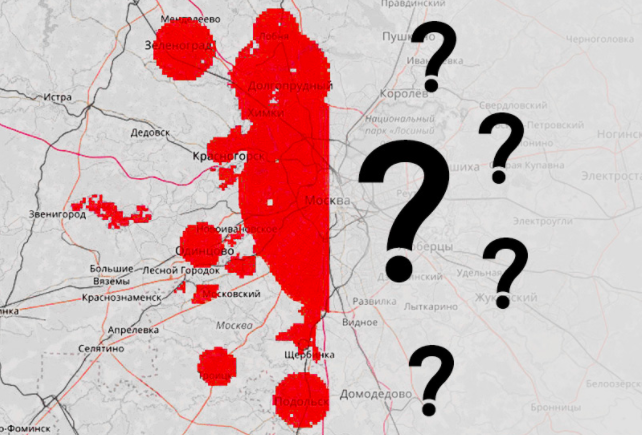
Geohack.112オンラインハッカソンから問題を解決してください。 与えられた:モスクワとモスクワ地方の領土は、500から500メートルの大きさの正方形に分割されました。 1日あたりの緊急コールの平均数(番号112、101、102、103、104、010、020、030、040)が初期データとして表示されます。 検討中の地域は、西部と東部に分けられました。 参加者は、すべての東部広場の緊急電話の数を予測するために、西部で勉強した後に招待されます。
 zone.csv
zone.csvテーブルには、すべての正方形とその座標がリストされます。 すべての広場はモスクワにあるか、モスクワから少し離れています。 サンプルの西部にある正方形は、モデルを訓練するように設計されています-これらの正方形については、1日あたりの正方形あたりの緊急コールの平均数がわかっています。
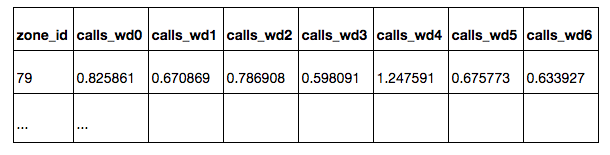
calls_daily :すべての日
calls_workday :
営業日
calls_weekend :週末
calls_wd {D} :曜日D(0-月曜日、6-日曜日)
サンプルの東部からの正方形では、曜日全体の呼び出し回数の予測を構築する必要があります。 予測の品質の評価は、正方形を含まない正方形のサブセットに基づいて行われます。正方形は含まれず、呼び出しは非常にまれです。 ターゲットの正方形のサブセットには、テーブルにis_target = 1があります。 テスト正方形の場合、calls_ *およびis_targetの値は非表示になります。
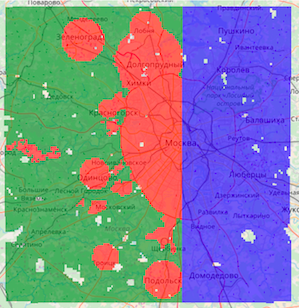
マップには3種類の正方形が示されています。
グリーンズ-トレーニング部分から、対象外
レッズ-トレーニングパートから、ターゲット
青-テスト、それらの予測を構築する必要があります
解決策として、すべてのテストスクエア、CSV予測テーブルを各スクエアごとに、曜日全体に提供する必要があります。
品質は、ターゲットの正方形のサブセットによってのみ評価されます。 参加者はどの正方形が目標かを知りませんが、トレーニングとテストのセクションで正方形を選択する原理は同じです。 競争中、品質はテスト対象の正方形の30%(ランダムに選択)と推定され、競争の終わりに、残りの70%の正方形の結果が合計されます。
予測品質メトリック-
ケンドールのTau-bランク相関係数は、ターゲット変数の同じ値を持つペアに対して調整された、誤った順序の予測を持つオブジェクトのペアの割合と見なされます。 メトリックは、正確な値ではなく、予測が相互に関連する順序を評価します。 異なる曜日は、独立したサンプリング要素と見なされます。 すべてのテストペア(zone_id、曜日)の相関係数が予測されます。
パンダを使って正方形の表を読むimport pandas df_zones = pandas.read_csv('data/zones.csv', index_col='zone_id') df_zones.head()
OpenStreetMapからの機能の取得
呼び出し回数の予測は、機械学習法を使用して行うことができます。 これを行うには、各正方形が特徴的な説明を含むベクトルを作成する必要があります。 マークアップされたモスクワの西部でモデルをトレーニングした後、それを使用して東部のターゲット変数を予測できます。
競争の状況に応じて、問題を解決するためのデータは、あらゆるオープンソースから取得できます。 地図上の小さなエリアを記述する場合、最初に思い浮かぶのは、コミュニティによって作成されたオープンで非営利の電子地図OpenStreetMapです。
OSMマップは、3つのタイプの
要素のコレクションです。
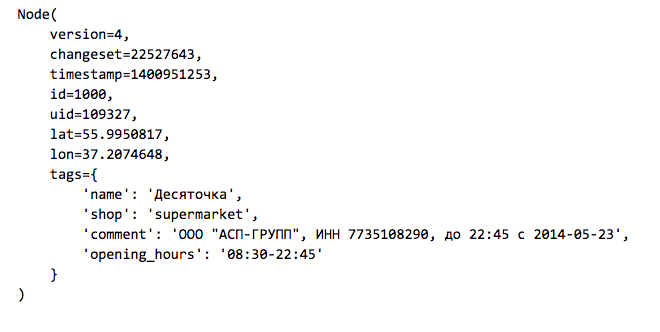
ノード:マップ上のポイント
方法:道路、正方形、ポイントのセットによって定義されます
関係:マルチパート道路への参加など、要素間の関係
要素には、タグとキーと値のペアのセットを含めることができます。 次に、マップ上でNodeタイプの要素として示されるストアの例を示します。
OpenStreetMapをアップロードする実際のデータは、
GIS-Lab.infoサイトから取得できます。 モスクワとその周辺に興味があるため、
RU-MOS.osm.pbfファイルをアップロードします。これは、
osm.pbfバイナリ形式の対応する領域からOpenStreetMapの一部です。 Pythonからこのようなファイルを読み取るためのシンプルなosmreadライブラリがあります。
作業を開始する前に、OSMから、タグを持つ必要な領域のNode型のすべての要素を検討します(残りは削除され、今後使用されません)。
コンテストの主催者は、
ここで利用可能なベースラインを準備し
ました 。 以下のコードはすべてこのベースラインに含まれています。
OpenStreetMapからオブジェクトをロードする import pickle import osmread from tqdm import tqdm_notebook LAT_MIN, LAT_MAX = 55.309397, 56.13526 LON_MIN, LON_MAX = 36.770379, 38.19270 osm_file = osmread.parse_file('osm/RU-MOS.osm.pbf') tagged_nodes = [ entry for entry in tqdm_notebook(osm_file, total=18976998) if isinstance(entry, osmread.Node) if len(entry.tags) > 0 if (LAT_MIN < entry.lat < LAT_MAX) and (LON_MIN < entry.lon < LON_MAX) ]
Pythonで作業する場合、
foliumライブラリを使用して対話型マップでジオデータをすばやく視覚化できます。これは、
内部では
Leaflet.jsがOpenStreetMapを表示するための標準ソリューションです。
フォリウムを使用した可視化の例 import folium fmap = folium.Map([55.753722, 37.620657])
結果のポイントセットを正方形で集約し、単純な記号を作成します。
1.広場の中心からクレムリンまでの距離
2.正方形の中心から半径Rの点の数(Rの異なる値の場合)
a。 タグ付きのすべてのドット
b。 鉄道駅
c。 お店
d。 公共交通機関
3.正方形の中心から上記のタイプの最も近いポイントまでの最大および平均距離
正方形の中心付近のポイントをすばやく検索するには、NearestNeighborsクラスのSciKit-Learnパッケージに実装されて
いるkdツリーデータ構造を使用
します。
正方形の特徴的な説明を含むテーブルを作成する import collections import math import numpy as np from sklearn.neighbors import NearestNeighbors kremlin_lat, kremlin_lon = 55.753722, 37.620657 def dist_calc(lat1, lon1, lat2, lon2): R = 6373.0 lat1 = math.radians(lat1) lon1 = math.radians(lon1) lat2 = math.radians(lat2) lon2 = math.radians(lon2) dlon = lon2 - lon1 dlat = lat2 - lat1 a = math.sin(dlat / 2)**2 + math.cos(lat1) * math.cos(lat2) * \ math.sin(dlon / 2)**2 c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a)) return R * c df_features = collections.OrderedDict([]) df_features['distance_to_kremlin'] = df_zones.apply( lambda row: dist_calc(row.lat_c, row.lon_c, kremlin_lat, kremlin_lon), axis=1)
その結果、トレーニングサンプルとテストサンプルの各正方形について、予測に使用できる特性記述があります。 提案されたコードを少し修正すると、標識内の他のタイプのオブジェクトを考慮することができます。 参加者は独自の特性を追加できるため、モデルに都市開発に関する詳細情報を提供できます。
コール番号予測データ分析コンテストの経験豊富な参加者は、高い地位を獲得するためには、公開リーダーボードを見るだけでなく、トレーニングサンプルで独自の検証を行うことも重要であることを知っています。 サンプルのトレーニング部分をサブサンプルに簡単に分割して、70/30の比率でトレーニングと検証を行いましょう。
ターゲットスクエアのみを取得し、ランダムフォレストモデル(RandomForestRegressor)をトレーニングして、1日あたりの平均呼び出し数を予測します。
検証サブサンプルの強調表示とRandomForestのトレーニング from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor df_zones_train = df_zones.query('is_test == 0 & is_target == 1') idx_train, idx_valid = train_test_split(df_zones_train.index, test_size=0.3) X_train = df_features.loc[idx_train, :] y_train = df_zones.loc[idx_train, 'calls_daily'] model = RandomForestRegressor(n_estimators=100, n_jobs=4) model.fit(X_train, y_train)
検証サブサンプルで品質を評価し、同じ予測を作成するすべての曜日について行います。 品質メトリックは、Kendall tau-bのノンパラメトリック相関係数であり、関数scipy.stats.kendalltauとして
SciPyパッケージに実装されてい
ます 。
検証スコアが判明:0.656881482683
これは悪くない、なぜなら メトリックの値0は相関がないことを意味し、1は実際の値と予測値の完全な単調な対応を意味します。
検証予測と品質評価 from scipy.stats import kendalltau X_valid = df_features.loc[idx_valid, :] y_valid = df_zones.loc[idx_valid, 'calls_daily'] y_pred = model.predict(X_valid) target_columns = ['calls_wd{}'.format(d) for d in range(7)] df_valid_target = df_zones.loc[idx_valid, target_columns] df_valid_predictions = pandas.DataFrame(collections.OrderedDict([ (column_name, y_pred) for column_name in target_columns ]), index=idx_valid) df_comparison = pandas.DataFrame({ 'target': df_valid_target.unstack(), 'prediction': df_valid_predictions.unstack(), }) valid_score = kendalltau(df_comparison['target'], df_comparison['prediction']).correlation print('Validation score:', valid_score)
Data Festへの招待を受け取る参加者のランクに参加する前に、1つの小さなステップが残ります。すべてのテストスクエアで予測を含むテーブルを構築し、それらをシステムに送信します。
テストで予測を作成する idx_test = df_zones.query('is_test == 1').index X_test = df_features.loc[idx_test, :] y_pred = model.predict(X_test) df_test_predictions = pandas.DataFrame(collections.OrderedDict([ (column_name, y_pred) for column_name in target_columns ]), index=idx_test) df_test_predictions.to_csv('data/sample_submission.csv') df_test_predictions.head()
位置データを分析する理由テレコム会社のデータの主なソースは、空間(地理的)だけでなく、一時的でもあり、サービス提供国の地域全体にある信号受信および送信用機器の複合体です-基地局(BS)。 空間データ分析は技術的にはより困難ですが、機械学習モデルの有効性に大きな貢献をもたらす実質的な利点と機能があります。
MTSでは、地理データの使用が知識ベースの拡大に役立ちます。 通信の品質に関する加入者の苦情を分析する際に提供されるサービスの品質を改善し、信号のカバレッジエリアを改善し、ネットワーク開発を計画し、時空間通信が重要な要素であるその他の問題を解決するために使用できます。
特に大都市では、人口密度、インフラストラクチャと道路ネットワークの急速な発展、衛星画像とベクターマップ、サービスの提供に関連するエリアの公開マップからの建物とPOI(関心のあるポイント)の数の増加-これらのすべての空間データを取得できます外部ソースから。 このようなデータは追加の情報源として使用でき、ネットワークのカバレッジに関係なく客観的な状況を把握することもできます。
あなたは挑戦が好きですか? 次に、
Geohackに参加することを
勧めます
112地理データ
分析ハッカソン 。 ソリューションを登録し、4月24日まで
サイトにアップロードします。 上位3つの結果の著者には、賞金が授与されます。 問題に対する最高のパブリックソリューションとデータジャーナリズムの最高の視覚化を提示した参加者には、個別の推薦が提供されます。 MTS GeoHackの賞金総額は
500,000ルーブルです。 空間フィーチャの生成、ジオデータの視覚化、新しいオープンソースの情報の使用に対する興味深い新しいアプローチを期待しています。
授賞式は4月28日に
DataFestカンファレンスで開催されます。