春、木について考える時が来ました。 リレーショナルツリー-DBは、データを扱う際の最も差し迫った問題の1つです。 このトピックでは、explain analizeコマンドを使用して、マテリアライズドパスと隣接リストメソッドのパフォーマンスを比較します。
先日、私はある良い会社でインタビューを受け、誰もが彼らがより徹底的に取り組む主題を研究する準備ができているわけではないという結論に達しました。 つまり、一見暗示的で不正確な場合があるソリューションが、最も正しい場合があります。
問題が何であるかをもう少し詳しく理解し、2つの最も単純なオプションのテストを実施することにしました。 マテリアライズドパス(MP)および隣接リスト(AL)。 ネストされたセットこのトピックの目的を考慮していません。 そして、彼の目標は、parentId_parentId_parentIdの選択と選択(pid番号)を比較することです。
最速の選択は数字によるものと思われます。 しかし、詳しく見てみましょう。 ごくまれに、相続人のいない別のブランチを選択する必要があります。 多くの場合、ネストの数、または単に相続人の数は制御されません。
したがって、各ノードで10〜30の要素の5つのレベルにネストするいくつかの異なる親ブランチを使用しました。 100万件弱のレコードを取得しました。 あまり活発ではないブログ、メールクライアントなどの非常に有効な数値
2つのタイプのツリーに対して同時にツリーテーブルとインデックスを作成します(実験の純度のためです)。
最も注意深い人は、奇妙なフィールドbtreeに気づきました。 私たちは抽象的に話し、最適化を行います。
そこで、条件付きツリー、異なるメソッド用の2つのフィールド、一意の識別子を作成しました。 たとえば、次のようにデータを追加します。
ここでは、そのように書いたので、意図的に再帰に煩わされたくありませんでした。 最初は再帰的にやりたいと思っていましたが、これは別のトピックのトピックだと思い、そのまま残しました。
リクエストが簡単になりました。 pgAdmin4を開き、コストおよびタイミングフラグを有効にしてEXPLAIN ANALYZEを起動しました。
そして、2つのリクエストに興味がありました。
MPの場合:
SELECT * FROM tree WHERE btree && ARRAY[:pid] ORDER BY array_length(btree, 1);
ALの場合:
WITH RECURSIVE nodes(id,name,pid, btree) AS ( SELECT s1.id, s1.name, s1.pid, s1.btree FROM tree s1 WHERE pid = :pid UNION SELECT s2.id, s2.name, s2.pid, s2.btree FROM tree s2, nodes s1 WHERE s2.pid = s1.id ) SELECT * FROM nodes order by pid asc;
ここで:pid-親ID。
ALメソッドのクエリは非常に複雑です。 そして、このリクエストは十分に頻繁に使用する必要があります。
結果から並べ替えを削除し、両方のクエリで同等の時間実行しますが、並べ替えは非常に大きく、それなしでは結果はより印象的です。
ここにいくつかの美しい写真があります:
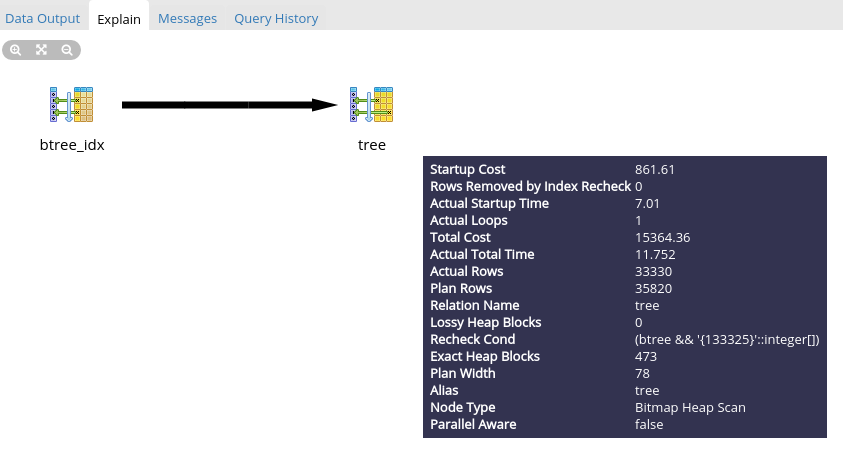
それはすべて簡単ですが、MP用です。 ALのリクエストを確認します。

すでにきれいになっていますが、MPには総コストの1.5倍の時間がかかるように見えます...それはすべて、インデックスに数字ではなく数字の配列が格納されているためです。 しかし、これにもかかわらず、MPの実行速度は1桁高くなります。 また、ネストと親要素の数が多いほど、速度の差が大きくなります。
さらに、クエリの取得が簡単であるため、単一のクエリでORMシステムを通じてデータを簡単に収集できます。 MPの大きなマイナスは、あるブランチから別のブランチにデータを転送するより複雑な方法ですが、それでもまったく透過的です。 そして、そのような操作は、原則として、大規模な性質のものではなく、これに焦点を当てることは、生産性のそのような違いにより完全に真実ではありません。
スクリーンショットでは、すべてのデータは最新のものであり、これらはピーク値ではなく、平均値です。 しかし、ピーク値であっても、速度の差は少なくとも5倍です(最も遅いMPと最速のALメソッド)。
同意します。本当にすべてを理解したい人には非常に良いボーナスです。