情報システムを使用して毎日どのくらいのデータを生成しますか? 膨大な量! しかし、そのようなデータを扱う可能性をすべて知っていますか? 絶対にない! この記事のフレームワークでは、Splunkでさらに運用分析するためにアップロードできるデータの種類を説明し、Fortinetログと非標準構造ログのロードを接続する方法を示します。これらのログは手動でフィールドに分割する必要があります。
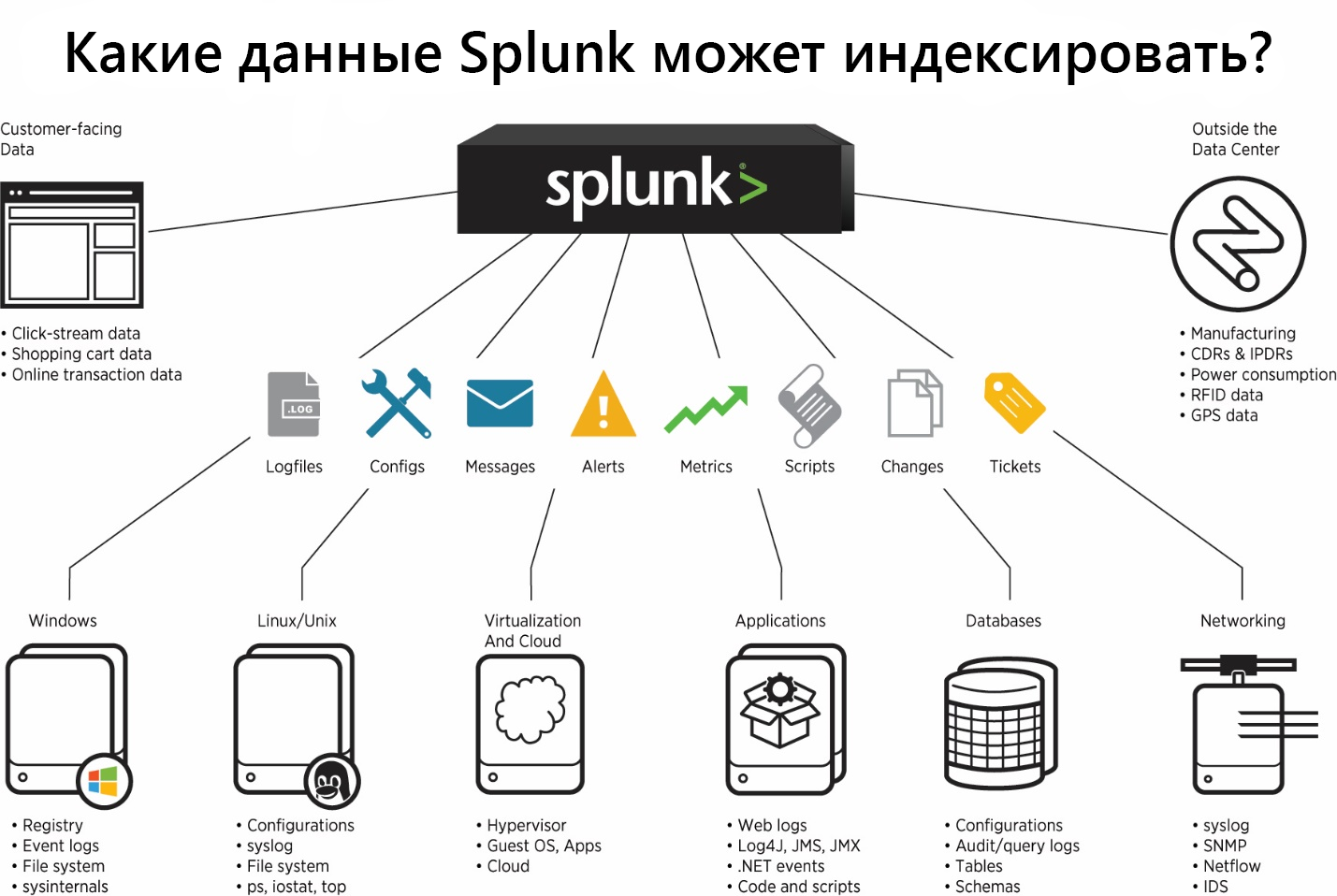
Splunkは、Splunkインデクサーと同じマシンおよびリモートデバイスにローカルにログを保存できるさまざまなソースからのデータにインデックスを付けることができます。 リモートマシンからデータを収集するには、インデクサーにデータを送信する特別なエージェントSplunk Universal Forwarderを使用します。
Splunkは、Windows、Linux、Cisco、CheckPointなどによって生成されたデータ用のアドオンなど、特定の種類のデータを読み込むための事前設定されたパラメーターを備えた多くの既製のアプリケーションとアドオンを提供します。 合計で、
SplunkBase Webサイトにある800以上のアドオンが作成されています。
データソースの種類
すべての受信データは、ソースに応じていくつかのグループに分類できます。
ファイルとディレクトリほとんどのデータは、ファイルとディレクトリから直接Splunkに送られます。 データを収集するディレクトリへのパスを指定するだけで、その後は常にデータを監視し、新しいデータが表示されるとすぐにSplunkにロードされます。 この記事の後半で、これがどのように実装されるかを示します。
ネットワークイベントまた、Splunkは、リモートsyslogデータや、TCPまたはUDPポートを介してデータを送信する他のアプリケーションなど、任意のネットワークポートからのデータにインデックスを付けることができます。 例としてフォーティネットを使用して、このタイプのデータソースを見ていきます。
WindowsソースSplunkでは、さまざまなデータの読み込みをカスタマイズできます。
イベントログ、レジストリ、WMI、Active Directory、パフォーマンス監視データなどのWindows。 以前の記事で、WindowsからSplunkへのデータのロードについて詳しく説明しました。 (リンク)
その他のデータソース- 指標
- スクリプト
- カスタムデータ読み込みモジュール
- HTTPイベントコレクター
ほとんどすべてのデータをロードできる多くのツールが既に実装されていますが、何もあなたに合わない場合でも、独自のスクリプトまたはモジュールを作成できます。これについては、以下の記事のいずれかで説明します。
フォーティネット
このセクションでは、フォーティネットのログロードの実装方法について説明します。
1.最初に、この
リンクを使用してSplunkBase Webサイトからアドオンをダウンロードする必要があります。
2.次に、Splunk-indexerにインストールする必要があります
(アプリ-アプリの管理-ファイルからアプリをインストール) 。
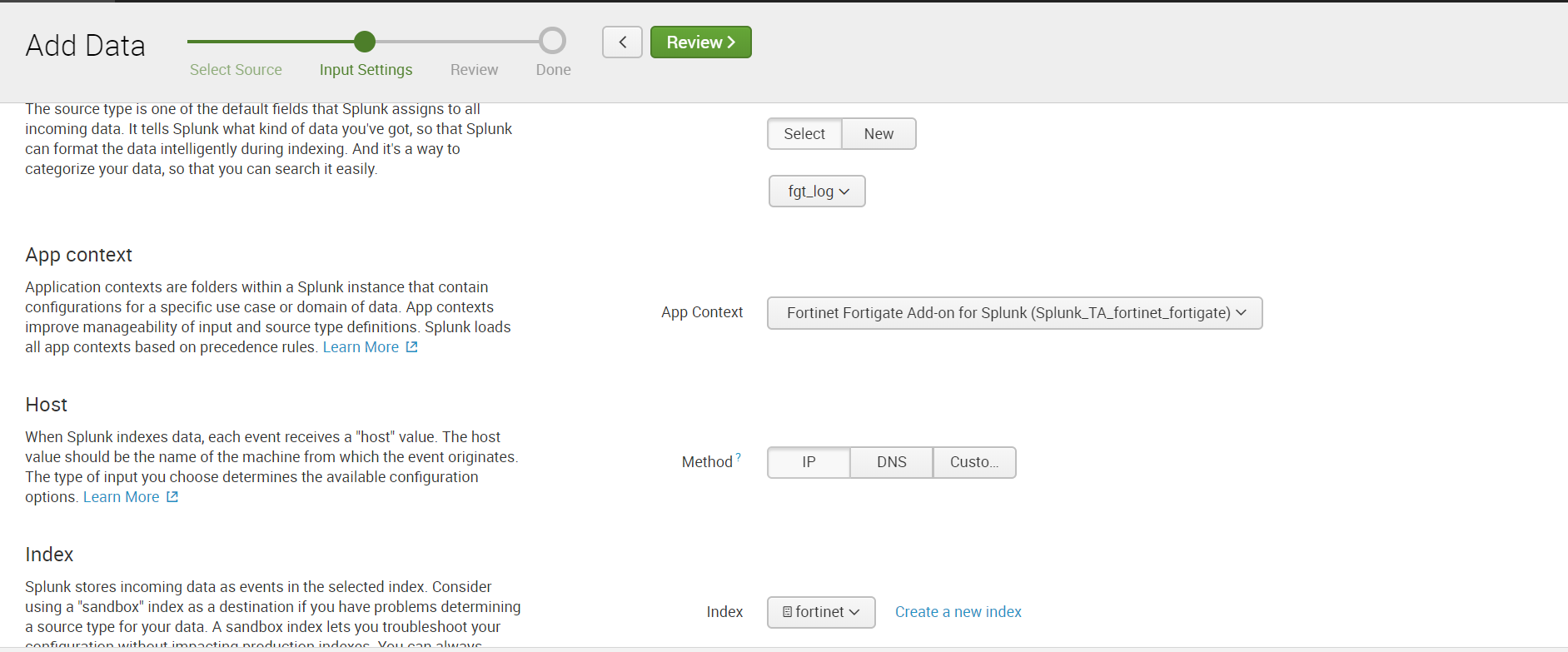
3.次に、UDPポートでのデータの受信を設定します。 これを行うには、
設定-データ入力-UDP-新規に進み
ます。 ポートを指定します。デフォルトでは514ポートです。

Sourcetype:fgt_logを選択し、必要なインデックスを選択するか、新しいインデックスを作成します。
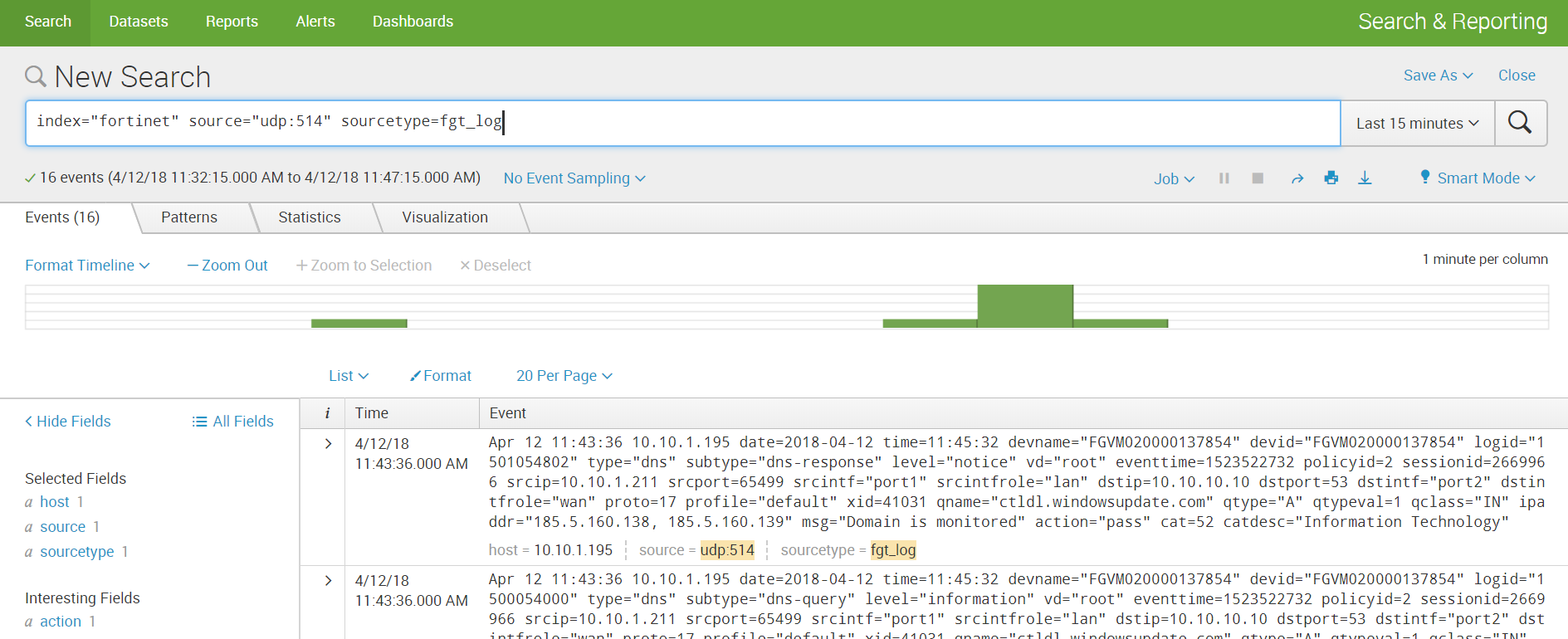
4. Fortinet自体でUDPを介したデータ送信を設定し、Splunkと同じポートを示します。
5.データを受け取り、分析を構築します。

カスタムログ
非標準のログとは、Splunkのソースタイプが不明であるため、フィールドに解析するための事前定義されたルールがないログを意味します。 フィールドの値を取得するには、最初にいくつかの簡単な操作を実行する必要があります。
このログを例として使用して、解析に加えて、ディレクトリからのデータのロードを実装する方法を示します。 データの場所に依存する2つの開発シナリオがあります。ローカルインデクサーマシン上またはリモートマシン上です。
ローカルマシン
データがSplunkローカルマシンに保存されている場合、ダウンロードは非常に簡単です。
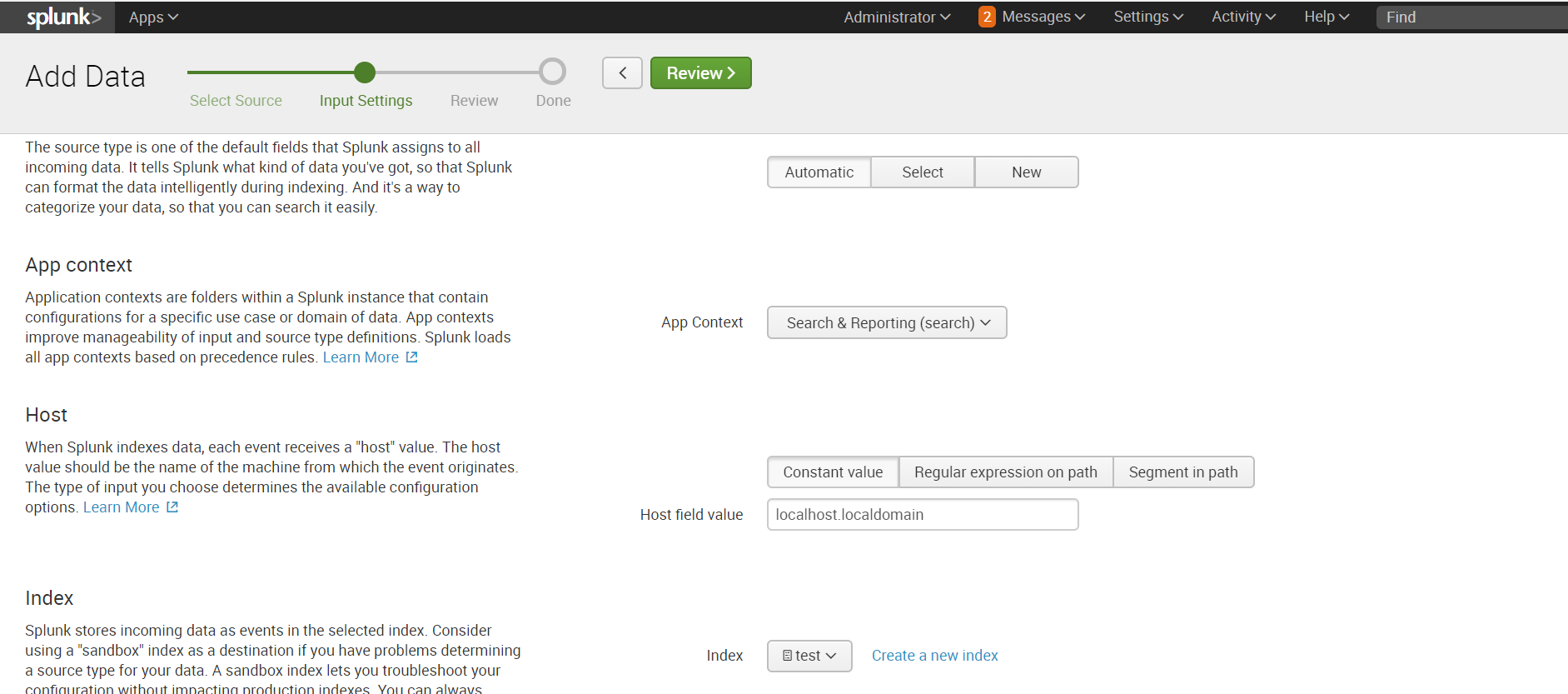
設定-データの追加-モニター-ファイルとディレクトリ
必要なディレクトリを選択します。必要に応じて、ホワイトリストまたはブラックリストを登録できます。
デフォルトでインデックスを選択するか、新しいインデックスを作成します。
リモートマシン
必要なデータが保存されているディレクトリがリモートマシンにある場合、アクションのアルゴリズムは多少異なります。 データを収集するには、SplunkインデクサーのForwarder Managementによって設定されたターゲットマシン(Splunk Universal Forwarder)のエージェント、sendtoindexerアプリケーション、およびブラウズするディレクトリを指示するアプリケーションが必要です。
前の記事でエージェントをインストールし、リモートマシンからのデータ収集を設定する方法を詳細に説明したので、繰り返しはせず、これらすべての設定が既にあると仮定します。
指定されたディレクトリからデータを送信するエージェントに応答する特別なアプリケーションを作成します。

アプリケーションは自動的に
..splunk / etc / appsフォルダーに保存されます。これを
..splunk / etc / deployment-appsフォルダーに転送する必要があります。
..monitor / localフォルダーに、
inputs.conf構成ファイルを配置する必要があります。このファイルには、転送するフォルダーを指定します。
ルートディレクトリのテストフォルダーを表示します。
[monitor:///test]
index=test
disabled = 0inputs.confファイルの詳細について
は、公式Webサイトをご覧ください 。
ターゲットマシンに関連するサーバークラスにアプリケーションを追加します。 これを行うために必要な方法と理由
は、前の記事で説明しました 。
これは、
設定-フォワーダー管理のパスをたどることで実行できることを思い出してください
。データをロードするためには、inputs.confで指定されたインデックスが存在する必要があります。インデックスが存在しない場合は、新しいインデックスを作成します。
データ解析
ダウンロード後、フィールドに分割されていないデータを受け取りました。 フィールドを選択するには、[フィールドの抽出]メニューに移動します([
すべてのフィールド ]
-[新しいフィールドの抽出 ])

組み込みのツールキットを使用してフィールドに解析できます。これは、正規表現に基づいて、指定したフィールドを強調表示します。 または、自動作業の結果が自分に合わない場合は、自分で正規表現を書くことができます。
ステップ1.フィールドを選択する
 ステップ2.
ステップ2.分離方法を選択する
正規表現を使用します。
 ステップ3.
ステップ3. 1つのフィールドに適用する値を選択して呼び出します。
 ステップ4.
ステップ4.他のイベントでフィールドが正しく強調表示されたかどうかを確認し、そうでない場合は、選択したフィールドにこのイベントを追加します。
 ステップ5.
ステップ5.構造が異なるすべてのイベントのフィールドを選択します。
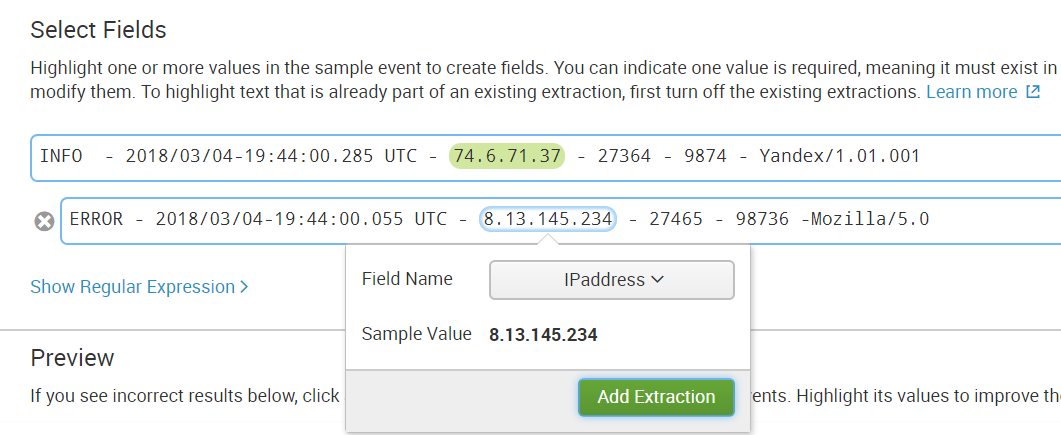 ステップ6.
ステップ6.たとえば、イベントにそのようなフィールドがない場合、余分なものが強調表示されていないか確認します。
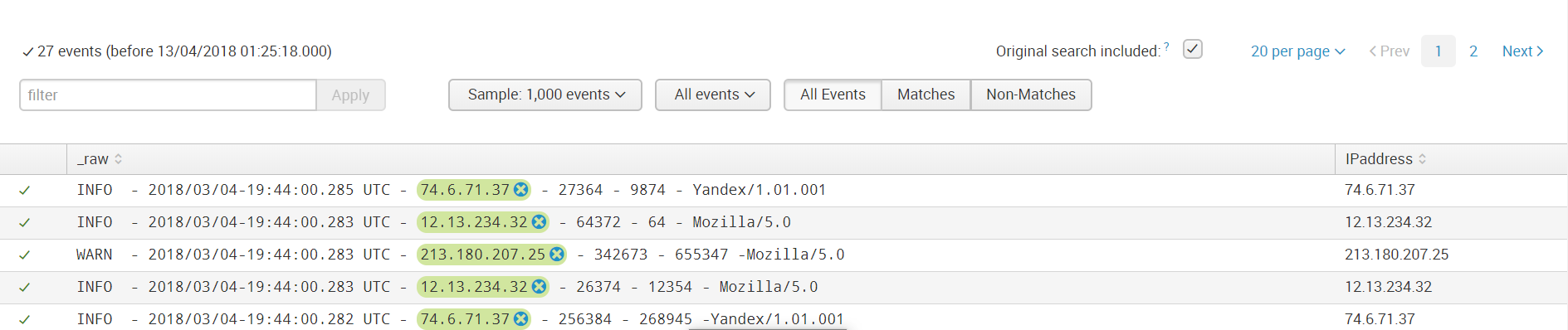
次に、フィールドを保存し、同じソースタイプのデータをロードするときに、フィールド値を強調表示するためのこのようなルールがそれらに適用されます。
次に、必要なすべてのフィールドを作成します。 これで、データをさらに分析する準備ができました。
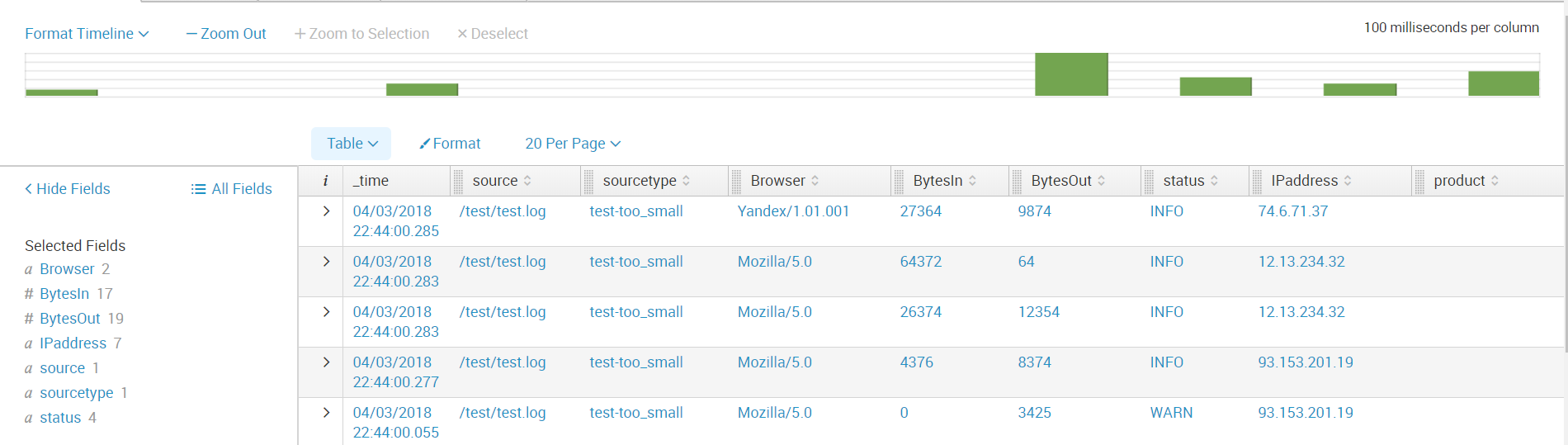
おわりに
したがって、データをSplunkにアップロードできるソースから、ネットワークポートからの受信を設定する方法、および非標準のログをダウンロードして解析する方法を示しました。
この情報がお役に立てば幸いです。
このトピックに関するすべての質問とコメントに回答させていただきます。 また、この分野、または一般的なマシンデータ分析の分野に特に興味がある場合は、特定のタスクのために既存のソリューションを完成させる準備ができています。 これを行うには、コメントにそれについて書くか、当社の
ウェブサイトのフォームからリクエストを送信してください。
