こんにちは、私の名前はアレクセイです。ルネッサンスクレジットバンクのチーフITアーキテクトです。 約10年前、私たちは多くの企業と同様に、サービス指向アーキテクチャ(SOA)のおかげで開発を加速しました。 しかし、時間の経過とともに、アーキテクチャの要件が変化し、このパラダイムに対して深刻な疑問が生じ始めました。 最終的に、ESB統合バスからマイクロサービスに移行することにしました。 この例では、なぜSOAの有効性について考える価値があるのか、そしてこのモデルもあなたに合わない場合に何ができるのかを説明します。
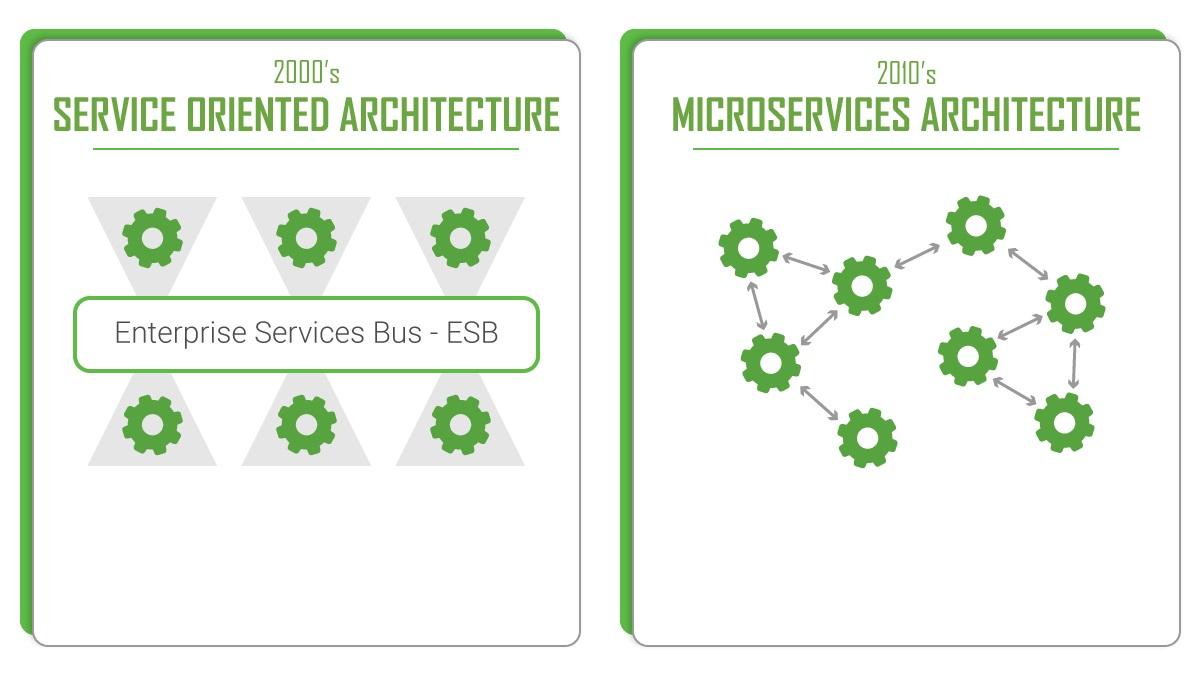
新しいESBの問題
それはすべて、統合バスの構造に感謝したという事実から始まりました。 この図は、ESBの統合フローの典型的な状況を示しています。
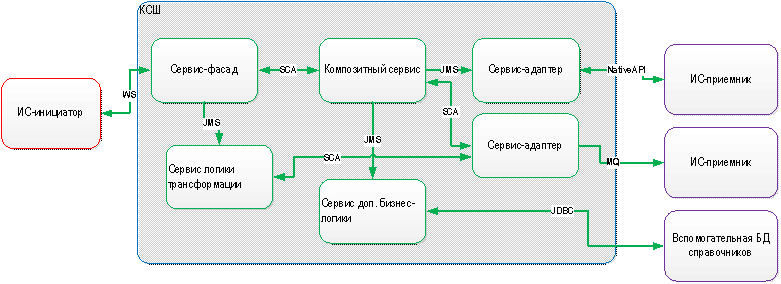
このようなブロックは数十(最大で数百!)あり、それらは密接に絡み合っています。 新しい製品を作成して変更する必要がある場合、この巨大なモノリスを処理するのに十分なリソースはありません。 そして、これは単なる一般的な見方です。 すべての側面からSOAを調査し、7つの主要な問題を特定しました。
- サービスの再利用に重点を置いています。 このルールはSOAの基礎でしたが、最終的にはすべてのチーム(フロント、バック、統合)が緊密に接続されているため、統合の更新にはバス全体のリグレッションチェックが必要でした。
- ヘビーテクノロジースタック。 最初は、単一のESBコンテナーが利点でした。これにより、サービスを迅速にデプロイできました。 しかし今日、限られた技術、ライブラリ、プログラミング言語のスタックがすでに開発を著しく妨げています。
- ESBをすべてのプロセスのボトルネックに変えます。 時間が経つにつれて、バスは機能を獲得し、ウォーターフォールアプローチと統合フローの「カット」により、銀行の本格的な情報システムに変わります。 ESBチームの負荷が大幅に増加しているため、他の開発チームの作業が遅くなります。
- DataSilo。 SOAでは、サービスインターフェイスは実装から分離されています。 しかし、サービスで使用されるデータはどの程度分離されていますか? 1つのサービスが別のサービスにアクセスし、dblinkメカニズムが使用され、混乱と「データサイロ」があります。
- 統合パターンの混合。 厳密に言えば、SOAには2つの方法があります。データを交換するためにシステム間でメッセージがやり取りされる従来のMessageBrokerと、「他にこだわらないサービス」を配置するサービスのハブです。 これらのテンプレートが混在すると、ESBは完全にブラックボックスになります。
- 「シャドウIT」の形成。 多くの場合、ビジネスのお客様は、ITチームを結成して重要なシステムを開発しますが、統合にバスを使用することはできません。 そのため、情報システムへの「左」接続の数が増えています。
- 概念レベルでのITSec(情報セキュリティ)のサポートの欠如。 ここでは、少し説明する必要があります。まず、ESBの完全に「西側の」概念では、ロシアの法律の特性(たとえば、ソースからレシーバーへの転送時の個人データの保護)が考慮されません。 ITSecの特別な要件に準拠する必要はありません。
新しい顧客のニーズ
複雑で遅いプロセスを備えた従来のウォーターフォール指向のサービスタイヤは、市場に適合しません。 今日、顧客はアジャイル開発の方法論を認識しています。 彼らはアジャイルとウォーターフォールの違いを知らないかもしれませんが、最初の結果-アイデアから運用中のプロトタイプまで-6-8ではなく、2-3か月で、しかし一般的にはより良い結果を得たいです。 それをMVPにしますが、顧客がビジネスアイデアをできるだけ早く確認し、ソリューションが開始されることを理解することが重要です。
このような状況では、従来の水平志向のチームは垂直志向よりも劣り、対話チャネルからバックエンドまで、製品のすべてのコンポーネントで機能します。 エッジは疑問を提起します:サービスの再利用のためにモノリスに変わった統合バスをどうするか? 新しい技術的アプローチが必要です。
新しいアプローチの基盤
基本要件のステートメントを使用して、SOAの代替案を作成し始めました。
- アイデアをすばやくパイロットする機能。 これには、システム間の接続の単純な(通常の、繰り返しの)構造、迅速な展開、およびバージョン管理が必要です。
- アジャイル開発のサポート。 新しい垂直チームの簡単な接続、「開発工場」のレベルへのアクセス、および日常的なタスクの自動化。
- さまざまなタイプの開発チームを持つエコシステムの存在 :内部、外部、パートナーシップ。 外部アクセス用のインターフェースを提供し、このアクセスと請求を制御します。
技術ピラミッド
要件に従って、テクノロジーのピラミッドを形成しました。
次に、各レベルのコンポーネントについて個別に説明します。
1.方法論のレベル- アジャイル 柔軟なアプローチは、多くの感情と反対意見を引き起こします(さまざまな規模の組織での適用可能性のトピックについて)。 私たち自身が主なものを定式化しました。このアプローチは、要件の構築、ラピッドプロトタイピング、MVPの作成、つまり製品のアイデアのテストの基礎となります。
- DevOps。 このパラダイムでは、最大限の自動化と、システムの開発と保守の「境界を曖昧にする」ことが必要です。 日常的な展開およびメンテナンス操作での時間の損失を回避します。
- 工場開発 。 分析段階から作成された製品の展開および操作への成果物の移動は、後続の各段階で成果物を再作成することなく、継続的である必要があります。 たとえば、サービスインターフェイスがアナリストによって最初に何らかの形式で記述され、開発者が手動で同じインターフェイスを別のツールで再度作成するような状況はありません。
2.インフラストラクチャレベル- コンテナ化(Docker) 。 このレベルでマイクロサービスを提供する唯一のオプションは、単一のバスコンテナーを回避し、サービスのインスタンスごとに個別のコンテナーを使用することです。 これは、起動時に広範囲のライブラリを実行する「重い」アプリケーションサーバーの使用も適切でないことを意味します。 コンテナは、サービスに必要な一連の機能のみが起動されるように、できるだけ軽量で構成可能である必要があります。 そしてこの観点から、Dockerは素晴らしいです。
- コンテナオーケストラ 。 コンテナは、フォールトトレランスの典型的なタスクを解決するツールによって管理する必要があり、展開/停止/開始のバランスを取り、統一する必要があります。 さらに、このツールは、モノリシックなコンテナを備えたタイヤの類似物にはなり得ません。
3.適用されたアーキテクチャ- マイクロサービスアーキテクチャ(MSA) 。 マイクロサービスの正確な定義の問題は未解決のままです。 ただし、統合アーキテクチャとシステムの完全な開発のために、マイクロサービスの次の重要な特性を特定しました。
| 物件
| 説明
|
1
| インターフェースとサービス実装の分離
| このプロパティはSOAから継承されるため、実装を変更してもインターフェイスを変更する必要はありません。 サービスへの呼び出しには、サービスの実装の複雑さを理解することなく、インターフェイスの知識のみが必要でした。
|
2
| 良い粒度
| マイクロサービスは比較的小さく(「2ピザルール」)、互いに分離し、対象領域の機能の変更が最大1つのマイクロサービスに集中するようにします。
|
3
| すべてのレベルでのサービスの分離
| マイクロサービスは互いに完全に分離する必要があります。 インターフェイスレベルおよび実行レベル-それぞれに独自の実行コンテナがあります。 データレベルでは、マイクロサービスは「その」データにのみアクセスでき、近隣のマイクロサービスのデータベース機能については何も知りません。
|
4
| 統一された相互作用
| マイクロサービスが他のマイクロサービスがアクセスを提供するデータを必要とする場合、インターフェース呼び出しは機能するはずです。 データベースを介して隣接回線にアクセスしないでください。
|
注:MSA
には必須の再利用要件
はありません !
4.データモデルのレベル- DDD(ドメイン駆動設計) 。 最も難しい問題の1つは、マイクロサービスを作成するための一連のルールと、ソフトウェアの分析開発の初期段階との接続を保証することです。 私たちは、2つの主な目標を掲げてDDDコンセプトに基づいて構築しようとしました。 最初に、サブジェクトエリアでドメインを作成し、それらを製品チームに正常に関連付けることができます(アジャイル!)。 第二に、RESTfulサービスのリソースに対応する特定のビジネスオブジェクトを操作するためのAPIとしてマイクロサービスを形成するのに役立ちます。
- ドメインは銀行商品に対応しています。 これにより、従来の前面、背面、統合の分離から離れて、製品チームと団結することができます。
5.統合のレベル。- API管理と最初のAPIアプローチ 。 バスを使用した統合とは、サービスを再利用して、統合フローをフロントからバックに「カット」することです。 新しいバージョンでは、「API First」アプローチに焦点を当てています。 バックエンドシステムは、最も一般的なAPIを準備します。 統合は基本クリスタルの原則に基づいています。フロントエンドシステム開発者は、API管理ポータルで公開する必要があるAPI呼び出しを選択します。
- オープンAPI Open APIは、基本的に異なるカテゴリの開発者(外部、内部、パートナーエコシステム参加者)のアクセスと操作を整理するためのAPI Managementシステムの使用を意味します。 実際、パブリック組織APIを取得しています。
アーキテクチャの変更
テクノロジーの新しい組み合わせに基づいて、私たちは何になりたいかを提示しました。 以下の図は、統合バスを備えた現在のインフラストラクチャの図です。 近くに私たちが目指しているスキームがあります。

何が変わっていますか? 当初、バックオフィスレベルでは、ABSにはビジネスロジックとデータソースがあります。 バックオフィスシステムは、変更がほとんどないストレージと「核」機能のみに限定されるように努めています。 また、製品ロジックはマイクロサービスのレベルに移行しているため、ドメインごとに分割された製品を柔軟に変更および作成できます。
チャネルの規模では、マイクロサービスに基づいて、フロントエンド層に沿って「広がる」ロジックを形成および管理する計画を立てています。 その結果、フロントエンドアプリケーション自体には、チャネルロジック、つまり、要求の処理に必要なチャネルを自動化するネイティブアプリケーションのみが含まれます。
すべてのアクセス制御は、すべてのAPIが説明および公開されるAPI管理ポータルを介して実行されます。 ここで、すべての開発者がそれらに関するすべての情報を取得し、開発工場に参加できます。 GitLabテクノロジーの助けを借りて、計画、開発、テスト、リリース、運用などの継続的な作業サイクルがGitLabテクノロジーで編成されます。
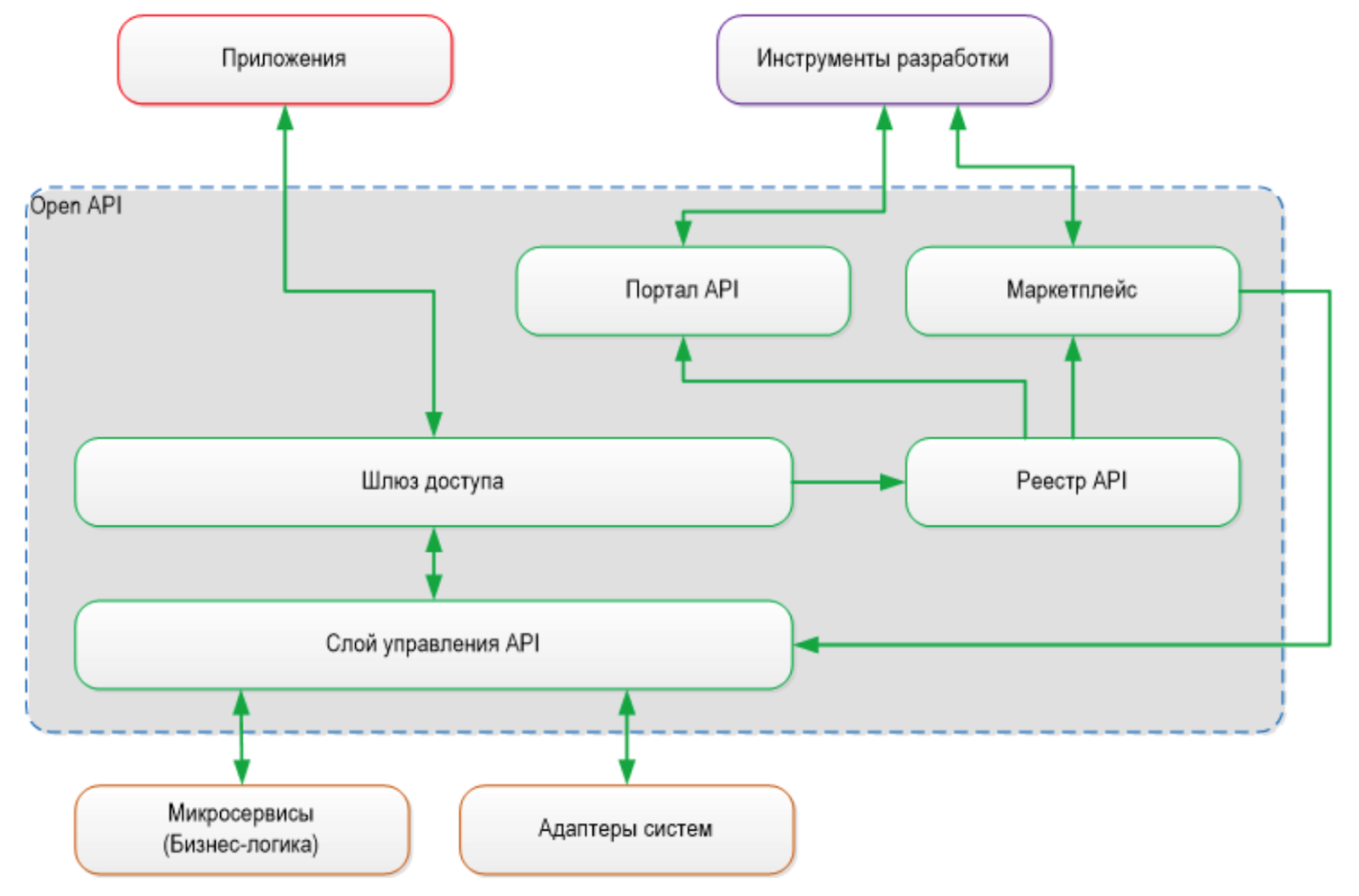 API管理とOpen APIスキーマ
API管理とOpen APIスキーマ次は?
この大きさの変化は困難なしには行かない。 それらは主に、モノリシックボックスシステムをマイクロサービスに分割すること、およびESBとデータサイロのブラックボックスの接続を復元することに関連しています。 マイクロサービスのモデルでは、ビジネスプロセスの構築にBPMエンジンを使用すると、その関連性が著しく失われます。 そして今、その代替の問題-イベント駆動型アーキテクチャと振り付けは私たちにとって非常に重要になっています。 また、純粋なDevOpsからITSec要件を含むDevSecOpsに移行し、データサイロをドメインに分割する予定です。 これらのタスクを実行するには、説明した概念の使用をテストし、最大限に活用するために、経験を積極的に収集する必要があります。