あなたが誰であるかは関係ありません-実績のある会社であっても、最初のサービスを開始しようとしている場合でも、いつでもテキストデータを使用して製品をテスト、改善、機能拡張できます。
自然言語処理(NLP)は、テキストデータに基づいて意味の検索と学習に従事する、積極的に発展している科学分野です。
この記事はどのように役立ちますか?
過去1年間、
Insightチームは数百のプロジェクトに参加し、米国の大手企業の知識と経験を組み合わせてきました。 彼らはこの研究の結果を記事にまとめました。記事の翻訳はあなたの前にあり
、機械学習の最も一般的な応用問題を解決するためのアプローチを推測しました。
機能
する最も単純な方法から始めます。そして、
機能エンジニアリング 、単語ベクトル、ディープラーニングなどのより微妙なアプローチに徐々に進みます。
記事を読んだ後、次の方法を知ることができます。
- データの収集、準備、検査。
- シンプルなモデルを構築し、必要に応じてディープラーニングに移行します。
- モデルを解釈して理解し、ノイズではなく情報を解釈していることを確認してください。
投稿はウォークスルー形式で書かれています。 また、高性能標準アプローチのレビューとして見ることもできます。
オリジナルのJupyterノートブックが元の投稿に添付され、記載されているすべてのテクニックの使用を示しています。 記事を読むときに使用することをお勧めします。機械学習を使用してテキストを理解して使用する
自然言語処理は
エキサイティングな 新しい 結果を提供し、非常に幅広い分野です。 ただし、
Insightは、他のアプリケーションよりもはるかに一般的な、実用的なアプリケーションの次の重要な側面を特定しました。
- ユーザーまたは顧客のさまざまなコホートの識別(たとえば、顧客解約の予測、顧客の総利益、製品の好み)
- レビューのさまざまなカテゴリの正確な検出と抽出(肯定的な意見と否定的な意見、衣服のサイズなどの個々の属性への参照など)
- 意味に応じたテキストの分類(基本的な支援の要請、緊急の問題)。
インターネット上のNLPのトピックに関する科学出版物やトレーニングマニュアルは多数ありますが、今日では、これらの問題の解決策を非常に基本的に検討しながら、NLPタスクを
効果的に処理する方法に関する本格的な推奨事項やヒントはほとんどありません。
ステップ1:データを収集する
サンプルデータソース
機械学習タスクはすべて、データから始まります-それが電子メールアドレス、投稿、またはツイートのリストであるかどうか。 テキスト情報の一般的なソースは次のとおりです。
- 製品のレビュー(Amazon、Yelp、さまざまなアプリストア)。
- ユーザーが作成したコンテンツ(ツイート、Facebookの投稿、StackOverflowに関する質問)。
- 診断情報(ユーザーリクエスト、サポートチケット、チャットログ)。
ソーシャルメディア災害データセット
説明されているアプローチを説明するために、
CrowdFlowerから親切に提供されたSocial Media in Disaster
データセットを使用し
ます 。
著者は、「発火中」、「検疫」、「パンデモニウム」などのさまざまな検索クエリを使用して選択された1万件を超えるツイートをレビューしました。 次に、ツイートが災害イベントに関連していたかどうか(これらの言葉を使ったジョーク、映画のレビュー、または災害に関連しないものとは対照的に)に注目しました。
無関係のトピック (たとえば、映画)に関連するツイートとは対照的に
、どのツイートが
災害イベントに関連するかを判断するタスクを設定します。 なぜこれをしなければならないのですか? 潜在的な用途は、サンドラー提督の最新の映画に注意を払う必要がある緊急の緊急職員への排他的な通知です。 このタスクの特定の難点は、これらのクラスの両方に同じ検索条件が含まれているため、より微妙な違いを使用してそれらを分離する必要があることです。
次に、災害のツイートを
「災害」と呼び、それ以外のすべてのツイートを
「無関係 」と呼びます。
ラベル
データにはタグが付けられているため、ツイートが属するカテゴリがわかります。 リチャード・ソッチャーが強調するように、通常、教師なしで複雑な教育方法を最適化しようとするよりも、モデル化
するのに十分なデータを
見つけてマークアップする方が速く、簡単で、安価です。
教師なしで機械学習タスクを定式化するのに1か月を費やすのではなく、データをマークアップして分類器をトレーニングするのに1週間を費やすだけです。ステップ2.データを消去する
ルールナンバー1:「あなたのモデルは非常に良くなることができますが、
あなたのデータはどれくらい良いですか "
プロのデータサイエンティストの重要なスキルの1つは、次のステップであるモデルまたはデータの操作を理解することです。 実践が示すように、最初はデータ自体を確認してからクリーンアップする方がよいでしょう。
クリーンなデータセットを使用すると、モデルは重要な属性を学習でき、無関係なノイズを再学習できません。以下は、データをクリアするために使用されるチェックリストです(詳細は
コードに記載されてい
ます )。
- 関係のない文字(たとえば、英数字以外の文字)をすべて削除します。
- テキストを個々の単語に分割してトークン化します。
- 無関係な単語を削除します-例えば、TwitterのメンションやURL。
- すべての文字を小文字に変換して、「hello」、「hello」、および「hello」という単語が同じ単語と見なされるようにします。
- スペルミスや代替スペルの単語(たとえば、cool / cool / cool)を組み合わせることを検討してください
- lemmatizingを検討してください。 つまり 、1つの単語のさまざまな形式を辞書形式に減らします(たとえば、「machine」、「by machine」、「machines」などの代わりに「machine」)
これらの手順を実行して追加のエラーを確認したら、クリーンなタグ付きデータを使用してモデルのトレーニングを開始できます。
ステップ3.データの適切なビューを選択します。
入力として、機械学習モデルは数値を受け入れます。 たとえば、画像を操作するモデルは、各カラーチャネルの各ピクセルの強度を表示するマトリックスを取ります。
 数字の配列として表される笑顔
数字の配列として表される笑顔データセットは文のリストであるため、アルゴリズムがデータからパターンを抽出するには、まずアルゴリズムがそれを理解できる方法でそれを提示する方法を見つける必要があります。
ワンホットエンコーディング(「単語の袋」)
コンピューターでテキストを表示する自然な方法は、各文字を個別に数字としてエンコードすることです(このアプローチの例は
ASCIIエンコードです)。 このような単純な表現を分類器に「フィード」する場合、ほとんどのデータセットでは不可能なデータのみに基づいて、単語の構造をゼロから研究する必要があります。 したがって、より高いレベルのアプローチを使用する必要があります。
たとえば、データセット内のすべての一意の単語の辞書を作成し、辞書内の各単語に一意のインデックスを関連付けることができます。 その後、各文は辞書にある一意の単語の数と同じ長さのリストに表示でき、このリストの各インデックスには、この単語が文に出現する回数が格納されます。 このモデルは、
Bag of Wordsと呼ばれます。これは、文の語順を完全に無視するマッピングであるためです。 以下はこのアプローチの実例です。
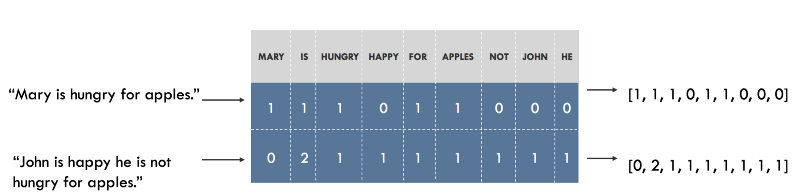 「単語の袋」の形での文章の提示。 元の文は左側に示され、そのプレゼンテーションは右側にあります。 ベクトルの各インデックスは、1つの特定の単語を表します。
「単語の袋」の形での文章の提示。 元の文は左側に示され、そのプレゼンテーションは右側にあります。 ベクトルの各インデックスは、1つの特定の単語を表します。ベクトル表現を視覚化します。
ソーシャルメディア災害辞書には、約20,000語が含まれています。 これは、各文が長さ20,000のベクトルに反映されることを意味します。各文には辞書の小さなサブセットのみが含まれるため、このベクトルには
主にゼロが含まれます。
ベクトル表現(
埋め込み )が
タスクに関連する情報をキャプチャ
するかどうか(たとえば、ツイートが災害に関連するかどうかなど)を調べるには、それらを視覚化して、これらのクラスがどの程度分離されているかを確認する必要があります。 辞書は通常非常に大きく、20,000次元のデータ視覚化は不可能であるため、
主成分法 (PCA)のようなアプローチは
、データを2次元に投影するのに役立ちます。
 「単語の袋」のベクトル表現の可視化
「単語の袋」のベクトル表現の可視化結果のグラフから判断すると、2つのクラスが本来のように分離されているようには見えません。これは、ビューの機能であるか、単に次元を縮小する効果である可能性があります。 「単語の袋」の機能が役立つかどうかを調べるために、それらに基づいて分類器をトレーニングできます。
ステップ4.分類
初めてタスクを開始するときは、この問題を解決できる最も単純な方法またはツールから開始するのが一般的です。 データ分類に関しては、汎用性と解釈の容易さから、最も一般的な方法は
ロジスティック回帰です。 モデルから最も重要な係数をすべて簡単に抽出できるため、トレーニングは非常に簡単で、その結果を解釈できます。
データをトレーニングサンプルに分割して、モデルをトレーニングするために使用します。テストサンプルは、これまで見たことのないデータに対してモデルがどれだけうまく一般化されるかを確認します。 トレーニング後、精度は75.4%になります。 そんなに悪くない! 最も頻繁なクラス(「無関係」)を推測すると、57%しか得られません。
ただし、75%の精度の結果で十分な場合でも、理解しようとせずに本番環境でモデルを使用しないでください。
ステップ5.検査
エラーマトリックス
最初のステップは、モデルで発生するエラーの種類と、今後発生する可能性の低いエラーの種類を理解することです。 この例の場合、
偽陽性の結果は無関係なツイートを大災害として分類し、
偽陰性の結果は大災害を無関係なツイートとして分類します。 すべての潜在的なイベントに対応することが優先される場合は、偽陰性の応答を減らしたいと思います。 ただし、リソースが限られている場合は、低い偽陰性率を優先して、誤報の可能性を減らすことができます。 この情報を視覚化する良い方法は、モデルで作成された予測と実際のラベルを比較
するエラーマトリックスを使用
することです。 理想的には、このマトリックスは左上から右下隅に向かう対角線になります(これは、予測が真実と完全に一致したことを意味します)。

私たちの分類器は、偽陽性よりも偽陰性の結果を(比例的に)作成します。 言い換えれば、私たちのモデルで最もよくある間違いは、大災害を不適切と分類することです。 偽陽性が法執行機関の高コストを反映している場合、これは分類器にとって適切なオプションである可能性があります。
モデルの説明と解釈
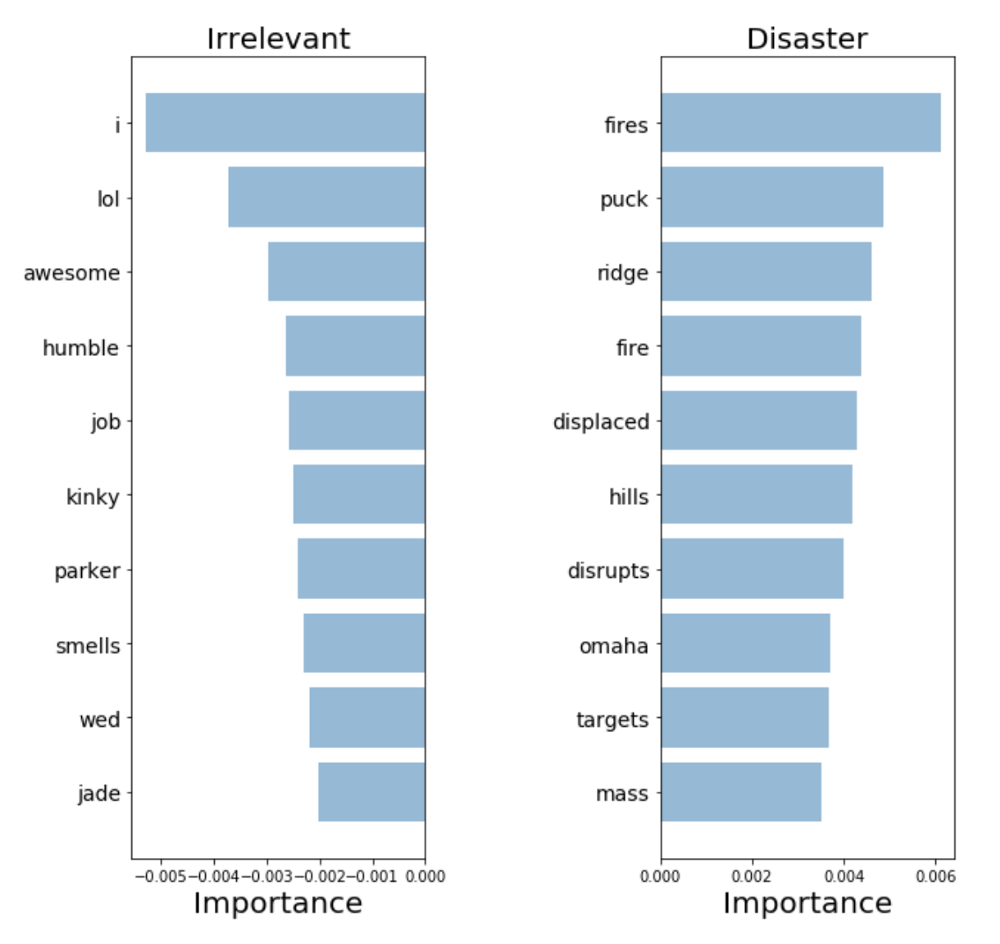
モデルを検証してその予測を解釈するには、意思決定に使用する単語を検討することが重要です。 データにバイアスがかかっている場合、分類器はサンプルデータの正確な予測を行いますが、モデルは実際の世界でそれらを十分に一般化できません。 以下の図は、災害クラスと無関係なツイートの最も重要な単語を示しています。 「単語の袋」とロジスティック回帰を使用する場合、モデルが予測に使用する係数を単純に抽出してランク付けするため、単語の意味を反映したチャートを作成することは難しくありません。
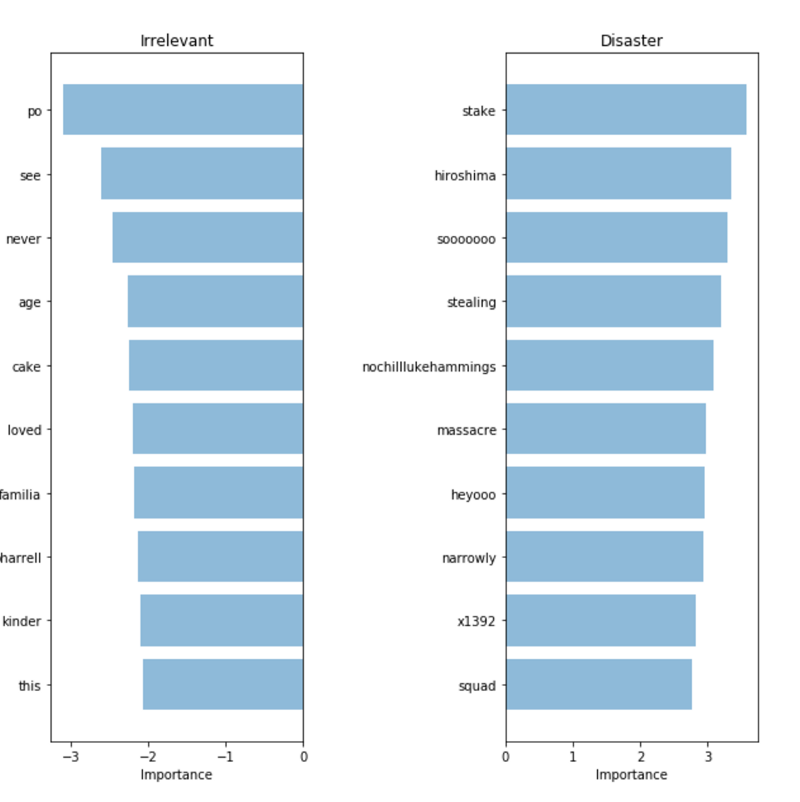 言葉の袋:言葉の重要性
言葉の袋:言葉の重要性分類子はいくつかのパターン(
hiroshima- "Hiroshima"、
虐殺 -"massacre")を正しく見つけましたが、彼がいくつかの意味のない用語( "heyoo"、 "x1392")で再訓練したことは明らかです。 そのため、今では「単語の袋」がさまざまな単語の巨大な辞書を扱っており、これらの単語はすべて彼にとって同等です。 ただし、これらの単語の一部は非常に一般的であり、予測にノイズを追加するだけです。 したがって、単語の頻度を考慮できるように文を提示する方法を見つけ、データからより有用な情報を取得できるかどうかを確認します。
ステップ6.辞書の構造を検討する
TF-IDF
モデルが意味のある単語に焦点を当てるのを助けるために、「ワードバッグ」モデルの上にスコアリングする
TF-IDF (
用語頻度、逆文書頻度 )を使用できます。 TF-IDFは、データセット内のそれらがどれほどまれであるかに基づいて重み付けを行い、あまりにも一般的でノイズを追加する優先語を減らします。 以下は、新しいビューを評価するための主成分法の予測です。
 TF-IDFを使用したベクトル表現の可視化。
TF-IDFを使用したベクトル表現の可視化。2つの色の間の明確な分離を観察できます。 これは、分類器が両方のグループを分離しやすくなることを示しています。 結果がどのように改善されるかを見てみましょう。 新しいベクトル表現で別のロジスティック回帰をトレーニングすると、
76.2%の精度が得られます。
非常にわずかな改善。 モデルがより重要な単語を選択し始めたのかもしれません。 この部分で得られた結果が良くなり、モデルに「チート」を許可しない場合、このアプローチは改善と見なすことができます。
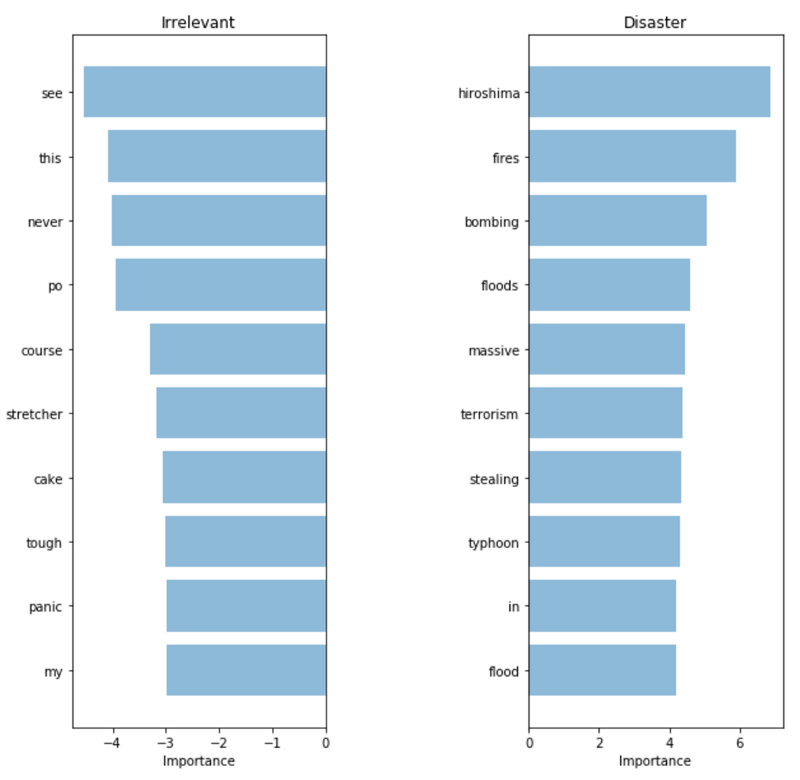 TF-IDF:言葉の重要性
TF-IDF:言葉の重要性モデルによって選択された単語は、実際にはるかに関連性があります。 テストセットのメトリックがわずかに増加したという事実にもかかわらず、顧客とやり取りする実際のシステムで
モデルを使用することにより自信が持てるようになりました。
ステップ7.セマンティクスの適用
Word2vec
私たちの最新モデルは、最も意味のある言葉を「つかむ」ことができました。 ただし、本番環境で彼女をリリースすると、トレーニングサンプルで見つからなかった単語に遭遇する可能性が高く、トレーニング中
に非常に類似した単語を見たとしても、これらのツイートを正確に分類することはできません。
この問題を解決
するには、単語のセマンティック(意味)の意味を把握する必要があります。つまり、「良い」と「肯定的な」という言葉は「アプリコット」と「大陸」という言葉よりも近いことを理解することが重要です。 Word2Vecツールを使用して、単語の意味を一致させます。
事前トレーニングの結果を使用する
Word2Vecは、単語の連続マッピングを見つけるための手法です。 Word2Vecは、膨大な量のテキストを読んでから、どの単語が同様の文脈で現れるかを覚えることで学習します。 十分なデータでトレーニングした後、Word2Vecは辞書内の各単語に対して300次元のベクトルを生成します。この場合、類似した意味を持つ単語は互いに近くに配置されます。
オープンアクセスでレイアウトされた単語の連続ベクトル表現のトピックに関する
出版物の著者は、以前に非常に大量の情報で訓練されたモデルにアクセスし、それをモデルで使用して、単語の意味的意味に関する知識をもたらすことができます。 事前にトレーニングされたベクターは、この
記事で言及されているリポジトリから取得できます。
提供レベルの表示
分類子の文の添付ファイルをすばやく取得する方法は、文のすべての単語のWord2Vec評価を平均することです。 これは以前の「単語の袋」と同じアプローチですが、今回はセマンティック(セマンティック)情報を保持しながら、文の構文を失うだけです。
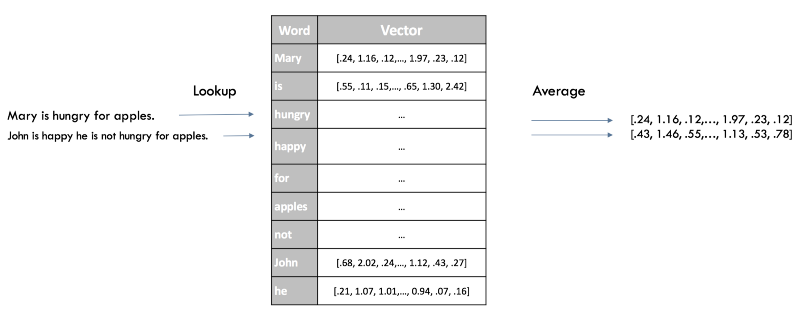 Word2Vecでの文章のベクター送信
Word2Vecでの文章のベクター送信上記の手法を使用した後の新しいベクトル表現の視覚化を次に示します。
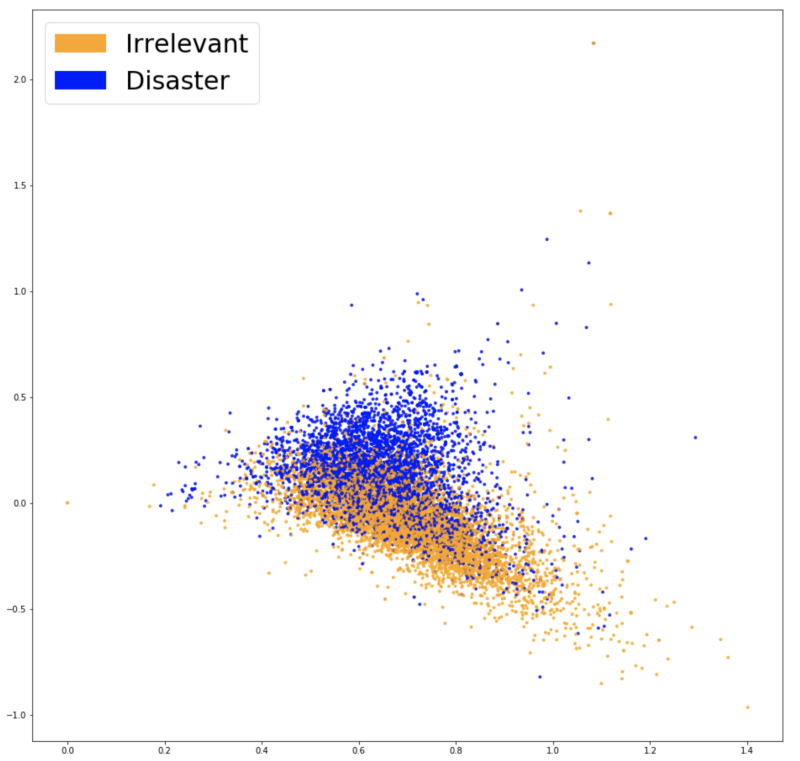 Word2Vecのベクトル表現の可視化。
Word2Vecのベクトル表現の可視化。, . ( ),
77,7% — ! .
, , , . , - , 300 , .
, — . ,
LIME , , , .
LIME
LIME Github . , ,
( — ) , .
.
 «».
«».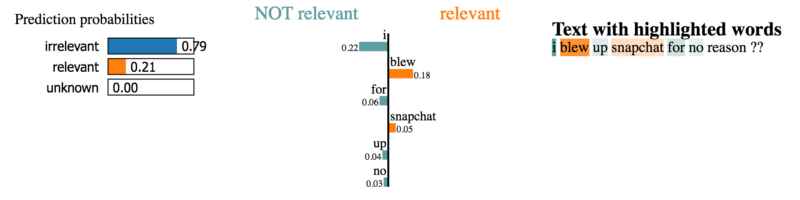 .
., , . , LIME , , . , , , .
, . , , .
8. end-to-end
. , , . , , , .
Word2Vec,
GloVe CoVe . .
 (end-to-end, )
(end-to-end, )(
CNNs for Sentence Classification ) . , (CNN) -, , , NLP (,
LSTM -
Encoder/Decoder ). , . , « » « ».
(
), , , , ,
79,5% . , , , , , , . , .
結論として
, , :
, , — , ; ,
.
, , , , . ++ Highload++ , , . , , :
- / (Allianz)
- / (Superjob)
- / (1-)
- / (Datastars)
++ Highload++ Siberia , , , .