ゲーム分析に適した市場には、Mixpanel、Localytics、Flurry、devtodev、deltaDNA、GameAnalyticsなどの多くの製品があります。 それでも、多くのゲームスタジオが決定を下しています。
私は多くのゲーム会社と仕事をしました。 プロジェクトが成長するにつれて、スタジオでは高度な分析シナリオが必要になることに気付きました。 いくつかのゲーム会社がこのアプローチに興味を持つようになった後、一連の2つの記事でそれを文書化することが決定されました。
「なぜ?」、「方法」の質問への回答 そして「いくらですか?」 カットの下にあります。
なんで?
ユニバーサルハーベスターは、簡単な作業に適しています。 しかし、もっと複雑なことをする必要がある場合、その機能は十分ではありません。 たとえば、前述の分析システムにはさまざまな程度の機能制限があります。
- イベント内のパラメーターの数
- ファンネルイベントのパラメーターの数
- データリフレッシュレート
- データ量ごと
- データ計算の期間
- ファンネル条件の数について
- および同じ種類の他の制限
既製のソリューションでは、生データにアクセスできません。 たとえば、より詳細な調査を実施する必要がある場合。 機械学習と予測分析を忘れてはなりません。 大量の分析データを使用して、ユーザーの行動の予測、購入の推奨、個人的なオファーなどの機械学習シナリオを試すことができます。
多くの場合、ゲームスタジオは、既存のソリューションに加えて、置き換えるのではなく独自のソリューションを構築します。
それでは、分析システムはどのように見えますか?
分析を構築する一般的なアプローチはラムダアーキテクチャであり 、分析はホットパスとコールドパスに分けられます。 ホットな方法は、最小限の遅延で処理する必要があるデータです(オンラインプレイヤーの数、支払いなど)。
コールドパスの後には、定期的に処理されるデータ(日/月/年のレポート)、および長期保存用の生データが続きます。

たとえば、これはマーケティングキャンペーンを開始するときに役立ちます。 キャンペーンから何人のユーザーが来たのか、何人のユーザーが支払いをしたのかを確認すると便利です。 これにより、非効率的な広告チャネルをできるだけ早く無効にすることができます。 ゲームのマーケティング予算を考えると、これは多くのお金を節約できます。
定期的なスライス、カスタムレポートなど、その他はすべてコールドパスに関連しています。
ユニバーサルシステムの柔軟性の欠如は、独自のソリューションの開発を促しています。 ゲームが発展するにつれて、ユーザーの行動を詳細に分析する必要性が高まります。 データに基づいてSQLクエリを構築する機能と比較できるユニバーサル分析システムはありません。
したがって、スタジオはソリューションを開発しています。 さらに、特定のプロジェクト向けに解決策が強化されることがよくあります。
システムを開発したスタジオは、システムを常にサポートおよび最適化する必要があることに不満を感じていました。 実際、多くのプロジェクトがある場合、またはそれらが非常に大きい場合、収集されるデータの量は非常に急速に増加しています。 システムの速度が低下し始めており、大幅な最適化の貢献が必要です。
どうやって?
技術的リスク
分析システムの開発は簡単な作業ではありません。
以下は、私が注目したスタジオの要件の例です。
- 大容量データストレージ:> 3Tb
- サービスの高負荷:1秒あたり1000イベントから
- クエリ言語のサポート(できればSQL)
- 許容可能なリクエスト処理速度の確保:<10分
- インフラストラクチャの復元力の確保
- データ視覚化ツールの提供
- 定期的なレポートの集約
これは完全なリストではありません。
決定方法を知りたいと思ったとき、私は次の優先事項/ウィッシュリストに導かれました。
- 速い
- 安い
- 確実に
- SQLサポート
- 水平スケーラビリティ
- 最小3Tbデータで効率的な作業、再びスケーリング
- リアルタイムデータを処理する機能
ゲームのアクティビティは定期的であるため、理想的には、ソリューションはピーク負荷に適応する必要があります。 たとえば、フィッシング中に負荷が何度も増加します。
たとえば、PlayerunknownのBattlegroundを見てください。 日中に顕著なピークが見られます。

ソース: SteamDB
また、年間のアクティブユーザー数(DAU)の増加を見ると、かなり速いペースで進んでいることがわかります。

ソース: SteamDB
ゲームがヒットしているという事実にもかかわらず、私は通常のプロジェクトで同様の成長チャートを見てきました。 1か月以内に、ユーザー数は2倍から5倍に増加しました。
拡張が容易なソリューションが必要ですが、事前に予約された容量に費用を支払う必要はありませんが、負荷の増加に応じて容量を追加します。
SQLベースのソリューション
額の決定は、何らかの種類のSQLデータベースを取得し、そこにすべてのデータを生の形式で送信することです。 箱から出して、クエリ言語の問題を解決します。
ゲームクライアントからの直接データはストレージに送信できないため、クライアントからのバッファリングイベントを処理してデータベースに送信する別のサービスが必要です。
このスキームでは、アナリストはクエリをデータベースに直接送信する必要がありますが、これは面倒です。 要求が重い場合、データベースが起動する可能性があります。 そのため、純粋にアナリストにはデータベースのレプリカが必要です。
アーキテクチャの例を以下に示します。
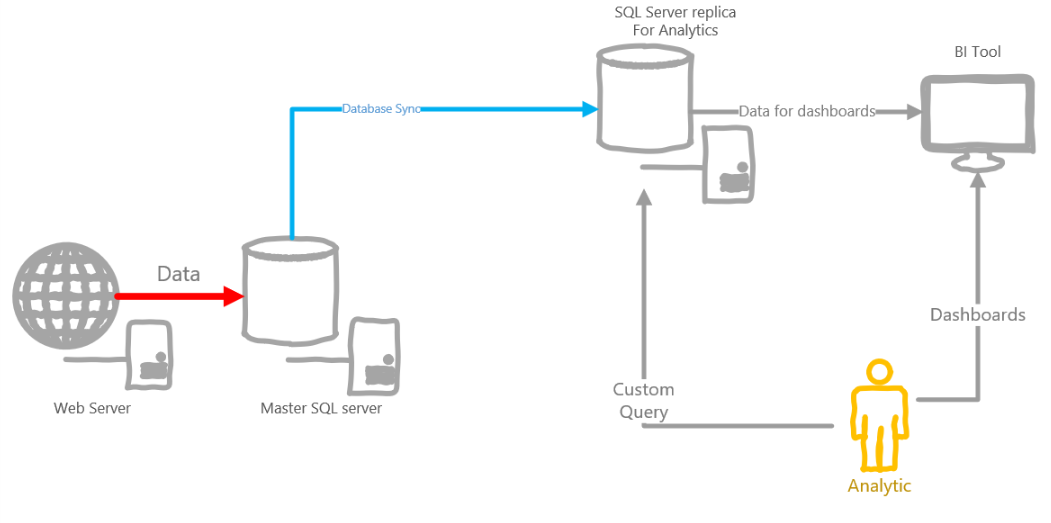
このアーキテクチャには、いくつかの欠点があります。
- リアルタイムのデータをすぐに忘れることができます
- SQLは強力なツールですが、イベントデータは多くの場合リレーショナルスキームに適合しないため、イベントのp0-p100500パラメーターなどの松葉杖を発明する必要があります
- 1日あたりに収集される分析データの量を考えると、データベースのサイズは飛躍的に増加し、パーティション分割などが必要になります。
- アナリストは、数時間、または場合によっては1日間実行されるリクエストを生成することができ、それによって他のユーザーをブロックします。 全員にデータベースの独自のレプリカを提供しないでください?
- SQLがオンプレミスの場合、フォールトトレランス、十分な空き領域などに常に注意する必要があります。 クラウド内の場合-それはかなりのペニーを飛ぶことができます
Apache Stackベースのソリューション
ここでは、Hadoop、Spark、Hive、NiFi、Kafka、Stormなどのスタックが非常に大きくなっています。
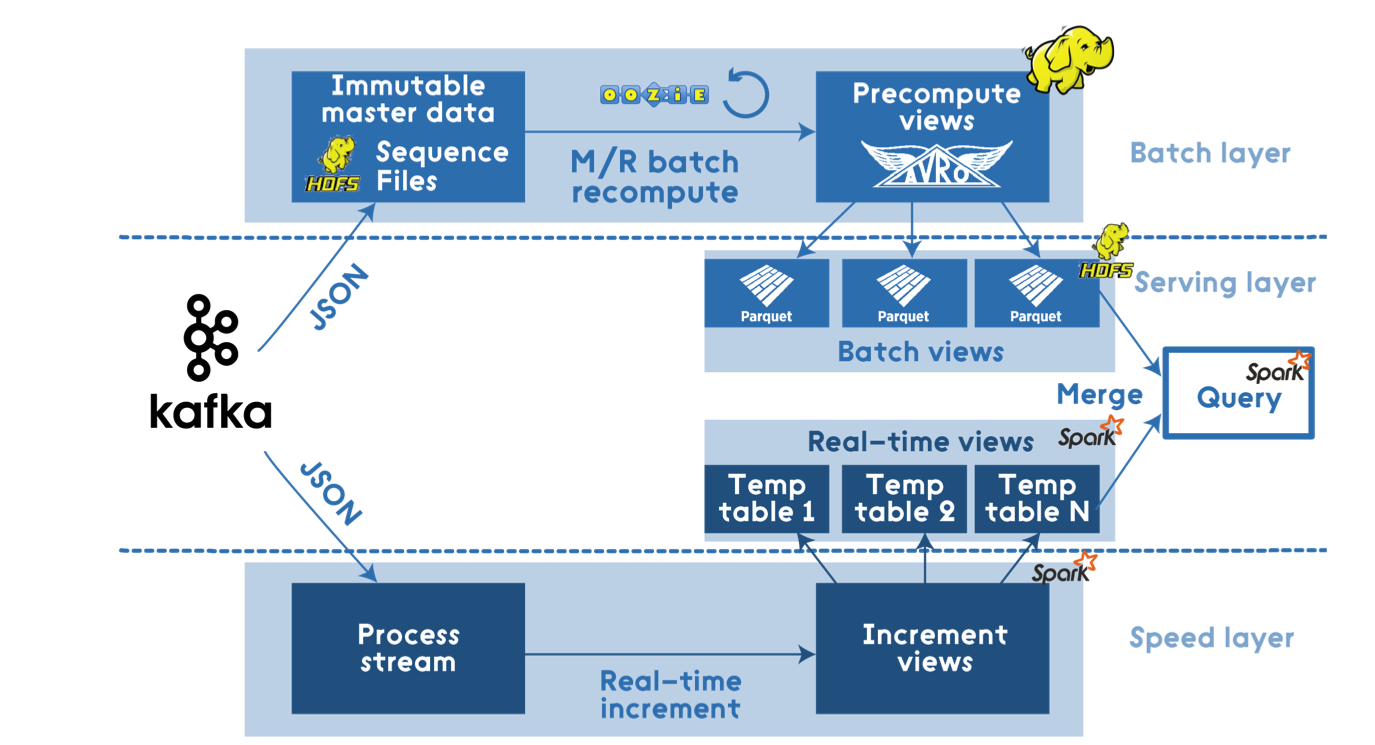
ソース: dzone.com
このようなアーキテクチャは、あらゆる負荷に正確に対応し、可能な限り柔軟になります。 これは、リアルタイムでデータを処理し、コールドデータに対して猛烈なクエリを作成できる完全なソリューションです。
しかし、実際には、要件に示されている負荷はBigDataを呼び出すのが難しく、単一のノードで計算できます。 したがって、Hadoopベースのソリューションは過剰です。
Spark Standaloneを使用すると、はるかに簡単で安価になります。
イベントの受信と前処理には、Sparkの代わりにApache NiFiを使用します。
クラスタ管理により、AKS上のKubernetesを大幅に簡素化できます。
長所 :
- 最も柔軟なソリューションであるデータハンドラーは、純粋なコードで記述するか、Spark SQLを使用できます。
- オープンソーススタック、大規模なコミュニティ
- 優れたスケーラビリティ。すべてをHadoopにいつでも転送できます。
短所 :
- 手動管理およびインフラストラクチャサポート、ただしAKSで簡素化できます
- 仮想マシンがほとんどアイドル状態の場合、仮想マシンの課金はあまり有益ではありません
- ソリューションのフォールトトレランスを確保するのは簡単な作業ではなく、自分で行う必要もあります
- リクエストはコードで記述されているため、誰もがそれを行うわけではなく、誰もがSQLに慣れているため、コードが圧倒されることはありません
クラウドプラットフォームソリューション
Azure Event Hubs
Azure Event Hubsは、最も単純な高帯域幅イベントハブです。 クラウドプラットフォームから-顧客から大量の分析を受信するのに最適なオプション。
長所 :
短所 :
- 乏しいイベント/キュー管理機能
- 組み込みの重複メッセージ追跡メカニズムはありません
- 自動スケールアップのみ
HDInsight
HDInsightは、Sparkなどの特定の製品とともに、すぐに使用できるHadoopクラスターを展開できるプラットフォームです。 このようなデータ量では過剰であり、非常に高価なので、すぐに廃棄できます。
Azure Databricks
Azure Databricksは、クラウド内のステロイドに対するこのようなスパークです。 DatabricksはSparkの著者による製品です。 2つの製品の比較については、 こちらをご覧ください 。 私が個人的に好きだったグッズの:
- Sparkの複数のバージョンのサポート
- イベントのストリームを処理できる完全なソリューション
- さまざまな最適化(データのスキップ、自動キャッシュ)により、バニラスパークよりも高速
- チームワークのために研ぎ澄まされた素敵なウェブインターフェース
- SQL、Python、R、Scalaをサポートするインタラクティブなメモ帳
- リアルタイムコラボレーション
- ノートブックのバージョン管理、github統合
- ノートブックをインタラクティブなダッシュボードとして公開する
- 組み込みのクラウドサポート
- すべてのクラウドパン:
- 簡単なスケーリング
- クラスター請求、ただし自動スケーリングおよび自動終了
- オンデマンドクラスターを作成および強制終了するジョブシステム
長所 :
- 自動スケーリング
- インフラストラクチャを維持する必要はありません
- インタラクティブなノートブック形式の便利な分析バン
- 実際に使用される計算時間に対する柔軟な分単位の請求
短所 :
- 不便なデバッグジョブ
- ジョブをデバッグするためのローカルエミュレータがない
Azure Data Lake Analytics(ADLA)
Azure Data Lake AnalyticsはMicrosoftのクラウドプラットフォームであり、Databricksに非常によく似ています。
私の意見では、請求はほぼ同じですが、もう少し明確です。 クラスターの概念も、ノードとそのサイズの概念もまったくありません。 抽象分析ユニット(AU)があります。 1 AU = 1つの抽象ノードの動作時間と言えます。
ADLAはマイクロソフト製品であるため、エコシステムとの統合性が向上しています。 たとえば、ADLAのジョブは、AzureポータルとVisual Studioの両方で作成できます。 ローカルADLAエミュレーターがあります。ビッグデータで実行する前に、マシンでジョブをデバッグできます。 カスタムC#コードの通常のデバッグがサポートされ、ブレークポイントがあります。
ジョブの並列化では、アプローチはデータブリックとは少し異なります。 クラスターの概念がないため、ジョブを開始するときに、割り当てられたAUの数を指定できます。 したがって、あなたはあなた自身がどれくらいの仕事を並行させるべきかを選ぶことができます。
クールな機能には、詳細なジョブプランがあります。 処理されたデータの量と量、各段階で処理された量を示します。 これは、最適化とデバッグのための強力なツールです。
ジョブの主な言語はU-SQLです。 カスタムコードについては、C#のみがあります。 しかし、多くの人はこれを利点と考えています。
長所 :
- ジョブのスケーリング
- 便利なU-SQL
- Azureサービスを含む製品のMicrosoftエコシステムとの良好な統合
- ローカルマシン上のジョブの便利なデバッグ
- 遅延ジョブプラン
- Azureポータルを介して作業する機能
短所 :
- イベントのストリームを処理できません。これには別のソリューションが必要です
- Azure Databricksのようなインタラクティブなコラボレーションツールはありません
- カスタムコードには1つの言語のみ
- タイマーデータ処理を構成するには、追加のツールが必要です
Azure Stream Analytics
ストリームイベントを処理するためのクラウドベースのプラットフォーム。 かなり便利なもの。 すぐに使えるのは、ポータルで直接デバッグ/テストするためのツールです。 T-SQLダイアレクトで話します。 集約用にさまざまなタイプのウィンドウをサポートします。 入力と出力の両方で多くのデータソースを使用できます。
すべての利点にもかかわらず、複雑なものにはほとんど適していません。 生産性または価値のいずれかに直面します。
考慮に値する機能は、PowerBIとの統合です。これにより、数回クリックするだけでリアルタイムの統計情報を構成できます。
長所:
- スケーリング
- すぐに使用できるすべてのクラウドサービスとの統合
- T-SQLサポート
- リクエストの便利なデバッグ
短所:
- ジョブをシャットダウンせずにスケールすることはできません
- prod / devスクリプト間でのジョブブリーディング用のツールはありません
- 高コスト
- DISTINCT'aのような重いクエリが存在する場合のパフォーマンスの低下
ハイブリッドソリューション
クラウドプラットフォームとOSSソリューションの組み合わせを禁止する人はいません。 たとえば、Apache Kafka / NiFiの代わりに、イベント変換用の追加ロジックがない場合は、Azure Event Hubsを使用できます。
他のすべてについては、例えば、Apache Sparkから離れることができます。
特定の番号
価格についての可能性を見つけました。 以下は、スタジオの1つで行った計算の例です。
Azure Pricing Calculatorを使用してコストを計算しました。
西ヨーロッパ地域のコールドデータを操作するための価格を計算しました。
簡単にするために、計算能力のみを考慮しました。 リポジトリのサイズは特定のプロジェクトに大きく依存しているため、リポジトリを考慮しませんでした。
この段階では、比較のためにバッファリングシステムの価格を表に含めました。 開始する最小クラスター/サイズの価格があります。
ネイキッドVMでのApacheスタックのコスト
| 解決策 | 価格 |
|---|
| スパーク | 204ドル |
| カフカ | 219ドル |
| 合計 | 433ドル |
ADLAベースのプラットフォームソリューションのコスト
| 解決策 | 価格 |
|---|
| Azure Data Lake Analytics | 108ドル |
| Azure Event Hubs | 11ドル |
| 合計 | 119ドル |
Azure Databricksプラットフォームプラットフォームコスト
| 解決策 | 価格 |
|---|
| Azure Databriks | 292ドル |
| Azure Event Hubs | 11ドル |
| 合計 | 303ドル |
その他の計算
ベアVM上のKafka
多かれ少なかれ信頼できるソリューションを提供するには、少なくとも3つのノードが必要です。
1 x Zookeeper (Standard A1) = $43.8 / month
2 x Kafka Nodes (Standard A2) = $175.2 / month
Total: $219
公平に言うと、このようなKafka構成は、要件で必要とされるよりもはるかに多くの帯域幅を消費することに注意する価値があります。 したがって、より高い帯域幅が必要な場合、Kafkaはより収益性が高くなります。
ベアVMでのSpark
話し合う価値のある最小構成は、4 vCPU、14GB RAMです。
最も安価なVMの中で、標準D3v2を選択しました。
1 x Standard D3v2 = $203.67 / month
Azure Databricks
Databricksには、標準とサーバーレス(ベータ)の2種類のクラスターがあります。
Azure Databricksの標準クラスターには、少なくとも2つのノードが含まれます。
- ドライバー-メモ帳をホストし、それらに関連する要求を処理します。これはSparkマスターでもあり、SparkContextをサポートします。
- ワーカー-実際には、すべてのリクエストを処理するワーカー
正直なところ、ここではサーバーレスの意味がわかりませんが、このタイプについて私が気づいたことは次のとおりです。
- とにかく、あなたは労働者のメモの種類、番号(from and to)を選択します
- サーバーレスは、別のリソースグループに、サブスクリプションでノードを直接作成します
- 自動終了機能がありません
- R / Python / SQLクエリのみをサポートします。
- 少なくとも2つのノードが含まれます
Databricksには2つの射撃場も含まれており、Premiumにはノートブックのアクセス制御などの機能がいくつかあります。 しかし、私は最低限の標準を検討しました。
計算機で数えてみると、1つの興味深い点に遭遇しました-Driverノードがそこにありません。 その結果、クラスターの最小サイズは2ノードであるため、計算機のコストは完全ではありません。 だから私はペンを数えました。
Databricks自体はDBU(コンピューティングパワー)に対して請求されます。 各タイプのノードには、1時間ごとに独自のDBUがあります。
ワーカーの場合、最小DSv2(\ $ 0.272 /時間)を使用しました。これは0.75 DBUに相当します。
ドライバーの場合、最も安いF4インスタンス(\ $ 0.227 /時間)を使用しました。これは0.5 DBUに相当します。
DSv2 = ($0.272 + $0.2 * 0.75 DBU ) * 730 = $308.06 F4 = ($0.227 + $0.2 * 0.75 DBU ) * 730 = $275.21 Total: $583.27
この計算は、この小さなクラスターの24時間365日の作業に基づいています。 しかし、実際には、自動終了の機能のおかげで、この数値は大幅に削減できます。 クラスターの最小アイドルタイムアウトは10分です。
クラスターで1日12時間動作するという公理(浮動時間を含むフルタイム)を採用した場合、コストは既に$583 * 0.5 = $291.5ます。
アナリストが作業時間の100%をクラスターに使用しない場合、数値はさらに少なくなる可能性があります。
Azure Data Lake Analytics
ヨーロッパの価格\ 1 アナリティクスユニットあたり2ドル。
分析ユニットは基本的に1つのノードです。 ノードの1時間あたり2ドルは少し高価ですが、このビジネスは毎分課金されます。 通常、ジョブには少なくとも1分かかります。
Jobが大きい場合、それを並列化するにはより多くのAUが必要です。
それから私は、空に指を突くのはあまり良くないことに気づきました。 したがって、以前は小さなテストを実施しました。 100 MBのJSONファイルを1 GBだけ生成し、脇に置いて、Azure Data Lake Analyticsで簡単なデータ集約リクエストを実行し、1 GBの処理にかかる時間を確認しました。 0.09 AU / hになりました。
これで、データ処理のコストを大まかに計算できます。 1か月あたり600 GBのデータを蓄積するとします。 このすべてのデータを少なくとも1回処理する必要があります。
600 * 0.09AU * $2 = $108
これらは、分析の最小構成のかなり粗雑な計算です。
簡単な要約
SQLデータベースに基づくソリューションには、十分な柔軟性とパフォーマンスがありません。
Apache Stackベースのソリューションは非常に強力で柔軟性がありますが、示された要件には少し高価です。 さらに、ハンドルによるクラスターサポートが必要です。 これはオープンソースなので、ベンダーロックは安全です。 さらに、Apache Stackは、コールドデータとホットデータの処理という2つのタスクを同時にカバーできます。これはプラスです。
管理の難しさを恐れないのであれば、これが理想的な解決策です。
大量のアナリティクスを常に使用している場合は、独自のクラスターを作成する方が収益性の高いソリューションになります。
クラウドプラットフォームには、いくつかのソリューションがあります。
イベントのバッファリング-EventHub。 少量の場合、カフカよりも安くなります。
コールドデータの処理には、2つの適切なオプションがあります。
- Azure Databricks(プレビュー)は、インタラクティブなノートブックと組み込みのSparkを備えたクールなツールです。 ホットデータとコールドデータの両方を処理できます。 それほど高価ではない、多くの言語のサポート、クラスターの自動管理、その他多くの機能。
- Azure Data Lake Analytics-クラスター、ジョブレベルでの並列化、Visual Studioとの良好な統合、便利なデバッグツール、毎分課金
インフラストラクチャをサポートするリソースがなく、かなり安価なスタートが必要な場合、これらのオプションは非常に魅力的です。
Azure Databricksは、大量のジョブが継続的に実行される場合、より安価なオプションになります。
示されたオプションをいくつかのスタジオに提供したことで、多くはプラットフォームソリューションに興味を持つようになりました。 これらは、不必要な管理作業なしで、既存のプロセスやシステムに非常に簡単に統合できます。
以下では、Azure Data Lake Analyticsプラットフォームソリューションに基づいた詳細なアーキテクチャの概要を確認します。
Azure Event Hubのゲーム分析/ Azure Functions / Azure Data Factory / Azure Data Lake Analytics / Azure Stream Analytics / Power BI
建築
長所と短所を見積もり、Azureでのラムダアーキテクチャの実装を取り上げました。 次のようになります。
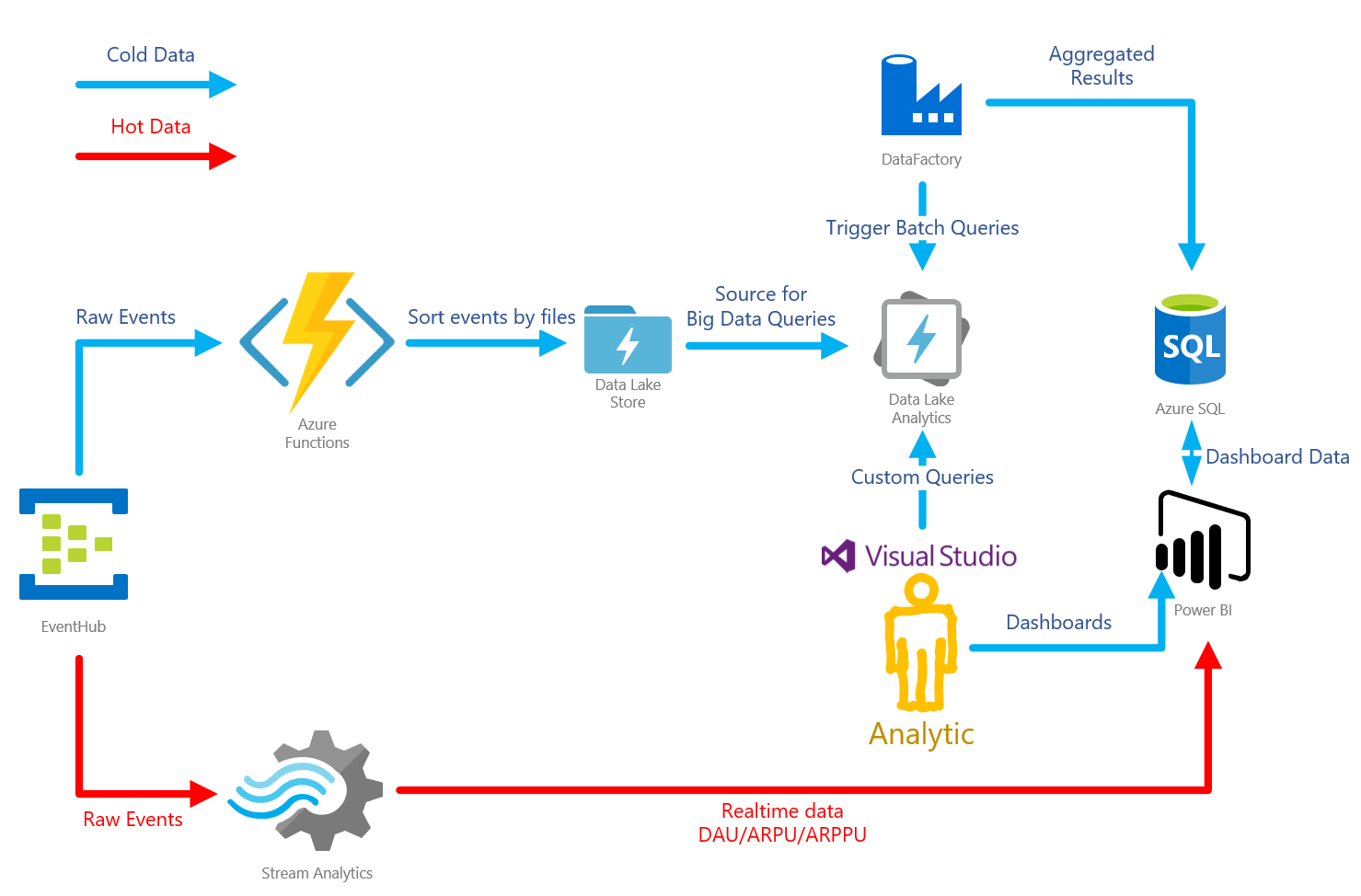
Azure Event Hubはキューであり、大量のメッセージを受信できるバッファーです。 また、生データをストレージに書き込む便利な機能もあります。 この場合、Azure Data Lake Storage(ADLS)。
Azure Data Lake Storeは、HDFSに基づくストレージです。 Azure Data Lake Analyticsサービスと組み合わせて使用します。
Azure Data Lake Analytics-分析サービス。 さまざまなソースからのデータに対してU-SQLクエリを構築できます。 最速のソースはADLSです。 特に難しいケースでは、C#でクエリ用のカスタムコードを作成できます。 Visual Studioには、詳細なクエリプロファイリングを備えた便利なツールボックスがあります。
Azure Stream Analyticsは、データフローを処理するためのサービスです。 この場合、ホットデータを集約し、PowerBでの視覚化のために転送するために使用されます
Azure Functions-サーバーレスアプリケーションをホストするためのサービス。 このアーキテクチャは、イベントキューを「カスタム」処理するために使用されます。
Azure Data Factoryはかなり物議を醸すツールです。 データパイプラインを整理できます。 この特定のアーキテクチャでは、バッチの起動に使用されます。 つまり、ADLAでクエリを起動し、特定の時間のスライスを計算します。
PowerBIはビジネスインテリジェンスツールです。 ゲーム内のすべてのダッシュボードを整理するために使用されます。 リアルタイムデータを表示できます。
同じ決定ですが、異なる視点で。
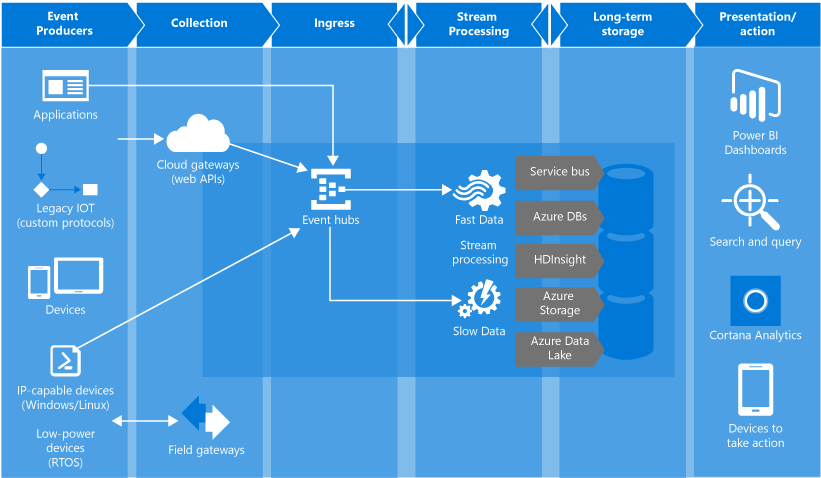
ここでは、Event Hubsクライアントで直接またはGateway APIを介してクライアントができることを明確に見ることができます。 同様に、Event Hubsではサーバー分析をスローできます。
イベントキュー処理
コールドデータ
EventHubに入った後、イベントはコールドとホットの2つの方法で進みます。 コールドパスはADLSストレージにつながります。 イベントを保存するためのオプションがいくつかあります。
EventHubのキャプチャ
最も簡単な方法は、EventHubのキャプチャ機能を使用することです。 ハブに入ってくる生データをストレージの1つ(Azure StorageまたはADLS)に自動的に保存できます。 この機能を使用すると、ファイルの命名パターンをカスタマイズできますが、非常に制限されています。
機能は便利ですが、すべての場合に適しているわけではありません。 たとえば、ファイルのパターンで使用される時間がEventHubのイベントの到着時間に対応するため、私には向いていませんでした。
実際、ゲームでは、イベントは顧客が蓄積し、パックで送信できます。 この場合、イベントは間違ったファイルに保存されます。
ファイル構造でデータを整理することは、ADLAのパフォーマンスにとって重要です。 ファイルを開く/閉じるオーバーヘッドは非常に高いため、ADLAは大きなファイルを操作するときに最も効果的です。 経験的に、30〜50 MBの最適なサイズを見つけました。 負荷によっては、ファイルを日/時間で分割する必要がある場合があります。
もう1つの理由は、イベント自体の種類に応じて、フォルダーにイベントを配置する機能がないことです。 分析に関しては、クエリは可能な限り効率的である必要があります。 不要なデータを除外する最善の方法は、ファイルをまったく読み取らないことです。
タイプごとにイベントがファイル内で混在している場合(たとえば、許可イベントや経済イベント)、不要なデータの破棄に分析計算能力の一部が費やされます。
長所:
短所:
- リポジトリにイベントを保存するときのみAVRO形式をサポートします
- ファイルの命名機能がかなり制限されています。
ストリーム分析(コールドデータ)
Stream Analyticsを使用すると、SQLのようなクエリをイベントのストリームに書き込むことができます。 データソースとしてのEventHubと出力としてのADLSのサポートがあります。 これらのリクエストのおかげで、既に変換/集約されたデータをストレージに追加できます。
同様に、ファイル命名機能がわずかです。
長所:
- 素早く簡単なセットアップ
- 入力/出力イベントの複数の形式をサポート
短所:
- ファイルの命名機能がかなり制限されています。
- 高価格
- 動的スケーリングの欠如
Azure Functions(コールドデータ)
最も柔軟なソリューション。 Azure FunctionsにはEventHubのバインディングがあり、キューの解析に煩わされる必要はありません。 また、Azure Functionsは自動的にスケーリングされます。
イベントの到着ではなく、イベントが生成された時間に対応するフォルダーにイベントを配置することができたため、この決定に基づいて停止しました。 また、イベントの種類に応じて、イベント自体がフォルダーに散らばっていました。
請求には2つのオプションがあります。
- 消費プランはサーバーレスキャッシュであり、1秒あたりの使用済みメモリごとに支払います。 重い負荷の下では少し高価になることがあります
- App Serviceプラン-このオプションでは、Azure Functionsにはサーバーがあり、そのタイプは自由に選択できますが、自動スケーリングの可能性があります。 私の場合、このオプションがより安価であることが判明しました。
長所:
- 生データファイルの命名の柔軟性
- 動的スケーリング
- EventHubとの組み込みの統合があります
- 適切な請求書による低コストのソリューション
短所:
ホットデータ
ストリーム分析(ホットデータ)
繰り返しになりますが、Stream Analyticsはホットデータを集約するための最も簡単なソリューションです。 長所と短所は、寒い方法とほぼ同じです。 Stream Analyticsの主な利点は、PowerBIとの統合です。 ホットデータは「リアルタイム」で出荷できます。
長所:
- 素早く簡単なセットアップ
- SQL、Blob Storage、PowerBIなど、多くの調査結果があります
短所:
- ただし、Stream Analyticsで使用されるT-SQLサブセットには独自の制限があり、いくつかの問題を解決する際に制限に直面する可能性があります
- 価格
- 動的スケーリングの欠如
Azure Functions(ホットデータ)
すべてがコールドデータと同じです。 詳細は説明しません。
長所:
- 完全にカスタムロジック
- 動的スケーリング
- 統合されたEventHub統合
- 適切な請求書による低コストのソリューション
短所:
- カスタムコードを記述する必要がある
- 関数はステートレスであるため、別個のステートストアが必要です。
完全なソリューションの価格を考慮します
したがって、負荷の計算は1秒あたり1000イベントです。
| 解決策 | 価格 |
|---|
| Azure EventHub | 10.95ドル |
| Azure Stream Analytics | 80.30ドル |
| Azure関数 | 73.00ドル |
| Azure Data Lake Store | 26.29ドル |
| Azure Data Lake Analytics | 108.00ドル |
ほとんどの場合、Stream Analyticsは必要ない場合があるため、合計は217ドルから297ドルになります。
今、私がどう思ったかについて。 上記の計算からAzure Data Lake Analyticsのコストを取りました。
Azure Event Hubの計算
Azure Event Hub-100万メッセージごとに課金され、1秒あたりの帯域幅も課金されます。
スループットユニット(TU)のスループットは、1000イベント/秒または1MB /秒のいずれか早いほうです。
1秒あたり1000メッセージをカウントします。つまり、1 TUが必要です。 執筆時点でのTUの価格は、 Basic Tierの場合$0.015です。 730時間の月に信じられています。
1 TU * $0.015 * 730 = $10.95
その月の同じ負荷を考慮して、月あたりのメッセージ数を考慮します(これは起こりません)。
1000 * 3600 * 730 = 2 628 000 000
着信イベントの数の価格を考慮します。 執筆時点での西ヨーロッパの価格は、イベント100万件あたり$0.028 。
2 628 000 000 / 1 000 000 * $0.028 = $73.584
合計$10.95 + $73.584 = $84.534 。
何かがうまくいきます。 通常、イベントは非常に小さいため、これは有益ではありません。
複数のイベントを1つにパックするためのアルゴリズムをクライアントで記述する必要があります(ほとんどの場合、そうする)。 これにより、イベントの数が減るだけでなく、負荷がさらに増加して必要なTUの数も減ります 。
既存のシステムから実際のイベントをアンロードし、平均サイズ-0.24KBを計算しました。 EventHubで許可される最大イベントサイズは256KBです。 したがって、約1000個のイベントを1つにまとめることができます。
ただし、微妙な点があります。最大イベントサイズは256KBですが、 64KBの倍数で請求されます 。 つまり、最も圧縮されたメッセージは4つのイベントとしてカウントされます。
この最適化を考慮して再計算します。
$73.584 / 1000 * 4 = $0.294
これはすでにはるかに優れています。 次に、必要な帯域幅を計算しましょう。
1000 events per second / 1000 events in batch * 256KB = 256KB/s
この計算は別の重要な機能を示しています。 イベントのバッチ処理を行わない場合、2.5MB /秒が必要になり、3TUが必要になります。 しかし、1秒間に1000個のイベントを送信するため、1TUだけで十分だと考えました。 しかし、帯域幅の制限は早くなります。
いずれにせよ、3の代わりに1 TUを満たすことができます! そして、計算は変更できません。
TUの価格を考慮します。
合計$10.95 + $0.294 = $11.244ます。
イベントパッケージを除く価格と比較: (1 - $11.244 / $84.534) * 100 = 86.7% 。
86%の収益性向上!
このアーキテクチャを実装するときは、イベントパッケージを考慮する必要があります。
Azure Data Lake Storeの計算
それでは、ストレージサイズの増加の大まかな順序を推定しましょう。 1秒あたり1000イベントの負荷で256KB / sを取得することを既に計算しました。
256 * 3600 * 730 = 657 000 M = 641
これはかなり大きな数字です。 おそらく、1秒あたり1000イベントは時刻の一部に過ぎませんが、それでも最悪のオプションを計算する価値があります。
641 * $0.04 = $25.64
ADLSは、10,000件のファイルトランザクションごとに請求されます。 トランザクションは、ファイルに対する任意のアクションです:読み取り、書き込み、削除。 幸いなことに、削除は無料です=)。
データを記録するだけの価値があるものを計算しましょう。 前の計算を使用して、1か月あたり2,628,000,000イベントを収集しますが、イベントごとに1,000をパックするため、2,628,000イベントになります。
2 628 000 / 10000 * $0.05 = $13.14
それほど高価ではありませんが、1000個のイベントをまとめて記録することで削減できます。 パッケージングはクライアントアプリケーションレベルで行い、EventHubのイベント処理レベルでバッチ記録する必要があります。
$13.14 / 1000 = $0.0134
これは悪くありません。 ただし、EventHubキューを解析するときは、バッチ処理を検討する必要があります。
合計$26.28 + $0.0134 = $26.2934
Azure関数の計算
Azure Functionsの使用は、コールドとホットの両方の方法で可能です。 同様に、単一のアプリケーションとして、または個別にデプロイできます。
それらが1つのアプリケーションとしてスピンするときに、最も簡単なオプションが見つかります。
したがって、1秒あたり1000イベントの負荷があります。 これはそれほどではありませんが、少しではありません。 前に、Azure Functionsはイベントをバッチで処理できると述べました。これは、イベントを個別に処理するよりも効率的に実行されます。
バッチサイズを1000イベントにすると、負荷は1000 / 1000 = 1 ます。 なんてばかげた図。
したがって、すべてを1つのアプリケーションにデプロイでき、1つの最小インスタンスS1がこの負荷を引き出します。 その費用は73ドルです。 もちろん、B1を使用することもできますが、さらに安くなりますが、私は安全で、S1に落ち着きます。
ストリーム分析の計算
Stream Analyticsは、スライディングウィンドウの仕組みが必要な高度なリアルタイムシナリオにのみ必要です。 これはゲームではかなりまれなシナリオです。主な統計は1日あたりのウィンドウに基づいて計算され、翌日にリセットされるためです。
Stream Analyticsが必要な場合、ガイドラインでは、6つのストリーミングユニット(SU)のサイズから開始することをお勧めします。これは、強調表示された1つのノードに相当します。 次に、作業負荷を確認し、それに応じてSUをスケーリングする必要があります。
私の経験では、クエリにDISTINCTが含まれていない場合、またはウィンドウがかなり小さい(時間)場合、SUは1つで十分です。
1 SU * $0.110 * 730 hours = $80.3
まとめ
市場で提供されている既存のソリューションは非常に強力です。 ただし、高度なタスクにはまだ十分ではなく、常にパフォーマンスの制限またはカスタマイズの制限があります。 そして、中規模のゲームでさえ、すぐにそれらに遭遇し始めます。 これにより、独自のソリューションの開発が促進されます。
技術スタックを選択する前に立って、価格を考えました。 強力なApacheスタックは、あらゆるタスクと負荷に対処できますが、手動で管理する必要があります。 簡単にスケーリングできない場合、特にマシンに24時間年中無休で負荷がかかっていない場合は、非常に高価です。 さらに、スタックに精通していない場合、そのようなソリューションは安価で迅速なスタートには機能しません。
インフラストラクチャの開発とサポートに投資したくない場合は、クラウドプラットフォームを検討する必要があります。 ゲーム分析には、主に定期的な計算が必要です。 たとえば、1日に1回。 したがって、使用した分のみに料金を支払う能力がまさにポイントです。
最も安価で最速のスタートは、ADLAベースのソリューションです。 よりリッチで柔軟なソリューションは、Azure Databricksです。
ハイブリッドオプションもあります。
既存のプロセスおよびシステムに統合するための最も簡単なオプションとして、優先クラウドソリューションと連携したスタジオ。
クラウドサービスを使用する場合、ソリューションの構築には細心の注意が必要です。 価格設定の原則を検討し、コストを削減するために必要な最適化を検討する必要があります。
その結果、計算では、1秒あたり1,000クエリ(平均)に対して、1か月あたり300ドルでカスタム分析システムを取得できることが示されています。 これはかなり安いです。 この場合、ソリューションの開発に投資する必要はありません。 興味深いことに、ADLAオプションは、他のソリューションとは異なり、アイドル時にまったくお金を消費しません。 したがって、開発およびテストスクリプトにとって非常に興味深いものです。
次の記事では、実装の技術的な側面について詳しく説明します。
不快な瞬間についてお話しします。 たとえば、ゲームシナリオのAzure Stream Analyticsのパフォーマンスはあまりよくありませんでした。 多くの要求はDAUに関連付けられており、その計算にはDISTINCTを介した一意の要求の計算が必要です。 それは生産性を殺し、多くのお金を注ぎました。 Azure Functions + Redisの簡単なコードで問題を解決しました。
好き、欲しい、欲しい、欲しい
— Microsoft, . , , . .
, , , , , . . .
, , .