最近、 Pythonプログラミング言語は 、科学分野と商業分野の両方で、データ分析にますます使用されています。 これは、言語のシンプルさと幅広いオープンライブラリによって促進されます。
この記事では、いくつかのPythonライブラリを使用してデータを調査および分類する簡単な例を取り上げます。 研究のために、興味のあるデータセット( DataSet )を選択する必要があります。 さまざまなデータセットキットをサイトからダウンロードできます。 DataSetは通常、JSONまたはCSV形式のテーブルファイルです。 可能性を実証するために、 UFO目撃情報に関する簡単なデータセットを調べます。 私たちの目標は、生命、宇宙、その他すべての主要な質問に対する包括的な答えを得ることではなく、Pythonを使用してかなり大量のデータを処理する単純さを示すことです。 実際、UFOの代わりに任意のテーブルを配置できます。
したがって、観測テーブルには次の列があります。
- datetime-オブジェクトが登場した日付
- city-オブジェクトが登場した都市
- 状態-状態
- 国-国
- 期間(秒)-オブジェクトが表示された時間(秒)
- 期間(時間/分)-オブジェクトが表示された時間(時間/分)
- shape-オブジェクトの形状
- コメント-コメント
- 投稿日-公開日
- 緯度-緯度
- 経度-経度
スクラッチを試したい人のために、職場を準備します。 私は自宅のPCにUbuntuを持っているので、彼女に見せます。 最初に、ライブラリとともにPython3インタープリター自体をインストールする必要があります。 Ubuntuのようなディストリビューションでは、次のようになります。
sudo apt-get install python3 sudo apt-get install python3-pip
pipは、Pythonで記述されたソフトウェアパッケージをインストールおよび管理するために使用されるパッケージ管理システムです。 それを使用して、使用するライブラリをインストールします。
sklearnは機械学習アルゴリズムのライブラリです。今後、調査中のデータを分類するために必要になります。
matplotlib-グラフ作成ライブラリ、
パンダは、データを処理および分析するためのライブラリです。 一次データ処理に使用しますが、
numpy-多次元配列をサポートする数学ライブラリ、
yandex-translate -yandex APIを使用してテキストを翻訳するためのライブラリ(使用するには、YandexでAPIキーを取得する必要があります)、
pycountry-国コードを国のフルネームに変換するために使用するライブラリ、
pipパッケージの使用は簡単に言えます:
pip3 install sklearn pip3 install matplotlib pip3 install pandas pip3 install numpy pip3 install yandex-translate pip3 install pycountry
DataSetファイル-scrubbed.csvは、プログラムファイルが作成される作業ディレクトリに存在する必要があります。
それでは始めましょう。 プログラムで使用されるモジュールを接続します。 モジュールは指示に従って接続されます:
import < >
モジュールの名前が長すぎる場合、および/または利便性や政治的理由でモジュールが気に入らない場合は、asキーワードを使用してモジュールのエイリアスを作成できます。
import < > as <>
次に、モジュールで定義されている特定の属性を参照します
< >.<>
または
<>.<>
特定のモジュール属性を接続するには、 fromステートメントを使用します。 便宜上、属性にアクセスするときにモジュール名を書き込まないように、目的の属性を個別に接続できます。
from < > import <>
必要なモジュールの接続:
import pandas as pd import numpy as np import pycountry import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot3d import Axes3D from yandex_translate import YandexTranslate
グラフの可視性を改善するために、カラースキームを生成するための補助関数を作成します。 入力時に、関数は生成する必要のある色の数を受け入れます。 この関数は、色付きのリンクリストを返します。
名前の一部を英語からロシア語に翻訳するために、 translate関数を作成します。 はい、 Yandexのトランスレーター APIを使用するにはインターネットが必要です。
関数は入力引数を受け入れます。
- string-翻訳される文字列
- translator_obj-翻訳者が実装されているオブジェクト。Noneの場合、行は翻訳されません。
そして、ロシア語に翻訳された文字列を返します。
def translate(string, translator_obj=None): if translator_class == None: return string t = translator_class.translate(string, 'en-ru') return t['text'][0]
トランスレーターオブジェクトの初期化は、コードの先頭になければなりません。
YANDEX_API_KEY = ' API !!!!!' try: translate_obj = YandexTranslate(YANDEX_API_KEY) except YandexTranslateException: translate_obj = None
YANDEX_API_KEYはYandex APIアクセスキーであり、Yandexから取得する必要があります。 空の場合、 translate_objオブジェクトはNoneに初期化され、翻訳は無視されます。
dictオブジェクトをソートするための別のヘルパー関数を作成しましょう。
dict -Pythonの組み込みタイプで、データはキーと値のペアとして保存されます。 この関数は、値の降順で辞書をソートし、ソートされたキーのリストとそれに対応する値のリストを要素の順序で返します。 この機能は、ヒストグラムを作成するときに役立ちます。
def dict_sort(my_dict): keys = [] values = [] my_dict = sorted(my_dict.items(), key=lambda x:x[1], reverse=True) for k, v in my_dict: keys.append(k) values.append(v) return (keys,values)
データに直接アクセスしました。 テーブルでファイルを読み取るには、 pdモジュールのread_csvメソッドを使用します。 csvファイルの名前を関数の入力に指定し、ファイルの読み取り時の警告を抑制するために、 escapecharパラメーターとlow_memoryパラメーターを設定します。
- escapechar-無視する文字
- low_memory-ファイル処理セットアップ。 部分ではなくファイル全体を読み取るには、 Falseを設定します。
df = pd.read_csv('./scrubbed.csv', escapechar='`', low_memory=False)
テーブルの一部のフィールドには、値がNoneのフィールドがあります。 これは不確実性を示す組み込み型であるため、一部の分析アルゴリズムはこの値では正しく機能しない可能性があるため、テーブルフィールドの文字列「不明」を「 なし 」に置き換えます。 この手順は代入と呼ばれます。
df = df.replace({'shape':None}, 'unknown')
pycountryおよびyandex-translateライブラリを使用して、国コードをロシア語の名前に変更します。
country_label_count = pd.value_counts(df['country'].values)
空にあるオブジェクトの種類の名前をすべてロシア語に翻訳します。
shapes_label_count = pd.value_counts(df['shape'].values) for label in list(shapes_label_count.keys()): t = translate(str(label), translate_obj)
ここで一次データ処理が完了します。
国別の観測スケジュールを作成します。 プロットには、 pyplotライブラリが使用されます。 簡単なスケジュールを作成する例は、公式ウェブサイトhttps://matplotlib.org/users/pyplot_tutorial.htmlにあります 。 ヒストグラムを作成するには、 barメソッドを使用できます。
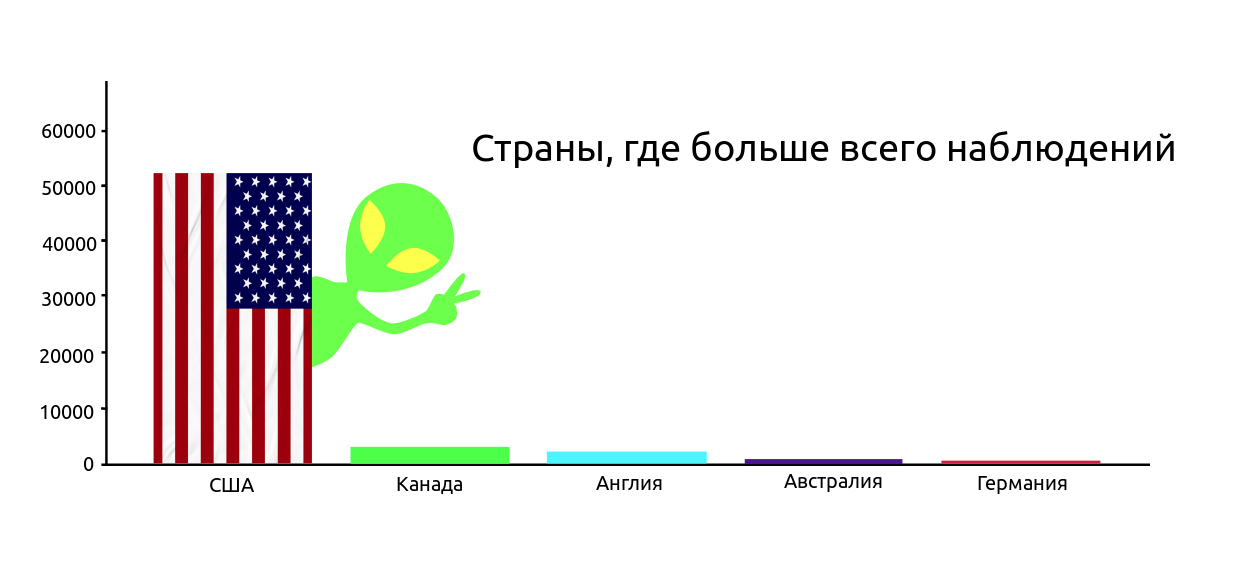
country_count = pd.value_counts(df['country'].values, sort=True) country_count_keys, country_count_values = dict_sort(dict(country_count)) TOP_COUNTRY = len(country_count_keys) plt.title(', ', fontsize=PLOT_LABEL_FONT_SIZE) plt.bar(np.arange(TOP_COUNTRY), country_count_values, color=getColors(TOP_COUNTRY)) plt.xticks(np.arange(TOP_COUNTRY), country_count_keys, rotation=0, fontsize=12) plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE) plt.ylabel(' ', fontsize=PLOT_LABEL_FONT_SIZE) plt.show()
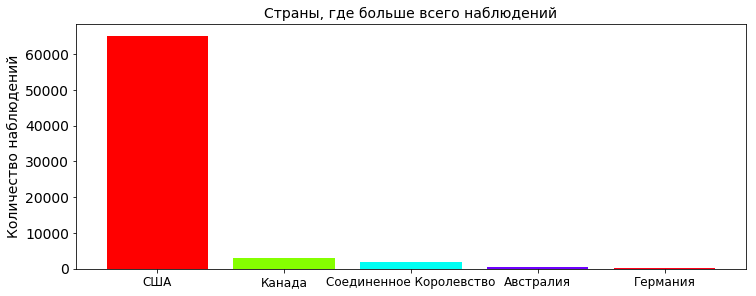
ほとんどの観測は米国では自然です。 ここでは、結局のところ、UFOを見るすべてのオタクが米国に住んでいます(テーブルが米国市民によって作成されたバージョンをいたずらに無視しています)。 アメリカ映画の数から判断すると、おそらく2番目の映画です。 キャップから:外国人が実際に野外で地球を訪れた場合、彼らが1つの国に興味を持つことはまずないでしょう、UFOについてのメッセージは異なる国から現れます。
また、ほとんどのオブジェクトが観測された年の何時かを見るのも興味深いです。 ほとんどの観測は春に行われているという合理的な仮定があります。
MONTH_COUNT = [0,0,0,0,0,0,0,0,0,0,0,0] MONTH_LABEL = ['', '', '', '', '', '', '', '', '' ,'' ,'' ,''] for i in df['datetime']: m,d,y_t = i.split('/') MONTH_COUNT[int(m)-1] = MONTH_COUNT[int(m)-1] + 1 plt.bar(np.arange(12), MONTH_COUNT, color=getColors(12)) plt.xticks(np.arange(12), MONTH_LABEL, rotation=90, fontsize=PLOT_LABEL_FONT_SIZE) plt.ylabel(' ', fontsize=PLOT_LABEL_FONT_SIZE) plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE) plt.title(' ', fontsize=PLOT_LABEL_FONT_SIZE) plt.show()

春の悪化が予想されたが、仮定は確認されなかった。 暖かい夏の夜と休暇期間が自分を強く感じさせているようです。
彼らが見た空のオブジェクトの形と回数を見てみましょう。
shapes_type_count = pd.value_counts(df['shape'].values) shapes_type_count_keys, shapes_count_values = dict_sort(dict(shapes_type_count)) OBJECT_COUNT = len(shapes_type_count_keys) plt.title(' ', fontsize=PLOT_LABEL_FONT_SIZE) bar = plt.bar(np.arange(OBJECT_COUNT), shapes_type_count_values, color=getColors(OBJECT_COUNT)) plt.xticks(np.arange(OBJECT_COUNT), shapes_type_count_keys, rotation=90, fontsize=PLOT_LABEL_FONT_SIZE) plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE) plt.ylabel(' ', fontsize=PLOT_LABEL_FONT_SIZE) plt.show()
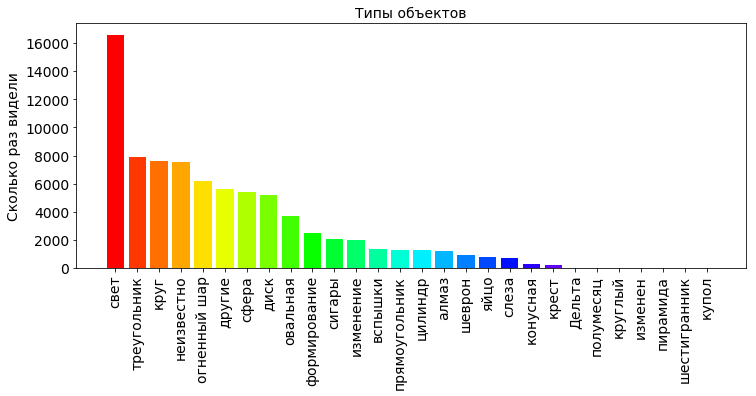
グラフから、空のほとんどすべてが光だけであることがわかります。これは原則として必ずしもUFOではありません。 この現象には明確な説明があります。たとえば、バットマン映画のように、夜空はサーチライトからの光を反射します。 また、これは北極光である可能性が高く、極域だけでなく、中緯度でも、場合によってはユーケーターの近くでさえ現れます。 一般に、地球の大気には、さまざまな性質、電場、磁場の多くの放射線が浸透しています。
一般に、地球の大気には、さまざまな性質、電場、磁場の多くの放射線が浸透しています。
詳細については、
https :
//www.nkj.ru/archive/articles/19196/を参照して
ください (科学と生命、空に輝くものは?)
また、各オブジェクトが空に現れた平均時間を見るのも興味深いです。
shapes_durations_dict = {} for i in shapes_type_count_keys: dfs = df[['duration (seconds)', 'shape']].loc[df['shape'] == i] shapes_durations_dict[i] = dfs['duration (seconds)'].mean(axis=0)/60.0/60.0 shapes_durations_dict_keys = [] shapes_durations_dict_values = [] for k in shapes_type_count_keys: shapes_durations_dict_keys.append(k) shapes_durations_dict_values.append(shapes_durations_dict[k]) plt.title(' ', fontsize=12) plt.bar(np.arange(OBJECT_COUNT), shapes_durations_dict_values, color=getColors(OBJECT_COUNT)) plt.xticks(np.arange(OBJECT_COUNT), shapes_durations_dict_keys, rotation=90, fontsize=16) plt.ylabel(' ', fontsize=12) plt.show()
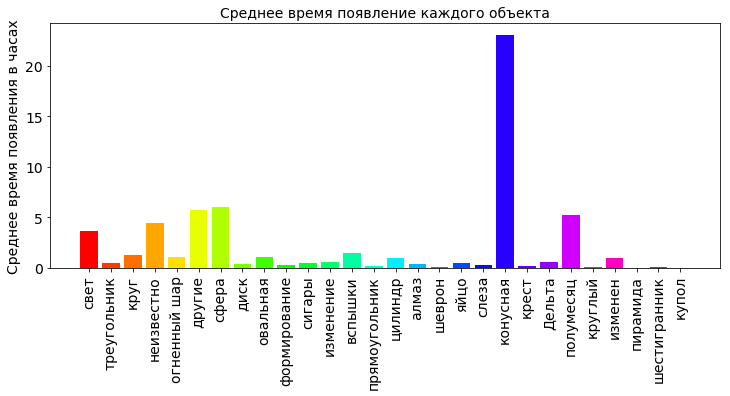
図から、コーンは平均してほとんど空にかかっていることがわかります(20時間以上)。 インターネットを掘り下げてみると、空の円錐形がはっきりしていることがわかります。これは、円錐形の光だけです(予想外ですよね?)。 おそらく彗星の落下からの光です。 20時間を超える平均時間は、ある種の非現実的な価値です。 調査中のデータには大きな広がりがあり、エラーが入り込む可能性があります。 出現時間の非常に大きく、誤った値がいくつかあると、平均値の計算が大きく歪む可能性があります。 したがって、偏差が大きい場合、平均値ではなく中央値が考慮されます。
中央値はサンプルを特徴付ける特定の数値で、サンプルの半分はこの数値より小さく、もう一方は大きくなります。 中央値を計算するには、 中央値関数を使用します。
上記のコードで置き換えます:
shapes_durations_dict[i] = dfs['duration (seconds)'].mean(axis=0)/60.0/60.0
に:
shapes_durations_dict[i] = dfs['duration (seconds)'].median(axis=0)/60.0/60.0
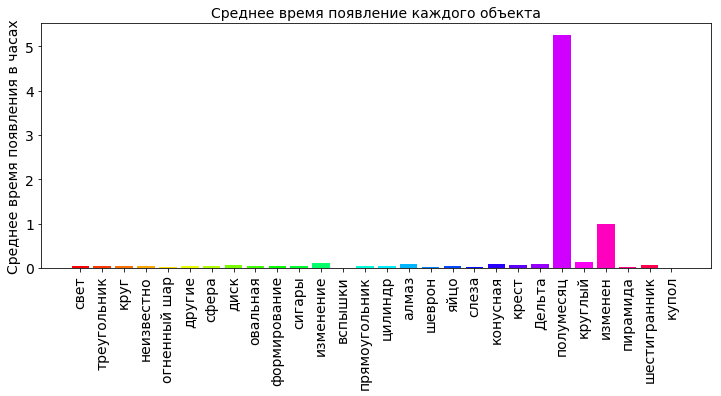
三日月が5時間強で空に見えました。 他のオブジェクトは、空で短時間点滅しませんでした。 これはすでに最も信頼できるものです。
Pythonでのデータ処理方法論の最初の知り合いについては、十分だと思います。 以下の出版物では、統計分析を行い、それほど重要ではない別の例を選択します。
便利なリンク:
Jupyterデータとblotknotアーカイブへのリンク
データ前処理用ライブラリ
機械学習アルゴリズムライブラリ
データ視覚化のためのライブラリ
Jupyterの使用に関するロシア語のチュートリアル