 各クラウドTPUデバイスは、4つの「TPUv2チップ」で構成されています。 チップには16 GBのメモリと2つのコアがあり、各コアにはマトリックス乗算用の2つのユニットがあります。 合わせて、2つのコアは45 TFLOPSを出力し、合計180 TFLOPSとTPUあたり64 GBのメモリ
各クラウドTPUデバイスは、4つの「TPUv2チップ」で構成されています。 チップには16 GBのメモリと2つのコアがあり、各コアにはマトリックス乗算用の2つのユニットがあります。 合わせて、2つのコアは45 TFLOPSを出力し、合計180 TFLOPSとTPUあたり64 GBのメモリ私たちのほとんどは、Nvidia GPUで詳細なトレーニングを提供しています。 現在、代替手段はほとんどありません。 Google Tensor Processing Unit(TPU)は、深層学習のために特別に設計されたチップであり、違いを生むはずです。
2週間前の最初の発表から9か月後、Googleはようやく
TPUv2を
リリースし、Google Cloudプラットフォームの最初のベータテスターが利用できるようにしました。
RiseMLで私たちはこの機会を利用して、いくつかの簡単なベンチマークを追い出しました。 経験と予備的な結果を共有したいと思います。
長い間、私たちはディープラーニング用機器の市場での競争の出現を待っていました。 Nvidiaの独占を破り、将来のディープラーニングインフラストラクチャがどのようになるかを判断する必要があります。
TPUはまだ初期のベータ版であり、Googleが明確かつ普遍的に私たちにそれを思い出させるので、議論された評価の一部は将来変更される可能性があることに留意してください。
Google CloudのTPU
TPUv1チップの第1世代はデータ出力の高速化に焦点を当てていましたが、現在の第2世代は主に学習の高速化に焦点を当てています。 TPUv2の中心には、行列の乗算を担当する
シストリックアレイがあり、これはディープラーニングで積極的に使用されています。 Jeff Deanの
スライドによると、各Cloud TPUデバイスは4つの「TPUv2チップ」で構成されています。 チップには16 GBのメモリと2つのコアがあり、各コアにはマトリックス乗算用の2つのユニットがあります。 2つのコアを合わせて45 TFLOPSを生成し、合計180 TFLOPSとTPUあたり64 GBのメモリを提供します。 比較のために、現在の世代のNvidia V100には125 TFLOPSと16 GBのメモリしかない。
Google Cloudプラットフォームでテンソルプロセッサを使用するには、Cloud TPUを実行する必要があります(以前に割り当てを受け取っていました)。 Cloud TPUを特定の仮想マシンインスタンスに割り当てる必要はありません(可能性もありません)。 代わりに、インスタンスからのTPUアクセスはネットワーク経由です。 各クラウドTPUには名前とIPアドレスが割り当てられます。これらはTensorFlowコードで指定する必要があります。
 新しいクラウドTPUを作成します。 IPアドレスがあることに注意してください。 GIFアニメーション
新しいクラウドTPUを作成します。 IPアドレスがあることに注意してください。 GIFアニメーションTPUはTensorFlowバージョン1.6でのみサポートされており、リリース候補ステータスのままです。 さらに、必要なすべてのコードがTensorFlowに含まれているため、VMにドライバーは必要ありません。 TPUで実行するためのコードは、TensorFlowの一部でもある
XLA JITコンパイラーによって最適化およびコンパイルされます。
TPUを効果的に使用するには、コードは
Estimatorクラスの高レベルの抽象化に基づいている必要があります。 次に、
TPUEstimatorクラスに
進みます。TPUEstimatorクラスは、TPUを効果的に使用するために必要な多くのタスクを実行します。 たとえば、TPUのデータキューを構成し、コア間の計算を並列化します。 TPUEstimatorを使用せずに実行する方法は間違いなくありますが、そのような例やドキュメントはまだわかっていません。
すべてが設定されたら、通常どおりTensorFlowコードを実行します。 TPUはブート時に検出され、計算スケジュールがコンパイルされて転送されます。 興味深いことに、TPUはクラウドストレージコントロールポイントと概要(イベント概要)を直接読み書きすることもできます。 これを行うには、クラウドTPUアカウントでクラウドストレージへの記録を有効にする必要があります。
ベンチマーク
もちろん、最も興味深いのは、テンソルプロセッサの実際のパフォーマンスです。 GitHubのTensorFlowリポジトリには、
実証済みで最適化されたTPUモデルのスイートがあります 。 以下は
ResNetと
Inceptionの実験結果です。 また、TPU用に最適化されていないモデルがどのように計算されるかを確認したいので、
モデルを適応させて、長期短期記憶(LSTM)のアーキテクチャ上の
テキストをTPUで実行
するよう分類しました。 実際、Googleはより大きなモデルの使用を推奨しています(
「TPUを使用するタイミング」を参照)。 モデルが小さいので、TPUが利点をもたらすかどうかを確認するのは特に興味深いです。
すべてのモデルについて、1つのCloud TPUと1つのNvidia P100およびV100 GPUの学習速度を比較しました。 完全な比較には、帯域幅だけでなく、モデルの最終的な品質と収束の比較を含める必要があることに注意してください。 私たちの実験は単なる表面的な最初のベンチマークであり、将来のために詳細な分析を残します。
TPUおよびP100のテストは、n1-standard-16 Google Cloudプラットフォーム(16個のIntel Haswell仮想CPU、60 GBメモリ)のインスタンスで実行されました。 V100
GPUでは、AWS上のp3.2xlargeインスタンス
が使用されました (8つの仮想CPU、60 GBのメモリ)。 Ubuntu 16.04の下のすべてのシステム。 TPUの場合、TensorFlow 1.6.0-rc1はPyPiリポジトリからインストールされました。 GPUのテストは、CUDA 9.0およびcuDNN 7.0のサポートを含む、TensorFlow 1.5イメージ(
tensorflow:1.5.0-gpu-py3 )を含む
nvidia- dockerコンテナーから実行されました。
TPU最適化モデル
まず、公式にTPU用に最適化されたモデルのパフォーマンスを見てみましょう。 以下に示すパフォーマンスは、1秒間に処理される画像の数です。
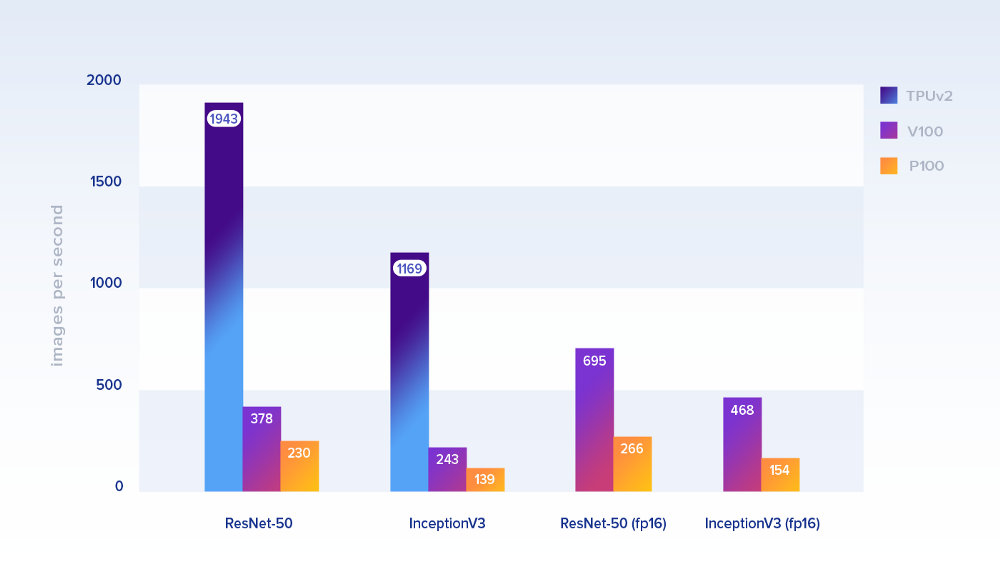 パッケージサイズ:TPUでは1024、GPUでは128。 後者の場合、彼らはTensorFlow ベンチマークリポジトリから実装を取得しました。 トレーニングデータとして、クラウドストレージ(TPUの場合)およびローカルドライブ(GPUの場合)でGoogleのImageNetデータセットをシミュレートします
パッケージサイズ:TPUでは1024、GPUでは128。 後者の場合、彼らはTensorFlow ベンチマークリポジトリから実装を取得しました。 トレーニングデータとして、クラウドストレージ(TPUの場合)およびローカルドライブ(GPUの場合)でGoogleのImageNetデータセットをシミュレートしますResNet-50では、1つのCloud TPUテンソルプロセッサ(8コアと64 GBのRAM)が、P100の約
8.4倍 、V100の約5.1倍の速度でした。 InceptionV3の場合、パフォーマンスの違いはほぼ同じです(それぞれ〜8.4および〜4.8)。 精度が低い(fp16)計算では、V100は非常に高速です。

速度に加えて、価格を考慮する必要があることは明らかです。 この表は、毎秒の請求ごとに価格で正規化されたパフォーマンスを示しています。 TPUは依然として明確に勝ちます。
カスタムモデルLSTM
カスタムモデルは、1024個の非表示ユニットを持つテキストを分類するための双方向LSTMです。 LSTMは最新のニューラルネットワークの主要な構成要素であるため、これは公式のマシンビジョンモデルに追加するのに適しています。
元のコードは既にEstimatorフレームワークを使用していたため、TPUEstimatorに簡単に適合させることができます。 大きな注意点が1つあります。TPUでは、
モデルの収束を達成できませんでしたが、同じモデル(パケットサイズなど)がGPUで正常に機能しました。 これは何らかの修正されたバグによるものだと思います-私たちのコード(見つけた場合はお知らせください!)またはTensorFlowのいずれかです。
TPUはLSTMモデル(21402サンプル/秒)のパフォーマンスをさらに大幅に向上させることが判明しました:P100(1658サンプル/秒)の
約12.9倍 、V100(2778サンプル)の約7.7倍の速度/ s)! モデルが比較的小さく、最適化されていないことを考えると、これは非常に有望な結果です。 ただし、バグが修正されるまで、これらの結果は暫定的なものとみなされます。
おわりに
テストされたモデルでは、最新世代のGPUと比較して、パフォーマンスとコスト削減の両方の面でTPUが非常に優れたパフォーマンスを発揮しました。 これは
以前の推定と矛盾します。
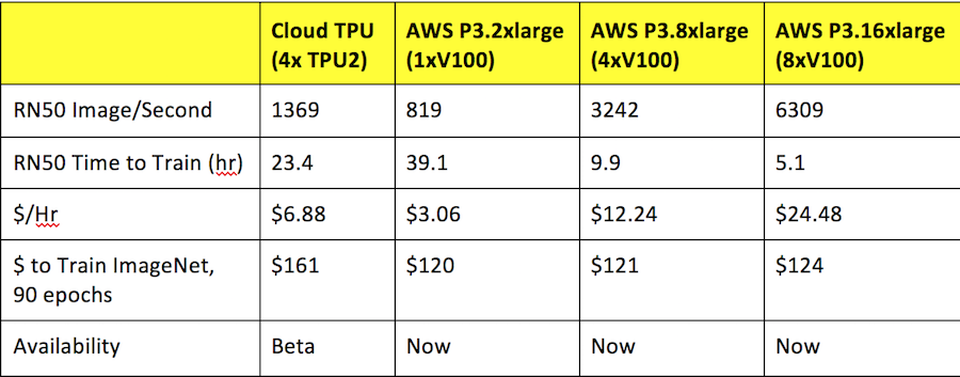 以前のベンチマークの結果。 ソース: フォーブス
以前のベンチマークの結果。 ソース: フォーブスGoogle
は TPUを大規模モデルのスケーリングに最適なソリューションとして推奨していますが、小規模モデルに関する予備的な結果は非常に有望です。 一般に、TPUの使用とTensorFlowコードの適応の経験は、ベータ版にはすでに適しています。
TPUがより多くの視聴者に利用可能になると、TPUはNvidia GPUの真の代替品になると考えています。