCursor<Cache.Entry<Long, Kladr>> cursor = cache.query(sql.setArgs(i))) { for (Cache.Entry<Long, Kladr> e : cursor) { e.getValue().upd_date = new Timestamp(new java.util.Date().getTime()); t++; } } } System.out.println("SqlQuery by id " + (System.currentTimeMillis() - start) + "msec, t=" + t);
1000個のオブジェクトの読み取りには300ミリ秒かかりました。 しかし、インデックスとして注釈が付けられたフィールド読み取りがありました。
@QuerySqlField(index = true) public Long id;
繰り返しになりますが、検索では他のフィールドも必要です。インデックスがない「コード」フィールドをチェックしてみましょう。結果は悲しいです。データベース(実際にはもっと悪い)フルスキャンのように、検索は既に30回1000回実行されています。
検索フィールド「コード」 String[] codes = new String[]{"4401300010999", "4401300011700"}; sql = new SqlQuery(Kladr.class, "code = ?"); start = System.currentTimeMillis(); t = 0; for (int i = 100_000; i < 101_000; i++) { try (QueryCursor<Cache.Entry<Long, Kladr>> cursor = cache.query(sql.setArgs(codes[i % 2]))) { for (Cache.Entry<Long, Kladr> e : cursor) { e.getValue().upd_date = new Timestamp(new java.util.Date().getTime()); t++; } } } System.out.println("SqlQuery by code " + (System.currentTimeMillis() - start) + "msec., t=" +t);

私は比較したくありませんでしたが、このケースはすべての値、キャッシュ内のデータ(メモリ内)で並べ替えて、私にとって興味深いものになりました。条件は非常に魅力的で、データベース(Oracle XE)はこの並べ替えをどのように行うか 結果は次のとおりです。データベースでの同じ検索では6秒かかりました。
declare TYPE code_type IS TABLE OF VARCHAR2(30); v_codes code_type; v_code varchar2(30); v_t number :=0; v_ts timestamp; v_id number; begin v_codes := code_type('4401300010999', '4401300011700'); v_ts := systimestamp; for i in 1..1000 loop v_code := v_codes((i mod 2)+1); select id into v_id from kladr k where k.code = v_code; v_t := v_t + 1; end loop; dbms_output.put_line('query by code ' || to_char(systimestamp - v_ts) || ', t=' || v_t); end;

どうやら、データベースはキャッシュ、ストレージ、検索などをより知的に処理しているようです。 フィールドにインデックスを追加すると、データベース内の検索は28ミリ秒になります。 Igniteでは、別のフィールドにインデックスを追加して、検索を開始することもできます!
@QuerySqlField(index = true) public String code;

160msに達しました。
確かに、データベースでは、インデックスを使用すると桁違いに速くなりました。 しかし、これは必ずしも主なことではなく
、コンピューティングシステム
のスケーリングの問題 (前述)も非常に重要です。
ScanQueryなど、他のタイプのキャッシュリクエストがありますが、これと同じ例があります。
スキャンクエリ for (int i = 100_000; i < 101_000; i++) { int id = i; try (QueryCursor<Cache.Entry<Long, Kladr>> cursor = cache.query(new ScanQuery<Long, Kladr>((k, v) -> v.id == id))) { for (Cache.Entry<Long, Kladr> e : cursor) e.getValue().upd_date = new Timestamp(new java.util.Date().getTime()); t++; } } System.out.println("ScanQuery by id " + (System.currentTimeMillis() - start) + "msec., t=" +t);
彼の結果は次のとおりです。
 素材
素材