この記事は何についてですか?
C ++ SObjectizerフレームワークの主な特徴の1つは、
ディスパッチャーの可用性です。 ディスパッチャは、アクター(SObjectizerの用語ではエージェント)がイベントを処理する場所と方法を決定します:別のスレッド、作業スレッドのプール、アクターのグループに共通する1つのスレッドなど。
SObjectizerの構造には、すでに
8つのフルタイムディスパッチャーが含まれています(さらに
、SObjectizerの拡張セットにもう1つあります)。 しかし、こうした多様性にもかかわらず、特定の特定のタスクのために独自のディスパッチャを作成することが理にかなっている場合があります。 この記事では、これらの状況の1つを取り上げ、何らかの理由で通常のディスパッチャが私たちに合わない場合に、独自のディスパッチャを作成する方法を示します。 また、同じアクターを異なるディスパッチャにリンクするだけで、アプリケーションの動作を簡単に変更できることが示されます。 まあ、いくつかのより興味深いささいなこととささいなことではありません。
一般的に、C ++向けの数少ない生きている、開発中のアクターフレームワークの実装の詳細に興味がある人は、安全に読み進めることができます。
前文
最近、SObjectizerのユーザーの1人が、SObjectizerの使用中に対処しなければならなかった特定の問題について話しました。 ポイントは、SObjectizerエージェントに基づいて、コンピューターに接続されたデバイスを管理するためのアプリケーションが開発されていることです。 一部の操作(つまり、デバイスの初期化および再初期化操作)は同期的に実行されます。これにより、しばらくの間、作業スレッドがブロックされます。 I / O操作は非同期であるため、読み取り/書き込みの開始と読み取り/書き込み結果の処理は非常に高速で、長時間にわたって作業スレッドをブロックしません。
数百から数千のデバイスが多数あるため、「1つのデバイス-1つの作業スレッド」スキームを使用することは有益ではありません。 このため、作業スレッドの小さなプールが使用され、デバイス上ですべての操作が実行されます。
しかし、このような単純なアプローチには不快な機能があります。 デバイスの初期化と再初期化のための多数のアプリケーションが発生すると、これらのアプリケーションはプールのすべてのスレッドに分散され始めます。 また、読み取り/書き込みなどの短い操作がキューに蓄積され、長時間処理されないのに、プールのすべての作業スレッドが長い操作の実行でビジーになると、状況が定期的に発生します。 この状況は、たとえば、アプリケーションの起動時、デバイスを初期化するためのアプリケーションの大きな「バンドル」がすぐに形成されるとき、安定して観察されます。 そして、この「バンドル」が分解されるまで、すでに初期化されたデバイスでのI / O操作は実行されません。
この問題を解消するには、いくつかのアプローチを使用できます。 この記事では、それらの1つを分析します。つまり、アプリケーションのタイプを分析する独自のcなthread_poolディスパッチャーを作成します。
何を達成したいですか?
問題は、長時間実行されるハンドラー(つまり、デバイスを初期化および再初期化するためのハンドラー)がプール内のすべての作業スレッドをブロックし、この要求のために、短い操作(つまり、I / O)を待機できることですキューは非常に長いです。 このようなスケジューリングスキームを取得して、短い操作のリクエストが表示されたときに、キューでの待機が最小限になるようにします。
模造「スタンド」
この記事では、
上記の問題の模倣を使用します。 なぜ偽物なのか? 第一に、ユーザーの問題の本質についてのアイデアしかありませんが、詳細がわからず、彼のコードを見たことがないからです。 また、模倣により、実際の製品コードには非常に多くある細かい部分に注意を散らすことなく、解決する問題の最も重要な側面に集中することができます。
ただし、ユーザーから学んだ重要な詳細が1つあり、これは以下で説明するソリューションに最も深刻な影響を及ぼします。 実際、SObjectizerにはメッセージハンドラーのスレッドセーフの概念があります。 つまり メッセージハンドラーがスレッドセーフとしてマークされている場合、SObjectizerは他のスレッドセーフハンドラーと並行してこのハンドラーを実行する権利を持ちます。 そして、まさにそれを行うadv_thread_poolディスパッチャーがあります。
そのため、ユーザーはadv_thread_poolディスパッチャーに関連付けられたステートレスエージェントを使用してデバイスを管理しました。 これにより、キッチン全体が大幅に簡素化されます。
それで、私たちは何を検討するつもりですか?
同じエージェントからなる模造品を作成しました。 1つのエージェントは、タイプa_dashboard_tの補助エージェントです。 そのタスクは、シミュレーション実験の結果を判断するための統計を収集して記録することです。 このエージェントの
実装については考慮しません。
a_device_manager_tクラスによって実装される 2番目のエージェントは、デバイスの操作をシミュレートします。 このエージェントがどのように機能するかについて少しお話します。 これは、状態を変更する必要のないエージェントをSObjectizerに実装する方法の興味深い例です。
シミュレーションには、ほぼ同じことを行う2つのアプリケーションが含まれています。コマンドライン引数を解析し、a_dashboard_tおよびa_device_manager_tエージェントを使用してシミュレーションを開始します。 ただし、最初のアプリケーションはa_device_manager_tをadv_thread_poolマネージャーにバインドします。 しかし、2番目のアプリケーションは独自のタイプのディスパッチャーを実装し、a_device_manager_tをこの独自のディスパッチャーにバインドします。
各アプリケーションの結果に基づいて、さまざまなタイプのディスパッチャがサービスアプリケーションの性質にどのように影響するかを確認できます。
エージェントa_device_manager_t
このセクションでは、a_device_manager_tエージェントの実装における主要なポイントを強調してみます。 他のすべての詳細は
、完全なエージェントコードで確認でき
ます 。 または、コメントで明確にします。
a_device_manager_tエージェントは、同じタイプの多くのデバイスでの動作をシミュレートする必要がありますが、同時に「ステートレスエージェント」、つまり その過程で自分の状態を変えてはなりません。 まさに、エージェントはその状態を変更せず、スレッドセーフなイベントハンドラーを持つことができます。
ただし、a_device_manager_tエージェントが状態を変更しない場合、どのデバイスを初期化する必要があるか、どのデバイスを再初期化する必要があるか、どのデバイスI / O操作を実行するかをどのように決定しますか? 簡単です。この情報はすべて、a_device_manager_tエージェントがそれ自体に送信するメッセージ内で送信されます。
開始時に、a_device_manager_tエージェントは自身にN個のinit_device_tメッセージを送信します。 このようなメッセージを受信すると、a_device_manager_tエージェントは「device」のインスタンス(device_t型のオブジェクト)を作成し、初期化します。 次に、このインスタンスをポイントすると、perform_io_tメッセージで送信されます。 次のようになります。
void on_init_device(mhood_t<init_device_t> cmd) const { // . handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd); // , // . auto dev = std::make_unique<device_t>(cmd->id_, calculate_io_period(), calculate_io_ops_before_reinit(), calculate_reinits_before_recreate()); std::this_thread::sleep_for(args_.device_init_time_); // IO- // . send_perform_io_msg(std::move(dev)); }
perform_io_tメッセージを受信すると、a_device_manager_tエージェントはデバイスのI / O操作をシミュレートします。ポインターは、perform_io_tメッセージ内に配置されます。 同時に、device_tのIO操作のカウンターが減少します。 このカウンターがゼロに達すると、a_device_manager_tはreinit_device_tメッセージ(再初期化カウンターがまだリセットされていない場合)を送信するか、デバイスを再作成するためのinit_device_tメッセージを送信します。 この単純なロジックは、固執する(つまり、通常のIO操作の実行を停止する)機能を備えた実際のデバイスの動作を模倣しているため、再初期化する必要があります。 また、各デバイスのリソースが限られているため、デバイスを交換する必要があるという悲しい事実もあります。
IO操作のカウンターがまだリセットされていない場合、エージェントa_device_manager_tはもう一度メッセージperform_io_tを送信します。
コードでは、すべて次のようになります。
void on_perform_io(mutable_mhood_t<perform_io_t> cmd) const { // . handle_msg_delay(a_dashboard_t::op_type_t::io_op, *cmd); // IO-. std::this_thread::sleep_for(args_.io_op_time_); // IO- . cmd->device_->remaining_io_ops_ -= 1; // , . // , . if(0 == cmd->device_->remaining_io_ops_) { if(0 == cmd->device_->remaining_reinits_) // . . so_5::send<init_device_t>(*this, cmd->device_->id_); else // . so_5::send<so_5::mutable_msg<reinit_device_t>>(*this, std::move(cmd->device_)); } else // , IO-. send_perform_io_msg(std::move(cmd->device_)); }
以下に、このような単純なロジックを示します。これについて、詳細を明確にすることが理にかなっています。
a_dashboard_tエージェントへの情報の送信
メッセージハンドラーinit_device_t、reinit_device_t、perform_io_tでは、最初の行は同様の構成です。
handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd);
これは、特定のメッセージが要求キューで費やした量に関する情報のエージェントa_dashboard_tへの転送です。 この情報に基づいて、統計が正確に構築されます。
原則として、メッセージがアプリケーションキューに費やされた時間に関する正確な情報は、SObjectizerの内臓に侵入することによってのみ取得できます。その後、アプリケーションをキューに配置する時間とそこから抽出する時間を修正できます。 しかし、このような単純な実験では、このような極端なスポーツには従事しません。 もっと簡単にしましょう。次のメッセージを送信するときに、メッセージの予想到着時間を保存します。 たとえば、250ms遅延したメッセージを送信する場合、その時点(Tc + 250ms)でメッセージが到着するのを待ちます。Tcは現在の時刻です。 メッセージが送信された場合(Tc + 350ms)、キューで100msを費やしました。
もちろん、これは正確な方法ではありませんが、模倣に非常に適しています。
現在の作業スレッドをしばらくブロックする
また、メッセージハンドラinit_device_t、reinit_device_t、perform_io_tのコードでは、std :: this_thread :: sleep_forの呼び出しを確認できます。 これは、現在のスレッドをブロックするデバイスとの同期操作のシミュレーションに過ぎません。
遅延時間はコマンドラインから設定でき、デフォルトでは次の値が使用されます:init_device_t-1250ms、perform_io_t-50ms。 reinit_device_tの期間は、init_deviceの期間の2/3として計算されます(つまり、デフォルトで833ms)。
可変メッセージを使用する
おそらく、a_device_manager_tエージェントの最も興味深い機能は、動的に作成されたdevice_tオブジェクトの有効期間がどのように提供されるかです。 結局、init_device_tの処理中にdevice_tインスタンスが動的に作成され、このデバイスを再初期化する試みが尽きるまで生き続ける必要があります。 また、再初期化の試行が尽きると、device_tインスタンスを破棄する必要があります。
同時に、a_device_manager_tは状態を変更しないでください。 つまり a_device_manager_tには、ある種のstd :: mapまたはstd :: unordered_mapを取得できません。これは、生きているdevice_tの辞書になります。
この問題を解決するには、次のトリックを使用します。 reinit_device_tおよびperform_io_tメッセージには、device_tインスタンスへのポインターを含むunique_ptrが含まれています。 したがって、reinit_device_tまたはperform_io_tを処理し、このデバイスの次のメッセージを送信する場合、unique_ptrを古いメッセージインスタンスから新しいインスタンスに単に転送します。 インスタンスが不要になった場合、つまり reinit_device_tまたはperform_io_tを送信しなくなったため、device_tインスタンスは自動的に破棄されます。 すでに処理されたメッセージのunique_ptrインスタンスは破棄されます。
しかし、ちょっとしたトリックがあります。 通常、SObjectizerのメッセージは、変更すべきではない不変オブジェクトとして送信されます。 これは、SObjectizerがPub / Subモデルを実装し、一般的な場合にmboxにメッセージを送信するため、メッセージを受信するサブスクライバーの正確な数を正確に言うことは不可能だからです。 たぶん10個になるでしょう。 たぶん百。 たぶん千。 したがって、一部のサブスクライバーはメッセージを同時に処理します。 したがって、あるサブスクライバーがメッセージのインスタンスを変更することを許可することはできませんが、別のサブスクライバーはそのインスタンスを使用しようとします。 このため、通常のメッセージは定数リンクによってハンドラーに渡されます。
ただし、メッセージが単一の受信者に送信されることが保証されている場合があります。 そして、この受信者は受信したメッセージインスタンスを変更したいと考えています。 この例では、結果のperform_io_tからunique_ptr値を取得し、それを新しいreinit_device_tインスタンスに渡す方法を示します。
そのような場合、
変更可能なメッセージのサポートがSObjectizer-5.5.19に追加されました。 これらのメッセージには特別なマークが付いています。 また、実行時にSObjectizerは、可変メッセージがマルチプロデューサー/マルチコンシューマmboxに送信されるかどうかを確認します。 つまり 可変メッセージは、複数の受信者に配信できます。 したがって、通常の非一定リンクによって受信者に送信され、メッセージの内容を変更できます。
この痕跡は、コードa_device_manager_tにあります。 たとえば、次のハンドラシグネチャは、ハンドラが変更可能なメッセージを予期していることを示しています。
void on_perform_io(mutable_mhood_t<perform_io_t> cmd) const
しかし、このコードは、可変メッセージのインスタンスが送信されることを示しています。
so_5::send<so_5::mutable_msg<reinit_device_t>>(*this, std::move(cmd->device_));
adv_thread_poolディスパッチャーを使用したシミュレーション
a_device_manager_tが通常のadv_thread_poolマネージャーでどのように動作するかを確認するには、a_dashboard_tおよびa_device_manager_tエージェントの連携を作成し、a_device_manager_tをadv_thread_poolマネージャーにリンクする必要があります。 これは次の
ようになります :
void run_example(const args_t & args ) { print_args(args); so_5::launch([&](so_5::environment_t & env) { env.introduce_coop([&](so_5::coop_t & coop) { const auto dashboard_mbox = coop.make_agent<a_dashboard_t>()->so_direct_mbox(); // // adv_thread_pool-. namespace disp = so_5::disp::adv_thread_pool; coop.make_agent_with_binder<a_device_manager_t>( disp::create_private_disp(env, args.thread_pool_size_)-> binder(disp::bind_params_t{}), args, dashboard_mbox); }); }); }
プール内の20個のワークスレッドと他のデフォルト値を使用したテスト実行の結果、次の図が得られます。

作業の開始直後に大きな「灰色」のピークと同様に、最初に大きな「青」のピーク(これは起動時のデバイスの大規模な作成です)を見ることができます。 最初に、多数のinit_device_tメッセージを受信します。そのうちのいくつかは、順番が処理されるまで長時間待機します。 その後、perform_io_tは非常に迅速に処理され、多数のreinit_device_tが生成されます。 これらのreinit_device_tの一部は並んで待機しているため、顕著な灰色のピークがあります。 また、緑色の線に顕著な低下が見られます。 これは、reinit_device_tとinit_device_tが一括処理されている時点で処理されたperform_io_tメッセージの数が減少することです。
私たちの仕事は、「グレー」バーストの数を減らし、「グリーン」ディップをそれほど深くしないことです。
独自のcなthread_poolディスパッチャーのアイデア
adv_thread_poolディスパッチャーの問題は、彼にとってすべてのリクエストが等しいことです。 したがって、作業スレッドを解放するとすぐに、キューから最初のアプリケーションを彼女に渡します。 これがどんな種類のアプリケーションであるかを完全に理解していない。 これにより、すべての作業スレッドがinit_device_tまたはreinit_device_tのリクエストの処理でビジー状態になり、perform_io_tタイプのリクエストがキューに蓄積される状況になります。
この問題を取り除くために、2つのタイプのワークスレッドの2つのサブプールを持つ独自の巧妙なthread_poolマネージャーを作成します。
最初のタイプの作業スレッドは、あらゆるタイプのアプリケーションを処理できます。 タイプinit_device_tおよびreinit_device_tのリクエストが優先されますが、それらが現在利用できない場合、タイプperform_io_tのパフォーマンスも処理できます。
2番目のタイプのワーカースレッドは、init_device_tおよびreinit_device_tタイプのリクエストを処理できません。 タイプperform_io_tの要求は処理できますが、タイプinit_device_tの要求は処理できません。
したがって、reinit_device_tタイプの50のクレームとperform_io_tタイプの150のクレームがある場合、最初のサブプールはreinit_device_tクレームをレーキし、2番目のサブプールは同時にperform_io_tクレームをレーキします。 reinit_device_tタイプのすべての要求が処理されると、最初のサブプールの作業スレッドが解放され、perform_io_tタイプの残りの要求の処理を支援できるようになります。
巧妙なthread_poolディスパッチャーは、短いリクエストを処理するための別個のスレッドセットを保持しているため、多数の長いリクエストがある場合でも(たとえば、作業の開始時、一度に大量のinit_device_tを送信する場合など)、ショートオーダーを遅くすることはできません。
unningなthread_poolディスパッチャーを使用したシミュレーション
同じシミュレーションを行うが、異なるディスパッチャを使用する
には、上記のrun_example関数
を再実行するだけです。
void run_example(const args_t & args ) { print_args(args); so_5::launch([&](so_5::environment_t & env) { env.introduce_coop([&](so_5::coop_t & coop) { const auto dashboard_mbox = coop.make_agent<a_dashboard_t>()->so_direct_mbox(); // // . coop.make_agent_with_binder<a_device_manager_t>( tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(), args, dashboard_mbox); }); }); }
つまり すべて同じエージェントを作成しますが、今回はa_device_manager_tを別のディスパッチャにバインドします。
同じパラメータで起動した結果、別の画像が表示されます。
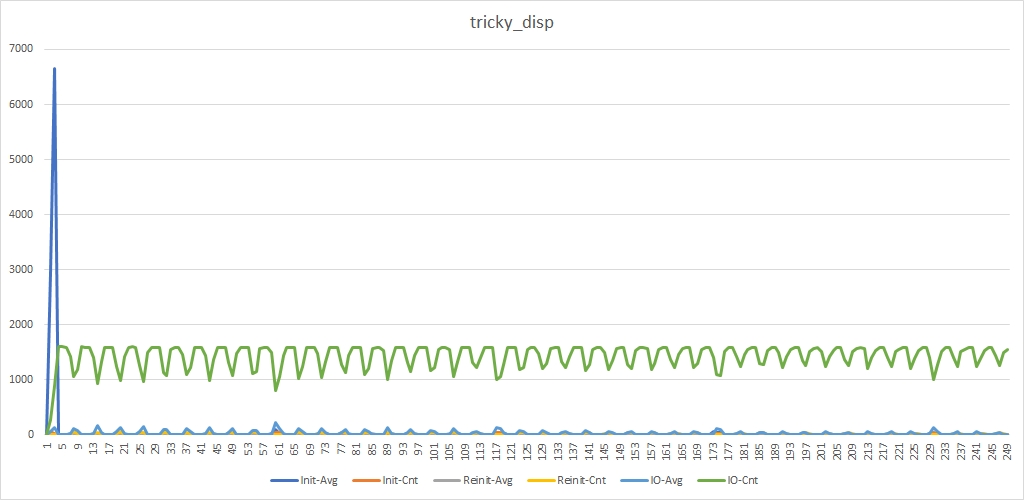
まだ同じ「青」ピークがあります。 今ではさらに高くなっていますが、驚くことではありません。 init_device_tを処理するために割り当てられる作業スレッドが少なくなりました。 しかし、「灰色」のピークは見られず、「緑」のディップはそれほど深くなりません。
つまり 望んだ結果が得られました。 そして、この最もunningなディスパッチャのコードを見ることができます。
トリッキーなthread_poolディスパッチャーの実装
SObjectizerのディスパッチャは2つのタイプに分けられます。
まず、公共ディスパッチャ。 各パブリックディスパッチャには一意の名前が必要です。 通常、ディスパッチャインスタンスは、SObjectizerの開始前、SObjectizerの開始時、パブリックディスパッチャの開始時、およびSObjectizerの終了時に停止します。 これらのコントローラーには、
特定のインターフェースが必要です。 しかし、これは時代遅れのタイプのディスパッチャです。 SObjectizerの次のメジャーバージョンでは、パブリックディスパッチャがなくなる可能性はほとんどありません。
第二に、プライベートディスパッチャー。 ユーザーは、SObjectizerの起動後いつでもこのようなディスパッチャを作成します。 プライベートディスパッチャーは、作成後すぐに起動する必要があり、使用されなくなった後は作業を終了します。 シミュレーションのために、プライベートディスパッチャとしてのみ使用できるディスパッチャを作成します。
ディスパッチャに関連する主要なポイントを見てみましょう。
ディスパッチャのdisp_binder
プライベートディスパッチャには、厳密に定義されたインターフェイスはありません。 すべての基本的な操作は、コンストラクターとデストラクターで実行されます。 ただし、プライベートディスパッチャーには、通常バインダー()と呼ばれる特別なバインダーオブジェクトを返すパブリックメソッドが必要です。 このバインダーオブジェクトは、エージェントを特定のディスパッチャーにバインドします。 そして、バインダーにはすでに明確なインターフェース
disp_binder_tがあるはずです。
したがって、
ディスパッチャでは、disp_binder_tインターフェイスを実装する独自のバインダータイプを作成します。
class tricky_dispatcher_t : public std::enable_shared_from_this<tricky_dispatcher_t> { friend class tricky_event_queue_t; friend class tricky_disp_binder_t; class tricky_event_queue_t : public so_5::event_queue_t {...}; class tricky_disp_binder_t : public so_5::disp_binder_t { std::shared_ptr<tricky_dispatcher_t> disp_; public: tricky_disp_binder_t(std::shared_ptr<tricky_dispatcher_t> disp) : disp_{std::move(disp)} {} virtual so_5::disp_binding_activator_t bind_agent( so_5::environment_t &, so_5::agent_ref_t agent) override { return [d = disp_, agent] { agent->so_bind_to_dispatcher(d->event_queue_); }; } virtual void unbind_agent( so_5::environment_t &, so_5::agent_ref_t) override { // . } }; ... // , so_5::event_queue_t , // . tricky_event_queue_t event_queue_; ... public: ... // , . so_5::disp_binder_unique_ptr_t binder() { return so_5::disp_binder_unique_ptr_t{ new tricky_disp_binder_t{shared_from_this()}}; } };
tricky_dispatcher_tクラスはstd :: enable_shared_from_thisを継承するため、参照カウンターを使用してディスパッチャーの有効期間を制御できます。 ディスパッチャーの使用が停止されるとすぐに、参照カウンターがリセットされ、ディスパッチャーは自動的に破棄されます。
ticky_dispatcher_tクラスには、tricky_disp_binder_tの新しいインスタンスを返すパブリックバインダー()メソッドがあります。 ディスパッチャー自体へのスマートポインターがこのインスタンスに渡されます。 これにより、run_exampleコードで前述したように、特定のエージェントを特定のディスパッチャに関連付けることができます。
// // . coop.make_agent_with_binder<a_device_manager_t>( tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(), args, dashboard_mbox); }); });
バインダオブジェクトは2つのことを行う必要があります。 1つ目は、エージェントをディスパッチャーにバインドすることです。 bind_agent()メソッドで行われていること。 実際、エージェントのディスパッチャへのバインドは2段階で実行されます。 まず、協力を登録するプロセスでbind_agent()メソッドが呼び出され、このメソッドはエージェントに必要なすべてのリソースを作成する必要があります。 たとえば、エージェントがactive_objディスパッチャーにバインドされている場合、新しい作業スレッドをエージェントに割り当てる必要があります。 これはまさにbind_agent()で起こるべきことです。 bind_agent()メソッドは、以前に割り当てられたリソースを使用してエージェントバインディング手順を既に完了するファンクタを返します。 つまり 協力を登録すると、まずbind_agent()が呼び出され、少し後にbind_agent()によって返されたファンクターが呼び出されます。
この場合、bind_agent()は非常に単純です。 リソースを割り当てる必要はありません。ファンクタを返すだけで、エージェントとディスパッチャが接続されます(これについては以下で詳しく説明します)。
2番目のアクションは、エージェントをディスパッチャーから切り離すことです。 この解放は、エージェントがSObjectizerから削除(登録解除)されるときに発生します。 この場合、エージェントに割り当てられている一部のリソースをクリアする必要がある場合があります。 たとえば、ディスパッチャactive_objは、エージェントに割り当てられた作業スレッドを停止します。
unbind_agent()メソッドは、2番目のアクションを実行します。 しかし、この例では、tricky_dispatcher_tではエージェントを解放するときにリソースをクリーニングする必要がないため、空です。
tricky_event_queue_t
上記で「エージェントをディスパッチャにバインドする」ことについて説明しましたが、このバインドのポイントは何ですか? ポイントは2つの簡単なことです。
まず、前述のactive_objのような一部のディスパッチャは、バインド時に特定のリソースをエージェントに割り当てる必要があります。
第二に、SObjectizerエージェントには、独自のメッセージ/リクエストキューがありません。 これが、SObjectizerと「クラシックアクターモデル」の実装との基本的な違いです。各アクターは独自のメールボックス(したがって、独自のメッセージキュー)を持ちます。
SObjectizerでは、ディスパッチャがアプリケーションのキューを所有しています。 アプリケーションの保存場所と方法(エージェントに宛てられたメッセージ)、アプリケーションの取得と処理の場所、時間、方法を決定するのはディスパッチャです。
したがって、エージェントがSObjectizer内で動作を開始すると、エージェントと注文キューの間に接続を確立する必要があります。この接続には、エージェント宛のメッセージを追加する必要があります。 これを行うには、エージェントで特別なメソッドso_bind_to_dispatcher()を呼び出し、このメソッドに
event_queue_tインターフェースを実装するオブジェクトへの参照を渡す
必要があります。 実際、これはtricky_disp_binder_t :: bind_agent()の実装に見られます。
しかし、問題は、tricky_disp_binder_tがso_bind_to_dispatcher()に正確に与えるものです。 私たちの場合、これはevent_queue_tインターフェースの特別な実装であり、これはtricky_dispatcher_t :: push_demand()を呼び出すための単なるシンプロキシとして機能します。
class tricky_event_queue_t : public so_5::event_queue_t { tricky_dispatcher_t & disp_; public: tricky_event_queue_t(tricky_dispatcher_t & disp) : disp_{disp} {} virtual void push(so_5::execution_demand_t demand) override { disp_.push_demand(std::move(demand)); } };
tricky_dispatcher_t :: push_demandは何を隠しますか?
そのため、tricky_dispatcher_tには、tricky_event_queue_tの1つのインスタンスがあり、ディスパッチャにバインドされているすべてのエージェントにリンクが渡されます。 そして、このインスタンス自体は、すべての作業をtricky_dispatcher_t :: push_demand()メソッドに単純に委任します。 push_demandの内部を見る時間です:
void push_demand(so_5::execution_demand_t demand) { if(init_device_type == demand.m_msg_type || reinit_device_type == demand.m_msg_type) { // . so_5::send<so_5::execution_demand_t>(init_reinit_ch_, std::move(demand)); } else { // , . so_5::send<so_5::execution_demand_t>(other_demands_ch_, std::move(demand)); } }
ここではすべてが簡単です。 新しいアプリケーションごとに、そのタイプがチェックされます。 要求がinit_device_tまたはreinit_device_tメッセージに関連する場合、1つの場所に配置されます。 これが他のタイプのアプリケーションである場合、別の場所に配置されます。
最も興味深いのは、init_reinit_ch_およびother_demands_ch_とは何ですか? そして、それらは
SObjectizerでmchainsと呼ばれるCSPチャネルにすぎません。
// , . so_5::mchain_t init_reinit_ch_; so_5::mchain_t other_demands_ch_;
エージェントに対して新しいアプリケーションが生成され、このアプリケーションがpush_demandに達すると、そのタイプが分析され、アプリケーションが1つのチャネルまたは別のチャネルに送信されることがわかりました。 そして、ディスパッチャプールの一部であるすでに動作しているスレッドは、すでにアプリケーションを抽出および処理しています。
ディスパッチャースレッドの実装
前述のように、トリッキーなディスパッチャは2種類のワークスレッドを使用します。
これで、最初のタイプの作業スレッドがinit_reinit_ch_からアプリケーションを読み取り、実行する必要があることはすでに明らかです。また、init_reinit_ch_が空の場合、other_demands_ch_からアプリケーションを読み取って実行する必要があります。両方のチャネルが空の場合、一方のチャネルがアプリケーションを受信するまでスリープする必要があります。または、両方のチャネルが閉じられるまで。2番目のタイプの作業スレッドを使用すると、さらに簡単になります。other_demands_ch_からのみアプリケーションを読み取る必要があります。実際、これは、tricky_dispatcher_tコードで見られるとおりです。 // so_5::execution_demand_t. static void exec_demand_handler(so_5::execution_demand_t d) { d.call_handler(so_5::null_current_thread_id()); } // . void first_type_thread_body() { // , . so_5::select(so_5::from_all(), case_(init_reinit_ch_, exec_demand_handler), case_(other_demands_ch_, exec_demand_handler)); } // . void second_type_thread_body() { // , . so_5::select(so_5::from_all(), case_(other_demands_ch_, exec_demand_handler)); }
つまり
最初のタイプのスレッドは、2つのチャネルの選択でハングします。2番目のタイプのスレッドは1つのチャネルからのみ選択されます(原則として、second_type_thread_body()内では、so_5 :: select()の代わりにso_5 :: receive()を使用できます)。実際には、アプリケーションの2つのスレッドセーフキューを整理し、これらのキューを異なるワークスレッドで読み取るために必要なことはこれだけです。トリッキーなディスパッチャの開始と停止
完全を期すために、tricky_dispatcher_tの開始と停止に関連するコードも記事に含めることは理にかなっています。コンストラクターで開始が実行され、デストラクタで停止がそれぞれ実行されます。 // . tricky_dispatcher_t( // SObjectizer Environment, . so_5::environment_t & env, // , . unsigned pool_size) : event_queue_{*this} , init_reinit_ch_{so_5::create_mchain(env)} , other_demands_ch_{so_5::create_mchain(env)} { const auto [first_type_count, second_type_count] = calculate_pools_sizes(pool_size); launch_work_threads(first_type_count, second_type_count); } ~tricky_dispatcher_t() noexcept { // . shutdown_work_threads(); }
コンストラクターでは、init_reinit_ch_およびother_demands_ch_チャンネルの作成も確認できます。ヘルパーメソッドlaunch_work_threads()およびshutdown_work_threads()は次のようになります。 // . // , // . void launch_work_threads( unsigned first_type_threads_count, unsigned second_type_threads_count) { work_threads_.reserve(first_type_threads_count + second_type_threads_count); try { for(auto i = 0u; i < first_type_threads_count; ++i) work_threads_.emplace_back([this]{ first_type_thread_body(); }); for(auto i = 0u; i < second_type_threads_count; ++i) work_threads_.emplace_back([this]{ second_type_thread_body(); }); } catch(...) { shutdown_work_threads(); throw; // . } } // , . void shutdown_work_threads() noexcept { // . so_5::close_drop_content(init_reinit_ch_); so_5::close_drop_content(other_demands_ch_); // , // . for(auto & t : work_threads_) t.join(); // . work_threads_.clear(); }
ここで、おそらく唯一の注意点は、launch_work_threadsで例外をキャッチし、shutdown_work_threadsを呼び出してから、さらに例外をスローする必要があることです。他のすべてはささいなことのようで、困難を引き起こすべきではありません。おわりに
一般的に、SObjectizerのディスパッチャの開発は簡単なトピックではありません。また、SO-5.5およびso_5_extraに含まれる標準ディスパッチャは、この記事で示したtricky_dispatcher_tよりもはるかに高度な実装を備えています。それにもかかわらず、特定の状況では、単一のフルタイムディスパッチャが100%適切でない場合、タスクに合わせて特別に調整された独自のディスパッチャを実装できます。実行時の監視や統計などの複雑なトピックに触れようとしない場合、独自のディスパッチャを書くことはそのような極端に禁止的なトピックには見えません。また、上記のtricky_dispatcher_tは、バインドされているすべてのエージェントのイベントがスレッドセーフであり、同時に何も考えずに呼び出すことができるという非常に重要な仮定のために単純であることが判明したことに注意する必要があります。ただし、これは通常そうではありません。ほとんどの場合、エージェントにはスレッドセーフでないハンドラーしかありません。ただし、スレッドセーフハンドラに遭遇した場合でも、スレッドセーフハンドラと同時に存在します。また、アプリケーションをディスパッチするときは、次のハンドラーのタイプを確認する必要があります。たとえば、次のスレッドセーフアプリケーションのハンドラが動作し、スレッドセーフが現在動作している場合、以前に起動したスレッドセーフハンドラが終了するまで待つ必要があります。通常のadv_thread_poolディスパッチャーだけがこれを処理します。しかし、実際にはほとんど使用されません。多くの場合、他のディスパッチャが使用され、ハンドラーのスレッドセーフフラグを分析しませんが、すべてのハンドラーがスレッドセーフでないと見なします。結論として、2017年のC ++ロシアでのSObjectizerについての報告の後、サイドラインで話した後、この記事で言及された可変メッセージを操作する機能がSObjectizerに追加されたと言いたいと思います。誰かがライブでSObjectizer開発者とチャットし、あなたがこれについて考えていることをすべて伝えたい場合、これはC ++ Russia 2018で行うことができます。