最近、ある古いプログラムの機能を補うためにタスクが飛んできました(プログラムのソースコードはありません)。 実際、定期的にデータベースをスキャンし、情報を分析し、これに基づいてメーリングを行うだけで十分でした。 全体の難しさは、アプリケーションがすでに1984年に作成されたcツリーデータベースで動作することであることが判明しました。
このデータベースについて製造元のWebサイトを調べたところ、特定のodbcドライバーを見つけましたが、まったく接続できませんでした。 多くのグーグルも、データベースに接続してデータを取得するのに役立ちませんでした。 その後、技術サポートに連絡してこのデータベースの開発者に支援を求めることが決定されましたが、男は正直34年が過ぎ、すべてが100,500回変化し、そのような古いものに接続するための通常のドライバーがなく、プログラマーも生きていないことを正直に認めましたこの奇跡を書いた。
データベースファイルを調べて構造を調べたところ、データベース内の各テーブルは、拡張子が* .datおよび* .idxの2つのファイルに保存されていることがわかりました。 idxファイルには、id、インデックスなどに関する情報が保存されます。 データベース内の情報をより高速に検索します。 datファイルには、タブレットに保存されている情報自体が含まれています。
これらのファイルを独自に解析し、何らかの方法でこの情報を取得することが決定されました。 Goは言語として使用されました。 プロジェクトの残りの部分はそれに書かれています。
データの処理中に遭遇した最も興味深い瞬間のみを説明します。これは主にGo言語自体ではなく、計算アルゴリズムと数学の魔法に影響します。
ファイルのどこが非現実的であるか、すぐに理解できます。そこには通常のエンコードがないため、データは特定のビットに書き込まれ、最初はデータガベージのように見えます。

クライアントから、「****は8086プロセッサで実行されているMS-DOSアプリケーションであり、メモリが不足していました」という短い説明を含む感動的なフレーズを受け取りました。
作業のロジックは次のとおりです。新しいデータをプログラムに割り当て、どのファイルが変更されたかを確認し、値が変更されたデータの一部をパンチアウトします。
開発プロセスの間に、私はより速く理解するのに役立つ以下の重要なルールに気付きました。
- ファイルの先頭と末尾(サイズは常に異なります)は表形式データ用に予約されています
- テーブルの行の長さは常に同じバイト数を使用します
- 計算は256の10進数システムで実行されます
予定時間
アプリケーションは、15分間隔でスケジュールを作成します(たとえば、12:15-14:45)。 さまざまなタイミングで突くと、クロックの原因となっているメモリ領域が見つかりました。 バイト単位でファイルからデータを読み取ります。 時間については、2バイトのデータが使用されます。
スケジュールに15分を追加すると、最初のバイトに15が追加され、さらに15分が追加され、バイトは既に30などになります。
たとえば、次の値があります。
[0] [245]値が255を超えるとすぐに、次のバイトに1が追加され、残りが現在のバイトに書き込まれます。
245 + 15 = 260
260-256 = 4ファイルに値がある合計:
[1] [4]今注目! 非常に興味深いロジック。 これが1時間あたり0分から45分までの範囲である場合、15分がバイトに追加されます。 しかし! これが1時間の最後の15分(45から60)である場合、55がバイトに追加されます。
1時間は常に100に等しいことがわかります。15時間45分がある場合、ファイルには次のようなデータがあります。
[6] [9]次に、いくつかのマジックをオンにして、値をバイトから整数に変換します。
6 * 256 + 9 = 1545この数値を100で除算すると、整数部分は時間に等しくなり、小数部分は分に等しくなります。
1545/100 = 15.45コジャラ:
data, err := ioutil.ReadFile(defaultPath + scheduleFileName) if err != nil { log.Printf("[Error] File %s not found: %v", defaultPath+scheduleFileName, err) } timeOffset1 := 98 timeOffset2 := 99 timeSize := 1
予定日
日付のバイトから値を計算するロジックは、時間と同じです。 バイトは最大255まで埋められ、その後リセットされ、次のバイトに1が追加されます。 日付に対してのみ、2バイトではなく4バイトのメモリが既に割り当てられています。 どうやら、開発者は、アプリケーションがさらに数百万年生き残ることができると判断しました。 取得できる最大数は次のとおりです。
[255] [255] [255] [256]
256 * 256 * 256 * 256 + 256 * 256 * 256 + 256 * 256 + 256 = 4311810304アプリケーションの参照開始日は1849年12月31日です。特定の日付は日を追加することで検討します。 私は当初、時間パッケージのAddDateに制限があり、4311810304日を食べることができないことを知っていますが、次の年には200日で十分です。
適切な数のファイルを分析した後、メモリ内の日付を配置するための3つのオプションを見つけました。
- 読み取りバイト、メモリの特定のセクション、左から右に実行する必要があります
- 読み取りバイト、特定のメモリ、右から左に実行する必要があります
- データの各「有用なバイト」の間にヌルバイトが挿入されます。 たとえば、[1] [0] [101] [0] [100] [0] [28]
データを整理するために異なるロジックが使用された理由を理解できませんでしたが、日付を計算する原理はどこでも同じであり、主なことはデータを正しく取得することです。
コジャラ:
func getDate(data []uint8) time.Time { startDate := time.Date(1849, 12, 31, 0, 00, 00, 0, time.UTC) var result int for i := 0; i < len(data)-1; i++ { var sqr = 1 for j := 0; j < i; j++ { sqr = sqr * 256 } result = result + (int(data[i]) * sqr) } return startDate.AddDate(0, 0, result) }
利用可能スケジュール
従業員には空き時間スケジュールがあります。 1日あたり最大3つの時間間隔を割り当てることができます。 例:
8:00-13:00
14:00-16:30
17:00-19:00スケジュールは、曜日を問わず設定できます。 次の3か月のスケジュールを作成する必要がありました。
ファイルストレージスキームの例を次に示します。
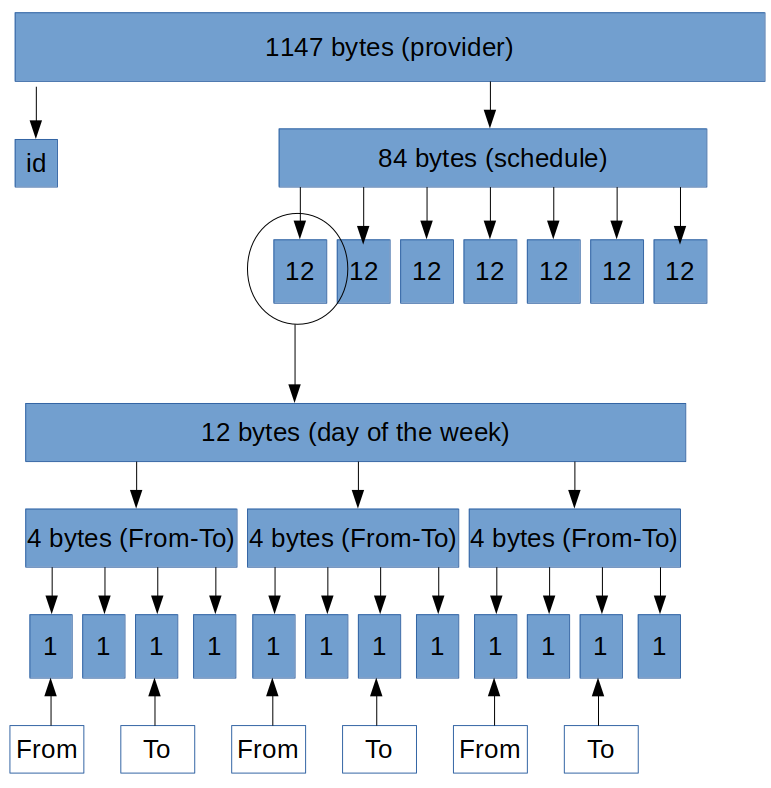
ファイルから各レコードを個別に切り取り、曜日に応じて特定のバイト数だけシフトすると、すでに時間を処理しています。
コジャラ:
type Schedule struct { ProviderID string `json:"provider_id"` Date time.Time `json:"date"` DayStart string `json:"day_start"` DayEnd string `json:"day_end"` Breaks *ScheduleBreaks `json:"breaks"` } type SheduleBreaks []*cheduleBreak type ScheduleBreak struct { Start time.Time `json:"start"` End time.Time `json:"end"` } func ScanSchedule(config Config) (schedules []Schedule, err error) { dataFromFile, err := ioutil.ReadFile(config.DBPath + providersFileName) if err != nil { return schedules, err } scheduleOffset := 774 weeklyDayOffset := map[string]int{ "Sunday": 0, "Monday": 12, "Tuesday": 24, "Wednesday": 36, "Thursday": 48, "Friday": 60, "Saturday": 72, }
一般に、以前に使用した計算アルゴリズムに関する知識を共有したかっただけです。